一、Linux 的中断策略
1.1 核心概念:PSTATE中的DAIF
在深入探讨“中断抢占”之前,我们需要先回到 ARM Architecture Reference Manual,看懂控制 CPU 控制中断的四个开关——PSTATE 寄存器中的 DAIF 域。
这四个位决定了 CPU 当前是否响应特定的异常事件:
- • D (Debug): 调试异常掩码。如果设为 1,Breakpoint 和 Watchpoint 将被忽略。
- • A (SError): 系统错误掩码。处理异步外部中断(Asynchronous External Abort),通常代表严重的硬件故障。
- • I (IRQ): 普通中断掩码。控制定时器、网络、外设等常规中断的响应。
- • F (FIQ): 快速中断掩码。在 Linux 中通常用于 TrustZone,或者作为伪 NMI 使用。
当这些位为 1 (Masked) 时,表示为中断屏蔽;只有为 0 (Unmasked) 时,CPU 才会去处理异常。
由于硬件操作,DAIF 默认被屏蔽。那么,这是否意味着 Arm64 不支持中断嵌套呢?
让我们看看官方文档的说明:
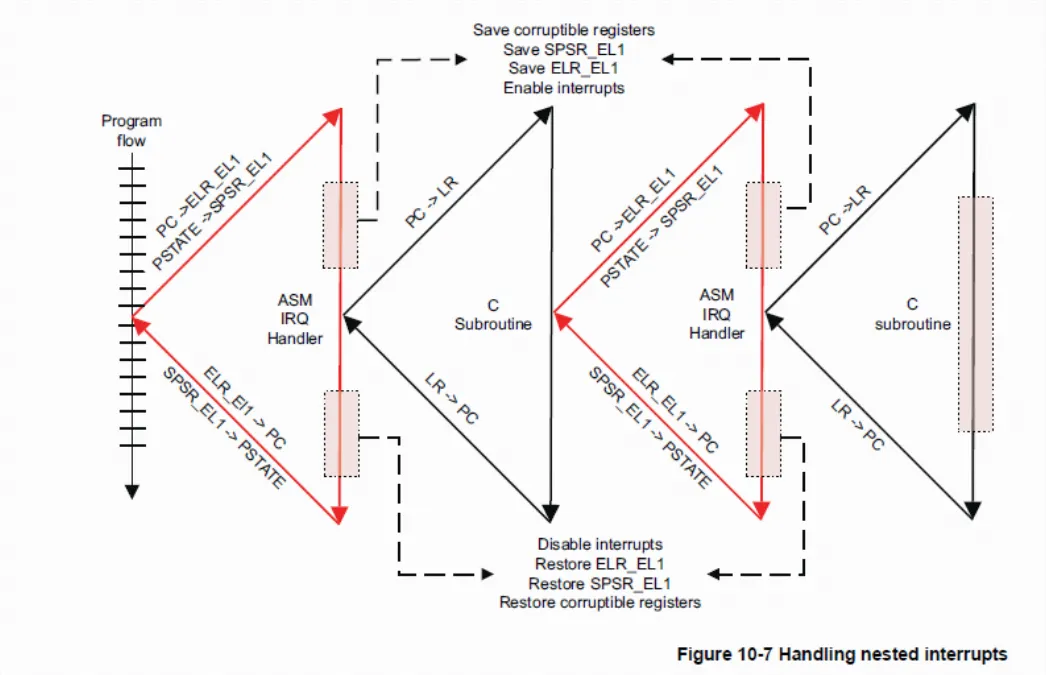
If software is to support nested exceptions, for example, to allow a higher priority exception to interrupt the handling of a lower priority exception, then software needs to explicitly re-enable interrupts. After corruptible registers have been stacked, exceptions can be nested.
