截止时间调度(SCHED_DEADLINE,简称DL)是 Linux 内核的高精度实时调度机制,允许任务以 “每周期最多运行多久(runtime)” 的方式使用CPU,确保在deadline前获得可预测的执行资源,适用于音视频、工业控制等时序敏感场景。
在深入介绍DL调度器的细节之前,我们先介绍一下相关的参数和一些基本数据结构。
相关参数和数据结构
在使用DL调度策略时,需要指定三个关键参数:
- • 周期(dl_period):任务的激活间隔,即每隔多长时间启动一次新的执行实例;
- • 运行时间(dl_runtime):在每个周期内,任务最多可使用的 CPU 时间;
- • 截止时间(dl_deadline):从周期开始起,任务必须在此时间内完成其工作。
这三个参数共同定义了任务的实时行为和资源需求,是DL实现确定性调度的基础,写代码时可以通过 sched_setattr() 指定这三个参数,参数值最终会被存放到sched_dl_entity调度实体中,Linux内核执行调度时依据调度实体的取值来做决策。
我们通过配置关键参数来启动一个具体的DL任务:
// 用户空间兼容定义(若未包含 linux/sched/types.h)structsched_attr {unsignedint size;unsignedint sched_policy;unsignedlonglong sched_flags;int sched_nice;unsignedint sched_priority;unsignedlonglong sched_runtime;unsignedlonglong sched_deadline;unsignedlonglong sched_period;};int main() {structsched_attrattr = { .size = sizeof(struct sched_attr), .sched_policy = SCHED_DEADLINE, //指定使用 deadline 调度策略 .sched_runtime = 2000000ULL, // 2 ms .sched_deadline= 8000000ULL, // 8 ms .sched_period = 10000000ULL// 10 ms };if (syscall(__NR_sched_setattr, 0, &attr, 0) == -1) { perror("sched_setattr");return1; }// ... 执行实时工作负载 ...}
那么这个任务的运行情况应该是:每10ms构成一个调度周期,周期开始时获得2ms的 CPU 预算,必须在8ms截止期限前完成工作;若提前完成,剩余时间立即释放;若用尽 2ms 仍未完成,则被节流,暂停执行,直到下一周期恢复预算并继续运行。
在NanoCode中执行下面的命令就可以列出就绪队列上的各个任务:
!ndx.ready 6 -f 1
结果如下:

当前正在运行一个 DL 测试任务
其调度实体sched_dl_entity的地址为0xffff00010df551c8。可通过 dt 命令进一步查看该实例的字段内容:
dt lk!sched_dl_entity 0xffff00010df551c8
显示如下:
