在上几次的分享中,我们把Python的变量、命名美学以及数字的算术魔法安排得明明白白。今天,我们要彻底进军Python世界中用来处理“文本”的头号主角——字符串(String,简称str)。
无论是在屏幕上打印一句"Hello World",还是处理复杂的电商用户数据、清理网页文本,字符串都是绝对绕不开的基石。今天,我们就用小白也能听懂的语言,扒开字符串的外衣,看看那些简单的神奇的“运行规则”和“性能陷阱”!
一、什么是字符串?用引号括起来的“文本字符序列”
简单来说,任何用引号包裹起来的文本,在Python眼里都是字符串。你可以把它想象成一串用线穿起来的珍珠,每颗珍珠就是一个字符。
Python创建字符串的方式非常灵活,主要有以下清晰:
1. 单引号
s1 ='Hi, Python'
2. 双引号(最常用)
s2 ="Hello World"
3. 三引号(用于多行文本,会保留你的换行和空格排版)
s3 ="""第一行文本第二行文本"""
💡区别避坑小贴士:单引号和双引号在Python里没有任何功能,但必须成对出现。不能一边用单引号引号,另一边用双引号前缀。
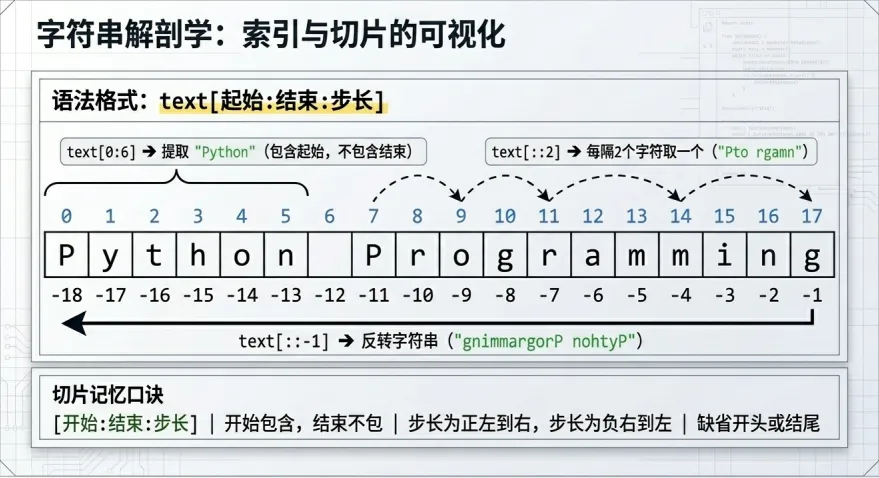
二、字符串剖析学:索引与切片的可视化
一串串是一串串排好、按顺序起来的“珍珠”,那我们就要精准抓取其中的某一颗颗或者某一段呢?这就需要用到索引(Index)和切片(Slice)的黑魔法了。
1. 索引(精准抓取某个角色)
在Python中,队列是从0开始计数的(而不是1)。同时,Python还支持超酷的负数索引,代表从倒数第一个开始数。我们以文本text = "Python"为例:
text ="Python"
print(text[0])
输出 'P' —— 正数第一位
print(text[2])
输出 't' —— 正数第三位
print(text[-1])
输出 'n' —— 倒数第一位
2. 文本切片(批量完成某段时间)
如果你想提取的是一段连续的文本,则应使用切片的语法格式:text[起始位置 : 结束位置 : 步长]。
⚠️核心死理:包前不包后!既然,包含起始位置,但绝对不包含结束位置。
text ="Python"
提取 "Pyth"
print(text[0:4])
包含位置 0, 1, 2, 3,不包含 4!
快捷缩写
print(text[:3])
省略起始位置,默认从头开始抓,输出 'Pyt'
print(text[3:])
省略结束位置,默认一直抓到最后,输出 'hon'
跳着抓取:步长设为 2
print(text[::2])
每隔2个字符取一个,输出 'Pto'
三、核心铁律:字符串的“绝对不可变性”
这是所有Python新手最容易触碰的一个大坑,请大家在小本本上画上五颗星:字符串一旦在内存中被创建,内部的字符就绝对不可能被原地篡改!
