Python:快速掌文件层级关系目录
- 2026-07-10 01:52:08
Python:快速掌文件层级关系目录
工具核心价值
规避误删风险:删除文件前快速识别其中结构,避免误删关键逻辑
节省时间成本:无需打开文件,直接查看内部代码结构,减少重复操作
提升整理效率:整理文件夹时,快速判断每个文件的功能定位
快速熟悉项目:接手他人项目时,高效掌握整体代码组织架构
备份决策依据:备份前快速确认哪些文件包含核心程序逻辑
工具完整代码
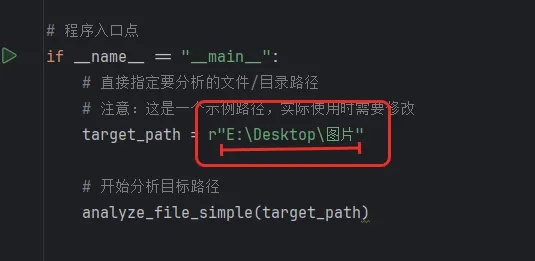
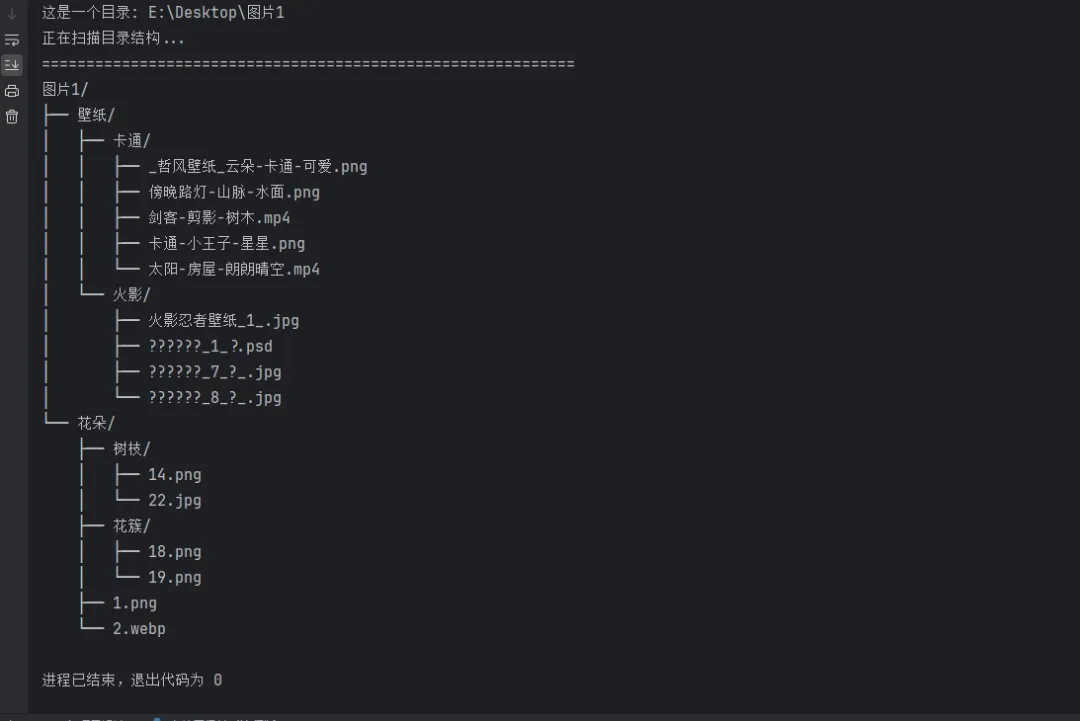
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""简单文件结构分析工具 - 已嵌入文件地址功能:分析文件/目录结构,支持检测多种编程语言的代码结构"""import osimport refrom pathlib import Pathimport sysdefsafe_print_filename(name):""" 安全打印文件名,处理编码问题 参数: name: 要打印的文件名 返回:处理后的安全字符串 """ifnot isinstance(name, str): name = str(name)# Windows控制台直接打印UTF-8字符串(让IDE/终端自己处理编码)return namedefanalyze_file_simple(filepath):""" 简单分析文件结构 参数: filepath: 文件路径字符串 功能:如果路径是文件,分析文件内容;如果是目录,扫描目录结构 """# 将路径字符串转换为Path对象,便于操作 path = Path(filepath)# 检查路径是否存在ifnot path.exists(): print(f"错误: 路径不存在: {filepath}")return# 判断路径是文件还是目录if path.is_file():# 处理文件:分析文件内容中的代码结构 print(f"分析文件: {path.absolute()}") print("=" * 60)# 尝试读取文件内容try:# 使用utf-8编码读取,忽略无法解码的字符with open(path, 'r', encoding='utf-8', errors='ignore') as f: lines = f.readlines() # 读取所有行到列表中except Exception as e: print(f"无法读取文件: {e}")return# 存储检测到的代码结构信息# 每个元素格式:(行号, 缩进空格数, 结构描述) structures = []# 遍历文件的每一行(从第1行开始计数)for i, line in enumerate(lines, 1): stripped = line.strip() # 去除首尾空白字符# ----------------------------# 检测Python类定义# 示例:class MyClass:# ----------------------------if stripped.startswith('class '):# 提取类名:从第6个字符开始(跳过"class "),# 分割掉括号和冒号部分 class_name = stripped[6:].split('(')[0].split(':')[0].strip()# 计算该行的缩进量(用于显示层级关系) indent = len(line) - len(line.lstrip())# 添加到结构列表 structures.append((i, indent, f"类: {class_name}"))# ----------------------------# 检测Python函数定义# 示例:def my_function():# ----------------------------elif stripped.startswith('def '):# 提取函数名:从第4个字符开始(跳过"def "),# 分割掉括号部分 func_name = stripped[4:].split('(')[0].strip() indent = len(line) - len(line.lstrip()) structures.append((i, indent, f"函数: {func_name}"))# ----------------------------# 检测Java类定义# 示例:public class MyClass# private class InnerClass# ----------------------------elif re.match(r'^\s*(public|private|protected)?\s*class\s+\w+', stripped):# 使用正则表达式查找类名 match = re.search(r'class\s+(\w+)', stripped)if match: indent = len(line) - len(line.lstrip()) structures.append((i, indent, f"类: {match.group(1)}"))# ----------------------------# 检测C++/C#类和结构体定义# 示例:class MyClass# struct MyStruct# ----------------------------elif re.match(r'^\s*(class|struct)\s+\w+', stripped):# 查找类或结构体名称 match = re.search(r'(class|struct)\s+(\w+)', stripped)if