换句话说,要在 Arm64 下实现抢占,需要通过软件解除 DAIF 屏蔽。
1.2 Linux的处理策略
在 ARM64 架构的 Linux 世界中,当一个 IRQ 发生时,硬件逻辑会自动将 PSTATE.DAIF 全部置为 1。这意味着,在进入中断向量表的那一刻,CPU 处于一种“绝对原子”的状态——不响应调试、不理会硬件报错、更不会被其他中断打断。然而,Linux 内核并非一直保持这种全封闭状态。在 entry.S 的处理逻辑中,内核会显式调用 enable_da_f。
el1_irq: kernel_entry 1 enable_da_f
只清除了 D、A 和 F的掩码,唯独保留了 PSTATE.I = 1。这意味着绝对禁止另一个 IRQ 进来抢占当前的 CPU 资源。
为了更好的理解,尝试用Qemu来复现这个环境,在 Qemu 中添加一个GPIO控制器,通过 QMP 给 Linux 中注入 GPIO 中断,中断服务函数打印出 DAIF 的值。
// Linux上的测试程序,只贴出关键部分。static irqreturn_t daif_spy_isr(int irq, void *dev_id){ unsigned long daif; asm volatile("mrs %0, daif" : "=r"(daif)); pr_info("[Target Verified] DAIF: 0x%lx \n", daif); pl061_write(PL061_ICR, gpio_mask); return IRQ_HANDLED;}
可以看到终端输出
[Target Verified] DAIF: 0x80
DAIF = 0x80 → 只有 I=1(IRQ 屏蔽),D/A/F 已被清掉。
接下来尝试把el1_irq 中的enable_da_f 注释。
终端输出:
[Target Verified] DAIF: 0x3c0
DAIF = 0x3c0 → D/A/I/F 全部为 1(全部屏蔽)
那么Linux为什么要这么设计只禁用IRQ?
ARM64 的内核栈通常只有 16KB,如果允许中断嵌套,每来一个中断就要压一次栈。如果出现了中断风暴,就很容易爆栈。
支持中断嵌套也会引入额外的重入问题。中断 A 拿了一把锁,被中断 B 打断,中断 B 又要去拿同一把锁,这就死锁了。
Linux 内核社区在极速响应和系统稳定之间,毫不犹豫地选择了后者。对于服务器而言,晚 10 微秒响应网卡中断是可以接受的,但内核栈溢出导致宕机是不可接受的。
而需要enable_da_f 的原因是因为需要及时响应高优先级异常(Debug/SError/FIQ),其场景有:
- • 内核调试/跟踪:kgdb、kprobe、breakpoint、single-step、ptrace 等需要在任意时刻插入。
- • 如果在 IRQ 里把 D 也屏蔽,会导致调试点失效或延迟,影响定位严重 bug。
- • 硬件错误上报:ECC、总线/内存子系统异步错误、RAS 事件。
- • 这类错误往往“时间敏感”,延迟处理可能导致错误扩散或丢失上下文。
- • firmware‑first 系统尤其希望尽快进入 EL3/firmware 处理。
- • 更高优先级的快速中断:某些平台把看门狗、关键计时器、性能/安全相关事件放在 FIQ。
- • 如果在 IRQ 中屏蔽 FIQ,可能导致看门狗超时或关键定时事件延迟。
我们前面讨论的 DAIF 都是异步异常。有些读者可能会问,既然我们都在 IRQ 里了,那由代码逻辑直接触发的同步异常(如访问空指针、缺页)会被屏蔽吗?答案是:不会,而且是致命的。即使 DAIF 全关,一旦触发缺页,CPU 依然会跳转到 el1_sync。但因为此时内核处于原子上下文(Atomic Context),无法睡眠等待磁盘 I/O,内核会直接由 OOPS 转为 Panic。
既然Linux 对中断嵌套的态度已经很明确了:不支持。那如果尝试在 Linux 中支持中断嵌套,会对中断延迟性能提高还是降低呢?
