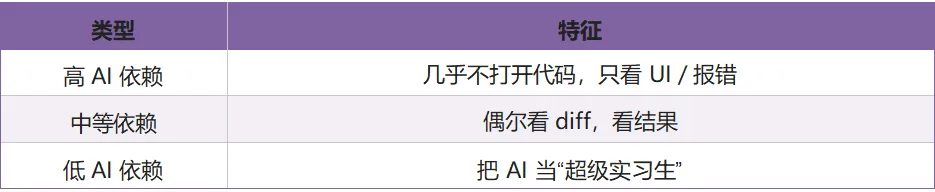
01 Vibe Coding 不是一种行为 ,而是一个「连续谱」
论文并未将 Vibe Coding 视为一种单一、固定的开发方式。相反,研究者观察到,不同开发者、甚至同一开发者在不同阶段,对AI 的依赖程度差异显著:有人几乎完全不查看生成代码,而有人会主动检查、修改并重新组织输出。这种从“高度代理”到“人机协作”的连续变化,构成了本文对 Vibe Coding 的一个重要认识。我们可以简单概括为以下三种人群:
论文指出,每个开发者在不同开发阶段,都有可能在这三种人群中不断切换,这也是将 “Vibe Coding” 称为“连续谱”的核心原因,同时我们也能从中得到一个结论,对于 “Vibe Coder” 的分类不是以“是否看代码”为依据,而是更深化为“你将多少认知权力交给了 AI”。
02 为什么说 Vibe Coding 像「掷骰子」?
在研究过程中,研究者发现,一些开发者在遇到错误时,仅通过重复提交相同或高度相似的错误信息作为 prompt ,而不提供额外上下文,期待模型在多次尝试中“ 自行修正”问题。这样带来的问题有两点:
(1)问题的空间并没有被缩小;
(2)每一次生成都是独立采样。
此外,也有开发者在遇到问题时通过“回滚”至之前操作,然后重新来过,这不属于调试,而是重新抽样。也往往有一批开发者仅接受可用结果,而不深究可解释性的修复,这将工程构建变得更加无法被理解,无论成功与否。
以上三种都属于 “Vibe Coding” 中出现的行为模式,我们在日常使用AI解决编码问题时也会出现类似行为。这证明了 “Vibe Coding” 这种范式的随机性并不完全来自模型,而是来自开发流程本身对因果控制的弱化。即使模型变得更强大,但是如果开发者不检查代码,不缩小问题空间,不建立明确假设,这种开发中的随机性仍然存在,“掷骰子”行为仍会发生。03 Vibe Coding 的核心不是 Prompt ,而是「认知模型」。
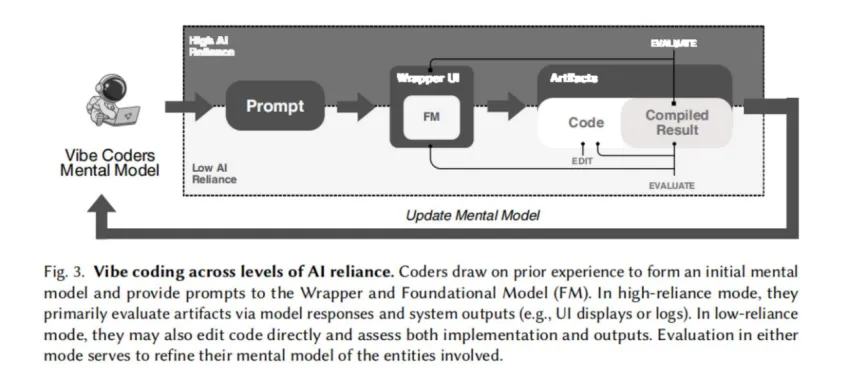
从研究者对开发行为的分析来看,Vibe Coder 在与大模型的交互过程中,实际上是在不断调整和修正自己对系统的认知模型,同时不断循环 “Prompt → AI → Artifact → Evaluation →心智模型更新→下一个 Prompt” 这一过程,正如下图所示:
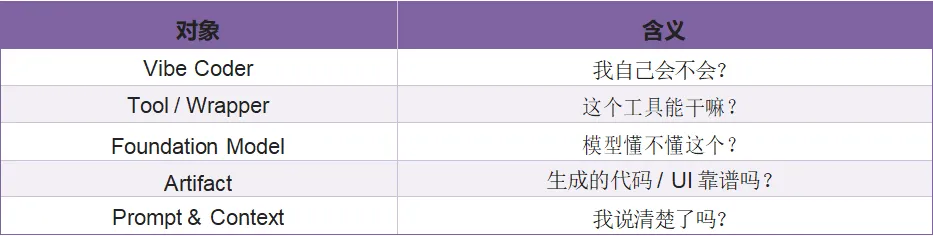
同时,Vibe Coder 一直在构建 5 种认知模型,如下表所示:
而这一研究也引出了一个值得关注的发现:很多时候不是大语言模型解决不了问题,而是使用者的认知模型有误,这一误差导致无法与大语言模型产生合理交互,最终导致问题无法解决,也印证了上文提到的“掷骰子”现象。







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
