大家好,我是木木。
今天给大家分享一个向量化的 Python 库,chromadb。
chromadb
chromadb 是一个面向 AI 应用的开源向量数据库,常用于保存文档 embedding、做语义检索和构建轻量知识库。它可以本地内存运行,也可以持久化或作为服务部署。对 RAG 项目来说,Chroma 的优点是上手快、概念直观;但 embedding 来源、元数据过滤、重建索引和权限隔离仍然要认真设计。
项目地址:https://github.com/chroma-core/chroma
官方文档:https://docs.trychroma.com/
三大特点
语义检索
用向量相似度找相关文本,适合知识库、问答和推荐原型。
本地可跑
内存模式和持久化模式都支持,验证想法时不必先搭复杂服务。
过滤灵活
文档、embedding 和 metadata 可以一起管理,方便做条件检索。
最佳实践
安装方式:pip install chromadb。
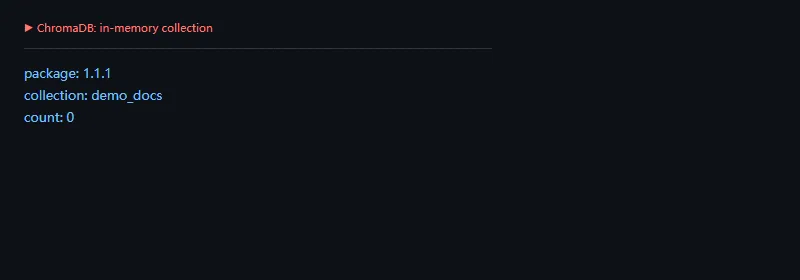
第一段代码解决的问题是:创建一个内存 Chroma 客户端和 collection,先确认集合元信息。
importos,warningsos.environ["PYDANTIC_DISABLE_PLUGINS"]="1"warnings.filterwarnings("ignore")importchromadbfromchromadb.configimportSettingsfromimportlib.metadataimportversionclient=chromadb.Client(Settings(anonymized_telemetry=False,is_persistent=False))collection=client.create_collection("demo_docs",metadata={"hnsw:space":"cosine"})print("package:",version("chromadb"))print("collection:",collection.name)print("count:",collection.count())
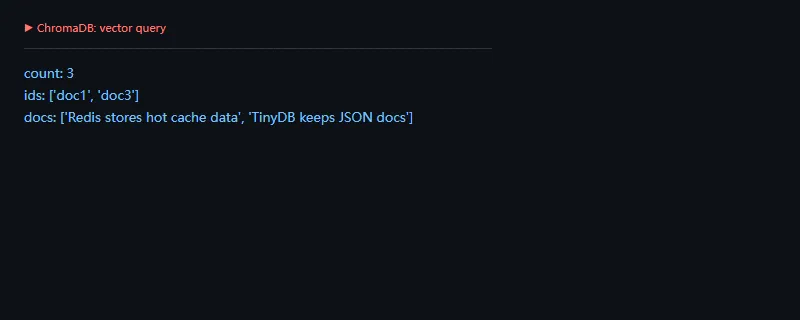
第二段代码解决的问题是:手动写入 embedding 和文档,再用 query embedding 做一次语义检索。
importos,warningsos.environ["PYDANTIC_DISABLE_PLUGINS"]="1"warnings.filterwarnings("ignore")importchromadbfromchromadb.configimportSettingsclient=chromadb.Client(Settings(anonymized_telemetry=False,is_persistent=False))collection=client.create_collection("demo_docs")collection.add(ids=["doc1","doc2","doc3"],documents=["Redis stores hot cache data","DuckDB analyzes local files","TinyDB keeps JSON docs"],embeddings=[[1.0,0.1,0.0],[0.0,1.0,0.1],[0.1,0.0,1.0]],)result=collection.query(query_embeddings=[[1.0,0.0,0.0]],n_results=2)print("count:",collection.count())print("ids:",result["ids"][0])print("docs:",result["documents"][0])
环境与版本信息
本文示例使用 Python 3.11,chromadb 1.1.1。示例关闭遥测并使用内存 collection,embedding 为手写小向量,避免依赖外部模型。
高级功能
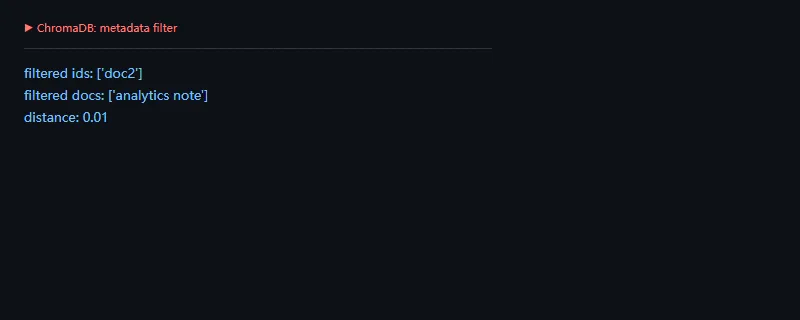
进阶一点看 metadata 过滤。真实知识库里,按租户、来源或业务类型过滤通常和向量相似度一样重要。
importos,warningsos.environ["PYDANTIC_DISABLE_PLUGINS"]="1"warnings.filterwarnings("ignore")importchromadbfromchromadb.configimportSettingsclient=chromadb.Client(Settings(anonymized_telemetry=False,is_persistent=False))collection=client.create_collection("demo_docs")collection.add(ids=["doc1","doc2","doc3"],documents=["cache note","analytics note","local db note"],embeddings=[[1.0,0.1,0.0],[0.0,1.0,0.1],[0.1,0.0,1.0]],metadatas=[{"topic":"cache"},{"topic":"analytics"},{"topic":"local"}],)result=collection.query(query_embeddings=[[0.0,1.0,0.0]],n_results=3,where={"topic":"analytics"},)print("filtered ids:",result["ids"][0])print("filtered docs:",result["documents"][0])print("distance:",round(result["distances"][0][0],4))
适用场景
适合 RAG 原型、文档问答、语义搜索、AI Agent 记忆检索和小团队本地知识库验证。
不适用场景
如果你需要强权限隔离、超大规模多租户、严格审计或复杂混合检索,应该先评估专门的向量数据库和检索系统。
上线检查
- 固定 embedding 模型和维度,避免新旧向量混用。
- 为来源、租户、时间等字段设计 metadata 过滤。
- 准备重建索引和重新 embedding 的离线流程。
总结
chromadb 很适合把“语义检索”快速跑起来。真正上线时,把 embedding、过滤条件和数据生命周期管住就更稳。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
