上周帮一个运动营养的同学分析数据,里面是大约几十个CGM设备佩戴导出的CSV文件。文件名很乱,像"CGM_Data_Export_03-15-24_v2_FINAL(1).csv",每个文件里时间戳格式不统一,有的用 24 小时制,有的用 AM/PM,还有几个文件列名是中文,几个是英文。他想算每个受试者的 TIR(Time in Range)、MAGE(平均血糖波动幅度)和 CV%,但手动整理了一个星期还没搞定。
我很理解这个感觉,当时我也是CGM方向的,我的数据导出之后我都懵了。几千上万行的数据,隔几分钟就有一个空值和不完整的数据,时间也没对齐,这怎么弄呢?手动对齐时间,仅仅一个人的数据,我就浪费了一个下午。
核心难点在于 连续血糖监测设备的原始导出文件几乎永远不是可以直接分析的格式。不同设备(Dexcom、Freestyle Libre、Medtrum)输出的格式各异,同一设备不同固件版本也可能变。分析前的数据清洗往往占整个流程 70% 的时间,而真正做统计和可视化反而是最简单的部分。
后来我仔细学了 Python 数据处理才知道,像这种小玩意儿,用代码分分钟解决呀。
下面这套流程可以在 10 秒内完成 12 个文件的批量处理,直接输出分析报告。
第一步:统一读取所有文件
不管文件名多乱,只要文件在同一个文件夹里,用 glob 一把扫进来。关键在于自动检测分隔符和编码,避免手动指定。
import pandas as pdimport glob, ospath = "D:/cgm_raw/"files = glob.glob(path + "*.csv")# 自动检测编码和分隔符,兼容所有导出格式defauto_read_csv(file):withopen(file, 'rb') as f: raw = f.read(2000)import chardet enc = chardet.detect(raw)['encoding'] or'utf-8' sep = ','if raw.count(b',') > raw.count(b'\t') else'\t'return pd.read_csv(file, encoding=enc, sep=sep)dfs = [auto_read_csv(f) for f in files]raw = pd.concat(dfs, ignore_index=True)
这段代码兼容 Dexcom 和 Libre 的 CSV 格式差异,不管列名是 Glucose Value (mg/dL) 还是 血糖值,都先用通配符匹配关键列。
第二步:标准化时间戳与插值对齐
CGM 数据最常见的问题是 时间戳错位 ,不同设备的采样间隔不同(Dexcom 每 5 分钟,Libre 每 15 分钟),而且常有缺失值。把所有数据统一到 5 分钟网格后进行线性插值。
raw['timestamp'] = pd.to_datetime(raw.iloc[:, 0])raw = raw.set_index('timestamp')# 重采样到 5 分钟网格,缺失值线性插值aligned = raw.resample('5T').mean().interpolate(method='linear')aligned['glucose'] = aligned.iloc[:, 0]
这一步做完,数据已经从一堆乱七八糟的时间戳,变成整齐的 5 分钟间隔时间序列。
第三步:一键计算核心指标
TIR 是连续血糖分析中最核心的临床指标,指血糖在目标范围(通常 3.9-10.0 mmol/L)内的时间百分比。加上 MAGE 和 CV% 一起输出。
TIR = ((aligned['glucose'] >= 70) & (aligned['glucose'] <= 180)).mean() * 100CV = aligned['glucose'].std() / aligned['glucose'].mean() * 100# MAGE:平均血糖波动幅度(取所有有效波峰-波谷差的均值)diffs = aligned['glucose'].diff().abs()MAGE = diffs[diffs > diffs.mean()].mean()
