龙哥读论文学术交流群(知识星球)来了!每日提供最新最快最好的CV/DL/ML/LLM论文速递、优质开源项目、学习教程和实战训练等资料!
元旦福利暴击!!🐉 龙哥读论文知识星球:让你看论文像刷视频一样简单!元旦星球优惠券限时放送,每次发券少10元,现在是最优选!元旦假期专属,有效期截止26年1月16日,扫码立减,解锁一整年的论文干货+技术资源!手慢则无,冲就对了!

龙哥推荐理由:
这篇论文精准地戳中了当前大模型发展的两大痛点:高质量通用推理数据从哪来?以及如何更高效地训练模型? 腾讯Hunyuan团队提出的ULTRALOGIC框架,不仅像一台“代码印钞机”一样能无限生成海量、多样且难度可控的推理题,还创新性地引入了“负分”奖励机制,让模型对“差不多就行”的答案感到“肉疼”,从而逼着它走向完美。这种“数据生产+训练机制”的组合拳,思路清晰,效果显著,对推动大模型推理能力的发展极具启发性和实用价值。
原论文信息如下:
论文标题:
ULTRALOGIC: Enhancing LLM Reasoning through Large-Scale Data Synthesis and Bipolar Float Reward
发表日期:
2026年01月
发表单位:
Hunyuan, Tencent; Waseda University
原文链接:
https://arxiv.org/pdf/2601.03205v1.pdf
最近大模型圈真是热闹,各种推理模型层出不穷。但你有没有发现一个怪象?🤨 号称能“推理”的模型,很多在解决像“张三、李四、王五谁说谎”这种经典逻辑谜题时,表现依然拉胯。问题出在哪?今天的论文就给你答案。
原因很简单:空有屠龙术,无龙可屠。 模型想学会通用推理,需要海量的、高质量的、难度各异的推理题来训练。而现实中,这样的数据比熊猫血还稀缺。
别急,腾讯Hunyuan团队出手了!他们搞了个叫ULTRALOGIC的框架,号称是“逻辑数据印钞机”,能量产无限推理题,还能给每道题标上精确的“难度等级”。更绝的是,他们还给强化学习训练加了个“负分”机制,让模型对“差不多就行”的答案感到“肉疼”,逼着它走向完美逻辑。
话不多说,跟着龙哥一起拆解这篇被多家外媒报道的硬核论文,看看他们是如何“凭空造海”来解决大模型推理的数据饥渴症的。破解LLM通用推理瓶颈:数据从哪来?
想让大模型(LLM)学会像人一样“思考”,进行多步骤的逻辑推理、规划和验证,是AI迈向更高智能的关键瓶颈。目前一个非常有效的训练范式叫做基于可验证奖励的强化学习。简单说,就是给模型出一个题(比如数学题、代码题),模型给出答案后,系统能自动判断对错(比如运行单元测试、比对数学答案),并把“对/错”作为一个明确的奖励信号,用来指导模型下一次如何改进。
这招在数学、编程等有明确答案的领域效果拔群。但当我们想把它扩展到更通用的推理领域时,问题来了:高质量的训练数据从哪来?
现有的通用推理数据集,要么任务类型单一,覆盖不了五花八门的推理场景;要么像一锅大杂烩,题目难度忽高忽低,没有清晰的分级。这就好比教小孩,一会儿让他做1+1,一会儿又扔给他一道微积分,学习效率能高才怪。训练数据的难度如果无法与管理模型的当前能力匹配,就会严重影响学习效率和稳定性。
所以,核心矛盾就是:我们迫切需要一套能自动化、大规模生产高质量、多样化且难度可控的通用推理数据的“流水线”。 这就是ULTRALOGIC框架诞生的背景。
ULTRALOGIC框架:如何自动化生产海量推理题?
