Coze高阶玩法:Prompt美学与代码逻辑,解锁“图文转动画”新姿势 | Day37
- 2026-07-06 10:42:22
🚀 60天挑战119个Coze工作流 | Day 37
在短视频领域,知识付费和育儿赛道始终占据着巨大的流量池。传统的书单视频往往停留在“PPT翻页”水平,而育儿视频则多依赖真人实拍,制作门槛高且周期长。
今天,我们将解锁两个不仅有“颜”更有“脑”的高阶工作流:
V31 短视频书单 (Book to Video):用极致的 Prompt 审美,将书名一键转化为治愈系风景解说视频,让知识以最美的样子呈现。 V33 育儿故事动画 (Parenting Animation):利用角色扮演与图生视频技术,批量生产“动态绘本”,用 AI 讲好每一个育儿冲突故事。
当前进度:80/119[▓▓▓▓▓▓▓▓▓▓▓░░░░] 67%
💡 省流版:文末直接获取完整 DSL 源码 + 核心提示词。
01. 📖 V31:短视频书单——用审美重塑知识传播
核心价值:市面上的书单号千篇一律,V31 的破局点在于“审美降维打击”。它摒弃了枯燥的剧情复述,而是通过 System Prompt 挖掘书名背后的哲学意境,配合 Ansel Adams 风格的黑白/治愈系摄影画面,将“卖书”变成了“卖意境”。
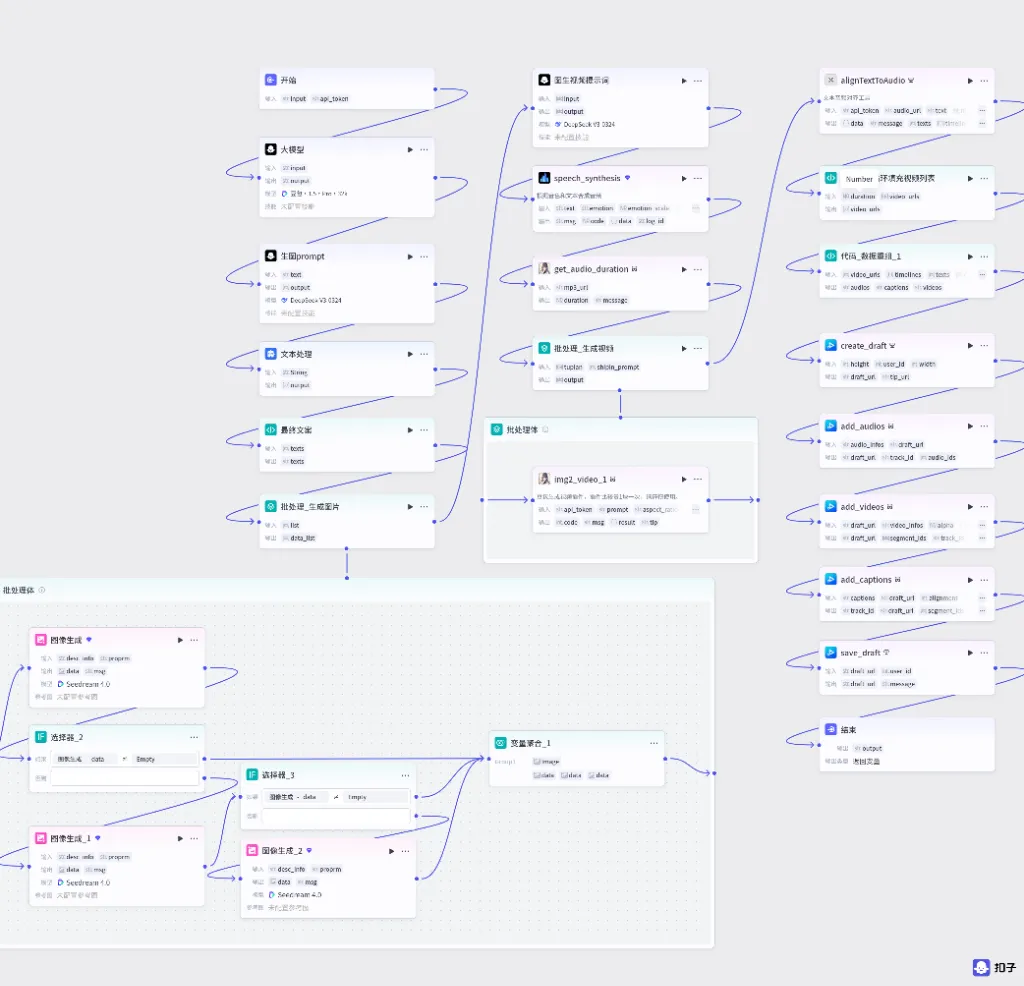
工作流程:书名输入 → 哲理文案生成 → 意象提取生成 Prompt → 循环生图 → 音画同步合成 → 剪映草稿
🔧 阵法布局
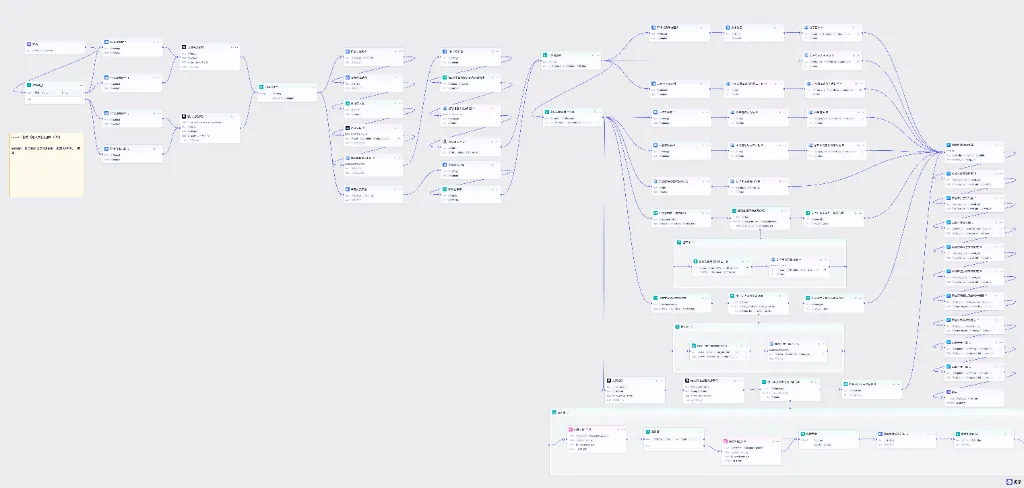
💡 工作流说明:
输入参数: input(书籍名称+作者) 和wenan(可选的口播文案)核心流程:开始节点 → 数据处理 → 文案生成/聚合 → 选择器判断 → 视觉脚本转化 → 批量生图 → 视频合成 → 剪映草稿 关键节点:选择器用于判断是否已有文案,变量聚合用于统一两个分支的输出
步骤 1.0:入参配置 (开始节点)
