文件写入磁盘时,linux系统做了些什么?
- 2026-07-02 16:29:50
刚接触Linux时,我以为磁盘管理就是"插上硬盘 →fdisk分个区 →mkfs格式化 →mount挂载"。直到某天线上报警:"磁盘写满",我登录一看——df -h显示还有10G空闲;又有一天,"文件删了,空间却不释放";还有一次,服务器突然卡死,dmesg 里全是 I/O error……
这些经历让我明白:磁盘不是一块沉默的铁片,而是一套精密的软硬协同系统。今天,我们就从最底层的物理结构开始,一路向上,讲清楚Linux中磁盘的完整工作链路,以及运维中那些“看似诡异实则有因”的问题。
1
硬件层:数据是如何被“记住”的
一切始于物理介质。在Linux系统运维与系统管理中,磁盘管理是基础且关键的一环。无论是新服务器部署、数据扩容,还是性能调优,都离不开对磁盘底层机制和上层工具的深入理解
机械硬盘(HDD):旋转的磁性记忆,数据存储在高速旋转的盘片上,靠磁头改变磁性颗粒方向记录 0/1。最小读写单位是扇区(Sector),传统为 512 字节,现代采用 4096 字节(4K)。性能瓶颈在于寻道时间 + 旋转延迟,随机 I/O 极慢。
固态硬盘(SSD):电子化的闪存存储。基于 NAND 闪存芯片,无机械部件。以“页”(Page,通常 4–16KB)为单位写入,以“块”(Block,含 256+ 页)为单位擦除。写前必须擦除,不能直接覆盖 → 依赖 FTL(闪存转换层) 映射逻辑地址到物理位置。有写入寿命限制(P/E Cycle),需靠磨损均衡和 TRIM 延长寿命。
HDD 适合大容量冷存储,SSD 适合高性能热数据;
2
接口层:如何与主机通信
磁盘通过接口连接主板,接口决定了带宽上限。
SATA | ~600 MB/s | 消费级主流,兼容好 |
SAS | 12–24 Gb/s | 企业级,支持双端口 |
NVMe over PCIe | PCIe 4.0 x4 ≈ 8 GB/s | 专为 SSD 设计,低延迟、高并发 |
3
分区层:磁盘的逻辑空间
一块裸盘不能直接用,必须先分区——这是操作系统与磁盘协商的“空间划分协议”,当前有两种磁盘分区表格式。,新服务器一律使用 GPT。
MBR:传统磁盘分区表
位于 LBA 0(第 0 扇区),512 字节
仅支持 4 个主分区,最大识别 2TB
分区表无校验,损坏即丢失
GPT:现代标准
支持 >2TB(理论 8ZB)
默认 128 个分区,头尾双备份 + CRC 校验
UEFI 启动必备
#查看分区表sudo fdisk -l /dev/sda # 显示 MBR/GPT 类型sudo parted -l # 更详细,支持 GPT#parted创建分区parted /dev/sdb(parted) mklabel gpt(parted) mkpart primary ext4 0% 100%(parted) quit
4
文件系统层:管理数据存储
分区后需格式化,即创建文件系统,定义如何存储文件、目录、元数据结构,使操作系统能高效组织和访问数据
常见文件系统
ext4:Linux 传统默认,支持最大 16TB 单文件,成熟稳定
xfs:高性能日志文件系统,CentOS/RHEL 默认,擅长大文件和高并发
swap:交换分区,用于虚拟内存
# 查看磁盘fdisk -l# 对 /dev/sdb1 创建 ext4 文件系统mkfs.ext4 /dev/sdb1# 或创建 XFSmkfs.xfs /dev/sdb1# 创建 swap 分区mkswap /dev/sdb2swapon /dev/sdb2# 挂载mount /dev/sdb1 /mnt/data # 永久挂载需编辑 /etc/fstab
核心概念
超级块(superblock):描述文件系统整体状态信息(大小、状态、块大小等)
inode:每个文件/目录的唯一标识,记录权限、大小、时间戳、数据块指针
数据块(Data Block):实际存储文件内容的单元(通常 4KB),标记哪些块被使用
目录项(Directory Entry):文件名 ↔ inode 编号的映射
常见问题
场景1:inode耗尽,明明有空间,却写不进去数据。原因是Linux文件系统不仅限制空间,还限制 inode 数量(每个文件/目录都要一个 inode)。小文件特别容易吃光 inode。
