第一章 Direct I/O 的产生背景
1.1 Page Cache 机制带来的问题
Linux 文件系统默认采用 Buffered I/O 模式运行。当应用程序执行 read() 或 write() 时,请求首先进入 VFS,然后通过 address_space 找到对应的 Page Cache 页面。对于读取操作,如果缓存命中,则直接从内存返回数据;对于写入操作,则将数据复制到缓存页并标记为 Dirty Page,随后由后台回写线程异步刷新到磁盘。这种设计能够显著减少磁盘访问次数,提高普通业务场景下的系统吞吐量,因此 Page Cache 一直是 Linux 存储子系统最核心的优化机制之一。
然而对于数据库、分布式存储以及高性能文件系统来说,Page Cache 并不一定总是有利。MySQL、PostgreSQL、Oracle 等数据库自身已经维护 Buffer Pool,而 Linux 又额外维护一份 Page Cache,相同的数据会在用户空间和内核空间各保存一份,形成典型的 Double Cache 问题。大量内存被重复占用,同时每次写入还需要执行用户空间到内核空间的数据复制,CPU 消耗明显增加。当存储设备从机械硬盘发展到 SATA SSD、NVMe SSD 后,存储访问延迟大幅下降,数据复制和缓存管理反而逐渐成为新的性能瓶颈。
1.2 O_DIRECT 的设计目标
为了解决双缓存和额外数据复制问题,Linux 引入了 O_DIRECT 机制。应用程序在打开文件时指定 O_DIRECT 标志后,内核会尽量绕过 Page Cache,直接在用户缓冲区和块设备之间建立数据传输路径。这里所谓的“直接”并不是绕过文件系统,而是绕过页缓存层。文件系统仍然需要完成权限检查、块映射、日志处理以及元数据更新,只是不再为数据页建立缓存。
用户空间开启 Direct I/O 的方式非常简单:
int fd;fd = open("data.bin", O_RDWR | O_DIRECT);
文件打开后,后续 read()、write() 请求都会携带 Direct I/O 标记。对于数据库而言,这意味着数据可以直接进入磁盘而无需经过页缓存;对于大规模顺序读写场景,则可以减少缓存污染,避免热点缓存被海量文件访问冲掉。因此 O_DIRECT 并不是为了替代 Buffered I/O,而是针对存储系统和数据库场景设计的一种特殊优化机制。
第二章 从系统调用到 Direct I/O
2.1 write() 调用链分析
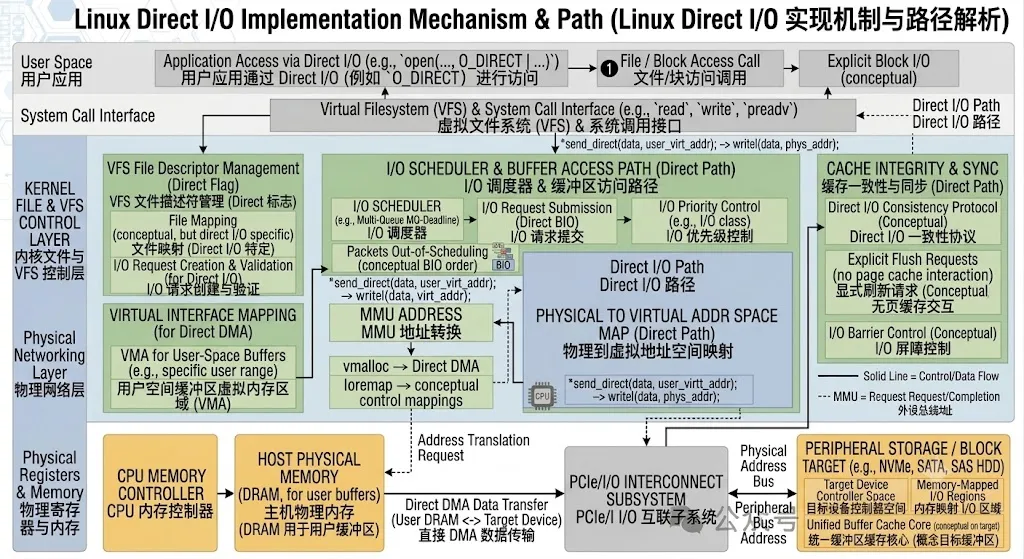
无论是否使用 O_DIRECT,Linux 文件写入都会从系统调用入口开始。用户态调用 write() 后,请求经过系统调用表进入内核,随后依次经过 ksys_write()、vfs_write()、__vfs_write() 等通用层,最终进入具体文件系统实现。整个调用链如下:
write() └─ ksys_write() └─ vfs_write() └─ __vfs_write() └─ file->f_op->write_iter()
VFS 的职责是屏蔽 ext4、XFS、F2FS 等不同文件系统之间的差异,因此在到达 write_iter() 之前,系统并不会关心当前请求是否属于 Direct I/O。所有请求都会经过统一的文件对象 struct file,而 O_DIRECT 标志也正是保存在该结构体中。这样 VFS 可以把具体实现细节全部交给文件系统层处理,实现统一接口与分离实现的设计目标。
struct file 中包含大量与文件相关的信息,其中最重要的成员之一就是 f_flags。应用程序在 open() 时传入的 O_DIRECT 最终会被记录到这里,后续所有读写请求都通过该标志判断是否进入 Direct I/O 路径。这也是 Linux 将打开操作和实际读写操作解耦的重要体现。
2.2 ext4 如何识别 O_DIRECT
以 ext4 为例,写请求最终会进入 ext4_file_write_iter()。这里是 Buffered I/O 与 Direct I/O 的分叉点:
static ssize_t ext4_file_write_iter( struct kiocb *iocb, struct iov_iter *from){ if (iocb->ki_flags & IOCB_DIRECT) return ext4_dio_write_iter(iocb, from); return ext4_buffered_write_iter( iocb, from);}
从源码可以看到,判断逻辑非常简单。当 IOCB_DIRECT 被设置时,请求直接进入 ext4_dio_write_iter();否则进入传统 Buffered I/O 流程。虽然这里只是一个简单的 if 分支,但后续执行路径完全不同。Buffered I/O 会围绕 Page Cache 展开,而 Direct I/O 则直接进入块映射与 BIO 构建阶段。
早期 Linux 内核使用 fs/direct-io.c 实现 Direct I/O,代码复杂且维护成本较高。近年来 ext4、XFS 等主流文件系统逐渐迁移到 iomap 框架,通过统一接口实现 Direct I/O。这样不仅减少了重复代码,也让不同文件系统能够共享同一套 DIO 基础设施。因此现代 Linux 内核中看到的 Direct I/O 调用链,大多数最终都会进入 iomap_dio_rw()。
第三章 Buffered I/O 与 Direct I/O 的差异
3.1 Buffered I/O 的执行过程
Buffered I/O 的核心思想是先写缓存,再写磁盘。当应用程序执行 write() 时,内核首先检查目标页是否已经存在于 Page Cache 中。如果不存在,则分配新的缓存页;如果存在,则直接使用已有页面。随后用户数据通过 copy_from_user() 被复制到缓存页,并将页面标记为 Dirty 状态,等待后台线程回写,流程:
write() └─ generic_perform_write() └─ grab_cache_page_write_begin() └─ copy_page_from_iter() └─ set_page_dirty()
这里最关键的对象是 struct page。Linux 使用 struct page 描述物理内存中的每个页面,而 Page Cache 本质上就是大量 struct page 组成的缓存集合。文件系统通过 address_space 管理这些页面,因此 Buffered I/O 的核心工作实际上是在维护缓存页生命周期,包括页分配、页回收、脏页回写以及缓存一致性管理等。
3.2 Direct I/O 如何绕过缓存
Direct I/O 最大特点是不创建 Page Cache。请求进入文件系统后不会调用 grab_cache_page_write_begin(),也不会执行 set_page_dirty()。数据直接从用户缓冲区映射到块层 BIO,随后提交给底层设备驱动,现代 ext4 的执行路径:
write() └─ ext4_dio_write_iter() └─ iomap_dio_rw() └─ submit_bio() └─ blk_mq_submit_bio()
这里可以看到,Page Cache 完全消失了。整个流程重点变成用户页锁定、块映射查询以及 BIO 构建。对于大型顺序读写场景,这种方式能够减少一次内存复制,同时避免页缓存占用大量内存资源。但代价是失去了 Page Cache 带来的缓存命中优势,因此 Direct I/O 更适合数据库、大文件流式处理以及存储系统,而不是普通业务程序。
第四章 用户缓冲区与页面锁定机制
4.1 为什么 DMA 不能直接访问用户地址
很多人理解 O_DIRECT 时容易产生误解,认为数据直接从用户缓冲区进入磁盘,因此内核完全不参与数据处理。实际上设备驱动并不能直接访问用户空间虚拟地址,因为用户程序中的 malloc() 返回的是虚拟地址,而 DMA 控制器需要访问物理地址。内核必须先建立虚拟地址到物理页之间的映射关系,才能让设备正确执行数据传输。
