是不是总羡慕 CNS 顶刊里那些既展示数据全貌、又透着高级感的统计图?📊✨
明明是同样的数据,别人画出来是“艺术品”🎨,我们画出来却是平平无奇的柱状图。
别急,今天就用两段 Python 代码,带你复刻顶刊里出镜率超高的
云雨图(Raincloud Plot)⛅ 和分位数连接对齐图🔗,让你的下一篇文章配图瞬间提升格调!📈
☁️🌧️ 云雨图:三合一信息黄金组合
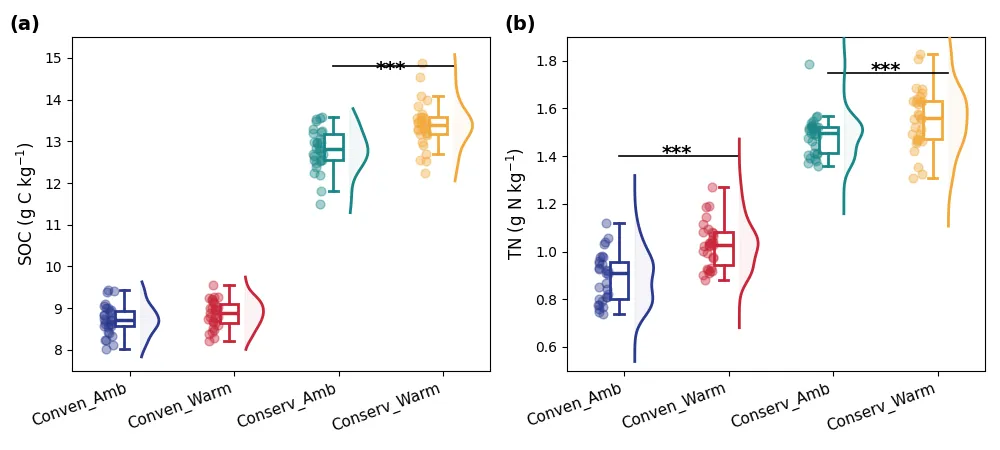
云雨图其实是一个“组合拳”💪——它把散点 + 箱线图 + 半边小提琴密度图放在一起。
顶刊论文常用它来同时对比多个组别,例如不同处理下的土壤有机碳(SOC)🌱 或总氮(TN)含量。下面我们就用 Python 的matplotlib把它画出来。👀数据运用随机数替代:
🐍 核心代码思路
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import gaussian_kdenp.random.seed(42)n_samples = 30groups = ['Conven_Amb', 'Conven_Warm', 'Conserv_Amb', 'Conserv_Warm']data_f = { 'Conven_Amb': np.random.normal(8.8, 0.4, n_samples), 'Conven_Warm': np.random.normal(8.9, 0.35, n_samples), 'Conserv_Amb': np.random.normal(12.8, 0.5, n_samples), 'Conserv_Warm': np.random.normal(13.4, 0.6, n_samples)}data_g = { 'Conven_Amb': np.random.normal(0.9, 0.1, n_samples), 'Conven_Warm': np.random.normal(1.0, 0.1, n_samples), 'Conserv_Amb': np.random.normal(1.48, 0.08, n_samples), 'Conserv_Warm': np.random.normal(1.55, 0.12, n_samples)}colors = ['#2B3A8F', '#C82538', '#1A8787', '#F2A93B']def draw_raincloud(ax, data_dict, ylabel, ylims, sig_pairs): for i, grp in enumerate(groups): y = data_dict[grp] x_base = i # 抖动散点 x_jitter = x_base - 0.2 + np.random.uniform(-0.05, 0.05, len(y)) ax.scatter(x_jitter, y, color=colors[i], alpha=0.4, s=40, zorder=1) # 箱线图 box = ax.boxplot(y, positions=[x_base - 0.05], widths=0.18, patch_artist=True, showfliers=False, zorder=2) plt.setp(box['boxes'], facecolor='none', edgecolor=colors[i], linewidth=2) plt.setp(box['whiskers'], color=colors[i], linewidth=2) plt.setp(box['caps'], color=colors[i], linewidth=2) plt.setp(box['medians'], color=colors[i], linewidth=2.5) # 半边小提琴 (KDE) kde = gaussian_kde(y) y_grid = np.linspace(y.min() - 0.2, y.max() + 0.2, 100) kde_val = kde(y_grid) kde_val = (kde_val / kde_val.max()) * 0.18 ax.plot(x_base + 0.1 + kde_val, y_grid, color=colors[i], linewidth=2, zorder=3) ax.fill_betweenx(y_grid, x_base + 0.1, x_base + 0.1 + kde_val, color=colors[i], alpha=0.05) ax.set_xticks(range(len(groups))) ax.set_xticklabels(groups, rotation=20, ha='right', fontsize=11) ax.set_ylabel(ylabel, fontsize=12) ax.set_ylim(ylims) for p1, p2, h, line_h in sig_pairs: ax.plot([p1 - 0.05, p2 + 0.1], [h, h], color='black', linewidth=1.2) ax.text((p1 + p2) / 