第 1 章 CUDA 简介
1.1. 简介
1.1.1 图形处理器 (GPU)
- • 起源: GPU 最初是为 3D 图形渲染设计的专用硬件(固定功能)。
- • 进化 (2003): 变得可编程,可以并行处理 3D 场景的每个像素。
- • 革命 (2006): NVIDIA 推出 CUDA,允许任何类型的计算(不仅是图形)都在 GPU 上运行。
- • 现状: 从科学模拟(流体、能源)到现代 AI(大语言模型、扩散模型),GPU 是算力基础。
1.1.2 使用 GPU 的优势
- • 核心优势: 在同等价格和功耗下,GPU 比 CPU 提供更高的指令吞吐量和内存带宽。
- • CPU: 专为低延迟设计(快速完成一个任务)。擅长复杂的逻辑控制和串行运算。
- • GPU: 专为高吞吐量设计(同时完成成千上万个任务)。牺牲了单线程速度,换取海量并行能力。
- • 晶体管分配: CPU 把晶体管花在缓存和控制上;GPU 把晶体管花在数据处理(计算单元)上。
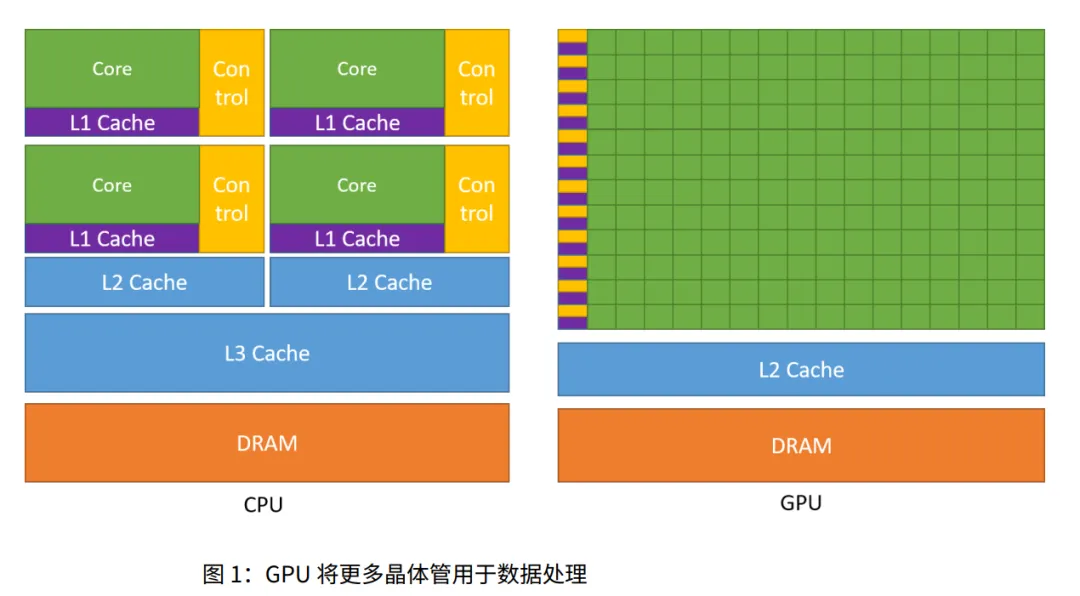
1.1.3 快速入门
这一节列举了使用 GPU 的不同层次(从易到难):
- 1. 现成库 (最快): 直接调用 NVIDIA 优化好的库 (cuBLAS, cuDNN, cuFFT)。
- 2. 框架: 使用 PyTorch, TensorFlow 等 AI 框架。
- 3. 领域特定语言 (DSL): OpenAI Triton, NVIDIA Warp。
- 4. CUDA C++ (本书重点): 直接编写底层代码,控制力最强。
1.2. 编程模型
这是本章最核心、也是最抽象的部分。
1.2.1 异构系统
- • 概念: 系统由 主机 (Host, 即 CPU) 和 设备 (Device, 即 GPU) 组成。
- 3. CPU 启动 内核 (Kernel) 在 GPU 上运行。
- • 内核 (Kernel): 在 GPU 上运行的那个函数。启动一次内核,就像在 GPU 上生成了成千上万个线程来执行这一个函数。
1.2.2 GPU 硬件模型
- • 定义与资源: GPU 的核心构建块,相当于一个 “独立车间”。它内部自带计算单元和关键的存储资源(寄存器 + 统一数据缓存(包含 L1 和共享内存))。
