你往文件里写数据,write() 返回的时候,数据真的落盘了吗?
没有。数据只是从用户态拷贝到了页缓存(page cache),真正的磁盘 I/O 是内核自己异步干的。这个机制叫"延迟写"(write-back),几乎所有现代操作系统都用。
但有个问题:页缓存里的脏页(被修改过还没写盘的数据)总得找个时机刷回磁盘。什么时候刷?谁来刷?刷多少?这几个问题直接关系到你的程序会不会被莫名阻塞。
我第一次在生产环境遇到这个问题,是一个 Java 服务突然卡了 3 秒,top 看到 kworker 占满了一个 CPU,dmesg 里一行:blocked for more than 120 seconds。排查半天才发现是脏页积压太多,触发了同步回写。
脏页从哪来
先看一个最基本的写操作:
$ echo "hello" > test.txt
$ grep -A5 "Dirty:" /proc/meminfo
Dirty: 4 kB
Writeback: 0 kB
Dirty 就是当前内存中已修改但还没写盘的页大小。每个 4KB 页被用户态 write() 修改后,就会被标记为脏页。
内核怎么跟踪?每个页对应的 struct page 有一个标志位:
// include/linux/page-flags.h
enum pageflags {
PG_locked, // 页被锁定
PG_referenced, // 最近被访问过
PG_uptodate, // 页内容有效
PG_dirty, // 脏页标志!这个页被修改过,需要回写
PG_writeback, // 正在被回写到磁盘
PG_reclaim, // 正在被回收
...
};
PG_dirty 这个位一旦被设置,这个页就上了"待回写"的名单。
三条触发路径
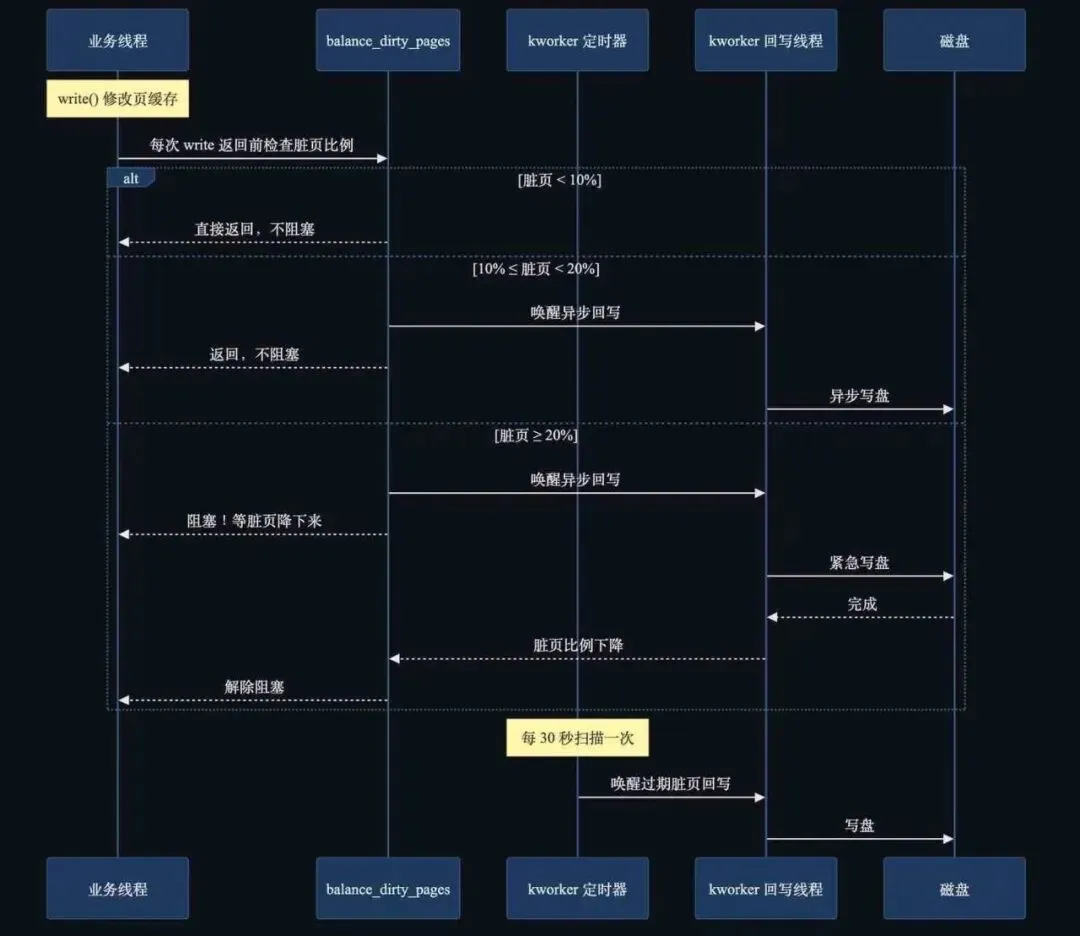
脏页不会一直待在内存里。内核设计了三条路径来决定"什么时候刷",每条路径都涉及两个角色:谁来检测、谁来执行。
回写的执行者统一是 kworker——内核工作线程池里的线程,每个磁盘(bdi 设备)对应一个 bdi_writeback 实例。你用 ps 看到的 kworker/u16:1 之类就是它在干活:
$ ps -ef | grep kworker | head -3
root 281 2 0 Jun19 ? 00:00:12 [kworker/u16:1+events_unbound]
root 457 2 0 Jun19 ? 00:00:03 [kworker/0:1H+kintegrityd]
检测者有两个:你的业务线程自己,和 kworker 的定时器。三条路径就是这两拨检测者分工的结果。
先看两个关键阈值:
$ cat /proc/sys/vm/dirty_background_ratio
10
$ cat /proc/sys/vm/dirty_ratio
20
这是百分比,对应脏页占总内存的比例。16GB 内存的机器,10% 就是 1.6GB,20% 是 3.2GB。
路径一:脏页到 10%,后台异步回写
谁检测:两拨人都在查这个阈值。