$ df -hFilesystem Size Used Avail Use% Mounted on/dev/sda2 20G 10G 10G 50% /var$ touch testfiletouch: cannot create 'testfile': No space left on device
排查方法
df -i # 查看 inode 使用率ncdu -i /var # 按 inode 排序,定位罪魁祸首
场景2:文件删除了,但是空间没有释放。因为Linux 删除文件 = unlink(),即移除目录项与 inode 的链接。只要还有进程打开该文件(持有文件描述符),inode 就不会释放,数据仍在磁盘上。
# 终端 Atail -f /var/log/app.log# 终端 Brm /var/log/app.log
验证方法,查看是否有标记删除的文件,如果有,那就是还有进程在用,空间还在占用中,这个阶段数据完全可以恢复回来。
lsof | grep deleted# 输出示例:java 1234 user 12w REG 8,2 1073741824 123456 /var/log/app.log (deleted)
恢复文件(如果进程还在)
# 找到进程 PID(如 1234)和 fd 编号(如 12)cp /proc/1234/fd/12 /var/log/app.log.recovered
如果确认数据不需要了,可以对当前看到占用该文件的进程kill掉,或者重启恢复。
5
linux的哲学:一切皆文件
理解 Linux 中与文件和磁盘相关的路径(尤其是 /proc、/dev、/sys 等虚拟文件系统)是深入掌握系统行为的关键,Linux 抽象了硬件、进程、内核状态等资源,统一用“文件”接口暴露给用户空间。这种设计让所有 I/O 操作都可用 open()、read()、write()、close() 完成,极大简化了编程模型。你操作的磁盘是/dev/sda这样的块设备文件;你敲击键盘是/dev/input/event0这样的字符设备文件;当前进程信息是/proc/self/下的一堆虚拟文件;网络连接可通过/proc/net/tcp查看。
dev目录
设备目录文件。/dev/sda块设备, /dev/null字符设备等。
proc目录
进程与内核运行时信息,这是一个内存中的虚拟文件系统,文件内容由内核动态生成,不占用磁盘空间,这里说几个与磁盘相关的核心子目录
(1)/proc/<PID>/fd/ —— 文件描述符的窗口。每个进程目录下都有 fd/ 子目录,列出该进程打开的所有文件描述符,每个 fd 是一个符号链接,指向实际文件或设备。
$ ls -l /proc/1234/fd/lr-x------ 1 user user 64 Dec 31 02:00 0 -> /dev/pts/0lrwx------ 1 user user 64 Dec 31 02:00 1 -> /dev/pts/0lrwx------ 1 user user 64 Dec 31 02:00 2 -> /dev/pts/0lr-x------ 1 user user 64 Dec 31 02:00 3 -> /var/log/app.log (deleted)
(2)/proc/mounts ——当前挂载点列表。等价于mount命令的输出,格式如下:
设备 挂载点 文件系统类型 挂载选项 dump/fsck标志(3)/proc/partitions ——内核识别的分区表,显示所有被识别到的磁盘和分区(单位是:1kb块)
major minor #blocks name8 0 500107608 sda8 1 1048576 sda18 2 499057664 sda2
(4)/porc/swaps ——交换分区文件信息。显示当前启用的swap空间
(5)/proc/diskstats —— 磁盘IO统计,每行对应一个块设备,包含读写次数、扇区数、耗时等,iostat的数据来源于此。
sys目录
设备与驱动的视图关系,比proc更加结构化,反映了设备、驱动、总线之间的拓扑关系,在SAN存储中常用到volume和lan的映射关系。
(1)/sys/block ——列出所有块设备(例如:sda,nvme0n1),每个设备目录包含扇区总大小(size),一个扇区512B;和队列(queue),涉及io调度,队列纵深,逻辑/物理块大小等。
cat /sys/block/sda/queue/scheduler # 查看调度器echo 'none' > /sys/block/sda/queue/scheduler # 切换(需 root)
