大家好,我是木木。
今天给大家分享一个实时数据处理的 Python 库,pathway。
pathway
pathway 是一个面向流式 ETL、实时分析和在线 RAG 的 Python 数据处理框架。它让你用 Python 写表、连接器和转换逻辑,底层由 Rust 引擎做增量计算。对已经习惯 pandas/SQL 思维的团队来说,Pathway 比较有意思的点在于:同一套逻辑可以从本地静态测试逐步走向持续更新的数据流。
项目地址:https://github.com/pathwaycom/pathway
官方文档:https://pathway.com/developers/
三大特点
流批统一
同一套表转换模型可以覆盖静态数据、回放数据和持续进入的数据流。
增量计算
底层引擎关注变化量,适合实时指标、告警和在线索引更新。
部署明确
官方文档强调 Docker、Kubernetes 和监控,适合工程化落地。
最佳实践
安装方式:pip install -U pathway。官方 README 说明 Pathway 主要面向 macOS 和 Linux;Windows 用户建议使用虚拟机、WSL 或 Linux 容器。本文当前机器是 Windows,所以先做环境判断和接入草图,正式运行应放到官方支持的环境里。
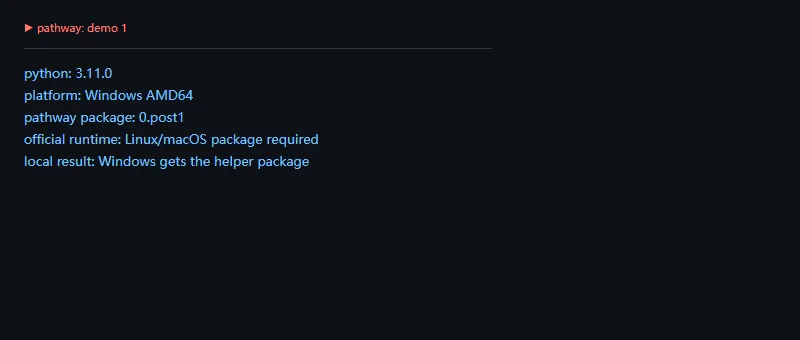
第一段代码解决的问题是:先确认本机拿到的包和运行平台,避免把 Windows 上的提示包误当成正式运行环境。
fromimportlib.metadataimportversion,PackageNotFoundErrorimportplatformimportsystry:installed=version("pathway")exceptPackageNotFoundError:installed="not installed"print("python:",sys.version.split()[0])print("platform:",platform.system(),platform.machine())print("pathway package:",installed)print("official runtime:","Linux/macOS package required")print("local result:","Windows gets the helper package")
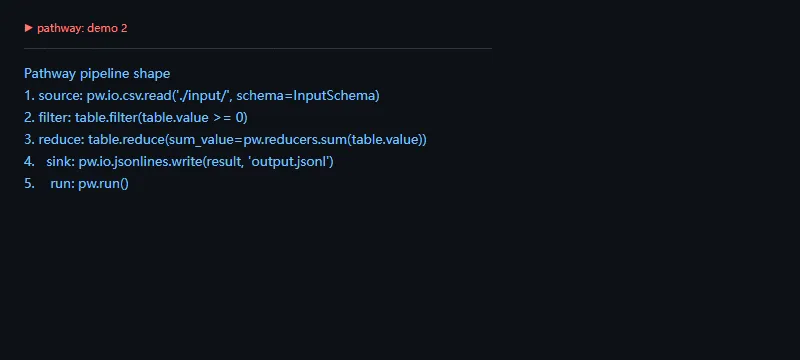
第二段代码解决的问题是:把一个 Pathway 程序拆成 source、transform、sink、run 五个阶段,方便评审数据流。
steps=[("source","pw.io.csv.read('./input/', schema=InputSchema)"),("filter","table.filter(table.value >= 0)"),("reduce","table.reduce(sum_value=pw.reducers.sum(table.value))"),("sink","pw.io.jsonlines.write(result, 'output.jsonl')"),("run","pw.run()"),]print("Pathway pipeline shape")foridx,(name,api)inenumerate(steps,1):print(f"{idx}. {name:>6}: {api}")
环境与版本信息
本文示例使用 Python 3.11.0,本机 pathway 包版本显示为 0.post1,这是 Windows 平台的提示入口,不是正式运行时。真正的 Pathway pipeline 建议在 Linux/macOS 或容器里验证。
高级功能
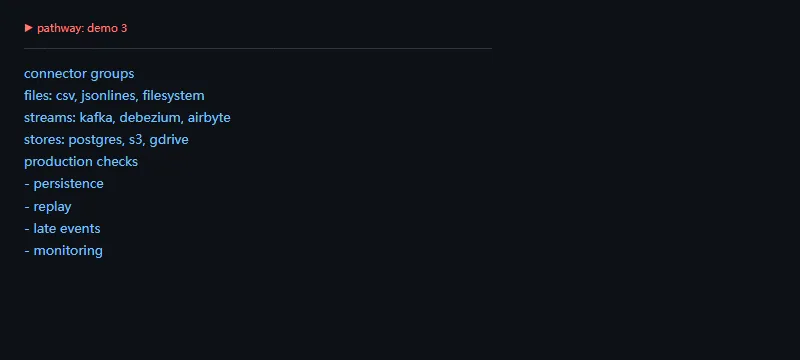
Pathway 的进阶能力通常围绕连接器和状态管理展开。实时系统最怕“能跑但不可恢复”,所以在写业务逻辑前,就要把输入源、输出端、回放策略和监控指标列清楚。
connectors={"files":["csv","jsonlines","filesystem"],"streams":["kafka","debezium","airbyte"],"stores":["postgres","s3","gdrive"],}print("connector groups")forgroup,namesinconnectors.items():print(f"{group}: {', '.join(names)}")print("production checks")foritemin["persistence","replay","late events","monitoring"]:print("-",item)
适用场景
适合实时 ETL、Kafka/文件/数据库数据流、在线 RAG 索引刷新、事件告警和需要增量计算的分析任务。
不适用场景
不适合只做一次性小表清洗,也不适合当前只能在原生 Windows Python 环境运行、无法使用容器或 Linux 运行时的团队。
上线检查
- 在 Linux/macOS 或容器里安装并跑通最小 pipeline。2. 明确输入连接器、输出连接器和状态持久化位置。3. 对回放、迟到数据和失败重启做压测。4. 观察监控面板和日志噪声。
总结
pathway 适合把 Python 数据逻辑推向实时系统。真正使用前,先把运行环境和状态恢复确认好,会比单纯跑通 demo 更重要。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