- • 通俗理解: 只有当车间(SM)里有足够的工具(寄存器/共享内存)时,才能派更多工人(线程)进去干活。
- • 定义: 多个 SM 组成的集合,相当于一个 “厂区”。
- • 层级关系: 一个 GPU 包含多个 GPC,一个 GPC 包含多个 SM。
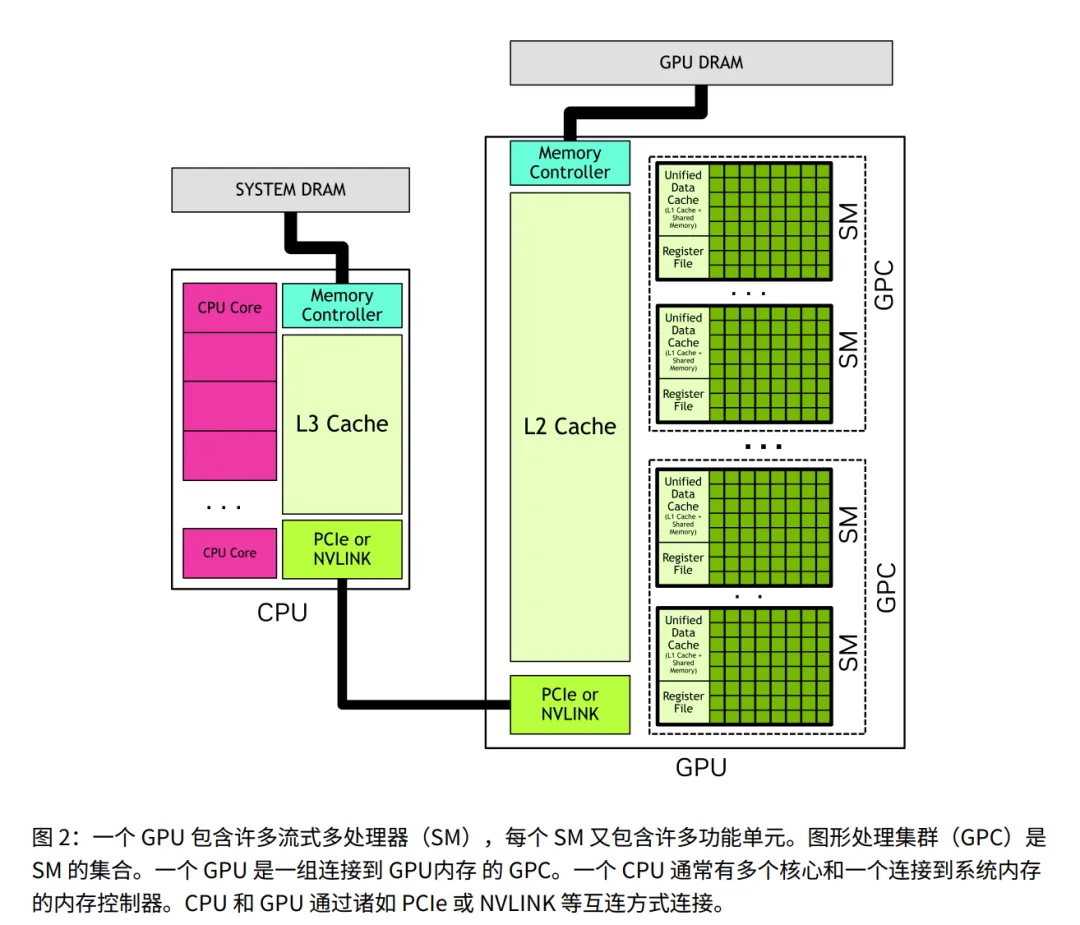
1.2.2.1 线程块与网格 (Thread Blocks and Grids)
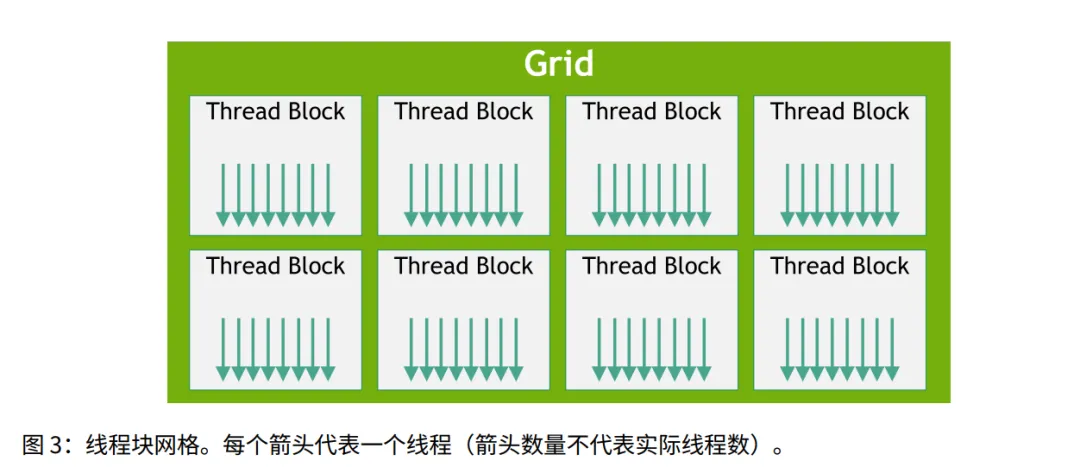
1. 核心层级与维度
- 1. 启动机制: 应用程序启动一个内核 (Kernel) 产生数百万个线程。
- • 线程 (Thread) 组成 线程块 (Block)。
- • 线程块 (Block) 组成 网格 (Grid)。
- 3. 一致性约束: 同一个网格内的所有线程块,其大小和维度必须完全相同(不能 Block 0 有 32 个线程,Block 1 有 64 个线程)。
- 4. 多维特性: Block 和 Grid 都可以是 1D, 2D, 或 3D。
- • 目的: 简化数据映射。比如处理 2D 图像时,用 (x, y) 坐标比用一维的线性索引更直观。
💡 通俗解读:阅兵方阵
- • Block (线程块) = 一个具体的方阵(如陆军方阵、海军方阵)。
- • 约束: 哪怕部队很大,规定了一个方阵是 人,那么所有方阵都得是 人。
- • 维度: 就像方阵可以排成“一字长蛇阵”(1D) 或 “矩形阵”(2D),怎么排取决于方便怎么点名。
2. 身份定位与执行配置
- • 必选: 网格维度 (Grid Dim)、线程块维度 (Block Dim)。
- • 可选: 集群大小 (Cluster size)、流 (Stream)、SM 配置。
- 2. 内置变量: 硬件提供了特殊的变量,线程可以直接读取:
- •
blockDim / gridDim: 块和网格的总大小。
- 3. 唯一标识 (Unique ID): 通过组合上述变量,每个线程都能算出自己在整个网格中的全球唯一 ID。
- • 用途: 决定当前线程负责计算数组中的哪一个元素(数据映射)。
💡 通俗解读:身份证系统
任何一个线程激活,都可以问系统:“我是谁?我在哪?”
