这是 Claude Code 深度专栏的第 4 篇。前几篇我们分别聊了 CLAUDE.md 、Agent SDK、拆解Claude Code的一次请求历程。如果说前面是拆原理,那今天就是上战场——直接拿出三份实战配置,分别对应前端 React 项目、后端 Python API 项目、以及 Python 数据分析项目。
看过这三份之后,你会注意到一个挺有意思的事:它们的篇幅都不长,但侧重点截然不同。这不是巧合——每种技术栈里 Claude 最容易翻车的地方不一样,CLAUDE.md 要做的就是精准打击那些"高频出错点"。
一个核心原则:CLAUDE.md 只写 Claude 猜不到的事
在展开具体配置之前,先把今天最核心的原则摆出来。这个原则我之前提过,但值得反复强调,因为太多人把 CLAUDE.md 写成了"新人入职手册"——罗列一堆 Claude 早就知道的通用知识,什么"用 React 18"、"Python 缩进是四个空格"、"用 Git 做版本管理"。
删掉这些。Claude 不需要你告诉它什么是 React,也不需要你提醒 Python 的缩进语法。它需要的是:这个项目独有的约定、抉择和边界规则。
用一条黄金检验标准来量:如果删掉某条规则,Claude 依然能做出正确的行为,那这条规则就不该出现在 CLAUDE.md 里。
带着这根准绳,我们看第一份配置。
实战一:React 前端——管好状态管理和组件边界
先说 React 前端。这个领域里,最让团队头疼的不是语法错误,而是风格割裂。你让 Claude 自由发挥,它极有可能在同一项目里混用 Redux Toolkit、Context API 和本地 useState——不是因为它不懂这些技术,而是它根本不知道你这项目选的是哪条路。
我拿一个团队协作平台的前端项目为例。项目技术栈是 React 18 + TypeScript + Zustand,组件库用的是 Ant Design,样式选的是 CSS Modules。下面这份 CLAUDE.md 你直接看:
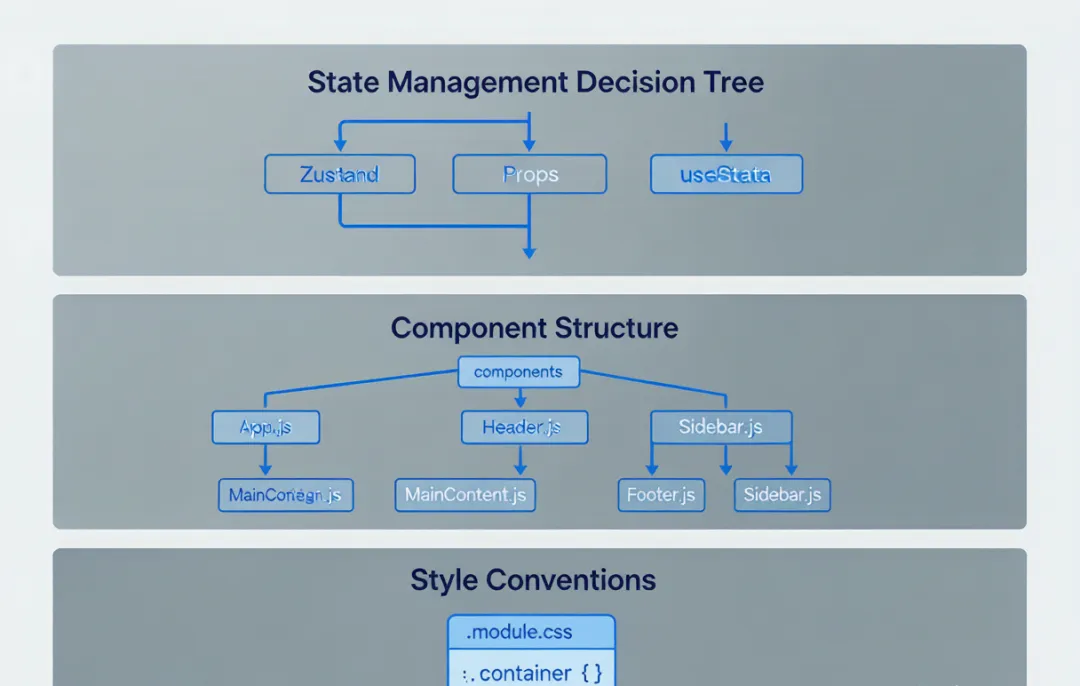
# 项目架构与约定本项目的技术栈选择:React 18 + TypeScript + Zustand + Ant Design + CSS Modules。## 状态管理决策树(必须遵守)- 跨页面/跨模块共享的状态 → 使用 Zustand store(路径统一放在 src/stores/)- 单页面内多个组件共享的状态 → 提升到该页面的容器组件,通过 props 向下传递- 仅单个组件使用的 UI 状态(如弹窗开关、输入框内容)→ 组件内 useState- ❌ 本项目不使用 Redux 或 