ULTRALOGIC的核心思想非常巧妙:将一个推理问题的“逻辑内核”与它的“自然语言表达”剥离开。
想象一下,一个逻辑谜题的核心是几条规则和几个变量(比如:5个人,每人说一句话关于谁说真话)。我们可以用代码(输入函数)来生成这些变量,也可以用另一段代码(解题函数)根据规则算出唯一答案。至于题目是用“侦探破案”还是“公司开会”的背景故事讲出来,那只是“皮肤”而已,可以随意更换。
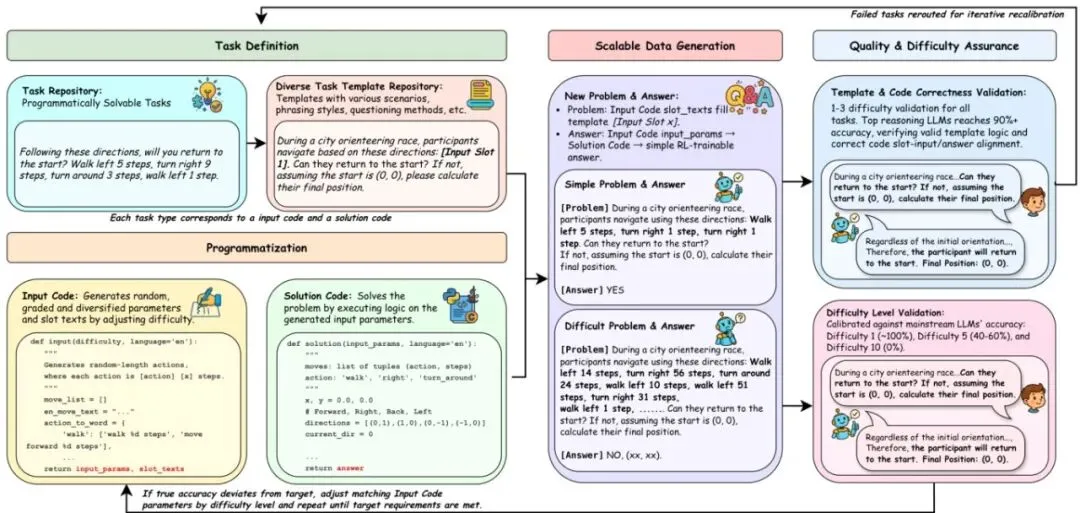
基于这个“代码化解题框架”,ULTRALOGIC搭建了一条完整的自动化流水线。它的整体架构如图1所示:
1. 原始任务仓库:这是多样性的源泉。团队建立了一个包含数百种独特任务类型的仓库。为了确保系统性和新颖性,他们设计了一个三维正交分类系统来给每个任务打标签:
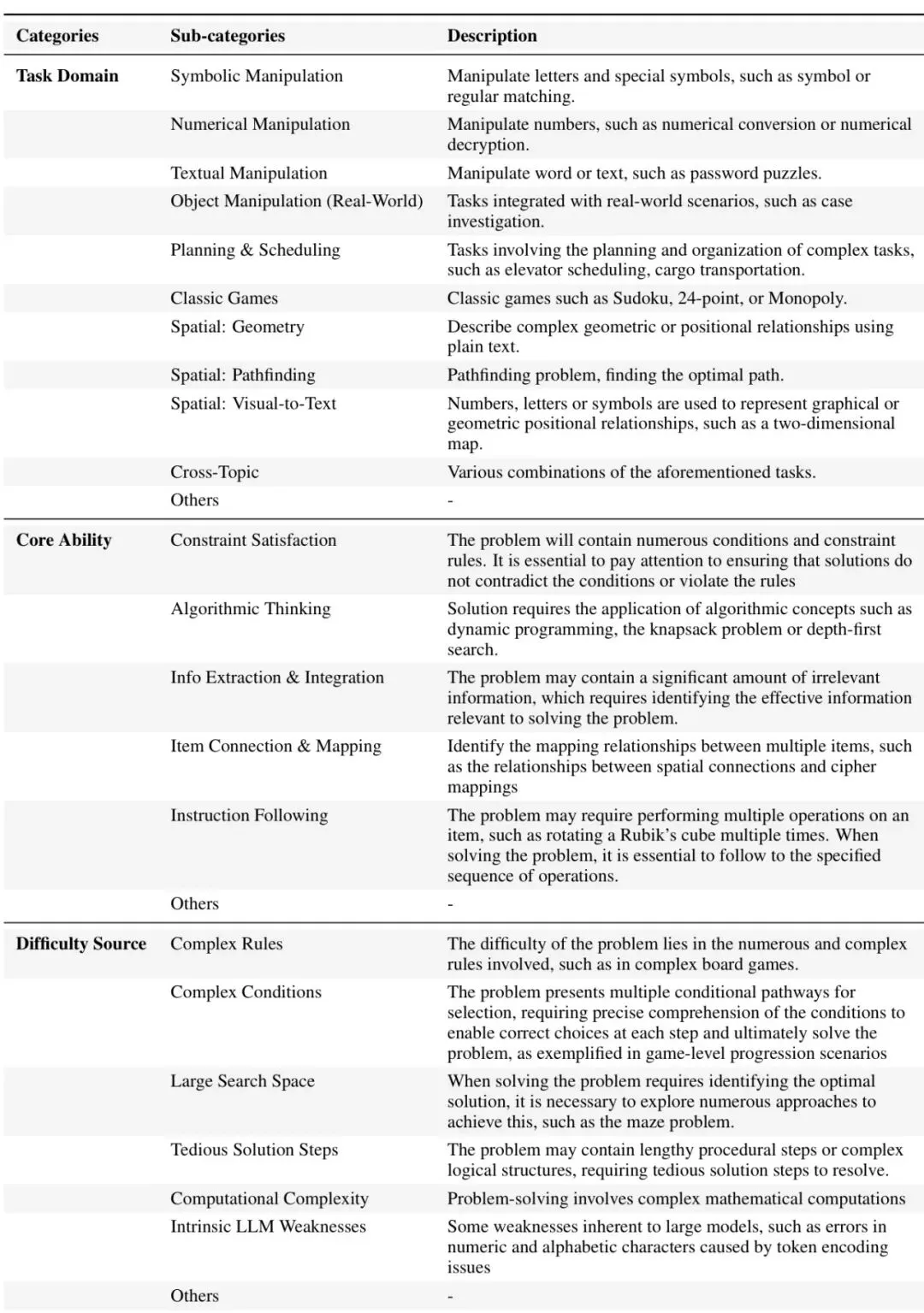
表3:ULTRALOGIC任务库的三维正交分类系统。· 任务领域:问题发生的场景,比如符号操作、数字游戏、现实物体操作、规划调度、经典游戏(数独)、空间几何/寻路等。· 核心能力:解题需要的关键认知技能,比如约束满足、算法思维、信息提取与整合、项目连接与映射、指令遵循等。· 难度来源:问题到底难在哪?是规则复杂、条件繁多、搜索空间巨大、解决步骤繁琐,还是计算复杂,甚至是利用了LLM固有的弱点(如数字字符编码易错)。
一个任务就是这三个维度交叉点的产物,确保覆盖了推理能力的方方面面。
2. 多样化模板仓库:这是为了防止模型死记硬背题目文本。对于每个任务类型,团队会先用LLM分析一个原始问题,抽取出核心逻辑和可变的“槽位”,生成一个基础模板。然后,再用LLM为这个基础模板生成多达10个不同叙事背景的变体(比如侦探故事、科幻场景、公司会议),而核心逻辑和槽位保持不变。最后由人工审核,确保语言流畅、逻辑一致。这个仓库原生支持中英文,方便训练双语模型。
· 输入代码生成:为每个任务类型编写一个Python的 `input(difficulty, language)` 函数。它接收一个难度等级和目标语言,然后根据一套规则,随机生成填充模板槽位所需的核心参数数据。因为参数是随机生成的,所以理论上可以为任何任务类型产生无限多道 unique 的题目。· 解题代码生成:配套一个 `solution(params, language)` 函数。它接收与输入函数完全相同的参数 `params`,运行一个确定性算法,计算出该问题实例的绝对正确答案。由于问题和答案共享同一套参数生成逻辑,从设计上就保证了“题”和“答案”的完美同步与正确性。