2, line_h, '***', ha='center', va='bottom', color='black', fontsize=14, weight='bold')fig1, (ax_f, ax_g) = plt.subplots(1, 2, figsize=(10, 4.5))draw_raincloud(ax_f, data_f, "SOC (g C kg$^{-1}$)", (7.5, 15.5), [(2, 3, 14.8, 14.5)])ax_f.text(-0.15, 1.02, '(a)', transform=ax_f.transAxes, fontsize=14, weight='bold')draw_raincloud(ax_g, data_g, "TN (g N kg$^{-1}$)", (0.5, 1.9), [(0, 1, 1.4, 1.37), (2, 3, 1.75, 1.72)])ax_g.text(-0.15, 1.02, '(b)', transform=ax_g.transAxes, fontsize=14, weight='bold')plt.tight_layout()plt.show()
只需调节x_base的偏移量,就能将三个元素无缝拼接在一起。🧩 再添上显著星号(***)⭐ 和个性配色 🎨,你的第一幅顶刊风格云雨图就诞生啦!🎉🔗 分位数连接对齐图:比较两个分布的神器
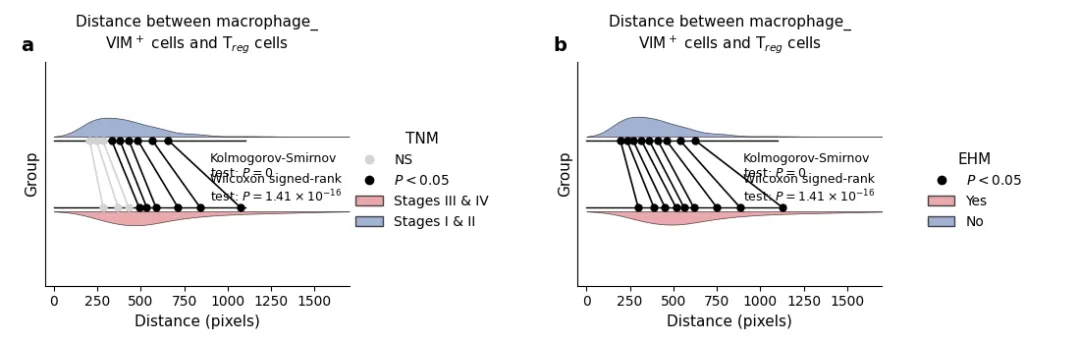
有时候我们不仅要对比均值,还要看整个分布形状的差异——比如肿瘤微环境中 🧬,不同分期下免疫细胞间的“距离”分布是否右偏、是否集中。
这时候,镜像密度曲线 + 分位数连线的图形就派上用场了!
这种图的上半部分是组1的核密度曲线,下半部分是组2的核密度曲线(翻转)🔄,中间用连线把相同分位数的点连起来。如果两条线对应的分位数点很靠近,连线就比较短,说明分布相似;偏离大的分位数点则能一眼看出差异位置。👀数据运用随机数替代:
🐍 核心代码思路
import numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom scipy.stats import gaussian_kdefrom matplotlib.patches import Patchfrom matplotlib.lines import Line2Dnp.random.seed(42)n_dist_samples = 200dist_blue = np.random.chisquare(df=4, size=n_dist_samples) * 80 + 100dist_pink = np.random.chisquare(df=5, size=n_dist_samples) * 95 + 150def draw_quantile_alignment(ax, d1, d2, label_top, label_bottom, legend_title): kde1 = gaussian_kde(d1) kde2 = gaussian_kde(d2) x_grid = np.linspace(0, 1700, 500) # 上半部分密度 (蓝) ax.fill_between(x_grid, 0.5, 0.5 + kde1(x_grid) * 120, color='#7A92C3', alpha=0.7, edgecolor='black', linewidth=0.5) # 下半部分密度 (粉) ax.fill_between(x_grid, -0.5, -0.5 - kde2(x_grid) * 120, color='#E2858A', alpha=0.7, edgecolor='black', linewidth=0.5) # 基准线 ax.plot([0, 1100], [0.45, 0.45], color='black', linewidth=1) ax.plot([0, 1100], [-0.45, -0.45], color='black', linewidth=1) quantiles = np.linspace(0.1, 0.9, 9) q1_vals = np.percentile(d1, quantiles * 100) q2_vals = np.percentile(d2, quantiles * 100) for i, (q1, q2) in enumerate(zip(q1_vals, q2_vals)): is_ns = i < 3 and legend_title == "TNM" line_color = '#D3D3D3' if is_ns else 'black' marker_color = '#D3D3D3' if is_ns else 'black' ax.plot([q1, q2], [0.45, -0.45], color=line_color, linewidth=1.2, marker='o', markersize=5, markerfacecolor=marker_color, markeredgecolor=marker_color) ax.set_xlabel("Distance (pixels)", fontsize=11) ax.set_ylabel("Group", fontsize=11) ax.set_xlim(-50, 