在大数据与新文科融合发展的当下,社会网络分析(SNA)成为衔接社会学、经济学、管理学与计算机技术的重要研究方法。它将现实世界中的个体、机构、地域等实体抽象为网络节点,把实体间的关联关系定义为网络边,结合数据挖掘、可视化技术挖掘网络结构、关联强度与运行规律。由邵鹏、李梦蕾主编的《社会网络分析方法与案例》是该领域的实用教材,书中原本依托 Excel VBA 完成案例实操,而本文结合 Python 语言对全书第 7 至 11 章共 13 个典型案例进行完整复现,覆盖文本、学术、商业、人才、经济贸易五大应用领域,完整展示从数据处理、网络搭建、指标统计到可视化输出的全流程,同时详解不同场景下社会网络分析的落地思路。
一、项目基础概况
本次案例复现项目依托通用 CPU 运行环境与 2025 版基础镜像开发,核心使用pandas完成数据读取与清洗,networkx搭建各类复杂网络,jieba实现中文文本分词,搭配matplotlib、plotly、seaborn等库完成多形式可视化。所有代码均适配 Excel 格式数据源,输出文件支持 Gephi、Cytoscape 等专业网络分析工具,兼顾教学学习与实际项目使用需求。
整套案例遵循标准化操作流程:Excel 数据读取→数据清洗(去空值、格式统一、文本预处理)→构建有向 / 无向加权网络→统计网络基础指标→可视化呈现→导出通用格式文件。根据业务逻辑不同,网络分为无向网络(双向平等关系)、有向网络(单向流向关系)、加权网络(以次数、强度为权重)三大类型,适配不同现实场景的关系特征。