Context API 做状态管理,不要引入## 组件文件结构每个组件独占一个目录,结构固定为:ComponentName/├── index.tsx # 组件主文件├── styles.module.css # CSS Modules 样式├── types.ts # 该组件的 TypeScript 类型定义└── hooks.ts # 该组件专用的自定义 hooks(如有)命名规范:组件目录和文件名使用 PascalCase。## 网络请求- 所有 API 调用统一通过 src/utils/request.ts 中封装的 axios 实例- 不要在组件中直接 import axios 或裸写 fetch- API 接口类型定义统一放在 src/types/api/ 目录下## 样式约定- 使用 CSS Modules(.module.css),不做全局样式污染- 响应式断点:576px / 768px / 1024px / 1280px- 颜色变量统一引用 src/styles/variables.css 中的 CSS 变
这份配置一共 30 行出头。你仔细看看它的"火力分布"——80% 的篇幅砸在两个问题上:状态管理和组件结构。这就是 React 项目里 Claude 最容易"即兴发挥"导致架构混乱的地方。
特别留意"状态管理决策树"这部分的写法。它不是简单罗列"我们用 Zustand",而是构建了一个"场景 → 工具"的映射:跨页面用 Zustand、单页面用容器提升、局部用 useState。这种决策指导比工具清单有效得多——它直接告诉 Claude,遇到什么场景该走哪条路。
如果你不写这个决策树,只写一句"用 Zustand 做状态管理",Claude 大概率会把所有状态都往 Zustand 里塞,连一个弹窗开关都不放过——毕竟它从字面上理解,就是"所有状态用 Zustand"。
实战二:Python 后端 API——锁死分层架构和 API 约定
Python 后端的麻烦和 React 完全不同。一个典型的 FastAPI 项目,如果 CLAUDE.md 不够清晰,Claude 最容易犯的毛病不是技术选型混乱,而是架构越界——比如在路由函数里直接写数据库查询、在 Service 层裸调第三方 API、或者返回的响应格式每个接口都不一样。
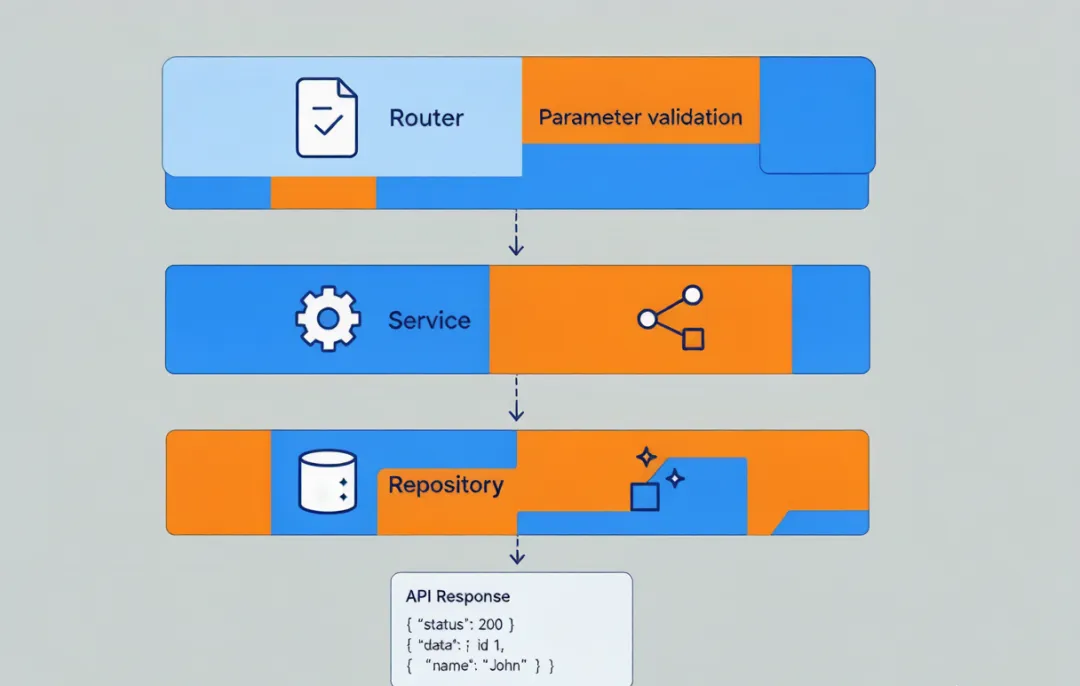
我们看一个任务管理 API 项目。技术栈是 FastAPI + SQLAlchemy + Pydantic v2,数据库用 PostgreSQL。项目采用经典的三层架构:Router → Service → Repository。