这样,选定一个任务类型和一个模板,调用输入函数生成参数,填入模板得到题目文本,再调用解题函数得到答案。一条高质量的数据就诞生了。由于整个过程是程序化的,可以轻松实现大规模生产。难度可控的秘诀:十级天梯与自动校准
光有大量题目还不够,还得知道每道题有多难。ULTRALOGIC设计了一个统一的1-10级难度天梯,并通过一个自动校准闭环来保证难度设定的客观性和可重复性。
具体怎么操作?系统首先为特定等级预定义目标成功率,例如:
· 等级1:约100%(送分题)
· 等级3:约70%
· 等级5:约50%(半对半错,最有挑战性)
· 等级7:约30%
· 等级10:约0%(地狱难度)
接着,系统用当前的输入/解题函数生成一批测试样本,然后用多个开源的主流模型去尝试解答,计算实际的平均成功率。如果实际成功率偏离了目标值,一个自动化算法就会动态调整输入和解题函数内部的复杂度参数(比如增加推理步骤、添加干扰条件等),直到实际成功率收敛到目标范围内。
这个过程本质上是让系统自己“思考-行动-观察”,反复迭代,最终为每个任务类型找到对应10个难度等级的完美参数配置。一旦配置确定,就可以无限扩展。这个设计非常聪明,因为它使得难度定义可以超越当前模型的水平,未来有更强的模型出现时,只需重新校准,就能生成更难的题目来挑战它。
超越对与错:双极浮点奖励如何引导模型精益求精?
有了高质量的数据,训练方法也得跟上。传统的强化学习通常使用二元奖励:答案全对得1分,有任何错误就得0分。这在复杂多步推理中有一个致命缺陷:信号过于稀疏且缺乏区分度。
想象一下,模型费了九牛二虎之力,推理过程几乎全对,只在最后一步犯了个小错,得0分;而另一个模型从一开始就胡言乱语,也得0分。这对前者太不公平了!它无法从“接近正确”的尝试中获得任何有用的反馈,学习效率自然低下。
一个自然的想法是:引入连续分数,比如在[0, 1]区间打分,0.9分代表“几乎全对”。然而实验发现,这会导致模型陷入“非负奖励陷阱”:既然只要不是最烂就能得正分,模型就失去了探索完美逻辑链的动力,容易满足于“差不多就行”的次优解。