二、关键词共现网络:挖掘文本背后的热点与关注点
关键词共现网络是文本分析的常用手段,核心逻辑为多个词汇在同一文本中共同出现,则建立节点连接,共现频次作为边的权重,广泛应用于学术热点研判、电商舆情分析、社交媒体热点监测等场景。本章共包含知网论文、电商评论、微博文本三个案例。
2.1 知网论文关键词共现网络
该案例以学术论文关键词为分析对象,数据源为 Excel 表格中逐行记录的单篇论文关键词,规则为提取每篇论文前 5 个关键词构建共现网络,以此梳理学科研究热点与词汇关联逻辑。
实操中首先读取表格数据,剔除空值后提取有效关键词,通过排列组合算法生成关键词两两配对关系,累计共现次数作为边权重。最终构建出包含 851 个关键词节点、1907 条关联边的无向加权网络。

关键词共现网络可视化图
从可视化结果可以清晰看到,“绿色消费” 等核心词汇处于网络中心位置,与周边词汇连接紧密,直观反映出该领域的核心研究方向。项目同时支持将网络导出为.gexf格式文件,可导入专业软件做深度拓扑分析。
2.2 商用评论关键词共现网络
本案例选取汉服产品电商评论作为数据源,面向商业场景挖掘消费者诉求。由于评论文本为自然语言,需要先完成分词、停用词过滤、词性筛选等预处理工作。
流程上先读取全部评论文本,利用jieba分词工具拆分语句,剔除虚词、单字等无效词汇,筛选名词、动词、形容词等有效词汇,统计所有词汇出现频次并选取排名前 50 的高频词。基于这 50 个词汇,统计其在单条评论中的共现关系,搭建共现网络,最终形成 50 个节点、1029 条边的网络结构,并导出边列表 CSV 文件。