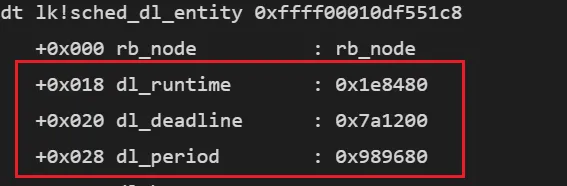
这是16进制的数据,换算成十进制并转换单位:
- • dl_runtime = 0x1e8480 ns=2ms
- • dl_deadline = 0x7a1200 ns= 8ms
- • dl_period = 0x989680 ns=10 ms
从结果可以看出,通过sched_setattr() 设置的参数已成功写入任务的调度实体sched_dl_entity中。
再看运行时状态中的两个关键字段:
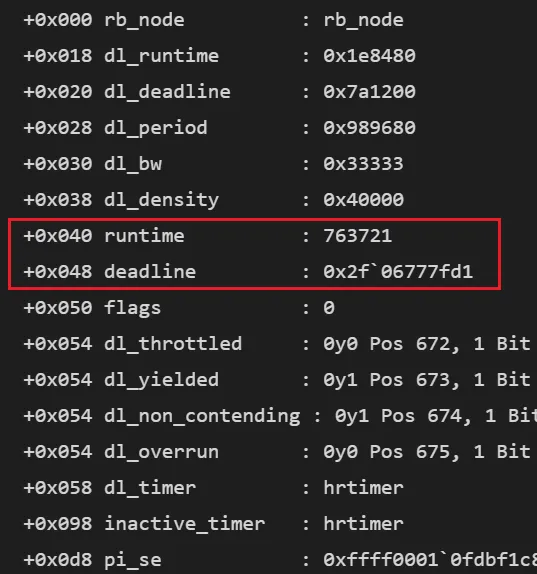
- • runtime = 763721 ns ≈ 0.76 ms:这是
当前周期中剩余的运行时间,表示该任务还能继续使用 CPU 约 0.76 毫秒。 - • deadline = 0x2f06777fd1≈199 秒(自系统启动起):这是一个
绝对时间戳,代表当前调度周期的截止时刻。
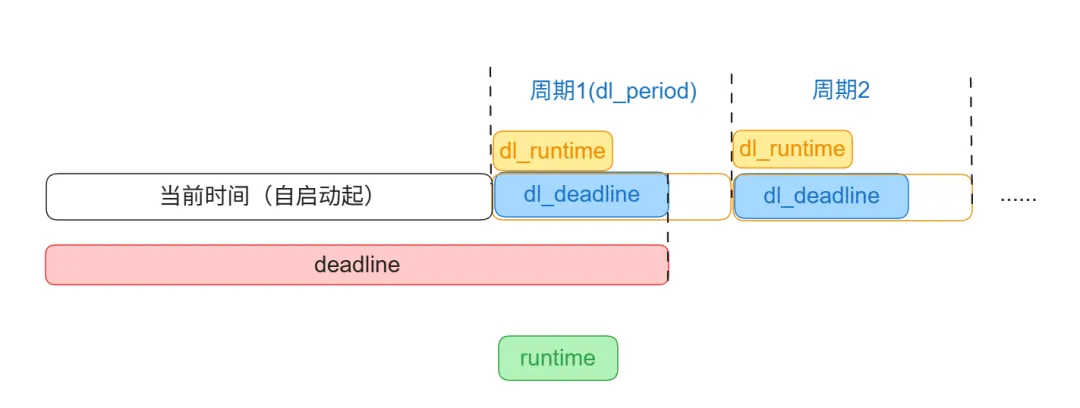
我用一张图表示它们的关系:
接下来,我们将以调度类为切入点,分析SCHED_DEADLINE调度器如何利用这些参数进行实时调度决策。
DL调度类
调度类中注册了一系列回调函数,用于在调度过程中操作调度实体,它在内核中的定义如下(简化版):
DEFINE_SCHED_CLASS(dl) = { .enqueue_task = enqueue_task_dl, // 任务入队(加入 deadline 队列) .dequeue_task = dequeue_task_dl, // 任务出队 .pick_next_task = pick_next_task_dl, // 选择 deadline 最早的任务运行(EDF 核心) .put_prev_task = put_prev_task_dl, // 切出当前任务 .task_tick = task_tick_dl, // 时钟滴答:更新执行时间、检查 runtime 是否耗尽 .update_curr = update_curr_dl, // 累加当前任务已用 CPU 时间(用于限流) .task_fork = task_fork_dl, // 子任务初始化 deadline 和预算#ifdef CONFIG_SMP .select_task_rq = select_task_rq_dl, // 为任务选择目标 CPU(通常绑定)#endif};
我们追踪调度类中函数,分析DL调度器如何利用这些参数进行实时调度决策:
- • 通过 入队函数(enqueue_task_dl),队列中如何组织调度实体。
- • 通过 选择下一任务函数(pick_next_task_dl),揭示调度器如何基于EDF策略选取下一个运行的任务。
- • 通过更新当前任务函数(update_curr_dl)与时钟滴答函数(task_tick_dl),剖析运行时间(runtime)的计费机制、周期重置逻辑以及限流的实现原理。
调度实体的组织方式
通过入队函数(enqueue_task_dl),我们可以了解调度实体在运行队列中的组织方式。为探究其调用过程,我们在 NanCode 上设置断点:
bp lk!enqueue_task_dl
断点命中后,查看调用栈如下:
kkFrame Base Return Address Call Siteffff8000`0aceba28 ffff8000`080b6620 lk!enqueue_task_dl [kernel/sched/deadline.c @ 1673]ffff8000`0aceba60 ffff8000`080b7d38 lk!enqueue_task+0x11c [kernel/sched/core.c @ 2066]ffff8000`0aceba80 ffff8000`080b8220 lk!activate_task+0x34 [kernel/sched/core.c @ 2094]ffff8000`0acebab0 ffff8000`080b9aa4 lk!ttwu_do_activate+0xb8 [kernel/sched/core.c @ 3705]ffff8000`0acebb30 ffff8000`080b9be8 lk!try_to_wake_up+0x2ac [kernel/sched/core.c @ 3910]ffff8000`0acebb40 ffff8000`080a685c lk!wake_up_process+0x20 [kernel/sched/core.c @ 4367]
从调用栈可见:当通过 wake_up_process() 唤醒一个DL任务时,内核最终会调用入队函数将其调度实体加入对应的运行队列。
接下来,我们进入该入队函数,进一步分析 DL 调度实体的具体组织结构。
入队函数相关调用:
enqueue_task_dl └─ enqueue_dl_entity ├─ update_dl_entity │ └─ replenish_dl_new_period // 重置 runtime 和 deadline(基于当前时间初始化新周期) └─ __enqueue_dl_entity └─ rb_add_cached // 按 deadline 顺序插入,用于 EDF 调度
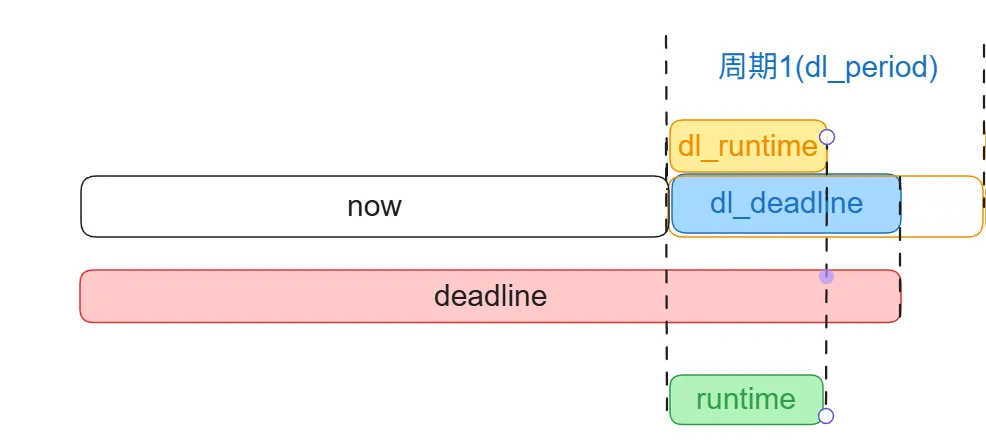
刚创建的任务在首次入队时,会调用 replenish_dl_new_period() 初始化其调度参数:
staticinlinevoidreplenish_dl_new_period(struct sched_dl_entity *dl_se,struct rq *rq){/* deadline = 当前系统时间 + 用户指定的相对截止期(dl_deadline) */ dl_se->deadline = rq_clock(rq) + pi_of(dl_se)->dl_deadline;/* runtime = 用户配置的运行预算(dl_runtime) */ dl_se->runtime = pi_of(dl_se)->dl_runtime;}
- • 绝对截止时间:
deadline = now + dl_deadline - • CPU 预算:
runtime = dl_runtime
然后调用rb_add_cached,将调度实体加入红黑树,它的具体实现如下:
static __always_inline struct rb_node *rb_add_cached(struct rb_node *node, struct rb_root_cached *tree,bool (*less)(struct rb_node *, conststruct rb_node *)){structrb_node **link = &tree->rb_root.rb_node;structrb_node *parent =NULL;bool leftmost = true; // 标记新节点是否将成为最左(最小)节点while (*link) { parent = *link;if (less(node, parent)) { link = &parent->rb_left; // 插入左子树 } else { link = &parent->rb_right; // 插入右子树 leftmost = false; // 不是最左节点 } } rb_link_node(node, parent, link); // 将节点链接到树中 rb_insert_color_cached(node, tree, leftmost); // 重新着色并更新缓存(如最左节点)return leftmost ? node : NULL; // 若为最左节点,返回 node;否则返回 NULL}
简单来说,该函数根据 less 比较函数将调度实体插入到带缓存的红黑树中,并维护rb_leftmost 缓存:若新插入的节点成为整棵树的最小(最左)节点,则返回该节点;否则返回 NULL。
而 less 比较函数正是基于 deadline 字段进行比较的:

现在我们清楚了:DL调度器将任务按照deadline作为排序依据,组织在带缓存的红黑树中。
趁热打铁,知道怎么存后,我们再看怎么取,聚焦pick_next_task_dl(选择下一个任务的函数)。
pick_next_task_dl └─ pick_task_dl └─ pick_next_dl_entity
最终调用pick_next_dl_entity()选择实体,具体实现十分简洁:
#define rb_first_cached(root) (root)->rb_leftmoststaticstruct sched_dl_entity *pick_next_dl_entity(struct dl_rq *dl_rq){structrb_node *left = rb_first_cached(&dl_rq->root);if (!left)returnNULL;return __node_2_dle(left);}
通过直接获取该最左节点,高效选出下一个应运行的任务,正体现了最早截止时间优先(EDF) 调度策略的核心思想。
值得注意的是,在获取调度实体后,内核直接使用container_of进行反推得到task_struct:
staticinlinestruct task_struct *dl_task_of(struct sched_dl_entity *dl_se){return container_of(dl_se, struct task_struct, dl);}
这也意味着DL不支持组调度,否则此处需额外判断实体归属(例如是否属于任务组)。
现在我们已知调度实体按deadline组织在红黑树中,任务选择时总是取出deadline最早的实体;那么选中的任务在执行过程中,其runtime是如何更新的?限流机制(如每 10ms 重置预算)又是如何实现的?带着这些问题,我们再进入调度类中的相关更新函数一探究竟。