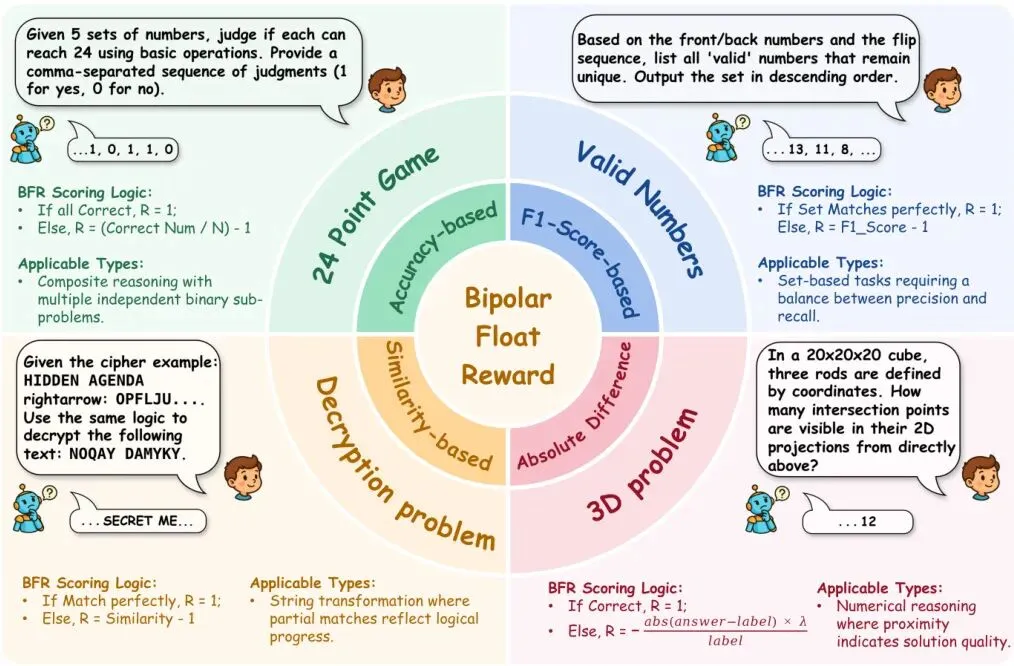
于是,本文提出了杀手锏——双极浮点奖励。它的规则简单粗暴却极其有效:
· 只有完全正确的答案,得 +1.0 分。
· 任何不完美的答案,根据其“正确程度”获得一个负分,范围在 [-1.0, 0)。
具体操作是:先像之前一样,给答案评一个[0, 1)区间的部分正确分数S。然后,对不完美的答案执行一个关键变换:最终奖励 = S - 1。
这意味着,一个得0.9分的“几乎正确”答案,最终奖励是 -0.1分;一个得0.1分的“几乎全错”答案,最终奖励是 -0.9分。而在+1.0和-1.0之间,存在一个巨大的“奖励悬崖”。
这个设计的精妙之处在于它强制的逻辑:“不完美就是错误,而且错得越多,罚得越狠。” 它构建了一个高效的“推-拉”动态机制:+1.0的满分像一块磁铁,把模型往完美答案上“拉”;而根据错误程度给出的负分,则像一只无形的手,把模型从错误的推理路径上“推”开,错误越离谱,推力越大。
那么,如何量化“部分正确”呢?BFR机制为不同任务类型匹配了最合适的评分方法,如图2所示:· 准确率:适用于分类或列表类任务,比如“哪些人说真话”。模型列出的人与标准答案比对。· F1分数:同样是列表任务,但同时考虑“找对了多少”和“找错了多少”,比单纯准确率更全面。· 相似度:适用于字符串匹配、解码等任务,计算模型输出与标准答案的文本相似度。· 绝对差异率:适用于数值答案,计算模型给出的数值与标准答案的绝对误差比例。
通过这种设计,BFR以较低的成本(无需人工标注每一步推理),为模型提供了信息密度极高的训练信号,有效驱动其逼近逻辑上的全局最优解。实验验证:任务多样性与难度匹配是关键
理论再好,也得实验说话。团队在Qwen3-8B和14B模型上进行了系统的消融实验。
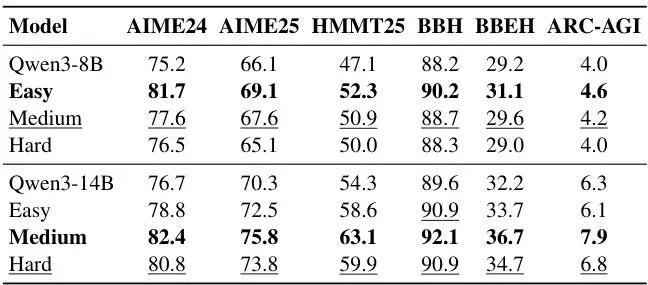
首先验证“难度匹配现象”。他们用不同难度(简单1-4级,中等4-7级,困难7-10级)的数据集分别训练模型,然后在包括AIME、BBH等多个权威推理基准上测试。结果如表1所示:
结果非常有意思:对于较小的Qwen3-8B模型,在简单难度数据上训练效果最好(Easy > Medium > Hard)。而对于能力更强的Qwen3-14B模型,则在中等难度数据上训练效果最佳(Medium > Hard > Easy)。这与教育心理学中的“最近发展区”理论完美契合:学习效率最高的区域,是那些略高于学生当前水平,但通过努力能够得着的任务。ULTRALOGIC的精细难度分级,使得为不同规模的模型“量身定制”训练课程成为可能。
