说真的,咱们做开发的,谁还没被PDF折磨过?
以前我接手过一个项目,要从几千份简历里抓取关键信息。当时傻乎乎地用了某款知名的库,结果呢?慢得像老牛拉破车,稍微遇到个图片多点的PDF,程序直接卡死。那时候我就在想,这世界上难道就没有一个既轻量、又快、还能处理各种乱七八糟格式的工具吗?
后来,我遇到了PyMuPDF。用完之后我只有一个感觉:相见恨晚,真的。
这玩意儿到底快在哪?
很多朋友可能不知道,PyMuPDF 底层其实是 C 语言写的 MuPDF。MuPDF 是什么概念?那是专门给低功耗设备设计的渲染引擎,主打的就是一个“快”和“稳”。
我做过测试,同样是提取 100 页文档的文本,PyMuPDF 的速度往往是其他库的几倍甚至十几倍。它不是那种笨重的工具,它就像一把手术刀,精准、锋利。你只需要pip install PyMuPDF,不需要安装什么乱七八糟的系统依赖,直接就能开搞。
它可不止能搞定 PDF
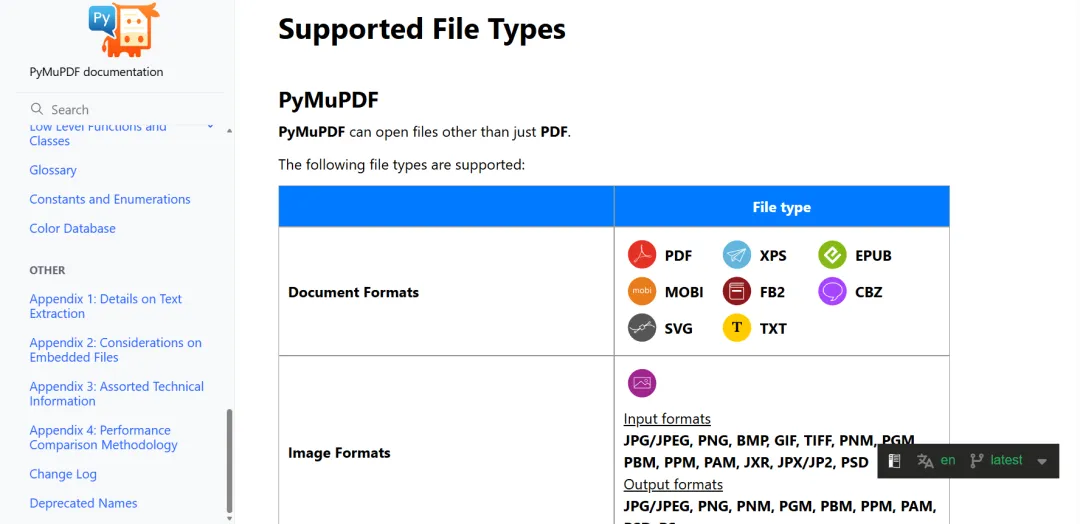
大家看名字,可能觉得它只能处理 PDF。其实这是最大的误解!
这哥们儿简直是个“杂食动物”。除了 PDF,什么 XPS、EPUB(电子书)、MOBI,甚至连 CBZ 漫画格式它都能吃得下。最让我惊喜的是,它现在连Office 三件套(DOCX, XLSX, PPTX)都能处理了(Pro版本)。
甚至,你随手写个.txt文本,或者一段 Python 代码,它都能直接当成文档打开。你敢信?
importpymupdf
没错,直接把代码文件当文档读,还能搜索、渲染doc = pymupdf.open("my_script.py", filetype="txt")
实战:三行代码的魔力
咱们不玩虚的,直接看代码。很多人问怎么提取文字,看好了,就这么简单:
importpymupdfdoc = pymupdf.open("那个折磨你的文件.pdf")forpageindoc:text = page.get_text()print(text)
搞定,文本出来了
就这几行,不管是 UTF-8 编码还是各种奇怪的字符,它处理得都非常顺滑。而且,它还有个“黑科技”:文件类型自动识别。
有时候我们下载的文件后缀名是错的,比如明明是 PDF 却没加后缀,或者后缀被改成.dat。换成别的库可能就报错了,但 PyMuPDF 聪明得很,它会去读文件头的二进制数据,自己判断这到底是个啥。这种“鲁棒性”,真的省了开发者太多心。
那些让人拍案叫绝的细节
我最喜欢 PyMuPDF 的一点是它的“全能性”。
- OCR 识别:它集成了 Tesseract。如果你的 PDF 是那种扫描件,全是图片,没关系,它能直接调用 OCR 把文字抠出来。
- 远程文件直接读:你不需要先把 PDF 下载到本地磁盘。配合 requests,直接把内存里的二进制流塞给它,它就能读。这在写爬虫或者做云端微服务的时候,简直是救命的功能,省去了频繁读写硬盘的开销。
- 渲染能力:如果你想把 PDF 转成图片(比如做预览图),它的渲染效果真的没话说,字体不虚,颜色不偏。
我的一点私货建议
虽然 PyMuPDF 很强,但我也得提醒大家一句:它用的是 AGPL 协议。这意味着如果你是做开源项目或者内部工具,随便撸;但如果你是要做商业闭源软件,记得去瞅一眼他们的商业授权。
另外,如果你处理的文件特别巨大(比如几百 MB 的那种),建议配合内存管理来用。虽然它已经优化得很好了,但毕竟内存不是无限的,对吧?
总结一下
如果你还在为 PDF 提取慢、格式乱、无法处理 Office 文档而头秃,听我的,赶紧试试 PyMuPDF。它不需要你有多牛的算法基础,只要你会点 Python,它就能让你在处理文档这件事上,体验到什么叫“降维打击”。
别再用那些老掉牙的库了,时代变了,朋友们!
项目地址:https://github.com/pymupdf/PyMuPDF
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
