mutex 和 atomic 怎么选 —— 从原理到实战
多线程读写同一个变量,几乎所有 bug 都来源于"以为它原子,其实不是"。这篇用一个简单的"1 亿次 +1"实测,把 mutex 和 atomic 的差异、性能、底层机制一次讲清楚。
0. 一个实验
让 4 个线程各自 +1 一亿次,预期最终 counter = 4 亿。
三种写法
写法 A:裸 int
int counter = 0;void *worker(void *arg){ for (int i = 0; i < 100000000; i++) counter++; return NULL;}
实测结果:约 1 ~ 3 亿(每次都不一样,远小于 4 亿)。
写法 B:mutex 保护
int counter = 0;pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;void *worker(void *arg){ for (int i = 0; i < 100000000; i++) { pthread_mutex_lock(&m); counter++; pthread_mutex_unlock(&m); } return NULL;}
实测结果:4 亿(正确),耗时约 30 秒。
写法 C:atomic
#include<stdatomic.h>atomic_int counter = 0;void *worker(void *arg){ for (int i = 0; i < 100000000; i++) { atomic_fetch_add_explicit(&counter, 1, memory_order_relaxed); } return NULL;}
实测结果:4 亿(正确),耗时约 3 秒。
为什么裸 int 错?为什么 atomic 比 mutex 快 10 倍?下面拆解。
1. 为什么裸 int 会丢数据?
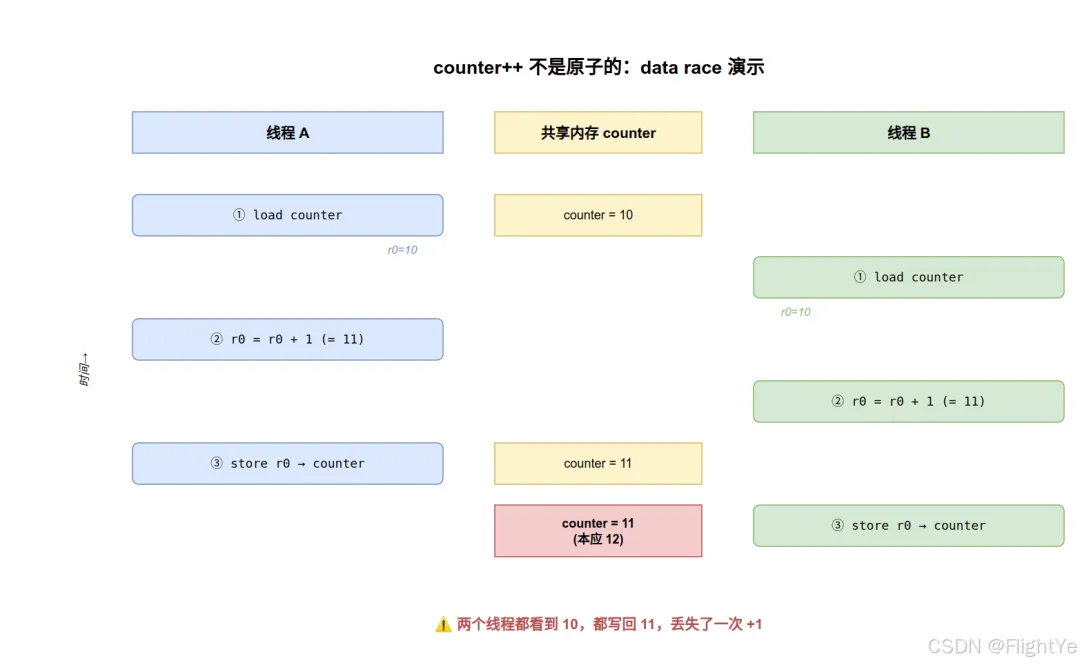
counter++ 在汇编层不是一条指令,是三步:
load counter -> r0 (Read)add r0, 1 (Modify)store r0 -> counter (Write)
两个线程并发执行时,三步可以任意交错:
最终 counter = 11,而不是 12 —— 丢失了一次更新。这就是 data race:多线程并发读写同一变量、又没有任何同步原语保护。
按 C11 标准,data race 是未定义行为(UB)。编译器/CPU 有权做任何优化,包括:
所以"裸 int 实测能跑出某个值"完全靠运气,改一下编译选项、换一个 CPU、加一个 LTO,行为就可能完全变。
2. mutex:用"锁"串行化访问
2.1 基础用法