配置工作流的启动参数,这里我们需要接收用户输入的主题和可选的口播文案。
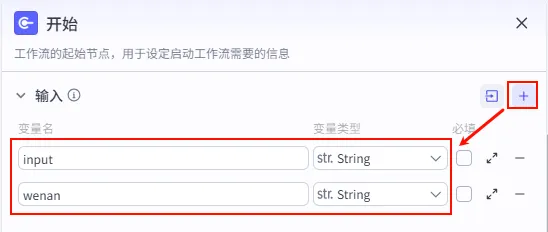
input (String): 书籍主题/书名 (如 "《百年孤独》" / "《活着》"),非必填。 wenan (String): 口播文案 (如果已有现成文案,可直接输入,跳过后续生成步骤),非必填。
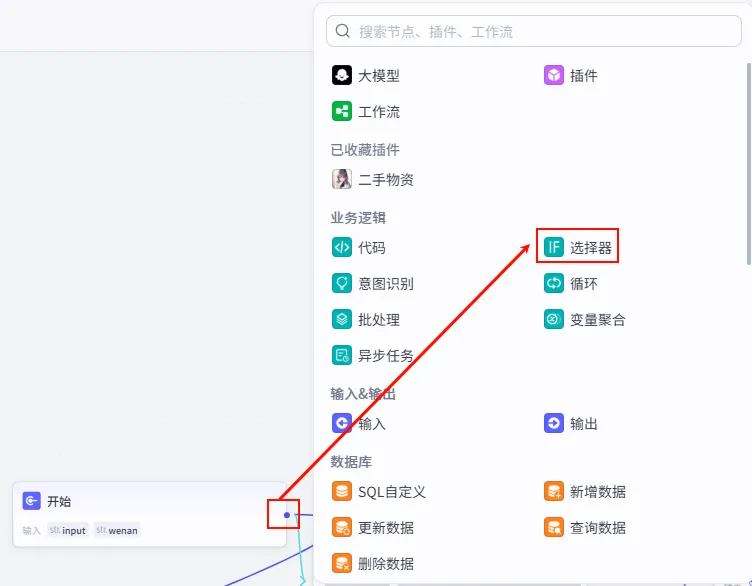
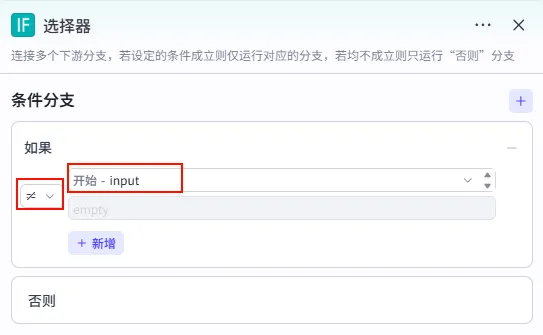
步骤 1.1:逻辑分流 (选择器)
为了提高灵活性,我们增加一个判断逻辑:如果用户没有输入口播文案 (wenan 为空),则让 AI 自动生成;如果输入了文案,则直接使用,跳过生成步骤。
操作步骤:点击 开始节点后的 + 号,在业务逻辑中选择 选择器 (IF 选择器)。
配置要点:
若不为空 (True) -> 同时运行 开场口播文字和开场口播文字_1(为大模型准备 Prompt)。若为空 (False) -> 同时运行 开场口播文字_2和开场口播文字_3(生成兜底/默认文案)。条件分支: 检查 开始.input(书籍主题) 是否 不为空。逻辑:
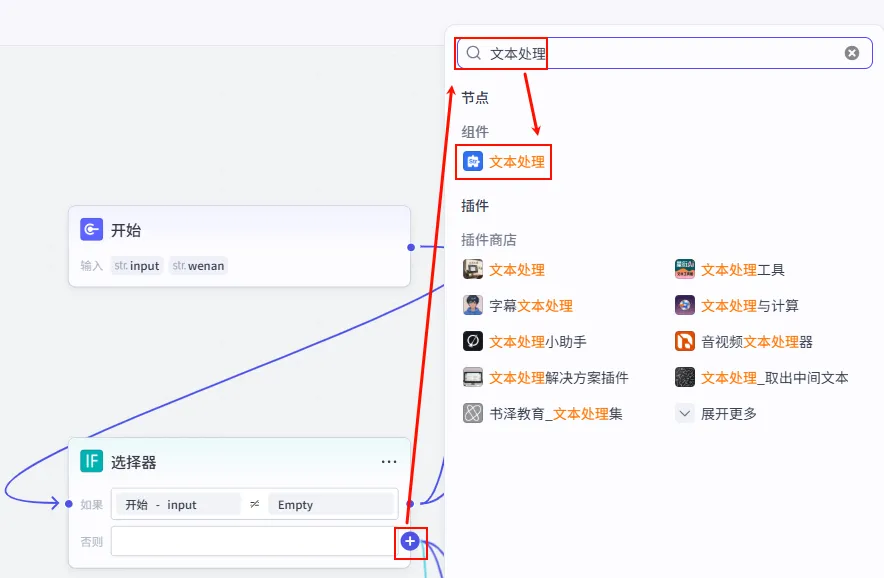
步骤 1.2:数据处理 (四路文本处理)
这里的设计非常巧妙:
有输入时:通过两个节点分别处理,拼接出给大模型的 Prompt。
无输入时:通过另外两个节点输出默认内容,并由 轻量级模型 (Doubao) 进行快速处理,既保证兜底又兼顾成本。
操作步骤:
点击 选择器的 否则 (Else) 分支后的 + 号,添加文本处理节点。命名为 开场口播文字_2:直接输出一份默认的高分书单列表。命名为 开场口播文字_3:输出默认开场白 "今天分享最治愈的书之一..."。连接:这两个节点 连接到后方的 客户文案拆分大模型节点 (见步骤 1.3.2),用于进一步拆解或优化文案。添加 开场口播文字:拼接 "今天我们要讲的是 {{input}}"。添加 开场口播文字_1:(配置辅助 Prompt 或其他必要信息)。连接:这两个节点均 连接到后续的大模型节点。 如果有主题 (True 分支): 如果无主题 (False 分支):
