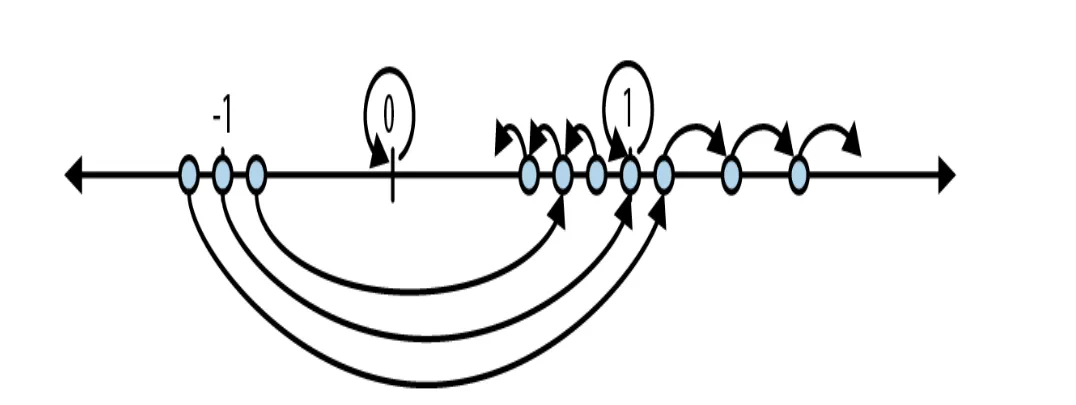
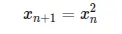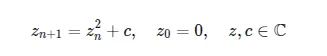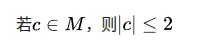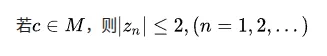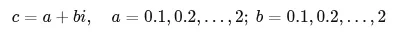起因是在写AI Agent的代码,写AI Agent时需要参考OpenAI/Codex实现, Codex又是Rust编写, 学习Rust时选择了O’REILLY的《Rust程序设计》,然后在本书第二章中用Mandelbrot集举例介绍Rust的基本使用。在书中介绍Mandelbrot集时其实已经把背景从实数逐步扩展到复数,也很好理解,我们按照书中的引导重新介绍下Mandelbrot集。这个迭代异常简单,随着n增长,x按照上述不断进行迭代,如果初始值x0 < 1, 平方会越来越小,最终趋于0,如果x0 = 1, 则以后所有结果一直是1,如果x0 > 1, 平方会越来越大,最终趋于无穷。所以这里的初始值1就是临界半径,或叫作逃逸半径。对于下面的情况,情况就稍有些复杂,每次迭代后会在平方后加上一个常数c,可以把它理解成系统里持续存在的“偏置”或“外力”。fn square_add_loop(c: f64) { let mut x = 0.; loop { x = x * x + c; }}
这种情况下反复迭代后,行为会变得非常丰富,注意x0 的值为0。几个典型例子如下:- 取c=−1:出现周期。x0=0,x1 = -1, x2 = 0, x3 = -1, ... 不发散也不收敛,呈现周期性变化,且数值有界(范围在-1,0之间)
- 取c=1, x0 = 0, x1 =1, x2 = 2, x3 = 5, x4 = 26 很快发散
数据学上可以证明,只要c大于0.25或者小于-2, 则x最终会发散。如果再增加一些复杂度,在迭代过程中,从实数领域扩展到复数,就到了Mandelbrot集出场了。对于上面的这个迭代过程,Zn以及c都是复数。它的正式定义如下:通俗易懂一点就是,在复平面上随便选一个 c,以z0 = 0开始不断做z = z*z +c的迭代,如果这个过程永远不会变到无穷大,那么这个数值c就属于Mandelbrot集合,Mandelbrot集就是所有满足这个条件的c的集合。理解了Mandelbrot集的定义之后,我们再来介绍其中常用两个定理。其中M表示Mandelbrot集,这个定理是说,如果c属于Mandelbrot集,则所有c的模都小于等于2。