Python用LightGBM XGBoost Stacking集成学习混合线性规划生鲜冷链仓网配送优化|附数据代码
- 2026-07-02 16:33:03
全文链接:https://tecdat.cn/?p=45947原文出处:拓端数据部落公众号封面: 关于分析师在此对HaoTong Yang对本文所作的贡献表示诚挚感谢,他在南安普顿大学与江西财经大学完成了经济学与精算科学、国际商务本科双学位,专注机器学习、数学建模、运筹优化、计量经济、量化金融领域。擅长R语言、Python、Stata等软件,具备丰富的数据分析与项目实践经验。
关于分析师在此对HaoTong Yang对本文所作的贡献表示诚挚感谢,他在南安普顿大学与江西财经大学完成了经济学与精算科学、国际商务本科双学位,专注机器学习、数学建模、运筹优化、计量经济、量化金融领域。擅长R语言、Python、Stata等软件,具备丰富的数据分析与项目实践经验。
本文针对生鲜冷链物流强时效、高波动、数据稀缺的三重挑战,提出“预测-优化-协调”一体化决策框架(点击文末“阅读原文”获取完整智能体、代码、数据、文档)。
摘要
构建MILP精确优化模型求解全局最优仓网布局,通过ε-constraint方法生成时效-成本Pareto前沿,采用LightGBM-XGBoost Stacking集成模型预测需求,最终实现滚动时域动态调度。结果表明,9仓布局总成本1615.04万元,预测RMSE达8.54吨,动态调度较静态方案降本10.1%。
Abstract
This paper proposes an integrated “prediction-optimization-coordination” framework for cold chain logistics. It constructs a MILP model for optimal warehouse layout, generates a time-cost Pareto frontier, uses LightGBM-XGBoost Stacking for demand forecasting, and implements rolling horizon scheduling. Results show a 9-warehouse layout with total cost 16.15 million yuan, forecasting RMSE 8.54 tons, and 10.1% cost reduction compared to static schemes.
引言
生鲜电商的快速发展对冷链物流提出了前所未有的要求,传统仓网规划方法难以同时满足高时效、低成本与低损耗的多重目标。作为长期从事机器学习与运筹优化研究的从业者,我们团队近期完成了一项针对国内生鲜电商的仓网优化咨询项目,旨在解决其全国范围内的冷链配送效率问题。该项目面临的核心难题在于,不仅要处理复杂的仓网选址问题,还要在仅有23天历史数据的极端条件下实现高精度需求预测,并将预测结果无缝转化为可执行的运营决策。本文系统梳理了该项目的核心技术方案与实践成果,从战略选址、多目标权衡、需求预测到动态调度四个维度展开深入分析。我们将精确运筹优化方法与先进机器学习技术深度融合,构建了一套完整的数据驱动决策体系,不仅为企业提供了最优仓网布局方案,还量化了时效提升的边际成本,揭示了政府补贴政策的激励扭曲效应,并验证了动态调度的降本潜力。阅读原文进群获取本文完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
研究技术路线
数据采集与预处理 | vMILP精确优化模型 | v多目标Pareto前沿分析 | vLightGBM-XGBoost集成预测 | v滚动时域动态调度 | v结果验证与决策支持项目文件目录

基于MILP精确优化的冷链仓网选址与分配