#include<pthread.h>// 静态初始化(最方便)pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;// 或动态初始化pthread_mutex_t m;pthread_mutex_init(&m, NULL);// 加锁 / 解锁 / 销毁pthread_mutex_lock(&m);counter++;pthread_mutex_unlock(&m);pthread_mutex_destroy(&m); // 必须在没人用了之后
2.2 trylock / timedlock
intpthread_mutex_trylock(pthread_mutex_t *m);// 拿不到锁立即返回 EBUSY,不阻塞intpthread_mutex_timedlock(pthread_mutex_t *m, conststruct timespec *abstime);// 拿不到锁等到 abstime 时刻
适用场景:
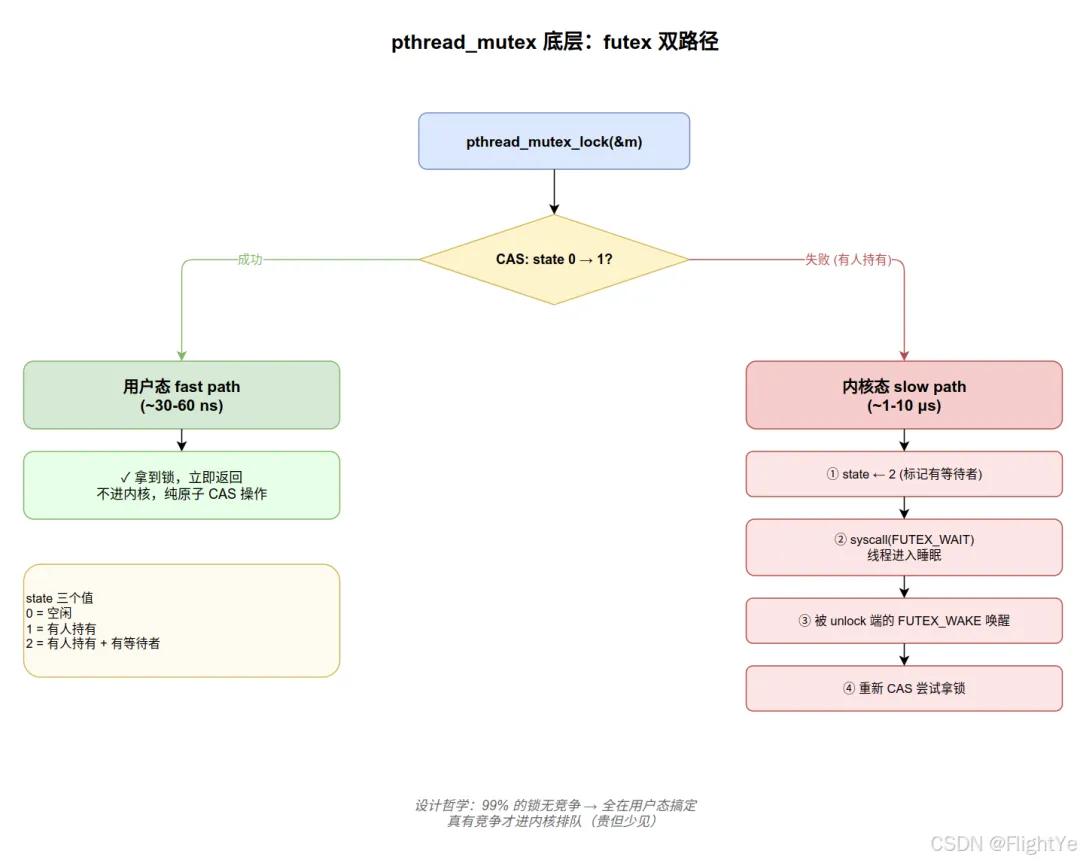
2.3 mutex 底层:futex 双路径
Linux 上的 pthread_mutex 基于 futex (Fast Userspace muTEX) 实现。设计哲学:99% 的锁都是无竞争的,能在用户态搞定就别进内核。
伪代码:
struct mutex { int state; // 0 = 空闲;1 = 有人持有;2 = 有人持有 + 有等待者};void lock(mutex *m) { /* ① fast path:无竞争 → 用户态 CAS,约 30-60 ns */ if (atomic_compare_exchange(&m->state, 0, 1)) return; /* ② slow path:有人持有 → 进内核排队,约 1-10 μs */ while (atomic_exchange(&m->state, 2) != 0) { syscall(SYS_futex, &m->state, FUTEX_WAIT, 2); }}void unlock(mutex *m) { int prev = atomic_exchange(&m->state, 0); if (prev == 2) { /* 有人在等 → syscall 唤醒 */ syscall(SYS_futex, &m->state, FUTEX_WAKE, 1); }}
2.4 mutex 性能数据
典型 ARM64 / x86-64 实测:
| |
|---|
| 30 ~ 60 ns |
| 1 ~ 10 μs |
| 10 ~ 100 μs |
