不会Python、看见代码就头疼——我是怎么做出全自动景观效果图转视频工具的?
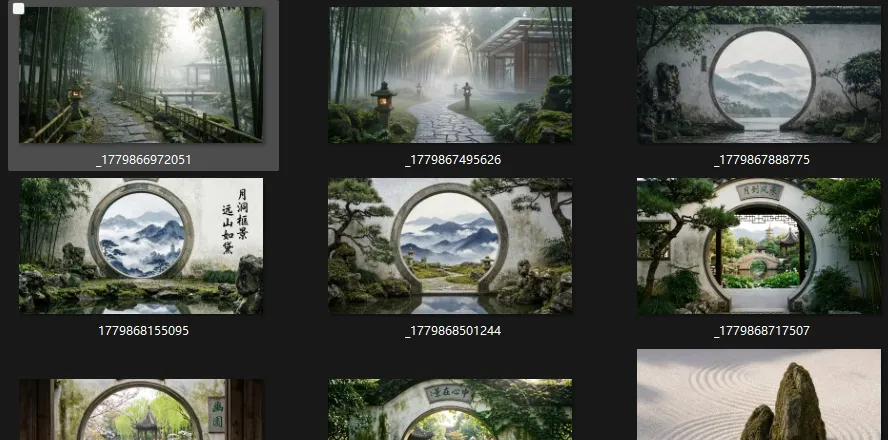
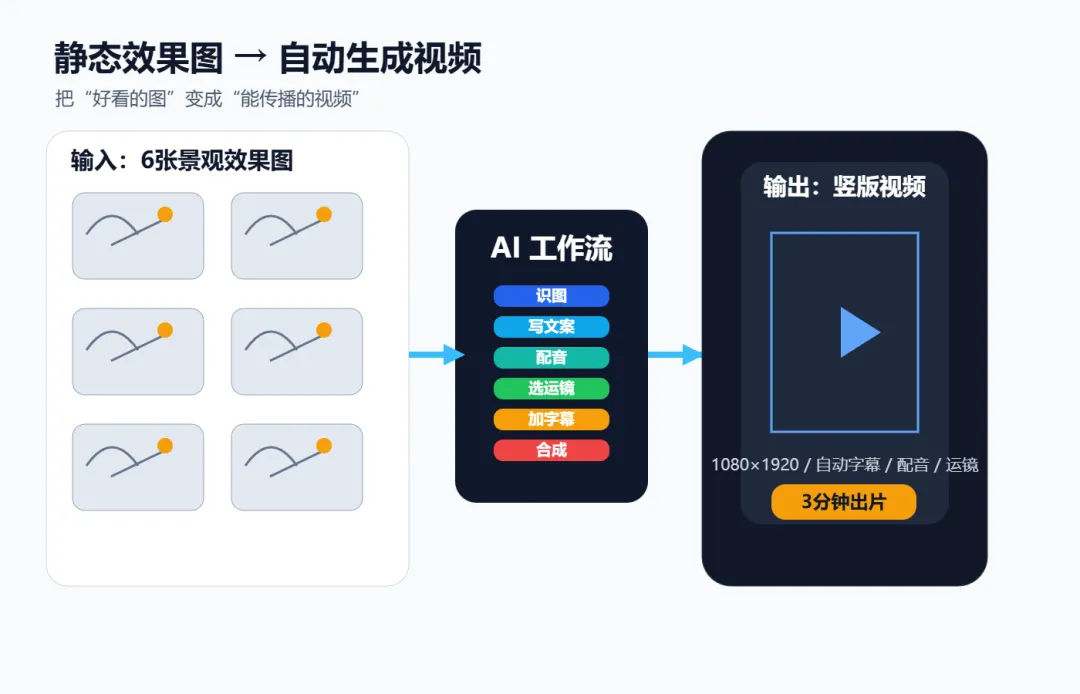
五月的风从窗户灌进来,带着郑州初夏那种干燥的热意。屏幕上是几张刚跑出来的AI景观效果图——月洞门,青石板,远山含黛。光影打得讲究,竹影落在粉墙上,疏疏朗朗的,挺好看。但一张张静态图在AI时代已经没有任何优势了,需要更进一步,图转视频。从事景观行业,太清楚了一条30秒的效果图动画,外包得两千起步。现在没公司、没团队、没预算,对着满屏的图,脑子里只有一个念头——能不能自己做?