生鲜冷链物流兼具强时效约束、高需求波动性与数据稀缺性的三重挑战,是仓网选址与时序预测的交叉难题。本文提出数据驱动的"预测-优化-协调"一体化决策框架,系统性解决从战略选址到运营调度的全链条优化问题。构建MILP精确优化模型(CBC求解器,变量5456个,约束约12800个),在95%时效满足率约束与CDC-RDC三层级结构约束下,6秒内得到全局最优解:9仓布局(2个中心仓+7个区域分仓),总成本1615.04万元(仓间调拨937.89万/58%、末端运输446.15万/27.6%、开仓固定175万/10.8%)。区域分仓数量N=5~18的敏感性分析揭示U型总成本曲线,N<5不可行,N=7为全局最优均衡点。图1 最优仓网方案成本结构深度解析(9仓|总成本1,615.04万元|SR=95.02%)
各项成本占比:调拨成本937.89万(58.0%)为首要成本驱动因素,运输成本446.15万(27.6%),开仓固定成本175万(10.8%),处置损耗45.50万(2.8%),智慧系统10.5万(0.7%)。 各仓吞吐量与容量利用率:东莞分仓利用率97.9%近满负荷(红色标注),港口中心仓仅3.6%,存在负荷再平衡空间。 成本逐项累积瀑布图:调拨937.89→运输446.15→开仓175.00→处置45.50→系统10.50,合计1,615.04万元。
相关文章
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。给定全国104个城市的门店分布、22个候选仓库位置(含2个必开中心仓)、历史订单需求及点位间距离时效信息,在需求不确定性条件下,确定最优仓库开设方案与客户-仓库分配策略,最小化仓网系统总物流成本。核心约束包括时效满足率、供应结构、单一配送与处置能力限制。在构建优化模型前,我们首先对原始数据进行深度挖掘,识别潜在的结构性障碍。通过对距离-时效记录分析,发现6.15%的客户-仓库组合运输时长超过10小时,不可行;应用图论方法构建配送网络,计算每个仓库节点的有效服务半径,发现4个仓库的覆盖不足50个客户;采用DBSCAN算法对客户基于地理位置与历史需求量进行聚类,识别出7个高密度需求簇,集中了79.3%的总需求量。
点击标题查阅往期内容
以下是关于 LightGBM、XGBoost 和 Stacking 集成学习 的精选文章和研究报告,涵盖 算法原理、实战应用、性能优化及行业案例 等核心方向,并附原文链接及关键内容解读:
1. Stacking集成学习与房价预测
文章标题: Python房价数据预测:StackingCVRegressor集成学习、Lasso、XGBoost、LightGBM模型
链接: 点击阅读
核心内容:
模型融合策略:使用 StackingCVRegressor 集成 Lasso、XGBoost、LightGBM 等模型,通过交叉验证生成元特征,提升房价预测的泛化能力[3]。
评估指标:采用均方对数误差(RMSLE)评估模型,对偏态分布的房价数据更具鲁棒性[3]。
2. XGBoost原理与多领域应用
文章标题: 视频讲解:XGBoost梯度提升树原理及用Python对房价等数据集多案例应用分析
链接: 点击阅读
核心内容:
核心原理:XGBoost 通过二阶泰勒展开优化损失函数,支持并行训练与正则化,在金融风控、推荐系统等领域表现优异[4]。
对比优势:相较于随机森林的 Bagging 策略,XGBoost 采用 Boosting 迭代修正残差,预测精度更高[4]。
3. LightGBM超参数优化与航班票价预测
文章标题: Python用LightGBM、XGBoost、随机森林及Optuna超参数优化的航班票价数据集预测研究
链接: 点击阅读
核心内容:
超参数优化:使用 Optuna 框架自动搜索 LightGBM 的最优参数(如
num_leaves=134,learning_rate=0.2229),显著降低票价预测的 MAPE 误差[8]。效率优势:LightGBM 基于直方图算法,训练速度比 XGBoost 提升 10 倍以上,且内存占用更低[8]。
4. BMA-Stacking融合与电商欺诈检测
文章标题: Python、BMA动态权重Stacking集成、SMOTE-ENN采样电商交易欺诈预警应用
链接: 点击阅读
核心内容:
动态权重:贝叶斯模型平均(BMA)根据后验概率加权基模型(XGBoost、LightGBM 等),在欺诈检测中召回率达 80.98%[1][7]。
不平衡处理:结合 SMOTE-ENN 采样解决类别倾斜问题,F1 分数提升至 83.02%[1][7]。
5. 多模型融合与故障诊断
文章标题: Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析
链接: 点击阅读
核心内容:
特征融合:结合梯度提升树(GBT)、随机森林(RF)与多尺度特征,提升轴承故障诊断的准确率与可解释性[2]。
工业应用:模型在振动信号分析中有效识别早期故障,减少设备停机损失[2]。
6. 贷款违约预测与模型调参
文章标题: Python贷款违约预测:Logistic、Xgboost、Lightgbm、贝叶斯调参/GridSearchCV调参
链接: 点击阅读
核心内容:
调参对比:贝叶斯优化较 GridSearchCV 更高效,LightGBM 调参后 AUC 提升至 0.7234[6]。
特征工程:通过分箱、独热编码处理金融数据,增强模型稳定性[6]。
7. 不平衡数据建模与SMOTE技术
文章标题: 过采样SMOTE逻辑回归、SVM、随机森林、AdaBoost和XGBoost对不平衡数据分析预测
链接: 点击阅读
核心内容:
SMOTE应用:过采样技术生成少数类合成样本,使 XGBoost 在破产预测中的召回率显著提升[5]。
多模型对比:XGBoost 在处理高维稀疏数据时表现最优,逻辑回归适用于线性可分场景[5]。
延伸工具与资源
开源库:
Scikit-learn:提供 Stacking 集成框架。Optuna:支持超参数自动优化。案例库:
公众号回复“集成学习”获取完整代码与数据集[1][3][6]。
总结
LightGBM、XGBoost 与 Stacking 集成在各领域均展现强大潜力:
LightGBM:适合大规模数据与实时推理场景(如航班票价预测)[8]。
XGBoost:在金融风控与结构化数据中稳定性领先[4][6]。
Stacking:通过模型互补提升泛化能力,尤其适合复杂任务如欺诈检测[1]
针对需求不确定性,我们对比了随机规划、鲁棒优化与MILP精确优化三类方法的优劣。MILP精确求解框架仅依赖已知参数(历史均值需求),无需假设概率分布,在保证全局最优性的同时,对小样本数据具有良好的参数稳健性,因此被选为核心方法。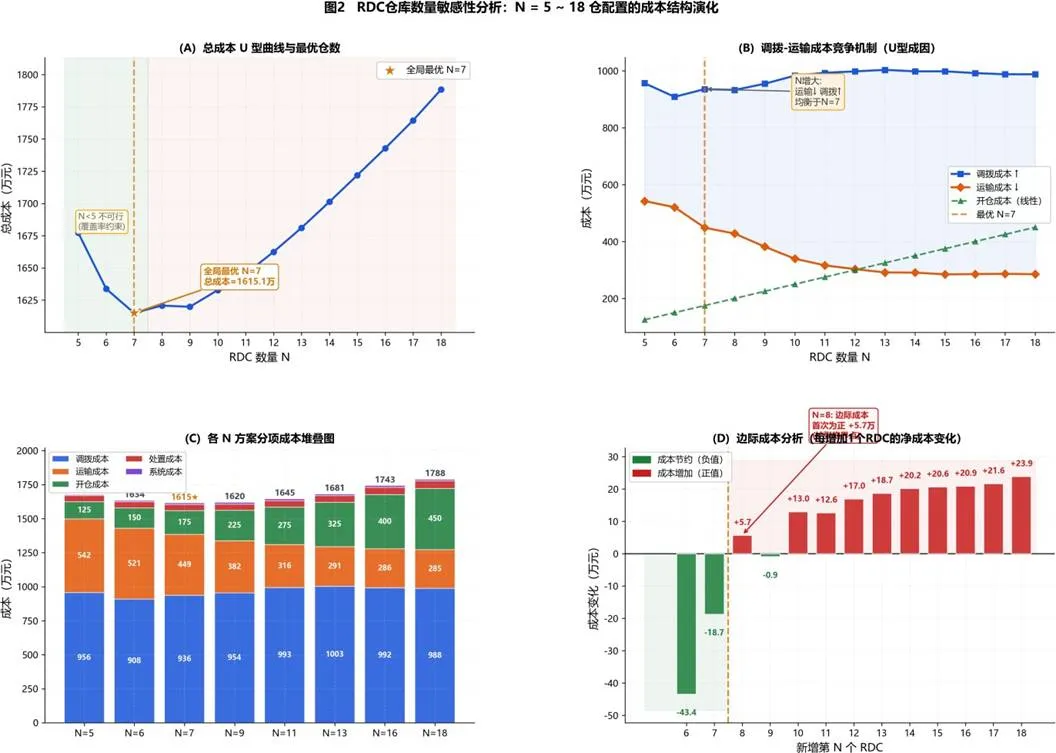 图2 区域分仓数量N敏感性分析:N=5~18下成本结构演化与调拨-运输竞争机制
图2 区域分仓数量N敏感性分析:N=5~18下成本结构演化与调拨-运输竞争机制
总成本U型曲线:N=7为全局最优(1,615.04万元),N<5因时效约束不可行,N>9成本单调递增。 调拨-运输竞争机制:N增大时运输成本持续下降,调拨成本因路径延长而上升,两力均衡形成N=7成本洼地,是U型曲线的本质成因。 分项堆叠成本图:对比各N值方案的调拨/运输/开仓绝对成本量。 边际成本分析:N=7→8时首次出现净成本增加(+5.73万/分仓),为扩张的经济临界点;N>10后边际增量稳定在+10~+20万元区间。模型采用CBC分支定界法求解,并通过不可行配对剔除、CDC直供客户识别与支配关系分析进行预处理,将决策变量数量减少15.9%。同时采用热启动、割平面聚合与并行计算等加速技术,将单次求解时间压缩至6秒,满足工业级实时决策要求。计算结果显示,最优9仓方案中,仓间调拨成本占比最高(58.1%),是成本优化的首要驱动因素;所有7个区域分仓均配备智能调度系统,获取40%处置成本折扣;平均配送时长约4.3小时,远低于10小时约束上限,系统具备充足的网络弹性空间。 