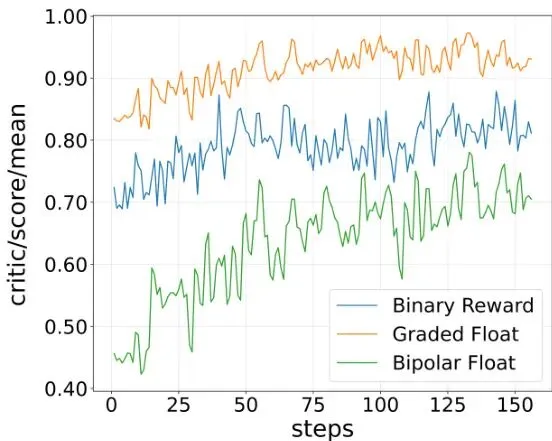
其次验证BFR机制的有效性。在Qwen3-8B上对比了三种奖励机制:二元奖励{0,1}、连续正分奖励[0,1]、以及本文提出的双极浮点奖励[-1,0)∪{1}。结果如表2和图3所示:
BFR在几乎所有基准测试上都取得了最优性能,显著超越了二元奖励基线,并且在收敛速度和最终准确率上都优于连续正分奖励。图3中的训练曲线显示,BFR为策略网络提供了更清晰、更高效的优化信号。
这些实验强有力地证明了:1. 任务多样性是提升通用推理能力的主要驱动力;2. 将训练难度匹配模型当前能力至关重要;3. 引入分级惩罚的双极奖励机制能有效打破复杂推理任务的性能瓶颈。局限与展望:迈向完全自动化的推理训练
尽管ULTRALOGIC框架取得了显著成果,但论文也诚实地指出了其局限:
对人工标注的依赖:逻辑推理任务对精确度的要求极高。实验发现,基于可验证奖励的强化学习对数据噪声的容忍度极低,50个任务类型中哪怕有1-3个存在逻辑错误,都可能导致整个训练崩溃。因此,在种子任务逻辑验证、初始难度校准等关键环节,仍然需要高质量的人工介入来确保100%的逻辑严谨性。这是追求“黄金标准”数据集必须付出的代价。
奖励标度的启发式性质:BFR机制虽然有效,但其具体的奖励值设置(如S-1变换)目前更多是基于直觉和经验。理论上,对于不同逻辑深度的任务,可能存在更精确、更细致的非整数奖励信号能提供更优的指导。但在缺乏通用方法论来自动搜索“数学上完美”的奖励值之前,当前这种稳健且直观的设置是确保梯度动态稳定的务实选择。
未来,一个重要的方向是探索如何在保证逻辑绝对正确的前提下,进一步减少对人力的依赖,实现从任务定义、数据生成到难度校准、奖励设计的全流程自动化。同时,将ULTRALOGIC框架与更多样的模型架构、更先进的训练算法结合,也大有可为。
龙迷三问
ULTRALOGIC到底是什么?它是由腾讯Hunyuan团队提出的一个自动化框架,用于大规模合成高质量、多样化且难度可控的通用逻辑推理训练数据。其核心是“代码化解题”思想,将问题的逻辑内核与语言表达解耦,通过程序化方式无限生成题目和答案。