# 项目架构与约定本项目是一个任务管理 API 后端,技术栈:FastAPI + SQLAlchemy + Pydantic v2 + PostgreSQL。## 分层架构(严格遵守,不得跨层调用)三层调用链:Router → Service → Repository- **Router 层**:只负责参数校验、调用 Service、返回 HTTP 响应。严禁写业务逻辑。- **Service 层**:业务逻辑的唯一所在。处理事务编排、数据校验、权限检查。- **Repository 层**:只负责数据库 CRUD 操作。严禁写业务逻辑。调用方向是单向的:Router 只能调 Service,Service 只能调 Repository。不允许 Service 之间互相调用,也不允许 Router 直接调 Repository。## API 响应格式(统一封装)所有接口必须使用 src/schemas/response.py 中的 ApiResponse 模型包装:{ "code": 0, "message": "success", "data": { ... }}- code=0 表示成功,非零值为业务错误码- message 为人类可读的描述信息- 错误响应同样使用此格式,只是 code 非零## 依赖注入- 数据库会话、当前用户等横切关注点,使用 FastAPI Depends() 注入- 不要在 Router 函数中手动创建数据库连接- 所有 Depends 放在 src/dependencies/ 目录下## 数据库操作- 使用 SQLAlchemy 2.0 风格的声明式映射- Repository 层的查询方法返回 Pydantic Schema 对象,不返回 ORM 对象- 批量操作使用 bulk_insert_mappings,避免循环单条插入## 命名约定- 文件名:snake_case- 类名:PascalCase(含 Pydantic 模型和 SQLAlchemy 模型)- 函数名:snake_case- 路由 URL:kebab-case(如 /task-lists/{id})
同样是 30 行出头。这份配置的火力集中点完全不一样了——核心是两件事:分层边界和接口一致性。
注意"分层架构"那一段的写法。我不光写了"三层架构"四个字,还明确写了什么能做什么不能做:"Router 不能直接调 Repository""Repository 不能写业务逻辑"。这种"负面清单"非常关键——Claude 在执行具体任务时,很容易为了"省事"跳过某层直接抄近路。明确禁止,就是帮它堵住这条短路。
