Python常用数据结构(列表、字符串、集合、字典以及元组)讲解(超详细)
- 2026-06-15 01:33:23
该篇,讲了Python数据结构中用到的【字符串】、【列表】、【元组】、【集合】以及【字典】这五种数据类型在Python中扮演的角色,讲了它们在Python中的概念、方法,希望该文章能够帮助到你解决在编程中遇到的问题。下面就让我们开启学习之路吧!

一、列表
1、概念
List(列表)是Python中使用最频繁的数据类型。列表是由一系元素按特定顺序构成的数据序列,这就意味着如果我们定义一个列表类型的变量,可以用它来报错多个数据。 列表可以完成大多数集合类的数据结构,列表中元素的类型可以不相同,它支持数字、字符串甚至可以包含列表(也就是所谓的嵌套)。列表是写在方括号[]之间,用逗号,隔开的元素列表。和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。 列表截取的语法格式如下:
变量[头下标 : 尾下标]
索引值以0为开始值,-1为末尾的开始位置。 同样的,加号
同样的,加号+是列表连接运算符,星号*是重复操作:
2、具体的实例(优化见遍历列表)
小试牛刀:将一个色子掷7000次,统计每种点数出现的次数;
import randoma1 = 0a2 = 0a3 = 0a4 = 0a5 = 0a6 = 0for i inrange(7000): face = random.randrange(1, 7)if face == 1: a1 += 1elif face == 2: a2 += 1elif face == 3: a3 += 1elif face == 4: a4 += 1elif face == 5: a5 += 1elif face == 6: a6 += 1else:print("你越界了!!")pass# 打印出现的次数print(f"点数1出现的次数:{a1}。")print(f"点数2出现的次数:{a2}。")print(f"点数3出现的次数:{a3}。")print(f"点数4出现的次数:{a4}。")print(f"点数5出现的次数:{a5}。")print(f"点数6出现的次数:{a6}。")运行结果:
点数1出现的次数:1151。
点数2出现的次数:1152。
点数3出现的次数:1169。
点数4出现的次数:1183。
点数5出现的次数:1140。
点数6出现的次数:1205。
上面的代码,看起来,最后的结果也确实实现出来了,但是分支用的太多,麻烦、冗余。我们有一种更好的方法来优化上面的代码,也就是用这里的列表来实现。在Python中,我们可以使用容器型变量来保存和操作多个数据,也就是这里的列表(List):Python中的列表,它的长度和列表元素都是可以改变的。
3、访问列表
注意:
- 访问列表中的值
:它与字符串的索引是一样的,即从 0开始,第二个索引是1,依此类推;而列表中的最后一个字符串的索引为-1,往前一个是-2,也是依此类推的,如下图:
- 使用索引进行截取列表
[],如下图: 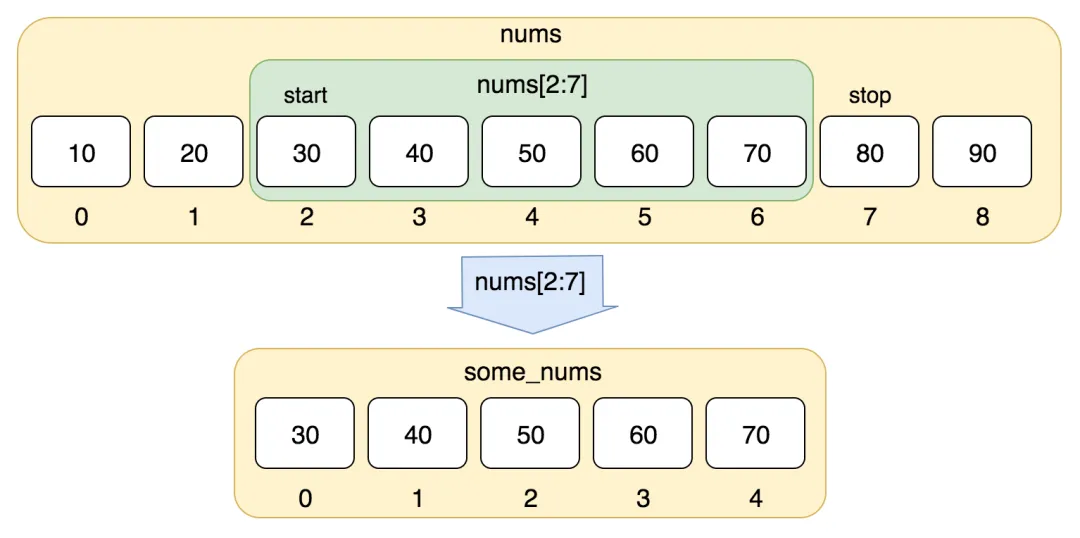
4、列表的方法
4.1 更新列表
我们可以对列表中的数据项进行修改或者更新,也可以使用append()来添加列表项,如下所示:
"""更新列表"""lists = ['Google', 'Alice', 'cn.bing.com', 'www.baidu.com', 'www.bilibili.com', 'Stock', '小明']# 打印这个列表print(f"这个列表数据项为:{lists}。")# 打印最后一个列表数据项print(f"列表lists中,最后一个数据项为{lists[-1]}。")# 替换列表中,最后一个元素 '小明' 将其替换为 'Yuer'lists[-1] = 'Yuer'# 打印替换后的最后一个元素print(f"列表lists替换后的,最后一个数据项为{lists[-1]}。")# 截取列表 listss = list[2 : 5]strList = lists[2:len(lists) - 3]# 打印出截取到的列表print(f"截取到的列表数据项为:{strList}。")# 向列表中添加一个元素 '大明'lists.append('大明')# 输出添加的列表数据项print(f"添加的列表数据项为:{lists[-1]}")print(f"经过更新后,这个列表中的数据项为{lists}")运行结果:
这个列表数据项为:['Google', 'Alice', 'cn.bing.com', 'www.baidu.com', 'www.bilibili.com', 'Stock', '小明']。
列表lists中,最后一个数据项为小明。
列表lists替换后的,最后一个数据项为Yuer。
截取到的列表数据项为:['cn.bing.com', 'www.baidu.com']。
添加的列表数据项为:大明
经过更新后,这个列表中的数据项为['Google', 'Alice', 'cn.bing.com', 'www.baidu.com', 'www.bilibili.com', 'Stock', 'Yuer', '大明']
5、列表的运算
我们可以使用+运算符来实现两个列表的拼接,拼接运算会将两个列表中的元素连接在一起,放到一个列表中,同理,使用*号也是同样的效果,如下:
"""列表的运算 —— +号"""aa = [1, 11, 12, 13, 14, 15]bb = [3, 11, 45, 67, 98, 12]cc = ['Python', 'Java', 'C++', 'JavaScript']# 拼接运算dd = aa + bb + ccprint(f"拼接后的列表为:{dd}。")"""使用 * 号代码重复运算"""ee = cc * 2print(f"使用*号的运算结果:{ee}")运算结果:
拼接后的列表为:[1, 11, 12, 13, 14, 15, 3, 11, 45, 67, 98, 12, 'Python', 'Java', 'C++', 'JavaScript']。
使用*号的运算结果:['Python', 'Java', 'C++', 'JavaScript', 'Python', 'Java', 'C++', 'JavaScript']
使用列表切片来提取子列表数据项:列表切片是一种非常强大的功能,它运行你从一个列表中提取一部分元素进而新成新的子列表。切片操作使用方括号
[]和冒号:来指定起始索引、结束索引以及步长。如下图:
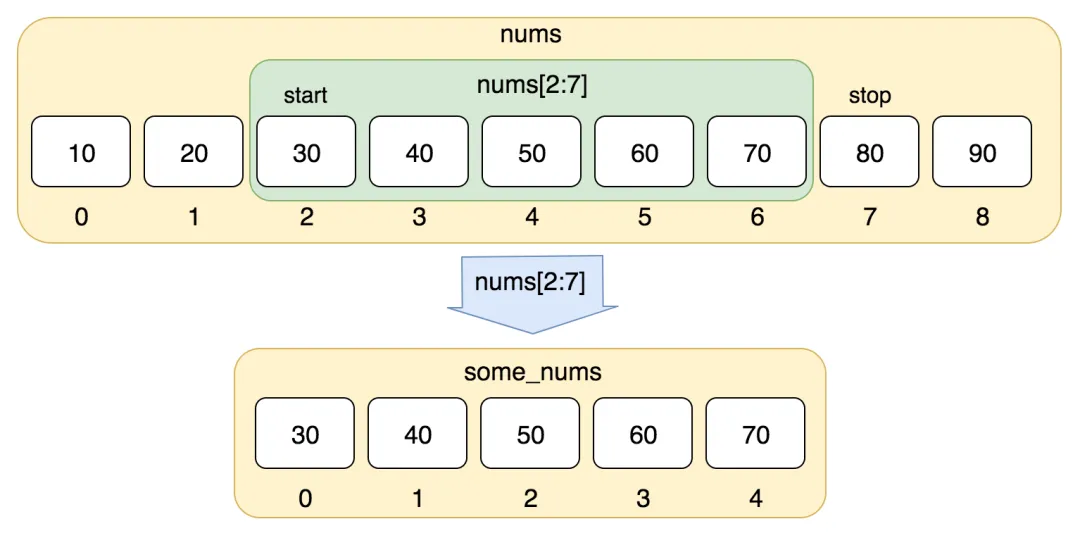
"""列表的运算 —— +号"""aa = [1, 11, 12, 13, 14, 15]bb = [3, 11, 45, 67, 98, 12]cc = ['Python', 'Java', 'C++', 'JavaScript']# 拼接运算dd = aa + bb + ccprint(f"拼接后的列表为:{dd}。")"""使用 * 号代码重复运算"""ee = cc * 2print(f"使用*号的运算结果:{ee}")"""切片提取列表数据项形成新的子列表"""nums = [10, 20, 30, 40, 50, 60, 70, 80, 90]# 使用切片来对nums进行切割形成新的子列表num1 = nums[2:7]print('使用切片后获取到的子列表为:', num1)输出结果:
拼接后的列表为:[1, 11, 12, 13, 14, 15, 3, 11, 45, 67, 98, 12, 'Python', 'Java', 'C++', 'JavaScript']。
使用*号的运算结果:['Python', 'Java', 'C++', 'JavaScript', 'Python', 'Java', 'C++', 'JavaScript']
使用切片后获取到的子列表为: [30, 40, 50, 60, 70]
语法:
切片运算是形如
[start:end:stride]的运算符,其中start代表访问列表元素的起始位置,end代表访问列表元素的终止位置(终止位置的元素无法访问),而stride则代表了跨度,简单的说就是位置的增量,比如我们访问的第一个元素在start位置,那么第二个元素就在start + stride位置,当然start + stride要小于end。
如果
start值等于0,那么在使用切片运算符时可以将其省略;如果end值等于N,N代表列表元素的个数,那么在使用切片运算符时可以将其省略;如果stride值等于1,那么在使用切片运算符时也可以将其省略。
- 通过切片来更改列表数据项:如下
# 操作切片来修改列表中的数据项# 操作切片来修改列表中的数据项dd1 = [1, 13, 3, 67, 'Python']dd1[1: 3: 1] = ['C#', 'C++'] # 如果通过切片来更新列表中的数据,若给定的切片数据项个数小于切片的结束位置减去开始位置,那么缺失的数据由原列表的数据补上,如输出结果print(f"输出经过使用切片修改后的列表数据项:{dd1}。")输出结果:
输出经过使用切片修改后的列表数据项:[1, 'C#', 'C++', 67, 'Python']。
- 列表之间还可以做关系运算:我们可以比较两个列表是否相等,也可以给两个列表比较大小,如下:
"""列表做关系运算"""a = [1, 3, 7, 89]b = [4, 9, 20]print(a == b) #Falseprint(a != b) #Trueprint(a > b) #False上面的
a和b对应的元素完全不相等,索引进行==运算的结果为False;进行!=运算后的结果为True;而进行>运算的结果为False。大小关系通常比较的是第一个元素,所以才会出现,进行a > b的运算后,结果为False。
6、遍历列表
在Python中,for循环是一种常见的遍历列表的方式,通过for循环,我们可以一次访问列表中的每一个元素,并对其进行操作。
c = ['Python', 'Java', 'C++', 'JavaScript']for i in c:print(i)代码解析:
1、
c = ['Python', 'Java', 'C++', 'JavaScript']:定义了一个包含三个元素的列表c;2、
for i in c::使用for循环遍历列表c,每次循环将列表中的一个数据项赋值给变量i。3、
print(i),在每次循环中,打印当前i的值;
输出结果:
Python
Java
C++
JavaScript
上面的掷色子就可以优化了,优化如下:
import randomcount = [0] * 6print(count)# 循环7000次for a inrange(7000):# face用来记录,出现1到7出现的点数 face = random.randrange(1, 7)# 利用索引每次循环就对对应的点数加一,即将循环后的索引对应的列表数据项进行更新 count[face - 1] += 1# 再对1到7生成的点数进行循环,即获取列表count中的列表数据项for face inrange(1, 7):print(f"点数{face}出现的次数为{count[face - 1]}。")运行结果:
点数1出现的次数为1210。
点数2出现的次数为1175。
点数3出现的次数为1160。
点数4出现的次数为1161。
点数5出现的次数为1179。
点数6出现的次数为1115。
上面使用用random模块来实现,统计抛掷骰子的次数,其中方法randrange()是指定随机生成的数的范围;以下是random模块中的方法: random 模块方法如下(仅供参考,当做字典来用):
7、Python中的列表方法
下面是列表中常见的方法:
7.1 append()方法
在末尾追加一个元素
# 定义一个lists列表 lists = ['Python', 'C++', 'Java']# 在列表末尾添加一个列表数据项lists.append('JavaScipt')# 得到列表List的数据项print(lists)输出结果: ['Python', 'C++', 'Java', 'JavaScipt']
7.2 extend(iterable)方法
将可迭代对象(如列表、元组、字符串)的元素逐个添加到列表的末尾。参数:iterable指的是可迭代对象;
"""可迭代对象:逐个添加到列表末尾"""aa = ['2', '5']bb = ['1', '9']aa.extend(bb)aa.extend('Python')print(aa)运行结果: ['2', '5', '1', '9', 'P', 'y', 't', 'h', 'o', 'n']
7.3 insert(index, element)方法
在指定索引位置插入元素,原位置及后续元素右移;index:插入位置的索引;element:要插入的元素;
dd = ['Python', 'C++', 'Java']dd.insert(3, 'C++')# 索引超出范围时,插入末尾dd.insert(9, 'C#')dd.insert(0, 'JavaScript')print(dd)运行结果: ['JavaScript', 'Python', 'C++', 'Java', 'C++', 'C#']
7.4 remove(element)方法
删除列表中第一个匹配的元素;element:要删除的元素;注意:若元素不存在,抛出ValueError。
ee = ['2', '56', '90', 'Python']ee.remove('Python')print(ee)try: ee.remove('JavaScript')except ValueError:print(f'列表中没有这个数据项!!')运行结果: ['2', '56', '90'] 列表中没有这个数据项!!
7.5 pop([index])方法
删除并返回指定索引的元素(默认删除最后一个元素);index:可选,默认-1;返回的值是被删除的元素;注意:索引越界时抛出IndexError。
"""删除并返回指定索引的元素""""""删除并返回指定索引的元素"""ff = ['Python', 'C++', 'JavaScript']cc = ff.pop(0)print(cc)try: dd = ff.pop(8)except IndexError:print("列表中没得这个数据项!!")运行结果: Python 列表中没得这个数据项!!