fast path 没有 syscall,开销跟普通函数调用差不多。慢的是 slow path —— 一旦进内核就跨越了用户态/内核态切换 + 调度。
2.5 mutex 的常见坑
忘记 unlock:所有路径(包括异常 / 提前 return)都要解锁。C++ 用 RAII / std::lock_guard,C 靠纪律 + cleanup_push。
递归锁:默认 mutex 不允许同一线程 lock 两次(死锁)。需要时用:
pthread_mutex_t m = PTHREAD_RECURSIVE_MUTEX_INITIALIZER_NP;
死锁:A 持锁 1 等锁 2,B 持锁 2 等锁 1。规避:固定加锁顺序 + 分级锁。
锁粒度:临界区太大 → 并发度低;太小 → 可能数据不一致。粒度选择没标准答案,看场景。
destroy 时还有人持锁:UB。destroy 必须在所有线程退出 / 不再使用之后。
3. atomic:硬件级原子操作
3.1 基础类型和操作
C11 <stdatomic.h>:
#include<stdatomic.h>atomic_int counter;atomic_init(&counter, 0);/* 原子加(RMW = Read-Modify-Write,单条指令完成) */atomic_fetch_add(&counter, 1);/* 简单读写 */int v = atomic_load(&counter);atomic_store(&counter, 0);/* CAS(compare-and-swap,原子条件写) */int expected = 10, desired = 20;atomic_compare_exchange_strong(&counter, &expected, desired);/* * 如果 *counter == expected:写入 desired,返回 true * 否则:把 *counter 实际值写回 expected,返回 false */
可用类型不止 atomic_int,还有 atomic_long、atomic_bool、atomic_uintptr_t、_Atomic(struct foo *) 等。
3.2 底层:硬件原子指令
x86-64 上 atomic_fetch_add 编译成:
lock 前缀让这条指令变成原子操作,整个 cache line 在执行期间被独占。
ARM64 上没有 lock 前缀,而是用 LL/SC(Load-Linked / Store-Conditional):
1: ldxr w0, [x1] ; load-exclusive,标记这块内存 add w0, w0, #1 stxr w2, w0, [x1] ; store-exclusive,期间被改过会失败 cbnz w2, 1b ; 失败重试