还有 API 响应格式。你可能觉得这是小事,但如果不写清楚,Claude 生成的接口响应格式会五花八门——有的直接返回裸 dict,有的套了一层不统一的包装,前端那边对接起来就是地狱。事实是,后端接口的响应一致性,往往是团队协作里最容易被忽视、但后患最大的技术债。
实战三:Python 数据分析——堵住数据处理的反模式
数据项目的 CLAUDE.md 又完全是另一副面孔了。如果说前端项目管的是风格漂移、后端项目管的是架构越界,那数据项目管的就是数据处理的反模式。
在没配 CLAUDE.md 的情况下,Claude 处理 pandas 时,有几个特别高频的错误:滥用 inplace=True(破坏数据流的可追溯性)、混用 None 和 pd.NA(导致缺失值处理逻辑乱套)、或者在 Jupyter Notebook 里写的代码没有做模块化,每次都要手动重跑一堆 cell 才能复现结果。
下面这份配置针对的是一个电商运营数据分析项目,技术栈是 pandas + numpy + matplotlib + Jupyter Notebook。
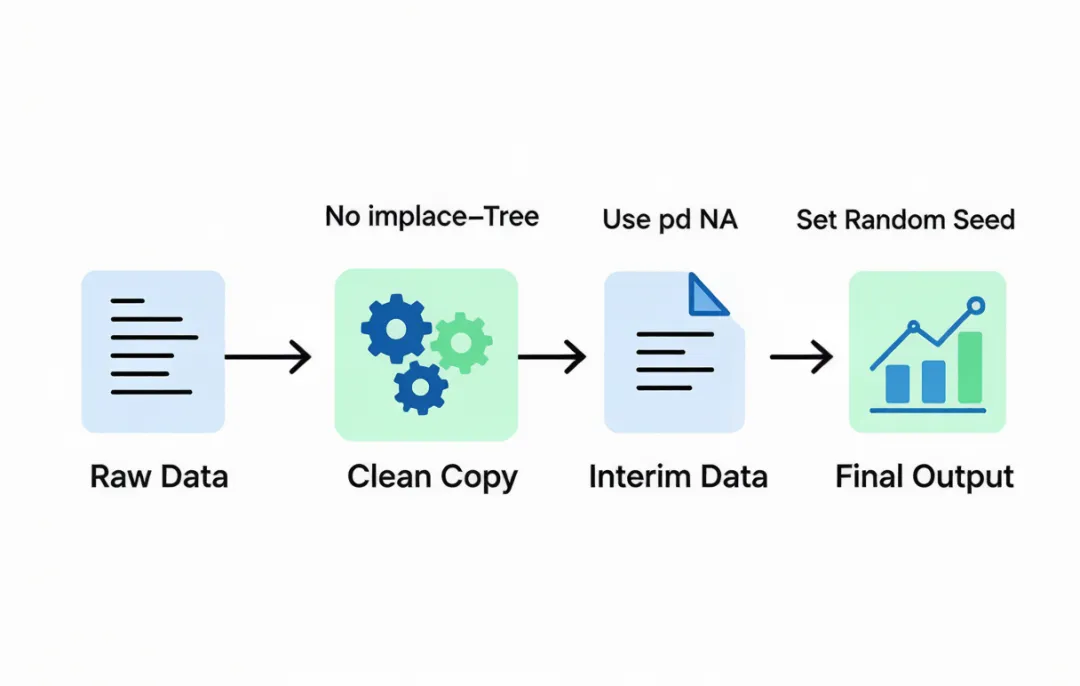
# 项目约定本项目是电商运营数据分析系统,技术栈:pandas + numpy + matplotlib + Jupyter Notebook。## 数据处理铁律(必须遵守)- ❌ 禁止使用 inplace=True。所有 DataFrame 操作必须通过赋值产生新对象。 - 正确:df = df.dropna() - 错误:df.dropna(inplace=True)- 缺失值统一使用 pd.NA,不使用 None 或 np.nan。- 数值列的空值填充:用中位数,不可以用均值(业务数据存在偏态分布)。- 字符串列的空值填充:用 "未知",不可以用空字符串。## 数据流管理- 原始数据(raw data)一旦读入,禁止原地修改。所有清洗和转换操作在副本上进行。- 中间数据输出统一保存到 data/interim/ 目录(Parquet 格式)。- 最终结果输出统一保存到 data/output/ 目录。## 实验复现约定- 每个分析 Notebook 开头固定包含: 1. 数据版本号(日期标签) 2. 随机种子设置(np.random.seed(42)) 3. 依赖包的版本信息(requirements.txt 或 pd.show_versions())- Notebook 从上到下可顺序执行,不允许存在需要手动调整执行顺序的 cell。- 运行 Notebook 前,通过 papermill 参数化传入日期标签,确保每次分析的输入数据版本明确可追溯。## 代码组织- 可复用的数据处理函数放在 src/utils/ 目录下,不要在多个 Notebook 中重复定义相同的函数。