6、 clear():清空列表,移除所有元素,返回值为None;
cc = ['1', '9', 'Python']print(cc.clear())输出结果: None
7.6 index(element, start, end)方法
返回元素第一次出现的索引;element:要查找的元素;start和end(可选,指定搜索的范围);返回的值是索引值(int);注意:元素不存在时抛出ValueError。
"""返回元素第一次出现的位置,即索引"""gg = ['Python', 'C++', 'JavaScript']gg.append('Python')gg.insert(7, 'C++')print(gg.index('C++'))print(gg.index('C++',2))运行结果: 1 4
7.7 count(element)方法
统计元素在列表中出现的次数;element:要统计的元素,返回的值是次数(int);
"""统计指定元素在列表中出现的次数"""gg = ['Python', 'C++', 'JavaScript', 'C++', 'C#', 'C++']print(gg.count('C++'))运行结果:3
7.8 sort(key = None, reverse = False)方法
排序列表(默认升序)且是永久性的排序,reverse:排序规则,reverse = True表示降序,reverse = False表示升序(默认);该方法没有返回值,但是会对这个列表内的数据项进行排序;
"""sort函数的使用"""a = ['Python', 'C++', 'JavaScript', 'C++', 'C#', 'C++']b = [2, 5, 10, 23, 4, 1, 6, 9, 21]c = [1, 4, 'Python']# 对列表a内的数据项进行排序a.sort()print(a)# 对列表b内的元素进行排序b.sort()print(b)# 对列表c进行排序c.sort()print(c)运行结果: ['C#', 'C++', 'C++', 'C++', 'JavaScript', 'Python'] [1, 2, 4, 5, 6, 9, 10, 21, 23]
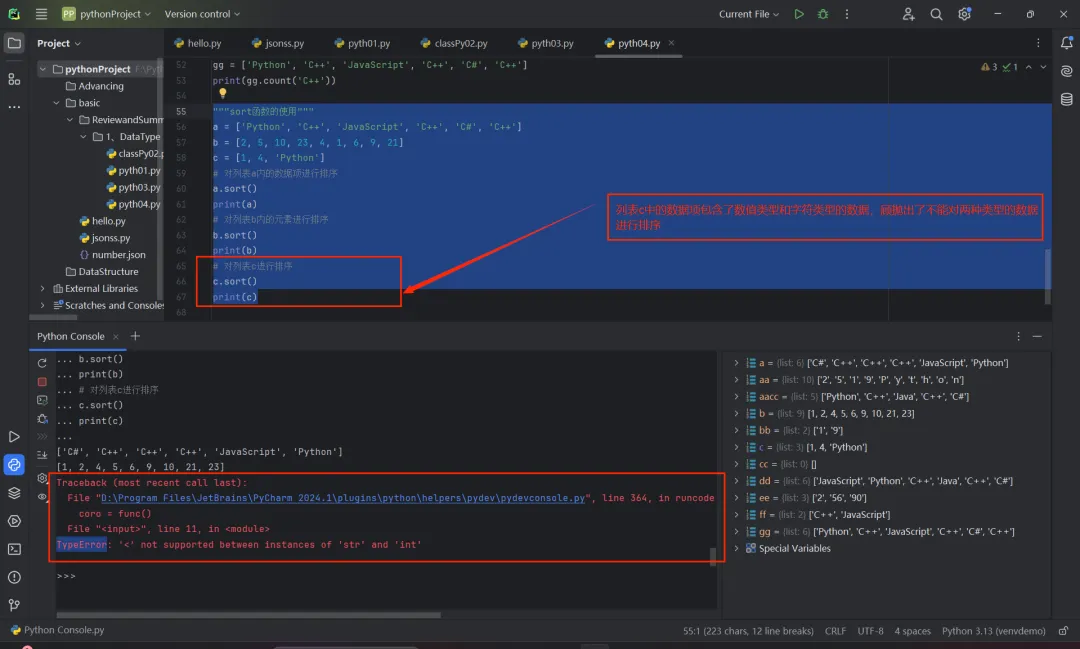
7.9 reverse()方法
反转列表元素的顺序,返回的值为None;
"""反正列表数据项"""b = [2, 5, 10, 23, 4, 1, 6, 9, 21]c = [1, 4, 'Python']b.reverse()c.reverse()print(b)print(c)运行结果: [21, 9, 6, 1, 4, 23, 10, 5, 2] ['Python', 4, 1]
7.10 copy()方法
返回列表的浅拷贝,返回的值是一个新列表(列表数据项与原列表相同);
解释浅拷贝:
定义列表 a:
a = ['C++', 'JavaScript', 'C', 'JavaScript', [2, 5, 23, 41]]这里创建了一个包含四个字符串和一个整数列表的列表
a。创建 b 作为 a 的浅拷贝:
b = a.copy()使用
copy()方法创建b,使其成为a的浅拷贝。这意味着b包含与a相同的元素,但它们共享相同的嵌套列表引用。打印 a 和 b:
print(a)print(b)此时,
a和b的输出会相同,因为它们的顶层元素相同,包括嵌套列表。修改 a 的第一个元素:
a[0] = 99修改
a的第一个字符串元素为 99。由于b是a的浅拷贝,修改a的元素不会直接影响b。修改 a 的最后一个嵌套列表:
a[4].append(100)嵌套列表
a[4]被添加了元素 100。由于b中的a[4]引用的是同一个列表对象,因此b[4]也会包含 100。再次打印 a 和 b:
print(a)print(b)打印后,
a和b都显示最后一个元素为[2, 5, 23, 41, 100],因为修改a[4]也影响了b[4]。
总结:这段代码展示了列表赋值的浅拷贝行为,特别是当列表包含其他可变对象(如列表)时,修改原列表会影响所有共享的可变对象。
8、列表生成式
在Python中,列表还可以通过一些特殊的字面量语法来创建,也就是【生成式】,它允许我们以简洁和高效的方式创建列表。下面的是一些列子来说明使用列表生成式,有啥好处;
8.1、生成平方数列表
传统方式:
# 定义一个空的列表squares = []for i inrange(1,8): squares.append(i ** 2)print(squares) # 输出:[1, 4, 9, 16, 25, 36, 49]汉字解释:
定义一个空列表 squares;使用 for循环来遍历这个左闭右开的整数序列;最后使用函数 append()来将这个运算结果i ** 2追加到列表squares中;
使用生成式:
# 使用生成式squares = [i ** 2for i inrange(1, 8)]print(squares) # 输出:[1, 4, 9, 16, 25, 36, 49]汉字解释:
使用 for循环遍历range(1,8)(生成1到8的数字);对每个数字 i,计算其平方i**2;将所有平方结果存储在 squares列表中;
对比:
列表生成式将传统 for和append相结合,代码更加简洁;列表生成式直接计算所有平方,而传统方式,需要每次迭代调用 append;列表生成式更高效,因为它利用了内置函数的优化;
8.2 生成奇数列表
传统方式:
# for循环和if的运用a = []for i inrange(1, 8):if i % 2 != 0: a.append(i)print(a)# 运行结果:[1, 3, 5, 7]- 汉字解释:
1、初始化空列表:a = []创建一个空列表用于存储奇数;
2、遍历整数序列range(1, 8):range(1, 8)生成[1, 2, 3, 4, 5, 6, 7]的整数序列;
3、条件判断if i % 2 != 0:如果等于零,则说明是偶数,不将i添加到空列表a中;
4、添加元素:符合条件的数通过append()方法加入列表a中;
5、输出列表a中的数据项:最终列表为[1, 3, 5, 7];
列表生成式(更高效简洁):
- 语法生成式:
[表达式 for 变量 in 可迭代对象 if 条件][expression for item in iterable if condition]- 语法解释: 1、
expression:表达式; 2、item:变量; 3、iterable:可迭代对象; 4、condition:条件; - 代码呈现:
""" 列表生成式"""a = [x for x inrange(1, 8) if x % 2 != 0]print(a)"""运行结果:[1, 3, 5, 7]"""- 列表生成式汉字解释:
1、在 for循环后加if x % 2 != 0,自动过滤奇数;2、好处:逻辑相对而言,减少缩进层级;
8.3 嵌套循环(多层for)
生成二维坐标列表的例子:
传统方式:
"""嵌套循环(多层for循环)"""a = []for i inrange(1, 8):for j inrange(1, 8):if (i + j) % 2 == 0: a.append((i, j))print(a)"""运行结果:[(1, 1), (1, 3), (1, 5), (1, 7), (2, 2), (2, 4), (2, 6), (3, 1), (3, 3), (3, 5), (3, 7), (4, 2), (4, 4), (4, 6), (5, 1), (5, 3), (5, 5), (5, 7), (6, 2), (6, 4), (6, 6), (7, 1), (7, 3), (7, 5), (7, 7)]"""- 汉字解释:
结构特点: 显式的多层 for循环,通过控制缩进控制层级,然后使用方法append()追加元素;核心步骤: (1)、初始化空列表 a;(2)、外层循环遍历第一个可迭代对象; (3)、内存循环遍历第二个可迭代对象; (4)、条件判断后追加元素;
列表生成式:
"""列表生成式"""a = [ (i, j)for i inrange(1, 8)for j inrange(1, 8)if (i + j) % 2 == 0]print(a)"""运行结果:[(1, 1), (1, 3), (1, 5), (1, 7), (2, 2), (2, 4), (2, 6), (3, 1), (3, 3), (3, 5), (3, 7), (4, 2), (4, 4), (4, 6), (5, 1), (5, 3), (5, 5), (5, 7), (6, 2), (6, 4), (6, 6), (7, 1), (7, 3), (7, 5), (7, 7)]"""- 汉字解释:
结构特点: 隐式嵌套,循环顺序与书写顺序一致(外层 ——> 内层),if条件直接过滤元素。核心语法:
[元素表达式for 外层循环 in 外层可迭代对象for 内层循环 in 内层可迭代对象if 条件]- 性能与可读性对比:
- 列表生成式适用场景:
1、简单数据生成: 如生成矩阵、坐标、笛卡尔积等结构化的数据;2、快速过滤数据:结合条件语句筛选嵌套结构中的元素; 3、代码简洁性优先的场景:需要快速实现且逻辑简单时使用;
- 传统嵌套循环适合:
1、复杂逻辑处理:如需要中间变量、循环内外混合操作;
"""处理多层列表"""b = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]# 将列表b中的元素,是偶数的挑选出来# 定义一个空列表c = []for i in b: temp = []for j in i:if j % 2 == 0: temp.append(j) c.append(temp)print(c)# 运行结果:[[2], [4, 6], [8]]2、调试要求高:需要逐步检查循环中的变量状态时;
3、多层循环嵌套(3层以上):生成式多层嵌套循环可读性差,传统循环更加清晰;