不信?我们做了一个实验。假设你创建了一个变量text = "Hello",你想把第一个字母'H'改写成小写的'h',你可能会尝试这样写:
text ="Hello"
错误尝试:
text[0] ="h"
如果你运行模仿代码,Python会直接把错误甩在你的脸上:(TypeError: 'str' object does not support item assignment字符串对象不支持原位赋值)。
🔍底层逻辑:字符串在Python中是“不可修改对象”。你不能直接跑到它的内存盒子里把其中一颗“珍珠”给抠下来换掉。正确的解法:如果你非要修改,必须利用切片和裁剪,在内存中创建一个全新的字符串,然后重新放回盒子里:
text ="Hello"
抓取第1位后面的所有内容,在前面拼上小写 'h'
text ="h"+ text[1:]
print(text)
输出:hello (这其实是一串全新的文本了)
四、业余 vs 专业:字符串拼接的性能对决
在日常写代码中,我们经常需要把好几个字符串凑在一起。这个时候,你是采用“业余做法”还是“专业做法”,直接决定了你程序的运行速度。
❌业余做法:用+号在循环里不断拼接
很多同学喜欢用+连连看:
模拟拼接 1 到 100 的数字字符串(别这么做!)
result =""
foriinrange(100):
result = result + str(i)
因为字符串是不可变的!每次你用拼接+一下,Python都要在内存里重新开辟一块大空间,把旧文本复制过去,再粘上新文本。循环100次,就要重新开辟100次内存,性能差极了!
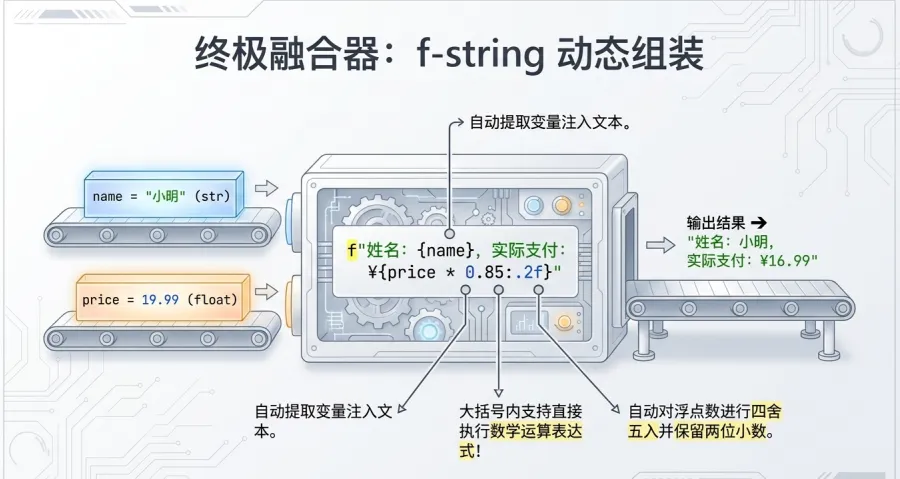
专业做法1:优雅的f-string规范(推荐)
如果你只是拼凑一句话,带上几个指标,f-string就是当之无愧的王者。
name ="小明"
age =18
用 f 开头,变量直接塞进花括号 {} 里
message =f"这位同学叫{name},今年{age}岁。"
print(message)
输出:这位同学叫 小明,今年 18 岁。
专业做法2:大量文本拼接join()
如果要批量把一个列表里的文本拼成大文章,标准动作是先追加到列表里,最后一次性用.join()结合:
words = ["Python","是","一门","好语言"]
用空字符串把列表里的元素连起来
result ="".join(words)
print(result)
输出:Python是一门好语言
这种做法,Python只需一次性申请一块足够大的内存,把所有字符填进去,效率+提升成百上千倍!
五、小白必备的三串“超级武器”
最后,送你三个在数据清洗和文本处理中出镜率 99% 的内置函数,记住它们,开发效率翻倍:
text.split()—— 文本大分割把一整段文本按照指定的符号忽略一个列表(默认按空格切)。
info ="苹果,香蕉,西瓜"
print(info.split(","))
输出:['苹果', '香蕉', '西瓜']
text.replace()——文本大替换把文本里的某些敏感词或错别字全部换掉。
text ="我觉得你太菜了"
print(text.replace("菜","牛"))
输出:我觉得你太牛了
len(text)——测量字符串长度一秒算出这串文本里到底有多少个字符(包含空格和标点符号)。
print(len("Hello!"))
输出:6
💡结语:字符串修炼通关卡
读完这篇文章,关于Python字符串的核心认知你已经超越了广大自学者。请收下这张通关卡:
字符修改计数从零开始,切片包前不包后。
落地创建不可变,若想覆盖新值。
循环拼接莫用加,列表加入性能佳!
快去打开你的编辑器,尝试用切片和f-string写两行代码感受一下文本的魅力吧!如果觉得有用,别忘记点赞、在看、转发一条龙哦!


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