- • 系统回答:“你是第 5 号方阵 (
blockIdx) 的第 3 排第 2 个兵 (threadIdx)。” - • 线程心里计算:“一个方阵 100 人,我在第 5 方阵,前面有 500 人,加上我在方阵里的序位... 懂了,我是全军第 532 号兵,我去搬第 532 块砖。”
3. 硬件映射与通信
- 1. Block SM 绑定: 一个线程块内的所有线程,必须在同一个流式多处理器 (SM) 上执行。
- 2. 通信优势: 因为在同一个 SM 上,块内线程可以:
- • 同步: 等待彼此(
__syncthreads())。
- 3. 共享内存 (Shared Memory): 既然在同一个 SM,大家可以访问同一块片上共享内存(相当于小组公共白板),用于交换信息。
🚧 核心限制 (硬规则)
- • Block 内: 亲密无间,可以协作,可以共享内存。
- • Block 间: 形同陌路,不能直接协作,不能指望谁先谁后。
4. 可扩展性与调度
- • 软件层:Grid 可能有 数百万个 Block。
- • 硬件层:GPU 可能只有 几十/几百个 SM。
- • 一个 Block 被分配给一个 SM 后,会一直在上面运行直到完成 (Run to completion)。
- • SM 就像一个窗口,做完一个 Block,再接下一个 Block。
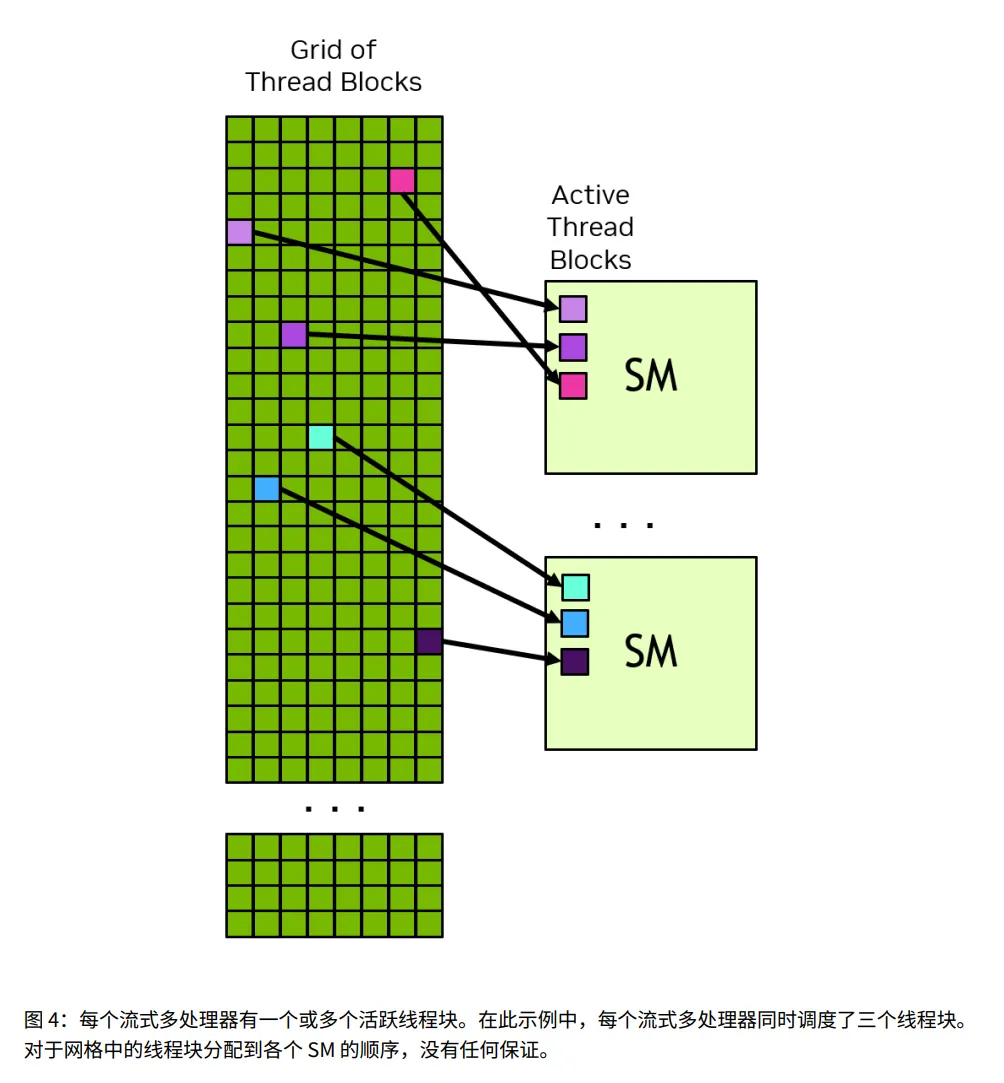
- • Block 0 可能比 Block 100 先执行,也可能后执行,甚至同时执行。
- • 后果: Block A 绝对不能依赖 Block B 的计算结果(因为 B 可能还没排上队呢)。
- • 因为 Block 之间没有依赖,且可以任意顺序执行,所以:
- • 高端显卡 (100个 SM): 一次并行处理 100 个 Block,很快跑完。
- • 低端显卡 (2个 SM): 一次处理 2 个 Block,慢慢排队也能跑完。
- • 结论: 同一份代码,可以在任意规模的 GPU 上运行。
💡 通俗解读:银行柜台模型
- • Grid = 银行大厅里等待办理业务的 1000 个客户 (Blocks)。
- • 低配显卡: 只开了 2 个窗口。客户 2 个 2 个地办,虽然慢,但总能办完。
- • 高配显卡: 开了 100 个窗口。客户 100 个 100 个地办,速度飞快。
- • 独立性原则: 客户之间不能有依赖。不能说“第 50 号客户必须拿到第 1 号客户的钱才能办事”,因为第 50 号可能排到了窗口,而第 1 号还在门外排队呢。
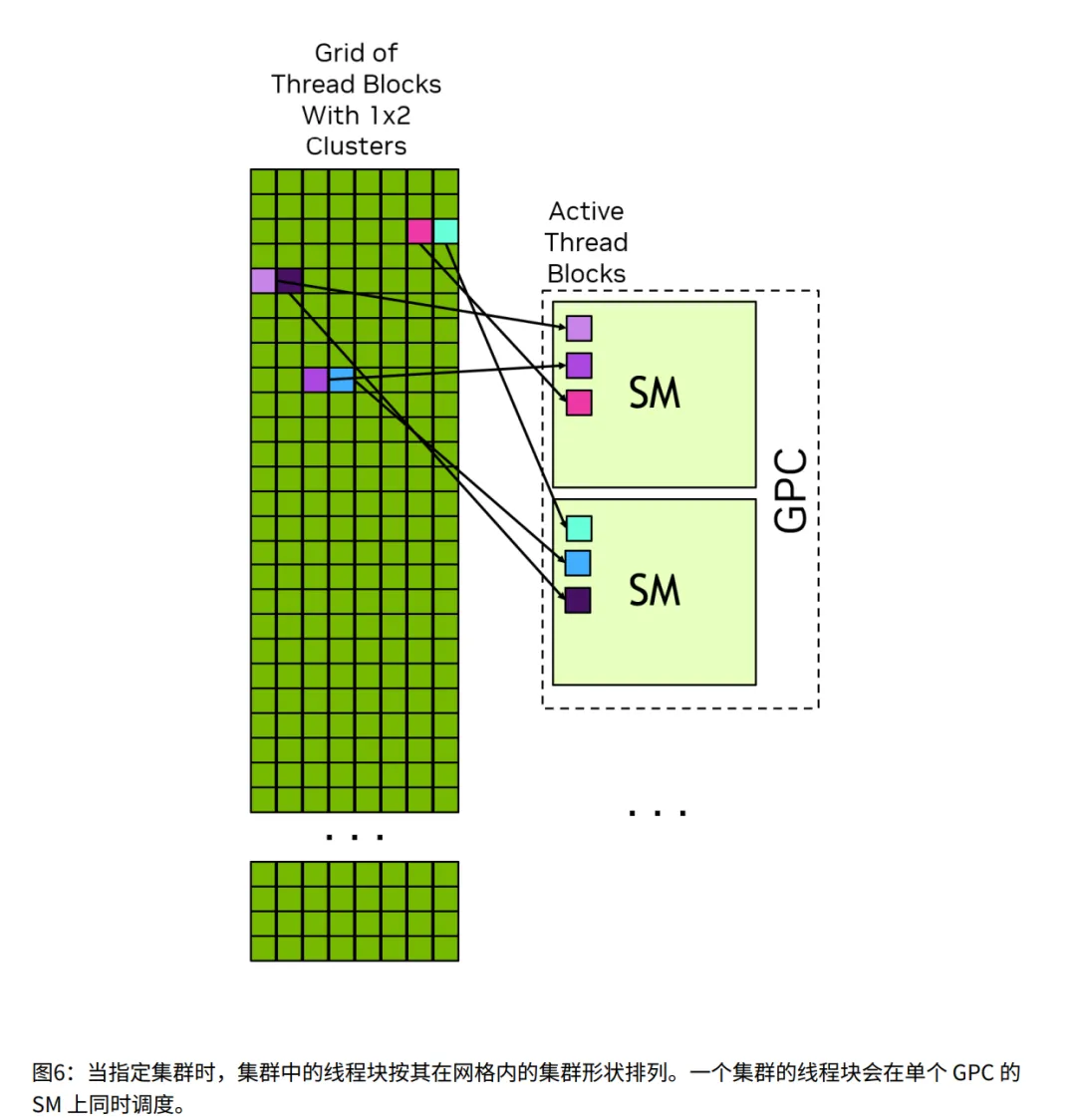
1.2.2.1.1 线程块集群 (Thread Block Clusters) [新特性]
- • 概念: 在 Block 和 Grid 之间加了一层。几个 Block 组成一个 Cluster。
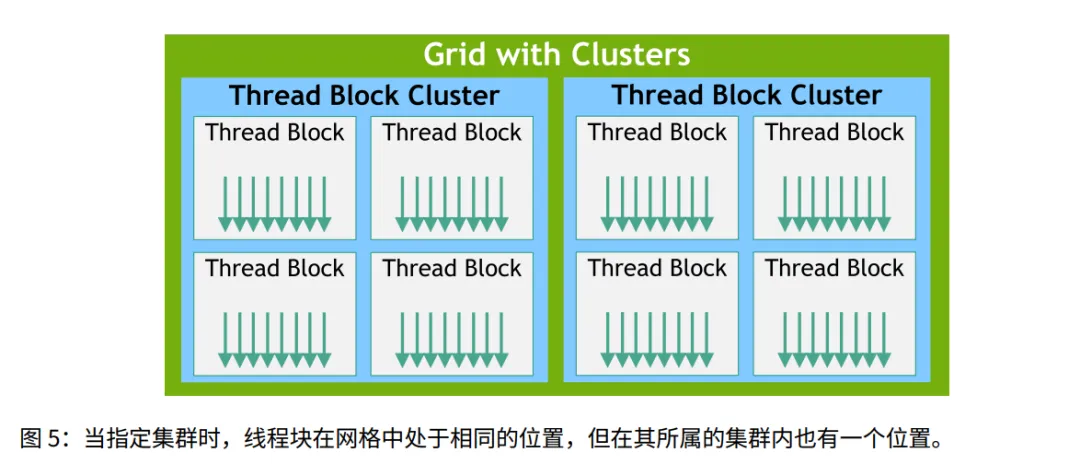
- • 优势: 同一个 Cluster 的 Block 保证在同一个 GPC 上运行,它们之间通信更快(分布式共享内存)。
1.2.2.2 线程束 (Warps) 与 SIMT
1. 基础定义与结构
- • 分组单位: 在线程块 (Block) 内部,线程是以 32 个 为一组进行组织的,这组线程叫 Warp (线程束)。