二、打破禁区
接下来,我们开始进行这个实验——在 GPIO 中断上下文中解除 I 位屏蔽,然后触发另一个中断,观察是否能实现中断抢占。
测试方法是在 Qemu 中添加两个 GPIO chip。由于 Linux 在 GIC 驱动中将所有 SPI/PPI 的默认优先级设为 0xa0,外设之间默认没有优先级区分。我们通过设置 GIC 的 IPRIORITYR 寄存器,让 GPIO B 的优先级高于 GPIO A。
在 GPIO A 的 ISR 中加入延时窗口,然后触发 GPIO B 中断,这样就能观察到中断抢占现象。
终端输入的日志为:
[ 194.630234] [Target Verified] DAIF: 0x80 (I-bit is SET) depth=1[ 194.632865] daif_spy: HPPIR=0x00000005 iter=0[ 194.633854] daif_spy: DAIF after enable=0x0[ 194.634426] daif_spy: GIC PMR=0xf0 BPR=0x03 HPPIR=0x00000005 IGRPEN1=0x01 CTLR=0x8c00[ 195.351570] daif_spy_b: first hit (depth=1) ——> **执行了GPIO B的ISR**[ 196.635751] daif_spy: preempt_hits=1 ——> 回到**GPIO A的ISR**[ 196.636346] [Target Verified] DAIF: 0x80 (I-bit is SET)
时间轴参考如下:
t0: GPIO_A 触发 (IRQ_A / daif_spy为 GPIO_A 中断服务函数) ├─ 进入 IRQ_A │ irq_depth: 0 → 1 │ preempt_hits: 0 │ DAIF = 0x80 (I-bit set) │ │ local_irq_enable() │ DAIF = 0x0 (I-bit clear) │ busy_us 延迟窗口 │ t1: GPIO_B 触发 (IRQ_B / daif_spy_b 为 GPIO_B 中断服务函数) ├─ 进入 IRQ_B(抢占 IRQ_A) │ irq_depth: 仍为 1 (B ISR 读取 depth=1) │ preempt_hits: 0 → 1 (在 B ISR 内检测到 depth>0) │ IRQ_B 处理完成 │ └─ 返回 IRQ_A IRQ_A 收尾: local_irq_disable() clear IRQ_A 打印 preempt_hits=1 irq_depth: 1 → 0
我们通过挂载 Tracepoint 从第三方角度观察中断抢占:
echo 0 > /sys/kernel/tracing/tracing_on echo > /sys/kernel/tracing/trace echo 1 > /sys/kernel/tracing/events/irq/irq_handler_entry/enable echo 1 > /sys/kernel/tracing/events/irq/irq_handler_exit/enable echo 1 > /sys/kernel/tracing/tracing_on
模拟注入 GPIO 中断后查看 Trace 日志:
<idle>-0 [000] d.h. 194.629827: irq_handler_entry: irq=49 name=daif_spy<idle>-0 [000] d.h. 195.351225: irq_handler_entry: irq=50 name=daif_spy_b<idle>-0 [000] d.h. 195.352257: irq_handler_exit: irq=50 ret=handled<idle>-0 [000] dNh. 196.636168: irq_handler_exit: irq=49 ret=handled
从日志中可以看到:
CPU Timeline:|----------------- IRQ A (GPIO_A) -----------------| [Unmask I] | | /--- IRQ B (GPIO_B) ---\ | | | +-->| Preempts A! | | | \----------------------/ | [Mask I]|--------------------------------------------------|
这是标准的嵌套/抢占模式,说明 GPIO_B 成功在 GPIO_A 的中断服务函数内完成了抢占。
总结
我们从技术上验证了 Linux 可以通过简单修改代码来实现中断抢占,但真的有必要这么做吗?
对于通用 Linux,不推荐。风险(栈溢出、死锁)远大于收益。
对于特定嵌入式场景(已知中断源有限、栈可控),这是一种极端优化手段,但更推荐使用中断线程化。中断线程化通过将中断处理程序分为上半部和下半部,在保持系统稳定性的同时,也能提供足够的实时性保证。
此外,对于需要极低延迟的场景,可以考虑使用 PREEMPT_RT 补丁或者专门的实时操作系统。通过这次死磕,我们证明了:规则是可以被打破的,但前提是你必须完全理解规则存在的意义。 Linux 关闭中断抢占不是因为‘做不到’,而是为了换取系统全局的稳定性。
If software is to support nested exceptions, for example, to allow a higher priority exception to interrupt the handling of a lower priority exception, then software needs to explicitly re-enable interrupts. After corruptible registers have been stacked, exceptions can be nested.