另一个定理是:即,如果c属于Mandelbrot集,那所有Z的模也小于等于2,反过来就是说,如果我们迭代过程中发现Z大于2,则可以断定此时的c一定不属于Mandelbrot集。这个推论也是计算程序用于判定c是否属于Mandelbrot集最常用的一个判定条件。如以下代码,一旦模的平方大于4,则认为逃逸。fn escape_time(c: Complex<f64>, limit: u32) -> Option<u32> { let mut z = Complex {re:0.0, im:0.0};for i in 0..limit { z = z*z + c;if z.norm_sqr() > 4.0 {return Some(i); } } None}
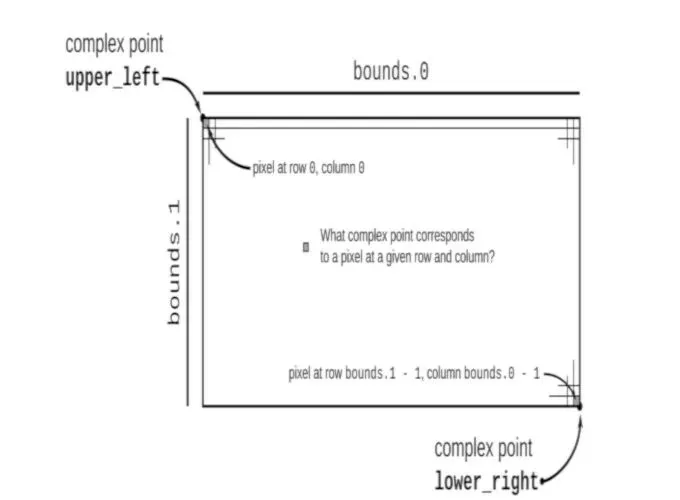
但是实际情况中,我们并不知道具体需要多少次迭代才能真正逃逸,有可能是10次,有可能100次,有可能是1000次,也有可能是一百万,一千万次,书中介绍的方法很简单,就是只需要计算255次即可。为什么使用255这个数字呢,为了方便着色。同样都是逃逸,迭代255次逃逸跟迭代10次逃逸也有区别,用255减去逃逸次数作为这个像素的颜色灰度,即迭代次数越少逃逸,颜色越浅,迭代次数越多才逃逸,颜色越深,越接近Mandelbrot集内数据的颜色。那我们如何绘制出Mandelbrot集呢?一个最直观的方法就是我们取一个步长,比如0.01,这样对于复数c,我们在复平面上均匀取样:对每个c, 从z0 = 0开始迭代,看是否发散,没发散就算在Mandelbrot集里。这样是否可以呢?不可以!这是因为Mandelbrot集的难点就在边界上,内部的轨道稳定,很快就知道是不发散,外部一旦超过半径2,就立即逃逸,但是在边界上拥有无限层级,无限细节,无限延迟逃逸。我们直觉上采用0.01的步长,哪怕是0.001的步长,前提条件是认为边界在这个尺度下是“均匀的”,“平滑的”,但是这个条件恰恰不满足。Mandelbrot在边界上拥有无限丰富的细节,这也导致我们采用这种方法的话,大部分采样都很无聊,两三步就逃逸了,而最有价值的边界点反而很少采样甚至直接越过了。这就是为什么不采用这种直观的方式的原因,也是书上省略掉,阅读时最为疑惑的点。书上采用的是一种“反向”的逻辑,即先给图像分辨率,比如4000x3000,然后扫描这张图的所有像素点,然后计算这个像素点映射到复平面区域的哪个点,判断这个点是否在Mandelbrot集合内。