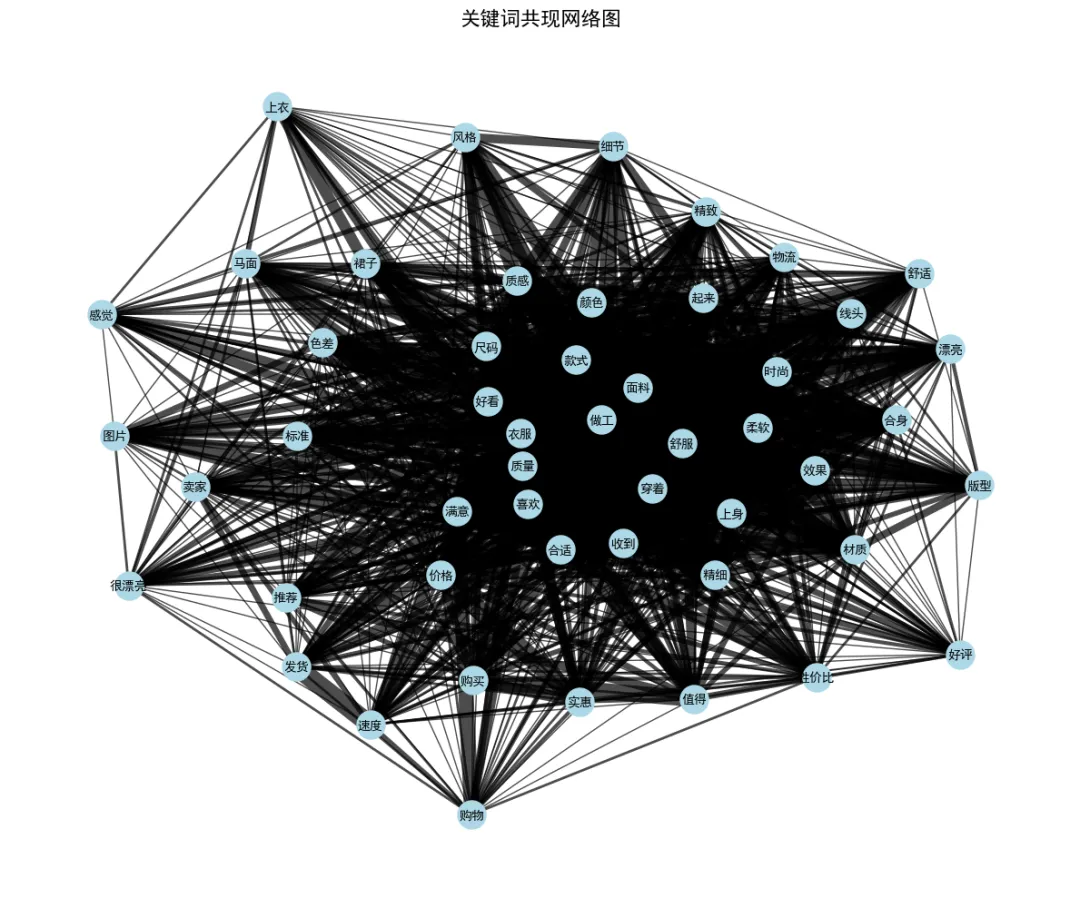
Top50 关键词共现网络图
网络中 “面料”“款式”“做工”“尺码” 等词汇关联度极高,精准体现出消费者选购服饰时的核心关注点,能够为商家优化产品、调整运营策略提供数据支撑。
2.3 微博关键词共现网络
针对人民日报 “夜读” 板块微博文本开展分析,适用于舆情监测、社会情绪与公众关注点研究。微博文本存在 URL 链接、@用户、表情符号等冗余内容,因此预处理环节增加了文本清洗步骤。
代码实现中依次剔除链接、特殊符号、表情与空白字符,加载外部停用词表过滤无意义词汇,统计高频词后选取 Top50 词汇搭建共现网络。除传统静态可视化外,本案例使用pyecharts制作交互式网络图,支持页面缩放、节点悬浮查看详情,交互性更强。
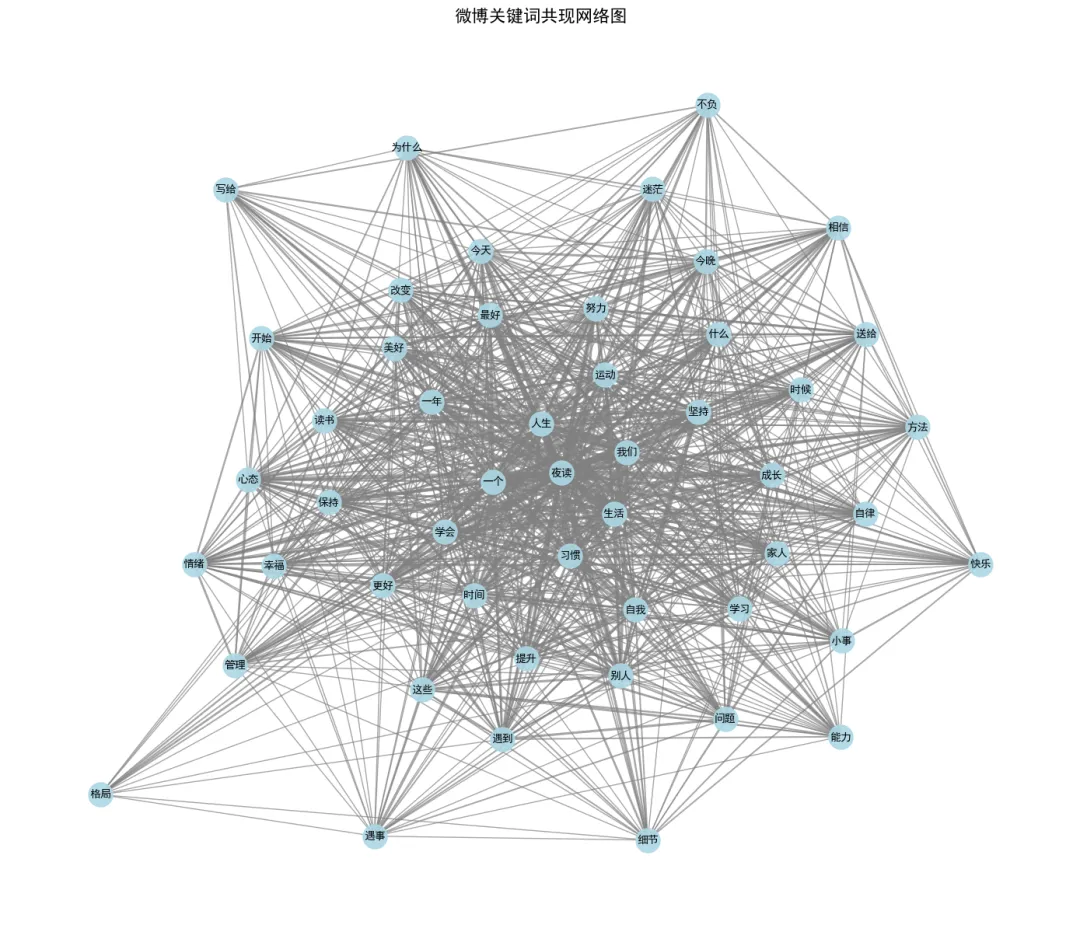
微博关键词交互式共现网络图
从网络结构能看出,“夜读”“生活”“人生”“坚持” 等词汇居于核心,契合该板块内容定位,也反映出网友对生活感悟、自我成长类内容的关注。
三、合作联合网络:解析组织与团队协作模式
合作联合网络以主体共同参与同一事件作为建网依据,合作次数决定边的权重,主要用于分析学术团队、区域机构、内部部门的协作关系,包含论文合作、省际科技合作、医院科室会诊三个案例。
3.1 论文合作网络
基于知网论文作者数据构建学者合作网络,规则为提取单篇论文前 3 位作者,两位及以上作者共同署名即判定为存在合作关系。