- • 通道 (Lane): Warp 中的每一个线程都有一个编号,称为 Warp Lane (线程束通道),编号范围是
0 到 31。 - • 分配规则: 线程分配给 Warp 的方式是确定的并且是可预测的(例如:Block 内的 Thread 0-31 分给 Warp 0,Thread 32-63 分给 Warp 1)。
💡 通俗解读:大巴车与座位
- • 分配: 游客 (线程) 按照报名顺序上车,前 32 人坐第一辆车,以此类推。
2. SIMT 执行机制
- • 范式: 采用 SIMT (单指令多线程) 模式。
- • 锁步前进 (Lock-step): Warp 内的所有 32 个线程,在同一时刻,必须执行同一条指令。大家是“绑在一起”前进的。
- • 逻辑独立性: 虽然大家指令一样,但每个线程有自己的寄存器状态和控制流路径(也就是每个线程依然觉得自己是独立的)。
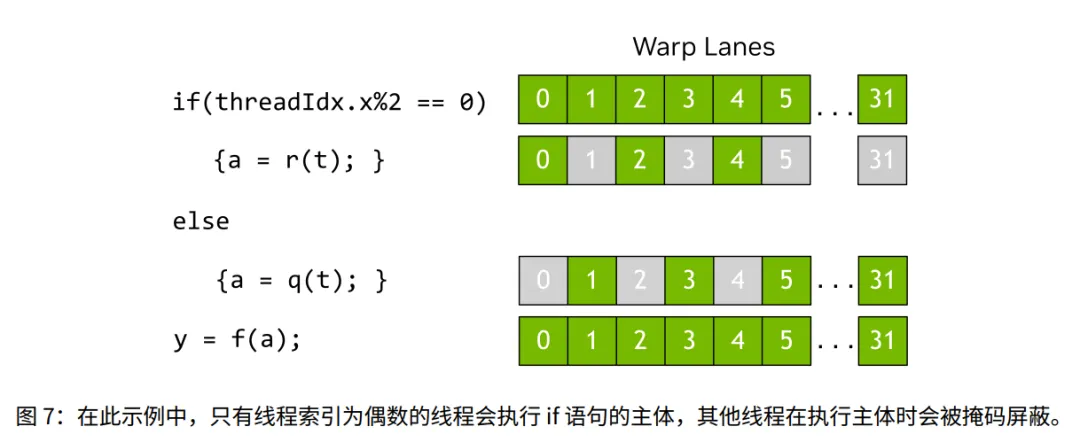
3. 分歧与掩码机制
解释了当“锁步前进”遇到“逻辑独立”时的矛盾。
- 1. 分歧 (Divergence): 当代码出现
if-else,导致 Warp 里一部分线程要走分支 A,另一部分要走分支 B。 - 2. 串行化处理: 硬件无法同时执行 A 和 B。必须分批执行。
- • 执行分支 A 时:硬件会把由“走分支 B”的那些线程对应的 Lane “掩码关闭” (Masked off)。被关闭的线程处于“休眠/非活跃”状态,不产生结果。
- 4. 性能最大化: 只有当 Warp 内所有线程都走同一条路时,硬件利用率才是 100%。
💡 通俗解读:广播体操
领操员 (控制单元) 喊口令,32 个学生 (Warp) 做动作。
- • 口令: “穿红衣服的跳一下 (if),穿蓝衣服的蹲一下 (else)。”
- 1. 领操员喊:“穿红衣服的跳!” 红衣跳,蓝衣站着不动 (Masked)。
- 2. 领操员喊:“穿蓝衣服的蹲!” 蓝衣蹲,红衣站着不动 (Masked)。
4. 编程模型 vs 硬件实现
- • 抽象层: CUDA 编程模型规定 Warp 内线程是“一起前进”的。
- • 硬件差异: 真实的硬件可能会做优化(比如对被掩码的通道进行特殊处理),但这通常对程序员是透明的(看不见的)。
- • 警告:不要依赖“硬件具体是怎么执行 Warp”的知识来写代码(比如试图利用某种未公开的同步行为)。
- • 风险: 违反模型可能导致未定义行为 (Undefined Behavior),你的代码在现在的显卡上能跑,换张卡可能就挂了。
5. 优化启示:Block 大小与内存 (Optimization Implications)
- 1. 内存访问: 理解 Warp 有助于理解 全局内存合并 (Coalescing) 和 共享内存 Bank 冲突。(后续章节会细讲,这里指出了为什么要学 Warp)。
- 2. Block 大小建议:线程块的总线程数最好是 32 的倍数。
- • 分配: Warp 0 满了 (32人);Warp 1 只有 1 个人 (Lane 0 活跃,Lane 1-31 空闲)。
- • 后果: Warp 1 依然占用硬件资源,但只有 1/32 的算力在工作。这就是尾部浪费。
💡 通俗解读:包车旅游
旅游团包车,一辆车 32 座。
- • 第 2 辆车上只有 1 个人,但这辆车的油费、司机费(硬件资源)和满载的那辆车是一样的。这是极大的浪费。
6. SIMT vs. SIMD (对比区分)