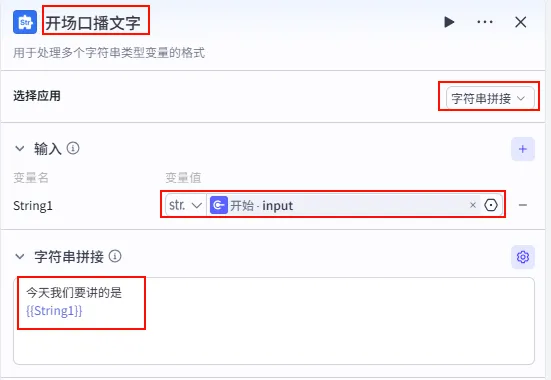
配置示例 ( 开场口播文字):输入: String1引用开始.input。模板: 今天我们要讲的是\n{{String1}}。
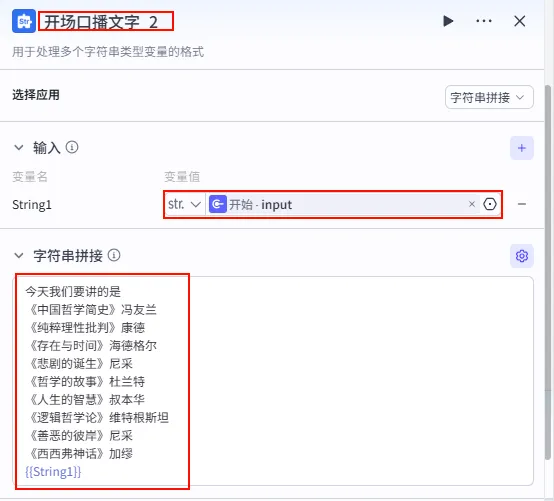
配置示例 ( 开场口播文字_2- 兜底书单):选择应用: 字符串拼接。输入: String1引用开始.input。模板: 今天我们要讲的是《中国哲学简史》冯友兰《纯粹理性批判》康德《存在与时间》海德格尔《悲剧的诞生》尼采《哲学的故事》杜兰特《人生的智慧》叔本华《逻辑哲学论》维特根斯坦《善恶的彼岸》尼采《西西弗神话》加缪{{String1}}目的: 当用户没输入时,自动推荐这些经典书籍。
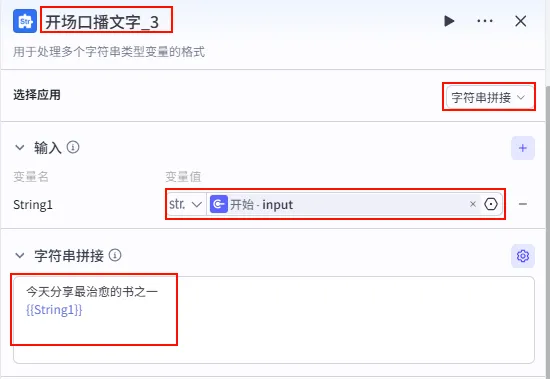
配置示例 ( 开场口播文字_3- 默认开场白):选择应用: 字符串拼接。输入: String1引用开始.input。模板: 今天分享最治愈的书之一{{String1}}目的: 为无主题输入的情况提供一个通用的开场白。
步骤 1.3:文案生成 (双轨制)
这里我们采用了双轨制生成策略:
True 分支 (有主题):使用 DeepSeek 生成深度哲理文案。 False 分支 (无主题/自定义):使用 Doubao (或其他模型) 处理默认或自定义文案。
1.3.1 哲理文案生成 (DeepSeek - True 分支)
当用户提供了书籍主题时,我们需要大模型来生成深度的哲理文案。
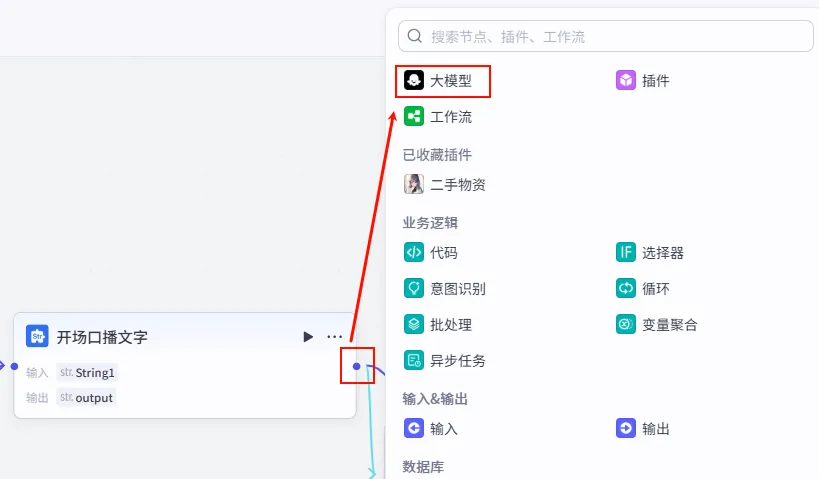
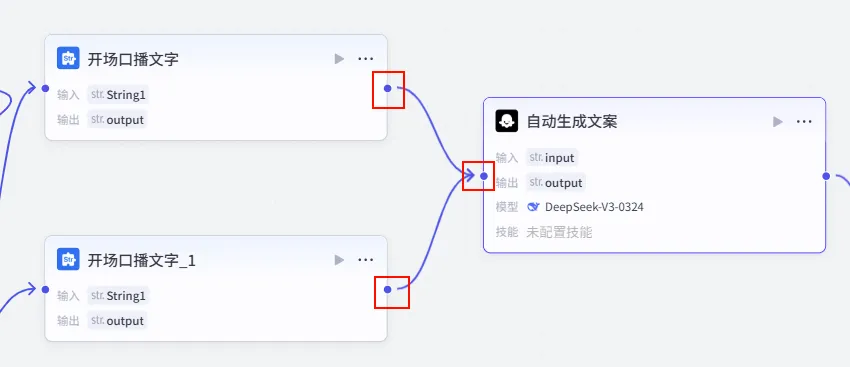