读取作者名单表格后,逐行提取作者姓名,过滤单人论文数据,对多名作者进行两两组合并累计合作频次。最终得到 338 个作者节点、492 条合作边,同时计算出网络密度等基础指标。

作者合作网络核心区域可视化图
可视化采用优化布局算法,将联系紧密的核心团队聚集在网络中心,外围为独立学者或松散合作群体,清晰划分出领域内主流研究团队,为学术交流、团队合作提供参考。
3.2 省际科技成果合作网络
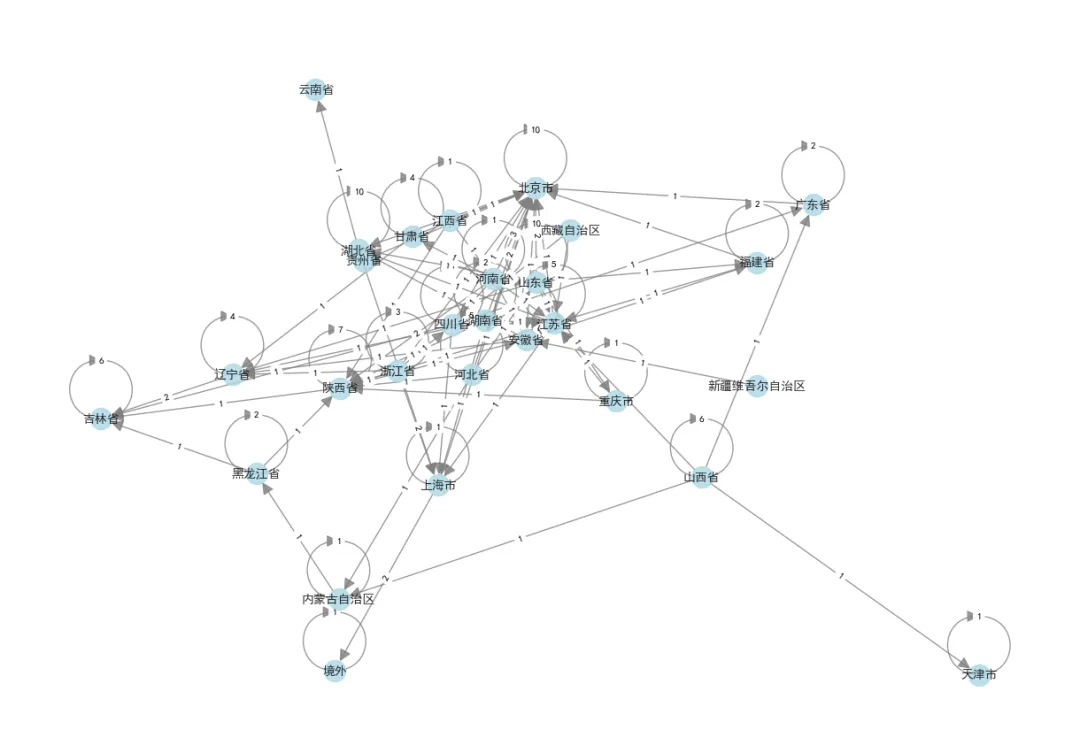
数据源为省份科技合作统计表,表格直接记录两两省份的合作次数,以此为权重搭建省际科技合作无向网络。
直接读取省份与合作次数数据,遍历表格完成节点与边的添加,最终网络包含 27 个省级行政区节点、161 条合作边。可视化时用节点大小代表省份合作广度(连接省份数量),边的宽度代表合作频次。
省际科技成果合作网络图
从图中可见,东部经济发达省份节点更大、连线更密集,是区域科技合作的核心枢纽,直观展现出国内科技资源的联动格局。
3.3 医院科室会诊网络
区别于前两个无向合作网络,本案例构建有向网络,贴合医院会诊的实际业务逻辑:以会诊科室为起点、申请会诊的科室为终点,箭头代表会诊流向。
读取申请科室与会诊科室两列数据,搭建有向图,最终形成 72 个科室节点、1989 条有向边。节点大小根据科室连接度数调整,度数越高代表该科室参与或发起的会诊越多。
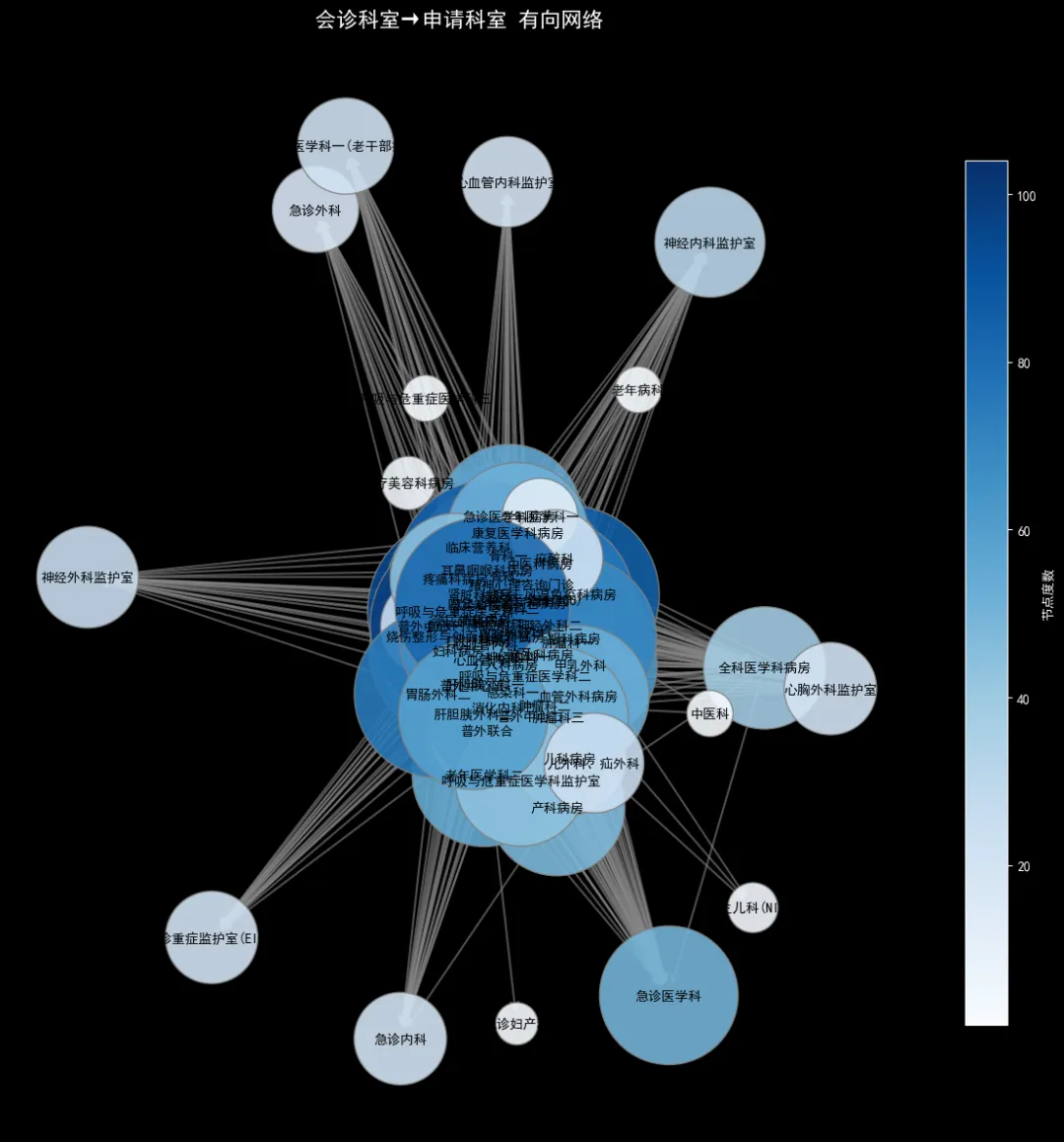
医院科室会诊有向网络图
该网络可以帮助医院管理者识别高频协作科室,优化科室分工、调配医疗资源,提升整体诊疗效率。
