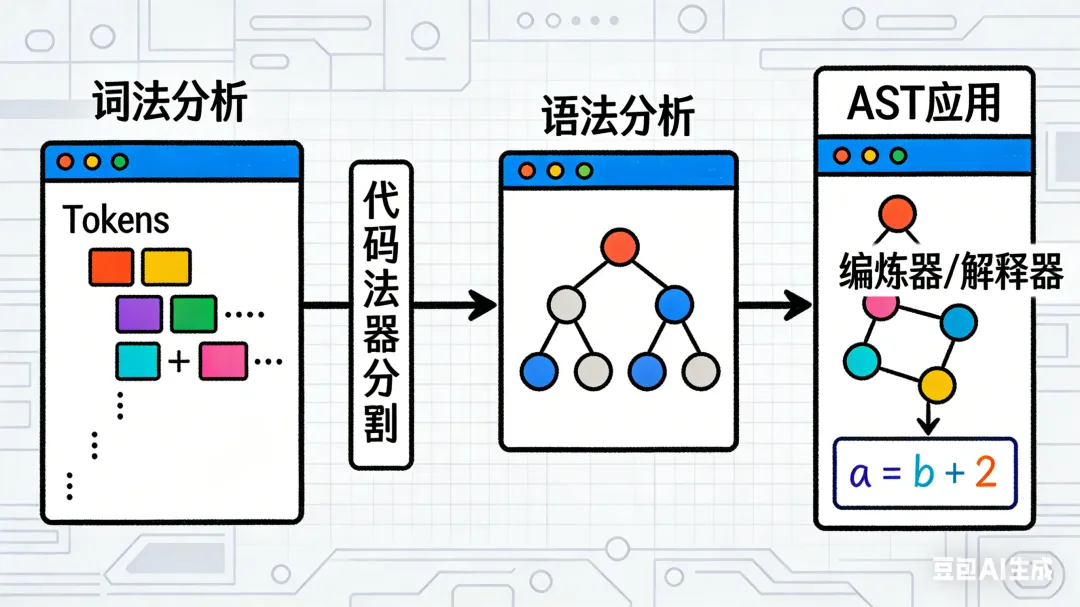
当我们写下 a = 1 + 2 * 3 这样一行简单代码时,编译器或解释器(后文统称“语言处理器”)是如何看懂它的?答案藏在三个关键步骤里:词法分析、语法分析、AST(抽象语法树)构建。
这三步就像我们理解一句话的过程:先认清每个字/词,再判断句子结构是否通顺,最后梳理出句子的语义逻辑。今天用大白话拆解这三个核心概念,搞懂语言处理器的“读代码”逻辑。
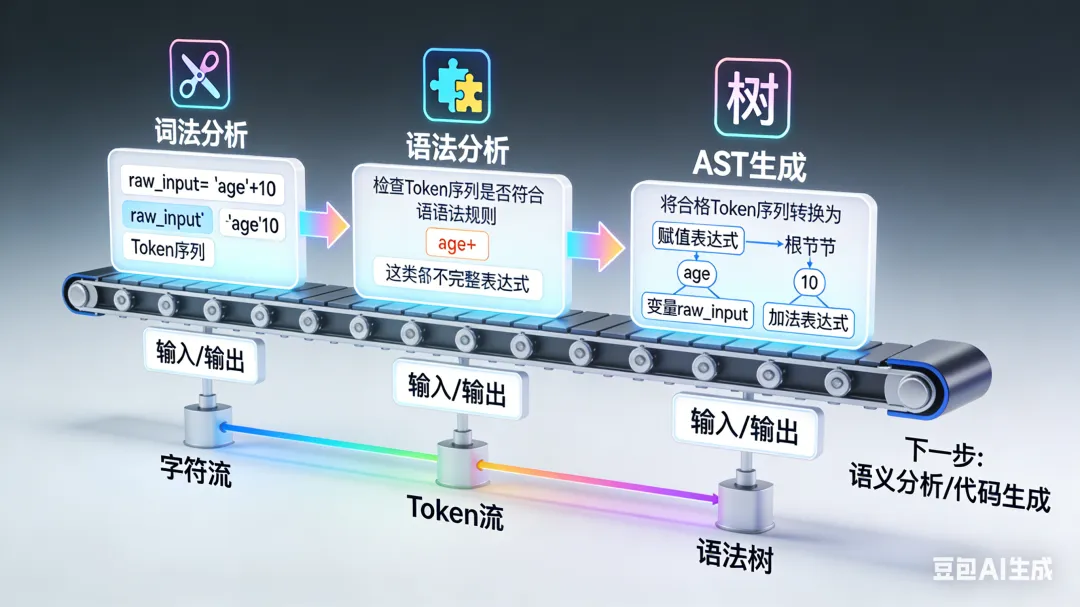
一、先认“单词”:词法分析(Lexical Analysis)
- 1. 核心目标:把“代码文本”拆成“语法单词”(Token)
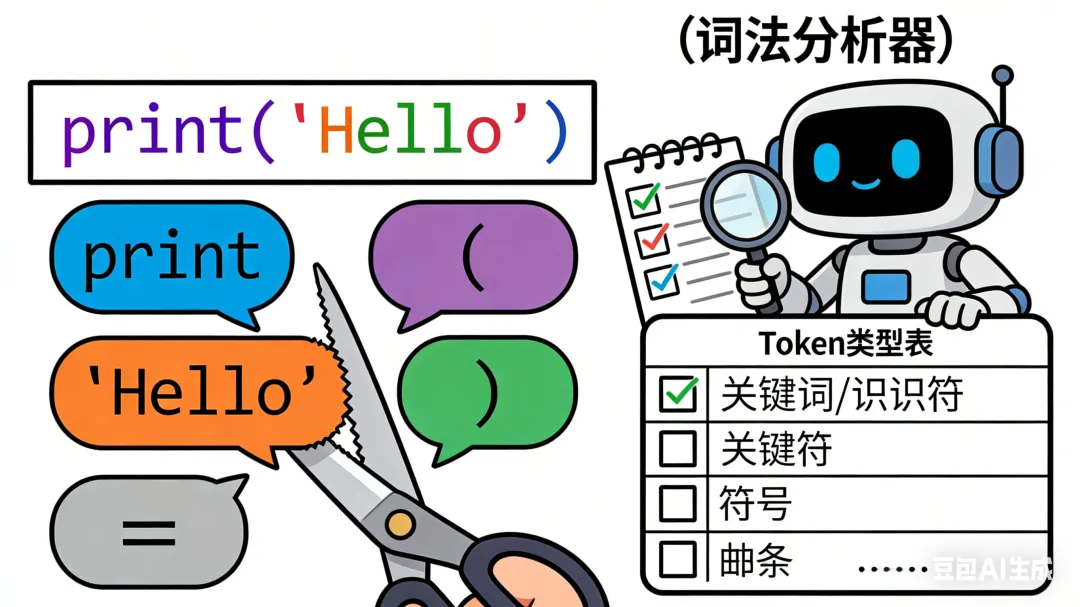
词法分析是语言处理器处理代码的第一步,核心工作是“扫描代码字符串,按规则拆分出最小的、有意义的语法单元”,这个单元就是 Token(词法单元/记号)。
类比我们读句子:“我吃了一个苹果”——词法分析就像把这句话拆成“我”“吃了”“一个”“苹果”这些独立的词,每个词都有明确含义,不能再拆(比如“苹果”不能拆成“苹”“果”,拆了就失去语法意义)。
语言处理器会用一个叫“词法分析器(Lexer)”的模块完成这项工作,流程如下:
- 1. 扫描代码文本,忽略无意义字符(空格、换行、注释,就像我们读句子忽略标点符号的排版作用);
- 2. 按预定义的“词法规则”(比如标识符由字母/下划线开头、数字不能开头,运算符是+/-/*/=等),将字符序列组合成Token;
- 3. 给每个Token打上“类型标签”,方便后续处理。
以代码 a = 1 + 2 * 3 为例,词法分析后会拆成以下Token列表:
Token内容 | Token类型 | 说明 |