(2)/sys/class/block —— 按块设备类创建的软连接,指向/sys/devices 下的实际设备
/etc/fstab ——静态配置文件,定义开机自动挂载的文件系统,和/proc/mounts一样。
文件功能性实战
场景1:恢复被删除的日志文件
# 1. 找到持有 deleted 文件的进程lsof | grep deleted# 2. 假设 PID=1234, fd=3cp /proc/1234/fd/3 ./recovered.log
场景2:查看哪些进程打开了哪些文件
ls -l /proc/$(pgrep nginx)/fd/ | grep -E '\.(log|dat)$'场景3:查看磁盘物理/逻辑扇区的大小
cat /sys/block/sda/queue/physical_block_size # 通常是 4096cat /sys/block/sda/queue/logical_block_size # 通常是 512
场景4:强制内核重新扫描scsi总线,一般在磁盘热插拔后执行。
echo "- - -" > /sys/class/scsi_host/host0/scan6
lvm逻辑卷组:物理磁盘虚拟化
传统分区一旦建好,扩容极其麻烦。而 LVM(逻辑卷管理) 提供了存储虚拟化,支持在线扩容、快照、跨盘聚合
物理磁盘 → PV(物理卷) → VG(卷组,存储池) → LV(逻辑卷,可挂载)
# 1. 创建 PVpvcreate /dev/sdb1 /dev/sdc1# 2. 创建 VG(名为 data_vg)vgcreate data_vg /dev/sdb1 /dev/sdc1# 3. 创建 LV(10GB,名为 web_data)lvcreate -L 10G -n web_data data_vg# 4. 格式化并挂载mkfs.xfs /dev/data_vg/web_datamount /dev/data_vg/web_data /var/www# 5. 扩容 LV(+5G)lvextend -L +5G /dev/data_vg/web_dataxfs_growfs /var/www # XFS 自动扩展# 若是 ext4:resize2fs /dev/data_vg/web_data
在线扩容
# 1. 云平台扩容磁盘后,通知内核重读大小echo 1 > /sys/class/block/sdb/device/rescan# 2. 用 parted 扩展分区到新边界parted /dev/sdb resizepart 1 100%# 3. 若是 LVM PV,执行pvresize /dev/sdb1# 4. 扩展 LV 和文件系统lvextend -l +100%FREE /dev/vg/dataxfs_growfs /data
7
磁盘故障诊断与恢复
诊断工具和命令
(1)smart诊断工具确认磁盘是否故障
# 安装sudo apt install smartmontools# 查看健康状态sudo smartctl -H /dev/sda# 查看详细属性(重点关注)sudo smartctl -A /dev/sda
判断故障的几个关键参数
Reallocated_Sector_Ct:重映射扇区数(>0 表示坏道)
Current_Pending_Sector:待重映射扇区(高危!)
UDMA_CRC_Error_Count:数据线问题(非磁盘本身)
(2)通过内核日志分析磁盘故障
dmesg | grep -i "error\|fail\|bad"journalctl -k | grep sd
典型错误,在之前维护ceph的时候,osd经常报I/O error,只能剔除这块osd,换新盘。
end_request: I/O error → 硬件通信失败
Buffer I/O error on dev sda1 → 文件系统层报错
(3)文件系统检查
# 必须在 unmounted 状态下运行!sudo fsck -f /dev/sdb1# ext4 日志回放(安全)sudo e2fsck -p /dev/sdb1
修复策略
场景1:分区表损坏,GPT格式,如果有备份,gdisk可以自动恢复。MBR引导代码损坏,重装grub
