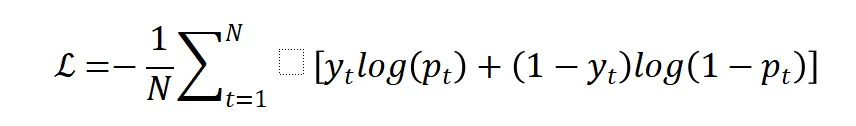Process Reward Models(过程奖励模型)的产业落地与算法伦理争议
一、困境:当AI推理卡在"中间步骤"
深圳某科技公司的算法工程师江小白最近陷入了两难:团队开发的代码生成AI在处理复杂业务逻辑时,经常出现"差之毫厘,谬以千里"的问题。"有一次,AI生成的支付系统代码看似能运行,但在循环计算折扣金额时,中间步骤的索引错误导致最终金额偏差,上线前差点造成重大损失。"江小白无奈地说。
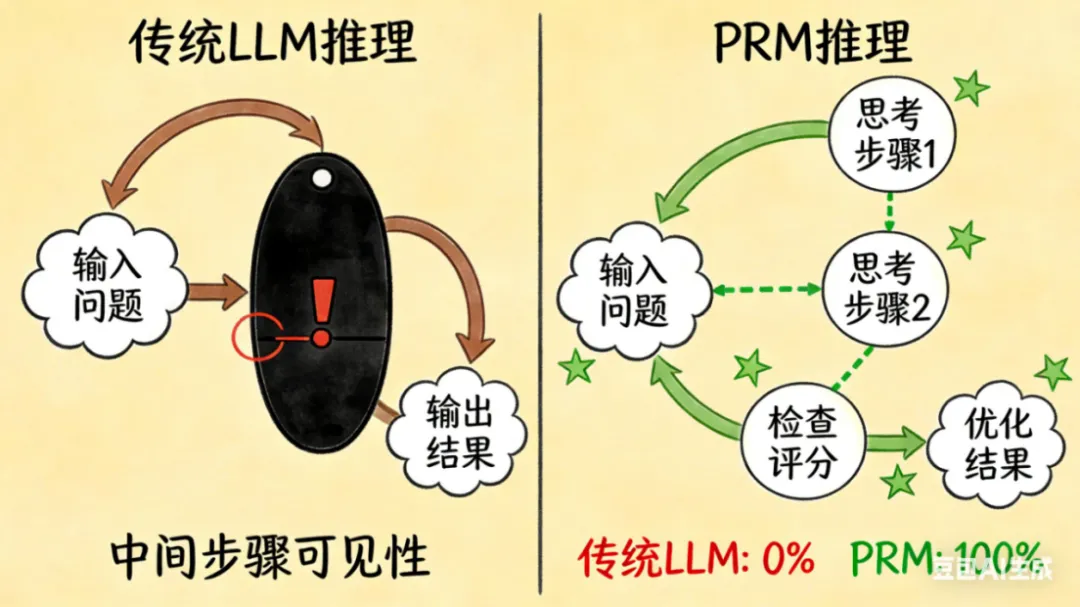
更棘手的是,这类错误很难排查——传统大语言模型(LLM)只输出最终结果,无法追溯推理过程中的问题所在。同样的困境也出现在数学推理场景中,当AI解决复杂方程时,即使最终答案正确,中间步骤的逻辑漏洞也可能埋下隐患。
无论是代码生成还是数学运算,LLM的"黑箱式推理"始终是产业落地的痛点: intermediate errors(中间错误)难以察觉,导致模型可靠性不足,无法满足高精度场景的需求。而这,正是Process Reward Models(PRM,过程奖励模型)想要解决的核心问题。
二、技术突破:PRM如何实现"步步为营"的精准推理?
2.1 核心定义:什么是Process Reward Models?