你的业务线程每次调 write(),内核在返回前会调 balance_dirty_pages() 检查脏页比例。同时 kworker 的定时器每 5 秒(dirty_writeback_centisecs = 500 厘秒)也扫一次,同样查这个 10% 阈值。
不管是谁先发现脏页超了 10%,都会唤醒 kworker 开始异步回写。这个回写在后台默默进行,不阻塞任何进程。
// mm/page-writeback.c(简化逻辑)
void balance_dirty_pages(struct bdi_writeback *wb)
{
unsigned long nr_dirty = global_node_page_state(NR_FILE_DIRTY);
if (nr_dirty < background_thresh) {
return; // 没超 10%,啥也不干
}
// 超 10%,唤醒 kworker 异步回写
wb_start_background_writeback(wb);
}
路径二:脏页到 20%,阻塞写进程
谁检测:只有业务线程自己查这个阈值。
当脏页达到 dirty_ratio(默认 20%),新发起 write() 的进程会被阻塞(已经在执行的进程不受影响),直到脏页比例降下来。这就是我那个 Java 服务卡 3 秒的原因。
// balance_dirty_pages 续
if (nr_dirty < dirty_thresh) {
return; // 没超 20%,路径一已经处理了
}
// 超 20%,唤醒 kworker + 阻塞自己
wb_start_background_writeback(wb);
wait_until_dirty_limit(wb); // 当前线程在这里被挂起
所以你的 write() 卡住,不是回写线程在阻塞你,是你自己的线程在 balance_dirty_pages 里等脏页降下来。
路径三:脏页超过 30 秒,强制回写
谁检测:kworker 定时器。
不管脏页比例多低,一个脏页如果超过 30 秒还没被刷,kworker 也会强制回写。这个时间由 dirty_expire_centisecs 控制:
$ cat /proc/sys/vm/dirty_expire_centisecs
3000
3000 百分之一秒 = 30 秒。这是兜底,防止脏页在内存里待太久——比如你的程序写完数据就不再写了,路径一和路径二都不会触发,只能靠路径三来收尾。
这里有个值得单独提的隐藏场景:直接内存回收(Direct Reclaim)也会触发回写。
系统内存紧张时,内核会主动扫描冷页腾空间。扫描过程中如果遇到脏页,内核会直接唤醒 kworker 强制回写这些脏页,然后才能回收这块内存。
为什么这个重要?因为这种场景下脏页比例可能还远没到 10%,但你的 CPU 已经被 kworker 占满了。如果你在生产环境看到 kworker 跑满、dmesg 报 blocked,但 Dirty: 数值很低,去查一下内存使用率——大概率是内存抖动或者轻微泄漏在作祟。
总结一下"两拨人、三条线":
- 业务线程的