|---|
a | 标识符(IDENTIFIER) | 变量名,用于指代数据 |
= | 赋值运算符(ASSIGN_OP) | 表示赋值操作 |
1 | 数字常量(NUMBER) | 整数常量 |
+ | 加法运算符(ADD_OP) | 表示加法操作 |
2 | 数字常量(NUMBER) | 整数常量 |
* | 乘法运算符(MUL_OP) | 表示乘法操作 |
3 | 数字常量(NUMBER) | 整数常量 |
词法分析只负责“拆单词”,不判断单词的排列是否符合语法。比如代码 1 = a + 2,词法分析会正常拆出Token(1、=、a、+、2),但不会发现“数字不能放在赋值符号左边”这个语法错误——这个工作留给下一步的语法分析。
二、再理“结构”:语法分析(Syntactic Analysis)
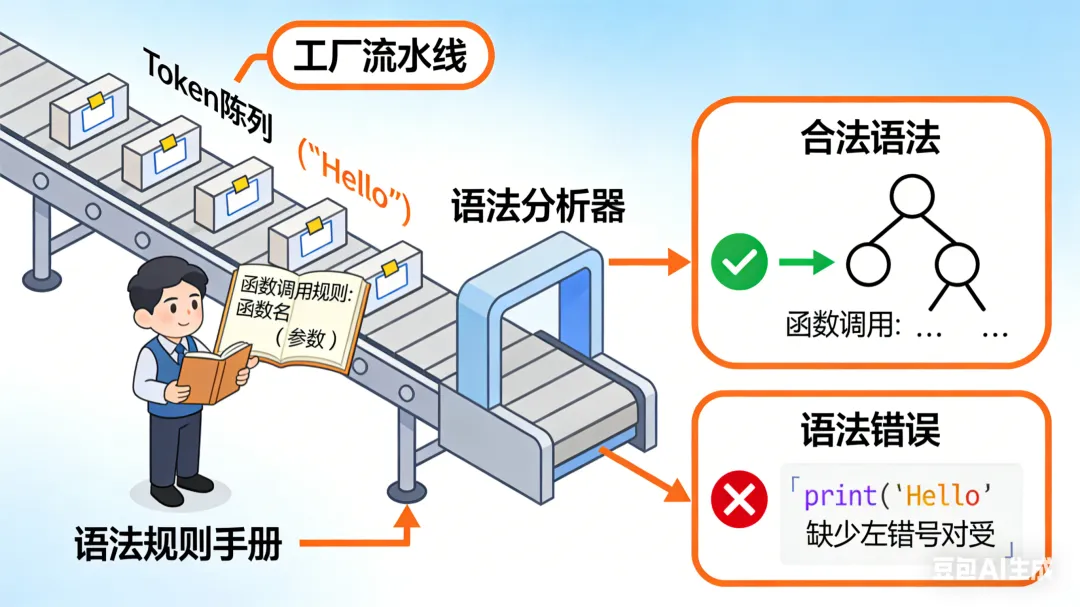
- 1. 核心目标:验证Token排列的“语法正确性”,生成结构化表示
语法分析是在词法分析的基础上,用“语法分析器(Parser)”验证Token序列是否符合编程语言的“语法规则”(比如“赋值语句必须是‘标识符+赋值符+表达式’”“表达式中运算符有优先级”),并将合法的Token序列转换成更易处理的“结构化中间表示”——最常用的就是AST。
类比我们读句子:“我吃了一个苹果”拆成单词后,语法分析会判断“我(主语)+吃了(谓语)+一个苹果(宾语)”的结构是否符合中文语法,再梳理出“谁做了什么”的逻辑结构。
- 2. 核心依据:编程语言的“语法规则”(BNF范式)
编程语言的语法规则会用“BNF范式”等形式化符号定义,比如赋值语句的规则可能是:
<赋值语句> ::= <标识符> "=" <表达式><表达式> ::= <数字> | <表达式> <运算符> <表达式><运算符> ::= "+" | "*" (注:实际会定义优先级)