例如下面代码:
char *buf;buf = malloc(4096);write(fd, buf, 4096);
这里的 buf 只是进程页表中的一个虚拟地址。如果 DMA 正在访问该缓冲区时,内核将页面换出到磁盘或者迁移到新的物理位置,那么 DMA 将访问到错误地址。因此 Direct I/O 首先必须解决页面稳定性问题,保证整个传输期间对应物理页不会发生变化。
4.2 pin_user_pages() 工作机制
现代 Linux 使用 pin_user_pages_fast() 锁定用户页。该函数会遍历用户页表,将涉及的物理页全部找到并增加引用计数,使页面在 I/O 完成之前无法被回收或迁移,用链如下:
iomap_dio_rw() └─ bio_iov_iter_get_pages() └─ pin_user_pages_fast()
执行完成后,内核获得一组 struct page 指针数组。后续 BIO 构建阶段不会再关心用户虚拟地址,而是直接使用这些物理页描述数据区域。从实现角度来看,Direct I/O 的核心并不是绕过内核,而是把用户虚拟内存转换成可供块设备访问的物理页集合。随着 NVMe 和高速网络存储的发展,pin_user_pages() 的性能开销越来越受到关注,因此 io_uring 提供了固定缓冲区机制,通过预注册页面减少频繁 Pin Page 带来的开销。
第五章 BIO 构建机制
5.1 Direct I/O 如何组织数据
完成用户页锁定之后,内核获得了一组 struct page 指针,但块层并不认识 struct page,它需要一种能够描述磁盘读写请求的数据结构。Linux 块层使用 BIO(Block I/O)完成这一工作。BIO 是块设备层最核心的数据结构之一,它负责描述本次 I/O 涉及哪些页面、对应哪些磁盘扇区以及需要执行什么类型的操作。无论是 Buffered I/O 最终触发的回写请求,还是 Direct I/O 直接提交的读写请求,最终都会转换为 BIO 并进入块层处理。
BIO 本质上是文件系统与块设备之间的桥梁。文件系统负责解决逻辑文件与物理块映射关系,而块层负责把这些物理块组织成磁盘请求。对于 Direct I/O 来说,由于没有 Page Cache 参与,因此 BIO 中描述的页面直接来自用户空间锁定页,而不是缓存页。这也是 Direct I/O 与 Buffered I/O 最大的区别之一。Buffered I/O 中 BIO 描述的是 Page Cache 页面,而 Direct I/O 中 BIO 描述的是用户空间页面。
5.2 bio_vec 与物理页映射
BIO 内部通过 bio_vec 描述具体数据区域。每个 bio_vec 对应一段物理页空间:
struct bio_vec{ struct page *bv_page; unsigned int bv_len; unsigned int bv_offset;};
其中 bv_page 指向实际物理页,bv_len 表示数据长度,bv_offset 表示页内偏移。当一个 Direct I/O 请求跨越多个页面时,内核会生成多个 bio_vec,并将它们组织到同一个 BIO 中。例如一个 64KB 写请求可能对应 16 个连续页面,那么 BIO 中就会存在 16 个 bio_vec 条目。块层不关心这些页面来自用户空间还是缓存页,只关心它们对应的物理地址和长度。
BIO 构建完成后,文件系统已经完成了自己的主要任务。后续工作全部交给块层处理。从架构角度看,Linux 存储栈的分层设计非常清晰:VFS 管理文件接口,文件系统管理逻辑块映射,BIO 管理数据组织,块层管理请求调度,驱动负责访问设备。Direct I/O 只是绕过了 Page Cache,并没有绕过这些核心层次。
第六章 iomap 与块层执行流程
6.1 iomap 为什么取代 direct-io.c
