数据分享|Python用偏最小二乘回归Partial Least Squares,PLS分析桃子近红外光谱数据可视化
- 2026-06-25 13:39:34
全文链接:https://tecdat.cn/?p=34376
PLS,即偏最小二乘(Partial Least Squares),是一种广泛使用的回归技术,用于帮助客户分析近红外光谱数据(点击文末“阅读原文”获取完整代码数据)。
相关视频
如果您对近红外光谱学有所了解,您肯定知道近红外光谱是一种次级方法,需要将近红外数据校准到所要测量的参数的主要参考数据上。这个校准只需在第一次进行。一旦校准完成且稳健,就可以继续使用近红外数据预测感兴趣参数的值。
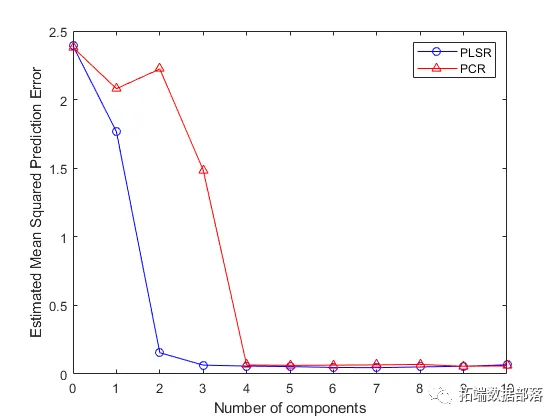
PCR只是使用通过PCA得到的若干主成分构建的回归模型。显然,这并不是最佳选择,而PLS就是解决这个问题的方法。
在本文中,我将向您展示如何使用Python构建一个简单的PLS回归模型。以下是我们将要做的概述。
展示PLS的基本代码
讨论我们要分析的数据及所需的预处理。我们将使用新鲜桃子水果的近红外光谱(查看文末了解数据免费获取方式),其关联的Brix值与PCR相同。这是我们要校准的量。
我们将使用交叉验证方法构建我们的模型
PLS Python代码
好的,以下是基于Python 3.5.2的运行PLS交叉验证的基本代码。
# 导入需要的库from sklearn.metrics import mean_squared_error, r2_score # 导入均方误差和R2得分指标from sklearn.model_selection import cross_val_predict # 导入交叉验证函数# 定义PLS对象pls = PLSReg......nts=5) # 定义保留5个成分的PLS回归模型# 拟合数据pls.f...... Y) # 将数据拟合到PLS模型中# 交叉验证y_cv = cros......y, cv=10) # 用10折交叉验证计算模型性能# 计算得分score = r2_score(y,v) # 计算R2得分mse = mean_squa......