//像素点到复平面点的映射fn pixel_to_point(bounds: (usize, usize), pixel: (usize, usize), upper_left: Complex<f64>, lower_right: Complex<f64>) -> Complex<f64> { let (width, height) = (lower_right.re - upper_left.re, upper_left.im - lower_right.im); Complex { re: upper_left.re + pixel.0 as f64 * width / bounds.0 as f64, im: upper_left.im - pixel.1 as f64 * height / bounds.1 as f64 }}// 绘制像素点,逃逸时迭代次数越多,颜色越深fn render(pixels: &mut [u8], bounds: (usize, usize), upper_left: Complex<f64>, lower_right: Complex<f64>) { assert!(pixels.len() == bounds.0 * bounds.1); for y in 0..bounds.1 { for x in 0..bounds.0 { let point = pixel_to_point(bounds, (x, y), upper_left, lower_right); let escape = escape_time(point, 255); pixels[y * bounds.0 + x] = match escape { None => 0, Some(count) => 255 - count as u8 }; } }}
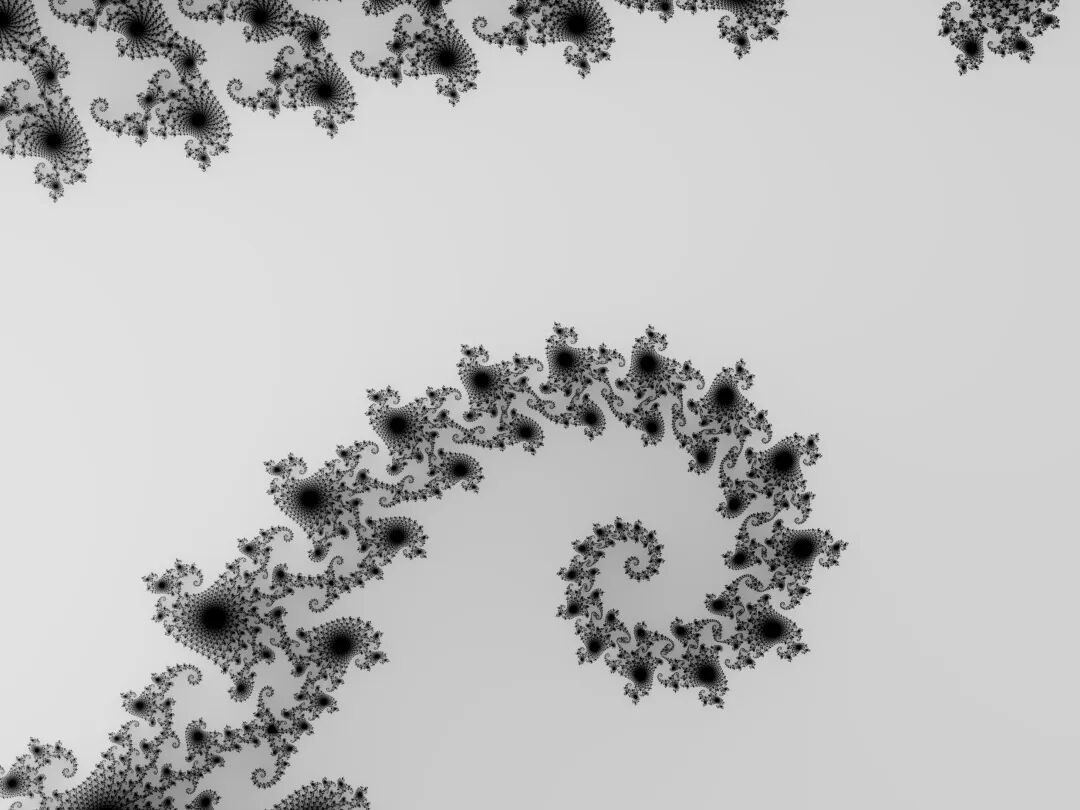
基于以上方式,对于固定的图像分辨率,需要先找一个复平面区域,然后再绘制。所以另一个关键问题便是,到底找哪一个区域呢?也就是说,如果我们选择一个区域不断放大查看它的细节的话,选哪个区域更好看呢?虽然没有明确的区域到底应该找哪里,但是有一些经典的路线,可以帮助我们快速找到那些丰富多彩的图形区域。以下是其中一个经典路线,以及按照这个经典路线绘制出来的图像。每行两个坐标,用空格分开。第一个为左上角复数坐标,第二个为右下角复数坐标,这两个点构成一个复平面区域。-2.5,1.5 1.5,-1.5
-0.95,0.25 -0.55,-0.05
-0.7635,0.1464 -0.7235,0.1164
-0.7456439,0.1333259 -0.7416439,0.1303259
-0.7438408,0.1319773 -0.7434408,0.1316773