1、一张白纸,零行代码
我不是程序员,不是谦虚——是真不是,Python一行没写过。FFmpeg这个名字,两个月前我连听都没听过。那种黑色的命令行窗口,以前在电脑上弹出来,我第一反应是关掉。我清楚一条效果图视频的成片该长什么样。画面从哪开始推,字幕浮上来该落在哪个位置,配音该沉一点还是亮一点,背景音乐什么时候该退到远处,把空间让给人声。这就像在工地上待久了——你不会砌砖,但一眼能看出哪堵墙是歪的。几行FFmpeg命令,六张图硬拼在一起,加个淡入淡出,垫一段背景音乐。没有配音,没有字幕,没有运镜——就是六张图轮流放。但我坐在屏幕前,心里有种说不清的东西。不管多丑、多简陋,它动了。从零到零点一,这一步跨过去了。2、让它能说话
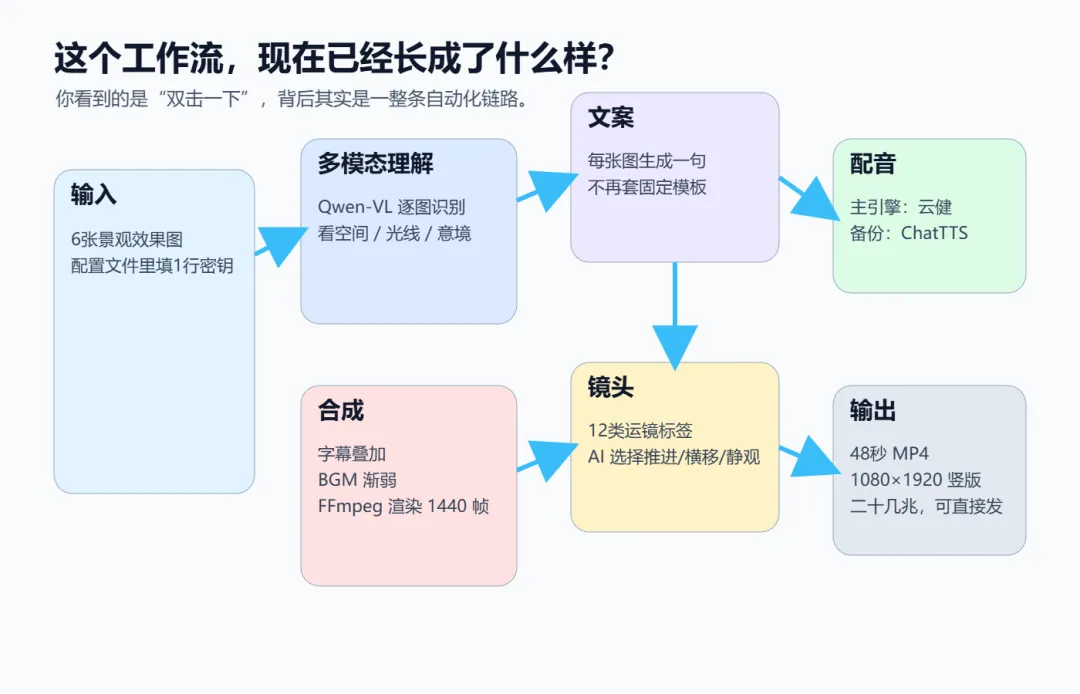
最早试的是Windows自带的语音朗读。你打开过那个吗?像一台机器在念说明书。每个字都念对了,但没有任何一个瞬间让你觉得对面坐着的是一个人。然后找到了ChatTTS。一个本地的深度学习语音模型,一个多G,不需要显卡。它有个"口语风格"的参数。你设好了,它生成出来的声音带着呼吸的停顿、语调的微微起伏。不是念,是说。我戴上耳机听第一段合成出来的语音。深夜,书房只有屏幕亮着。那个声音不紧不慢地说了一句——"月洞如镜,框住一帧江南烟雨"。但ChatTTS偶尔加载失败。有时候跑着跑着,它就罢工了。于是又接了一条备用的路——edge-tts,云端语音合成,永远不掉链子。主引擎倒了,自动切过去。这个"一主一备"的架构,从第一天就搭好了。后来成了整个东西最底下的那层地基。最早的方案是固定模板。六张图,配六句预设的文案。图换了,文案不变。能用,但笨——笨到什么程度呢?一张松竹掩映的庭院图,配的文案是"月洞如镜,远山含黛",可图上根本没有月洞门。现在的多模态大模型不是能看图说话吗?把图片丢给AI——让它自己看画面里有什么,然后自己写一句配得上的文案。
3、让AI替它睁开眼睛
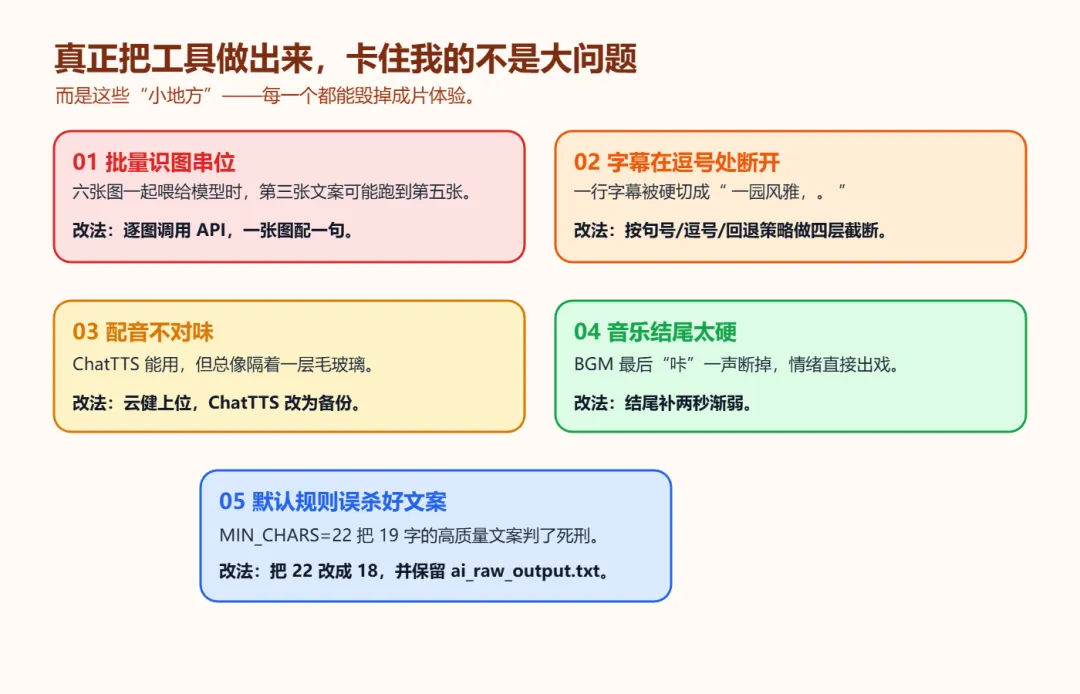
6月5号上午,注册了硅基流动。接入了Qwen-VL——一个能同时理解图片和文字的大模型。给它一张图。它告诉你:近处是月洞门,门框里透出远山,左侧有一枝松斜逸而出,水面有倒影微微晃动,光从右上角泻下来。不只描述,还给你写出来:"月洞如镜,远山含黛,竹影婆娑间,一帧江南烟雨入画。"不是"终于能跑了"——是"这东西居然能跑了"。AI的眼睛,穿过像素,看见了画面里的空间、光线、意境。然后用自己的话,把看懂的写了出来。为了省API调用次数,我一次把六张图全丢进去,让它一口气吐出六句文案。效率是高。可有的时候,第三张图的文案会莫名其妙地安到第五张上面。翻来覆去想了一下午才明白——视觉模型的注意力机制跟语言模型不一样。你在提示词里写"下面六张图",但AI看到的不是六张独立的画面——是一堆像素的集合。"先后顺序"这个人类觉得天经地义的概念,对多模态AI来说,是模糊的。解决办法很简单:一张一张送。每张图独立调一次API,独立生成一句文案。从批量到逐图——后来回头看,这是整个三十个版本里最重要的一次决定。