_cv) # 计算均方误差为了检查我们的校准效果如何,我们使用通常的指标来衡量。我们通过将交叉验证结果y_cv与已知响应进行比较来评估这些指标。为了优化我们的PLS回归参数(例如预处理步骤和成分数量),我们将跟踪这些指标,最常见的是均方差(MSE)。
还有一件事。在实际代码中,各种数组X, y等通常是从电子表格中读取的numpy数组。因此,您可能需要导入numpy(当然),pandas和其他一些库,我们将在下面看到。
这是Python中PLS回归的基本代码块。看一下数据导入和预处理了。
近红外数据导入和预处理
from sys import stdout ......from sklearn.metrics import mean_squared_error, r2_score接下来,让我们导入数据,这些数据保存在一个csv文件中。该数据由50个新鲜桃子的近红外光谱组成。每个光谱都有对应的Brix值(响应变量)。最后,每个光谱在1100 nm到2300 nm之间取600个波长点,步长为2 nm。
data = pd.read_csv('./datavalues.csv')# 获取参考值y = data[......lues# 获取光谱X = data......axis=1).values# 获取波长wl = np.a......0,2300,2)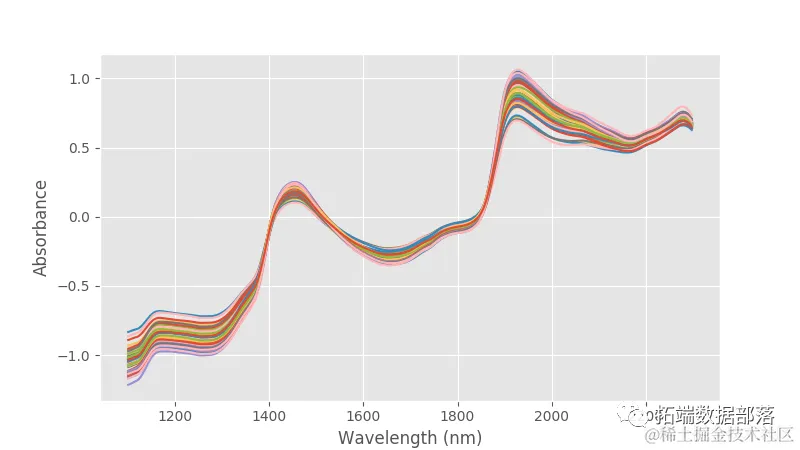
如果需要,数据可以通过主成分分析进行排序,并使用乘法散射校正进行校正,然而,一个简单但有效的去除基线和线性变化的方法是对数据进行二阶导数。让我们这样做并检查结果。
# 计算二阶导数X2 = savgol_fi......order = 2,deriv=2)# 绘制二阶导数图像plt.figure(fi......(8,4.5))with plt.style.context(('ggplot')):...... plt.show()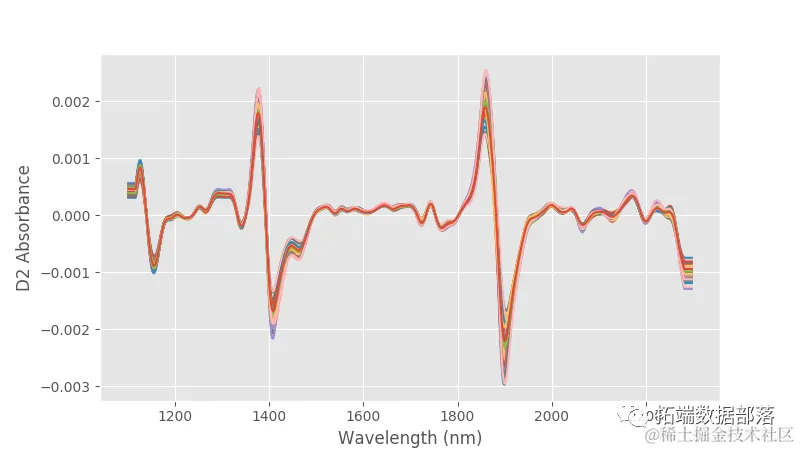
偏移已经消失,数据看起来更加紧密。
点击标题查阅往期内容