"""列表生成式:生成四维坐标"""d = [ (x, y, z, j)for x inrange(1,3)for y inrange(1,3)for z inrange(1,3)for j inrange(1,3)]print(d)"""传统方式"""d = []for x inrange(1,3):for y inrange(1,3):for z inrange(1,3):for j inrange(1,3): d.append((x, y, z, j))print(d)# 由比较可知,传统方式更具可读性- 输出完美的九九乘法表:
"""九九乘法表"""# 传统方式for i inrange(1,10):for j inrange(1, i+1):print(f"{j} * {i} = {i*j:2}", end = " ")print()**输出结果**:1 * 1 = 11 * 2 = 22 * 2 = 41 * 3 = 32 * 3 = 63 * 3 = 91 * 4 = 42 * 4 = 83 * 4 = 124 * 4 = 161 * 5 = 52 * 5 = 103 * 5 = 154 * 5 = 205 * 5 = 251 * 6 = 62 * 6 = 123 * 6 = 184 * 6 = 245 * 6 = 306 * 6 = 361 * 7 = 72 * 7 = 143 * 7 = 214 * 7 = 285 * 7 = 356 * 7 = 427 * 7 = 491 * 8 = 82 * 8 = 163 * 8 = 244 * 8 = 325 * 8 = 406 * 8 = 487 * 8 = 568 * 8 = 641 * 9 = 92 * 9 = 183 * 9 = 274 * 9 = 365 * 9 = 456 * 9 = 547 * 9 = 638 * 9 = 729 * 9 = 81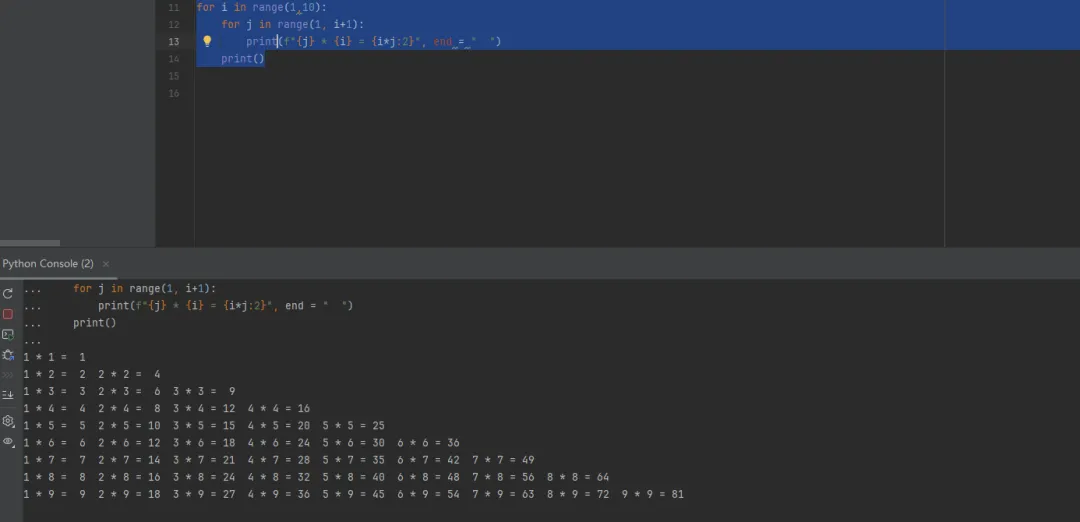
- 外层循环 (
i) for i in range(1, 10) 控制乘法表的行数变量 i表示乘法表中的第二个乘数(即"*"号后面的数字)范围1-9对应乘法表的9行 - 内层循环 (
j) for j in range(1, i + 1) 控制每行输出的列数变量 j表示乘法表中的第一个乘数(即"×"号前面的数字)每行的列数等于当前行号(第1行1列,第2行2列...第9行9列) - 格式化输出
j×i= 显示乘法表达式{i*j:2} 将乘积格式化为2位宽度,实现右对齐f"{j}*{i}={i*j:2}" 使用f-string格式化字符串end=" "指定每个乘法式后跟两个空格(不换行)- 换行控制
print()在内层循环结束后执行,实现每行输出后的换行
i*j:2】中的2是如下意思:{i*j:2}
│ │
│ └── 格式说明符:最小占 2 个字符宽度
└── 要格式化的值(乘法结果)
高级的写法:
"""高级的写法"""for i inrange(1, 10):# 列表生成式完成 row = [f"{j} x {i} = {i*j:3}"for j inrange(1, i + 1)]# 使用join来将每行的表达式用三个空格连接,确保末尾无多余的空格print(" ".join(row))语法解释:
1、外层循环(i):控制行数,从1到9;
2、内层循环(j):控制每行的列数,从1到当前行号i;
3、列表生成式:生成每行的所有乘法表达式,格式为j * i = 结果,使其结果右对齐三位(i * j : 3);
4、字符串拼接:使用join方法将每行的表达式用三个空格连接,确保对齐且无多余的空格;
5、打印输出:每生成一行立即打印,保持格式整齐;
9、列表的总结
1、Python列表方法主要用于动态修改、查询和操作列表。掌握这些方法可以高效处理列表数据。注意区分原地操作(如 sort())与非原地操作(如 sorted() 函数);
2、列表生成式与传统Python程序的写法对比,优缺点;
| 场景 | 传统方式 | 列表生成式 | 核心优势 |
|---|---|---|---|
forappend | [x for x in iterable] | ||
forif + append | [x for x in iterable if cond] | ||
for | [x for a in A for b in B] | ||
forappend | [s.upper() for s in strings] |

二、元组
1、元组的定义和运算
在Python语言中,元组也是多个元素按照一定顺序结果组成的序列,元组和列表的不同之处在于元组是不可变类型,这也就意味着元组的变量一旦定义后,其中的元素就不能再添加或删除,而且元素的值也不能被修改。如果尝试修改元组中的值,则会引发TypeError的错误,导致程序崩溃。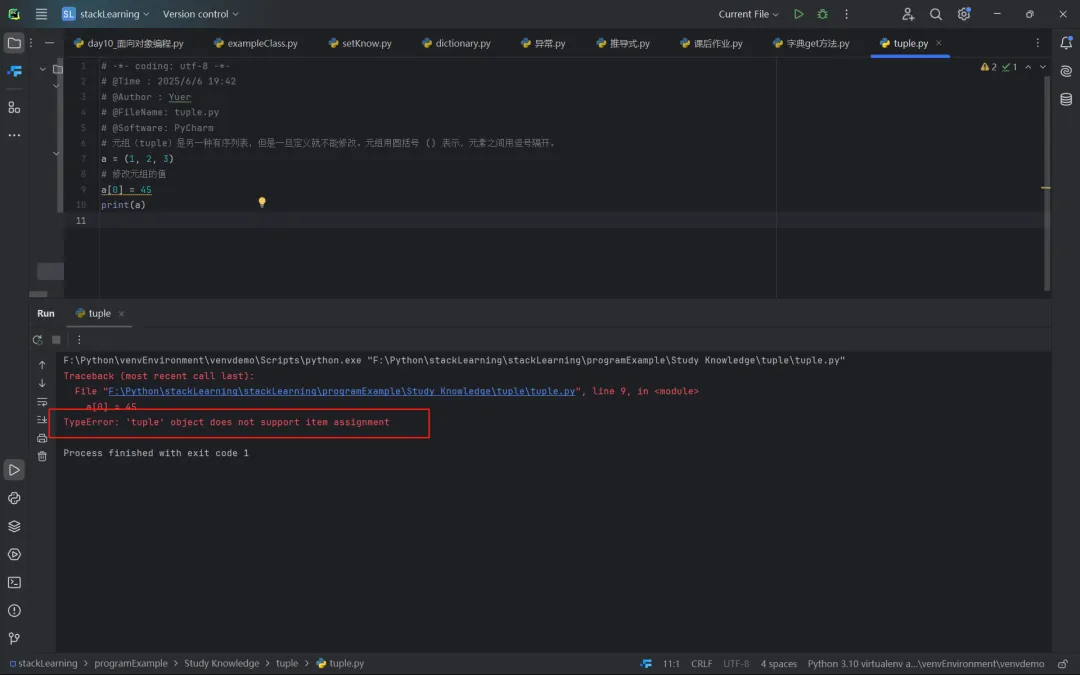
也就是,不能修改元组的值,如果修改就会发生报错,报TypeError: 'tuple' object does not support item assignment,简单来说,元组内的元素值不允许被修改。
1.1 定义元组
定义元组通常使用(x, y, z, ...)的字面量语法;元组内的元素可以使列表类型、字典类型、元组类型、数值类型以及集合类型,但是一旦被定义,就说明该元组内的元素不能被修改;
# 定义元组a = (1, 2, 3)b = ('小明', '小红', 56, {'name': '小刚'}, ['语文', '数学'], ('物理', '化学'), {'age', 26})print(a)print(b)1.2 元组的运算
元组的运算和集合的运算是一样的,如下:
1.2.1 连接元组
# 1. 连接元组c = a + bprint(c)# (1, 2, 3, '小明', '小红', 56, {'name': '小刚'}, ['语文', '数学'], ('物理', '化学'), {26, 'age'})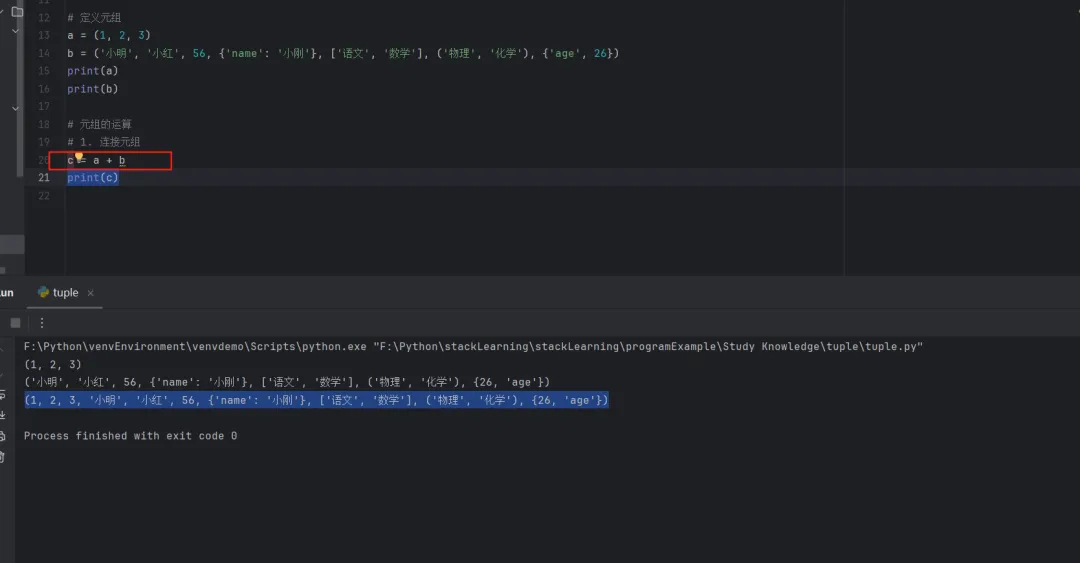
1.2.2 重复元组
# 2. 重复元组a = (1, 2, 3)d = a * 3print(d)# (1, 2, 3, 1, 2, 3, 1, 2, 3)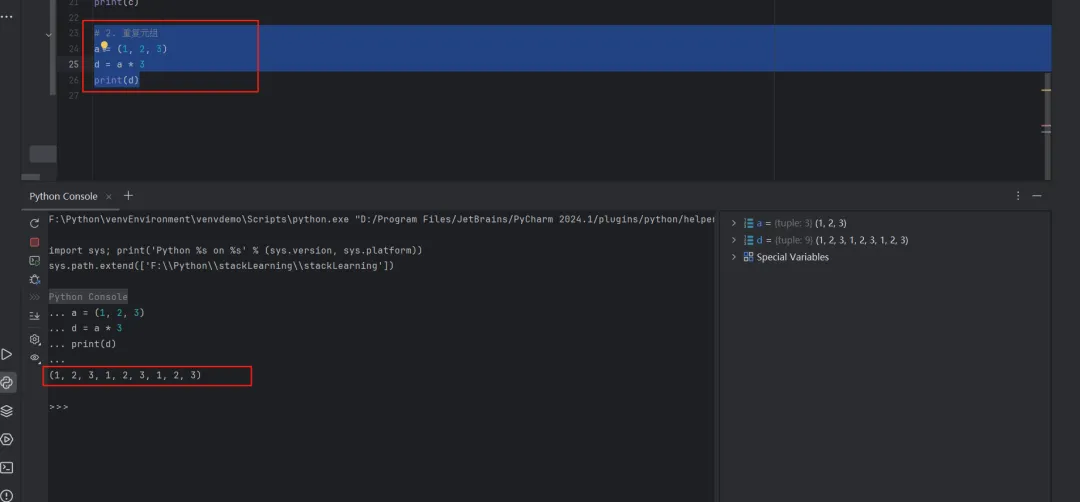
1.2.3 查看元组的类型
# 查看元组的类型a = (1, 2, 3)b = ('小明', '小红', 56, {'name': '小刚'}, ['语文', '数学'], ('物理', '化学'), {'age', 26})print(type(a))print(type(b))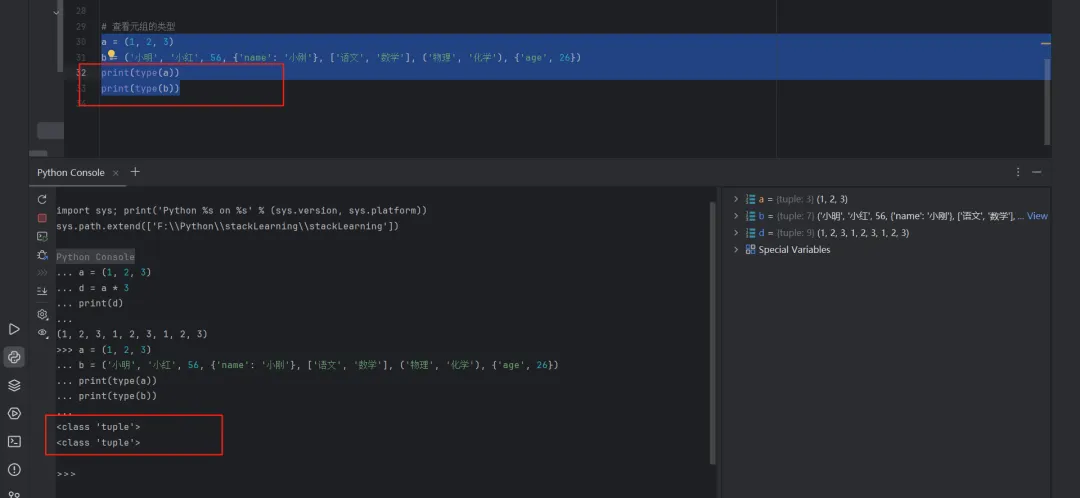
1.2.4 查看元组的数量
# 查看元组的数量a = (1, 2, 3)b = ('小明', '小红', 56, {'name': '小刚'}, ['语文', '数学'], ('物理', '化学'), {'age', 26})print(len(a))print(len(b))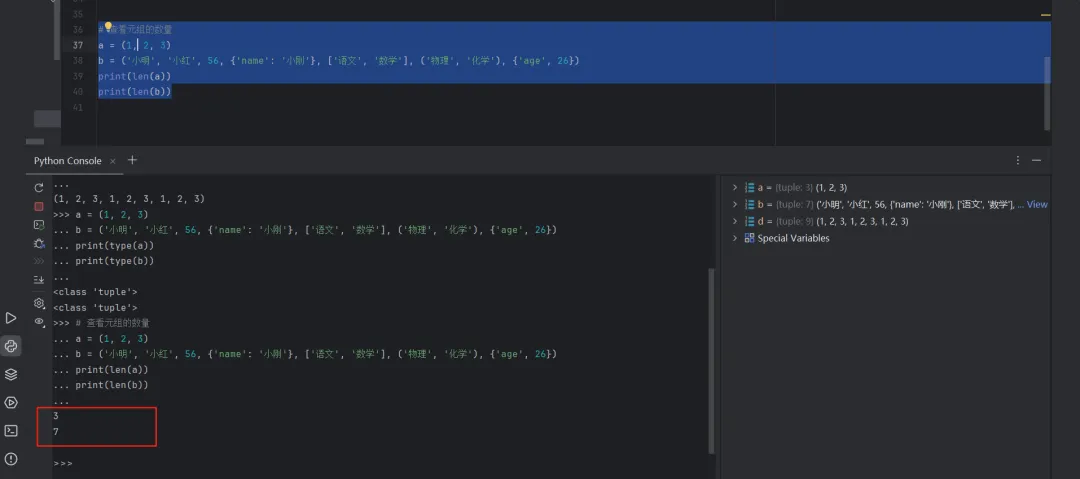
1.2.5 其他运算
# 查看元组的数量a = (1, 2, 3)b = ('小明', '小红', 56, {'name': '小刚'}, ['语文', '数学'], ('物理', '化学'), {'age', 26})print(len(a)) print(len(b))# 索引运算print(a[2]) # 3print(b[-1]) # {'age', 26}# 切片运算print(b[-2:]) # (('物理', '化学'), {26, 'age'})# 循环元组中的元素for i in b:print(i, end='\t') # 小明 小红 56 {'name': '小刚'} ['语文', '数学'] ('物理', '化学') {'age', 26}# 成元运算 结果返回的是布尔类型,也就是True或者Falseprint('\n', '小明'in b) # True# 比较运算print(a == b) # Falseprint(a >= (5, 4)) # False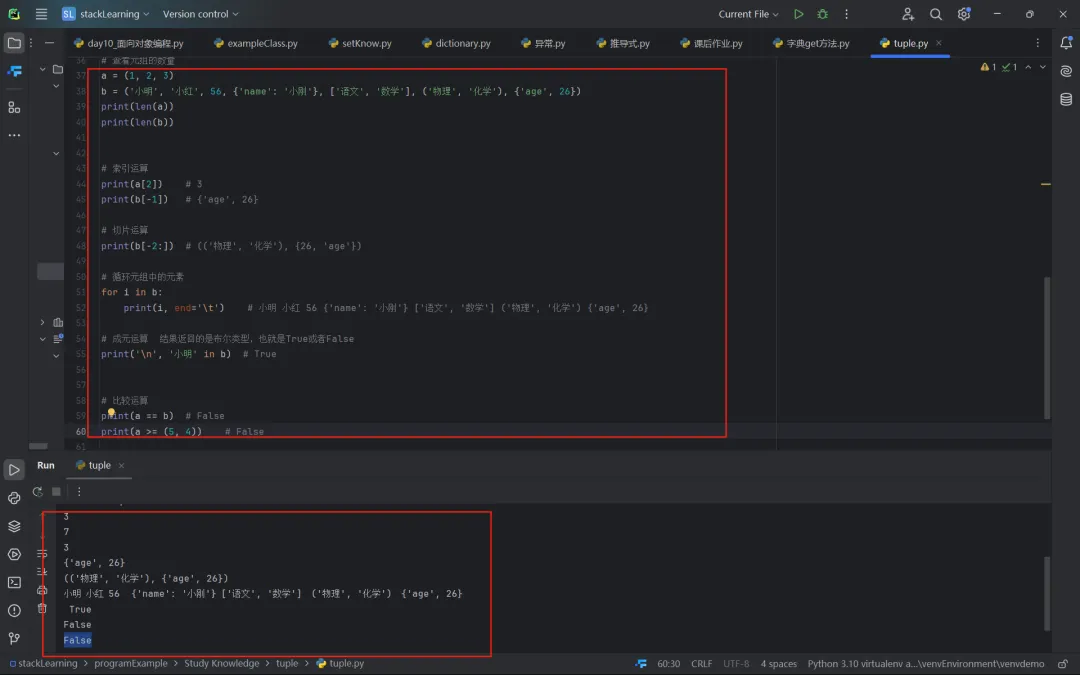
1.3 *元组
一个元组中如果有两个元素,我们就称之为二元组;一个元组中如果五个元素,我们就称之为五元组。需要提醒大家注意的是,()表示空元组,但是如果元组中只有一个元素,需要加上一个逗号,否则()就不是代表元组的字面量语法,而是改变运算优先级的圆括号,所以('hello', )和(100, )才是一元组,而('hello')和(100)只是字符串和整数。我们可以通过下面的代码来加以验证。
# *元组a = ()print(type(a))b = (1) # int类型c = ('hello') # str类型print(type(b), type(c)) # <class 'int'> <class'str'>d = ('hello', )print(type(d)) # <class 'tuple'>e = (299, )print(type(e)) # <class 'tuple'>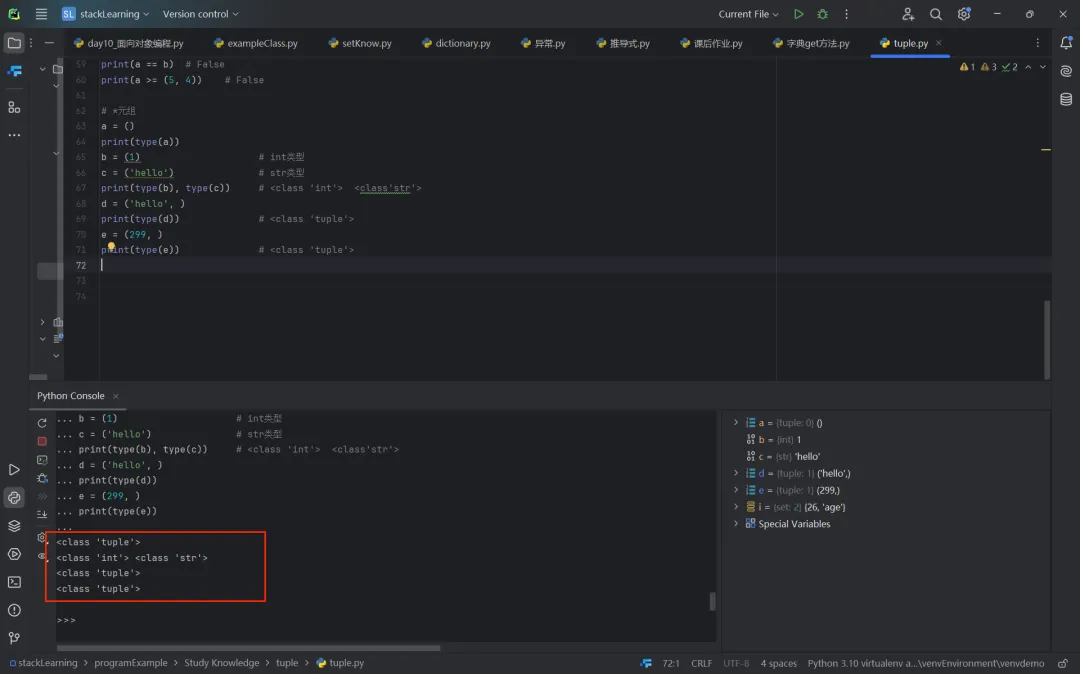
2、打包和解包操作
当我们把多个逗号分隔的值赋给一个变量时,多个值会打包成一个元组类型;当我们把一个元组赋值给多个变量时,元组会解包成多个值然后分别赋给对应的变量;
- 打包操作:
打包操作就是将多个变量打包成一个元组,然后将这个元组赋值给一个变量。
# 打包# 打包操作就是将多个变量打包成一个元组,然后将这个元组赋值给一个变量。a = 1, 20, 5, 200print(type(a)) # <class 'tuple'>print(a) #(1, 20, 5, 200)- 解包操作:
解包操作就是将一个元组中的元素拆开,然后赋值给多个变量。