操作步骤:点击 开场口播文字节点后的 + 号,选择 大模型。连接配置:确保 开场口播文字和开场口播文字_1(True 分支) 的输出都连接到此节点。
配置要点: 节点名称: 自动生成文案。模型: DeepSeek-V3。输入变量: input引用 True 分支文本处理节点的输出。
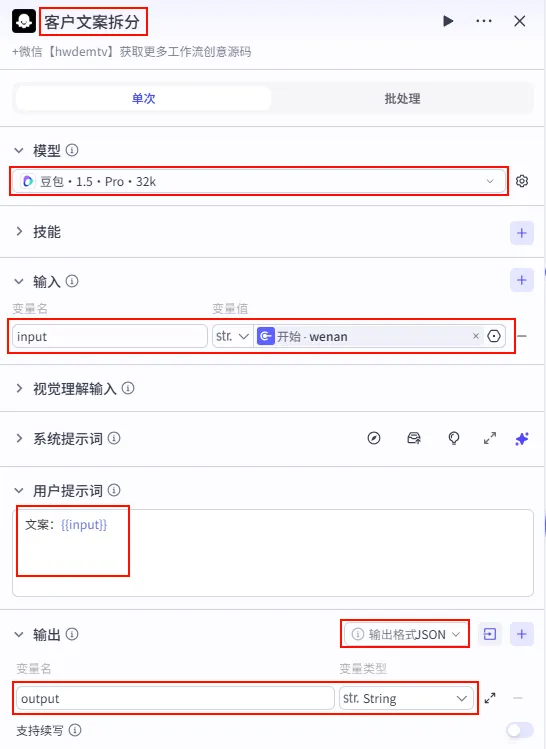
1.3.2 客户文案拆分 (Doubao - False 分支)
当走兜底逻辑时,我们需要另一个模型来处理默认推荐或用户直接输入的文案。
操作步骤:在 开场口播文字_2后添加 大模型 节点。连接配置:将 开场口播文字_2(兜底书单) 和开场口播文字_3(默认开场白) 同时连接到此节点。注意: 这是一个 多对一 的连接,确保两个文本处理节点的输出都能流向该大模型。
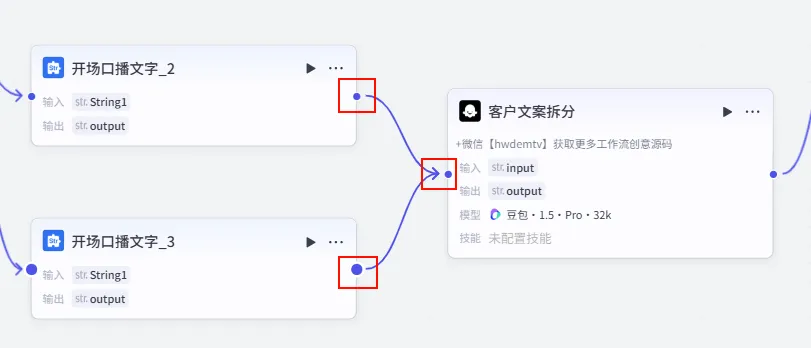
配置要点: 节点名称: 客户文案拆分。模型: 豆包·1.5·Pro·32k(处理速度快,适合结构化任务)。输入变量: input引用开始.wenan(直接处理用户输入的原始文案) 或 文本处理节点的输出。用户提示词: 文案:{{input}}。目的: 将输入的整段文案拆解为适合视频制作的片段。
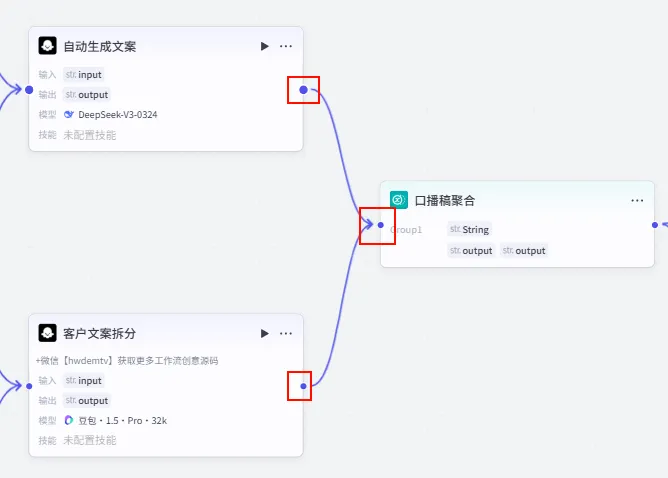
步骤 1.4:变量聚合 (汇聚双轨)
由于我们走了大模型双轨制,后续节点不知道该用哪个大模型的输出。因此,我们需要一个 变量聚合 节点,将两个大模型的输出 "合二为一"。
操作步骤: 添加 变量聚合 节点。 连接 自动生成文案(Step 1.3.1 的输出)。连接 客户文案拆分(Step 1.3.2 的输出)。
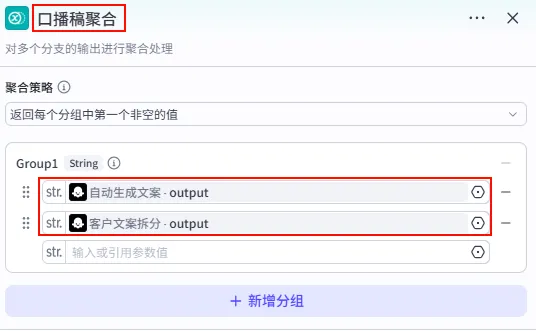
配置要点: 节点名称: 口播稿聚合。聚合策略: 返回每个分组中第一个非空的值(First Not Empty)。变量组 (Group1): 逻辑: 优先检测 自动生成文案,如果为空则使用客户文案拆分的值。引用 自动生成文案.output。引用 客户文案拆分.output。