BFR(双极浮点奖励)机制具体是怎么工作的?它是一种用于强化学习的奖励设计。规则是:只有完全正确的答案得+1分;任何不完美的答案,先根据其“正确程度”在[0,1)区间打分(S),然后通过“S-1”的变换,将其映射到负分区间[-1,0)。错误越严重,负分绝对值越大。这创造了一个“奖励悬崖”,强制模型追求完美,避免满足于次优解。
文中提到的GRPO算法是什么?GRPO (Group Relative Policy Optimization,分组相对策略优化) 是本文采用的核心策略优化算法,由深度求索公司在DeepSeekMath工作中提出。它是一种高效的强化学习算法,特别适用于基于可验证奖励的大模型训练。其核心思想是在一个批次(分组)的样本中计算相对优势,从而更稳定地进行策略更新。文中那个关于优势函数Â的公式就是GRPO计算的一部分。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★★
将“逻辑内核代码化”的思想贯穿始终,构建了从任务定义、模板生成、数据合成到难度校准的完整自动化流水线,思路清晰完整。BFR机制的设计简单却深刻,直指传统奖励机制的痛点。实验合理度:★★★★☆
实验设计系统,从难度匹配和奖励机制两个核心点进行消融,验证充分。使用了Qwen3系列不同规模的模型,并在多个外部基准测试,结果可信。扣一星在于对比基线可能还可以更丰富,例如与更多数据合成方法或奖励模型进行对比。学术研究价值:★★★★★
价值极高。不仅提供了一个可扩展的高质量数据生产范式,解决了领域内的一大痛点;其提出的“难度匹配现象”和“双极奖励”机制,对如何更高效地训练大模型推理能力提供了重要的理论和实践启示,具有很强的普适性和启发性。稳定性:★★★☆☆
论文自身承认对数据逻辑错误的容忍度极低,50个任务中混入少量错误即可导致训练崩溃。这表明框架的“上游”(数据生成与验证)必须极其稳固,否则下游训练非常脆弱。BFR机制虽然提升了训练效率,但其稳定性也高度依赖于评分函数设计的合理性。适应性以及泛化能力:★★★★☆
框架本身设计用于生成“通用推理”数据,三维分类系统覆盖了广泛的推理技能。自动难度校准机制使其能适应不同能力的模型。但当前任务类型仍依赖于人工定义和筛选,在向更开放、更复杂的现实世界推理场景泛化时,可能需要持续扩充任务库。硬件需求及成本:★★☆☆☆