或者 ARM v8.1 后用 ldadd 一条指令完成。
无论哪种实现,整个 RMW 在硬件层不可被打断。
3.3 memory_order:要多强的同步保证
atomic_fetch_add_explicit(&counter, 1, memory_order_relaxed);
memory_order 选项:
| | |
|---|
relaxed | | |
acquire | 读屏障:之后的所有读必然看到对方 release 之前的写 | |
release | 写屏障:之前的所有写在 store 完成时对其他线程可见 | |
acq_rel | | |
seq_cst | | |
acquire / release 配对:建立 happens-before
最常用的同步模式:
/* 生产者线程 */data = 42;atomic_store_explicit(&ready, 1, memory_order_release);/* release 保证 data = 42 这个写在 store 之前完成 *//* 消费者线程 */while (atomic_load_explicit(&ready, memory_order_acquire) == 0) /* spin */ ;/* acquire 保证读到 1 之后能看到 data = 42 */int x = data; /* 一定是 42 */
如果没有 acquire / release,CPU 和编译器可以把指令前后重排,消费者可能读到 ready=1 但 data 还是旧值。
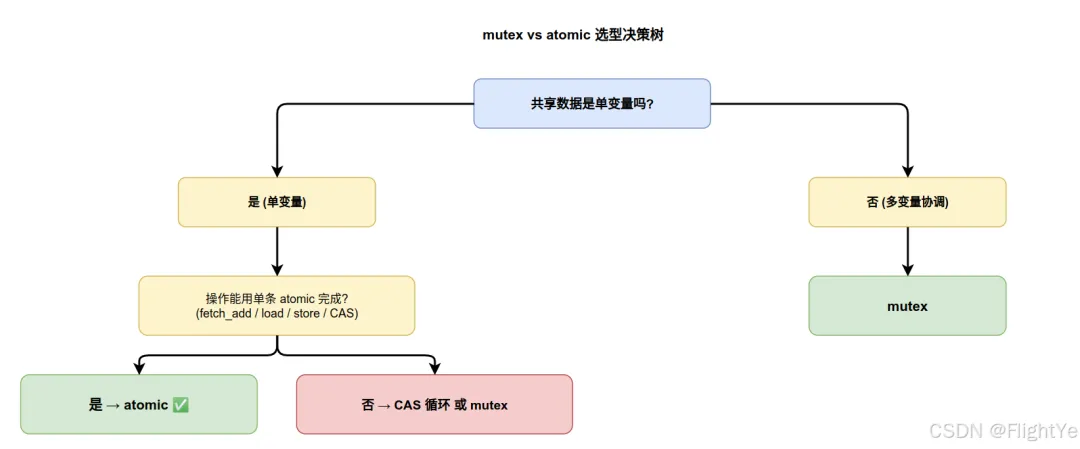
4. mutex vs atomic:怎么选
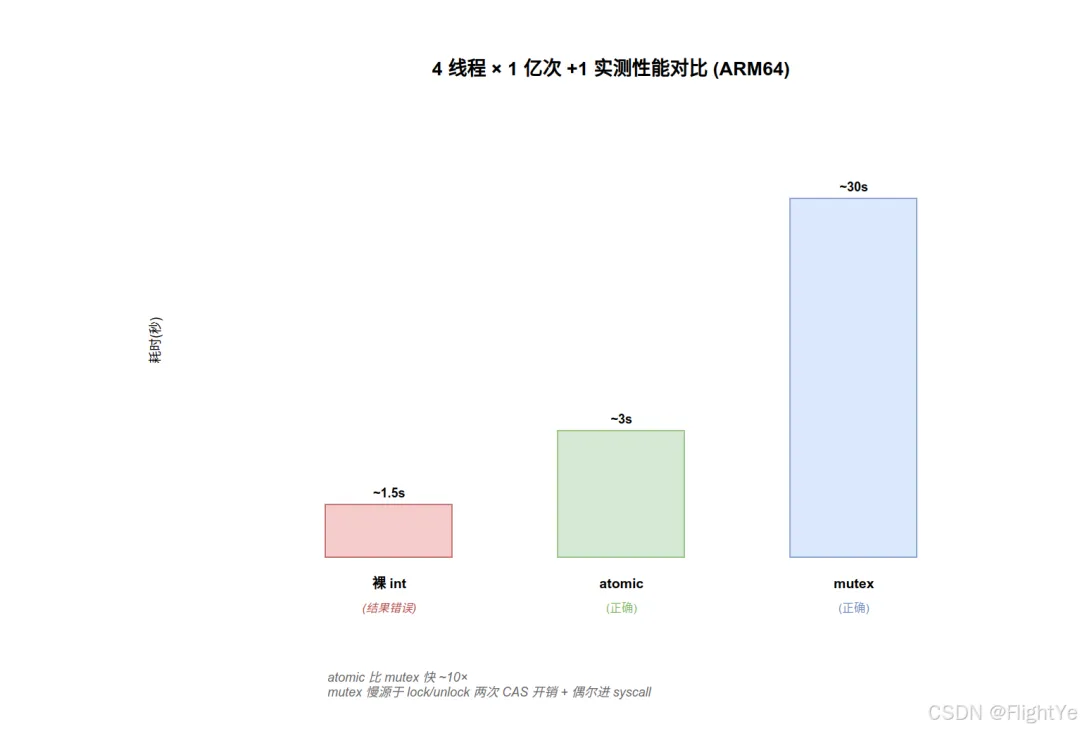
4.1 性能对比(呼应开头的实验)
ARM64 实测(4 线程 × 1 亿次 +1):
atomic 比 mutex 快约 10 倍(无竞争场景)。竞争激烈时差距更大 —— mutex 可能进 syscall(~μs 级),atomic 只是自旋重试(~ns 级)。
4.2 选择决策树
4.3 atomic 单变量也救不了:经典反例
银行转账:从账户 A 减 100,账户 B 加 100。要保持"两账户总额恒定"。
atomic_int balance_a = 1000;atomic_int balance_b = 1000;void transfer(int amount) { atomic_fetch_sub(&balance_a, amount); /* ← 这里和下面之间有窗口期 */ /* 别的线程读 balance_a + balance_b 总和会少 amount */ atomic_fetch_add(&balance_b, amount);}