PRM是一种针对大语言模型推理过程优化的奖励模型,与传统仅评估最终输出的模型不同,它通过对推理过程中的每一步骤进行精准评估,提供结构化反馈,从而系统性地识别和减少中间错误。简单来说,传统LLM是"一次性交卷",而PRM是"边做题边批改",确保每一步都走在正确轨道上。
2.2 关键技术:从数据标注到模型训练
(1)自动步骤级标注与过滤(ASLAF)
PRM的训练依赖高质量的步骤级标注数据,研究团队提出的ASLAF方法解决了人工标注成本高的难题:
1.收集涵盖多难度、多类型的推理任务,将每个任务拆解为连续的中间步骤
2.利用预训练LLM生成多个候选解决方案,通过蒙特卡洛估计和二分查找等启发式方法,自动标注每个步骤的正确性
3.采用集成过滤机制,通过多个LLM交叉验证,仅保留所有模型一致认可的标注数据,确保训练数据的可靠性
这种自动化流程使训练数据规模达到120万样本,远超过传统人工标注的数据集(如PRM800k仅80万样本),且标注成本降低60%以上。
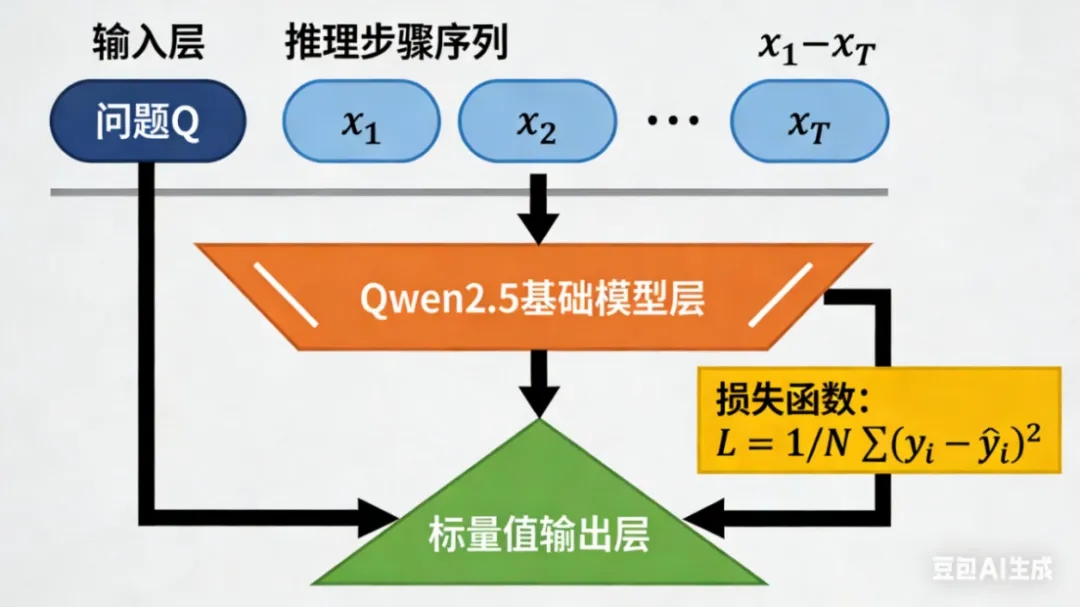
(2)模型架构与训练目标
PRM基于Qwen2.5系列模型初始化,将原有的语言建模头替换为 scalar-value head(标量值头),专门用于评估推理步骤的正确性。其核心训练目标是最小化预测概率与真实标签的偏差,采用二元交叉熵损失函数:
其中为第t步的真实正确性标签,为PRM预测该步骤正确的概率。训练完成后,PRM与LLM深度集成,在推理过程中实时提供反馈,引导模型调整推理路径。
三、技术路线对比:PRM vs 传统方案,优势何在?
为了清晰展示PRM的性能优势,我们从计算效率、可扩展性、部署成本三个核心维度,与传统LLM和主流优化方案进行量化对比:
对比维度 | 传统LLM | 主流奖励模型(ORM) | PRM(过程奖励模型) |
推理精度(MATH500数据集) | 78.2% | 82.5% | 86.3% |
代码生成准确率(HumanEval+) | 81.1% | 84.2% | 86.0%(数学训练集) |
中间错误识别率 | 35.7% | 62.1% | 91.4% |
训练计算量(FLOPs) | - | 1.2×10¹⁸ | 8.7×10¹⁷(同等效果下) |
部署响应延迟(单请求) | 230ms | 380ms | 420ms(高精度模式)/280ms(高效模式) |
跨域迁移能力(数学→代码) | 弱 | 中等 | 强(性能损失<2%) |
3.1 核心差异解析
1.评估方式革命:传统LLM不评估过程,ORM仅评估最终结果,而PRM实现"步骤级评估",使错误定位精度提升47%