# 解包操作a = 1, 20, 5, 200x, y, z, w = aprint(x, y, z, w) # 1 20 5 200- 值少或值多:会引发异常
ValueError错误
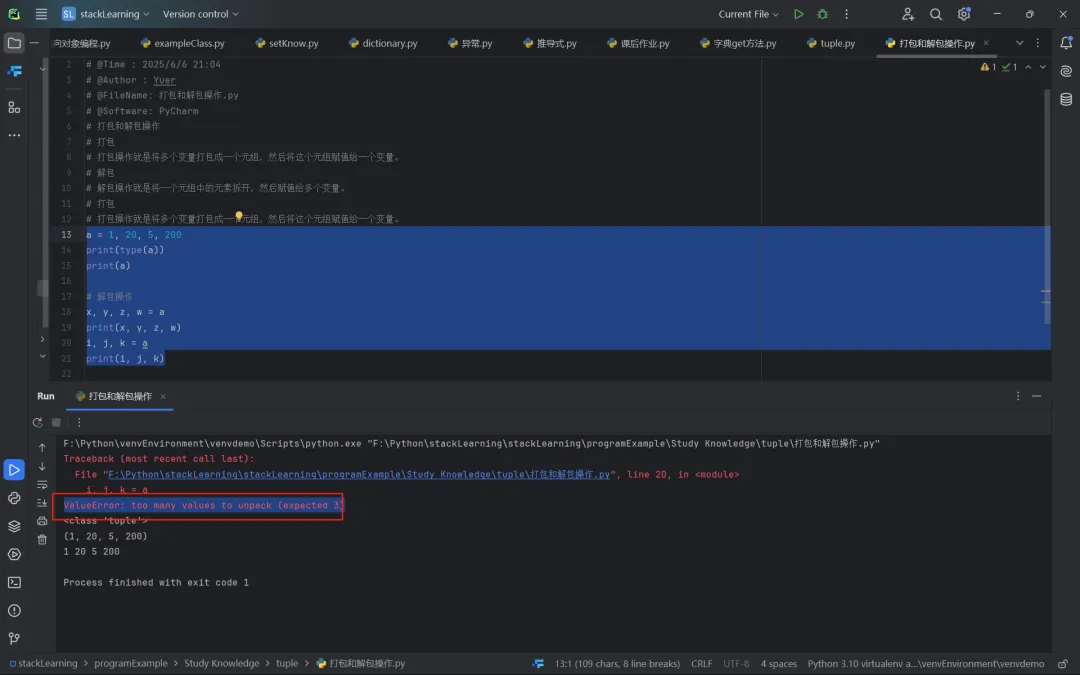
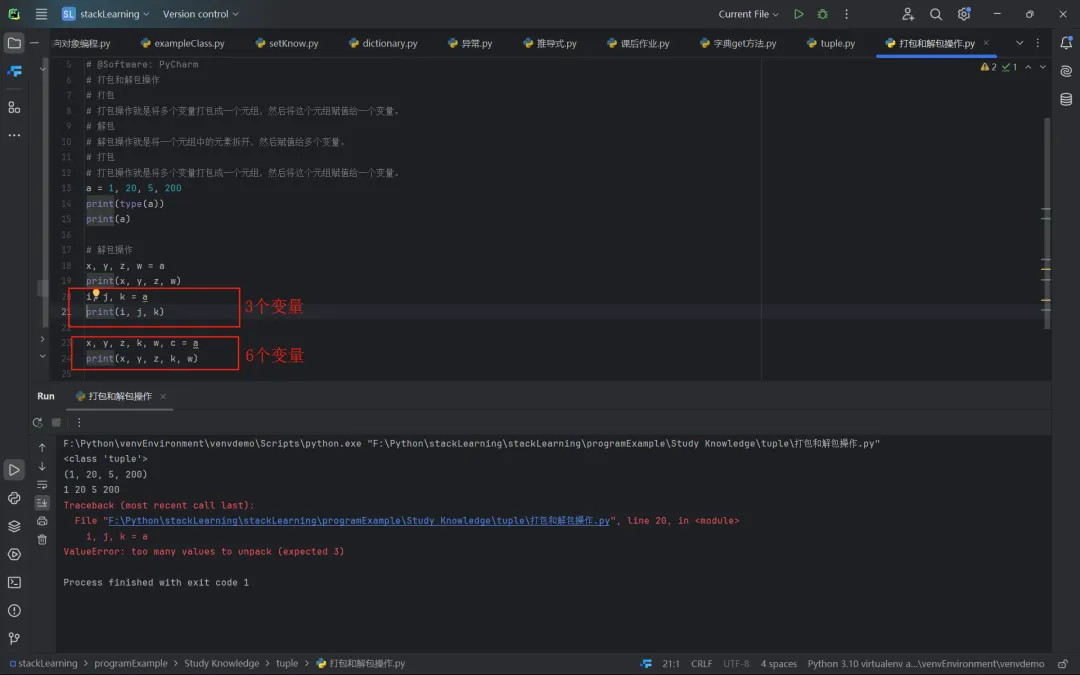
有一种解决变量个数少于元素的个数方法,就是使用星号表达式。通过星号表达式,我们可以让一个变量接收多个值,代码如下所示。需要注意两点:首先,用星号表达式修饰的变量会变成一个列表,列表中有0个或多个元素;其次,在解包语法中,星号表达式只能出现一次。
# 解包操作x, y, z, w = aprint(x, y, z, w)i, *j, k = aprint(i, j, k) #1 [20, 5] 200x, y, z, *k, w = aprint(x, y, z, k, w) #1 20 5 [] 200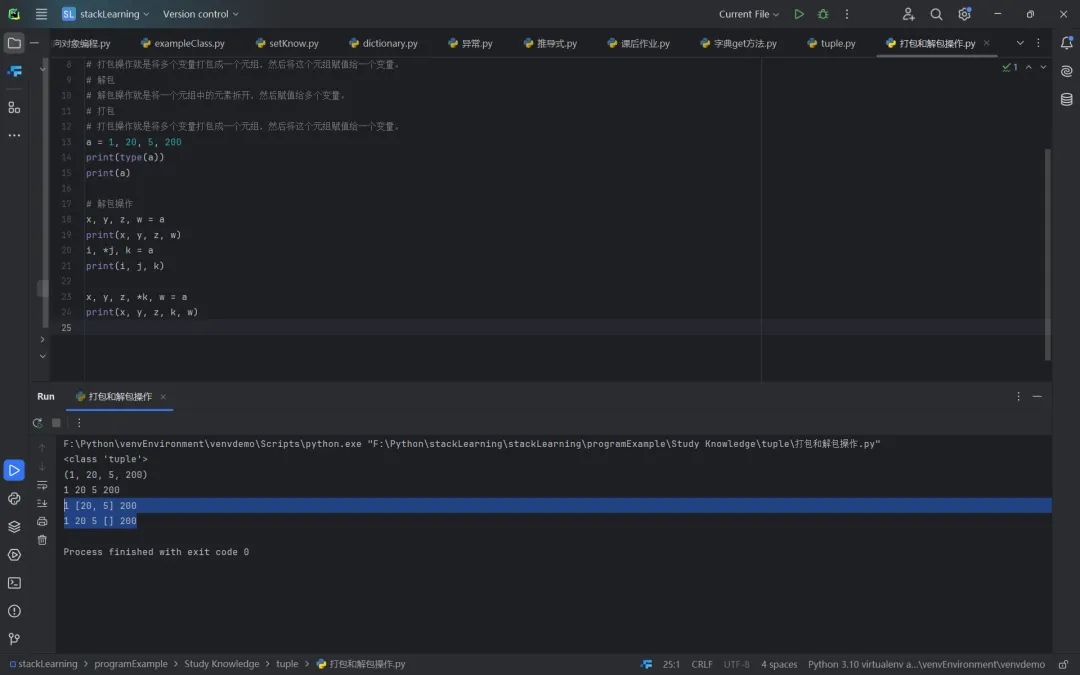
解包语法对所有的序列都成立,这就意味着我们之前讲的列表、range函数构造的范围序列甚至字符串都可以使用解包语法。
3、总结
列表和元组都是容器型的数据类型,即一个变量可以保存多个数据,而且它们都是按一定顺序组织元素的有序容器。列表是可变数据类型,元组是不可变数据类型,所以列表可以添加元素、删除元素、清空元素、排序反转,但这些操作对元组来说是不成立的。列表和元组都可以支持拼接运算、成员运算、索引运算、切片运算等操作
三、字符串
所谓字符串,就是由**零个或多个字符组成的有限序列**,一般记为:在 Python 程序中,我们把单个或多个字符用单引号或者双引号包围起来,就可以表示一个字符串。字符串中的字符可以是特殊符号、英文字母、中文字符、日文的平假名或片假名、希腊字母、Emoji 字符(如:💩、🐷、🀄️)等。
1、转义字符
我们可以在字符串中使用\来标识转义,也就是说,\后面的字符不再是它原来的意义,列如:\n不是代表字符\和n,而是表示换行;\t也不是表示\和t,而是表示制表符。所以如果字符串本身又包含了'、"、\这些特殊的字符,必须要通过\进行转义处理。
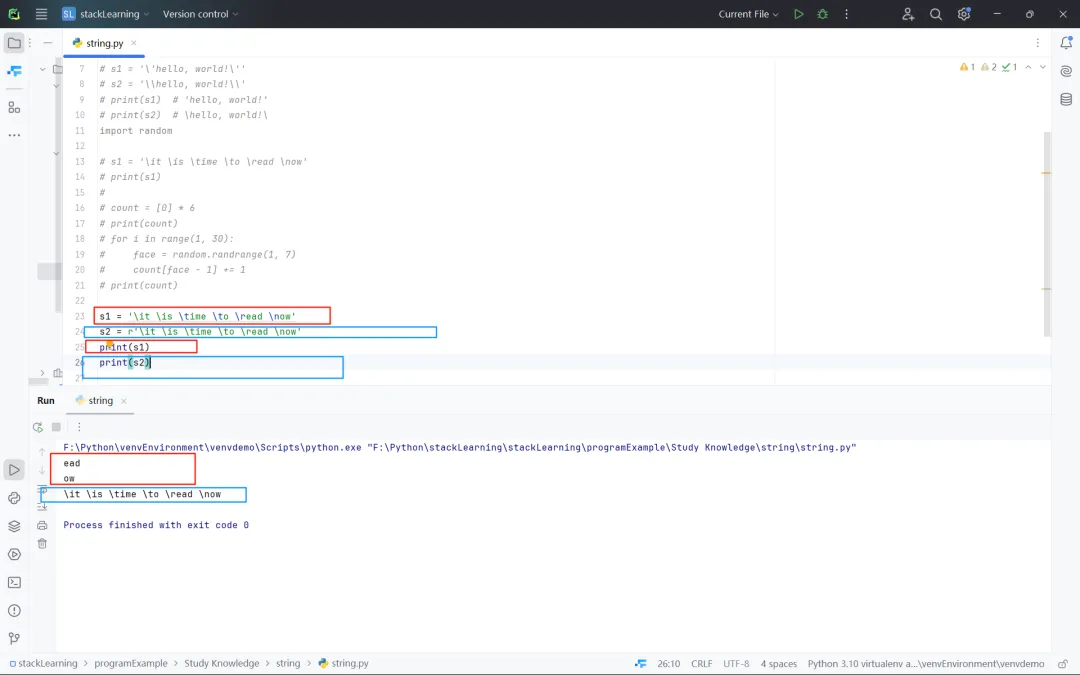
s1 = '\'hello, world!\''s2 = '\\hello, world!\\'print(s1) # 'hello, world!'print(s2) # \hello, world!\2、原始字符串
Python 中有一种以r或R开头的字符串,这种字符串被称为原始字符串,意思是字符串中的每个字符都是它本来的含义,没有所谓的转义字符。例如,在字符串'hello\n'中,\n表示换行;而在r'hello\n'中,\n不再表示换行,就是字符\和字符n。
3、字符的遍历
如果希望遍历字符串中的每个字符,可以使用for-in循环,有如下所示的两种方式。
方式一:
s = 'hello'for i inrange(len(s)):print(s[i])方式二:
s = 'hello'for elem in s:print(elem)4、字符串的方法
在 Python 中,我们可以通过字符串类型自带的方法对字符串进行操作和处理,假设我们有名为foo的字符串,字符串有名为bar的方法,那么使用字符串方法的语法是:foo.bar(),这是一种通过对象引用调用对象方法的语法,跟前面使用列表方法的语法是一样的。
4.1 大小写相关操作
下面的代码演示了和字符串大小写变换相关的方法。
s1 = 'hello, world!'# 字符串首字母大写print(s1.capitalize()) # Hello, world!# 字符串每个单词首字母大写print(s1.title()) # Hello, World!# 字符串变大写print(s1.upper()) # HELLO, WORLD!s2 = 'GOODBYE'# 字符串变小写print(s2.lower()) # goodbye# 检查s1和s2的值print(s1) # hello, worldprint(s2) # GOODBYE说明:由于字符串是不可变类型,使用字符串的方法对字符串进行操作会产生新的字符串,但是原来变量的值并没有发生变化。所以上面的代码中,当我们最后检查
s1和s2两个变量的值时,s1和s2的值并没有发生变化。
4.2 查找操作
如果想在一个字符串中从前向后查找有没有另外一个字符串,可以使用字符串的find或index方法。在使用find和index方法时还可以通过方法的参数来指定查找的范围,也就是查找不必从索引为0的位置开始。
s = 'hello, world!'print(s.find('or')) # 8print(s.find('or', 9)) # -1print(s.find('of')) # -1print(s.index('or')) # 8print(s.index('or', 9)) # ValueError: substring not found说明:
find方法找不到指定的字符串会返回-1,index方法找不到指定的字符串会引发ValueError错误。
find和index方法还有逆向查找(从后向前查找)的版本,分别是rfind和rindex,代码如下所示。
s = 'hello world!'print(s.find('o')) # 4print(s.rfind('o')) # 7print(s.rindex('o')) # 7# print(s.rindex('o', 8)) # ValueError: substring not found4.3 性质判断
可以通过字符串的startswith、endswith来判断字符串是否以某个字符串开头和结尾;还可以用is开头的方法判断字符串的特征,这些方法都返回布尔值,代码如下所示。
s1 = 'hello, world!'print(s1.startswith('He')) # Falseprint(s1.startswith('hel')) # Trueprint(s1.endswith('!')) # Trues2 = 'abc123456'print(s2.isdigit()) # Falseprint(s2.isalpha()) # Falseprint(s2.isalnum()) # True说明:上面的
isdigit用来判断字符串是不是完全由数字构成的,isalpha用来判断字符串是不是完全由字母构成的,这里的字母指的是 Unicode 字符但不包含 Emoji 字符,isalnum用来判断字符串是不是由字母和数字构成的。
4.4 格式化
在 Python 中,字符串类型可以通过center、ljust、rjust方法做居中、左对齐和右对齐的处理。如果要在字符串的左侧补零,也可以使用zfill方法。
s = 'hello, world'print(s.center(20, '*')) # ****hello, world****print(s.rjust(20)) # hello, worldprint(s.ljust(20, '~')) # hello, world~~~~~~~~print('33'.zfill(5)) # 00033print('-33'.zfill(5)) # -0033 我们之前讲过,在用print函数输出字符串时,可以用下面的方式对字符串进行格式化。
a = 321b = 123print('%d * %d = %d' % (a, b, a * b)) # 321 * 123 = 39483 当然,我们也可以用字符串的format方法来完成字符串的格式,代码如下所示。
a = 321b = 123print('{0} * {1} = {2}'.format(a, b, a * b)) # 321 * 123 = 39483 从 Python 3.6 开始,格式化字符串还有更为简洁的书写方式,就是在字符串前加上f来格式化字符串,在这种以f打头的字符串中,{变量名}是一个占位符,会被变量对应的值将其替换掉,代码如下所示。
a = 321b = 123print(f'{a} * {b} = {a * b}') # 321 * 123 = 39483如果需要进一步控制格式化语法中变量值的形式,可以参照下面的表格来进行字符串格式化操作。
3.1415926 | {:.2f} | '3.14' | |
3.1415926 | {:+.2f} | '+3.14' | |
-1 | {:+.2f} | '-1.00' | |
3.1415926 | {:.0f} | '3' | |
123 | {:0>10d} | '0000000123' | 0,补够10位 |
123 | {:x<10d} | '123xxxxxxx' | x ,补够10位 |
123 | {:>10d} | ' 123' | |
123 | {:<10d} | '123 ' | |
123456789 | {:,} | '123,456,789' | |
0.123 | {:.2%} | '12.30%' | |
123456789 | {:.2e} | '1.23e+08' |
4.5 修剪操作
字符串的strip方法可以帮我们获得将原字符串修剪掉左右两端指定字符之后的字符串,默认是修剪空格字符。这个方法非常有实用价值,可以用来将用户输入时不小心键入的头尾空格等去掉,strip方法还有lstrip和rstrip两个版本,相信从名字大家已经猜出来这两个方法是做什么用的。
s1 = ' jackfrued@126.com 'print(s1.strip()) # jackfrued@126.coms2 = '~你好,世界~'print(s2.lstrip('~')) # 你好,世界~print(s2.rstrip('~')) # ~你好,世界4.6 替换操作
如果希望用新的内容替换字符串中指定的内容,可以使用replace方法,代码如下所示。replace方法的第一个参数是被替换的内容,第二个参数是替换后的内容,还可以通过第三个参数指定替换的次数。