左右滑动查看更多

01
02
03
04
偏最小二乘回归
现在是时候优化偏最小二乘回归了。如上所述,我们想要运行一个具有可变组分数的偏最小二乘回归,并在交叉验证中测试其性能。实际上,我们想要找到最小化均方误差的组件数。让我们为此编写一个函数。
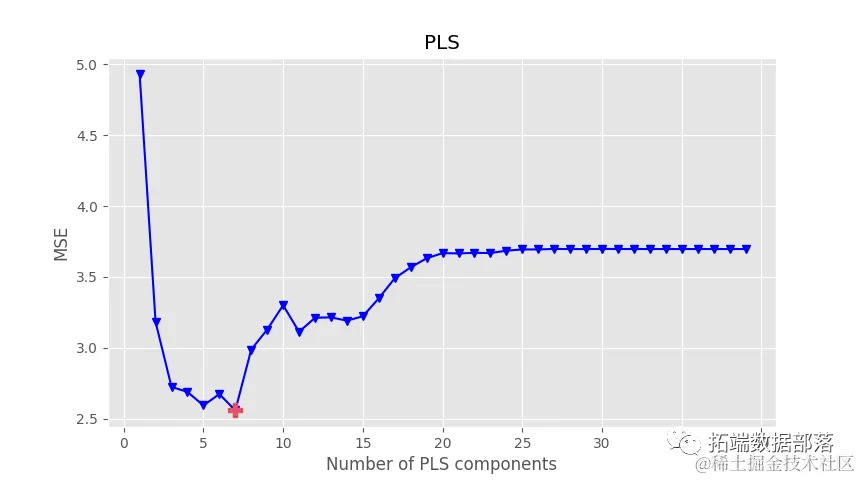
def optimisls_cv(X, ......=True): '''运行包括可变组件数量的偏最小二乘回归,最多到n_comp,并计算均方误差''' mse = []...... for i in component: pls = PLSR...... # 交叉验证 y_cv = cross_v...... comp = 100*(i+1)/n_comp # 在同一行上更新状态的技巧 stdout.write("\r%...... # 计算并打印均方误差最小值的位置 msemin = np...... stdout.write("\n") if plot_components is True: ...... plt.title('PLS') plt.xlim(left=-1) plt.show() # 使用最佳组件数定义PLS对象 pls_opt = PLSRe...... # 对整个数据集进行拟合 pls_opt.......t.predict(X) # 交叉验证 y_cv = cros...... cv=10) # 计算校准和交叉验证的得分 score_c = r2......e(y, y_cv) # 计算校准和交叉验证的均方误差 mse_c = mean_......y, y_cv) # 绘制回归图和评估指标 rangey = m......- min(y_c) # 将交叉验证和响应拟合为一条直线 z = np.poly......'red', edgecolors='k') # 绘制最佳拟合线 ax.plot(np.p......, linewidth=1) # 绘制理想的1:1线 ax.plot(y, ......idth=1) plt.show() return这个函数首先运行了一个循环,通过偏最小二乘回归的组件数计算预测的均方误差。其次,它找到最小化均方误差的组件数,并使用该值再次运行偏最小二乘回归。在第二次计算中,计算了一堆指标并将其打印出来。
让我们通过将最大组件数设置为40来运行此函数。
optimise......, plot_components=True)第一个图表是均方误差作为组件数的函数。建议最小化均方误差的组件数在该图中突出显示。
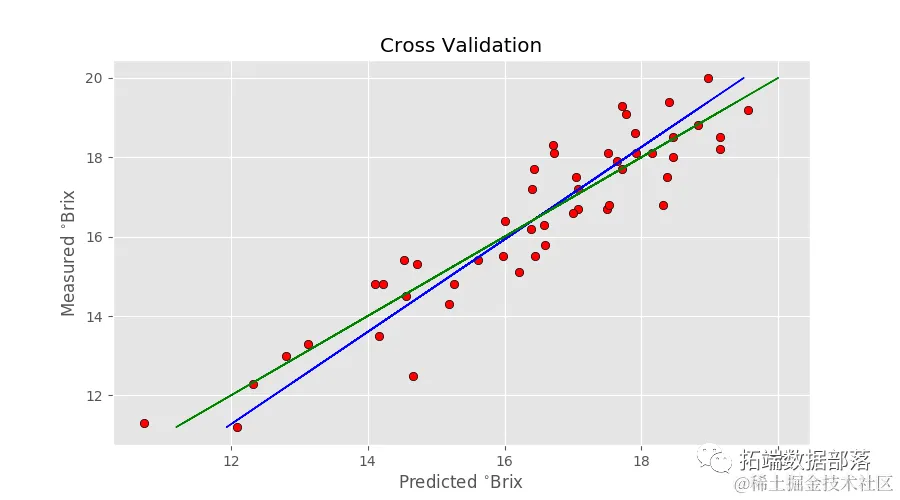
第二个图表是实际的回归图,包括预测指标。
同时,在屏幕上会打印出以下信息。

该模型在校准数据上似乎表现良好,但在验证集上的表现则不尽如人意。这是机器学习中所谓的过拟合的经典例子。
数据获取
在公众号后台回复“光谱数据”,可免费获取完整数据。

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《数据分享|Python用偏最小二乘回归Partial Least Squares,PLS分析桃子近红外光谱数据可视化》。


点击标题查阅往期内容


随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 用python从零开发一个哪吒动画项目
- Python注意力机制Attention下CNN-LSTM-ARIMA混合模型预测中国银行股票价格|附数据代码
- Python 列表推导式千万别乱用!这 3 种写法更清晰、更好维护
- 别让 Python 成了孤岛:一个初学者的 JSON 觉醒之路
- Python权限系统实战课程(Django5+DRF+vue3.2+elementplus+Jwt)38讲,已开源.
- 我通过 Python 自动化做信息收集,效率提升 10 倍(附实战案例)
- Python 有 LangChain,Go 有什么?揭秘字节 Eino 框架的生产级 AI 落地实战
- 学Python,买一个《PyMe》的永久VIP会员?
- 一文拿捏Python数据分析与可视化全流程
- Python 写核,GPU/TPU 跑飞!Keras 之父正在悄悄改写 AI 性能规则
