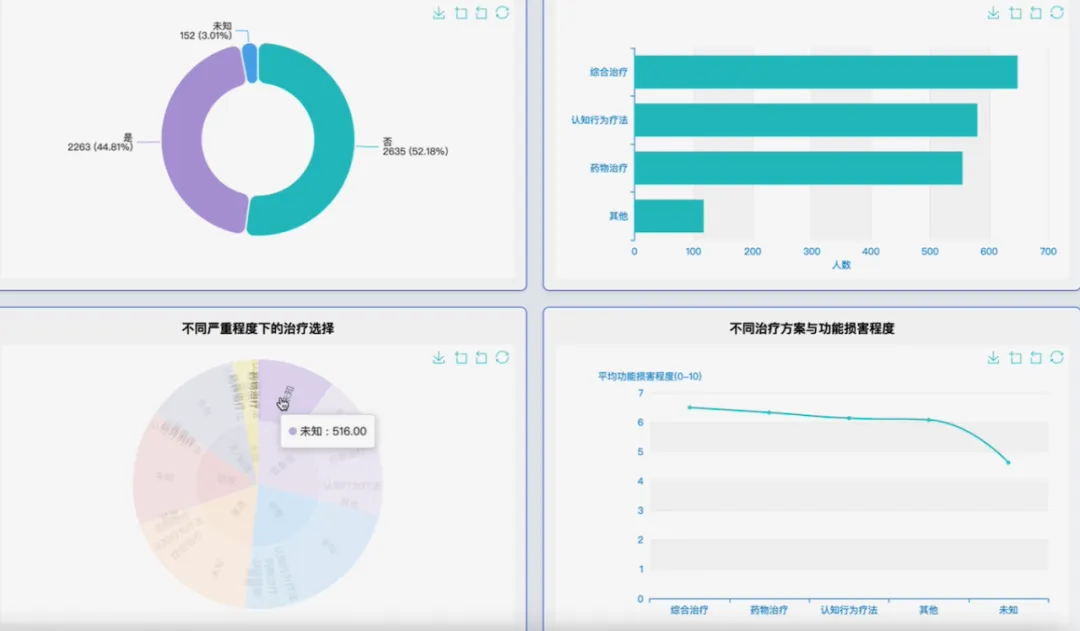
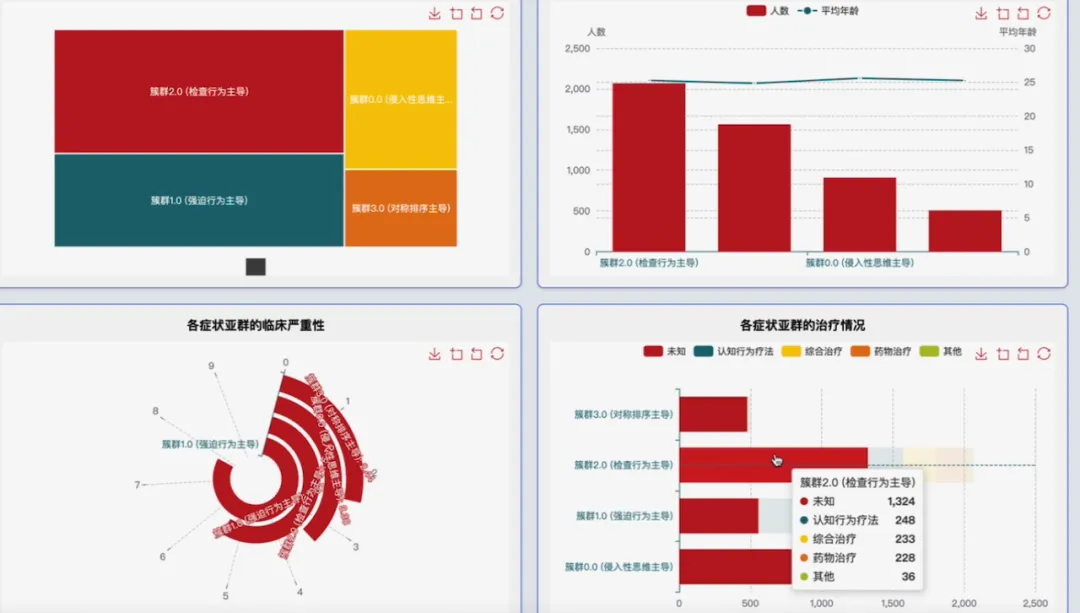
from pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, mean, when, isnan, isnull, round, avgfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.clustering import KMeansspark = SparkSession.builder.appName("OCD_Analysis_System").getOrCreate()# 核心功能1: 数据预处理与清洗def preprocess_data(df): # 处理年龄异常值99,将其转为None以便后续填充 df = df.withColumn("age", when(col("age") == 99, None).otherwise(col("age"))) # 计算数值列的平均值用于填充缺失值 age_mean = df.select(mean(col('age'))).collect()[0][0] distress_mean = df.select(mean(col('distress_level_0_10'))).collect()[0][0] impairment_mean = df.select(mean(col('impairment_work_school_0_10'))).collect()[0][0] onset_age_mean = df.select(mean(col('ocd_onset_age'))).collect()[0][0] # 填充数值型缺失值 df = df.fillna({'age': age_mean, 'distress_level_0_10': distress_mean, 'impairment_work_school_0_10': impairment_mean, 'ocd_onset_age': onset_age_mean}) # 填充分类型缺失值 df = df.fillna({'gender': '未知', 'education': '未知', 'prior_diagnosis': '未知', 'treatment_status': '未知'}) # 重新计算ocd_total_score symptom_cols = [f'C{i}' for i in range(1, 6)] + [f'CH{i}' for i in range(1, 6)] + [f'S{i}' for i in range(1, 6)] + [f'IT{i}' for i in range(1, 6)] # 填充症状评分内部的缺失值 for sc_col in symptom_cols: sc_mean = df.select(mean(col(sc_col))).collect()[0][0] df = df.fillna({sc_col: sc_mean}) # 使用填充后的分项计算总分 df = df.withColumn("ocd_total_score_calculated", sum(col(c) for c in symptom_cols)) # 用计算出的总分填充原始的缺失总分 df = df.withColumn("ocd_total_score", when(col("ocd_total_score").isNull(), col("ocd_total_score_calculated")).otherwise(col("ocd_total_score"))) # 移除辅助列 df = df.drop("ocd_total_score_calculated") # 移除完全为空的行 df = df.na.drop(how="all") return df# 核心功能2: 