很多人第一次查实时系统抖动,
最容易先怀疑业务线程:
是不是优先级不够高?是不是代码太重?
有时候确实是。
但现场里还有一类特别常见、又特别容易被低估的干扰源:
网卡。
更准确地说,
不只是网卡设备本身,
而是它背后的整条处理路径:
网卡中断
中断风暴
NAPI 收包
softirq 后续处理
协议栈收发路径
这些东西一旦压上来,
拖慢的往往不是“网络吞吐”本身,
而是你的实时线程。
所以很多现场现象看起来像业务线程不稳,
根子其实是:
网络路径把 CPU 时间切碎了。
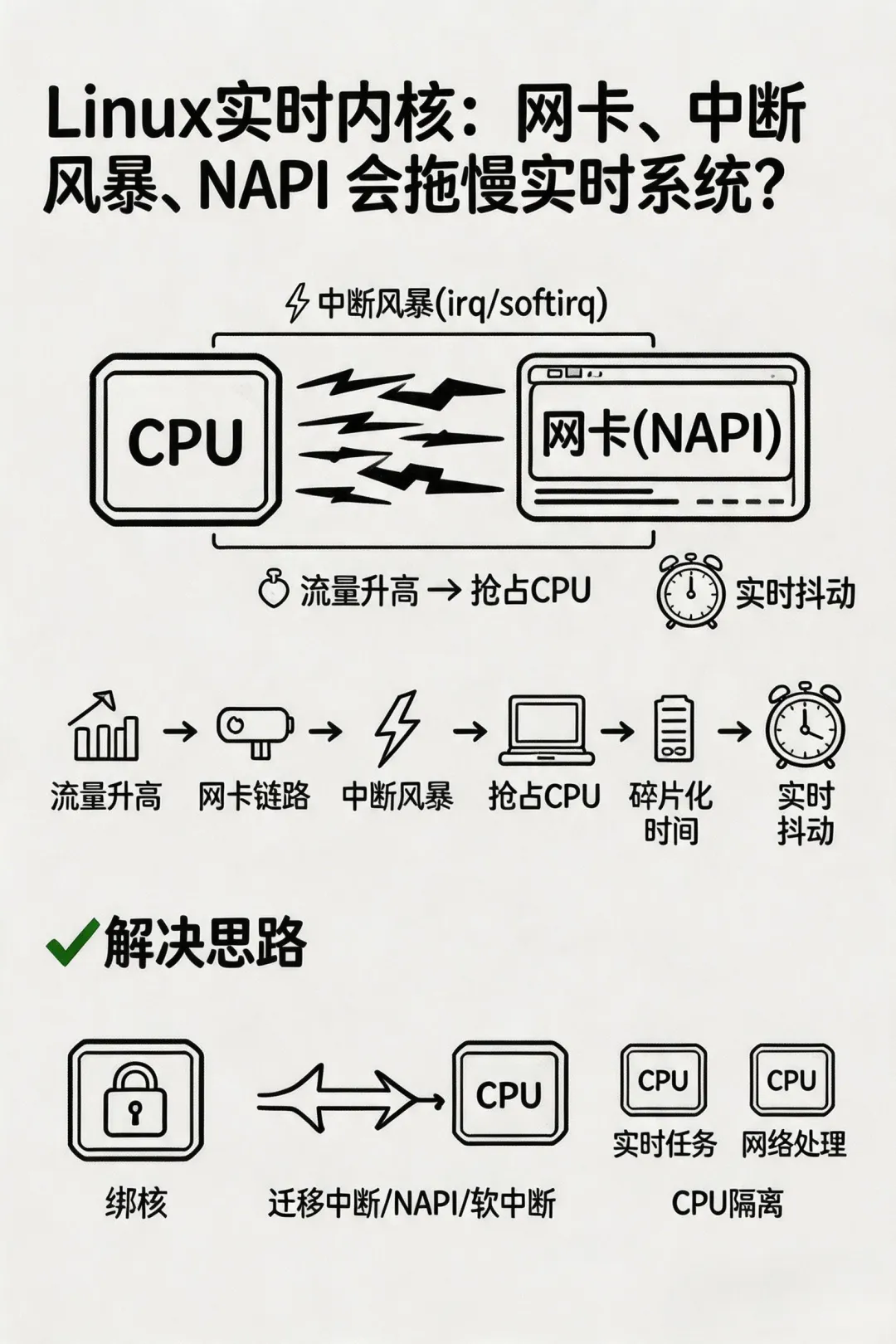
一句话先讲明白
网卡、中断风暴、NAPI 会把实时系统拖慢,不是因为“网络很忙”这句话本身,而是因为它们会制造大量异步前置处理,抢 CPU、打断关键线程、拉长调度延迟,并把本来稳定的实时路径拖成抖动路径。
第一,为什么网卡特别容易影响实时性?