- • SIMD (单指令多数据): 通常要求严格的单一控制流(所有元素必须做完全一样的事),数据宽度是固定的(如 4 个 float)。
- • SIMT (单指令多线程): 允许每个线程有自己的控制流(虽然分歧会降低性能,但硬件允许你这么写,逻辑上更灵活)。
1.2.3 GPU 内存
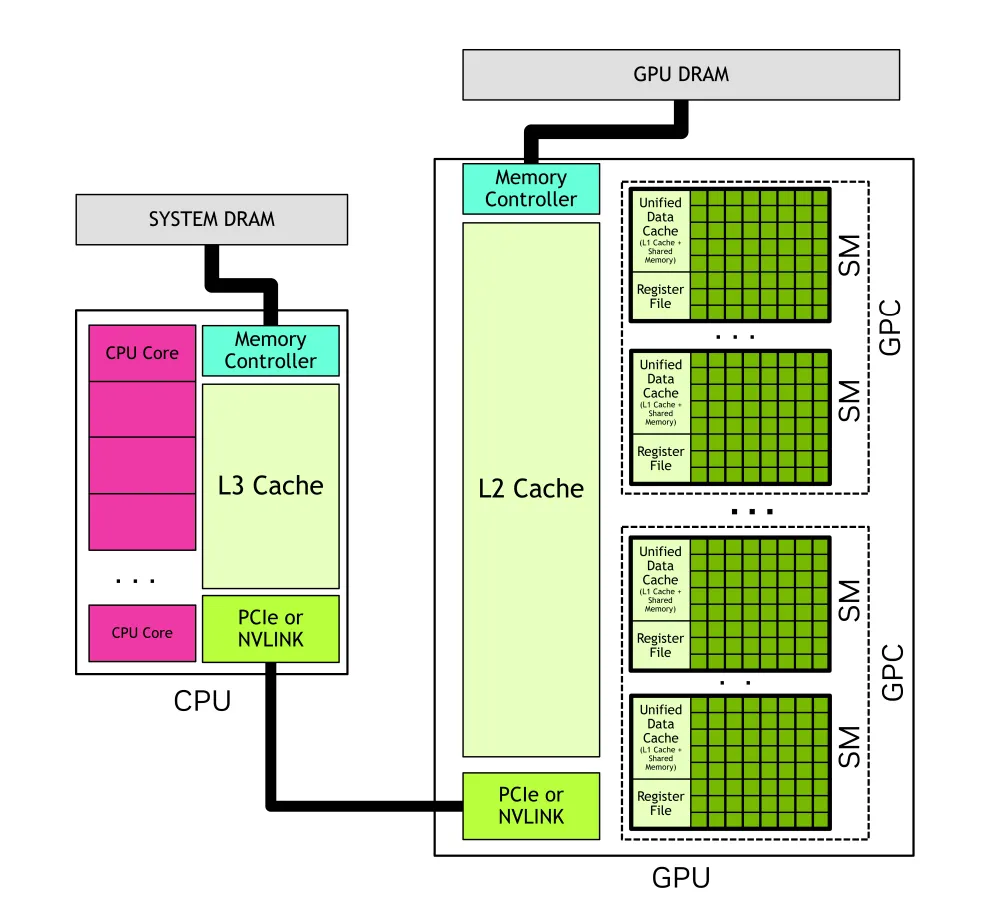
核心综述: 现代异构系统(CPU+GPU)拥有多个独立的内存空间。GPU 除了自动管理的缓存外,还拥有可编程的片上内存。
1.2.3.1 异构系统中的 DRAM 内存
这一节讲的是物理上位于 GPU 芯片外部,但焊在显卡板子上的大容量存储(即我们常说的“显存”)。
1. 物理连接与术语:
- • 全局内存 (Global Memory): 连接到 GPU 的 DRAM。
- • 注意: “全局”指 GPU 内部通用,不代表系统其他部分(如 CPU)一定能直接物理访问。
- • 系统/主机内存 (System/Host Memory): 连接到 CPU 的 DRAM。
2. 统一虚拟寻址 (Unified Virtual Addressing - UVA):
- • 机制: CPU 和 GPU 共用一个统一的虚拟地址空间。
- • 唯一性: 系统中每个 GPU 和 CPU 的地址范围互不冲突。
- • 智能识别: 给定一个指针地址,系统能确定它物理上位于 GPU 显存还是 CPU 内存,甚至能区分是哪一张显卡(多 GPU 系统)。
3. 数据操作:
- • CUDA API: 负责分配内存、在设备间(CPU ↔ GPU 或 GPU ↔ GPU)复制数据。
- • 显式控制: 程序员需要手动控制数据位置,以保证数据本地性(即数据要离计算单元越近越好)。
1.2.3.2 GPU 中的片上内存
这一节讲的是物理上位于 GPU 芯片内部的资源。主要聚焦在 SM 内部,速度极快但容量有限。
1. SM 私有资源 (寄存器与共享内存):
- • 特性: 极速访问,但 SM 之间不可见(SM A 不能读 SM B 的寄存器)。
2. 寄存器文件 (Register File):
- • 公式:
(单线程寄存器数 × 线程块内线程数) ≤ SM 总寄存器数。 - • 后果:超过限制则内核无法启动。需减少线程数或优化代码。
3. 共享内存 (Shared Memory):
- • 可见性: 对同一个 线程块 (Block) 或 集群 (Cluster) 内的所有线程可见。
4. 统一数据缓存配置:
- • 物理本质: SM 内的 L1 缓存 和 共享内存 通常共用同一块物理硬件。
- • 平衡配置: 可以在 L1 和共享内存之间调节大小比例(例如:多给点 L1 用于缓存,或多给点 Shared 用于通信)。
1.2.3.2.1 缓存
虽然也属于片上内存,但官方文档单独列出,因为除了 SM 私有的,还包含了全局共享的 L2。
1. L1 缓存:
- • 共享性: 和寄存器、共享内存一样,服务于该 SM 内的线程块。
2. L2 缓存:
- • 特点: 容量比 L1 大,速度比 L1 慢,但比全局内存快得多。
3. 常量缓存 (Constant Cache):
- • 用途: 缓存全局内存中声明为
const (常量) 的数据。 - • 优化技巧: 编译器常把 内核参数 (Kernel Arguments) 放在这里,避免占用 L1,提升性能。