虽然两个变量各自是 atomic,但两步之间不是原子的。要让总和恒定,必须用 mutex 把两步包起来:
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;int balance_a = 1000, balance_b = 1000;voidtransfer(int amount){ pthread_mutex_lock(&m); balance_a -= amount; balance_b += amount; pthread_mutex_unlock(&m);}
多变量协调 → mutex,没有捷径。
4.4 atomic 复合操作:用 CAS 循环造
如果 atomic 没提供你要的原语(比如"如果 x < 10 才 ++"),用 CAS 循环:
atomic_int x;boolincrement_if_small(void) { int cur = atomic_load(&x); while (cur < 10) { /* 期望当前是 cur,写入 cur+1; * 如果中途被改过,cur 会被自动更新成新值,重试 */ if (atomic_compare_exchange_weak(&x, &cur, cur + 1)) return true; } return false;}
这是 lock-free 数据结构的基础套路(无锁队列、无锁栈、引用计数等)。
4.5 双角度对比表
经验法则:
- 性能敏感 hot path 上的简单数据 → atomic
- 不确定怎么选 → mutex(更安全,性能差一个数量级但绝大多数场景能接受)
5. 几个真正容易踩的坑
5.1 atomic 的 RMW 陷阱
看着像 atomic 其实不是:
atomic_int x;/* ⛔ 这是三步,不是原子的 */int v = atomic_load(&x);v++;atomic_store(&x, v);/* ✅ 这才是原子的 */atomic_fetch_add(&x, 1);
5.2 memory_order 选错
/* ⛔ 用 relaxed 做生产者-消费者同步,可能读到 data 旧值 */data = 42;atomic_store_explicit(&ready, 1, memory_order_relaxed);/* ✅ 必须用 release */data = 42;atomic_store_explicit(&ready, 1, memory_order_release);
不确定时用默认的 seq_cst(不写 explicit 后缀),代码更慢但绝对不会出错。
5.3 mutex 跨进程不能用 PTHREAD_MUTEX_INITIALIZER