runtime更新和限流机制
调度类中的 update_curr_dl 函数负责更新当前任务的运行时统计信息,并在runtime预算耗尽时触发限流(throttling)。该函数主要在两个路径中被调用:
- • 在 task_tick_dl 中调用:task_tick_dl 是调度器的周期性回调,由内核时钟中断定期触发,因此 update_curr_dl 会按固定时间粒度(通常为 tick 或高精度定时器)更新 runtime 消耗,实现基于时钟周期的精确计费。
- • 在出队操作中调用:当任务被切换或主动让出 CPU 时(如在 dequeue_task_dl 路径中),也会调用 update_curr_dl,以确保最后一次执行片段的时间被准确计入预算。
接下来,我们聚焦于runtime更新的核心逻辑,其实现如下:
staticvoidupdate_curr_dl(struct rq *rq){structtask_struct *curr = rq->curr;structsched_dl_entity *dl_se = &curr->dl; u64 delta_exec, scaled_delta_exec; u64 now;if (!dl_task(curr) || !on_dl_rq(dl_se))return; now = rq_clock_task(rq); delta_exec = now - curr->se.exec_start;if (unlikely((s64)delta_exec <= 0)) {if (unlikely(dl_se->dl_yielded))goto throttle;return; } update_current_exec_runtime(curr, now, delta_exec); // 更新 se.sum_exec_runtime/* 计算考虑 CPU 频率和算力缩放后的执行时间 */unsignedlong scale_freq = arch_scale_freq_capacity(cpu_of(rq));unsignedlong scale_cpu = arch_scale_cpu_capacity(cpu_of(rq)); scaled_delta_exec = cap_scale(delta_exec, scale_freq); scaled_delta_exec = cap_scale(scaled_delta_exec, scale_cpu);/* 扣减 runtime 预算 */ dl_se->runtime -= scaled_delta_exec;}
关键步骤解析:
1、计算实际执行时间:
now = rq_clock_task(rq);delta_exec = now - curr->se.exec_start;
使用“任务可见时钟”(排除中断等不可调度时间)计算自上次调度以来的执行时长 delta_exec。
但还需考虑 CPU 频率与算力的差异。例如,在大小核架构中,大核和小核即使执行相同的时间,实际完成的工作量也不同。为此,内核会根据当前 CPU 的频率和算力对执行时间进行加权缩放,确保runtime消耗的计量在不同性能核心上保持公平性。