# gptsudo gdisk /dev/sda(gdisk) r → b → w # 从备份恢复# mbrsudo grub-install /dev/sda
场景2:文件系统元数据损坏,使用fsck修复inode、位图、超级快
sudo dumpe2fs /dev/sda1 | grep -i superblocksudo e2fsck -b 32768 /dev/sda1 # 指定备用超级块
场景3:物理坏道
badblocks -v /dev/sda > badblocks.txt# 创建文件系统时跳过坏块mkfs.ext4 -l badblocks.txt /dev/sda1
常用检查和恢复方式
# 健康监控smartctl -H /dev/sda # 查看健康状态smartctl -A /dev/sda # 查看详细属性# 文件系统修复(必须 unmount!)fsck -f /dev/sdb1# 数据恢复extundelete /dev/sdb1 --restore-all # ext3/4 误删photorec /dev/sdb # 按特征恢复(无视文件系统)ddrescue /dev/bad /dev/good log.txt # 克隆故障盘# 查找高 inode 消耗for d in /var/*; do echo $d; find $d | wc -l; done
磁盘性能测试
# 顺序写dd if=/dev/zero of=/testfile bs=1G count=1 oflag=direct# 随机读写(需安装 fio)fio --name=randwrite --ioengine=libaio --rw=randwrite --bs=4k --size=1G --numjobs=4 --runtime=60 --group_reporting
8
linux存储栈:数据从应用到硬件
当程序调用 `write()`,数据走过一条多层路径:

Page Cache:默认写入内存缓存,异步刷盘(断电可能丢数据)
fsync():强制刷盘(数据库常用)
O_DIRECT:绕过缓存,用于 Redis/MySQL 等自管理缓存的应用

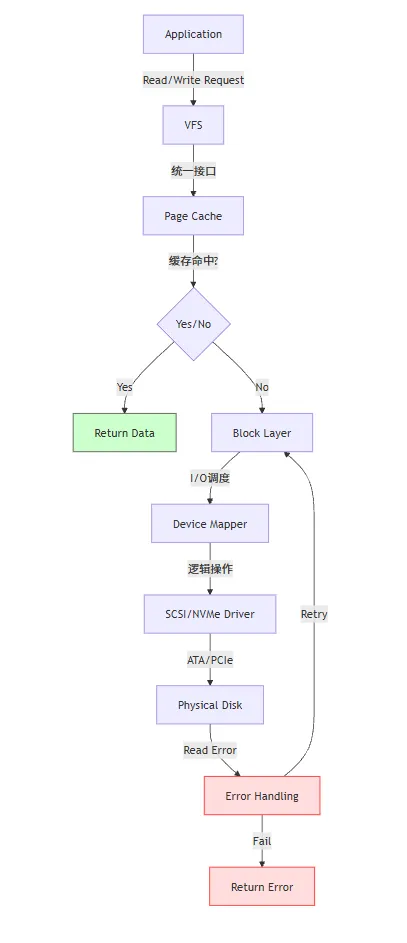
(1)Page Cache 与 Writeback
默认情况下,write() 仅将数据写入内存 Page Cache,立即返回内核后台线程(pdflush / writeback)在以下情况刷盘:
页面脏时间超过 dirty_expire_centisecs(默认 30 秒)
脏页占比超过 dirty_ratio(默认 20%)
强制刷盘:fsync()(文件级)、sync()(系统级)
风险:断电可能导致 Page Cache 中数据丢失!
(2)I/O 调度器(Scheduler)
CFQ(Completely Fair Queuing):公平分配带宽(HDD 时代主流)
Deadline:避免请求饿死,适合数据库
NOOP / none:SSD 无需寻道,直接传递请求(现代默认)
(3)Direct I/O 与 O_DIRECT
绕过 Page Cache,直接从用户缓冲区 → 块设备
用于数据库(如 MySQL InnoDB),避免双重缓存
往期推荐:
持续分享了 Linux 运维中的实用技巧和工具,希望能为你的日常工作带来帮助。
系统稳定,始于细节;运维之道,贵在积累。
🔹 欢迎点赞 + 在看 + 转发,让更多同行看到!
🔹 关注本号,持续更新 Linux、Shell、云计算等技术干货!
🔹 留言区开放:你在实践中遇到过哪些运维问题?欢迎交流!
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 为什么同一块 RDMA 网卡,在 Linux 里会有两个名字?
- 每天学一个Linux命令系列(10):sed - 替换文本的正确姿势,原地修改怎么做
- Python写循环的10个实用技巧:别人还在嵌套,你一行搞定
- Java vs Python:从语法到AI应用开发的全方位对比
- 这个Linux命令,能让你在终端里“回头看”
- 从 Python 算法到上板产品:用 AI 把这条路自动化
- 第009讲 Linux程序、进程和线程
- C、C++、MATLAB、Python、Go 哪个比较适合写算法?
- Knoppix满25岁:插张盘就能跑Linux,这条路是它第一个趟出来的
- 中移信息招聘后端开发工程师(Python)(002806)
