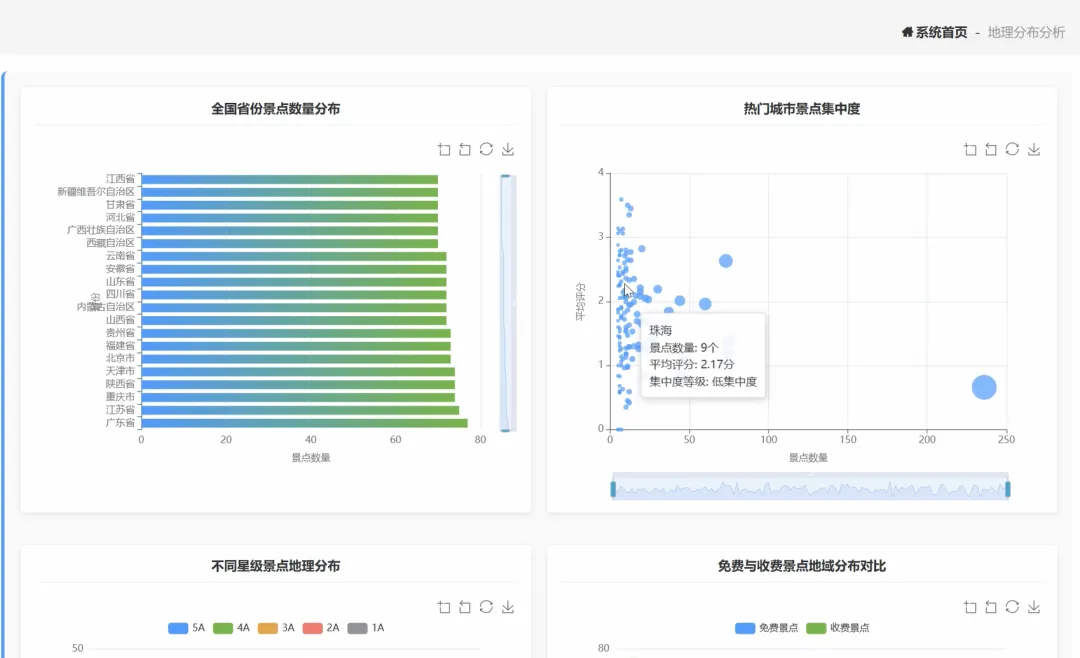
from pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.clustering import KMeansspark = SparkSession.builder.appName("TourismAnalysis").getOrCreate()def analyze_province_distribution(df): """ 核心功能1:全国省份景点数量分布分析 业务处理:从省/市/区字段提取省份,分组统计每个省份的景点总数,并按数量降序排列。 """ # 使用split函数从'省/市/区'字段中提取省份信息,通常以'·'分隔 province_df = df.withColumn('province', F.split(F.col('省/市/区'), '·').getItem(0)) # 按省份进行分组,并统计每个省份的景点数量 province_count_df = province_df.groupBy('province').agg(F.count('*').alias('spot_count')) # 按景点数量降序排序,方便查看旅游资源最丰富的省份 sorted_province_df = province_count_df.orderBy(F.col('spot_count').desc()) # 展示分析结果 print("全国省份景点数量分布分析结果:") sorted_province_df.show() # 返回结果DataFrame,以便后续处理或保存 return sorted_province_dfdef find_high_value_spots(df, score_threshold=4.5, price_threshold=100): """ 核心功能2:高评分低价格优质景点识别分析 业务处理:筛选出用户评分高于阈值且门票价格低于阈值的景点,按评分和销量排序。 """ # 筛选评分高于阈值且价格在0到指定阈值之间的景点 # 同时过滤掉评分为0的无效数据 high_value_df = df.filter((F.col('评分') > score_threshold) & (F.col('价格') > 0) & (F.col('价格') < price_threshold) & (F.col('评分') != 0)) # 选择需要展示给用户的字段 result_df = high_value_df.select('名称', '城市', '评分', '价格', '销量', '简介') # 首先按评分降序排序,评分相同则按销量降序排序,确保最优质的景点排在前面 final_df = result_df.orderBy(F.col('评分').desc(), F.col('销量').desc()) # 展示分析结果,默认前20条 print("高评分低价格优质景点识别结果:") final_df.show() # 返回结果DataFrame return final_dfdef cluster_high_rating_spots(df, k=5): """ 核心功能3:高星级景点空间聚类分析 业务处理:筛选高星级景点,提取其经纬度坐标,使用K-Means算法进行空间聚类。 """ # 筛选星级为5A或4A的高质量景点 high_rating_df = df.filter(F.col('星级').isin(['5A', '4A'])) # 从'坐标'字段中拆分出经度和纬度,并转换为Double类型 # 坐标格式为"经度,纬度" parsed_df = high_rating_df.withColumn('longitude', F.split(F.col('坐标'), ',').getItem(0).cast('double')) \ .withColumn('latitude', F.split(F.col('坐标'), ',').getItem(1).cast('double')) # 使用VectorAssembler将经度和纬度两个特征列合并成一个特征向量 assembler = VectorAssembler(inputCols=['longitude', 'latitude'], outputCol='features') assembled_data = assembler.transform(parsed_df) # 创建K-Means模型实例,设置聚类数量k kmeans = KMeans(featuresCol='features', predictionCol='cluster', k=k) # 训练K-Means模型 model = kmeans.fit(assembled_data) # 使用训练好的模型对数据进行转换,得到每个景点所属的聚类标签 clustered_df = model.transform(assembled_data) # 选择原始信息和聚类结果进行展示 result_df = clustered_df.select('名称', '星级', '城市', 'longitude', 'latitude', 'cluster') # 展示聚类结果 print("高星级景点空间聚类分析结果:") result_df.show(50) # 返回带有聚类标签的DataFrame return result_df

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
