用Python实现A股市场情绪分析:从新闻抓取到情感量化
- 2026-07-13 19:47:15
用Python实现A股市场情绪分析:从新闻抓取到情感量化
📈 当市场恐慌时贪婪,当市场贪婪时恐惧。但问题是——如何量化"恐慌"和"贪婪"?
2026新年快乐,预祝各位粉丝和量化开发者新年好运,万事如意!
作为一名量化爱好者,我一直在思考一个问题:能否通过分析财经新闻,量化当前市场情绪?
今天分享一个我用Python实现的市场情绪分析系统,它能够:
🔄 自动抓取财联社、新浪财经等实时新闻 💾 存储到SQLite数据库,支持历史回溯 🧠 基于金融词典的情感分析 📊 输出仪表盘分数,直观展示市场温度
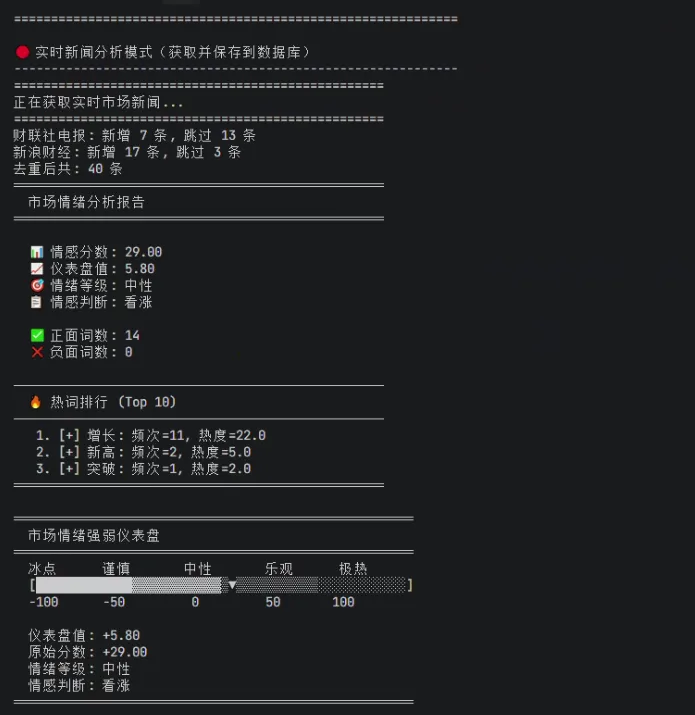
效果如下:
══════════════════════════════════════════════════ 市场情绪分析报告══════════════════════════════════════════════════ 📊 情感分数: 11.60 📈 仪表盘值: 2.32 🎯 情绪等级: 中性 📋 情感判断: 看涨 ✅ 正面词数: 9 ❌ 负面词数: 2══════════════════════════════════════════════════一、核心思路
整个系统分为三层:
┌─────────────────────────────────────────┐│ 数据采集层 ││ 财联社API → 新浪财经API → ... │└─────────────────┬───────────────────────┘ ↓┌─────────────────────────────────────────┐│ 数据存储层 ││ SQLite (news表) │└─────────────────┬───────────────────────┘ ↓┌─────────────────────────────────────────┐│ 情感分析层 ││ 分词 → 情感词典匹配 → 分数计算 │└─────────────────────────────────────────┘二、金融情感词典
情感分析的核心是词典。我这里构建了专门针对A股市场的金融词典:
# 正面金融词汇及其权重positive_words = { "涨": 1.0, "上涨": 2.0, "涨停": 3.0, "牛市": 3.0, "反弹": 2.0, "新高": 2.5, "利好": 2.5, "增持": 2.0, "盈利": 2.0, "突破": 2.0, "创新高": 3.0, "大涨": 2.5, "飙升": 3.0, "暴涨": 3.0, # ... 更多词汇}# 负面金融词汇及其权重negative_words = { "跌": 2.0, "下跌": 2.0, "跌停": 3.0, "熊市": 3.0, "利空": 2.5, "减持": 2.0, "亏损": 2.5, "暴跌": 3.0, "崩盘": 3.0, "跳水": 3.0, # ... 更多词汇}# 否定词(用于反转情感)negation_words = {"不", "没", "无", "非", "未", "别"}# 程度副词(用于调整强度)degree_words = { "非常": 1.8, "极其": 2.2, "大幅": 1.8, "小幅": 0.7, "稍微": 0.6,}# 转折词(转折后的情感更重要)transition_words = {"但是", "然而", "不过", "却", "可是"}设计要点:
- 权重分级
普通词汇权重1-2,强烈词汇权重2.5-3 - 否定词处理
"不看好" = 看好的反向 - 程度副词
"大幅上涨" 比 "上涨" 情感更强 - 转折词
"虽然下跌,但是反弹" → 反弹更重要(×1.5)
三、情感分数计算
核心算法如下:
def calculate_score(self, words: List[str]) -> Tuple[float, int, int]: """计算情感得分""" score = 0.0 positive_count = 0 negative_count = 0 i = 0 while i < len(words): word = words[i] # 检查是否为正面词 if word in self.positive_words: pos_score = self.positive_words[word] # 检查前一个词是否为否定词 if i > 0 and words[i-1] in self.negation_words: score -= pos_score # 反转! negative_count += 1 # 检查前一个词是否为程度副词 elif i > 0 and words[i-1] in self.degree_words: score += pos_score * self.degree_words[words[i-1]] positive_count += 1 else: score += pos_score positive_count += 1 # 检查是否为负面词(逻辑类似,省略) elif word in self.negative_words: # ... 类似处理 pass i += 1 return score, positive_count, negative_count转折词处理:
def analyze(self, text: str) -> SentimentResult: words = self.tokenize(text) # 检查是否有转折词 for i, word in enumerate(words): if word in self.transition_words: # 转折前 pre_score, _, _ = self.calculate_score(words[:i]) # 转折后(权重×1.5) post_score, _, _ = self.calculate_score(words[i+1:]) post_score *= 1.5 return pre_score + post_score # 无转折 return self.calculate_score(words)四、新闻数据采集
以财联社为例:
class MarketNewsApi: def get_cls_telegraph(self) -> List[Telegraph]: """获取财联社电报""" url = "https://www.cls.cn/nodeapi/telegraphList" headers = { "Referer": "https://www.cls.cn/", "User-Agent": "Mozilla/5.0 ..." } resp = requests.get(url, headers=headers, timeout=30) data = resp.json() telegraphs = [] if data.get("error") == 0: for item in data["data"]["roll_data"]: telegraph = Telegraph( title=item.get("title", ""), content=item.get("content", ""), source="财联社电报", is_red=item.get("level") != "C", # 重要新闻 data_time=datetime.fromtimestamp(item["ctime"]) ) telegraphs.append(telegraph) return telegraphs五、SQLite数据存储
class NewsDatabase: def __init__(self, db_path: str = "stock_monitor.db"): self.db_path = db_path self._init_db() def _init_db(self): """初始化数据库表""" conn = sqlite3.connect(self.db_path) conn.execute(''' CREATE TABLE IF NOT EXISTS news ( id INTEGER PRIMARY KEY AUTOINCREMENT, title TEXT, content TEXT, time TEXT, data_time DATETIME, source TEXT, is_red INTEGER DEFAULT 0, sentiment_result TEXT, created_at DATETIME DEFAULT CURRENT_TIMESTAMP ) ''') conn.commit() def save_news(self, telegraph: Telegraph) -> bool: """保存新闻(自动去重)""" conn = sqlite3.connect(self.db_path) # 检查是否已存在 if telegraph.title: count = conn.execute( 'SELECT COUNT(*) FROM news WHERE title = ?', (telegraph.title,) ).fetchone()[0] else: count = conn.execute( 'SELECT COUNT(*) FROM news WHERE content = ?', (telegraph.content,) ).fetchone()[0] if count > 0: return False # 已存在 # 插入新记录 conn.execute(''' INSERT INTO news (title, content, source, data_time, created_at) VALUES (?, ?, ?, ?, ?) ''', (telegraph.title, telegraph.content, telegraph.source, telegraph.data_time, datetime.now())) conn.commit() return True def get_news_24hours(self, limit: int = 1000) -> List[Telegraph]: """获取24小时内的新闻""" conn = sqlite3.connect(self.db_path) time_24h_ago = (datetime.now() - timedelta(hours=24)).isoformat() rows = conn.execute(''' SELECT title, content, source, data_time, is_red FROM news WHERE created_at > ? ORDER BY data_time DESC LIMIT ? ''', (time_24h_ago, limit)).fetchall() return [Telegraph( title=row[0], content=row[1], source=row[2], data_time=row[3], is_red=bool(row[4]) ) for row in rows]六、仪表盘分数
为了直观展示,我们将原始分数转换为仪表盘值:
# 仪表盘值 = 原始分数 × 0.2# 范围: -100 到 100def get_emotion_level(gauge_value: float) -> str: """根据仪表盘值获取情绪等级""" if gauge_value <= -75: return "冰点" # 极度悲观 elif gauge_value <= -25: return "谨慎" elif gauge_value <= 25: return "中性" elif gauge_value <= 75: return "乐观" else: return "极热" # 极度贪婪对照表:
七、一键使用
命令行方式
# 1. 获取新闻并保存到数据库python market_sentiment.py --fetch# 2. 从数据库查询24小时新闻分析python market_sentiment.py --db# 3. 一步到位:获取+保存+分析python market_sentiment.py --livePython API
from market_sentiment import *# 方式1: 快速分析单条文本result = quick_analyze("今日大盘强势上涨,多只个股涨停")print(result)# {'score': 9.5, 'emotion_level': '中性', 'description': '看涨'}# 方式2: 获取新闻并保存fetch_and_save_news()# 方式3: 从数据库分析24小时新闻(推荐)result = analyze_from_db()print(f"情绪等级: {result['gauge']['level']}")print(f"仪表盘值: {result['gauge']['value']}")# 方式4: 查看数据库统计stats = get_news_stats(hours=24)# {'total': 150, '财联社电报': 100, '新浪财经': 50}八、实战效果
这是节后第一天上班我跑的运行结果:
九、扩展思路
- 定时任务
:结合crontab,每小时自动采集分析 - 可视化
:用ECharts绑定仪表盘,做成Web页面 - 多源聚合
:接入东方财富、同花顺等更多数据源 - 机器学习
:用历史数据训练,预测次日大盘涨跌 - 预警推送
:当情绪达到极值时,推送微信/钉钉通知,或接入量化交易程序,提高胜率,避免单方面下跌行情。
写在最后
市场情绪只是辅助参考,不能作为唯一的投资依据。
但有了这个工具,至少能帮我们量化回答:"现在市场是恐慌还是贪婪?"
免责声明: 本文所提及的算法,不构成任何具体的投资建议。市场有风险,投资需谨慎。请您基于自身的独立判断进行决策。
本次研究的Python源码已经放到星球了,需要的自取。近期有粉丝加入星球,但优惠券已过期,应粉丝要求,现发放新的优惠券给大家,请领取使用。
终极量化数据实验室星球,已经运行半年多,现对外开放,前50名成员可领取下方优惠券加入。
星球向您提供六大服务:python基础,数据分析,量化编程,策略实现,模拟回测指导,软件解决方案指导,代码和数据在星球全部开源。
往期文章精选
高胜率机会!一套完整的A股“跳空缺口回补”策略+附源码
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