match: indent = len(line) - len(line.lstrip())# 区分class和struct structures.append((i, indent, f"{match.group(1)}: {match.group(2)}"))# ----------------------------# 打印检测结果# ----------------------------if structures: print("检测到的结构:")# 遍历所有检测到的结构for line_num, indent, desc in structures:# 将缩进空格数转换为层级(假设每级4个空格) level = indent // 4# 根据层级生成前缀(用于树状显示) prefix = " " * level + "├── "# 打印结构信息:前缀 + 描述 + 行号 print(f"{prefix}{desc} (第 {line_num} 行)")else: print("未检测到明显的代码结构")# 如果路径是目录,调用目录扫描函数elif path.is_dir(): print(f"这是一个目录: {path.absolute()}") print("正在扫描目录结构...") print("=" * 60) scan_directory_simple(filepath)defscan_directory_simple(dirpath):""" 简单扫描目录结构 参数: dirpath: 目录路径字符串 功能:递归扫描目录,以树状结构打印所有文件和子目录 """ path = Path(dirpath)# 内部递归函数,用于遍历目录deflist_contents(current_path, level=0, prefix=""):""" 递归列出目录内容 参数: current_path: 当前遍历的路径 level: 当前层级深度(根目录为0) prefix: 当前行的前缀字符串(用于树状结构显示) """try:# 获取当前目录下的所有条目 items = list(os.scandir(current_path))# 排序:目录在前,文件在后,按名称小写排序 items.sort(key=lambda x: (not x.is_dir(), x.name.lower()))# 遍历当前目录的所有条目for i, item in enumerate(items):# 判断是否是最后一个条目(用于显示不同的连接符) is_last = (i == len(items) - 1)# 当前条目的前缀:最后一个用"└── ",其他用"├── " current_prefix = "└── "if is_last else"├── "# 下一层级的前缀:需要继承当前前缀并添加空格或竖线 next_prefix = prefix + (" "if is_last else"│ ")if item.is_dir():# 尝试直接打印,如果出错则使用替代方案try: print(f"{prefix}{current_prefix}{item.name}/")except:# 如果打印失败,使用ASCII安全字符 safe_name = item.name.encode('ascii', errors='replace').decode('ascii') print(f"{prefix}{current_prefix}{safe_name}/")# 递归遍历子目录 list_contents(item.path, level + 1, next_prefix)else:try: print(f"{prefix}{current_prefix}{item.name}")except: safe_name = item.name.encode('ascii', errors='replace').decode('ascii') print(f"{prefix}{current_prefix}{safe_name}")except PermissionError:# 处理权限不足的情况 print(f"{prefix}[权限不足,无法访问]")except Exception as e:# 处理其他异常 print(f"{prefix}[错误: {str(e)[:50]}]")# 开始扫描:先打印根目录名try: print(f"{path.name}/")except: safe_name = path.name.encode('ascii', errors='replace').decode('ascii') print(f"{safe_name}/")# 调用递归函数开始遍历 list_contents(path)# 程序入口点if __name__ == "__main__":# 直接指定要分析的文件/目录路径# 注意:这是一个示例路径,实际使用时需要修改 target_path = r"E:\Desktop\图片1"# 开始分析目标路径 analyze_file_simple(target_path)快速使用方法
代码最后一段中
target_path = r"E:\Desktop\图片"这一行将双引号内的路径替换为你要分析的文件 / 目录路径(如
r"D:\Project\"或r"D:\Project\test")
注意事项
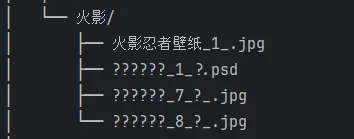
路径中的特殊符号(如表情符号、特殊字符)可能导致文件名显示乱码,建议分析前确保文件 / 目录名称为常规字符
 |  |
请在微信客户端打开
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