语法分析器会对照这些规则,逐一校验Token序列的排列是否合法。
语法分析主要有两种实现方式,核心都是“匹配语法规则”:
- • 自上而下分析:从“最顶层语法单元”(比如赋值语句)开始,逐步拆解成子单元,直到匹配所有Token(比如先假设代码是赋值语句,再拆成标识符、赋值符、表达式,再拆表达式为“表达式+运算符+表达式”,最终匹配Token序列);
- • 自下而上分析:从“最底层Token”开始,逐步组合成更大的语法单元(比如先把“2 * 3”组合成乘法表达式,再和“1 + ”组合成加法表达式,最后和“a = ”组合成赋值语句)。
如果Token序列不符合语法规则,语法分析器会直接抛出“语法错误”,比如:
- • 代码 a = + 1 2:Token序列是[a, =, +, 1, 2],不符合“表达式”规则,会提示“运算符‘+’后缺少操作数”;
- • 代码 a 1 = + 2:Token序列混乱,会提示“语法错误,标识符后意外出现数字”。
三、最终的“结构化成果”:AST(抽象语法树,Abstract Syntax Tree)
AST是语法分析的核心输出,它用“树状结构”表示代码的语法逻辑,每个“节点”对应一个语法单元(比如赋值语句、表达式、标识符、数字),“父子关系”对应语法单元的包含关系。
关键在于“抽象”二字:AST会忽略代码中的无意义信息(空格、换行、括号的具体位置),只保留核心语法结构——比如 a = 1 + (2 * 3) 和 a = 1 + 2 * 3 的AST完全一致,因为括号只是改变运算优先级的“语法糖”,核心结构都是“a赋值为1加2乘3”。
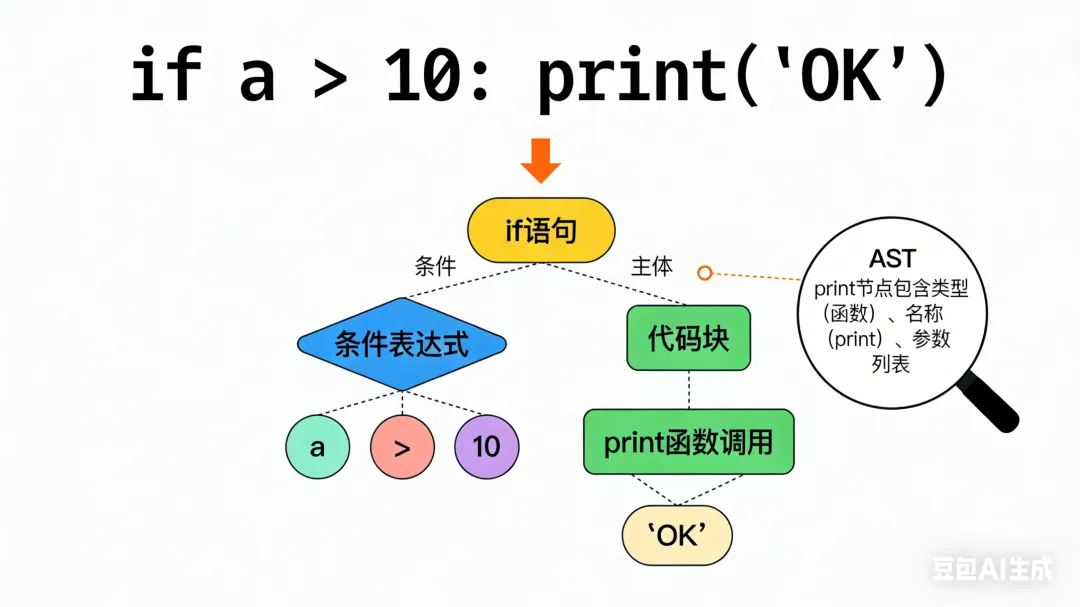