write() 路径:查 10%(唤醒 kworker)+ 查 20%(阻塞自己) - kworker 定时扫描:查 10%(启动回写)+ 查 30 秒超时(强制回写)

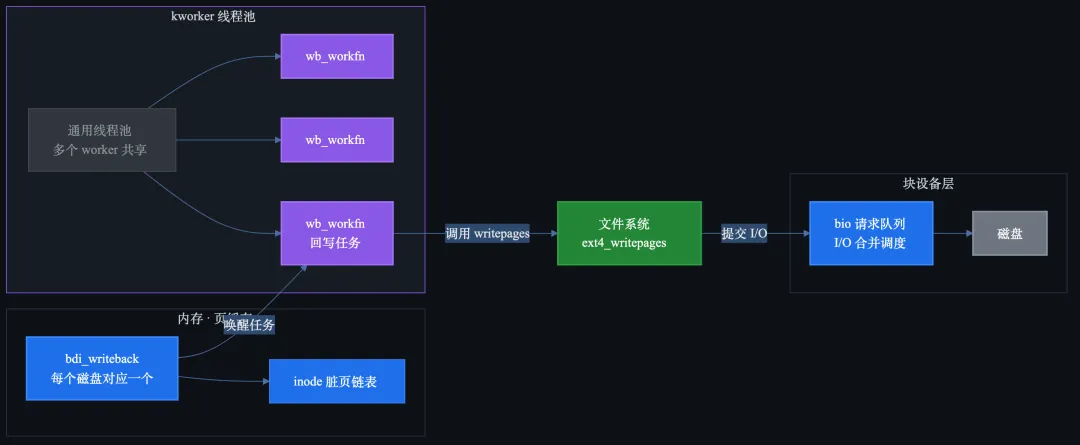
回写是怎么执行的
脏页真正写盘的路径是:kworker 找到所有脏页 → 按 bdi 分组 → 调用文件系统的 writepages → 最终到块设备的提交层。
一个简化版的调用链:
// fs/fs-writeback.c
// kworker 的入口
static void wb_workfn(struct work_struct *work)
{
struct bdi_writeback *wb = ...;
wb_writeback(wb, wb->work); // 开始回写
}
// 回写主循环
long wb_writeback(struct bdi_writeback *wb, struct wb_writeback_args *args)
{
struct inode *inode;
while ((inode = wb_inode(wb)) != NULL) {
mapping = inode->i_mapping;
mapping->a_ops->writepages(mapping, wbc); // 调文件系统的回调
}
}
在 /proc/*/stack 里能验证这个调用链:
$ cat /proc/$(pgrep kworker | head -1)/stack 2>/dev/null
[<0>] wb_writeback
[<0>] wb_workfn
[<0>] process_one_work
[<0>] worker_thread
mapping->a_ops->writepages 是文件系统提供的回调。比如 ext4 的实现会:
// fs/ext4/inode.c
static int ext4_writepages(struct address_space *mapping,
struct writeback_control *wbc)
{
// 把脏页按 extent 分组,批量提交到 JBD2 日志
// 然后提交到块设备
}
块设备层拿到请求后,会合并相邻的 I/O,然后发给磁盘控制器。所以你看到的 iostat 里偶尔出现很大的 avgqu-sz,可能就是一次脏页回写引起的批量 I/O。
怎么观察脏页状态
几个常用命令:
# 当前脏页量
$ grep Dirty /proc/meminfo
Dirty: 156 kB
# 正在回写中的页
$ grep Writeback /proc/meminfo
Writeback: 0 kB
# 各 bdi 的回写统计
$ cat /sys/class/bdi/*/stats
如果 Writeback 持续很高,说明回写在跑。如果 Dirty 一直涨不下来,可能是磁盘跟不上写入速度。
还有一种更直观的方式:直接看内核的回写日志。
$ dmesg -T | grep -i "writeback\|dirty"