步骤 1.5:文案组装 (文本处理)
我们将 "开场白" 和 "大模型生成的正文" 拼接在一起,形成完整的视频脚本。
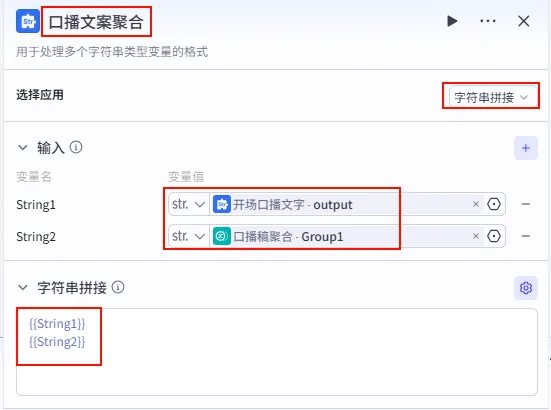
操作步骤:点击 口播稿聚合节点后的 + 号,选择 文本处理。
配置要点: String1: 引用开场口播文字.output(开场白)。String2: 引用口播稿聚合.Group1(正文)。节点名称: 口播文案聚合。选择应用: 字符串拼接。输入变量: 模板: {{String1}}{{String2}}。
步骤 1.6:文案格式处理 (文本处理)
为了便于后续的批量生图,我们需要将合并后的长文案拆分成一句句的短句。
操作步骤:点击 口播文案聚合节点后的 + 号,选择 文本处理。
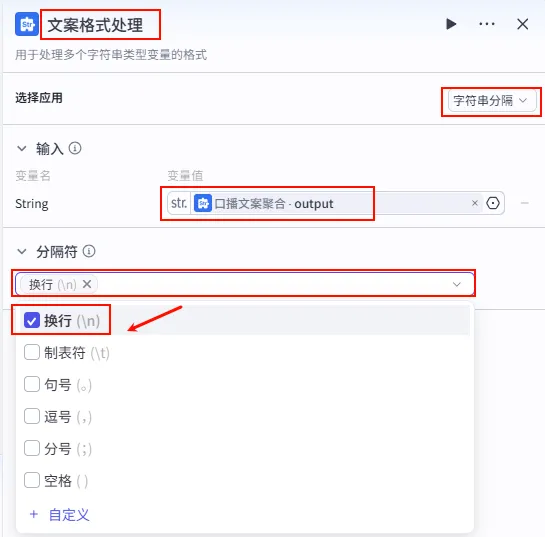
配置要点: 节点名称: 文案格式处理。选择应用: 字符串分隔。输入变量: String引用口播文案聚合.output。分隔符: 选择 换行 (\n)。输出变量: 这里会自动生成一个字符串数组 ( Array<String>),用于后续遍历。
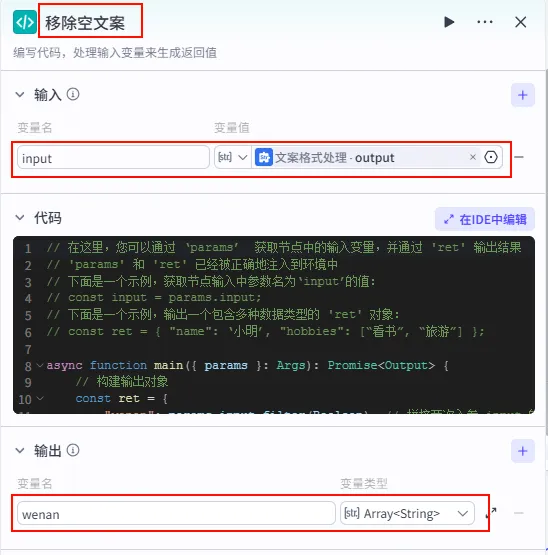
步骤 1.7:移除空文案 (代码)
我们将拆分后的文案数组进行清洗,去除可能产生的空行,确保每一条 Prompt 都是有效的。
操作步骤:点击 文案格式处理节点后的 + 号,选择 代码。
配置要点: input: 引用文案格式处理.output(Array<String>)。节点名称: 移除空文案。输入变量: 代码: (代码获取方式见文末)。 输出变量: wenan(Array<String>类型)。
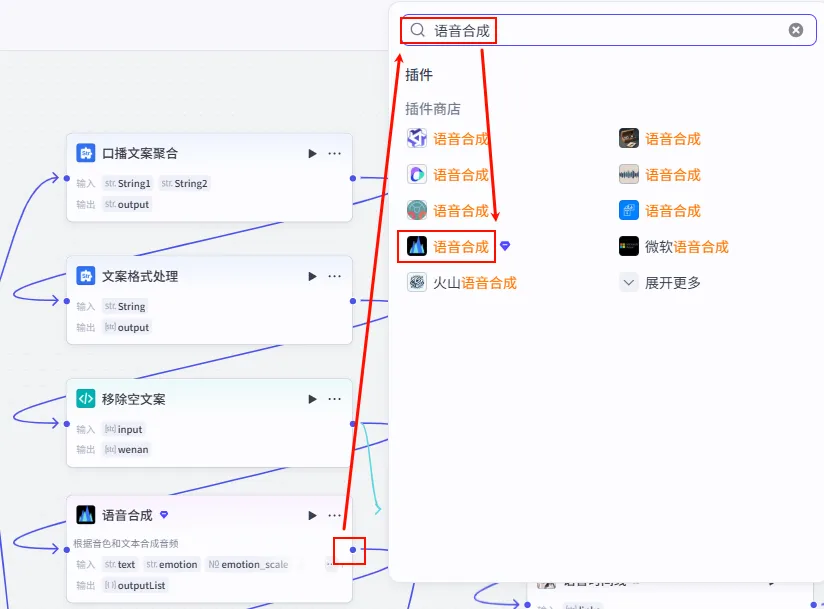
分支一:音频生成 (Audio Generation)