4、一千个小决定
v3.3到v3.9,三顿饭的间隙里改了七版。这个阶段的核心矛盾不是"能不能做"——能做了。是"做出来的东西对不对味"。AI写的文案,有时候太长了。一行字幕放不下,得截断。最早是在最大字数处硬切。不管三七二十一,一刀下去。于是屏幕上出现了这样的字幕——"一园风雅,。"在逗号处拦腰斩断。断完之后连句号都没了。那行字挂在画面底部,像个没说完就被掐住脖子的句子。于是重写了截断逻辑。不是一刀,是四刀——先找最后一个句号。找不到,往外再探三个字。没有句末标点,退一步用逗号。什么都没有,硬截——但逗号收尾的,自动换成句号。ChatTTS用着顺手,但声音的质地——你仔细听,总觉得隔了一层。像隔着毛玻璃看人。偶然试了edge-tts里的一个声音。叫"云健"。男声,不年轻,也不老。把速度放慢一成,音调压低十赫兹。那不是"读"。是"讲"。不是冷冰冰的播报,是一个人在你对面坐下来,不急不缓地跟你说话。声音里有重量,有停顿,有换气的位置。跟园林的画面——天然长在一起。从这一版开始,配音的主引擎换了。云健上位。ChatTTS退到幕后,做了备胎。同日还加了运镜标签。十二个选项——推镜-缓进、推镜-深推、横移-左展、横移-慢扫、升降-上摇、固定-静观……AI看完一幅图,自己判断:这张适合慢慢地推进去,还是从左往右缓缓扫过,还是安安静静地立在原地不动。以前决定运镜的,是代码算出来的梯度方向和亮度分布——说白了,是数学。现在决定运镜的,是一个看过画面之后的判断——是"导演"。5、魔鬼在细节里
v4.0,六张图全部跑通。配音、运镜、字幕——一条龙下来,看起来一切正常。第一条视频的背景音乐,在结尾"咔"一声断掉。四十八秒的片子,最后那一下,像有人突然关了音响。加了两秒的渐弱——音乐像潮水一样退下去,而不是戛然而止。第二条,手机外放,人声太轻。背景音乐把配音压在了底下。把人声提到一倍半——那个沉稳的声音终于从BGM里浮了上来。画面是砂纹、苔石、禅意庭院——氛围沉静,像日式枯山水里掺了宋代的留白。字幕显示的却是"入园方知深浅,一步一景,景景皆不同"。这不是AI根据本图片生成的,是调用原来的,错乱了!AI真实写的那句话,藏在一个日志文件里。我打开它——"砂纹如禅意流转,苔石静立,心随境远。"十九个字。画面和文字之间,是严丝合缝的。砂纹→禅意流转。苔石→静立。心→随境远。一个不多,一个不少。我给代码设了一个字数下限:AI写出来的文案少于二十二个字,自动判定为"不合格",直接替换成默认文案。AI写出了自己最得意的一句,却被我亲手写的一行代码判了死刑。那一晚我坐在屏幕前,什么也没改。就那么看着那行日志。AI的原文,和我的替换结果,并排放在一起。你知道那是什么感觉吗?像你盖了一堵墙,然后自己在上面凿了一个洞。要不是临时起意加的那个日志文件——ai_raw_output.txt,保存AI的原始输出,不经任何后处理——我可能永远不知道真相。因为我看到的,永远是"替换后"的结果。那晚最大的教训:永远留存原始数据。后处理吃掉的东西,你根本看不见。