早期 Linux Direct I/O 实现位于 fs/direct-io.c 中,各个文件系统需要编写大量适配代码。随着 ext4、XFS、F2FS 等文件系统不断发展,Direct I/O 代码逐渐出现大量重复逻辑,维护成本越来越高。为了解决这一问题,Linux 引入 iomap 框架,将块映射和 Direct I/O 通用逻辑统一管理。目前 ext4、XFS 等主流文件系统的 Direct I/O 基本都建立在 iomap 基础之上,现代 ext4 Direct I/O 调用链通常如下:
ext4_file_write_iter() └─ ext4_dio_write_iter() └─ iomap_dio_rw()
iomap_dio_rw() 成为整个 Direct I/O 路径的核心入口。它负责查询文件逻辑块对应的物理块位置、构建 BIO、管理页面锁定以及处理异步完成通知。这样文件系统只需要提供块映射关系,而不必关心 BIO 构建和提交细节,大幅降低了实现复杂度。
6.2 逻辑块到物理块映射
文件系统看到的是文件偏移,而磁盘驱动看到的是物理扇区,因此 Direct I/O 在提交 BIO 之前必须完成逻辑块映射。例如应用程序写入文件偏移 128KB 的位置,文件系统需要查询 inode 中的 extent 信息,找到对应物理块位置,然后将 BIO 指向正确的磁盘区域,以 ext4 extent 为例:
File Offset 128KB │ ▼Logical Block 32 │ ▼Physical Block 102400
当 iomap 获得映射关系后,就可以将用户页组织成 BIO,并填写目标扇区号。这里实际上完成了从文件语义向块设备语义的转换。对于 Direct I/O 而言,这一步尤为关键,因为没有 Page Cache 可以作为缓冲层,一旦映射错误,数据将直接写入错误磁盘区域。因此 ext4、XFS 等文件系统在 DIO 路径中都会严格检查块映射状态和文件边界条件。
第七章 块层提交与驱动执行
7.1 submit_bio 到 blk-mq
BIO 构建完成后,文件系统会调用 submit_bio() 将请求提交到块层。现代 Linux 使用 blk-mq(Multi Queue Block Layer)管理存储请求,它取代了早期单队列块层架构,能够充分利用多核 CPU 和高速 SSD 性能,调用链如下:
submit_bio() └─ blk_mq_submit_bio() └─ blk_mq_sched_insert_request() └─ queue_rq()
在这里,BIO 会被转换成 Request 对象,并放入对应硬件队列。对于机械硬盘,调度器可能会重新排序请求以减少磁头寻道;对于 NVMe SSD,则通常直接下发到硬件队列。Direct I/O 到这里已经与 Buffered I/O 没有区别,因为无论数据来自 Page Cache 还是用户页,块层最终处理的都是标准 BIO 请求。
7.2 驱动与 DMA 数据传输
请求进入驱动后,驱动程序根据 BIO 中记录的物理页地址建立 DMA 映射。对于 NVMe 驱动来说,会构建 PRP(Physical Region Page)列表并通知控制器开始传输;对于 AHCI/SATA 驱动,则会构建对应的 DMA 描述符表。设备获得这些物理地址后,即可直接访问内存中的数据区域,执行流程如下:
submit_bio() │ ▼blk-mq │ ▼NVMe Driver │ ▼DMA Engine │ ▼SSD
这里的数据已经完全绕过 Page Cache。DMA 控制器直接访问用户缓冲区对应物理页,并将数据写入 SSD。当设备完成传输后触发中断,驱动通知块层请求完成,块层释放 BIO,文件系统释放页面引用,最终用户态 write() 返回成功。整个过程中最大的特点就是没有缓存页参与,因此 CPU 开销显著低于 Buffered I/O。
第八章 Direct I/O 的对齐限制
8.1 为什么必须对齐
