我们已经在前文讨论过现代投资组合理论的核心思想和关键数学框架的推导,本篇则通过Python把抽象的金融理论变成可运行、可验证的代码,并以可视化直观的感受来描绘基本特征与核心结论。我们使用的是真实的A股市场数据,简单的数据分析用AKshare即可。01 认识均值与方差——从数据到直观
以中芯国际(SH.688981)为例,获取自2022年5月1日至2026年4月30日四年的日收盘价,并计算其每日涨幅,并计算年化回报率和年化波动率:import akshare as akimport pandas as pdimport numpy as npfrom matplotlib import pyplot as plt# 下载单只股票数据(以中芯国际为例)ticker = '688981'data = ak.stock_zh_a_hist(symbol=ticker, start_date='20220501', end_date='20260430', adjust='qfq')['收盘']returns = data.pct_change().dropna()# 计算均值(年化)和波动率(年化)mean_daily = returns.mean()mean_annual = mean_daily * 241 # 241是中国A股过去4年的平均交易日数量std_daily = returns.std()std_annual = std_daily * np.sqrt(241)print(f'年化均值: {mean_annual:.2%}')print(f'年化波动率: {std_annual:.2%}')
运行输出结果为:
1.2 可视化分布
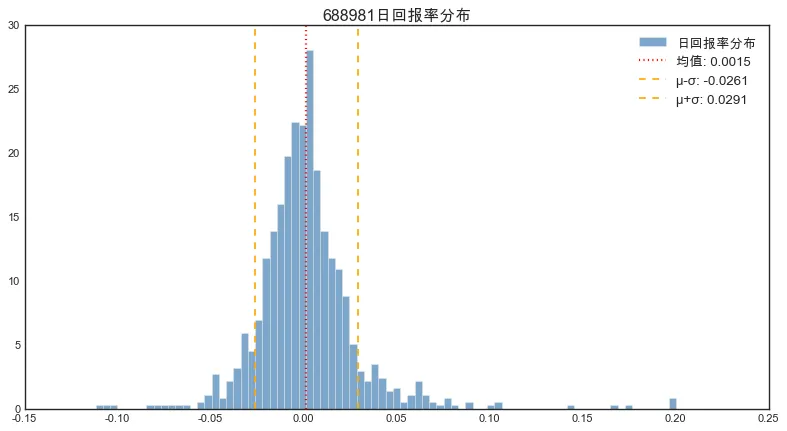
# 设置样式plt.style.use('seaborn-v0_8-white')# 设置中文字体和负号显示plt.rcParams["font.sans-serif"] = ["PingFang SC", "Arial Unicode MS", "Heiti TC"]plt.rcParams["axes.unicode_minus"] = False# 绘制直方图plt.figure(figsize=(12, 6))plt.hist(returns, bins=80, density=True, alpha=0.7, color='steelblue', label='日回报率分布')# 标注均值和均值±标准差mean = returns.mean()std = returns.std()plt.axvline(mean, color='r', linestyle=':', linewidth=2, label=f'均值: {mean:.4f}')plt.axvline(mean-std, color='orange', linestyle='--', linewidth=1.5, label=f'μ-σ: {mean-std:.4f}')plt.axvline(mean+std, color='orange', linestyle='--', linewidth=1.5, label=f'μ+σ: {mean+std:.4f}')plt.legend()plt.title(f'{ticker}日回报率分布')plt.show()
此处density=True参数使直方图总面积归一化为1,变成概率密度函数。
可视化效果如下:
很明显,股票的回报率分布为右偏,同时具备尖峰、厚尾的特征,并非正态分布。(这种特征在以后会反复提及)