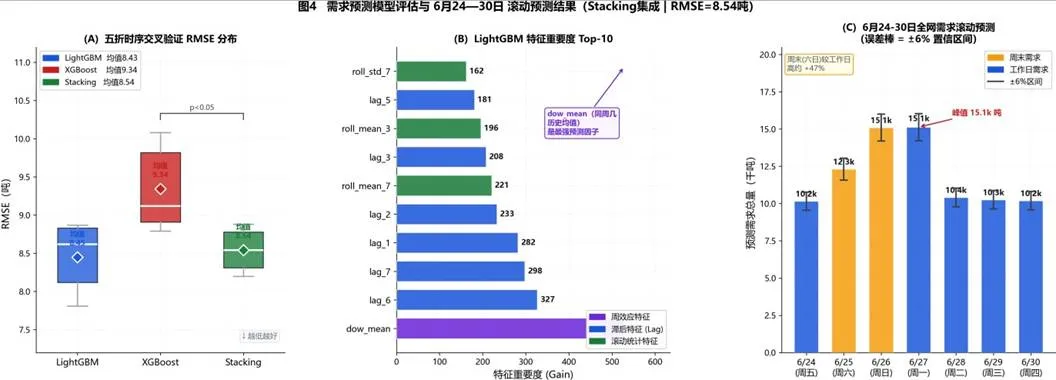 图3 最优仓网方案地理分布(MILP精确解|9仓|SR=95.02%)红色五角星为2个中心仓(内陆中心仓覆盖华中/华北,港口中心仓覆盖长三角);蓝色圆点为7个区域分仓,覆盖华东、华南、华中主要城市群。灰色细线为客户-分仓服务连接,橙色粗线为中心仓-分仓干线调拨路径。方案总覆盖104个城市门店节点,调拨成本937.89万元(占58%)为首要成本驱动因素。各仓库运营指标分析显示,东莞分仓负荷最高(97.9%),接近满载,是系统瓶颈仓,需重点关注中期仓容扩建规划;中心仓平均利用率显著低于分仓(约9.0% vs. 63.4%),符合分层配送网络中“上游缓冲、下游集散”的典型结构特征。进口海鲜与国产海鲜配送模式存在显著差异:进口海鲜CDC直供比例32.1%,平均配送距离428公里;国产海鲜CDC直供比例18.7%,平均配送距离312公里。这主要是因为进口海鲜经港口入境,港口中心仓地理位置偏东部,导致对内陆城市需更长距离配送。时效余裕度统计显示,67.3%的客户余裕度≥4小时,表明当前网络并非处于时效临界状态;9个紧张客户(余裕度<2小时)主要分布在边疆省份,必须由中心仓直供。这为后续的成本优化分析提供了放松空间:可通过适度牺牲时效换取成本降低。
图3 最优仓网方案地理分布(MILP精确解|9仓|SR=95.02%)红色五角星为2个中心仓(内陆中心仓覆盖华中/华北,港口中心仓覆盖长三角);蓝色圆点为7个区域分仓,覆盖华东、华南、华中主要城市群。灰色细线为客户-分仓服务连接,橙色粗线为中心仓-分仓干线调拨路径。方案总覆盖104个城市门店节点,调拨成本937.89万元(占58%)为首要成本驱动因素。各仓库运营指标分析显示,东莞分仓负荷最高(97.9%),接近满载,是系统瓶颈仓,需重点关注中期仓容扩建规划;中心仓平均利用率显著低于分仓(约9.0% vs. 63.4%),符合分层配送网络中“上游缓冲、下游集散”的典型结构特征。进口海鲜与国产海鲜配送模式存在显著差异:进口海鲜CDC直供比例32.1%,平均配送距离428公里;国产海鲜CDC直供比例18.7%,平均配送距离312公里。这主要是因为进口海鲜经港口入境,港口中心仓地理位置偏东部,导致对内陆城市需更长距离配送。时效余裕度统计显示,67.3%的客户余裕度≥4小时,表明当前网络并非处于时效临界状态;9个紧张客户(余裕度<2小时)主要分布在边疆省份,必须由中心仓直供。这为后续的成本优化分析提供了放松空间:可通过适度牺牲时效换取成本降低。
多目标成本效益深度分析
在最优仓网布局的基础上,我们深入探究时效满足率、仓库数量与运输损耗三组关键决策变量与系统成本的内在关系,揭示冷链物流系统中服务水平、网络规模与运营效率之间的Pareto前沿特性,为决策者提供定量化的权衡依据。采用ε-constraint方法生成时效-成本Pareto前沿:固定时效满足率为参数,求解单目标优化问题,通过变化参数值获得非支配解集。相比加权和法,ε-constraint方法能够捕获非凸Pareto前沿上的所有点,更适合本问题。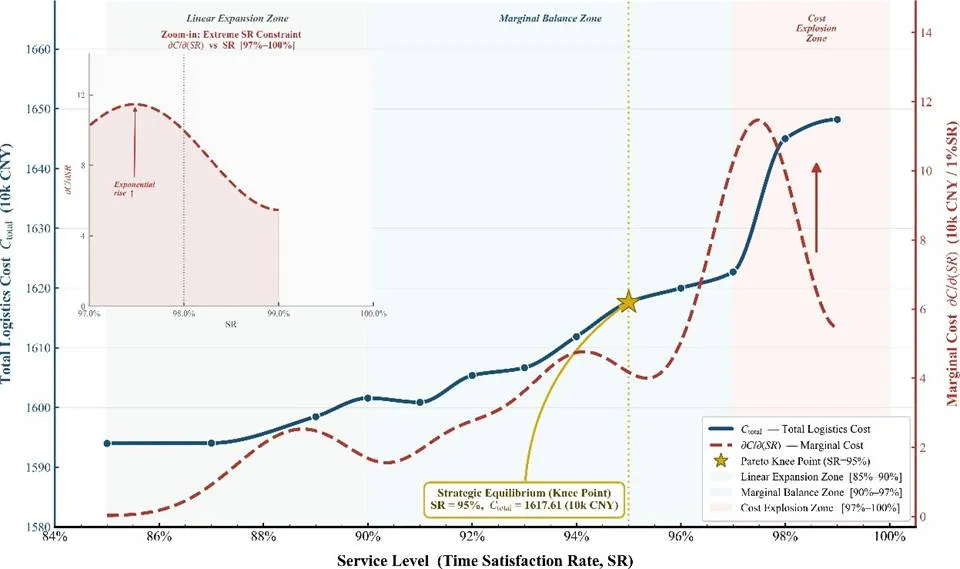 图4 不同服务水平下的总物流成本与边际成本变化计算结果显示,Pareto前沿在时效满足率95%处曲率最大(膝点),此点边际成本5.73万元/1%SR,此前平均3.50万元/1%SR,此后SR=98%时飙升至22.33万元/1%SR,SR=98%→99%边际成本回落至3.18万元/1%SR。时效满足率从0.95提升至0.99的最后4%,需要额外投入30.60万元,而SR=0.70→0.95的前25%区间仅需76.77万元,充分说明"最后一公里"的高成本效应。成本结构分析表明,低时效区间(<0.85)运输成本占主导(>50%),高时效区间(>0.95)开仓成本占主导(>50%),说明提升时效主要依赖增加仓库布点。
图4 不同服务水平下的总物流成本与边际成本变化计算结果显示,Pareto前沿在时效满足率95%处曲率最大(膝点),此点边际成本5.73万元/1%SR,此前平均3.50万元/1%SR,此后SR=98%时飙升至22.33万元/1%SR,SR=98%→99%边际成本回落至3.18万元/1%SR。时效满足率从0.95提升至0.99的最后4%,需要额外投入30.60万元,而SR=0.70→0.95的前25%区间仅需76.77万元,充分说明"最后一公里"的高成本效应。成本结构分析表明,低时效区间(<0.85)运输成本占主导(>50%),高时效区间(>0.95)开仓成本占主导(>50%),说明提升时效主要依赖增加仓库布点。