s = 'hello, good world'print(s.replace('o', '@')) # hell@, g@@d w@rldprint(s.replace('o', '@', 1)) # hell@, good world4.7 拆分与合并
可以使用字符串的split方法将一个字符串拆分为多个字符串(放在一个列表中),也可以使用字符串的join方法将列表中的多个字符串连接成一个字符串,代码如下所示。
s = 'I love you'words = s.split()print(words) # ['I', 'love', 'you']print('~'.join(words)) # I~love~you 需要说明的是,split方法默认使用空格进行拆分,我们也可以指定其他的字符来拆分字符串,而且还可以指定最大拆分次数来控制拆分的效果,代码如下所示。
s = 'I#love#you#so#much'words = s.split('#')print(words) # ['I', 'love', 'you', 'so', 'much']words = s.split('#', 2) # 拆分两次c = s.split('#', 3) # 拆分三次print(words) # ['I', 'love', 'you#so#much']print(c) # ['I', 'love', 'you', 'so#much']4.8 编码和解码
Python 中除了字符串str类型外,还有一种表示二进制数据的字节串类型(bytes)。所谓字节串,就是由零个或多个字节组成的有限序列。通过字符串的encode方法,我们可以按照某种编码方式将字符串编码为字节串,我们也可以使用字节串的decode方法,将字节串解码为字符串,代码如下所示。
a = '小明'b = a.encode('utf-8')c = a.encode('gbk')print(b) # b'\xe5\xb0\x8f\xe6\x98\x8e'print(c) # b'\xd0\xa1\xc3\xf7'print(b.decode('utf-8')) # 小明print(c.decode('gbk')) # 小明 注意,如果编码和解码的方式不一致,会导致乱码问题(无法再现原始的内容)或引发UnicodeDecodeError错误,导致程序崩溃。
4.9 其他方法
对于字符串类型来说,还有一个常用的操作是对字符串进行匹配检查,即检查字符串是否满足某种特定的模式。例如,一个网站对用户注册信息中用户名和邮箱的检查,就属于模式匹配检查。实现模式匹配检查的工具叫做正则表达式,Python 语言通过标准库中的re模块提供了对正则表达式的支持,我们会在后续的课程中为大家讲解这个知识点。
5、总结
知道如何表示和操作字符串对程序员来说是非常重要的,因为我们经常需要处理文本信息,Python 中操作字符串可以用拼接、索引、切片等运算符,也可以使用字符串类型提供的非常丰富的方法。

四、集合
1、概念
集合(Set):集合是一种容器型的数据类型。也就是把一定范围内、确定的、可以区别对待的事物当做一个整体来对待,那么这个整体也就叫做集合,集合中的各个事物称为集合的元素。
集合需要满足以下条件:
无序性:一个集合中,每个元素的地位都是相同的,元素之间是无序的; 互异性:一个集合中,任何两个元素都是不相同的,即元素在集合中只能出现一次; 确定性:给定一个集合和一个任意元素,该元素要么属于这个集合,要么不属于这个集合,二者则其一,不允许有模棱两可的情况出现;
Python中的集合和数学上的集合本质上没有啥大的区别,需要特别注意的是无序性和交互性。无序性说明集合中的元素并不像列表中的元素存在某种次序,通过索引运算就能访问任意元素,也就是说明一点集合并不支持索引运算。另外集合的互异性决定了集合中不能有重复元素,这一点,也是区别于列表的地方,我们无法将一个重复的元素添加到一个集合中。集合也支持in 和 not in 运算,这样也就可以确定一个元素是否属于集合,也就是上面的确定性。
集合的成员运算在性能上要优于列表的成员运算,这是集合的底层存储特性决定的;
集合的定义:集合(Set)是Python中的一种内置数据类型,用于存储==无序且唯一的==元素。 特性:
元素唯一(不允许重复); 无序(不支持索引访问); 可动态增删元素(可变类型); 元素必须是不可变类型(如整数、字符串、元组等)2、创建
创建集合,我们通常使用{ }创建,元素之间用,隔开,或者可以使用set()来创建;使用Python内置函数set来创建一个集合,准确的说set并不是一个函数,而是创建集合对象的构造器。
用户直接创建集合:
# 定义集合s = {4, 5, 9, 2, 1, 90, 45, 78, 32, 12, 21, 32, True, 1}print(s)"""用户自定义的集合:{4, 5, 9, 2, 1, 90, 45, 78, 32, 12, 21, 32, True, 1}运行结果:{32, 1, 2, 4, 5, 9, 12, 45, 78, 21, 90}"""由上,可以看出,《无序且唯一的特点》,因为元素32, 1以及True是重复的元素,而这里的True值为1;
列表转换为集合:
# 列表转换为集合 s2 = [43, 54, 23, False, True, 'String', (1, 'Hello', 54), 0, 1]s2 = set(s2)print(s2)"""定义一个列表:[43, 54, 23, False, True, 'String', (1, 'Hello', 54), 0, 1]经过转换后得到的结果:{False, True, 'String', 43, (1, 'Hello', 54), 54, 23}""" 在上面的代码中,如果我们在列表s2中再嵌套一个列表,再使用set(s2)转换为集合,就会报错,报TypeError: unhashable type: 'list';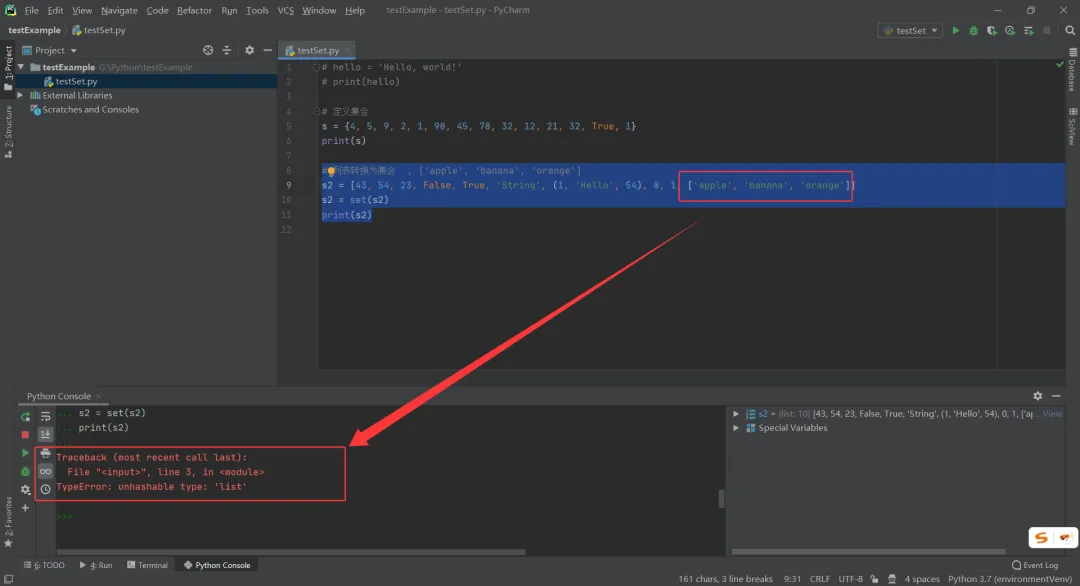 因为列表嵌套列表,列表数据类型是可以修改列表内的元素值,这也体现了集合的一个特性:《元素必须是不可变类型》;
因为列表嵌套列表,列表数据类型是可以修改列表内的元素值,这也体现了集合的一个特性:《元素必须是不可变类型》;
注意:如果要定义一个空的集合,要使用set(),不使用{ }因为{ }直接定义是字典而不是集合;
列表生成式来创建集合:
和之前创建列表的生成式一样,可参考【列表生成式语法格式】
# 生成范围1~99的整数,步长为6,且能被3或7整除的集合s = {x for x inrange(1, 100, 6) if x % 3 == 0or x % 7 == 0}print(f"利用列表生成式生成的集合为:{s}。")"""运行结果:利用列表生成式生成的集合为:{49, 91, 7}。""" 解释:生成1~99内的整数,步长为6,并且能够被3或者7整除的整数。1 ~ 99内,步长为6的整数有[1, 7, 13, 19, 25, 31, 37, 43, 49, 55, 61, 67, 73, 79, 85, 91, 97],经过x % 3 == 0 or x % 7 == 0筛选后,只有[7,49,91]满足条件,进而输出;
3、集合的基本操作
3.1 添加元素
add()将元素添加到集合中,如果集合中已经存在这个元素,则不进行任何操作;
s = {1, 4, 2, 5, 0}# 将90添加到集合s中s.add(90)# 将True添加到集合s中,其中True的值为1s.add(True)print(s)"""运行结果:{0, 1, 2, 4, 5, 90}"""2.update()update()可以添加任意的参数类型,比如字典、列表、元组、字符串类型;
s = {1, 4, 2, 5, 0}# 添加列表元素,将列表中的元素拆分插入s.update([32, 89, 1, 34, 45])print(f"添加列表后的结果:{s}。")# 添加字符串s.update('apple')print(f"添加字符串后的结果:{s}。")# 添加字典元素s.update({'name': '小明', 'gender': '女'})print(f"添加字典后的结果:{s}。")# 添加元组s.update((4, 1, 89, 'banana'))print(f"添加元组后的结果:{s}。")"""运行结果:添加列表后的结果:{0, 1, 2, 32, 4, 5, 34, 45, 89}。添加字符串后的结果:{0, 1, 2, 32, 4, 5, 34, 'p', 45, 'e', 'a', 89, 'l'}。添加字典后的结果:{0, 1, 2, 32, 4, 5, 34, 'p', 'gender', 45, 'e', 'a', 89, 'l', 'name'}。添加元组后的结果:{0, 1, 2, 32, 4, 5, 34, 'p', 'gender', 'banana', 45, 'e', 'a', 89, 'l', 'name'}。"""3.2 移除元素
remove()移除集合中存在的元素:
s = {1, 4, 2, 5, 0, 'orange', 'banana', True, (2, 3, 45)}s.remove(1)print(f"移除元素后的结果:{s}。")"""移除元素后的结果:{0, 2, 'banana', 4, 5, (2, 3, 45), 'orange'}。""" 移除集合中不存在的元素,报错;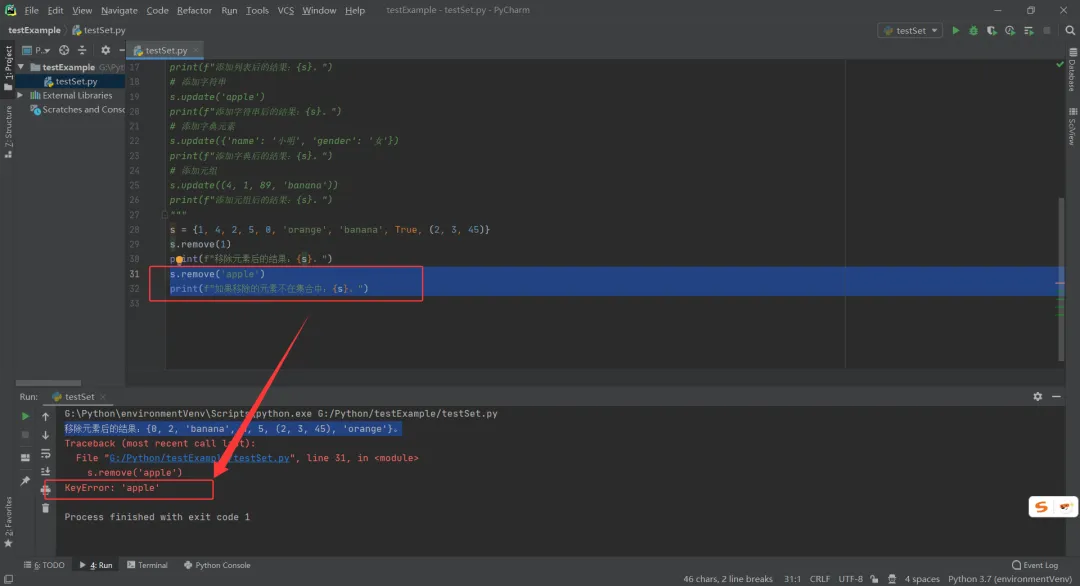
discard()移除集合中的元素,如果存在则移除,不存在不会报错,不进行任何操作;
s = {1, 4, 2, 5, 0, 'orange', 'banana', True, (2, 3, 45)}s.discard(1)print(f"移除元素后的结果:{s}。")s.discard('apple')print(f"如果移除的元素不在集合中:{s}。")"""运行结果:移除元素后的结果:{0, 2, 4, 5, (2, 3, 45), 'orange', 'banana'}。如果移除的元素不在集合中:{0, 2, 4, 5, (2, 3, 45), 'orange', 'banana'}。"""pop()随机删除一个元素;