2、按CPU算力缩放执行时间
scaled_delta_exec = cap_scale(delta_exec, scale_freq);scaled_delta_exec = cap_scale(scaled_delta_exec, scale_cpu);
3、将该值从任务当前周期的剩余运行预算中扣除:
dl_se->runtime -= scaled_delta_exec;
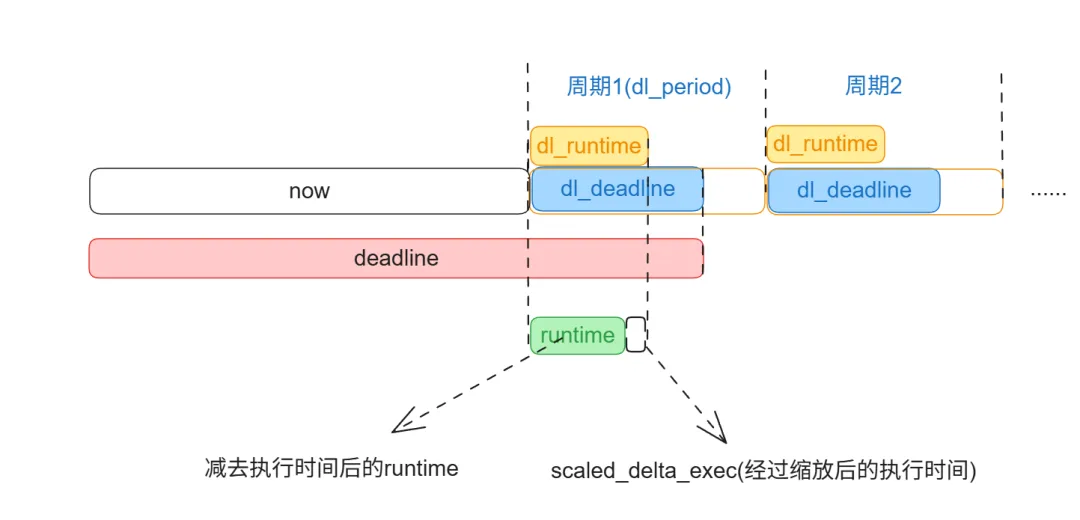
说到这里,runtime 的更新流程完成。
那么,当 runtime 耗尽时,内核如何阻止任务继续执行?又如何确保其在下一个周期开始时重新获得运行机会?那么,当 runtime 耗尽时,内核如何阻止任务继续执行?又如何确保其在下一个周期开始时重新获得运行机会?我们接着看 update_curr_dl中限流的部分,具体实现如下:
throttle:/* 检查是否耗尽 runtime 或主动让出 */if (dl_runtime_exceeded(dl_se) || dl_se->dl_yielded) { dl_se->dl_throttled = 1; // 标记为被限流if (dl_runtime_exceeded(dl_se) && (dl_se->flags & SCHED_FLAG_DL_OVERRUN)) dl_se->dl_overrun = 1; // 记录 overrun __dequeue_task_dl(rq, curr, 0); // 从运行队列移除/* 尝试启动 replenishment 定时器(周期重置) */if (unlikely(is_dl_boosted(dl_se) || !start_dl_timer(curr))) enqueue_task_dl(rq, curr, ENQUEUE_REPLENISH);if (!is_leftmost(curr, &rq->dl)) resched_curr(rq); // 触发重新调度 }
步骤解析:
当任务的 runtime 耗尽时,内核会将其标记为限流状态(dl_se->dl_throttled = 1),并从运行队列中移除,使其暂时不再参与调度。
为了确保任务在下一个调度周期开始时能重新获得CPU预算并恢复执行,内核需要设置一个“闹钟”来准时唤醒它。这个“闹钟”正是通过启动一个高精度定时器(hrtimer)来实现的。
关键代码行:
if (unlikely(is_dl_boosted(dl_se) || !start_dl_timer(curr)))
start_dl_timer()启动了这个定时器,这个定时器就会在下个周期开始时,触发回调函数dl_task_timer()用于恢复 runtime 并推进deadline。
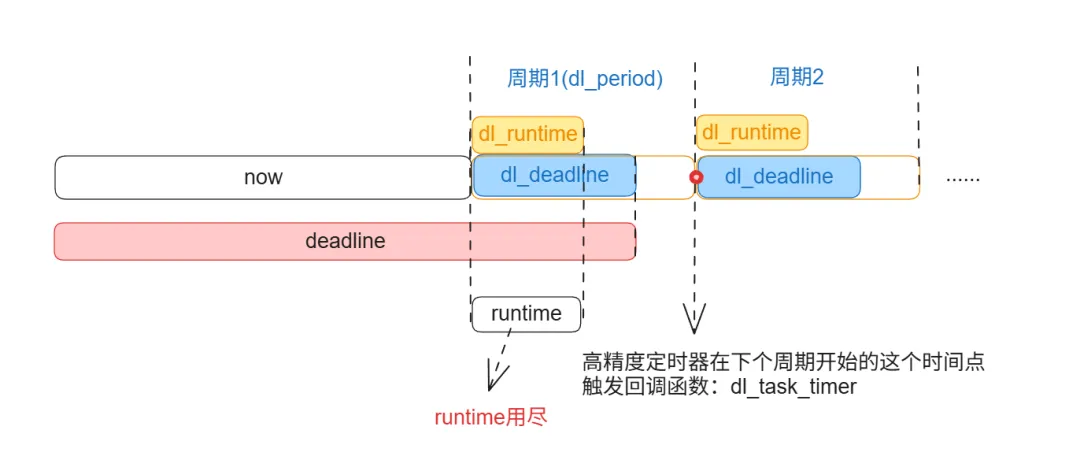
dl_task_timer() 中恢复 runtime 和推进 deadline 的操作由 replenish_dl_entity()实现。
具体代码如下(简化版):