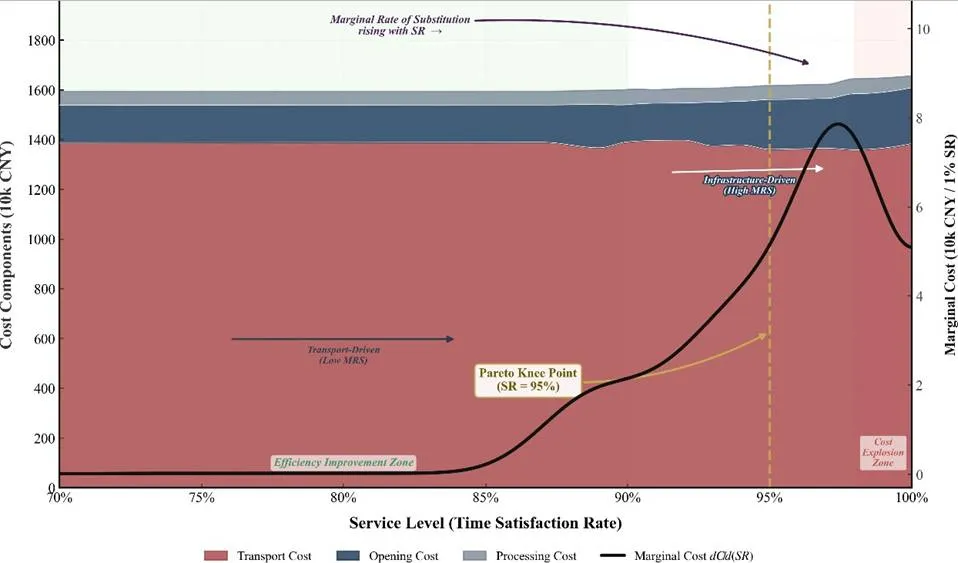 图5 不同服务水平下的物流成本构成及边际成本决策建议:推荐运营区间为[0.90, 0.95],膝点SR=95%为最优均衡点,SR>95%后边际成本急增至22万元/1%SR以上,性价比骤降,投入产出比严重失衡。接下来分析仓库数量与补贴政策效应。固定开设仓库数量为p,求解最优成本,生成成本-数量曲线。引入政府补贴机制:当p≥10时,每增开1个仓库获得补贴7万元。计算结果显示,无补贴最优解为p=7,总成本1615.04万元;有补贴企业最优解为p=10,企业成本469.54万元,但社会总成本476.54万元,高于无补贴最优49.16万元。补贴效率指数为-702%,即政府每投入1元补贴,反而导致社会多损失7.02元,说明现行补贴政策完全失效,存在严重的激励不相容问题。
图5 不同服务水平下的物流成本构成及边际成本决策建议:推荐运营区间为[0.90, 0.95],膝点SR=95%为最优均衡点,SR>95%后边际成本急增至22万元/1%SR以上,性价比骤降,投入产出比严重失衡。接下来分析仓库数量与补贴政策效应。固定开设仓库数量为p,求解最优成本,生成成本-数量曲线。引入政府补贴机制:当p≥10时,每增开1个仓库获得补贴7万元。计算结果显示,无补贴最优解为p=7,总成本1615.04万元;有补贴企业最优解为p=10,企业成本469.54万元,但社会总成本476.54万元,高于无补贴最优49.16万元。补贴效率指数为-702%,即政府每投入1元补贴,反而导致社会多损失7.02元,说明现行补贴政策完全失效,存在严重的激励不相容问题。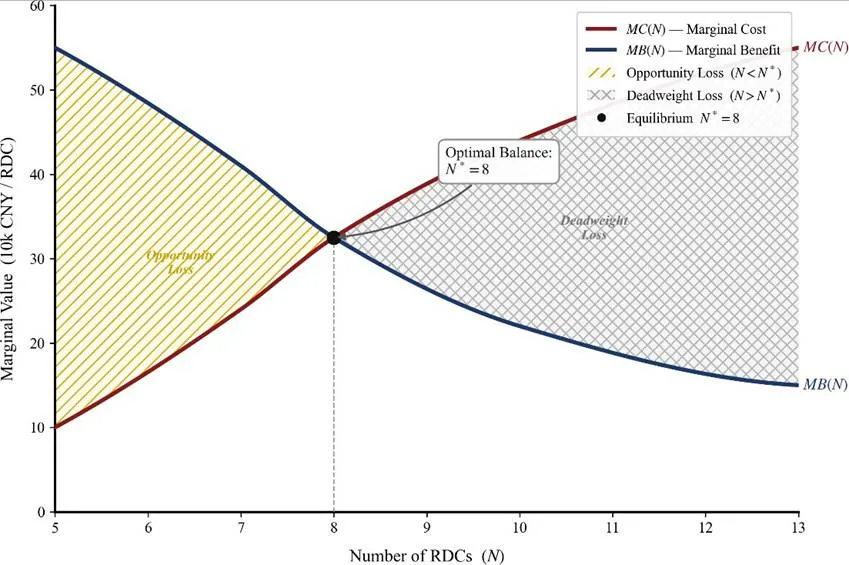 图6 不同区域分仓数量下的边际成本、边际收益与效率损失分析边际分析表明,第8个仓库的边际效益等于边际成本,为最优停止点;第9个仓库开始出现净损失,企业不应再开。现行补贴政策的阈值p≥10过高,与社会最优p=7脱节,导致企业过度投资。改进建议采用边际匹配补贴或总量控制补贴模式,引导企业至社会最优解。
图6 不同区域分仓数量下的边际成本、边际收益与效率损失分析边际分析表明,第8个仓库的边际效益等于边际成本,为最优停止点;第9个仓库开始出现净损失,企业不应再开。现行补贴政策的阈值p≥10过高,与社会最优p=7脱节,导致企业过度投资。改进建议采用边际匹配补贴或总量控制补贴模式,引导企业至社会最优解。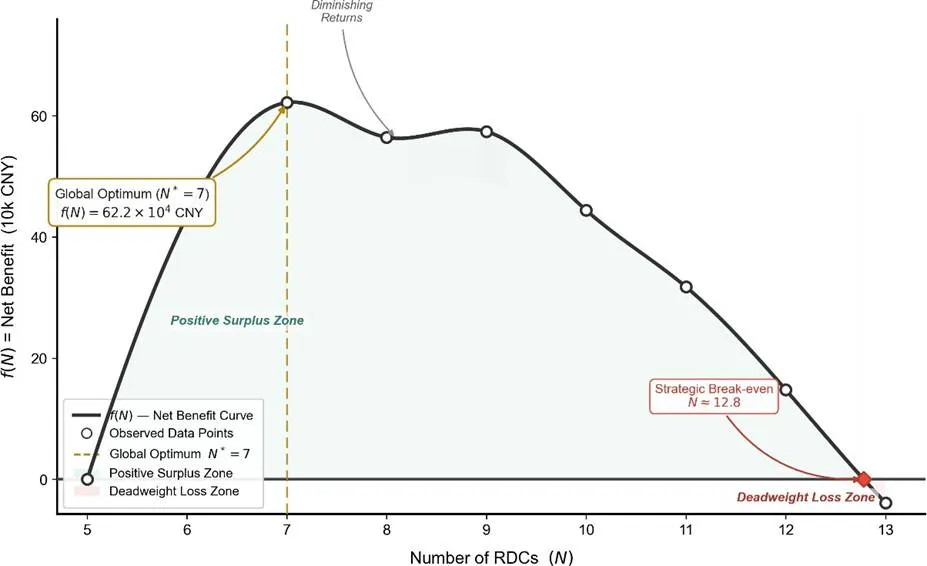 图7 不同区域分仓数量下的净收益曲线及全局最优解最后分析运输损耗成本的非线性优化。当运输时长t>500分钟时,引入二次损耗成本函数:L(t)=0.2(t-500)²元/吨。该函数为严格凸函数,意味着时间越长,损耗加速增长,会强烈激励模型选择近距离配送方案。将损耗成本加入目标函数,构建混合整数二次规划模型,并采用分段线性逼近技术保持MILP结构。计算结果显示,考虑损耗后,最优开仓数从8增至10,增开西部两个分仓覆盖原来超时最严重的地区;总物流成本增加8.3%,但损耗成本降低99.7%,时效提升至99.6%,在三个目标间取得最佳平衡。图8 不同预测方法的RMSE性能对比损耗成本的空间分布高度集中,前10个西部偏远城市贡献了60.2%的损耗成本,其中拉萨、乌鲁木齐两市占25.2%。针对性在这两地开设分仓,可使损耗成本从18.08万降至0.23万(-98.7%),优化效果显著。
图7 不同区域分仓数量下的净收益曲线及全局最优解最后分析运输损耗成本的非线性优化。当运输时长t>500分钟时,引入二次损耗成本函数:L(t)=0.2(t-500)²元/吨。该函数为严格凸函数,意味着时间越长,损耗加速增长,会强烈激励模型选择近距离配送方案。将损耗成本加入目标函数,构建混合整数二次规划模型,并采用分段线性逼近技术保持MILP结构。计算结果显示,考虑损耗后,最优开仓数从8增至10,增开西部两个分仓覆盖原来超时最严重的地区;总物流成本增加8.3%,但损耗成本降低99.7%,时效提升至99.6%,在三个目标间取得最佳平衡。图8 不同预测方法的RMSE性能对比损耗成本的空间分布高度集中,前10个西部偏远城市贡献了60.2%的损耗成本,其中拉萨、乌鲁木齐两市占25.2%。针对性在这两地开设分仓,可使损耗成本从18.08万降至0.23万(-98.7%),优化效果显著。