- Notebook 只做探索和可视化,核心数据 pipeline 逻辑抽到 .py 文件中。## 日志规范- 数据处理的关键步骤使用 Python logging 模块记录日志,不要用 print()- 日志级别:数据处理完成 → INFO,异常情况 → WARNING
这份配置最关键的规则就是第一条——禁止 inplace=True。你可能会想,这有什么大不了的?问题在于,inplace=True 看起来方便,但它的返回值是 None,你没法在这之后继续链式操作。一旦在数据 pipeline 中间偷偷改了一个 DataFrame,后面的步骤拿到的就是被污染的数据,而且你根本追溯不到在哪一步被改的。对于数据分析来说,可追溯性就是生命线。
同样值得强调的是缺失值那一行——统一使用 pd.NA,不用 None 或 np.nan。pd.NA 是 pandas 1.0 引入的统一缺失值标识,它的行为比 None 和 np.nan 更一致,尤其在类型推断和比较操作中。如果 Claude 在同一个项目里三种表示法混着用,后续的缺失值过滤逻辑会脆弱到你怀疑人生。
三份配置放在一起看
好,三份真实的 CLAUDE.md 都看完了。你注意到没有——每一份都只有二三十行,行行是干货,没有一句废话。
前端项目的火力全砸在状态管理和组件结构上,因为这两个地方是 React 项目里 Claude 最容易搞砸的。后端项目的火力全砸在分层架构和 API 约定上,这恰好是 FastAPI 项目里最容易出现架构腐化的地方。数据项目则把火力集中在数据处理规范和实验复现上——这是数据分析场景下最经不起出错的环节。
这些东西 Claude 猜不到,也没处学——因为每个团队、每个项目的约定都是独特的。而 React 的基本语法、FastAPI 的路由装饰器、pandas 的 groupby 用法,这些东西 Claude 闭着眼睛都能写对,你再写一遍不仅浪费篇幅,还会稀释那些真正关键的规则。
这就是 CLAUDE.md 写作的底层逻辑:少即是多,精准胜于全面。
附:黄金检验标准
写完 CLAUDE.md 之后,对着每一条规则问自己一句:
如果我把这条删了,Claude 还能做对吗?
能做对的——删掉。拿不准的——保留。这条标准没什么玄学,就是帮你砍掉那些"自我感觉良好"的无用配置。
你的 CLAUDE.md 里写的是什么?有没有踩过"写了等于白写"或者"没写后果严重"的坑?留言区聊聊,我挑几条有意思的在下期专栏专门讨论。
点赞在看转发安排上 👍新来的小伙伴记得点个关注 🙏,顺手星标 ⭐超多独家思考定期更新,不关注很容易刷不到,您的支持是我继续写下去的动力 👀

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