从这里开始,工作流分为两路并行处理。第一路负责生成视频的旁白音频和同步时间轴。
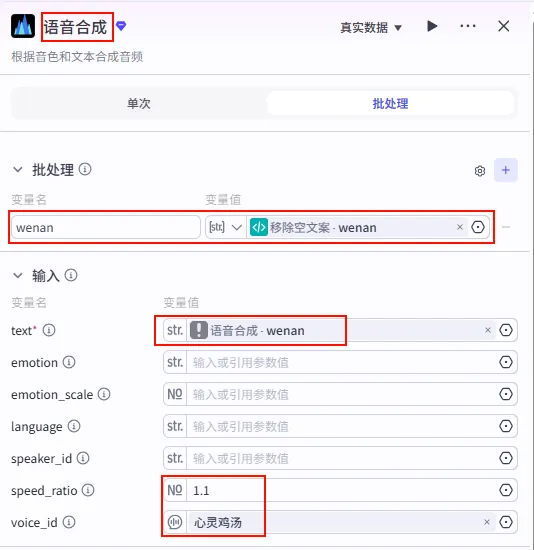
步骤 1.8:批量语音合成 (TTS)
为了实现音画同步,我们对拆解后的每一句文案分别生成音频,这样后期可以精确控制每一句话对应的画面时长。
操作步骤:点击 移除空文案节点后的 + 号,选择 语音合成 (TTS)。
配置要点: 语速 (speed_ratio): 1.1(稍快一点,适合短视频节奏)。音色 (voice_id): 心灵鸡汤(或根据书单风格选择)。节点名称: 语音合成。开启批处理: 点击节点右上角的设置图标,开启 批处理。 引用变量: wenan引用移除空文案.wenan(Array<String>)。输入 (text): 引用 语音合成.wenan(这里引用的是批处理中的单个元素)。参数设置:
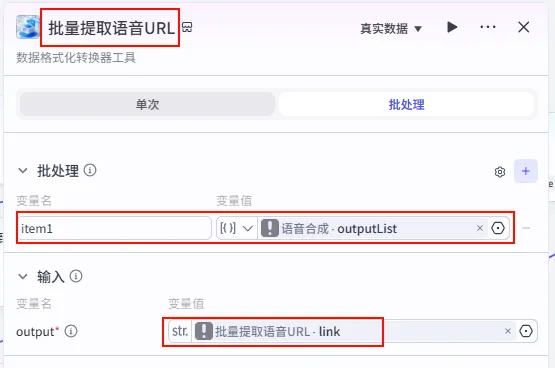
步骤 1.9:提取语音链接 (Plugin)
TTS 生成的结果包含很多冗余信息,我们需要通过插件提取出纯净的音频 URL 列表。
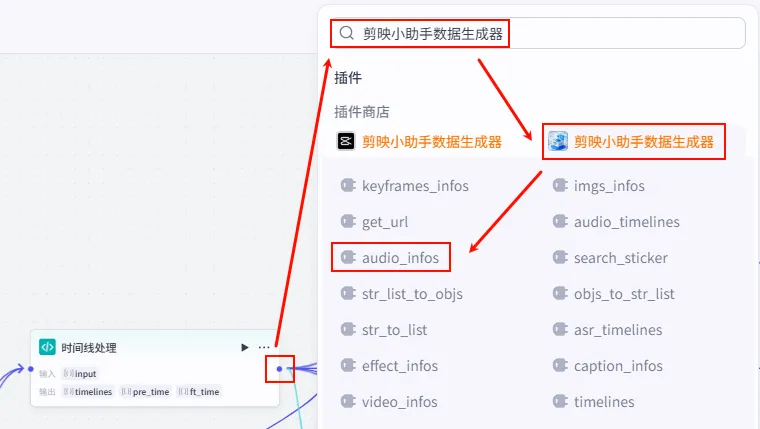
操作步骤:点击 语音合成节点后的 + 号,搜索 剪映小助手数据生成器 -> get_url。
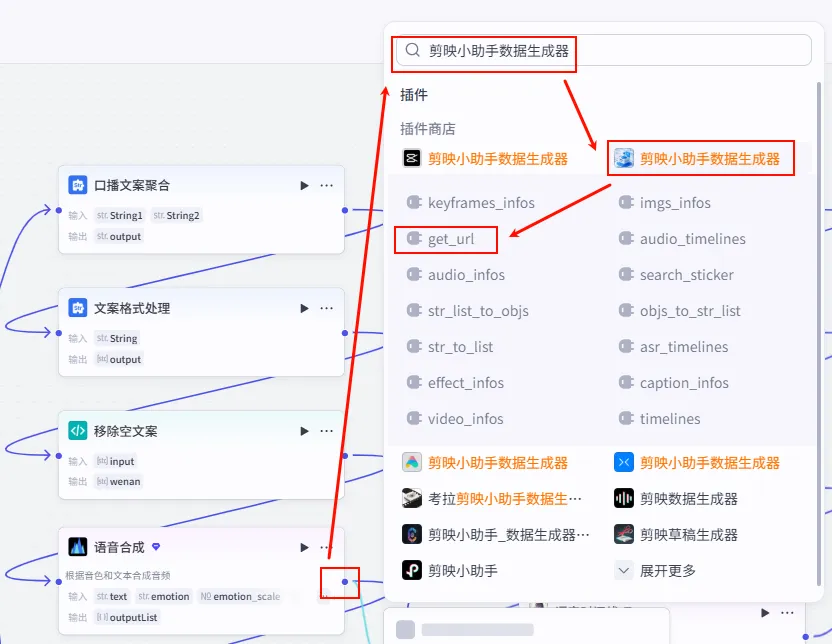
配置要点: 节点名称: 批量提取语音URL。开启批处理: 必须开启,因为输入是音频列表。 引用变量: item1引用语音合成.outputList。输入 (output): 引用 item1.link(意为提取对象中的 link 字段)。
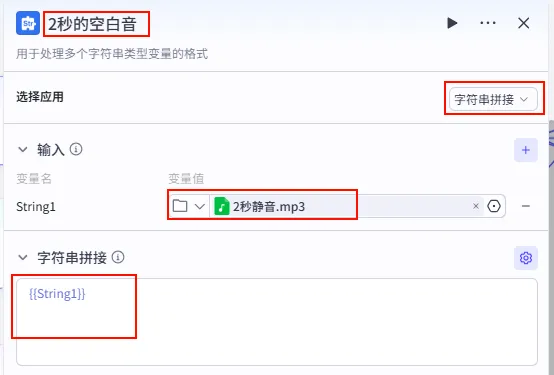
步骤 1.10:准备静音片段 (文本处理)
为了调节视频节奏,我们需要一个 2 秒钟的静音片段,后续可以穿插在语音之间。
操作步骤:点击 批量提取语音URL节点后的 + 号,选择 文本处理。