s = {x for x inrange(1, 200, 6) if x % 3 == 0or x % 7 == 0}print(f"利用列表生成式生成的集合为:{s}。")# pop()方法:print(f"输出集合中任意删除的元素:{s.pop()}。")"""运行结果:利用列表生成式生成的集合为:{133, 7, 175, 49, 91}。输出集合中任意删除的元素:133。利用pop()方法弹出集合中的元素:{7, 175, 49, 91}。"""clear()清空集合内的所有元素;
s = {x for x inrange(1, 200, 6) if x % 3 == 0or x % 7 == 0}# 清空集合内的所有元素:s.clear()print(f"使用clear()方法后,集合中的元素还有:{s}。")"""运行结果:使用clear()方法后,集合中的元素还有:set()。"""4、元素的遍历
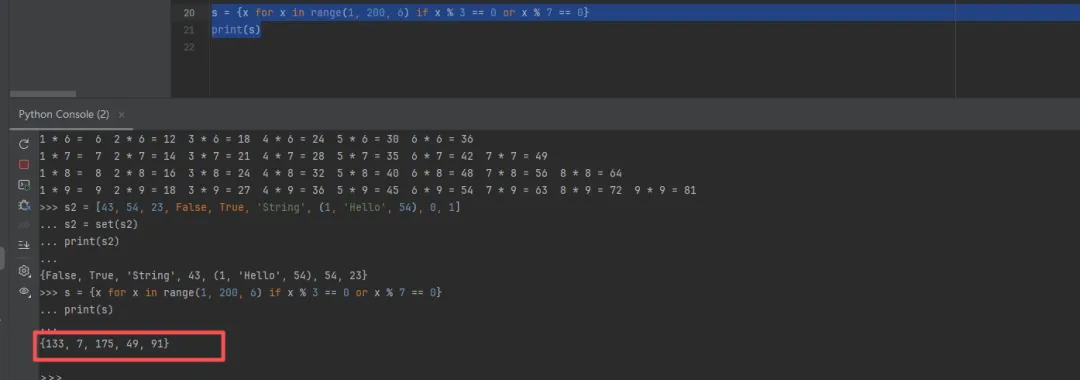
我们可以通过len()函数来获得集合中有多少个元素,但是我们不能通过索引运算来遍历集合中的元素,因为集合元素并没有特定的顺序。当然要实现对集合元素的遍历,仍然可以使用for ~ in循环来实现;
s = {x for x inrange(1, 200, 6) if x % 3 == 0or x % 7 == 0}s.update([3, 5, 9, True], 'Hello', "World")# 遍历生成的集合for x in s:print(x, end=' ')"""运行结果:True 3 l 133 5 7 W 9 d 175 r 49 e H o 91 """由代码的输出可以看出集合的无序性特点;
5、集合的运算
Python为集合类型提供了非常丰富的运算,主要包括:成员运算、交集运算、并集运算、差集运算、比较运算(相等性、子集、超集等)。
5.1 成员运算
可以通过成员运算`in` 和 `not in` 检查元素是否在集合中,其结果为布尔型;s = {x for x inrange(1, 200, 6) if x % 3 == 0or x % 7 == 0}print(14in s)print(21notin s)"""运行结果:FalseTrue"""5.2 二元运算
集合的二元运算主要指集合的交集、并集、差集、对称差等运算,这些运算可以通过运算符来实现,也可以通过集合类型的方法来实现,实例如下:
交集:得到两个集合中的公共元素;
# 交集 & —— 两个集合中的公共元素s1 = {1, 2, 3, 4, 5}s2 = {4, 5, 6, 7, 8}# 进行集合运算:print(s1 & s2)print(s1.intersection(s2))"""运行结果:{4, 5}{4, 5}"""并集:两个集合中的所有元素;
# 并集 | 两个集合中的所有元素s1 = {1, 2, 3, 4, 5}s2 = {4, 5, 6, 7, 8}print(s1 | s2)print(s1.union(s2))"""运行结果:{1, 2, 3, 4, 5, 6, 7, 8}{1, 2, 3, 4, 5, 6, 7, 8}"""差集:第一个集合中有,第二个集合中没有的元素;
# 差集 第一个集合中有,第二个集合中没有的元素s1 = {1, 2, 3, 4, 5}s2 = {4, 5, 6, 7, 8}print(s1 - s2)print(s1.difference(s2))print(s2.difference(s1))"""运行结果:{1, 2, 3}{1, 2, 3}{8, 6, 7}"""对称差:两个集合中不同时包含的元素;
# 对称差 两个集合中不同时包含的元素s1 = {1, 2, 3, 4, 5}s2 = {4, 5, 6, 7, 8}print(s1 ^ s2)print(s1.symmetric_difference(s2)) 通过上面的实例代码可以看出,对两个集合求交集,&运算和intersection()方法的作用是完全相同的,使用运算符的方式显然更直观且代码也更简短。需要特别注意的是,集合的二元运算还可以跟赋值运算一起构成复合赋值运算,比如s1 |= s2 等价于 s1 = s1 | s2,跟|=作用相同的方法是update(),s1 &= s2 等价于 s1 = s1 & s2,跟&=相等的方法是intersection_update();
# 复合赋值运算s1 = {1, 2, 3, 4, 5}s2 = {4, 5, 6, 7, 8}s1 &= s2print(s1)s1.update(s2)print(s1)"""运行结果:{4, 5}{4, 5, 6, 7, 8}"""5.3 比较运算
两个集合可以用==和!=进行相等性判断,如果两个集合中的元素完全相同,那么==比较的结果就是True,否则就是False。如果集合A的任意一个元素都是集合B的元素,那么集合A称为集合B的子集。即对于 ∀a∈A ,均有 a∈B ,则 A⊆B ,A是B的子集,反过来也可以称B是A的超集。如果A是B的子集且A不等于B,那么A就是B的真子集。Python 为集合类型提供了判断子集和超集的运算符,其实就是我们非常熟悉的<、<=、>、>=这些运算符。当然,我们也可以通过集合类型的方法issubset和issuperset来判断集合之间的关系,代码如下所示。
# 集合运算s1 = {1, 3, 5}s2 = {1, 2, 3, 4, 5}s3 = {5, 4, 3, 2, 1}print(f"【s1 > s2】的结果为:{s1 > s2}")print(f"【s1 >= s2】的结果为:{s1 >= s2}")print(f"【s1 < s2】的结果为:{s1 < s2}")print(f"【s1 <= s2】的结果为:{s1 <= s2}")print(f"【s2 == s3】的结果为:{s2 == s3}")# 使用issubset()方法来判断集合之间的关系print(f"【s1.issubset(s2)】的结果为:{s1.issubset(s2)}")print(f"【s2.issubset(s3)】的结果为:{s2.issubset(s3)}")print(f"【s1.issubset(s3)】的结果为:{s1.issubset(s3)}")# 使用issuperset()方法来判断集合之间的关系print(f"【s1.issuperset(s2)】的结果为:{s1.issuperset(s2)}")print(f"【s1.issuperset(s3)】的结果为:{s1.issuperset(s3)}")print(f"【s2.issuperset(s3)】的结果为:{s2.issuperset(s3)}")"""运行结果:【s1 > s2】的结果为:False【s1 >= s2】的结果为:False【s1 < s2】的结果为:True【s1 <= s2】的结果为:True【s2 == s3】的结果为:True【s1.issubset(s2)】的结果为:True【s2.issubset(s3)】的结果为:True【s1.issubset(s3)】的结果为:True【s1.issuperset(s2)】的结果为:False【s1.issuperset(s3)】的结果为:False【s2.issuperset(s3)】的结果为:True"""issubset()- 作用:检查一个集合是否是另外一个集合的子集;
- 定义:若集合A中的所有元素都包含在集合B中,则A是B的超集;
- 语法:
A.issubset(B)或A >= B; - 返回值:若A是B的超集返回
True,否则返回False; issuperset()- 作用:检查一个集合是否是另外一个集合的超集;
- 定义:若集合B中的所有元素都包含在集合A中,则A是B的子集;
- 语法:
A.issubset(B)或A <= B; - 返回值:若A是B的子集返回
True,否则返回False; 关键区别 - 方法参数:
issubset()和issuperset()可以接受**可迭代对象(如列表、元组)**作为参数,自动转换为集合后再比较; - 操作符限制:使用
<=或>=时,两边必须是集合;
a = {1, 2, 3, 4, 5}print(f"子集:{a.issubset([1, 2, 3, 4, 5, 7])}")print(f"超集:{a.issuperset([1, 2, 5])}")"""运行结果:子集:True超集:True"""6、不可变集合
Python中还有一种不可变类型的集合,名字叫frozenset。set跟frozenset的区别就如同list跟tuple的区别,frozenset由于是不可变类型,能够计算出哈希值,因此可以作为set中的元素。除了不能添加和删除元素,frozenset在其他方面跟set是一样的。下面是简单介绍:
fSet1 = frozenset({1, 2, 3, 4, 5})fSet2 = frozenset(range(1, 8))print(fSet1)print(fSet2)print(f"交集:{fSet2 & fSet1}")print(f"并集:{fSet2 | fSet1}")print(f"差集:{fSet2 - fSet1}")print(f"对称差:{fSet2 ^ fSet1}")print(f"比大小:{fSet2 > fSet1}")"""运行结果:frozenset({1, 2, 3, 4, 5})frozenset({1, 2, 3, 4, 5, 6, 7})交集:frozenset({1, 2, 3, 4, 5})并集:frozenset({1, 2, 3, 4, 5, 6, 7})差集:frozenset({6, 7})对称差:frozenset({6, 7})比大小:True"""7、总结