1700) ax.set_ylim(-1.5, 1.5) ax.set_yticks([]) ax.text(900, 0.1, "Kolmogorov-Smirnov\ntest: $P = 0$", fontsize=9, va='center') ax.text(900, -0.2, "Wilcoxon signed-rank\ntest: $P = 1.41 \\times 10^{-16}$", fontsize=9, va='center') if legend_title == "TNM": legend_elements = [ Line2D([0], [0], marker='o', color='none', markerfacecolor='#D3D3D3', markeredgecolor='#D3D3D3', label='NS'), Line2D([0], [0], marker='o', color='none', markerfacecolor='black', markeredgecolor='black', label='$P < 0.05$'), Patch(facecolor='#E2858A', edgecolor='black', alpha=0.7, label=label_bottom), Patch(facecolor='#7A92C3', edgecolor='black', alpha=0.7, label=label_top) ] else: legend_elements = [ Line2D([0], [0], marker='o', color='none', markerfacecolor='black', markeredgecolor='black', label='$P < 0.05$'), Patch(facecolor='#E2858A', edgecolor='black', alpha=0.7, label=label_bottom), Patch(facecolor='#7A92C3', edgecolor='black', alpha=0.7, label=label_top) ] ax.legend(handles=legend_elements, loc='center right', title=legend_title, frameon=False, bbox_to_anchor=(1.5, 0.2), fontsize=10, title_fontsize=11)fig2, (ax_g2, ax_h) = plt.subplots(1, 2, figsize=(11, 3.5))draw_quantile_alignment(ax_g2, dist_blue, dist_pink, "Stages I & II", "Stages III & IV", "TNM")ax_g2.set_title("Distance between macrophage_\nVIM$^+$ cells and T$_{reg}$ cells", fontsize=11, pad=10)ax_g2.text(-0.08, 1.05, 'a', transform=ax_g2.transAxes, fontsize=14, weight='bold')draw_quantile_alignment(ax_h, dist_blue * 0.95, dist_pink * 1.05, "No", "Yes", "EHM")ax_h.set_title("Distance between macrophage_\nVIM$^+$ cells and T$_{reg}$ cells", fontsize=11, pad=10)ax_h.text(-0.08, 1.05, 'b', transform=ax_h.transAxes, fontsize=14, weight='bold')sns.despine(left=False, bottom=False)plt.tight_layout()plt.show()
🧵 绘图关键步骤
计算核密度📐:用gaussian_kde获得平滑密度。
绘制镜像密度🪞:上面用fill_between填充正值区域,下面用负值区域并翻转,形成对称效果。
连接分位点🔗:取 10%~90% 分位数,在两个密度曲线上定位并用直线连接,根据统计检验(如 KS 检验)用不同颜色标注是否显著 🔴⚫。
给一组对比加上“NS”(不显著) 灰色标记 ⚪,另一组显著标黑色 ⚫,再配上手工定制 Legend 🏷️,一张美观又信息密集的分布对比图即刻完成。
🤔 为何科研绘图要这么“卷”?
✅审稿人友好🤝:数据展示更透明,避免单纯柱状图掩盖分布差异。
✅一图多用💡:一张云雨图可同时替代散点图、箱线图和直方图,节约版面。
✅故事感强📖:分位数连接图能清晰叙述“在哪段分布上不同”,让统计差异变得可视化。
这两类图形尤其适合环境科学 🌍、生物医学 🧪、心理学 🧠 等领域中需要展示多组、非正态数据的场景。
📦 拿来即用的完整代码
觉得有用的话,点个「在看」👍 或转发给同门,一起卷起来~
我们下一个小技巧见 👋😊
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