1.3 协方差矩阵和相关系数矩阵
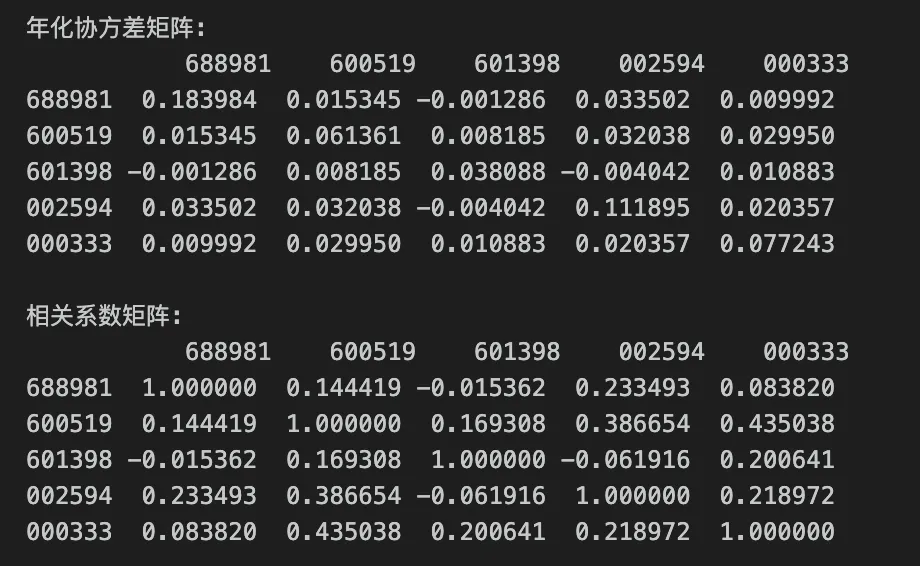
我们选取5只比较有代表性的上市公司(中芯国际、贵州茅台、工商银行、比亚迪和美的集团),计算它们回报率之间的协方差与相关系数。# 多只股票的协方差和相关系数tickers = ['688981', '600519', '601398', '002594', '000333']data = pd.DataFrame()for ticker in tickers: data[ticker] = ak.stock_zh_a_hist(symbol=ticker, start_date='20220501', end_date='20260430', adjust='qfq')['收盘']returns = data.pct_change().dropna()cov_matrix = returns.cov() * 241 # 年化协方差corr_matrix = returns.corr()print('年化协方差矩阵:\n', cov_matrix)print('\n相关系数矩阵:\n', corr_matrix)
输出结果为:
不难看出,这五只分属不同行业股票回报率的相关性很低(绝对值小于0.4),唯一比较相关的是贵州茅台(SH.600519)和美的集团(SZ.000333),相关系数为0.44,这也印证了二者同属于大消费板块,具有一定的共同特征。
02 两种资产组合的均值-方差特性
2.1 模拟组合可行集
我们用代码分析两种资产组合的回报和风险特征:
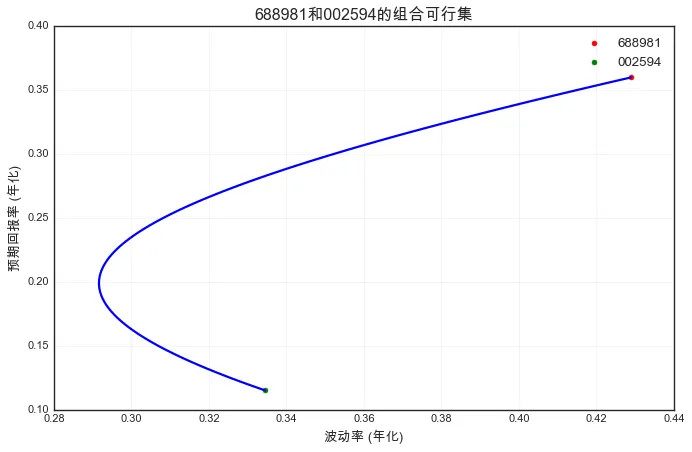
# 选取两只股票688981和002594进行组合分析rets = returns[['688981', '002594']]mean_rets = rets.mean() * 241cov_rets = rets.cov() * 241# 模拟不同权重下的组合weights = np.linspace(0, 1, 100)portfolios_returns = []portfolios_vols = []for w in weights: w_array = np.array([w, 1-w]) # 组合的预期回报率和波动率 port_ret = w_array @ mean_rets port_vol = np.sqrt(w_array @ cov_rets @ w_array) portfolios_returns.append(port_ret) portfolios_vols.append(port_vol) # 绘制可行集plt.figure(figsize=(10, 6))plt.plot(portfolios_vols, portfolios_returns, 'b-', linewidth=2)plt.scatter(np.sqrt(cov_rets.iloc[0, 0]), mean_rets.iloc[0], color='r', label='688981') plt.scatter(np.sqrt(cov_rets.iloc[1, 1]), mean_rets.iloc[1], color='g', label='002594') plt.xlabel('波动率 (年化)')plt.ylabel('预期回报率 (年化)')plt.title('688981和002594的组合可行集')plt.legend()plt.grid(True, alpha=0.3)plt.show()
输出可视化结果如下:
我们看到了什么?当权重从0(全仓比亚迪)变化到1(全仓中芯国际)时,组合的风险-回报点形成了一条曲线。曲线的左凸状表明,通过分散投资,在不牺牲太多回报的情况下降低风险,这正是马科维茨理论的核心洞见。
2.2 检验相关系数对可行集的影响
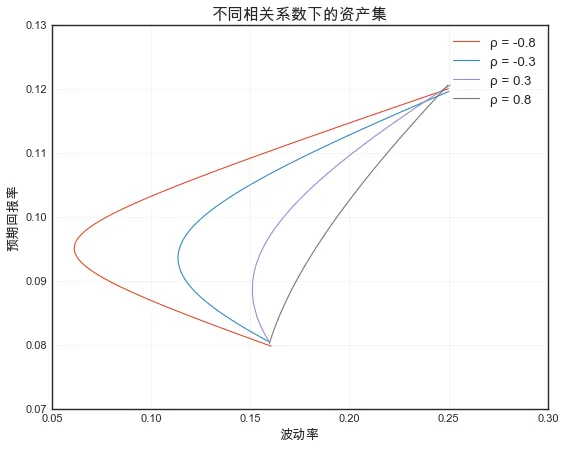
# 模拟不同相关系数的可行集np.random.seed(999)n = 100000# 生成两种具有不同相关性的资产for rho in [-0.8, -0.3, 0.3, 0.8]: mean = [0.08, 0.12] cov = [[0.16**2, rho*0.16*0.25], [rho*0.16*0.25, 0.25**2]] # 模拟资产的回报率并计算均值和标准差 returns_sim = np.random.multivariate_normal(mean, cov, n) mean_sim = returns_sim.mean(axis=0) cov_sim = np.cov(returns_sim.T) weights = np.linspace(0, 1, 100) port_rets = weights * mean_sim[0] + (1 - weights) * mean_sim[1] port_vols = [np.sqrt(np.array([w, 1-w]) @ cov_sim @ np.array([w, 1-w])) for w in weights] plt.plot(port_vols, port_rets, label=f'ρ = {rho:.1f}')plt.xlabel('波动率')plt.ylabel('预期回报率')plt.title('不同相关系数下的资产集')plt.legend()plt.grid(True, alpha=0.3)plt.show()
可视化结果如下:
由此可见,相关系数越低,组合的分散化效果越好,可行集越向左凸,风险降低空间越大。
03 构建有效前沿——均值-方差优化
3.1 模拟多只股票的有效前沿
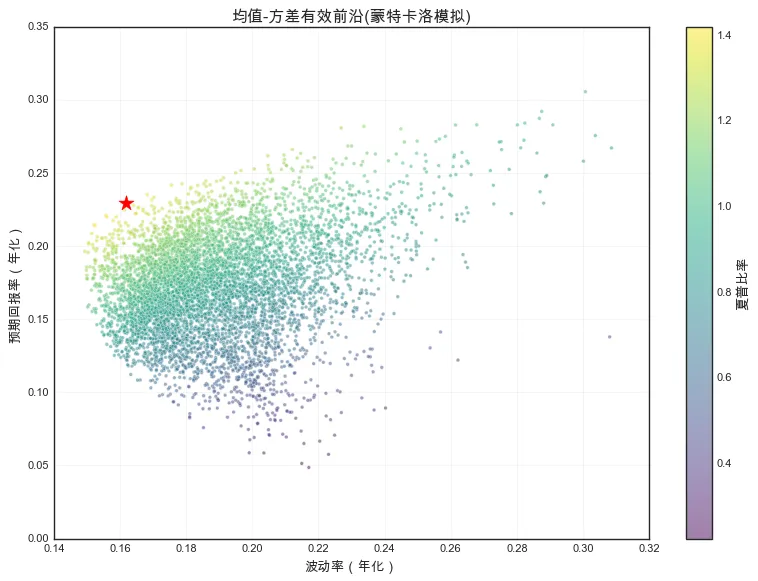
from scipy.optimize import minimize# 5只股票的预期回报率和波动率mean_rets = returns.mean() * 241cov_rets = returns.cov() * 241n_assets = len(tickers)# 蒙特卡洛模拟随机组合n_portfolios = 6000results = np.zeros((3, n_portfolios)) for i in range(n_portfolios): # 生成随机权重 weights = np.random.random(n_assets) weights /= np.sum(weights) port_ret = np.sum(weights * mean_rets) port_vol = np.sqrt(weights @ cov_rets @ weights) sharpe = port_ret / port_vol # 计算夏普比率, 假设无风险利率为0 results[0, i] = port_ret results[1, i] = port_vol results[2, i] = sharpe# 绘制所有随机组合plt.figure(figsize=(12, 