- 需要注意的是:
集合中的元素必须是 hashable类型,所谓的hashable类型指的是能够计算出哈希码的数据类型,通常不可变类型都是hashable类型,因为可变类型无法计算出确定的哈希码,所以它们就不能放在集合中; - 比如:
我们不能将列表作为集合中的元素;同理,由于集合本身是可变类型,集合不能作为集合中的元素;我们可以集合中嵌套列表(列表中的元素也是列表),但是我们不能创建出嵌套的集合,这是需要注意的。 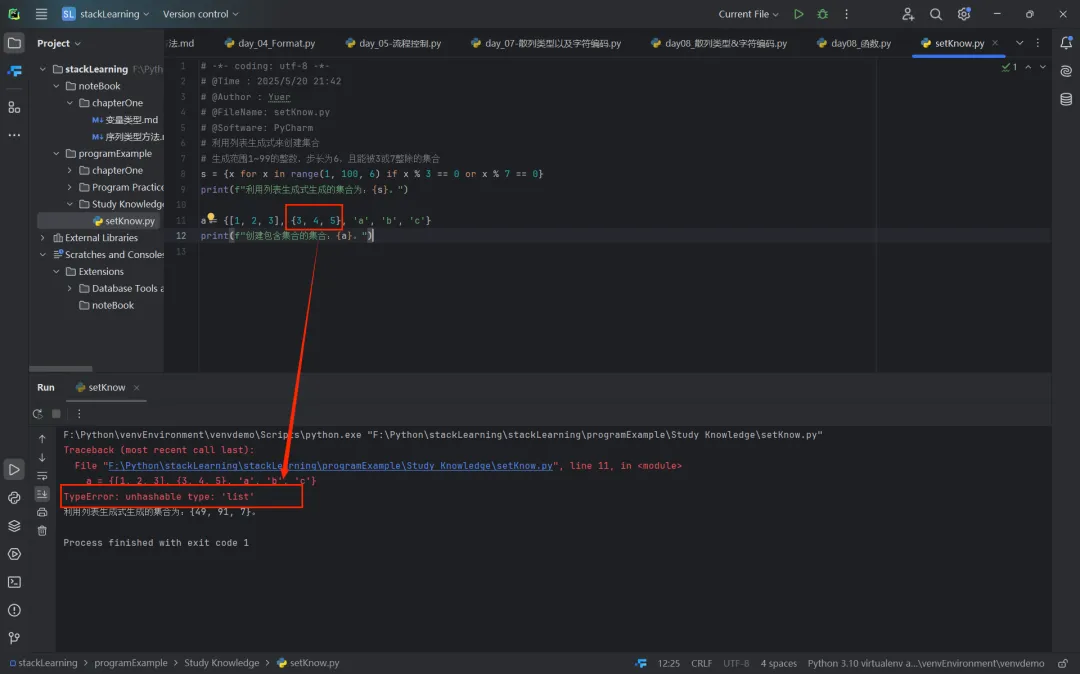 Python中的集合类型是一种无序容器,不允许有重复的元素,由于底层使用了哈希存储,集合中的元素必须是
Python中的集合类型是一种无序容器,不允许有重复的元素,由于底层使用了哈希存储,集合中的元素必须是hashable类型。集合与列表的最大区别就在于集合中的元素没有顺序、所以不能够通过索引运算访问元素、但是集合可以执行交集、并集、差集等二元运算,也可以通过关系运算符检查两个集合是否存在超集、子集等关系。
五、字典
1、背景
到目前为止,我们已经学了Python中的三种容器类型(列表、元组、集合),但是呢,这三种类型,仍然存在一些无法解决的问题。比如,使用一个变量来存储一个人的多项信息,如姓名、性别、年龄、体重、兴趣爱好、现住址、手机号,这是我们就会发现,我们之前学过的列表、元组和集合就不太友好。
# 用一个变量来存储这些信息:姓名、性别、年龄、体重、兴趣爱好、现住址、手机号、紧急联系人的手机号# 列表存储introduce1 = ['小明', '男', 18, 55.6, ['篮球', '足球', '乒乓球'], '北京市朝阳区', '13812345678', '12345612345']# 元组存储introduce2 = ('小明', '男', 18, 55.6, ['篮球', '足球', '乒乓球'], '北京市朝阳区', '13812345678', '12345612345')# 集合存储introduce3 = {'小明', '男', 18, 55.6, ('篮球', '足球', '乒乓球'), '北京市朝阳区', '13812345678', '12345612345'}首先,集合来存储这些信息,肯定是不合适的,因为集合中不能存储重复的元素,如果一个人的年龄和体重恰好相等,那么集合中肯定也就少了一项信息;同理一个人的手机号和紧急联系人的手机号是同一个,那么集合中肯定也就又少一项信息。另一方面,列表和元素虽然都能将这些元素都存储起来,但是当你要访问这些信息的时候,你得知道它们在列表或元组中的什么位置;
因此我们就需要字典(dictionary)来将这些关联的信息组装在一起,也就可以帮我们解决Python程序中的真实事物建模问题。
字典,想必大家都不陌生,曾经我也是用高价买过一本,如下:
2、概念
Python中的字典和现实生活中的字典很像,它以键值对(键和值的组合)的形式出现,通过键找到与之对应的值进行操作。就像《新华字典》中,每个(键)都有与之对应的解释(值)一样,每个字和它的解释合在一起就是字典中的一个条目,而字典中通常包含了很多个这个的条目。
3、创建和使用字典
Python中创建字典可以使用{ }字面量语法,和集合一样都是使用{ }进行包裹,而字典则是使用键值对的形式存在,每个元素由:分隔的两个值构成,:前面是键,后面是值;
xinHua= {'麓': '山脚下','路': '道,往来通行的地方;方面,地区:南~货,外~货;种类:他俩是一~人','蕗': '甘草的别名','潞': '潞水,水名,即今山西省的浊漳河;潞江,水名,即云南省的怒江'}print(f"新华字典:{xinHua}")# 上面的定义,使用字典定义如下introduce4 = {'姓名': '小明','性别': '男','年龄': 18,'体重': 55.6,'兴趣爱好': ['篮球', '足球', '乒乓球'],'地址': '北京市朝阳区','手机号': '13812345678','紧急联系人': '12345612345' ,}print(f"个人信息:{introduce4}")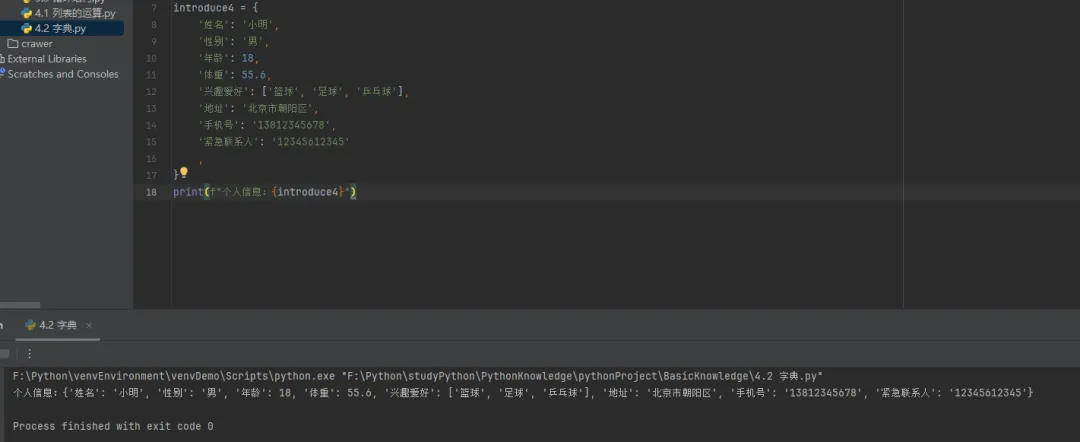
通过上面的实例,可以看出,使用字典来存储个人信息,看起来令人更舒服,也通俗易懂;
如果可以,我们还可以使用内置函数dict或者字典的生成式语法来创建字典,代码如下:
"""使用内置函数以及字典生成式来创建字典 + 内置函数dict()可以将序列中的元素转换为字典 + 字典生成式语法:{key:value for item in iterable}"""# 内置函数dict()可以将序列中的元素转换为字典introduce5 = dict(姓名='小明', 性别='男', 年龄=18, 体重=55.6, 兴趣爱好=['篮球', '足球', '乒乓球'], 地址='北京市朝阳区', 手机号='13812345678', 紧急联系人='12345612345')print(f"内置函数创建字典:{introduce5}")# 可以通过内置函数中的zip()压缩两个序列并创建字典item1 = dict(zip('ABCDEF', [1, 2, 3, 4, 5, 6]))item2 = dict(zip('ABCDEF', range(3, 90, 15)))print(f"使用zip()创建字典:{item1}\n{item2}")# 使用字典生成式来创建字典item3 = {x: x ** 4for x inrange(1, 20, 3)}print(f"使用字典生成式创建字典:{item3}")"""运算结果:内置函数创建字典:{'姓名': '小明', '性别': '男', '年龄': 18, '体重': 55.6, '兴趣爱好': ['篮球', '足球', '乒乓球'], '地址': '北京市朝阳区', '手机号': '13812345678', '紧急联系人': '12345612345'}使用zip()创建字典:{'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6}{'A': 3, 'B': 18, 'C': 33, 'D': 48, 'E': 63, 'F': 78}使用字典生成式创建字典:{1: 1, 4: 256, 7: 2401, 10: 10000, 13: 28561, 16: 65536, 19: 130321}"""4、字典的运算
对于字典类型来说,成员运算和索引运算肯定是很重要的,前者可以判断知道你的键在或不在字典中,后者可以通过键来访问对应的值或者向字典中添加新的键值对。值得注意的是,字典的索引不同于列表的索引,列表中的元素因为有属于自己的序号,索引列表的索引是一个整数;字典中因为保存的是键值对,所以需要用键去索引对应的值。
需要特别注意的是,字典中的键是不可变类型,例如整数(int)、浮点数(float)、字符串(str)、元组(tuple)等类型,这一点跟集合类型对元素的要求是一样的。很明显的一点是,之前学的列表(list)和集合(set)不能作为字典中的值,字典类型本身也不能作为字典中的键,因为字典也是可变类型,但是列表、集合、字典都可以作为字典中的值;
introduce6 = {'姓名': '小明','性别': '男','年龄': 18,'体重': 55.6,'兴趣爱好': {'运动': ['篮球', '足球', '乒乓球'],'音乐': ['流行', '摇滚', '民谣'],'阅读': ['小说', '散文', '诗歌'],'旅游': ['古镇', '城市', '乡村'],'美食': ['清蒸鲈鱼', '番茄拌面', '顿排骨、猪脚'],'动漫': ['完美世界', '火影忍者', '斗破苍穹', '镇魂街', '秦时明月'],'游戏': ['王者荣耀', '绝地求生', '刺激战场'],'其他': ['棋牌', '桌游', '棋类'], },'地址': '北京市朝阳区','手机号': '13812345678','紧急联系人': '12345612345' ,}print(f"个人信息:{introduce6}")4.1 字典的成员运算和索引运算
4.1.1 字典的成员运算
字典的成员运算也就是包含(in)以及不包含(not in):
- 语法:
key in dict或者key not in dict; - 作用:用来检查一个键是否存在于集合中;
- 返回值:如果键存在,
key in dict返回True,否则返回False;key not in dict则相反;
# 成员运算# 借用上节的字典定义【introduce6】print('运动'in introduce6)print('地址'in introduce6)print('音乐'in introduce6['兴趣爱好'])print('game'notin introduce6)4.1.2 索引运算
字典的索引运算(dict[key]):
- 语法:
dict[key]; - 作用:用于获取字典中键对应的值;
- 返回值:如果键存在,返回对应的值;不存在,则会引发
KeyError错误;
# 索引运算# 借用上节的字典定义【introduce6】print(introduce6['兴趣爱好'])try:print(introduce6['game'])except KeyError:print('键不存在') 上面的,我使用了try 代码块 except来处理当索引的键以及对应的值都不存在时,抛出【键不存在】,以便继续执行代码而不是终止代码;
4.1.3 区别
- 处理不存在的键的方式不同:
成员运算在键不存在时不会引发错误,只会返回 False,而索引运算,则会引发KeyError; - 功能侧重点不同:
成员运算主要判断键是否存在,而索引运算主要用于获取键对应的值;
5、字典的方法
字典类型的方法基本上都是跟字典的键值对操作相关,其中get方法可以通过键来获取对应的值。跟索引运算不同的是,get方法在字典中没有指定的键时不会产生异常,而是返回None或指定的默认值;