四、上市公司网络:挖掘企业关联与竞争格局
商业领域的社会网络分析能够挖掘企业间隐性关联,本次包含连锁董事网络、发明专利竞争网络两大案例,分别对应企业合作圈层与技术竞争格局分析。
4.1 连锁董事网络
核心逻辑:若同一个高管 / 董事(以唯一人员 ID 区分)在多家上市公司任职,那么这些上市公司之间就存在连锁关联关系。
数据处理阶段先读取证券代码与人员 ID 数据,清理缺失值并统一 6 位证券代码格式;再建立 “人员 - 任职公司” 映射关系,对单人任职的多家公司两两配对生成关联边,去除重复关系后完成网络搭建。最终网络拥有 2560 家上市公司节点、4398 条关联边,同时导出企业关联 Excel 清单。

上市公司连锁董事关系网络图
该网络可用于分析资本市场中的企业圈层、商业联盟,辅助研判企业经营关联与战略布局。
4.2 发明专利竞争网络
以专利 IPC 小类(技术分类)为关联依据:两家企业拥有同一技术领域的专利,即判定为存在技术竞争关系,共享专利的数量越多,竞争关联强度越高。
读取上市公司证券代码与专利 IPC 分类数据,按技术领域分组,对同一领域内的企业两两建边,累计共享专利数作为边权重。最终得到 133 家企业节点、7563 条竞争边,导出包含竞争强度的边列表文件。
上市公司专利竞争网络可视化图
通过该网络可快速划分行业竞争梯队,梳理细分技术领域的竞争态势,为企业技术研发、市场战略制定提供依据。
五、人员流动网络:追踪人才与客流迁移轨迹