换句话说,要在 Arm64 下实现抢占,需要通过软件解除 DAIF 屏蔽。
1.2 Linux的处理策略
在 ARM64 架构的 Linux 世界中,当一个 IRQ 发生时,硬件逻辑会自动将 PSTATE.DAIF 全部置为 1。这意味着,在进入中断向量表的那一刻,CPU 处于一种“绝对原子”的状态——不响应调试、不理会硬件报错、更不会被其他中断打断。然而,Linux 内核并非一直保持这种全封闭状态。在 entry.S 的处理逻辑中,内核会显式调用 enable_da_f。
el1_irq: kernel_entry 1 enable_da_f
只清除了 D、A 和 F的掩码,唯独保留了 PSTATE.I = 1。这意味着绝对禁止另一个 IRQ 进来抢占当前的 CPU 资源。
为了更好的理解,尝试用Qemu来复现这个环境,在 Qemu 中添加一个GPIO控制器,通过 QMP 给 Linux 中注入 GPIO 中断,中断服务函数打印出 DAIF 的值。
// Linux上的测试程序,只贴出关键部分。static irqreturn_t daif_spy_isr(int irq, void *dev_id){ unsigned long daif; asm volatile("mrs %0, daif" : "=r"(daif)); pr_info("[Target Verified] DAIF: 0x%lx \n", daif); pl061_write(PL061_ICR, gpio_mask); return IRQ_HANDLED;}
可以看到终端输出
[Target Verified] DAIF: 0x80
DAIF = 0x80 → 只有 I=1(IRQ 屏蔽),D/A/F 已被清掉。
接下来尝试把el1_irq 中的enable_da_f 注释。
终端输出:
[Target Verified] DAIF: 0x3c0
DAIF = 0x3c0 → D/A/I/F 全部为 1(全部屏蔽)
那么Linux为什么要这么设计只禁用IRQ?
ARM64 的内核栈通常只有 16KB,如果允许中断嵌套,每来一个中断就要压一次栈。如果出现了中断风暴,就很容易爆栈。
支持中断嵌套也会引入额外的重入问题。中断 A 拿了一把锁,被中断 B 打断,中断 B 又要去拿同一把锁,这就死锁了。
Linux 内核社区在极速响应和系统稳定之间,毫不犹豫地选择了后者。对于服务器而言,晚 10 微秒响应网卡中断是可以接受的,但内核栈溢出导致宕机是不可接受的。
而需要enable_da_f 的原因是因为需要及时响应高优先级异常(Debug/SError/FIQ),其场景有:
- • 内核调试/跟踪:kgdb、kprobe、breakpoint、single-step、ptrace 等需要在任意时刻插入。
- • 如果在 IRQ 里把 D 也屏蔽,会导致调试点失效或延迟,影响定位严重 bug。
- • 硬件错误上报:ECC、总线/内存子系统异步错误、RAS 事件。
- • 这类错误往往“时间敏感”,延迟处理可能导致错误扩散或丢失上下文。
- • firmware‑first 系统尤其希望尽快进入 EL3/firmware 处理。
- • 更高优先级的快速中断:某些平台把看门狗、关键计时器、性能/安全相关事件放在 FIQ。
- • 如果在 IRQ 中屏蔽 FIQ,可能导致看门狗超时或关键定时事件延迟。
我们前面讨论的 DAIF 都是异步异常。有些读者可能会问,既然我们都在 IRQ 里了,那由代码逻辑直接触发的同步异常(如访问空指针、缺页)会被屏蔽吗?答案是:不会,而且是致命的。即使 DAIF 全关,一旦触发缺页,CPU 依然会跳转到 el1_sync。但因为此时内核处于原子上下文(Atomic Context),无法睡眠等待磁盘 I/O,内核会直接由 OOPS 转为 Panic。
既然Linux 对中断嵌套的态度已经很明确了:不支持。那如果尝试在 Linux 中支持中断嵌套,会对中断延迟性能提高还是降低呢?