Direct I/O 最大的使用门槛就是严格的对齐要求。由于数据最终需要直接转换成 BIO 并交给 DMA 引擎访问,因此用户缓冲区地址、文件偏移以及数据长度都必须满足设备和文件系统要求。如果这些条件不满足,内核无法建立正确的块映射关系,也无法保证 DMA 访问合法性,例如下面代码:
char *buf = malloc(4096);write(fd, buf + 1, 4096);
虽然长度满足 4KB,但缓冲区地址没有对齐,很多文件系统会直接返回 EINVAL。同样,如果文件偏移不是块大小整数倍,或者长度不是块大小整数倍,也可能导致 Direct I/O 失败。因此数据库通常会采用专门内存分配接口确保对齐。
8.2 正确的内存分配方式
Linux 提供 posix_memalign() 用于申请对齐缓冲区:
void *buf;posix_memalign( &buf, 4096, 4096 * 16);
这里申请的内存地址保证按 4096 字节对齐,可以直接用于 O_DIRECT 读写。实际工程中,4KB 是最常见选择,因为大多数文件系统和 SSD 都采用 4KB 作为基本块大小。对于部分 RAID 阵列或者特殊存储设备,甚至可能要求更大的对齐粒度,因此数据库启动时通常会主动探测设备参数,确保后续所有 Direct I/O 请求都满足要求。
第九章 Direct I/O 与 Buffered I/O 混用问题
9.1 缓存一致性风险
很多开发人员认为同一个文件既可以使用 Buffered I/O,又可以使用 Direct I/O,但实际情况远比想象复杂。假设一个进程通过 Buffered I/O 将文件数据缓存到 Page Cache,而另一个进程通过 O_DIRECT 修改了相同文件内容,此时 Page Cache 中仍然保存旧数据。如果内核不进行额外处理,后续读取可能获得过期内容。
因此 Linux 在 Direct I/O 写入时通常需要执行缓存失效操作:
invalidate_inode_pages2_range(...)
其作用是删除相关 Page Cache 页面,避免旧缓存继续被访问。这一步虽然保证了一致性,但也会带来额外开销。因此对于数据库而言,通常会彻底选择 Direct I/O 或彻底选择 Buffered I/O,而不是混合使用。
9.2 数据库为什么偏爱 O_DIRECT
数据库最大的特点是拥有自己的缓存体系。例如 MySQL InnoDB Buffer Pool 本身就承担数据缓存功能。如果再启用 Linux Page Cache,那么相同数据会同时存在两套缓存中,不但浪费内存,还会增加缓存同步复杂度。因此许多数据库默认推荐启用 O_DIRECT。
对于大型 OLTP 系统而言,Direct I/O 最大优势不是提高单次 I/O 性能,而是避免缓存污染和内存浪费。数据库希望完全掌控缓存策略,而不是同时接受 Linux Page Cache 管理。正因为如此,O_DIRECT 在数据库领域应用极其广泛,而在普通业务程序中则相对少见。
现代 Linux Direct I/O 的完整路径:
Userspace │ ▼write() │ ▼VFS │ ▼ext4_dio_write_iter() │ ▼iomap_dio_rw() │ ▼pin_user_pages_fast() │ ▼BIO │ ▼submit_bio() │ ▼blk-mq │ ▼NVMe Driver │ ▼DMA │ ▼SSD
整个过程中最核心的三个对象分别是 struct file、struct page、struct bio。其中 struct file 决定是否进入 Direct I/O 路径,struct page 描述用户空间锁定页,struct bio 描述最终块设备请求。相比 Buffered I/O 围绕 Page Cache 展开,Direct I/O 的核心思想是将用户页直接转换为 BIO 并提交给块层,通过 DMA 完成数据传输,从而减少缓存管理和数据复制开销。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