1.2.3.3 统一内存 (Unified Memory)
这一节讲的是一种内存管理技术,而非物理硬件。它是与 1.2.3.2 (片上内存) 并列的概念。
1. 显式分配 (传统方式):
- • CPU 代码只能读写 CPU 内存,GPU 内核只能读写 GPU 内存。
2. 统一内存 (UM) 特性:
- • 概念: 允许申请一块可以从 CPU 或 GPU 访问的内存。
- • 底层机制: CUDA 运行时或硬件会在需要时,自动处理数据的重定位 (Relocation)。
- • 通俗理解: 系统会自动把数据“搬”到正在访问它的那个处理器旁边。
3. 性能原则:
- • 并非零开销: 即使使用 UM,物理数据依然需要通过总线传输。
- • 最佳实践: 依然要尽量减少迁移,确保计算时数据已经位于直连的内存中(即让 GPU 算的时候数据已经在 GPU DRAM 里,而不是算一次去 CPU 拿一次)。
1.3. CUDA 平台
核心综述: CUDA 平台不仅仅是编程语言,它是由硬件(GPU)、软件(驱动、工具包)以及一整套编译技术组成的复杂生态系统。
1.3.1 计算能力与流式多处理器版本
这部分讲的是怎么给 GPU 硬件划分“档次”和“版本”。
1. 定义与作用:
- • 编号含义: 每个 NVIDIA GPU 都有一个计算能力编号。
- • 作用: 它像一个身份证,决定了这块 GPU 支持哪些功能(如是否有 Tensor Core)以及硬件参数(如寄存器有多少)。
- • 查询: 可以在附录或官方页面查询,也可以通过 API 在代码里查询。
2. 版本格式 (X.Y):
- • 主版本号 (X): 代表架构的大换代(如 Ampere, Hopper, Blackwell)。
- • 示例:
CC 12.0 主版本 12,次版本 0。
3. 与 SM 的对应关系:
- • 计算能力直接对应 SM (流式多处理器) 的版本。
- • 命名规则:
CC 12.0 的 GPU,其 SM 版本叫 sm_120。 - • 用途: 编译代码时,生成的二进制文件会打上这个标记(比如“这是给 sm_120 用的”)。
1.3.2 CUDA 工具包与 NVIDIA 驱动
这部分区分了两个经常被搞混的安装包。
1. NVIDIA 驱动 (Driver):
- • 地位: GPU 的“操作系统”。是基础,必须安装。
- • 功能: 管理图形显示、Vulkan、DirectX 以及 CUDA 计算。
2. CUDA 工具包 (Toolkit):
- • 内容: 包含编译器 (
nvcc)、开发库、头文件、分析工具。 - • CUDA 运行时 (Runtime): 工具包里的一个核心库。
- • 提供语言扩展(能让你写
<<<...>>> 这种代码)。
3. 兼容性:
- • 驱动版本和工具包版本之间有严格的兼容性要求(通常新驱动能跑旧工具包编译的程序,反之未必)。
1.3.2.1 运行时 API vs. 驱动 API
- • 底层:CUDA Driver API (由驱动直接提供,更难,更繁琐)。
- • 上层:CUDA Runtime API (构建在 Driver API 之上,封装好了,更简单)。
- • 使用建议: 本书主要讲 Runtime API(因为它够用了且好用)。
- • 互操作: 你可以混合使用这两套 API,有些偏门功能只能靠 Driver API 实现。
💡 通俗解读:自动挡 vs 手动挡