staticvoidreplenish_dl_entity(struct sched_dl_entity *dl_se){structrq *rq = rq_of_dl_rq(dl_rq_of_se(dl_se));/* 若 dl_deadline 未初始化(如 PI-boosted 非 DL 任务),按新周期初始化 */if (dl_se->dl_deadline == 0) { replenish_dl_new_period(dl_se, rq);return; }/* 主动让出 CPU 时清空剩余预算,确保节流生效 */if (dl_se->dl_yielded && dl_se->runtime > 0) dl_se->runtime = 0;/* 循环推进周期,直到获得正的 runtime(可处理跨多个周期的 throttling) */while (dl_se->runtime <= 0) { dl_se->deadline += pi_of(dl_se)->dl_period; dl_se->runtime += pi_of(dl_se)->dl_runtime; }/* 若计算出的 deadline 仍早于当前时间(严重滞后),则以当前时间为起点重置 */if (dl_time_before(dl_se->deadline, rq_clock(rq))) replenish_dl_new_period(dl_se, rq);/* 清除节流与让出标志,允许任务重新入队 */ dl_se->dl_yielded = 0; dl_se->dl_throttled = 0;}
关键行:
/* 循环推进周期,直到获得正的 runtime(可处理跨多个周期的 throttling) */while (dl_se->runtime <= 0) { dl_se->deadline += pi_of(dl_se)->dl_period; dl_se->runtime += pi_of(dl_se)->dl_runtime; }
这是恢复runtime和推进deadline的关键逻辑:在一般情况下(runtime 为 0),循环执行一次即可完成 replenish。使用循环而非 if,是为了正确处理因调度延迟等导致的 runtime 超支(包括负值或跨多个周期的严重超支)。
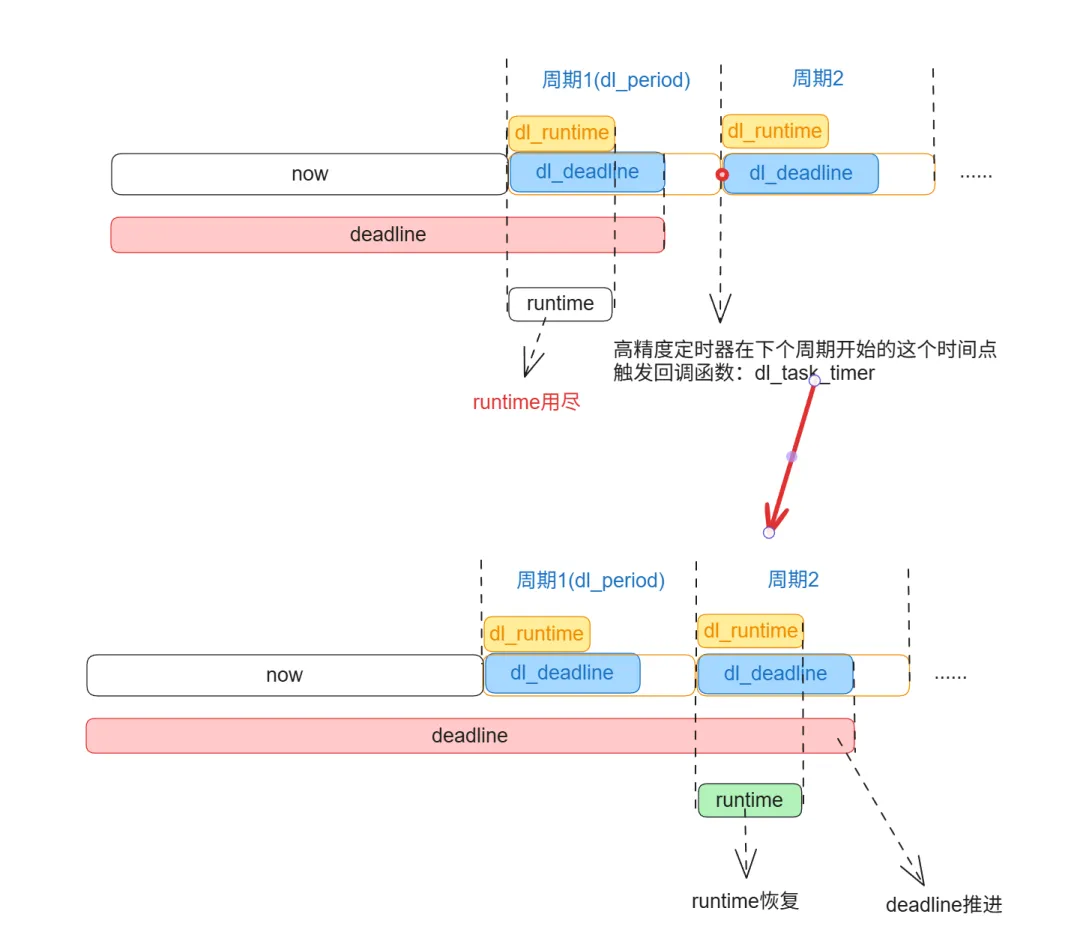
现在我们清楚了,在DL调度中,runtime 的扣减由调度时钟触发,并考虑CPU算力的影响;而周期性的replenish机制则由高精度定时器驱动,用于按时更新deadline和恢复runtime。
小结
行文至此,《Linux 任务调度探秘》系列完结。从整体框架到各类调度策略,从单任务到组调度,从完全公平到实时调度,从2025到2026……我们一路深入 Linux 内核调度这个神秘堡垒。初读调度代码时以为只是“选个任务跑”,细探后才发现:公平性、实时性、负载均衡、能效调度……处处是权衡。愈是深入,愈感敬畏——学然后知不足,知不足而后进。请关注我们,新一年里,我们将开启更多的探秘之旅!
(写文章很辛苦,恳请各位读者点击“在看”,也欢迎转发)*************************************************正心诚意,格物致知,以人文情怀审视软件,以软件技术改变人生
扫描下方二维码或者在微信中搜索“盛格塾”小程序,可以阅读更多文章和有声读物

也欢迎关注格友公众号