6、凌晨两点,四个字符,最后一个数字
同一张砂纹苔石的图,第六张。这次AI写的是"砂纹如涟,苔石立静,心随波纹渐入禅境。"还是十九个字。这个数字,是我某天下午拍脑袋定的——"低于22字的文案,太短了"。没有任何测试数据支撑,就是觉得"应该够了吧"。但现在数据摆在眼前:AI在一定的随机度下,偶尔会写出19到21个字的高质量文案。不是残句,不是应付——是"砂纹如涟,苔石立静",每个字都在点上。降到18?十八个字——大约六个三字词组的排列,是一个完整中文意象的底线。低于十八,确实撑不住一条字幕。凌晨快两点。窗外的天已经开始泛青。重新跑了一次。六张全过。零替换。那张砂纹苔石的图,配上了它该配的那行字。7、现在的它
从五月最后那天连文件夹都没留的"初代版",到六月七号凌晨两点的V4.6版——现在这个东西,是这样的。一个压缩包。解压,往配置文件里填一行密钥,把六张效果图拖进文件夹。双击一下。三分钟后,output目录里躺着一条mp4。48秒。运镜是AI选的,字幕是AI写的,配音是云健念的,配乐在最后两秒像潮水一样退掉。1080乘1920竖版。二十几兆。每条视频背后:AI调了六次多模态接口。语音合成了六段。FFmpeg渲了1440帧画面。如果你也是做景观的,手头正好有一套效果图......
砍下来,小心剃掉竹枝,不能伤到竹皮,伤皮就废了。然后用石头压住,晒几天,等它变直、变干、变轻。做好后往塘边一坐,钓不钓得到鱼其实不是最重要的。重要的是手里握着的那个东西——从头到尾,是你的。后来在工地指导工人叠假山,一块石头放上去,不对,换,再放,还是不对,再换,第三块放上去,"咔"一声,严丝合缝。不是重量对了——是那块石头的纹路,跟旁边那块搭上了。不断改,不断试,不断推翻重来,最后那个东西跑通了——六张图变成一条视频——那一刻的感觉,跟坐在塘边握着那根刚竹鱼竿,是一样的。十天迭代三十个版本,一条成品视频;一个星期,一根鱼竿。以前同事常问我:能不能做一条视频?我说能,需要时间。选BGM、调节奏、对齐字幕——一条30秒的片子坐一下午,是常事。
能看到这都是凤毛麟角的存在,如果觉得不错,随手点个赞、在看、转发三连吧,如果需要这个进阶版工具包,给我个星标⭐,私信我~谢谢您看我的文章,我们,下次再见。
专注AI时代下的景观迭代,如何打通景观人的OPC,做有温度、有本源、有思考的行业分享。如果你也在关注AI怎么改变设计、怎么改变内容创作,欢迎留言聊聊。




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