- • Toolkit (工具包) = 仪表盘和方向盘。
- • Runtime API = 自动挡。挂上 D 挡就能走,帮你在后台处理了很多离合器操作(上下文管理、初始化),简单方便。
- • Driver API = 手动挡。你得自己踩离合、换挡(手动管理 Context),虽然麻烦,但赛车手(高级优化)有时需要这种极致的控制力。
1.3.3 并行线程执行 (PTX)
这是 CUDA 实现“一次编写,到处运行”的关键中间层。
1. 定义:
- • PTX (Parallel Thread Execution) 是一种虚拟指令集架构 (Virtual ISA)。
2. 作用 (抽象层):
- • 不仅限于 C++: 因为有了 PTX 这一层,其他语言(如 Python, Fortran)只要能翻译成 PTX,就能在 GPU 上跑。
- • 硬件无关: PTX 还在天上(虚拟的),不针对具体的地面(物理 GPU)。
3. 生成与执行:
- • 生成: 源代码 编译器/DSL PTX 代码 (中间表示 IR)。
- • 执行: 必须通过 JIT (即时编译) 工具,把 PTX 翻译成真正 GPU 能懂的机器码。
4. 版本化:
- • PTX 也有版本(如
compute_80),对应它支持的计算能力特性。
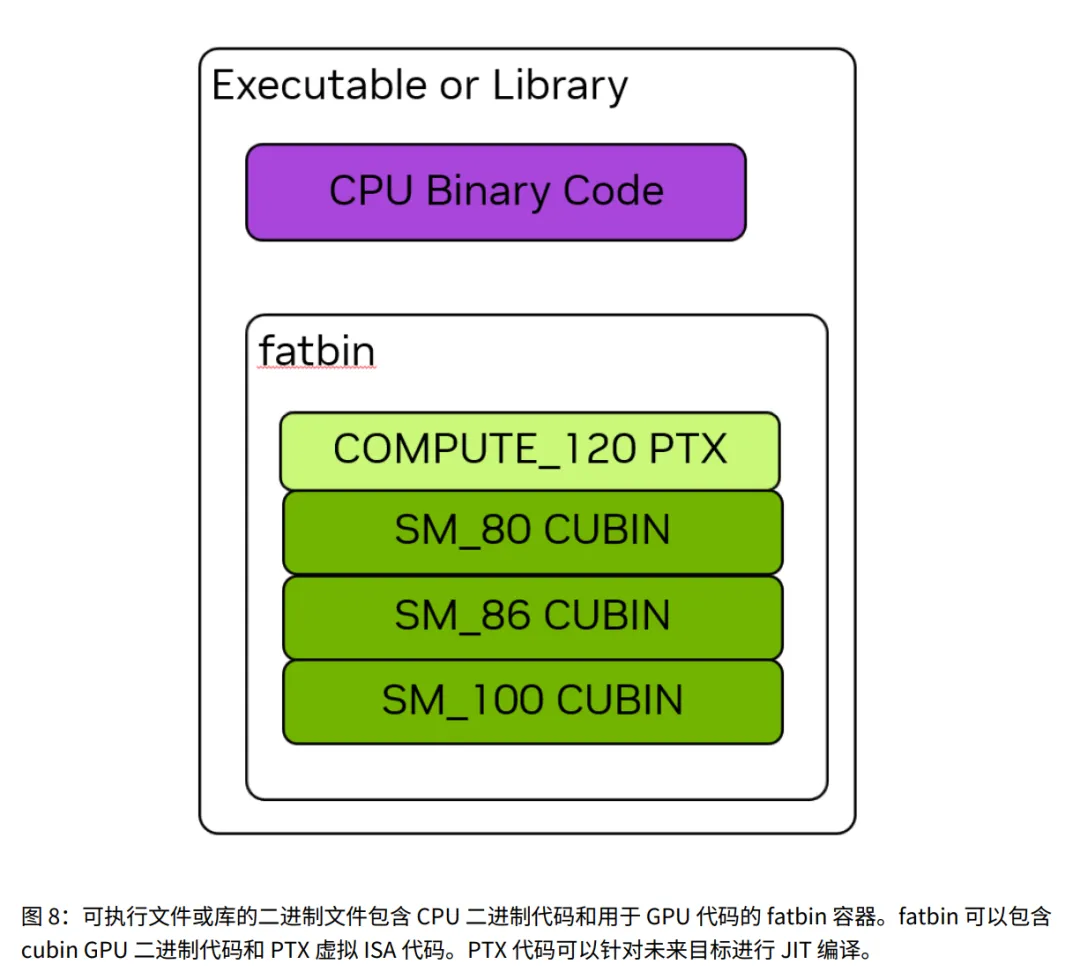
1.3.4 Cubins 和 Fatbins
这部分讲代码编译出来到底是个什么东西。
1. 编译流程:
- • C++ 高级语言 PTX (虚拟汇编) Cubin (真正的二进制机器码)。
2. Cubin (CUDA Binary):
- • 局限: 比如
sm_120 的 cubin,只能在计算能力 12.0 的 GPU 上跑,换个旧 GPU 就看不懂了。
3. Fatbin (Fat Binary):
- • 内容: 里面包含 CPU 代码 和 GPU 代码。
- • 多目标支持 (关键): 一个 Fatbin 可以同时塞进去:
- • 针对 sm_70 的 cubin (给老卡用)。
- • 针对 sm_90 的 cubin (给新卡用)。
- • 运行时机制: 程序运行时,驱动程序会自动打开这个包,挑出最适合当前 GPU 的那个文件来执行。
💡 通俗解读:万能钥匙包
- • Cubin = 一把实体钥匙。只能开特定型号的锁(显卡)。
- • PTX = 配钥匙的图纸。拿着图纸,现场可以配出任何型号的钥匙。
- • 里面预先放了几把常用锁的实体钥匙(Cubin),拿出来就能开,速度快。
- • 还塞了一张图纸(PTX)。如果遇到的锁没有现成钥匙,就拿出图纸现场配一把(JIT)。
1.3.4.1 二进制兼容性
针对 Cubin (实体钥匙)
- • 条件:
GPU 主版本 == Cubin 主版本 且 GPU 次版本 >= Cubin 次版本。 - • ✅ 在 GPU 8.6, 8.7, 8.9 上能跑(小版本够新)。
- • ❌ 在 GPU 8.0 上不能跑(GPU 太老,次版本 0 < 6)。
- • ❌ 在 GPU 9.0 上不能跑(架构大换代,主版本不同)。
- • 警告: 只有官方工具生成的二进制才保修,自己改了就不算。
1.3.4.2 PTX 兼容性
针对 PTX (配钥图纸)
- • 规则:前向兼容 (Forward Compatibility)。
- • 条件: 只要