数据合成阶段成本较低,主要依赖于代码运行。但后续的强化学习训练阶段成本高昂,论文中提到训练Qwen3-8B/14B模型2个epoch就需要120-300小时,并使用64块GPU。这属于当前大模型RL训练的典型高成本范畴。复现难度:★★☆☆☆
难度较高。虽然论文附录给出了详细的Prompt和流程说明,但构建包含数百个任务类型、配套代码和模板的完整仓库需要巨大的人工投入。目前论文未开源完整数据集和代码,复现其完整工作门槛很高。产品化成熟度:★★★☆☆
作为一种模型训练的基础设施和方法论,其思路已相对成熟,可以被AI研发团队内部采纳用于提升模型推理能力。但距离作为一个独立的、开箱即用的产品还有距离,主要因其对高质量人工校验的依赖和高昂的训练成本。可能的问题:
本文的亮点在于系统性的框架构建和巧妙的机制设计,工程实现价值突出。但从顶会要求角度看,理论深度有所欠缺,BFR机制和难度匹配现象更多是基于实验现象的归纳与启发式设计,缺乏更严格的理论分析与证明。此外,实验部分对“任务多样性”的贡献分析可以更量化一些。[1] Yile Liu, Yixian Liu, et al. "ULTRALOGIC: Enhancing LLM Reasoning through Large-Scale Data Synthesis and Bipolar Float Reward." arXiv preprint arXiv:2601.03205 (2026).原文链接:https://arxiv.org/pdf/2601.03205v1.pdf
*本文仅代表个人理解及观点,不构成任何论文审核意见,具体以同行评议结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

加入【龙哥读论文】知识星球,助你高效突破科研瓶颈,前沿研究一手掌握!
元旦福利暴击!!🐉 龙哥读论文知识星球:让你看论文像刷视频一样简单!元旦星球优惠券限时放送,每次发券少10元,现在是最优选!元旦假期专属,有效期截止26年1月16日,下方扫码立减,解锁一整年的论文干货+技术资源!手慢则无,冲就对了!

欢迎加入龙哥读论文粉丝群,
添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 图像处理+上海+清华+龙哥),根据格式备注,可更快被通过且邀请进群。