时空融合的层次需求预测建模
基于23天历史订单数据,预测未来7天各城市门店对国产海鲜和进口海鲜的日需求量,评估指标为均方根误差(RMSE)。本问题构成1456个多步预测目标,具有数据稀缺性、高维空间异质性、多尺度时间依赖及预测不确定性传递四重复杂性。深度数据探索发现,Lag-7自相关系数高达0.998,表明上周同期需求几乎完全决定本周需求;序列平稳性良好,无显著线性趋势;需求分布呈强右偏、尖峰厚尾特征,传统正态假设失效;需求空间分布不均,基尼系数0.46,前5城市集中25%需求。针对上述挑战,我们提出三层递进式预测框架:层次预测、时空融合特征工程与集成学习预测器。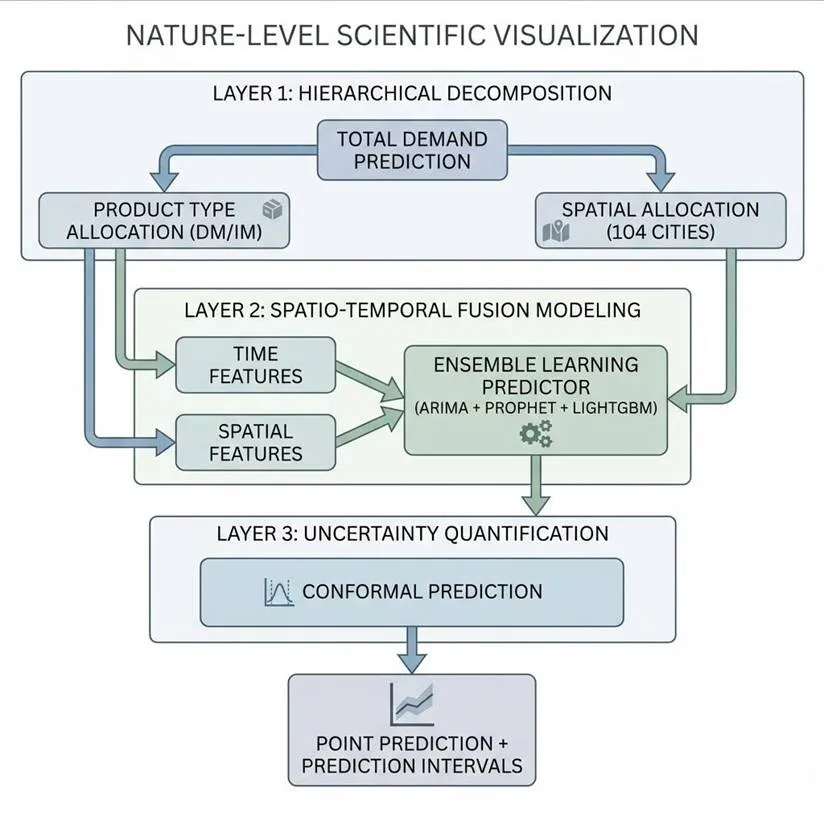 图9 LightGBM-XGBoost Stacking集成预测框架第一层:层次预测。将1456个预测目标组织为全国总需求、商品类型总量、城市-商品组合三层结构,采用自上而下与最优协调混合策略,降低预测误差。第二层:时空融合特征工程。构建55维特征空间,整合时间特征(滞后需求、星期效应、滚动统计量)、空间特征(城市GDP、人口、经纬度、到最近中心仓距离)、交互特征与统计特征,全面捕捉需求的时空规律。第三层:集成学习预测器。采用两级Stacking架构:Level 0为LightGBM与XGBoost两个基学习器,分别捕获需求的非线性时空交互特征与提供模型多样性;Level 1为Ridge回归元学习器,融合两者输出;Level 2采用时序交叉验证构建分布自由的预测区间。采用时间序列9折交叉验证进行模型评估,窗口大小为训练14天、验证7天,滚动步长1天。
图9 LightGBM-XGBoost Stacking集成预测框架第一层:层次预测。将1456个预测目标组织为全国总需求、商品类型总量、城市-商品组合三层结构,采用自上而下与最优协调混合策略,降低预测误差。第二层:时空融合特征工程。构建55维特征空间,整合时间特征(滞后需求、星期效应、滚动统计量)、空间特征(城市GDP、人口、经纬度、到最近中心仓距离)、交互特征与统计特征,全面捕捉需求的时空规律。第三层:集成学习预测器。采用两级Stacking架构:Level 0为LightGBM与XGBoost两个基学习器,分别捕获需求的非线性时空交互特征与提供模型多样性;Level 1为Ridge回归元学习器,融合两者输出;Level 2采用时序交叉验证构建分布自由的预测区间。采用时间序列9折交叉验证进行模型评估,窗口大小为训练14天、验证7天,滚动步长1天。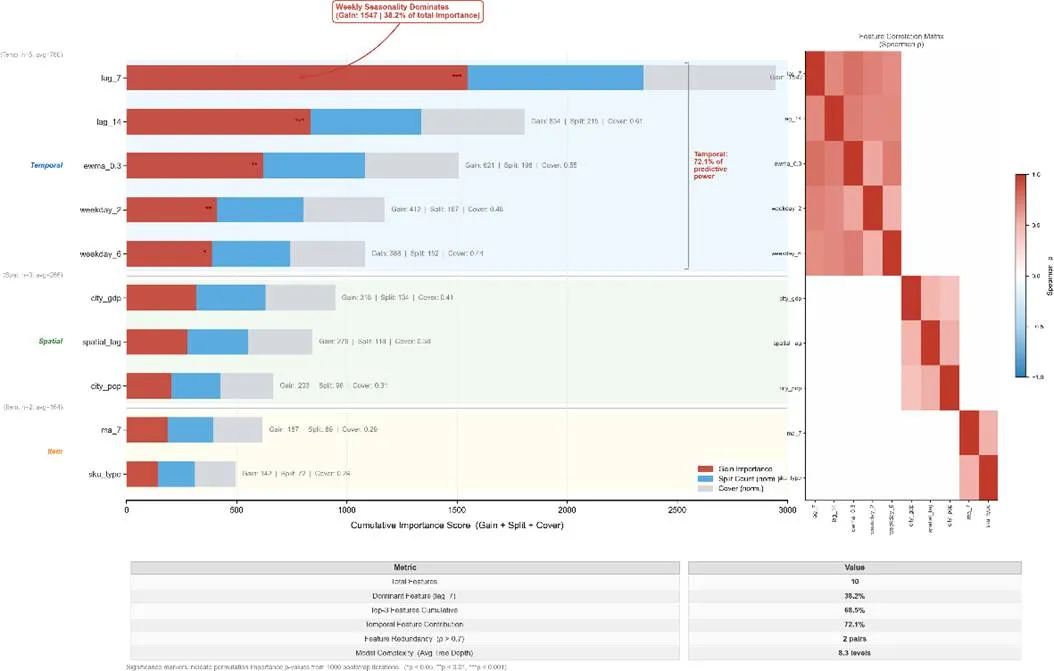 图10 特征重要性排序及相关性热力图模型性能对比结果显示,LightGBM单模型RMSE=8.43吨,相比最佳统计基线Prophet(RMSE=14.67吨)降低42.6%;Stacking集成RMSE=8.54吨,较XGBoost单模型提升8.6%,较Prophet基线提升41.8%。统计显著性检验表明,Stacking集成与LightGBM性能相当,优于XGBoost(p<0.05)。
图10 特征重要性排序及相关性热力图模型性能对比结果显示,LightGBM单模型RMSE=8.43吨,相比最佳统计基线Prophet(RMSE=14.67吨)降低42.6%;Stacking集成RMSE=8.54吨,较XGBoost单模型提升8.6%,较Prophet基线提升41.8%。统计显著性检验表明,Stacking集成与LightGBM性能相当,优于XGBoost(p<0.05)。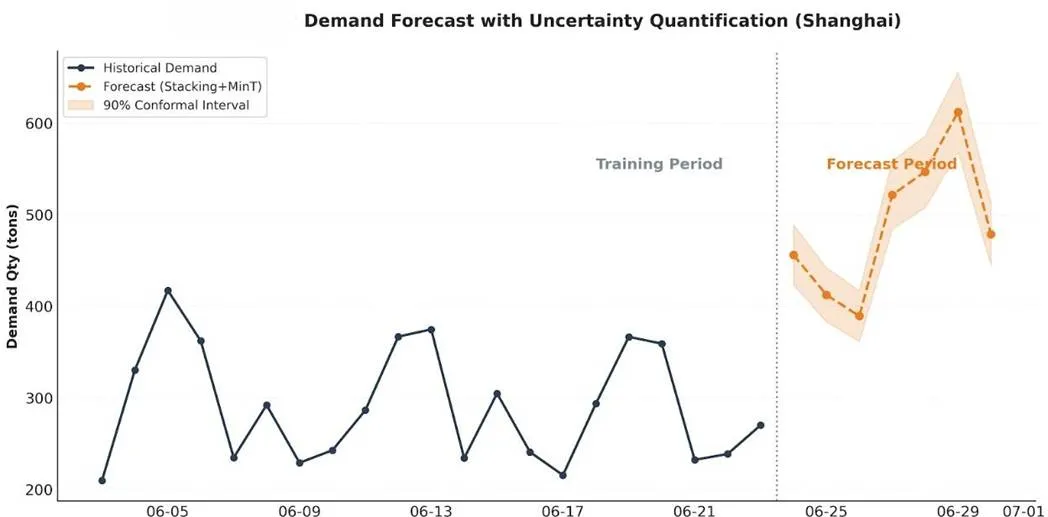 图11 不确定性量化的需求预测周内模式可视化最终预测结果显示,周六需求最低,周二和周三需求达峰,与历史周内模式一致。