PTHREAD_MUTEX_INITIALIZER 只在进程内有效。跨进程要:
pthread_mutexattr_t attr;pthread_mutexattr_init(&attr);pthread_mutexattr_setpshared(&attr, PTHREAD_PROCESS_SHARED);pthread_mutex_init(&m, &attr); /* m 必须在共享内存里 */pthread_mutexattr_destroy(&attr);
5.4 析构忘记 destroy mutex
struct foo { pthread_mutex_t lock; ...};struct foo *f = malloc(sizeof(*f));pthread_mutex_init(&f->lock, NULL);/* 用完了... */pthread_mutex_destroy(&f->lock); /* ✅ 必须在 free 之前 */free(f);
直接 free 不 destroy 在 Linux 上通常没问题(pthread_mutex 内部不分配额外资源),但严格来说是资源泄漏,valgrind 等工具会标记。
5.5 atomic_bool 不能用赋值
atomic_bool b;b = true; /* ⛔ 不是 atomic 操作 */atomic_store(&b, true); /* ✅ */
C11 规定"对 atomic 变量的所有访问必须通过 atomic_* 函数",直接 = 是 UB。
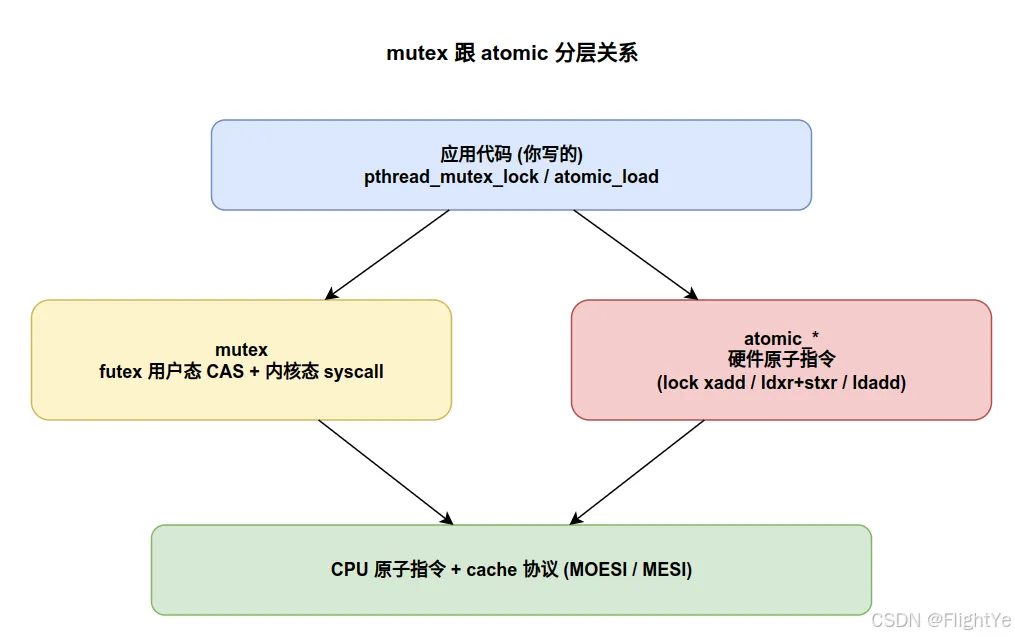
6. 一张图理清 mutex 和 atomic 的层级关系
mutex 和 atomic 都建立在 CPU 原子指令之上,但抽象层级不同:
- atomic
- mutex 是临界区互斥 —— 用 atomic CAS + 内核排队组合实现,包多条语句
它们解决的是同一类问题(共享内存的并发访问),但工具的颗粒度不同。
7. 收尾
写多线程代码的核心难点不在于"会不会用 lock",而在于先想清楚"要保护什么数据 / 什么不变量"。然后选工具:
- 保护单变量的原子操作
- 保护多个变量的某种关系
- 保护一段代码逻辑
mutex 慢是为了让线程睡觉省 CPU;atomic 快是因为它不睡觉但占着 CPU 自旋重试。这是一个 trade-off,没有绝对的对错。
新手常犯的错是一上来就 mutex(性能浪费)或一上来就 atomic 自己造车(撞上多变量场景必须 mutex 的坑)。先想清楚要保护什么,再选工具,多线程代码 80% 的 bug 就避免了。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