GPU 计算能力 >= PTX 版本。 - • ✅ 在 GPU 8.0, 8.6, 9.0, 10.0... 上都能跑。
- • ❌ 在 GPU 7.0 上不能跑(显卡太老,不支持 8.0 的特性)。
- • 意义: 这是让老程序能在未来发售的新显卡上运行的唯一救命稻草。
1.3.4.3 即时编译 (JIT Compilation)
1. 概念:
- • 运行时,驱动程序把 PTX 翻译成二进制代码的过程。
2. 优缺点:
- • 缺点: 应用程序启动变慢(因为要花时间现场“配钥匙”)。
3. 计算缓存 (Compute Cache):
- • 机制: 驱动程序编译完一次后,会把结果缓存起来。
- • 效果: 下次再运行,直接读缓存,不用再编译了。
- • 失效: 如果升级了显卡驱动,缓存自动作废(为了用新驱动的优化技术重新编译)。
4. 控制与工具:
- • 延迟加载 (Lazy Loading): 一种优化技术,不一次性编译所有内核,用到哪个编译哪个。
- • NVRTC: 一个运行时的库,允许你在代码里直接把一串 C++ 字符串编译成 PTX(动态生成代码)。
图解:编译流程与兼容性
这张图展示了从代码到硬件的完整路径,以及 Fatbin 是如何利用 Cubin 和 PTX 实现兼容的。
图解说明:
核心逻辑:双轨策略(速度 vs 兼容)
这张图展示了 NVIDIA 如何通过 Fatbin 这种机制,既保证了老显卡的速度,又解决了新显卡的兼容问题。
1. 开发与打包阶段 (Dev_Time & Fatbin)
“把做好的菜(Cubin)和菜谱(PTX)都装进饭盒(Fatbin)里”
- • Fatbin (多合一容器): 最终生成的可执行文件(exe/dll)。它里面装着两类东西:
- • Cubins (机器码): 针对特定显卡(如 RTX 3090 / sm_86)预先编译好的代码。
- • *特点:*即拿即用,启动极快,但换个架构就废了。
- • PTX Code (中间码): 一种虚拟的汇编代码(类似 Java 的字节码)。
- • *特点:*通用蓝图,不针对具体硬件,留给驱动去现场发挥。
2. 用户运行阶段 (Runtime_User)
“显卡吃饭:有现成的直接吃,没有现成的现场做”
驱动程序会检测当前显卡型号,自动选择两条路径之一:
- • 路径 A:直接加载 (Direct Load) —— [追求极致速度]
- • 场景: 用户的显卡架构(如 sm_86)刚好在 Fatbin 里有对应的 Cubin。
- • 动作: 驱动直接把 Cubin 喂给 GPU。
- • 路径 B:JIT 即时编译 (Just-In-Time) —— [战未来]
- • 场景: 用户的显卡太新了(如 sm_90),Fatbin 里没有对应的 Cubin。
- • 动作: 驱动拿出 **PTX(菜谱)**,调用内置编译器,现场将 PTX 翻译成 sm_90 的机器码。
- • 结果: 兼容性满分!虽然第一次启动稍微慢点(因为要翻译),但程序成功跑起来了。
3. 计算缓存 (Compute Cache)
“做好的菜记得留底,下次不用重新做”
- • 机制: 路径 B 中 JIT 现场翻译出来的机器码,会被驱动存到硬盘缓存里。
- • 效果: 用户第二次打开程序时,驱动发现缓存里已经有翻译好的 sm_90 代码了,直接加载。体验瞬间变回路径 A 的速度。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