人口学特征与严重程度交叉分析def analyze_demographics_severity(df): # 分析不同性别下的平均年龄和严重程度分布 gender_severity_analysis = df.groupBy("gender", "ocd_severity").agg( round(avg("age"), 2).alias("平均年龄"), round(avg("distress_level_0_10"), 2).alias("平均痛苦程度"), round(avg("impairment_work_school_0_10"), 2).alias("平均功能受损程度") ).orderBy("gender", "ocd_severity") # 分析不同教育水平下的平均发病年龄和严重程度分布 edu_severity_analysis = df.groupBy("education", "ocd_severity").agg( round(avg("ocd_onset_age"), 2).alias("平均发病年龄"), round(avg("hours_rituals_per_day"), 2).alias("平均每日仪式时长") ).orderBy("education", "ocd_severity") # 将两个分析结果union起来(实际应用中可能分开保存) # 这里仅作为示例,展示一个函数内可以包含多个业务逻辑 return gender_severity_analysis, edu_severity_analysis# 核心功能3: 基于核心症状的患者聚类分析def cluster_patients_by_symptoms(df, k=3): # 选择用于聚类的核心症状维度列 symptom_cols = [f'C{i}' for i in range(1, 6)] + [f'CH{i}' for i in range(1, 6)] + [f'S{i}' for i in range(1, 6)] + [f'IT{i}' for i in range(1, 6)] # 使用VectorAssembler将特征列合并为一个特征向量 assembler = VectorAssembler(inputCols=symptom_cols, outputCol="features") df_with_features = assembler.transform(df) # 初始化K-Means模型 kmeans = KMeans(featuresCol="features", predictionCol="cluster", k=k, seed=42) # 训练模型 model = kmeans.fit(df_with_features) # 进行聚类预测 clustered_df = model.transform(df_with_features) # 为聚类结果添加中文说明,便于理解 # 这里简化处理,实际应根据聚类中心特征来命名 cluster_mapping = {0: "簇群0:混合症状型", 1: "簇群1:检查行为主导型", 2: "簇群2:侵入性思维主导型"} from pyspark.sql.functions import lit, create_map mapping_expr = create_map([lit(x) for x in sum(cluster_mapping.items(), ())]) clustered_df = clustered_df.withColumn("cluster_description", mapping_expr.getItem(col("cluster"))) # 返回包含聚类标签和描述的DataFrame return clustered_df.select("respondent_id", "age", "gender", "ocd_severity", "cluster", "cluster_description")