5.1 查看方法
keys():返回一个包含字典所有键的视图对象;
introduce4 = {'姓名': '小明','性别': '男','年龄': 18,'体重': 55.6,'兴趣爱好': ['篮球', '足球', '乒乓球'],'地址': '北京市朝阳区','手机号': '13812345678','紧急联系人': '12345612345',}keys_view = introduce4.keys()print(keys_view)输出字典中的所有键;for key in keys_view:遍历字典中的键;
# 借用上面定义的introduce4# 1.keys()方法:返回字典所有键的集合keys_view = introduce4.keys()print(f"获取字典中的所有键:{keys_view}")for key in keys_view:print(key)"""运行结果:获取字典中的所有键:dict_keys(['姓名', '性别', '年龄', '体重', '兴趣爱好', '地址', '手机号', '紧急联系人'])姓名性别年龄体重兴趣爱好地址手机号紧急联系人"""values():返回一个包含字典所有值的视图对象;values_view = introduce4.values();print(values_view) 得到字典中键对应的所有值;for value in values_view: 遍历字典中的所有键值;
# 借用上面定义的introduce4# 2.values()方法:返回字典所有值的集合values_view = introduce4.values()print(f"获取字典中的所有键值:{values_view}")# 遍历获取到的值for value in values_view:print(value)"""运行结果:获取字典中的所有键值:dict_values(['小明', '男', 18, 55.6, ['篮球', '足球', '乒乓球'], '北京市朝阳区', '13812345678', '12345612345'])小明男1855.6['篮球', '足球', '乒乓球']北京市朝阳区1381234567812345612345"""items():返回一个包含字典所有键值对的视图对象;items_view = introduce4.items();print(items_view)得到对应的键值对;for key,values in items_view:遍历键值对的视图对象;
# 借用上面定义的introduce4# 3.items()方法:返回字典所有键值对的集合items_view = introduce4.items()print(f"获取字典中的所有键值对:{items_view}")# 遍历获取到的键值for key, value in items_view:print(f"{key}: {value}")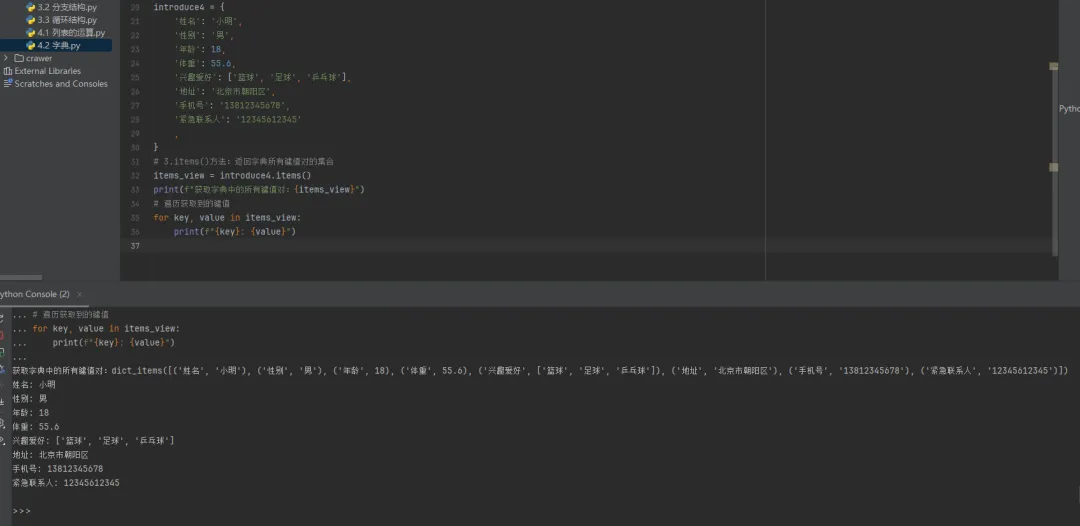
5.2 添加和更新方法
update(key)或update(key = value):若字典中有该键,则更新对应的值;若没有,则添加新的;introduce4.update({'年龄', 25}),将字典中的'年龄'对应的值更新为25;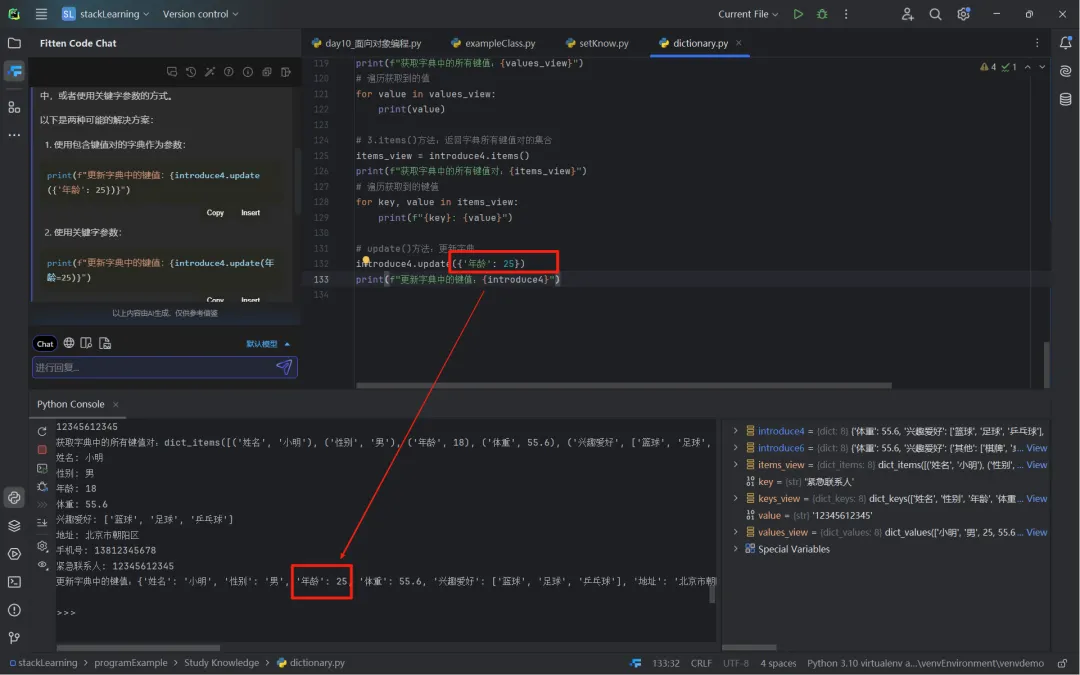
introduce4.update(城市 = '曲靖'),将字典中的城市对应的值更新为'曲靖';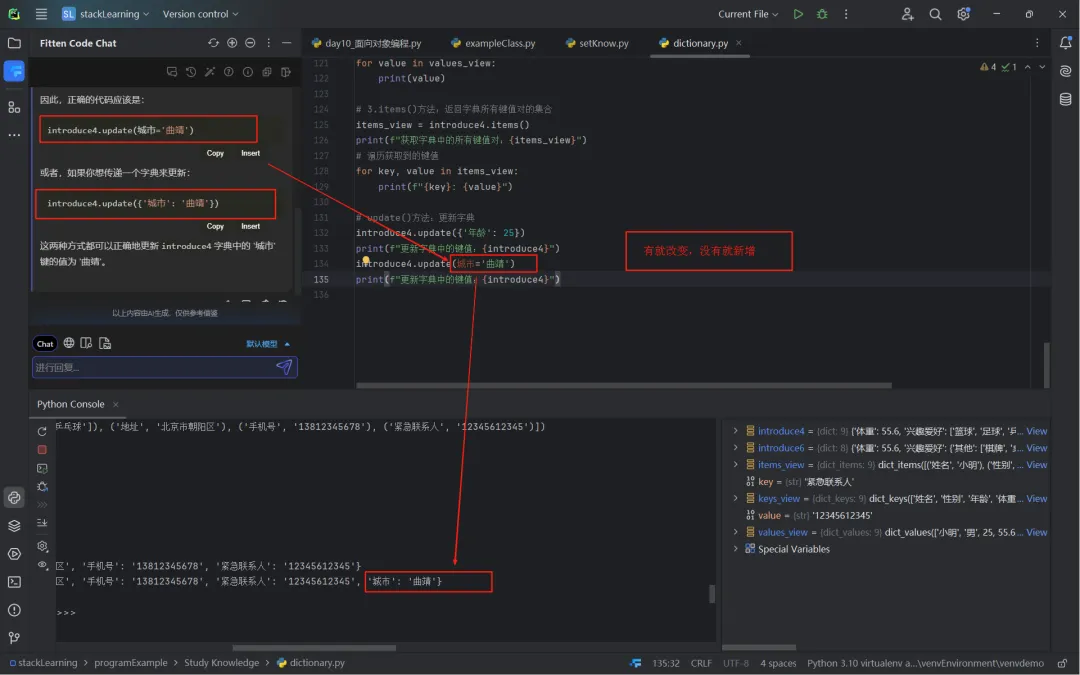
introduce4.update({'职业': '程序员'}),向字典中添加键值对'职业': '程序员';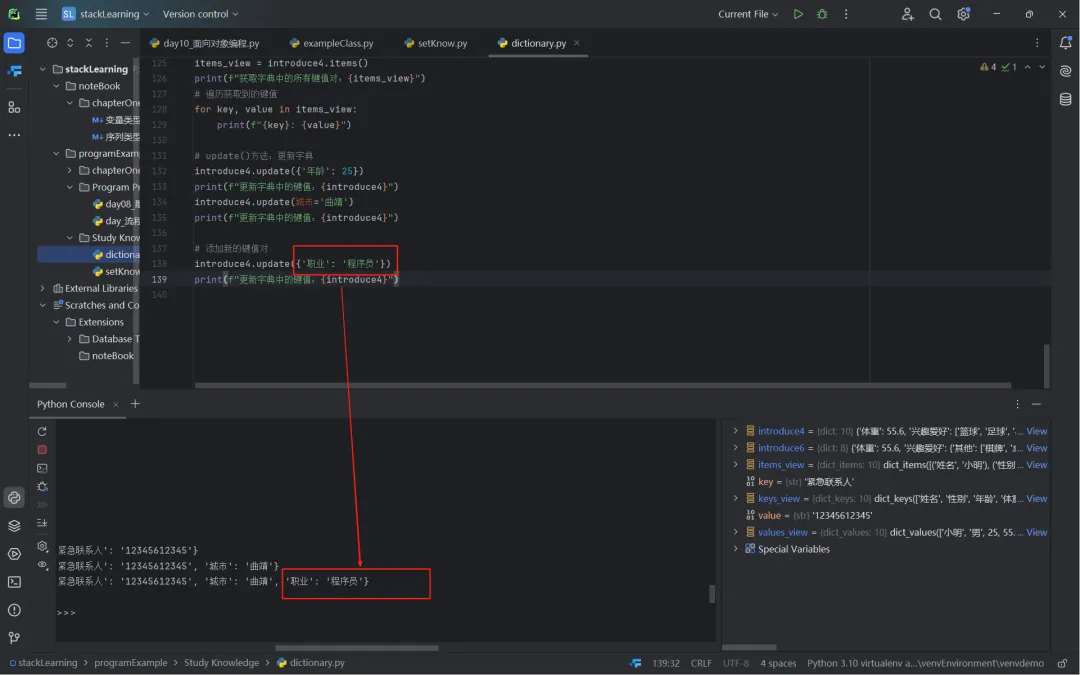
setdefault(key, default=None):若字典中有该键,则返回对应的值,否则就新增,默认的键值为None;value = introduce4.setdefault('年龄'):返回25;value = introduce4.setdefault('薪资','1w'):向字典 introduce4中添加'薪资','1w',并返回1w;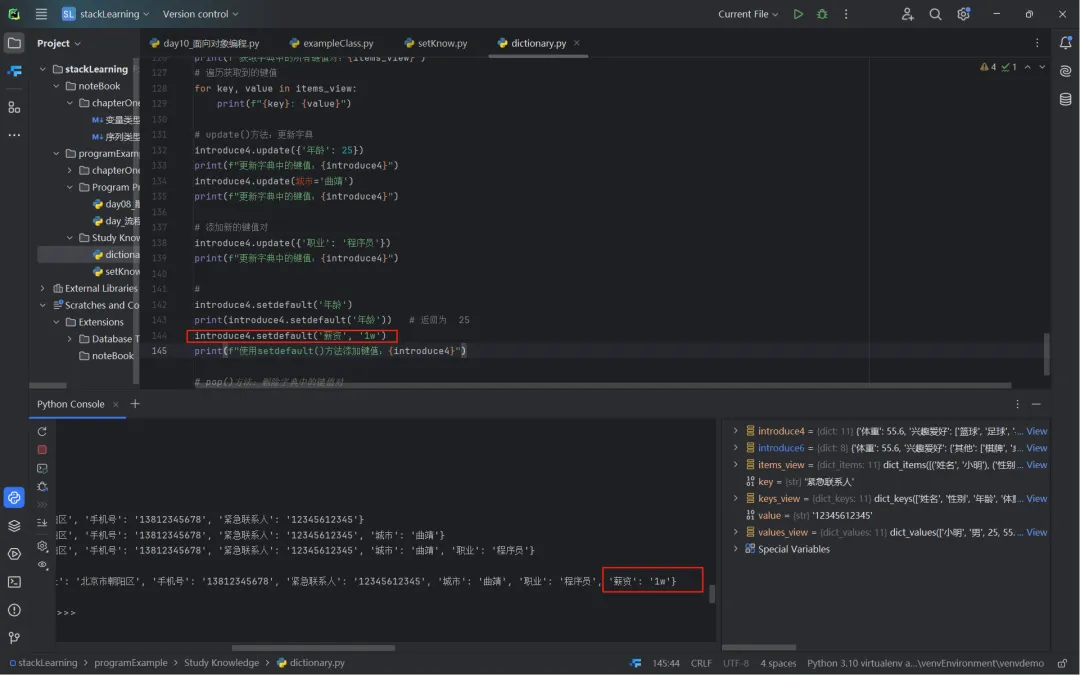
5.3 删除方法
clear():清空字典;introduce4.clear()执行后,字典为空; 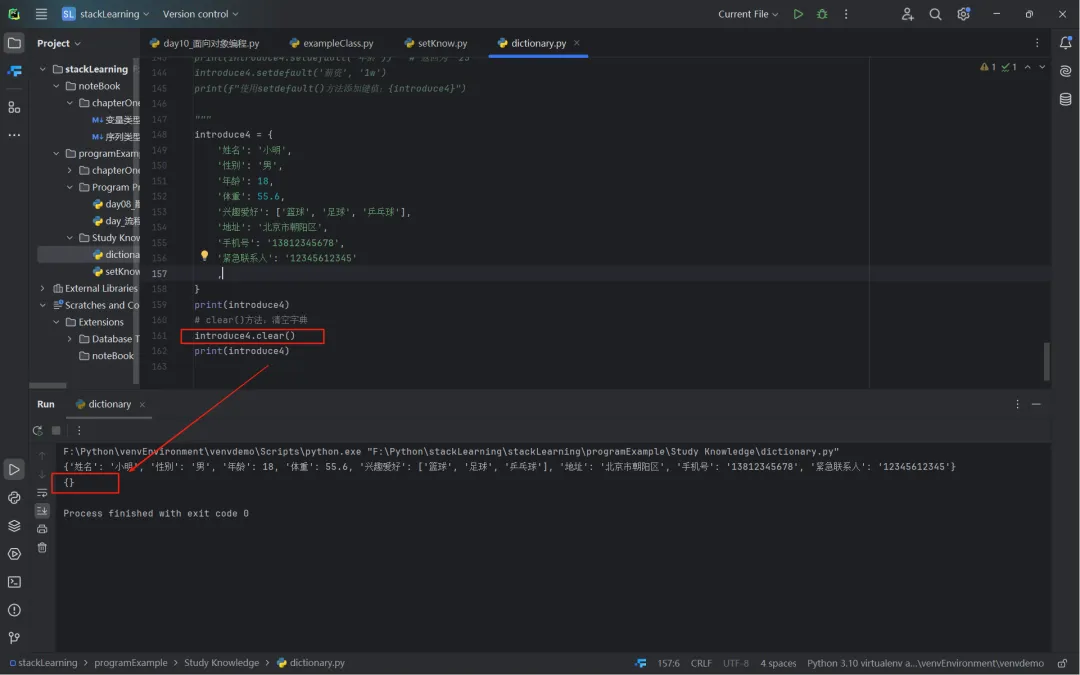
pop(key[, default]):根据键删除对应的键值,并返回被删除的键值,若键不存在且提供了 default,则返回default,否则抛出KeyError;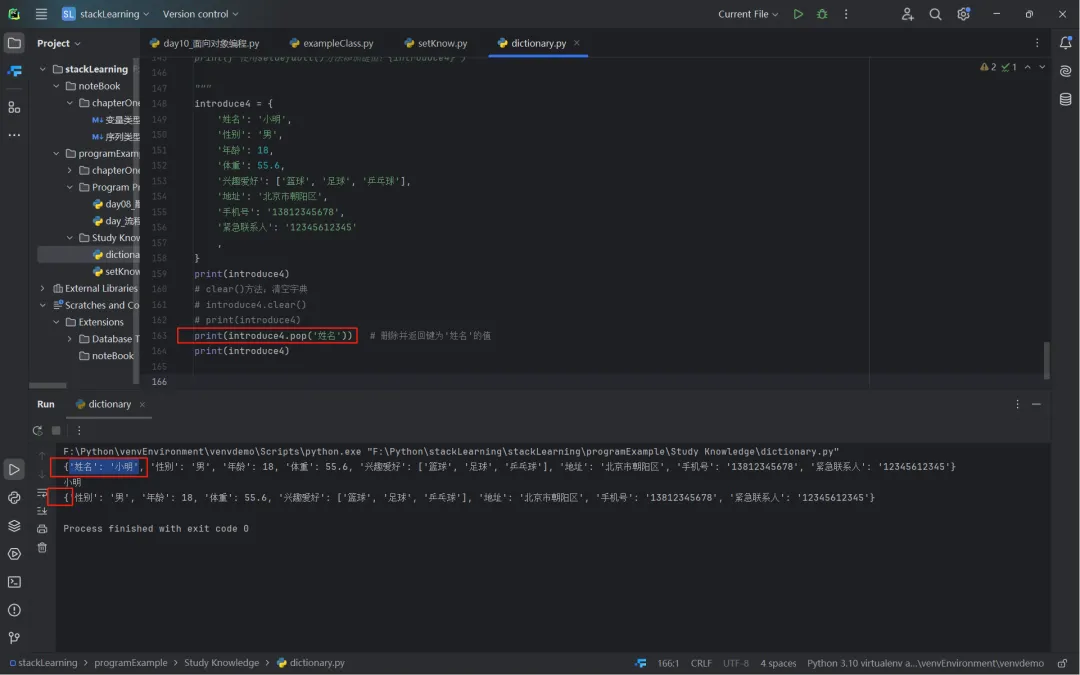
删除没有的就报错 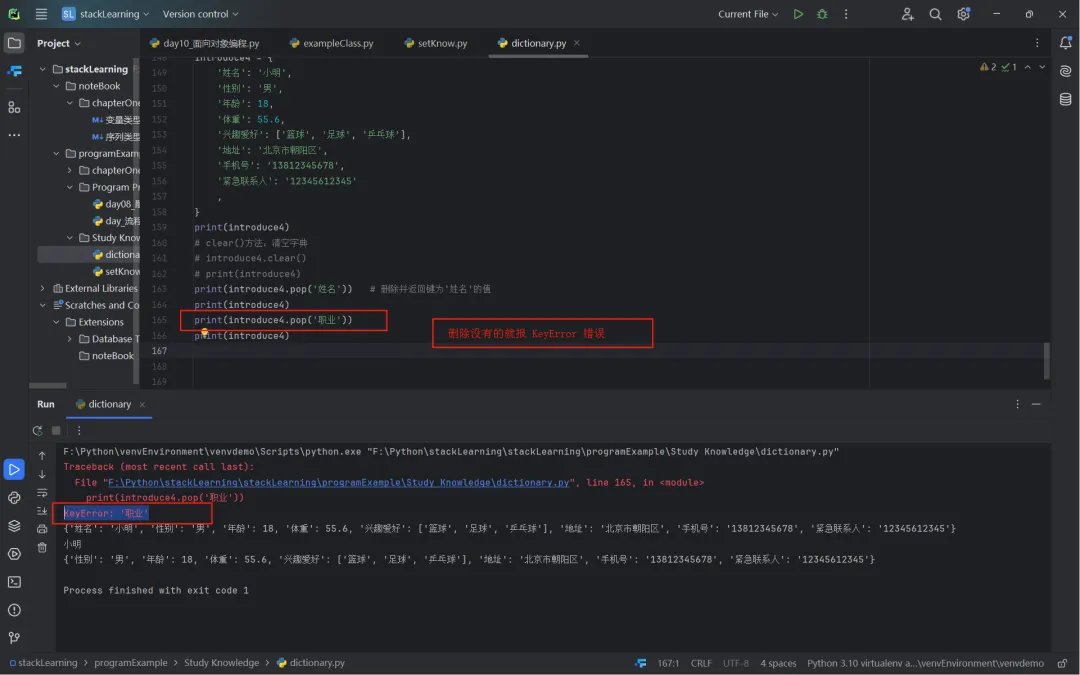
popitem():删除并返回字典中的最后一个键值对(Python 3.7以及以上的版本,是按插入顺序进行删除); 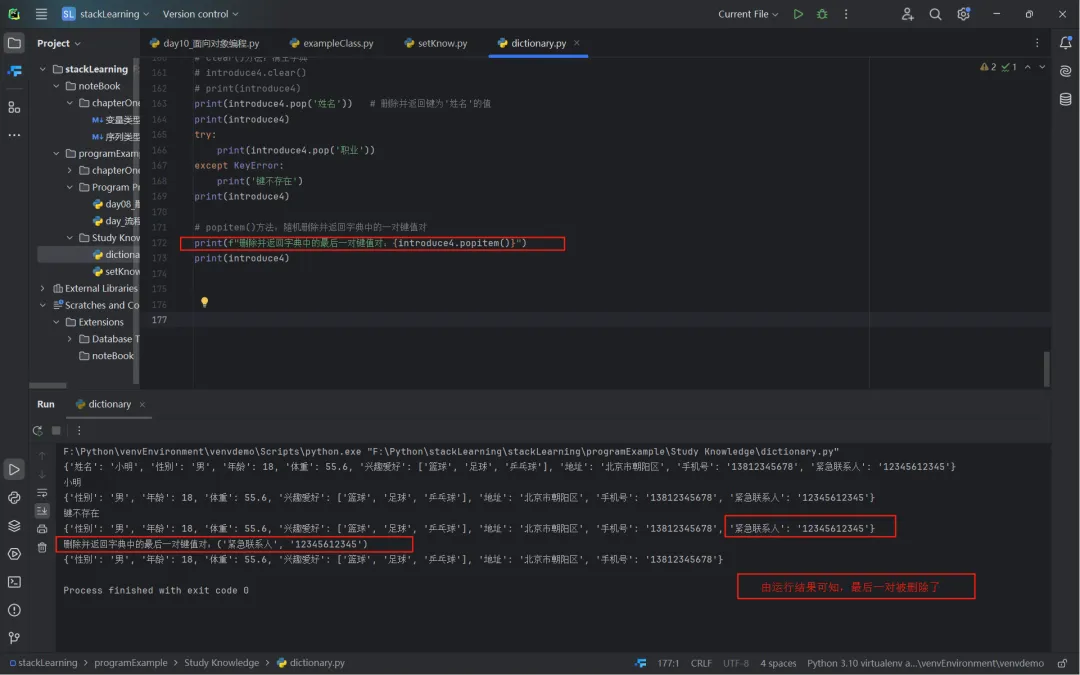
和列表一样,字典也可以使用 del进行删除字典元素,如果由则删除,若没有也会引发KeyError错误;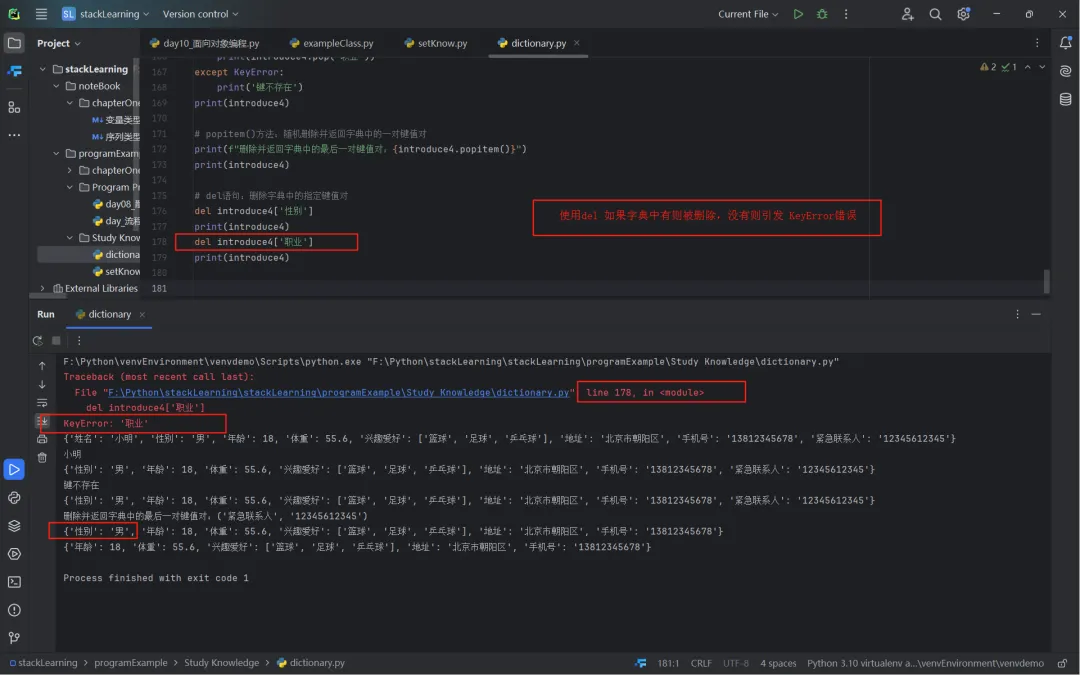
5.4 其他方法
- get(key[, default])
:返回指定键的值。若键不存在,返回 default(默认为 None)。相比之下,直接使用字典[key] 访问不存在的键会抛出 KeyError。例如: name = person.get("name"),返回 “Alice”。salary = person.get("salary", 0),返回 0。- copy():返回字典的浅拷贝。例如:
person_copy = person.copy(),创建 person 字典的副本。- fromkeys(iterable, value=None) :
根据可迭代对象中的元素创建一个新字典,各键对应的值为 value(默认为 None)。例如: keys = ["name", "age", "city"]new_dict = dict.fromkeys(keys)返回 { 'name': None, 'age': None, 'city': None }。new_dict = dict.fromkeys(keys, "default")返回 { 'name': 'default', 'age': 'default', 'city': 'default' }。
6、字典的应用
借用一些简单的例子来说明一下字典在实际中的应用;
输入一段话,统计每个英文字母出现的次数,按出现次数有高到低输出;
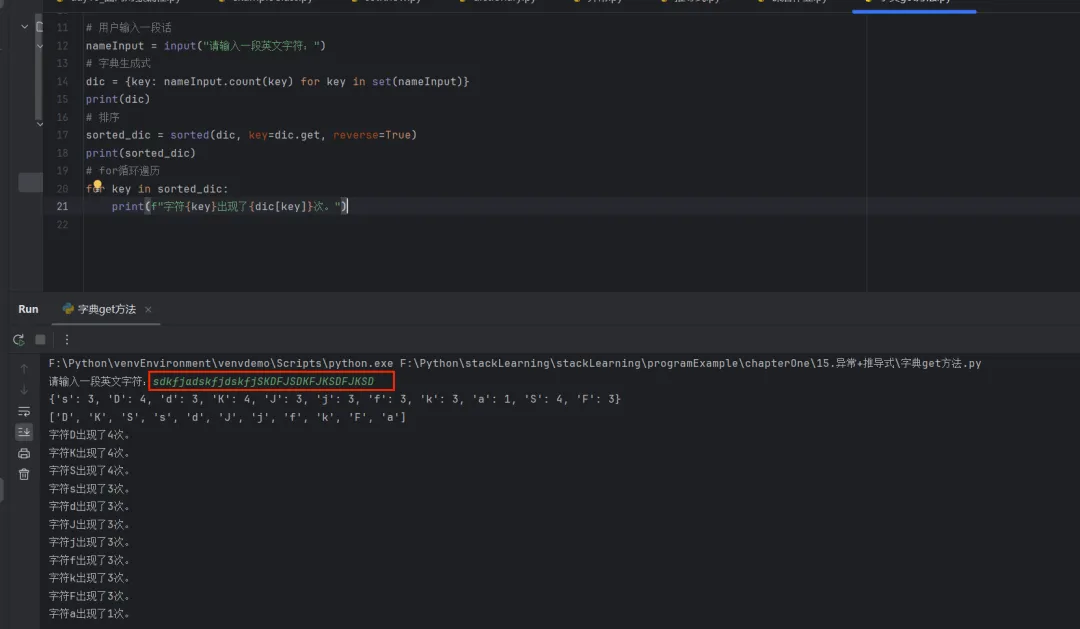
# 用户输入一段话nameInput = input("请输入一段英文字符:")# 字典生成式dic = {key: nameInput.count(key) for key inset(nameInput)}print(dic)# 排序sorted_dic = sorted(dic, key=dic.get, reverse=True)print(sorted_dic)# for循环遍历for key in sorted_dic:print(f"字符{key}出现了{dic[key]}次。")运行结果
上面的集合生成式,也可以用下面的进行替代:
# 定义一个空的字典dicS = {}# 循环遍历,将键和值存到空字典dicS中for i in dd: dicS[i] = dicS.get(i, 0) + 1print(dicS)7、总结
Python 程序中的字典跟现实生活中字典非常像,允许我们以键值对的形式保存数据,再通过键访问对应的值。字典是一种非常有利于数据检索的数据类型,但是需要再次提醒大家,字典中的键必须是不可变类型,列表、集合、字典等类型的数据都不能作为字典的键。
6、文章重点内容:
列表:
列表是可变数据类型,支持动态添加、删除和修改元素。 元素可以是不同类型,支持嵌套列表。 列表操作包括索引、切片、连接(+)、重复(*)、遍历等。 提供多种方法如 append()、extend()、insert()、remove() 等进行元素操作。 列表生成式可以高效、简洁地创建列表。
元组:
元组是不可变数据类型,一旦定义不可修改。 创建简单,支持多种运算,如连接和重复。 打包和解包操作方便数据传递和赋值。
字符串:
字符串是由字符组成的序列,支持索引和切片。 提供丰富的操作如转义字符、原始字符串、大小写转换、查找、替换等。 格式化方法多样,包括 % 操作符、format() 方法和 f-string。
集合:
集合是无序、不重复的元素集合,支持集合运算如交集、并集、差集等。 提供添加、移除元素的方法,支持成员运算和比较运算。
字典:
字典是以键值对形式存储数据的结构,键必须是不可变类型。 支持通过键快速访问值,提供丰富的操作方法如 keys()、values()、items() 等。 可用于模拟现实中的字典,方便数据管理和检索。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 同舟助飞丨Python期末辅导活动回顾
- 教程丨AI+Python驱动的高光谱遥感全链路解析
- Rocky Linux 9.7 系统安装配置(4C8G60G 虚拟机 + 容器化 Zabbix 专属分区配置)
- 爆肝整理!Linux/UNIX 进程间通信(IPC)方式图解
- Linux下如何用C语言解析json文件,含源码
- 为没有Linus的一天做准备!Linux社区敲定接班预案:若维护者不愿干就立刻定替代人选,这事绝不能拖!
- 掌握Linux基础命令,看完这篇就够了
- 每日Python面试题 · 第2期
- 开始Python编程
- 2026 Linux 内核页缓存提权漏洞检测脚本 -- linux-lpe-detect