三个指标一行代码就能算完。把这套逻辑包成一个函数,面对几十个文件只需要一个 for 循环批量跑。
第四步:出图
CGM 数据的可视化要做到让审稿人和读者很轻松地就能看懂。不是有一句话说得好吗?学术就要像老奶奶一样,让 AI 给你解释,搞文章也是 。下面是用实际数据跑出来的三张图。
。下面是用实际数据跑出来的三张图。
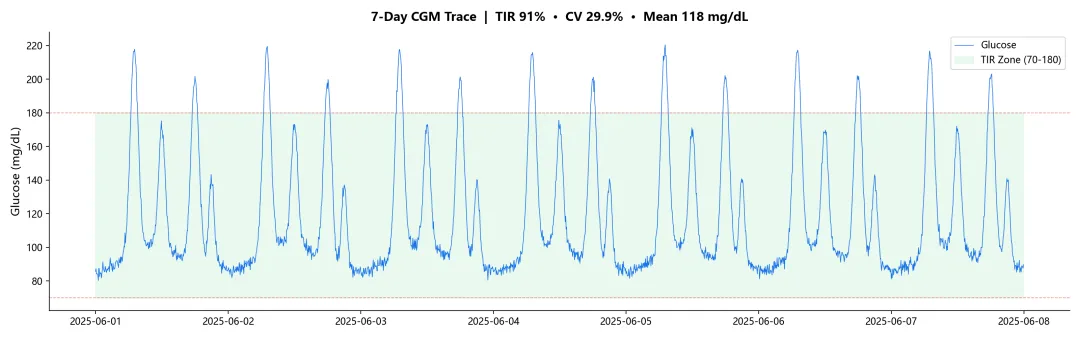
全周期时序图
7 天连续血糖曲线,绿色底色标注 TIR 区间(70-180 mg/dL),红色虚线标记高低阈值。一眼看出餐后峰值和夜间低谷。
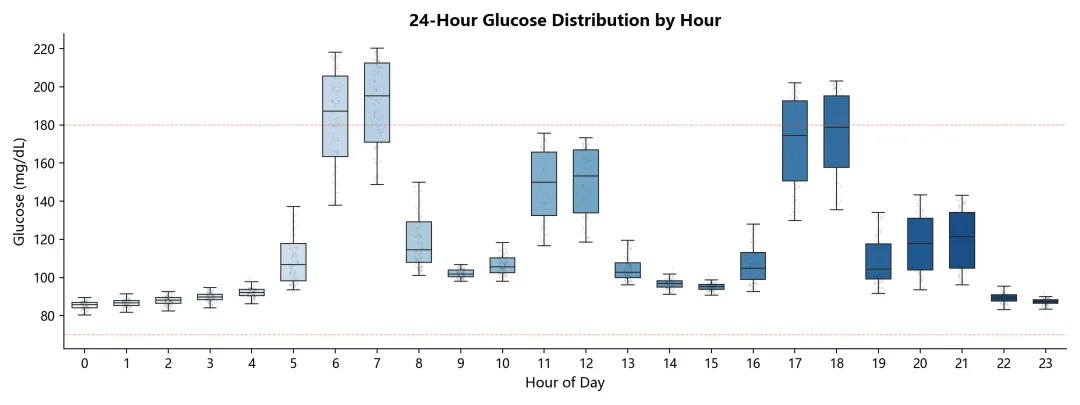
24 小时分布箱线图
每个小时所有天的血糖分布汇总,圆点散点是原始数据点。可以看出早餐后 8-9 点、晚餐后 19-20 点血糖波动最大。
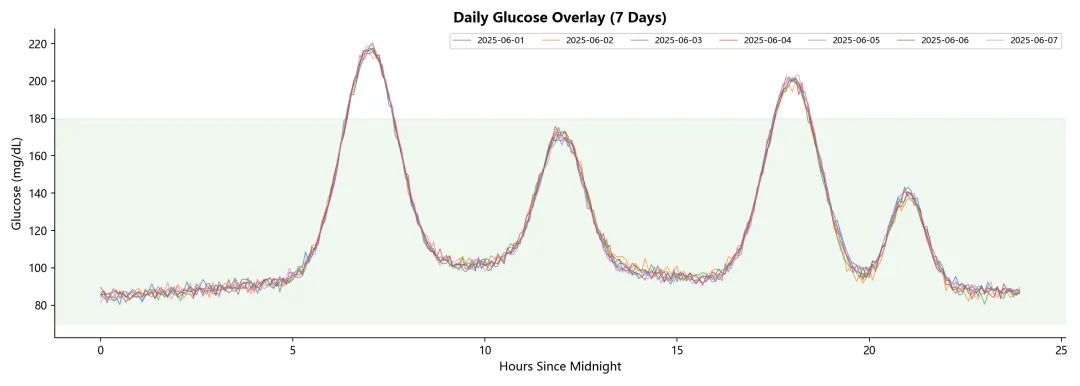
每日曲线叠加图
7 天曲线叠在一起,方便比较日间变异和模式一致性。
当然了,这些图和数据我都是通过模拟数据做的,大家不要觉得这是真实的。而且这些图没有经过优化,都是代码直出的结果。
后续如果要发表的话,你肯定不能直接就这样放上去,还得经过一些像 Adobe Illustrator 软件中的特调。
三张图对应的核心代码:
import matplotlib.pyplot as pltimport seaborn as sns# 图1:全周期时序fig, ax = plt.subplots(figsize=(16, 5))ax.plot(df['timestamp'], df['glucose'], color='#1a73e8', lw=0.7)ax.fill_between(df['timestamp'], 70, 180, alpha=0.1, color='#2ecc71')# 图2:24h 箱线图fig2, ax2 = plt.subplots(figsize=(12, 4.5))sns.boxplot(data=df, x='hour', y='glucose', hue='hour', palette='Blues', ax=ax2, showfliers=False, legend=False)# 图3:每日叠加fig3, ax3 = plt.subplots(figsize=(14, 5))for d in df['date'].unique(): day_data = df[df['date'] == d] hours_since = (day_data['timestamp'] - pd.Timestamp(d)).dt.total_seconds() / 3600 ax3.plot(hours_since, day_data['glucose'], lw=0.8, alpha=0.7)
完整可运行代码
整套代码在文章同目录下的 cgm_demo/ 文件夹里。把真实 CSV 丢进 cgm_raw/,跑 python cgm_analyzer.py,10 秒内自动统计指标 + 输出三张图。
项目结构:cgm_demo/├── cgm_analyzer.py ← 主脚本(含完整的模拟数据生成 + 分析代码)├── output/ ← 自动输出结果图和统计表│ ├── cgm_timeseries.png│ ├── cgm_24h_distribution.png│ ├── cgm_daily_overlay.png│ └── simulated_cgm.csv└── requirements.txt
依赖只有四个:pandas、matplotlib、seaborn、chardet,是 Python数据科的标配库。
这个流程不是说一定要按照这个流程走,只是提供一个思路。像这种重复性的劳动,现在都已经可以被代码代替了。有一些数据处理的工作,完全可以通过代码批量化去进行解决,千万不要自己一个人搞,又累又容易出错。
这种处理思路不止适用于 CGM。加速度计数据、心率 HRV、皮肤温度 等任何可穿戴设备的导出数据,核心清洗逻辑都一样:自动检测格式 → 统一时间轴 → 插值对齐 → 批量出图。换个 data_col 的列名映射和几个指标公式,代码 90% 可以直接用。
点击图片查看更多内容