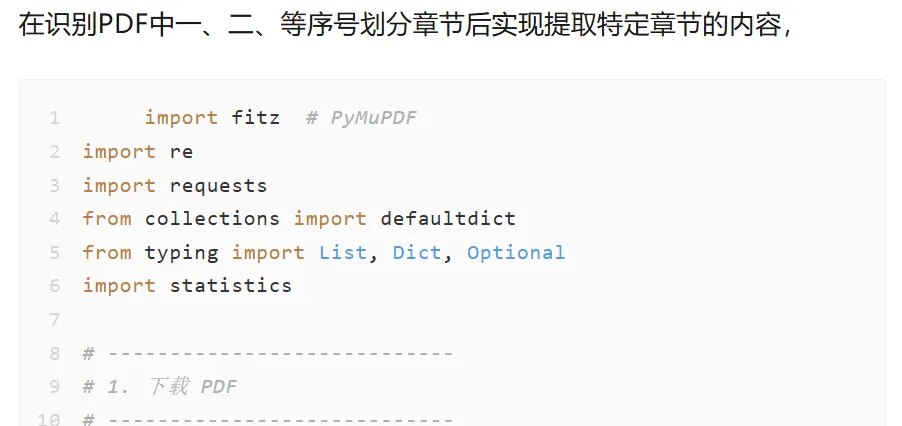
import fitz # PyMuPDFimport reimport requestsfrom collections import defaultdictfrom typing import List, Dict, Optionalimport statistics# ----------------------------# 1. 下载 PDF# ----------------------------def download_pdf(url: str, timeout: int = 30) -> bytes: headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36" } resp = requests.get(url, headers=headers, timeout=timeout, stream=True) resp.raise_for_status() return resp.content# ----------------------------# 2. 中文标题匹配与特征打分# ----------------------------CHINESE_NUM_PATTERN = re.compile(r'^[一二三四五六七八九十百千]+[、..]')def is_chinese_heading(text: str) -> bool: return bool(CHINESE_NUM_PATTERN.match(text.strip()))def score_heading_line(line, global_median_size, page_width, page_height): text = "".join([s["text"] for s in line["spans"]]).strip() if not is_chinese_heading(text): return 0 score = 1 sizes = [s["size"] for s in line["spans"]] max_size = max(sizes) if sizes else 0 is_bold = any("Bold" in s.get("font", "") for s in line["spans"]) if max_size > global_median_size * 1.1: score += 1 if is_bold: score += 1 bbox = line["bbox"] if bbox[1] < page_height * 0.4: score += 1 if bbox[0] < page_width * 0.1: score += 1 return score# ----------------------------# 3. 页码处理(物理→显示)# ----------------------------def get_display_page(doc: fitz.Document, physical_index: int) -> str: """物理页码(0-based)转显示页码(标签或数字)""" label = doc[physical_index].get_label() return label.strip() if label and label.strip() else str(physical_index + 1)# ----------------------------# 4. 提取章节(包含物理页码)# ----------------------------def extract_chapters( pdf_bytes: bytes, score_threshold: int = 3, numbered_only: bool = False) -> List[Dict]: """ 返回章节列表,每项包含: - title: 标题文本 - start_disp: 显示起始页码 - end_disp: 显示结束页码 - phys_start: 物理起始页索引(0-based) - phys_end: 物理结束页索引(0-based) """ doc = fitz.open(stream=pdf_bytes, filetype="pdf") chapters = [] total_phys = doc.page_count # ===== 书签优先 ===== toc = doc.get_toc() if toc: level1 = [(t, p) for l, t, p in toc if l == 1] if numbered_only: level1 = [(t, p) for t, p in level1 if is_chinese_heading(t)] for i, (title, page_num) in enumerate(level1): phys_start = page_num - 1 # PyMuPDF书签页码是1-based if i + 1 < len(level1): phys_end = level1[i+1][1] - 2 # 下一章起始页的前一页 if phys_end < phys_start: phys_end = phys_start else: phys_end = total_phys - 1 chapters.append({ "title": title, "start_disp": get_display_page(doc, phys_start), "end_disp": get_display_page(doc, phys_end), "phys_start": phys_start, "phys_end": phys_end }) return chapters # ===== 无书签时,文本特征识别 ===== all_sizes = [] for page in doc: for b in page.get_text("dict")["blocks"]: for line in b.get("lines", []): for span in line["spans"]: all_sizes.append(span["size"]) if not all_sizes: return chapters global_median_size = statistics.median(all_sizes) candidates = [] for pnum, page in enumerate(doc): pw, ph = page.rect.width, page.rect.height for b in page.get_text("dict")["blocks"]: for line in