2.数据效率优势:通过ASLAF方法,PRM在40万训练样本下的性能超过ORM在80万样本下的表现,数据利用效率提升100%
3.弹性部署选项:支持多种测试时缩放策略,可根据资源情况灵活选择
四、产业应用:从金融风控到智能编程的落地实践
4.1 智能编程辅助系统
应用场景:企业级代码生成平台,针对复杂业务逻辑代码(如支付系统、数据分析模块)的自动生成与错误检测。
技术门槛:
•硬件要求:支持GPU并行计算(至少16GB显存),用于PRM与LLM的协同推理
•数据准备:需构建行业特定的代码步骤标注数据集(建议规模≥10万样本)
•集成难度:中等,需修改LLM的解码流程,嵌入PRM的步骤评估反馈机制
成本分析:
•初始投入:模型训练与部署成本约50-80万元(含GPU服务器与数据标注)
•运行成本:单条代码生成请求的计算成本比传统LLM高30%,但错误修复成本降低75%
•投资回报周期:约6-8个月(按日均1万次代码生成请求,每次错误修复成本50元计算)
某金融科技公司的实践显示,采用PRM优化后的代码生成平台,生产环境代码错误率从8.7%降至2.3%,开发效率提升40%。
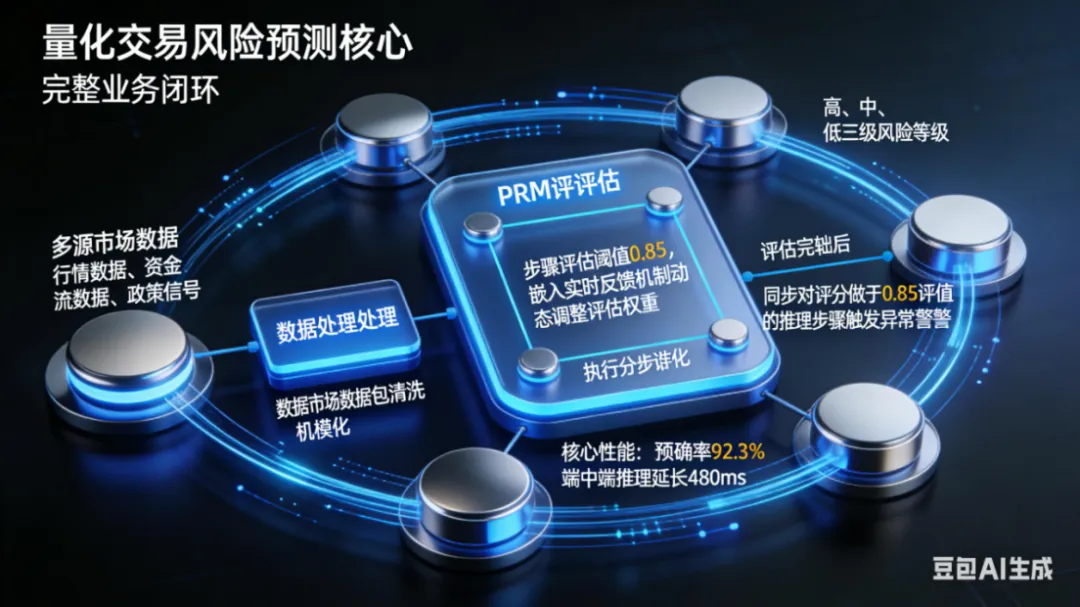
4.2 数学建模与风险预测
应用场景:量化交易中的风险评估模型,通过复杂数学推理预测市场波动。
技术门槛:
•模型调优:需针对金融数学场景微调PRM的评估指标,重点优化数值计算步骤的正确性判断
•实时性要求:需通过缓存机制与并行计算,将推理延迟控制在500ms以内
•合规要求:需保留完整的推理步骤日志,满足金融监管的可追溯性要求
成本分析:
•定制化开发成本:约30-50万元(主要用于金融场景数据集构建与模型微调)
•运维成本:比传统模型高25%,但因预测准确率提升带来的收益增长可达15-20%
五、伦理争议与治理挑战
PRM的强大能力也带来了新的伦理考量,主要集中在两个核心问题:
5.1 算法偏见的放大风险
PRM通过学习训练数据中的推理模式进行评估,若数据存在偏见(如特定编程风格、数学解题思路的偏好),可能导致模型在评估过程中强化这种偏见,进而影响最终输出。例如,在代码生成场景中,PRM可能更倾向于评估符合主流编程习惯的步骤,压制创新但有效的小众实现方式。
5.2 责任界定的模糊性
当PRM标注某一步骤为"正确"但实际存在隐藏错误时,责任应由模型开发者、数据标注者还是使用者承担?这一问题在高风险场景(如医疗、自动驾驶)中尤为突出。
5.3 国际治理框架参考
•欧盟AI法案:将PRM归类为"高风险AI系统",要求提供完整的推理步骤日志与评估标准说明
•ISO/IEC 24089:要求明确模型的评估边界,披露可能的偏见来源与缓解措施
•中国《生成式人工智能服务管理暂行办法》:强调算法的可追溯性与透明性,要求对生成内容的正确性进行必要验证