人员流动网络属于典型有向流动网络,节点为地域 / 景点,边代表流动方向,频次代表流动规模,涵盖科学家地域流动、旅游数字足迹等三类案例。
5.1 女青年科学家流动网络
基于科学家不同人生阶段的所在地数据,划分三类独立流动场景:求学流动(出生地→本科就读地)、就业流动(最高学历所在地→首次工作地)、职场流动(首次工作地→当前工作地)。
读取包含出生、本科、学历、工作等多阶段省份信息的表格,按三大流动关系分别构建有向加权网络,统计不同省份间的人才流动频次,三类网络分别生成对应数量的节点与流向边,并导出.gexf文件。
分层网络能够清晰展现人才在求学、就业、职场阶段的地域选择偏好,为各地人才引进、科教资源布局提供参考。
5.2 人工智能科学家流动冲击图
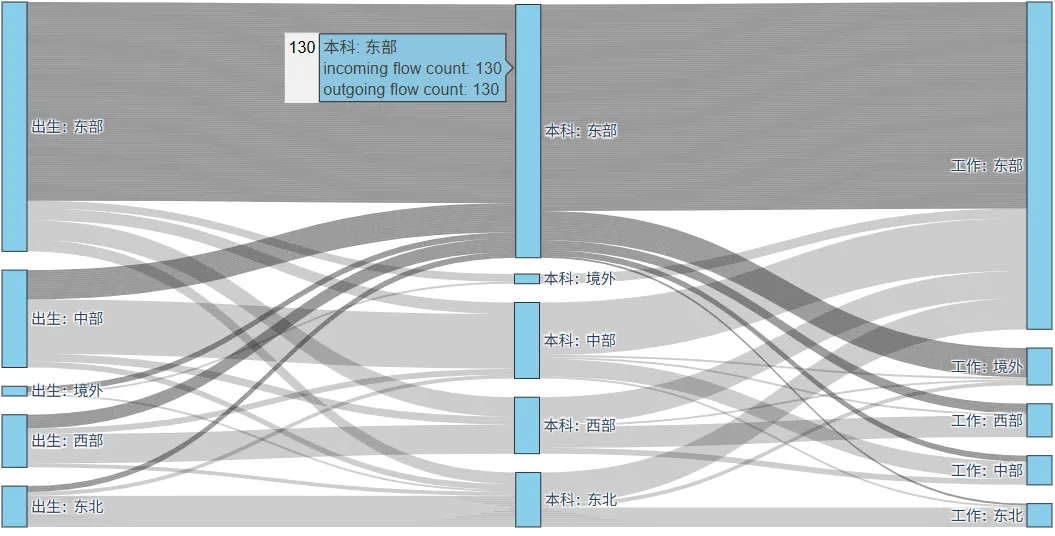
选取出生地、本科就读地、当前工作地三个核心阶段,将地域划分为东部、西部、中部、东北、境外五大区域,使用plotly绘制桑基图(冲击图),可视化人才跨区域的完整流动路径。
对各阶段区域名称添加标识区分节点,梳理相邻阶段的流动关系并统计人数,生成交互式桑基图,可导出 HTML 文件在浏览器中打开查看。
人工智能科学家区域流动冲击图
桑基图直观展示了 AI 人才的整体流动趋势,比如东部区域既是人才主要出生地,也是核心就业地,区域人才集聚效应显著。
5.3 旅游数字足迹网络
以西安旅游游记和景点清单为数据源,规则为两个景点在同一篇游记中出现,即产生共现关联,用于分析游客游览偏好与经典旅游线路。