因为网卡不是一个“安静地在后台搬数据”的设备。
它一忙起来,
通常会连带触发整条处理链:
硬中断
中断线程
NAPI poll
NET_RX_SOFTIRQ 等软中断后续处理
协议栈收发
驱动回调
这意味着,
系统面对的就不再只是“网络包变多了”,
而是:
CPU 上多了一批持续插队的前置工作。
而实时线程最怕的,
恰恰就是前面不断有人插队。
第二,什么是中断风暴?为什么它危险?
中断风暴可以先简单理解成:
某类设备中断来得过于频繁,导致 CPU 大量时间都花在处理中断。
放到网卡场景里,
常见触发条件包括:
高频收包
小包洪泛
广播、组播过多
某类异常流量
中断合并参数不合适
驱动配置不合适
它危险的地方不只是 CPU 忙,
而是关键线程会被反复打断。
这会直接表现成:
周期线程晚醒
调度延迟变大
cyclictest 尖峰升高
控制线程偶发超期
EtherCAT 或其他周期任务开始抖
所以中断风暴的问题,
不是“带宽不够”。
而是:
CPU 被中断切碎了。
第三,为什么中断一多,实时线程就容易不稳?
因为实时线程要稳定运行,
至少要满足两件事:
而中断风暴会同时伤这两件事。
1. 它会拉长前置处理时间
线程本来该醒了,
但 CPU 还在忙中断路径。
2. 它会打乱调度节奏
线程即使醒了,
也可能先让位给更靠前的中断处理。
特别要注意一层:
网络路径里最难缠的,很多时候不是业务线程,而是 NET_RX_SOFTIRQ 这类软中断后续处理。
因为它会继续消耗 CPU,
把收包这条链往后拖长。
所以网卡一忙,
你表面上看到的是线程慢了。
但真正的根因往往是:
线程前面插进来了太多网络相关工作。
第四,NAPI 明明是优化,为什么也会影响实时性?
是优化。
但它优化的是:
降低中断频率,提高收包效率。
它不是专门为实时线程设计的。
NAPI 的核心思路是:
先用中断通知,再切到轮询批量处理。
这样做的好处很明显:
但从实时角度要多看一层:
中断少了,不代表干扰没了。
因为原来分散的中断工作,
会有一部分变成:
NAPI poll 里的成批处理
poll 之后的 softirq 后续处理
结果就是:
中断频率下降了
但单次 poll 可能更重了
softirq 持续时间也可能更长
如果这些路径和关键线程共核,实时线程照样会被拖
所以 NAPI 不是“没有问题”。
它只是把问题从“频繁打断”部分,
转成了“成批占用”部分。
第五,NAPI 在什么情况下会特别伤实时性?
最典型的是下面几类场景。
1. 高频收包场景
比如系统持续收到大量小包、状态包、广播包。
这时候 NAPI poll 会很活跃。
2. NAPI 和关键线程共核
这是最常见的问题。
实时线程自己不重,
但和收包处理跑在同一个 CPU 上。
3. 系统同时跑多种网络业务
比如你一边做控制,
一边还有:
这时候网络路径更复杂,
实时线程更容易被波及。
4. 没有做 IRQ 绑核和任务绑核
如果线程、中断、NAPI、softirq 后续处理都混在一起,
抖动通常最明显。
第六,PREEMPT_RT 下为什么还要特别注意 irqthread?
很多人以为上了 PREEMPT_RT,
中断线程化了,
实时性就自然好了。
这不完整。
在 PREEMPT_RT 里,
大量硬中断会被线程化成 irqthread。
这当然提升了可抢占性。
但也带来一个新问题:
如果网卡 irqthread 的优先级很高,或者它和关键线程共核,它照样会压你的实时线程。
也就是说,
你不能只看“有没有线程化”。
还要看:
irqthread 跑在哪个 CPU
irqthread 优先级是多少
它和你的关键业务线程谁更靠前
所以有些系统明明绑核了还是抖,
问题不是绑核没做,
而是:
网卡中断线程本身就还在关键核上抢时间。
第七,现场最常见的表现是什么?