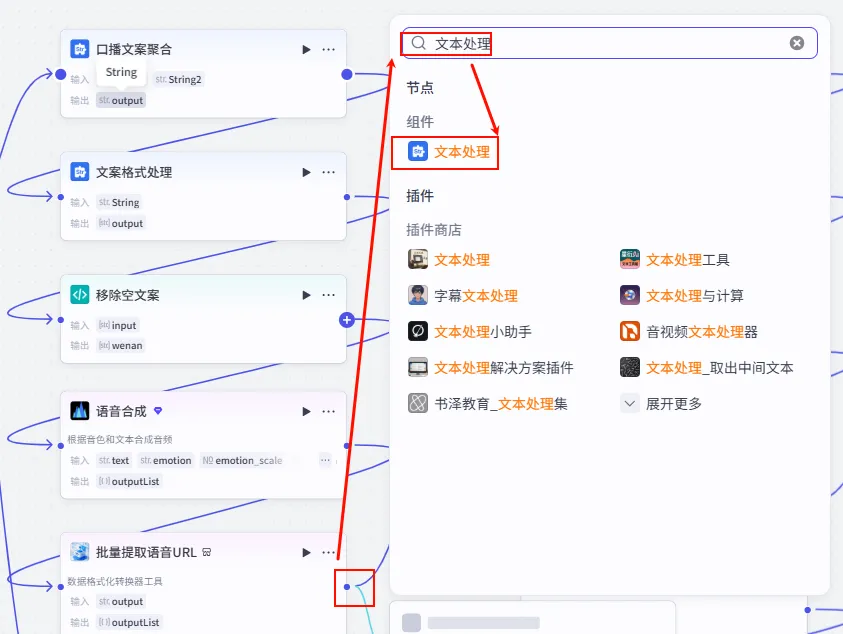
配置要点: 节点名称: 2秒的空白音。选择应用: 字符串拼接。输入变量: String1上传或引用一个名为2秒静音.mp3的音频文件。模板: {{String1}}。
步骤 1.11:插入静音片段 (代码)
我们将准备好的静音片段插入到语音列表中(例如插在第一句之后,作为开场白和正文的停顿)。
操作步骤:点击 2秒的空白音节点后的 + 号,选择 代码。
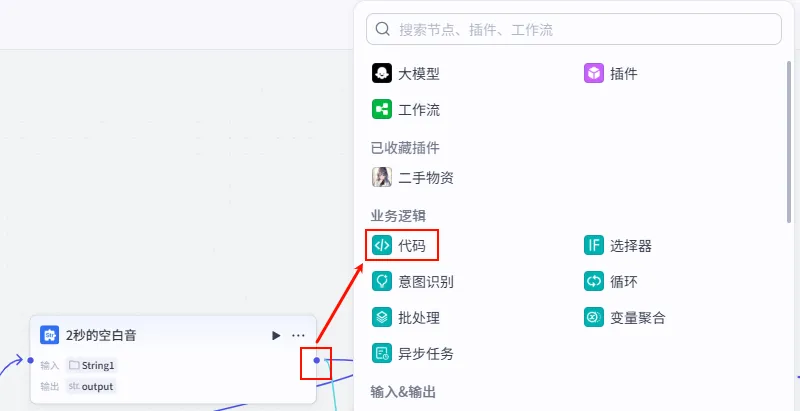
配置要点: input: 引用批量提取语音URL.outputList(Array<Object>)。output: 引用2秒的空白音.output(String)。节点名称: 将2秒空白音插入到音频链接中。输入变量: 代码: (代码获取方式见文末)。 输出变量: link_list(Array<Object>类型)。
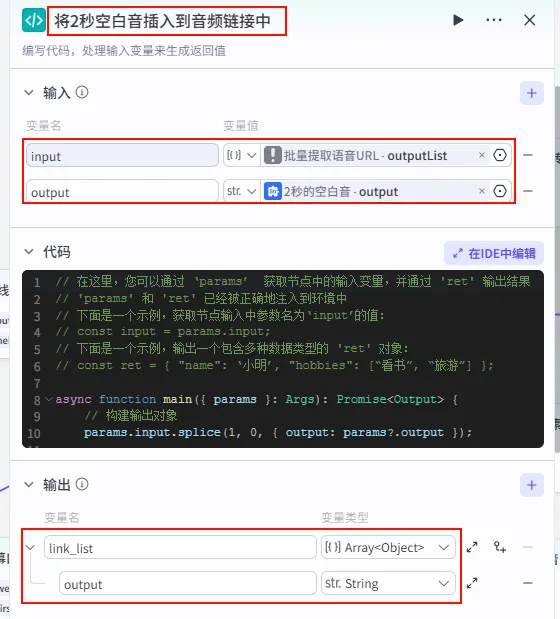
步骤 1.12:提取语音URL为列表 (Plugin)
经过代码处理后的数据结构发生了变化,我们需要再次调用插件,将其格式化为标准的 infos 格式,供后续剪映剪辑使用。
操作步骤:点击 将2秒空白音插入到音频链接中节点后的 + 号,搜索 剪映小助手数据生成器 -> get_url。
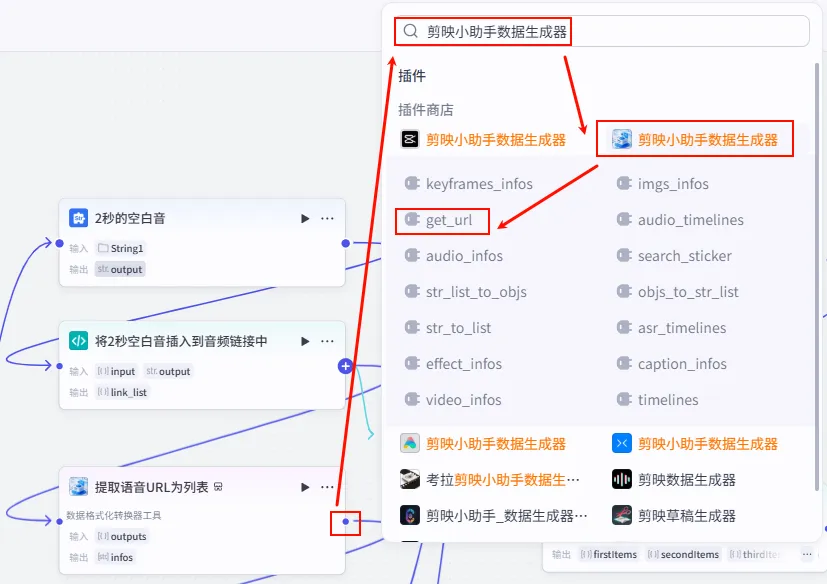
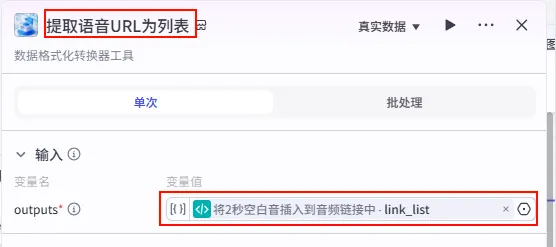
配置要点: outputs: 引用将2秒空白音插入到音频链接中.link_list。节点名称: 提取语音URL为列表。输入变量: 输出: 获得最终的音频 infos列表。
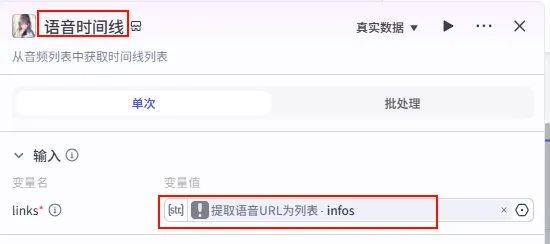
步骤 1.13:获取语音时间线 (Plugin)