如果看到 blocked for more than 120 seconds,基本就是脏页回写阻塞了。
实际调参建议
这几个参数是你可以直接调的,生产环境调过几次,算是有点经验:
# 查看当前值
$ sysctl vm.dirty_ratio vm.dirty_background_ratio vm.dirty_expire_centisecs
vm.dirty_ratio = 20
vm.dirty_background_ratio = 10
vm.dirty_expire_centisecs = 3000
几个场景下的调整思路:
大文件写入场景(视频转码、日志归档)
# 放大阈值,让后台多攒一些再批量写
sysctl -w vm.dirty_ratio=40
sysctl -w vm.dirty_background_ratio=20
积压到 40% 再阻塞,后台线程 20% 就开始写。对顺序写很友好,因为批量 I/O 效率高。
数据库场景(MySQL、PostgreSQL)
# 缩小阈值,尽快落盘
sysctl -w vm.dirty_ratio=10
sysctl -w vm.dirty_background_ratio=5
数据库自己有缓冲区管理(InnoDB 的 buffer pool),脏页积压在页缓存里反而影响判断。早点刷出去,让数据库自己控制更靠谱。
通用场景(Web 服务、中间件)
默认值基本够用。除非你看到了 blocked for more than 120 seconds 这种 dmesg 警告,否则别动。
和 O_DIRECT 的关系
O_DIRECT 可以绕过页缓存,直接写磁盘。MySQL、Kafka 这些对数据持久性要求高的软件都会用它。
int fd = open("data.log", O_WRONLY | O_CREAT | O_DIRECT, 0644);
用了 O_DIRECT,write() 返回时数据已经到了磁盘控制器(但不一定到盘片,那是 O_SYNC 的事)。代价是页缓存的优势没了——重复读同一块数据不能命中缓存。
MySQL 的做法是:数据文件用 O_DIRECT 绕过页缓存,日志文件不用。因为数据页需要精确控制缓存策略(InnoDB 自己管 buffer pool),而日志是顺序追加,页缓存的预读和批量写反而有优势。
MySQL 用 O_DIRECT 有一个最容易踩的坑:用户态缓冲区必须按块大小(通常 4KB)对齐。
具体来说,你的 buffer 地址和文件偏移量都必须是对齐的。如果没对齐,内核为了安全会默默退化为普通 Buffered I/O——O_DIRECT 形同虚设,数据依然走页缓存,断电依然丢数据。Java 的 ByteBuffer 默认不一定对齐,要格外注意。
说到这里你应该理解了:页缓存是内核给普通应用免费加的缓冲层,绝大多数情况是好的。但你要知道脏页积压到什么程度会卡住你的程序,以及出问题的时候怎么排查。这几条路径搞清楚了,下次看到 dmesg 里的 blocked 警告就不会慌了。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