二、打破禁区
接下来,我们开始进行这个实验——在 GPIO 中断上下文中解除 I 位屏蔽,然后触发另一个中断,观察是否能实现中断抢占。
测试方法是在 Qemu 中添加两个 GPIO chip。由于 Linux 在 GIC 驱动中将所有 SPI/PPI 的默认优先级设为 0xa0,外设之间默认没有优先级区分。我们通过设置 GIC 的 IPRIORITYR 寄存器,让 GPIO B 的优先级高于 GPIO A。
在 GPIO A 的 ISR 中加入延时窗口,然后触发 GPIO B 中断,这样就能观察到中断抢占现象。
终端输入的日志为:
[ 194.630234] [Target Verified] DAIF: 0x80 (I-bit is SET) depth=1[ 194.632865] daif_spy: HPPIR=0x00000005 iter=0[ 194.633854] daif_spy: DAIF after enable=0x0[ 194.634426] daif_spy: GIC PMR=0xf0 BPR=0x03 HPPIR=0x00000005 IGRPEN1=0x01 CTLR=0x8c00[ 195.351570] daif_spy_b: first hit (depth=1) ——> **执行了GPIO B的ISR**[ 196.635751] daif_spy: preempt_hits=1 ——> 回到**GPIO A的ISR**[ 196.636346] [Target Verified] DAIF: 0x80 (I-bit is SET)
时间轴参考如下:
t0: GPIO_A 触发 (IRQ_A / daif_spy为 GPIO_A 中断服务函数) ├─ 进入 IRQ_A │ irq_depth: 0 → 1 │ preempt_hits: 0 │ DAIF = 0x80 (I-bit set) │ │ local_irq_enable() │ DAIF = 0x0 (I-bit clear) │ busy_us 延迟窗口 │ t1: GPIO_B 触发 (IRQ_B / daif_spy_b 为 GPIO_B 中断服务函数) ├─ 进入 IRQ_B(抢占 IRQ_A) │ irq_depth: 仍为 1 (B ISR 读取 depth=1) │ preempt_hits: 0 → 1 (在 B ISR 内检测到 depth>0) │ IRQ_B 处理完成 │ └─ 返回 IRQ_A IRQ_A 收尾: local_irq_disable() clear IRQ_A 打印 preempt_hits=1 irq_depth: 1 → 0
我们通过挂载 Tracepoint 从第三方角度观察中断抢占:
echo 0 > /sys/kernel/tracing/tracing_on echo > /sys/kernel/tracing/trace echo 1 > /sys/kernel/tracing/events/irq/irq_handler_entry/enable echo 1 > /sys/kernel/tracing/events/irq/irq_handler_exit/enable echo 1 > /sys/kernel/tracing/tracing_on
模拟注入 GPIO 中断后查看 Trace 日志:
<idle>-0 [000] d.h. 194.629827: irq_handler_entry: irq=49 name=daif_spy<idle>-0 [000] d.h. 195.351225: irq_handler_entry: irq=50 name=daif_spy_b<idle>-0 [000] d.h. 195.352257: irq_handler_exit: irq=50 ret=handled<idle>-0 [000] dNh. 196.636168: irq_handler_exit: irq=49 ret=handled
从日志中可以看到:
CPU Timeline:|----------------- IRQ A (GPIO_A) -----------------| [Unmask I] | | /--- IRQ B (GPIO_B) ---\ | | | +-->| Preempts A! | | | \----------------------/ | [Mask I]|--------------------------------------------------|
这是标准的嵌套/抢占模式,说明 GPIO_B 成功在 GPIO_A 的中断服务函数内完成了抢占。
三、总结
我们从技术上验证了 Linux 可以通过简单修改代码来实现中断抢占,但真的有必要这么做吗?
对于通用 Linux,不推荐。风险(栈溢出、死锁)远大于收益。
对于特定嵌入式场景(已知中断源有限、栈可控),这是一种极端优化手段,但更推荐使用中断线程化。中断线程化通过将中断处理程序分为上半部和下半部,在保持系统稳定性的同时,也能提供足够的实时性保证。
此外,对于需要极低延迟的场景,可以考虑使用 PREEMPT_RT 补丁或者专门的实时操作系统。通过这次死磕,我们证明了:规则是可以被打破的,但前提是你必须完全理解规则存在的意义。 Linux 关闭中断抢占不是因为‘做不到’,而是为了换取系统全局的稳定性。


