Python语法日报 第10期|Excel自动化开篇——行列操作与遍历,批量操作不香吗?
- 2026-07-01 21:12:16
Python语法日报 第10期|Excel自动化开篇——行列操作与遍历,批量操作不香吗?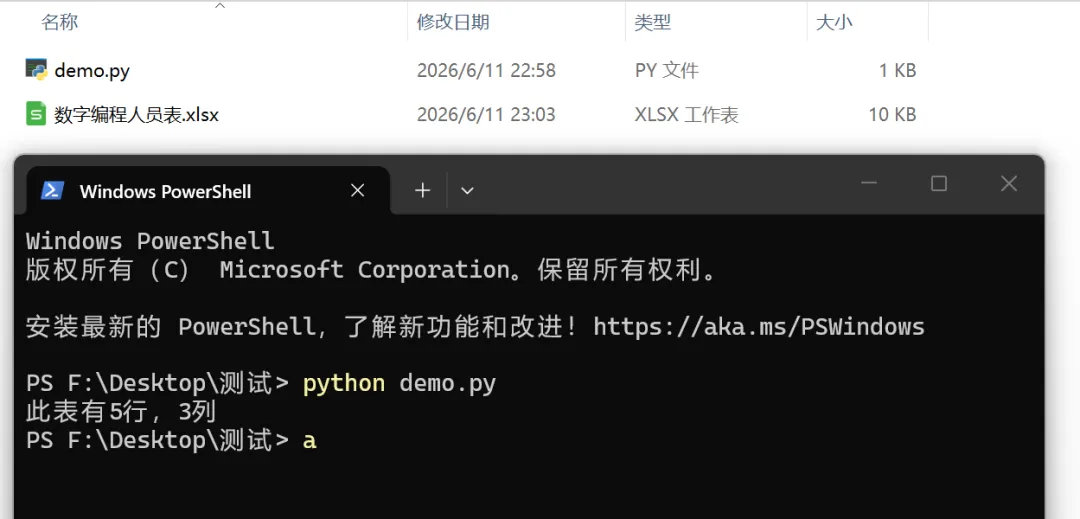
后台回复 001 ,直接拿Python全套学习资料、办公脚本、实战代码,拿走就能用。
15款使用办公自动化脚本 批量调整图片尺寸及大小 PDF批量输出图片 批量提取Word文件中的图片 秒拆分几万行Excel表格数据 批量提取PDF文件中的文字 批量提取PDF文件中的图片 批量Word转PDF 批量改名几百个文件 合并PDF别再傻傻充会员了 图片转PDF还要花钱?
断更了快俩月?罪过罪过。今天赶紧补上,咱接着上期的
openpyxl,把一行一列、整个表格批量读写整明白。
一、上期回顾:已会读一个格子
上期干了三件事:装库、读一个格子、写一个格子。但现实中谁TM只操作一个格子?几百行数据,一个一个弄会累死。今天就讲 一次性拿到整行、整列、甚至整个表的数据。
二、准备个有模有样的Excel
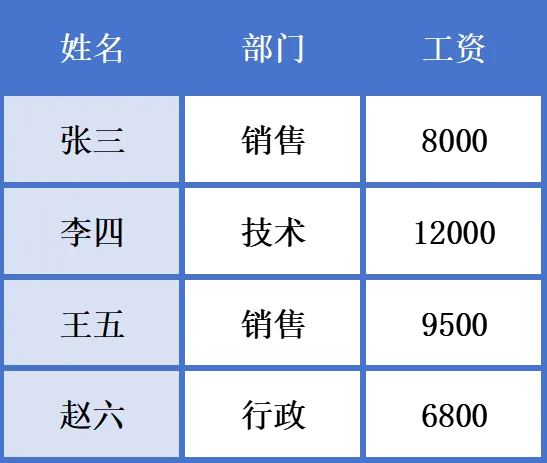
比如(数字编程人员表.xlsx):
三、整总行数和总列数
from openpyxl import load_workbookwb = load_workbook('数字编程人员表.xlsx')ws = wb.activerows = ws.max_row # 总共多少行(包括表头)cols = ws.max_column # 总共多少列print(f'此表有{rows}行,{cols}列')输出:此表有5行,3列。max_row 和 max_column 是openpyxl自动算的,比肉眼数快一万倍。如图所示:
四、拿到整行或整列的数据
# 拿第一行(表头)row1 = []for cell in ws[1]: row1.append(cell.value)print('第一行:', row1)# 拿B列(部门列)col_b = []for cell in ws['B']: col_b.append(cell.value)print('B列:', col_b)ws[1] 是行号索引(从1开始),拿到这一行所有格子对象,再取 .value。ws['B'] 是整列,同理。更简洁的写法(列表推导式):
row1 = [cell.value for cell in ws[1]]col_b = [cell.value for cell in ws['B']]五、遍历整个表格:iter_rows 是亲爹
上面拿整行整列还行,但如果想跳过表头只拿数据,或者只拿某几列,用 iter_rows。
for row in ws.iter_rows(min_row=2, values_only=True): name, dept, salary = row # 每行是个元组,直接拆包print(f'{name} 在 {dept} 部门,工资 {salary}')解释:
min_row=2表示从第二行开始(跳过了表头)。values_only=True直接返回格子的值,而不是格子对象。不加这个拿到的是Cell对象,还得再取.value,多费一道手。每行是一个元组,可以直接用三个变量接住。
如果想控制列范围,加 min_col 和 max_col:
for row in ws.iter_rows(min_row=2, min_col=1, max_col=2, values_only=True): name, dept = rowprint(name, dept)六、写入数据到整列或整行
比如:给所有人加500块工资。先把工资列(C列)的数据读出来,改完再写回去。
wb = load_workbook('数字编程人员表.xlsx')ws = wb.active# 从第二行开始,遍历C列for row in range(2, ws.max_row + 1): old = ws.cell(row, 3).value # 第3列是工资 ws.cell(row, 3).value = old + 500wb.save('数字编程人员表_涨薪.xlsx')用了 ws.cell(row, col),行列号从1开始。也可以直接写 ws[f'C{row}'],但 cell 更直观。一次性写入多行:用 append 在末尾追加。
new_rows = [ ['孙七', '技术', 10500], ['周八', '销售', 7200]]for r in new_rows: ws.append(r)wb.save('数字编程人员表_追加.xlsx')七、实战:统计部门平均工资
把前面学的串起来:
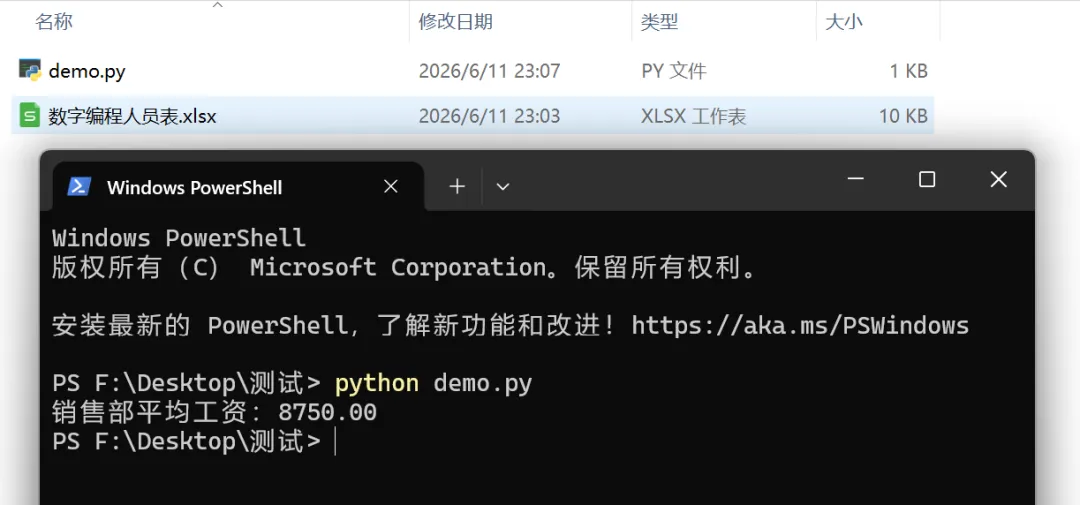
from openpyxl import load_workbook # 切记先导入wb = load_workbook('数字编程人员表.xlsx')ws = wb.activetotal = 0count = 0for row in ws.iter_rows(min_row=2, values_only=True): name, dept, salary = rowif dept == '销售': total += salary count += 1if count > 0: avg = total / countprint(f'销售部平均工资:{avg:.2f}')else:print('没有销售部的人')运行结果如图:
八、今日知识点打包带走

九、下期预告
单元格样式与公式——加粗、标红、求和、平均,让表格看起来像回事儿。老板看了想给你涨薪的那种哈。
觉得有用、看着顺手,记得点个赞、转一圈,收个藏,支持下继续更!
 想学习,拓展自己知识可以点进相应精选,查看代码解释和思路逻辑:
想学习,拓展自己知识可以点进相应精选,查看代码解释和思路逻辑:
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