分别读取游记文本与景点名称列表,逐篇检索游记中出现的景点,统计景点两两共现次数,最终生成景点邻接矩阵、权重矩阵、景点频次表三类数据文件。本次共纳入 20 个景点,矩阵数据清晰量化了景点之间的联动关系。
旅游景点共现权重矩阵热力图
从数据与可视化结果可知,兵马俑、城墙、大雁塔等高频景点相互共现概率高,是游客首选的组合游览线路,可为景区规划、旅游路线设计提供数据支撑。
六、经济贸易网络:分析区域联动与国际贸易格局
经济贸易类网络结合地理数据、引力模型等专业方法,分析城市经济关联、全球贸易流向,包含黄河流域城市空间关联网络、镍及其制品贸易网络两个案例。
6.1 黄河流域城市空间关联网络
采用引力模型计算城市间关联强度,计算公式:城市关联强度 =(城市 A 产业韧性 × 城市 B 产业韧性)÷ 两城市直线距离的平方。关联强度越高,代表两座城市经济联动性越强。
数据源分为两张表格:其一为各城市产业韧性指标,其二为城市间距离矩阵。匹配城市名称后,遍历所有城市对计算关联强度,生成完整关联矩阵,并利用热力图展示城市间关联强弱,同时导出矩阵与边列表 Excel 文件。本次分析覆盖 82 座黄河流域城市。
热力图中颜色越深代表关联强度越高,可据此划分经济联动组团,助力黄河流域城市协同发展规划。
6.2 镍及其制品贸易网络
融合贸易数据与地理经纬度数据构建国际贸易有向网络,创新采用经纬度定位节点位置,实现 “地理实景式” 网络布局。
读取出口国、进口国、贸易额组成的贸易表,以及国家名称、经纬度的地理表,匹配数据后搭建有向网络:节点为各个国家,箭头代表贸易进出口方向,边的宽度与颜色通过对数缩放映射贸易额大小,节点大小代表该国贸易往来频次。最终网络包含 89 个国家节点、290 条贸易边。