b.get("lines", []): text = "".join([s["text"] for s in line["spans"]]).strip() if not is_chinese_heading(text): continue s = score_heading_line(line, global_median_size, pw, ph) if s >= score_threshold: candidates.append((text, pnum, s)) candidates.sort(key=lambda x: x[1]) # 同页去重,保留最高分 page_best = {} for t, pn, sc in candidates: if pn not in page_best or sc > page_best[pn][1]: page_best[pn] = (t, sc) filtered = [(page_best[pn][0], pn) for pn in sorted(page_best)] for i, (title, pn) in enumerate(filtered): phys_start = pn if i + 1 < len(filtered): phys_end = filtered[i+1][1] - 1 if phys_end < phys_start: phys_end = phys_start else: phys_end = total_phys - 1 chapters.append({ "title": title, "start_disp": get_display_page(doc, phys_start), "end_disp": get_display_page(doc, phys_end), "phys_start": phys_start, "phys_end": phys_end }) return chapters# ----------------------------# 5. 章节拆分器# ----------------------------def split_chapter( pdf_bytes: bytes, chapter: Dict, output_path: Optional[str] = None) -> bytes: """ 从原 PDF 中提取某个章节的页面,保存为新 PDF。 - chapter 必须包含 'phys_start' 和 'phys_end'(如 extract_chapters 的输出) - 如果提供 output_path,则保存文件并返回字节流;否则仅返回字节流 """ doc = fitz.open(stream=pdf_bytes, filetype="pdf") new_doc = fitz.open() # 空白文档 start = chapter["phys_start"] end = chapter["phys_end"] # 插入指定页码范围 new_doc.insert_pdf(doc, from_page=start, to_page=end) result_bytes = new_doc.tobytes() if output_path: new_doc.save(output_path) print(f"已保存至:{output_path}") new_doc.close() doc.close() return result_bytes# ----------------------------# 6. 交互式拆分(控制台选择)# ----------------------------def interactive_split(chapters: List[Dict], pdf_bytes: bytes): """列出章节并让用户选择要拆分的章节。""" if not chapters: print("没有可拆分的章节。") return print("\n识别到的章节:") for i, ch in enumerate(chapters, 1): range_str = f"第{ch['start_disp']}-{ch['end_disp']}页" print(f" [{i}] {ch['title']} ({range_str})") while True: sel = input("\n请输入要拆分的章节编号(多个用逗号分隔,q退出): ").strip() if sel.lower() == 'q': break try: indices = [int(x.strip()) - 1 for x in sel.split(',') if x.strip()] for idx in indices: if 0 <= idx < len(chapters): ch = chapters[idx] # 自动生成文件名:标题 + 页码范围 safe_title = re.sub(r'[\\/*?:"<>|]', "_", ch['title']) fname = f"{safe_title}_p{ch['start_disp']}-{ch['end_disp']}.pdf" split_chapter(pdf_bytes, ch, output_path=fname) else: print(f" 无效编号:{idx+1}") except ValueError: print("输入格式错误,示例:1,3,5") else: print("拆分完成。")# ----------------------------# 7. 完整示例主程序# ----------------------------if __name__ == "__main__": # 替换为你的 PDF 链接 URL = "https://sthjj.suzhou.gov.cn/szhbj/jsslgs/202605/3a30a2711bb5402389ffa4882a5a71d4/files/e493759743c242e69f9d6cb572f61d75.pdf" try: print("正在下载 PDF...") pdf_data = download_pdf(URL) print("正在识别章节...") # numbered_only=True 可以只保留带中文序号的标题 chapters = extract_chapters(pdf_data, score_threshold=3, numbered_only=False) if not chapters: print("未识别到任何章节。") else: print(f"共识别到 {len(chapters)} 个章节。") # 进入交互式拆分 interactive_split(chapters, pdf_data) except Exception as e: print(f"出错了: {e}")