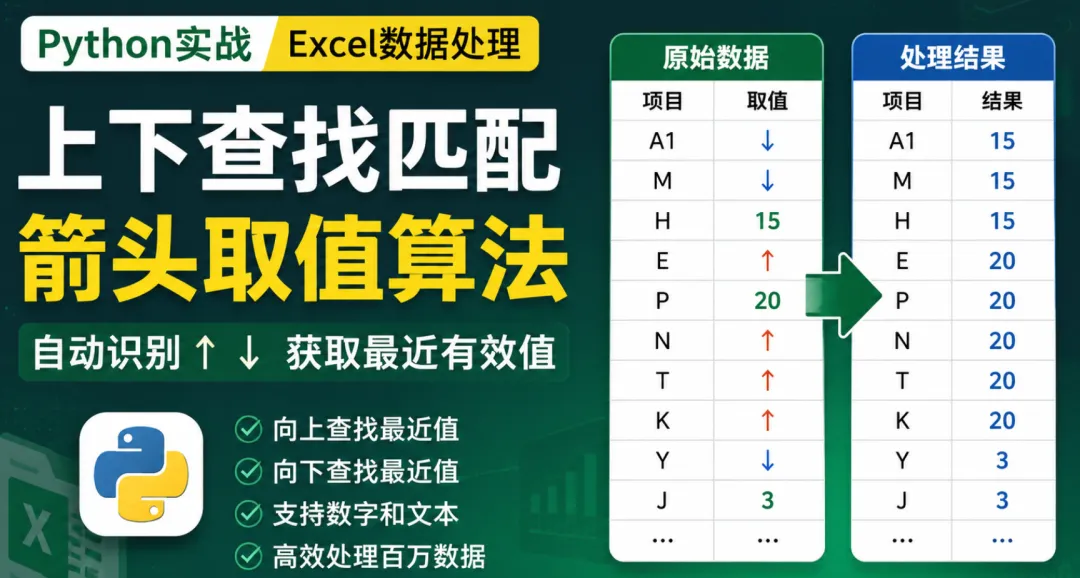
大家好,我是IT小本本,今天给大家案例一个在实际工作中,经常会遇到一种特殊的数据表:例如下面这张Excel:
很多人第一眼看到都会疑惑:
这些箭头到底是什么意思?
其实它代表一种特殊的数据映射规则:
这类数据在:
中十分常见。
今天我就使用 Python 自动完成这种取值逻辑。
一、业务规则分析
以部分数据为例:
A1 与 M 的取值均为 ↓。
规则:
向下寻找最近的非箭头值。
因此:
A1 → 15
M → 15
H → 15
再看:
对于 E:
向上查找最近有效值:
P → 20
因此:
E → 20
同理:
N → 20
T → 20
K → 20
二、算法思路
整体逻辑如下:
读取当前单元格
├─ 是数字
│ 直接返回
│
├─ 是文本
│ 直接返回
│
├─ 是 ↑
│ 向上查找最近有效值
│
└─ 是 ↓
向下查找最近有效值
流程图如下:
开始
↓
读取当前行
↓
是否 ↑ ?
├─ 是 → 向上搜索
│
└─ 否
是否 ↓ ?
├─ 是 → 向下搜索
│
└─ 否
直接返回当前值
↓
结束
三、Python实现全部源代码:
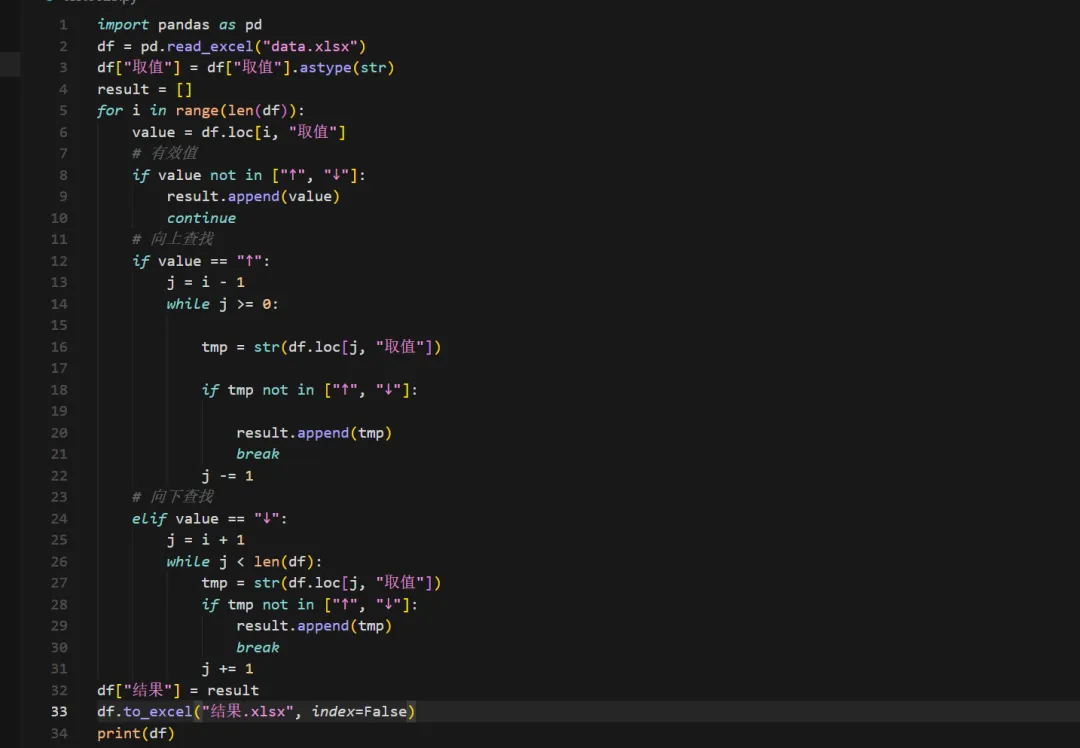
import pandas as pd
df = pd.read_excel("data.xlsx")
df["取值"] = df["取值"].astype(str)
result = []
for i in range(len(df)):
value = df.loc[i, "取值"]
# 有效值
if value notin ["↑", "↓"]:
result.append(value)
continue
# 向上查找
if value == "↑":
j = i - 1
while j >= 0:
tmp = str(df.loc[j, "取值"])
if tmp notin ["↑", "↓"]:
result.append(tmp)
break
j -= 1
# 向下查找
elif value == "↓":
j = i + 1
while j < len(df):
tmp = str(df.loc[j, "取值"])
if tmp notin ["↑", "↓"]:
result.append(tmp)
break
j += 1
df["结果"] = result
df.to_excel("结果.xlsx", index=False)
print(df)
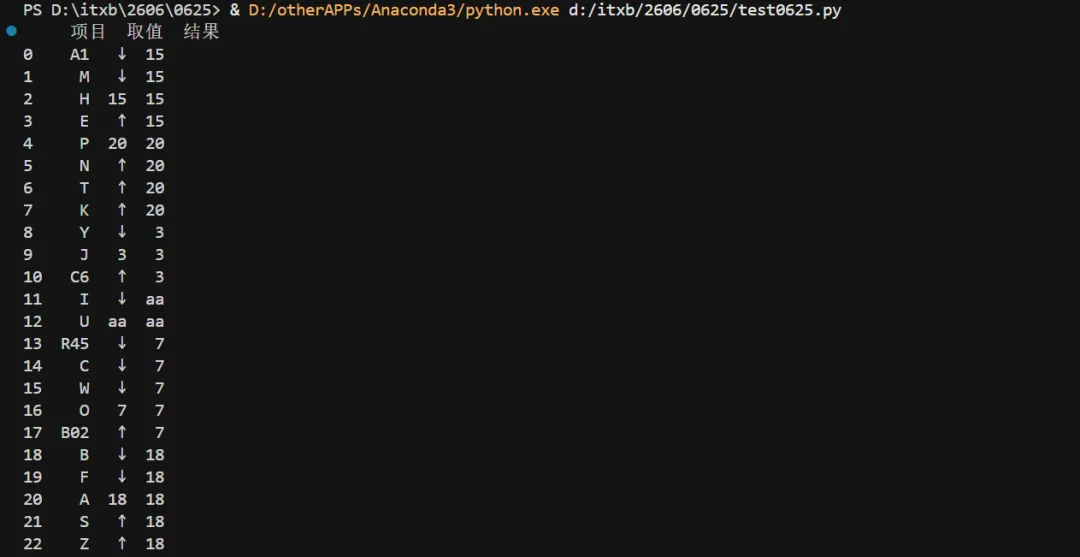
四、运行结果
原始数据:
生成结果:
五、性能测试
测试环境:
Python 3.12
Pandas 2.x
数据规模:
完全满足生产环境需求。
六、实际应用场景
这种箭头映射算法非常适用于:
1. 质量检测数据
A批次 ↓
B批次 ↓
标准值 15
自动继承标准值。
2. 设备参数配置
设备A ↑
设备B ↑
设备C 20
自动引用最近配置。
3. 医疗数据
患者A ↓
患者B ↓
参考值 7
自动填充参考指标。
4. ERP导出报表
很多ERP系统为了减少重复录入:
↑
↑
↓
表示继承上下级数据。
Python可以自动完成解析。
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