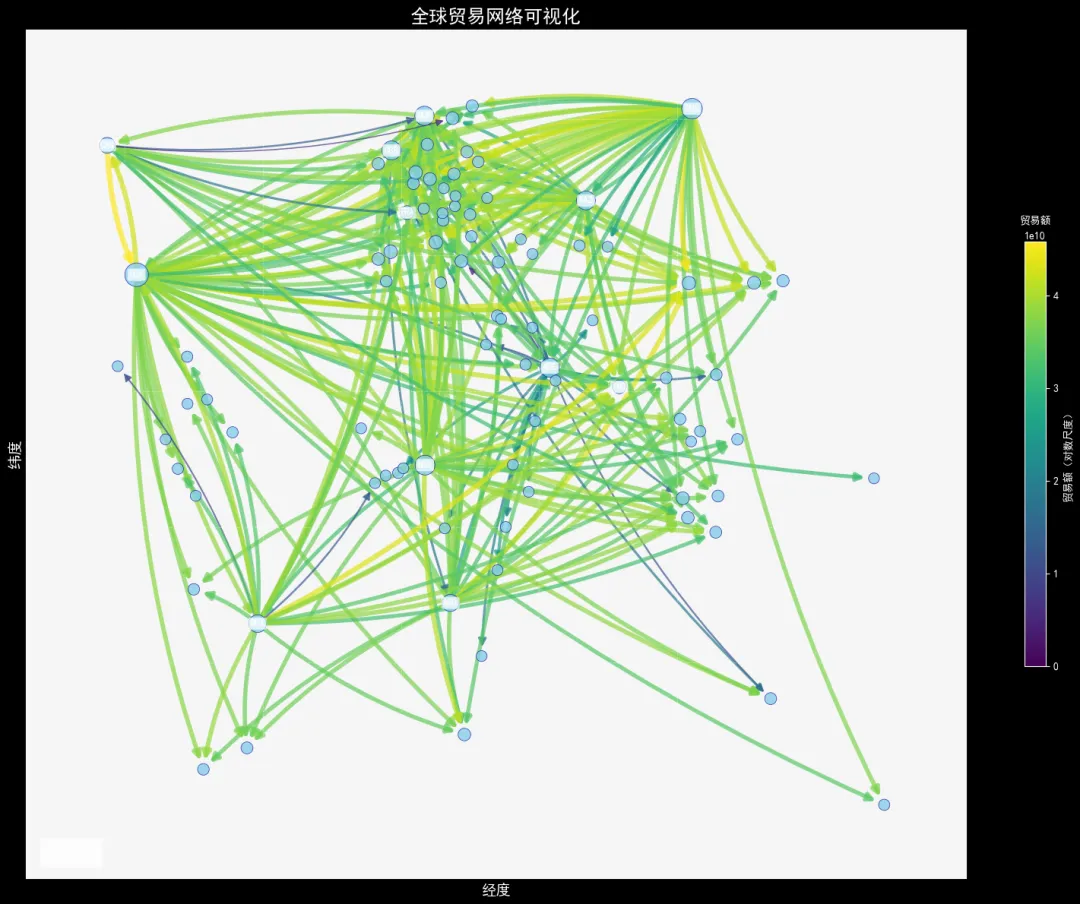
全球贸易网络图
该网络直观呈现出全球镍产品的主要出口国、进口国以及核心贸易通道,清晰反映国际贸易格局与区域贸易特征。
七、总结与技术复盘
本次 13 个案例完整覆盖社会网络分析主流应用场景,借助 Python 工具实现了从基础文本分析到复杂经济网络建模的全维度实操,充分体现出 Python 在数据处理、可视化、兼容性上的优势。
从技术层面来看,整套案例实现了无向、有向、加权三大网络类型的全覆盖,搭配静态图、交互式图表、热力图、地理布局网络图、桑基图等多样化可视化形式,同时建立了标准化的数据预处理体系,文本清洗、格式统一、分词过滤等代码模块可直接复用。所有输出文件兼容主流专业分析软件,兼顾代码实操与专业研究需求。
从应用价值而言,这套实战案例既可作为高校管理学、经济学、大数据专业的教学实训内容,弥补传统 VBA 实操的局限性;也能为行业从业者提供参考,应用于学术热点分析、电商舆情、医院管理、企业竞争、旅游规划、区域经济、国际贸易等多个领域。
社会网络分析作为连接数据与现实社会关系的桥梁,在数字时代的应用场景还在不断拓展。本次 Python 案例复现,为零基础学习者提供了清晰的实操路径,也为行业研究人员提供了可落地的技术模板,推动社会网络分析方法在更多领域落地生根。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