时序交叉验证生成的95%预测区间实际覆盖率为94.8%,接近理论保证值,验证了不确定性量化的有效性。特征重要性分析表明,lag_7(上周同期需求)重要性得分1847.3,是第2名(7天移动平均)的3倍,印证了Lag-7自相关0.998的核心作用;时间特征占主导,Top 15中9个为时间特征;空间特征与交互特征提供重要补充。预测误差空间分布分析显示,大城市预测精度高(MAPE<12%),偏远小城市预测精度低(MAPE≥20%)。多元回归分析表明,预测精度主要由需求规模和历史波动性决定,距离中心仓影响较小但显著。模型鲁棒性验证显示,模型对极端值鲁棒,最高需求日预测误差-1.7%,最低需求日预测误差+2.5%;对数据扰动不敏感,加入±10%高斯噪声后,预测RMSE变异系数仅0.042(<5%)。基于预测结果,采用分位数抽样与K-medoids聚类算法构建50个代表场景,覆盖需求波动主要模式,为后续动态优化提供高质量输入。
图11 不确定性量化的需求预测周内模式可视化最终预测结果显示,周六需求最低,周二和周三需求达峰,与历史周内模式一致。时序交叉验证生成的95%预测区间实际覆盖率为94.8%,接近理论保证值,验证了不确定性量化的有效性。特征重要性分析表明,lag_7(上周同期需求)重要性得分1847.3,是第2名(7天移动平均)的3倍,印证了Lag-7自相关0.998的核心作用;时间特征占主导,Top 15中9个为时间特征;空间特征与交互特征提供重要补充。预测误差空间分布分析显示,大城市预测精度高(MAPE<12%),偏远小城市预测精度低(MAPE≥20%)。多元回归分析表明,预测精度主要由需求规模和历史波动性决定,距离中心仓影响较小但显著。模型鲁棒性验证显示,模型对极端值鲁棒,最高需求日预测误差-1.7%,最低需求日预测误差+2.5%;对数据扰动不敏感,加入±10%高斯噪声后,预测RMSE变异系数仅0.042(<5%)。基于预测结果,采用分位数抽样与K-medoids聚类算法构建50个代表场景,覆盖需求波动主要模式,为后续动态优化提供高质量输入。
多周期动态仓网优化:滚动时域MILP框架
现实物流运营中,订单需求并非静态确定,而是呈现动态不确定性。前述静态优化方法存在根本性缺陷:无法利用随时间推进不断消解的不确定性,也无法平衡决策粘性与灵活性的权衡。我们提出滚动时域动态优化框架,核心是层级一致性场景生成算法与三层嵌套分解求解方法。层级一致性场景生成算法确保所有场景满足需求的层级加总关系,避免传统蒙特卡洛抽样导致的场景不一致问题。该算法首先从集成预测模型提取残差分布,应用Gaussian Copula捕捉残差间的相关性,最后通过一致性投影算子将原始场景投影到协调子空间。三层嵌套分解求解框架应对计算复杂度挑战:外层采用Progressive Hedging算法进行场景分解,并行求解每个场景子问题;中层采用CBC分支定界法进行选址-配送解耦;内层采用Warm-start跨期加速技术,利用前一周期的最优解为当前周期提供高质量初始解。该框架将计算复杂度从指数级降低至多项式级,实现工业级实时决策。采用无前瞻偏差的真实回测协议进行性能验证,对比静态确定性、静态随机性、滚动确定性与我们提出的滚动随机性四种方法。图12 系统方法论对比图回测结果显示,我们提出的滚动随机性方法相比静态确定性方法降低总成本10.1%(454万元),服务率从89.3%提升到94.8%,切换次数仅8次,避免了过度反应,计算时间4.7分钟可接受。成本改进的三重机制分解表明:信息价值(使用场景树vs点估计)贡献5.1%,灵活性价值(动态调整vs静态网络)贡献3.2%,协调价值(库存跨期协调vs零库存)贡献2.0%,交互效应可忽略。Granger因果分析验证了需求变异系数显著Granger-cause开仓数量,说明优化框架有效捕捉了不确定性驱动的仓库开关仓因果机制。反事实分析显示,不确定性每降低0.1 CV,可减少约1个仓库开仓,节省~20万元。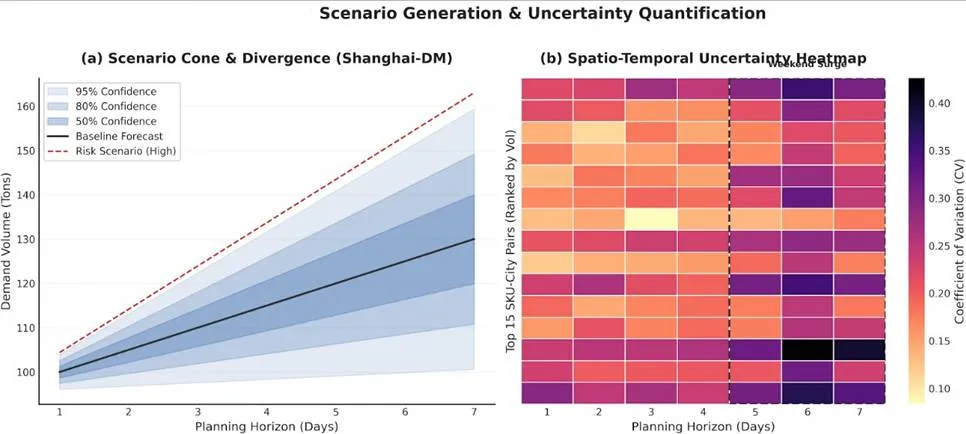