- 2. 实例:a = 1 + 2 * 3 的AST结构(文字描述)
以最顶层的“赋值语句”为根节点,树结构如下(缩进表示父子关系):
赋值语句(根节点)├─ 左子节点:标识符(a)└─ 右子节点:加法表达式 ├─ 左子节点:数字(1) └─ 右子节点:乘法表达式 ├─ 左子节点:数字(2) └─ 右子节点:数字(3)
这个结构清晰体现了:
- • 赋值的右值是“1 + (2 * 3)”(因乘法优先级高于加法,乘法表达式是加法表达式的子节点);
AST是语言处理器后续工作的“核心桥梁”,编译型语言和解释型语言都会基于AST做进一步处理:
- • 解释型语言(如Python):直接遍历AST,逐节点执行(比如先执行乘法表达式2*3,再执行加法表达式1+6,最后执行赋值a=7);
- • 编译型语言(如C++):基于AST进行优化(比如常量折叠,直接计算出1+2*3=7,减少运行时计算),再生成机器码;
- • 其他场景:代码混淆、格式化、静态分析(比如检测未定义变量)、框架编译(如Vue的模板编译成渲染函数),都以AST为核心。
四、词法分析→语法分析→AST的完整流程
语言处理器“读懂”代码的过程,本质是“从文本到结构”的转化,三步递进、环环相扣:
- 1. 词法分析:输入“代码文本”,输出“Token列表”(拆单词,不关心结构);
- 2. 语法分析:输入“Token列表”,输出“AST”(验结构,生成结构化表示);
- 3. AST应用:输入“AST”,输出“执行结果/机器码”(基于结构做执行或编译)。
简单记:词法认“字”,语法认“句”,AST定“逻辑结构”——这三步是所有编程语言实现的基础,理解它们,就相当于搞懂了编译器/解释器的“底层逻辑骨架”。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