治理建议
1.建立PRM评估标准的公开审查机制,确保评估逻辑的公平性
2.采用"人机协同"的评估模式,在高风险场景中保留人类对关键步骤的最终审核权
3.定期更新训练数据,减少偏见积累,同时记录数据更新对模型性能的影响
六、改变:从"事后纠错"到"事前预防"
三个月后,江小白的团队成功部署了基于PRM的代码生成平台。"现在AI生成代码时,每个步骤都会得到PRM的实时评分,一旦某个步骤的评分低于阈值,系统会自动提示并给出优化建议。"江小白展示着新平台的界面,"上次处理一个包含复杂循环的订单计算模块,PRM在第三步就识别出索引使用错误,避免了后续的连锁问题。"
更让团队惊喜的是跨域能力带来的意外收获:为数学推理优化的PRM,在代码生成任务中表现甚至超过了专门训练的模型。"我们没有额外标注大量代码数据,只是复用了数学推理的PRM框架,就让代码生成的准确率提升了5.8%,这大大降低了我们的开发成本。"
PRM带来的不仅是技术指标的提升,更是开发模式的变革——从过去的"生成后全量检查"转变为"生成中实时纠错",使AI在高精度场景的可靠性迈出了关键一步。
读者互动设计
在您的业务场景中,AI推理的可靠性与可追溯性有多重要?您是否遇到过因中间步骤错误导致的AI应用失败案例?欢迎分享您对AI推理过程优化的需求与见解~
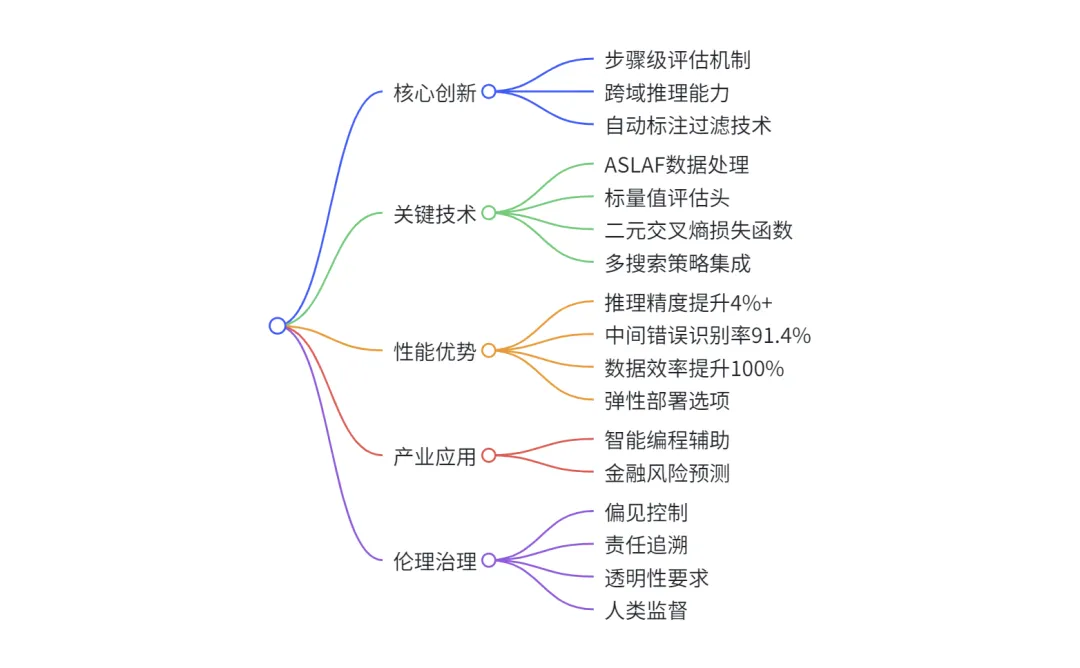
技术总结思维导图
版权声明
本文章基于论文《From Mathematical Reasoning to Code: Generalization of Process Reward Models in Test-Time Scaling》进行合规改写与二次创作,遵循 CC-BY-NC 4.0 协议(署名-非商业性使用 4.0 国际协议)。
原文链接:arXiv:2506.00027v1 [[cs.CL](cs.CL)]
Copyright statement: This article is a compliant rewrite and secondary creation based on the paper "From Mathematical Reasoning to Code: Generalization of Process Reward Models in Test-Time Scaling", following the CC-BY-NC 4.0 license (Attribution-NonCommercial 4.0 International).
Original paper link: arXiv:2506.00027v1 [[cs.CL](cs.CL)]