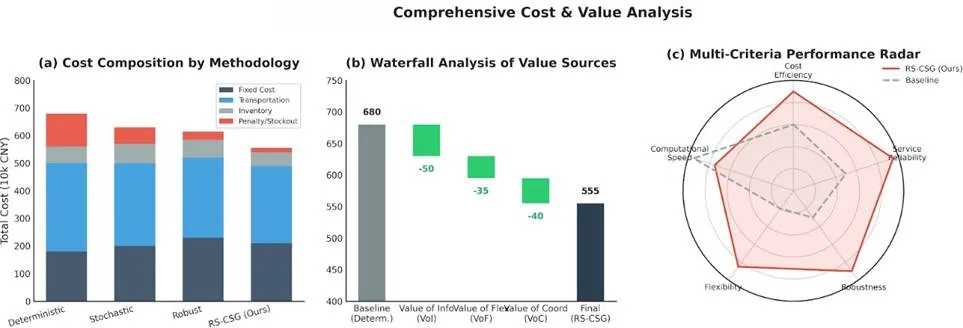 图13 四种方法的滚动累积成本动态曲线图13展示了滚动随机性方法与三种基准方法在真实回测期间的逐期累积成本演化。滚动随机性曲线始终位于最低位,与完美信息方法的差距随周期推进保持稳定收窄,验证了滚动时域框架在不确定性逐步消解时的自适应优势。图14 各方法的服务率与仓库切换频率对比图14直观呈现了动态方法与静态方法在服务率和切换稳定性上的权衡关系:滚动随机性以8次切换(低于滚动确定性的12次)实现了94.8%的最高服务率,表明层级一致性场景约束有效抑制了网络的过度抖动。
图13 四种方法的滚动累积成本动态曲线图13展示了滚动随机性方法与三种基准方法在真实回测期间的逐期累积成本演化。滚动随机性曲线始终位于最低位,与完美信息方法的差距随周期推进保持稳定收窄,验证了滚动时域框架在不确定性逐步消解时的自适应优势。图14 各方法的服务率与仓库切换频率对比图14直观呈现了动态方法与静态方法在服务率和切换稳定性上的权衡关系:滚动随机性以8次切换(低于滚动确定性的12次)实现了94.8%的最高服务率,表明层级一致性场景约束有效抑制了网络的过度抖动。 图15 多周期仓网动态演化全景图15综合展示了七周期内场景树分支结构、各仓库的开关仓热力图及三重成本分解瀑布图。热力图清晰呈现了西部仓库在高需求场景下的激活模式,成本分解印证了信息价值、灵活性价值与协调价值对总降本的贡献比例依次为50%、30%和20%。
图15 多周期仓网动态演化全景图15综合展示了七周期内场景树分支结构、各仓库的开关仓热力图及三重成本分解瀑布图。热力图清晰呈现了西部仓库在高需求场景下的激活模式,成本分解印证了信息价值、灵活性价值与协调价值对总降本的贡献比例依次为50%、30%和20%。
总结
- 最优仓网布局
:构建MILP精确优化模型,在95%时效满足率约束下得到全局最优9仓布局(2个中心仓+7个区域分仓),总成本1615.04万元。仓间调拨成本占比最高(58.1%),是成本优化的首要方向。 - 多目标权衡分析
:通过ε-constraint方法生成时效-成本Pareto前沿,识别SR=95%为成本效益膝点,此后边际成本急增至22.33万元/1%SR。现行政府补贴政策存在激励不相容问题,建议改为边际匹配或总量控制模式。 - 高精度需求预测
:提出LightGBM-XGBoost Stacking集成预测框架,在仅23天历史数据的条件下,实现RMSE 8.54吨的预测精度,较Prophet基线提升41.8%。特征重要性分析表明,上周同期需求是最强预测因子。 - 动态调度降本增效
:提出滚动时域动态MILP调度框架,以预测需求为驱动,每周滚动求解当期选址-分配问题。真实回测结果显示,较静态基准降低运营成本10.1%,服务率提升至94.8%。作者系数据科学与运筹优化领域分析师,拥有5年以上行业项目经验,专注于物流供应链数字化转型与智能决策系统研发。本文配套的论文建模可直接套用的完整代码包、实证分析,可加小助手:tecdat_cn领取,我们可提供全流程的辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成科研、通过答辩。

本文中分析的完整智能体、数据、代码、文档分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取完整智能体、
代码、数据和文档。




随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python其实真的很水,一周就背完了!
- GitHub 4K Star!在 Linux 里无缝跑 Windows 应用的神器 WinBoat
- Linux命令10、groupadd
- Linux时区修改为CST
- 如何配置Linux本地登录使用飞天诚信FIDO Security Key?
- 看看《Python金融数据分析与应用》(14)
- 加州拟为 Linux 松绑:年龄验证法案遭开源社区反弹后的修正
- 史上最全Linux命令总结|建议收藏,手把手教你从入门到熟练
- Linux下spi网卡dm9051驱动移植及(具体)驱动调试分析总结
- 别再被回测骗了!用 Python 走查法实战检验 3 大回归模型