6))plt.scatter(results[1, :], results[0, :], c=results[2, :], cmap='viridis', alpha=0.5, s=10)plt.colorbar(label='夏普比率')# 找出最大夏普比率的组合max_sharpe_idx = np.argmax(results[2, :]) plt.scatter(results[1, max_sharpe_idx], results[0, max_sharpe_idx], color='r', s=200, marker='*')plt.xlabel('波动率(年化)')plt.ylabel('预期回报率(年化)')plt.title('均值-方差有效前沿(蒙特卡洛模拟)')plt.grid(True, alpha=0.3)plt.show()
可视化结果如下:
上图中的红色五角星便是均值-方差的最优组合,即既定约束调价下夏普比率最高的组合。投资组合点集合的边缘勾勒出的双曲线便是有效边界,曲线的上半部分便是有效前沿。
3.2 用优化算法求出最优组合
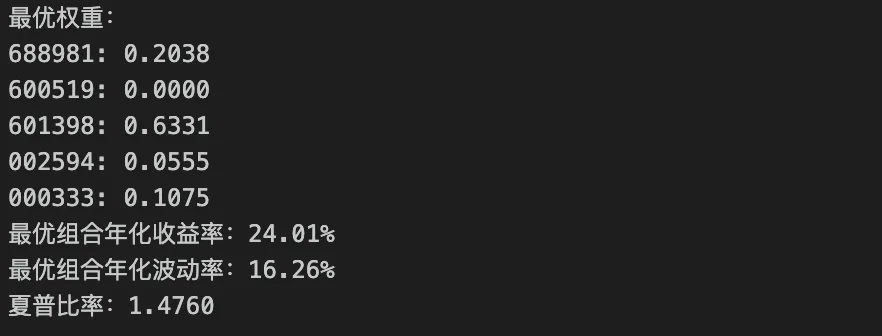
def portfolio_stats(weights): """计算组合的预期回报率和波动率""" weights = np.array(weights) port_rets = weights @ mean_rets port_vols = np.sqrt(weights @ cov_matrix @ weights) return port_rets, port_volsdef neg_sharpe(weights): """负夏普比率(用于最小化)""" port_rets, port_vols = portfolio_stats(weights) return -(port_rets / port_vols)# 约束:权重之和为1constraints = ({'type': 'eq', 'fun': lambda w: np.sum(w) - 1})# 边界: 允许做空时权重为负,不允许时权重>0bounds = tuple((0, 1) for _ in range(n_assets))# 初始猜测init_guess = np.array([1/n_assets] * n_assets) # 等权重组合# 优化:最大化夏普比率opt_result = minimize(neg_sharpe, init_guess, method='SLSQP', bounds=bounds, constraints=constraints)optimal_weights = opt_result.xopt_ret, opt_vol = portfolio_stats(optimal_weights)print('最优权重:')for t, w in zip(tickers, optimal_weights): print(f'{t}: {w:.4f}')print(f"最优组合年化收益率:{opt_ret:.2%}")print(f"最优组合年化波动率:{opt_vol:.2%}")print(f"夏普比率:{opt_ret/opt_vol:.4f}")
得出的结果为:
虽然以上是一种模拟的状态,但也能看出一些有意思的现象:在既定的5只股票构成的最优组合中,贵州茅台的权重为0(这与过去4年其回报不佳应该有关)。总的来说,在构建投资组合的过程中,通过分散化牺牲一部分回报就能极大降低波动率(风险)。