如果问题和网卡、中断风暴、NAPI 有关,
现场通常会出现这些现象:
这些现象有个共同点:
业务逻辑没变,网络活动一上来,时序就坏。
第八,怎么判断是“网卡路径在拖你”,而不是业务线程自己太重?
最实用的判断看四件事。
1. 看问题是否和网络负载强相关
如果网络一忙就差,
网络一停就稳,
方向已经很明确了。
2. 看 /proc/interrupts
重点看:
哪些网卡 IRQ 涨得快
它们打在哪个 CPU 上
关键 CPU 上是不是堆了很多网卡中断
3. 看关键线程是不是和网卡路径共核
如果实时线程绑在 CPU2,
而网卡 IRQ、irqthread、NAPI 主要也压在 CPU2,
那就非常值得优先怀疑这里。
4. 看 ksoftirqd 和网卡相关线程是否活跃
如果网络一压上来,
对应 CPU 上的软中断处理明显活跃,
那就说明网络后续路径确实在吃你的时间。
一句话说:
如果系统时序坏掉总是跟着网络活动走,先查网卡路径。
第九,工程上最有效的规避办法是什么?
把网络干扰和关键实时路径隔开。
优先做这几件事:
1. 把关键实时线程绑到专用 CPU
让它别和普通任务混跑。
2. 把网卡 IRQ 迁出关键 CPU
这是最直接的动作。
别让高频网卡中断打到关键核上。
3. 把 irqthread、NAPI、softirq 后续处理一起迁走
只绑业务线程不够。
很多时候中断和收包后续路径也得一起迁走。
4. 关掉不必要的网络服务和无关流量
实时系统最怕“看起来没啥,但一直在后台响”的东西。
5. 配合 CPU 隔离一起看
单纯 taskset 绑核,
很多时候还不够彻底。
如果场景要求高,
要考虑 isolcpus 这类 CPU 隔离手段,
把关键核尽量从普通调度活动里挖出来。
也就是说,
不要只是“把线程放过去”,
而是要尽量做到:
把关键核真的清出来。
第十,为什么很多人“线程绑核了”还是没效果?
因为 CPU 上不只有线程。
还有:
硬中断
中断线程
NAPI poll
softirq 后续处理
内核后台活动
如果你只是把实时线程绑到了 CPU2,
但网卡最活跃的那套路径也还在 CPU2,
那你只是把关键线程固定到了一个吵闹的房间里。
所以很多人会出现这种错觉:
明明绑核了,
为什么还是抖?
答案往往是:
你只绑了人,没清场。
第十一,工程上最该怎么理解这个问题?
最稳的理解方式不是:
网卡会占带宽,所以系统慢。
更准确的理解是:
网卡路径会制造大量异步前置工作,而实时线程最怕的,就是前面不断有人插队。
这些插队者包括:
高频中断
irqthread
NAPI poll
NET_RX_SOFTIRQ 后续处理
所以网卡、中断风暴、NAPI 影响实时性的本质,
不是“数据多”。
而是:
它们把 CPU 时间切碎了,把调度节奏打乱了。
这才是为什么网络一忙,
实时系统就容易不稳。
最后怎么一句话记住?
网卡拖慢实时系统的本质,不是因为带宽拥塞,而是因为中断、irqthread、NAPI 和 softirq 制造了大量不可预期的异步抢占;
真正有效的办法,不是只盯业务线程,而是通过 IRQ 亲和性、CPU 绑定和 CPU 隔离,把网络路径和实时控制路径在核级别彻底切开。
所以后面你再遇到“空载很稳、带网就抖、cyclictest 一压流量就起尖峰”这类问题,
先看中断。再看 irqthread。再看 NAPI 和 softirq 到底压在哪个核上。
面试时 30 秒怎么答
网卡拖慢实时系统的本质,不是带宽不够,而是网络路径会产生大量异步抢占,包括:硬中断、irqthread、NAPI poll 和 NET_RX_SOFTIRQ 后续处理。这些工作会抢 CPU、打断关键线程、拉长调度延迟。解决思路不是先优化业务线程,而是通过 IRQ 亲和性、线程绑核和 isolcpus 这类 CPU 隔离手段,把网络路径和实时路径在物理核级别尽量切开。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