为了让后续的 "智能合成" 节点知道每一张图片应该显示多长时间(与语音时长匹配),我们需要计算出每个音频片段的时长信息。
操作步骤:点击 提取语音URL为列表节点后的 + 号,搜索 获取音频时间 -> 选择 语音时间线 工具。
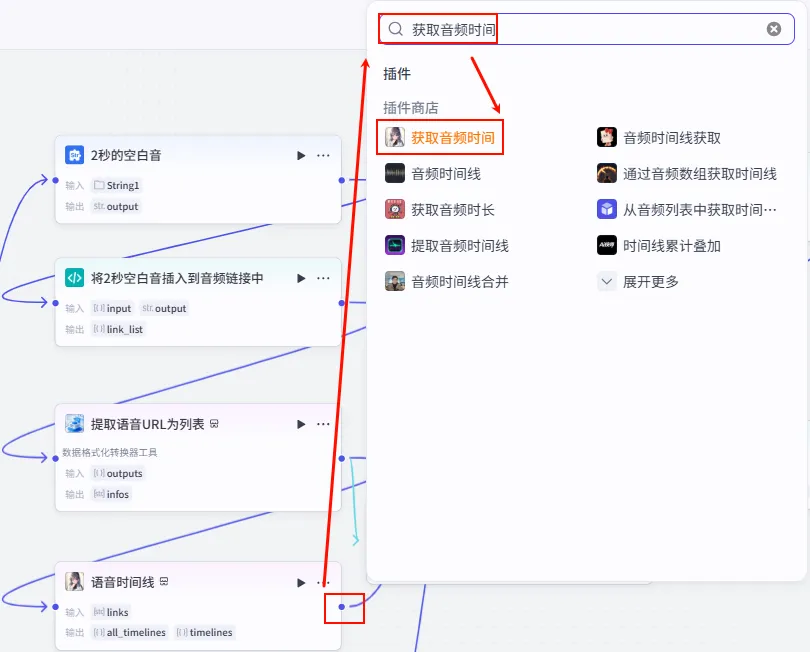
配置要点: links: 引用提取语音URL为列表.infos。节点名称: 语音时间线。输入变量: 输出: 获得包含时长的 timelines数据。
步骤 1.13.1:处理文案人声信息 (Plugin)
在获得语音时长后,我们可以立即配置 核心旁白音轨。
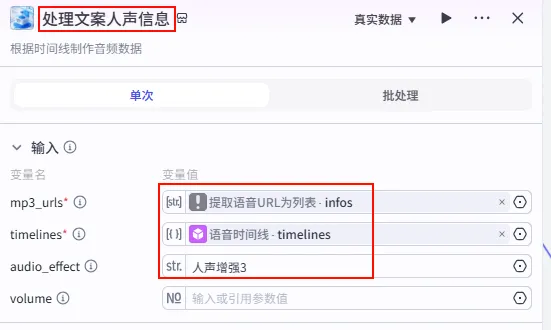
操作步骤:点击 语音时间线节点后的 + 号,搜索 剪映小助手数据生成器 -> audio_infos。需同时连接提取语音URL为列表。
配置要点: mp3_urls: 引用提取语音URL为列表.infos(Step 1.12 输出)。timelines: 引用语音时间线.timelines(Step 1.13 输出)。audio_effect: 选择人声增强3(提升旁白清晰度)。节点名称: 处理文案人声信息。输入变量: 输出: 获得旁白音轨的最终参数 audio_infos。
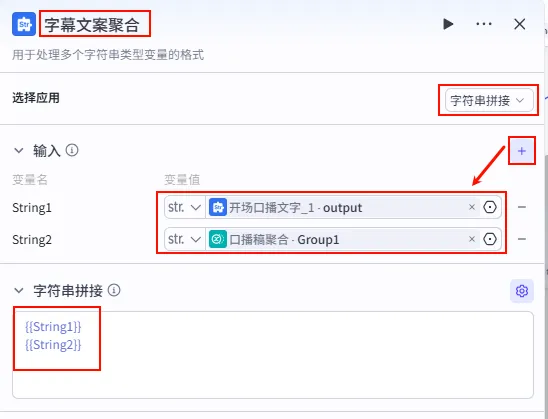
步骤 1.14:字幕文案聚合 (文本处理)
除了生成语音和画面,我们还需要准备一份原始的字幕文本,供视频合成时显式使用。
操作步骤:点击 口播稿聚合节点后的 + 号(拉出第二条连线,与口播文案聚合并行),选择 文本处理。
配置要点: String1: 引用开场口播文字_1.output(开场白)。String2: 引用口播稿聚合.Group1(正文)。节点名称: 字幕文案聚合。选择应用: 字符串拼接。输入变量: 模板: {{String1}}{{String2}}(注意:这里使用\n换行还是直接拼接,取决于后续字幕插件的需求,通常建议与口播文案保持一致)。
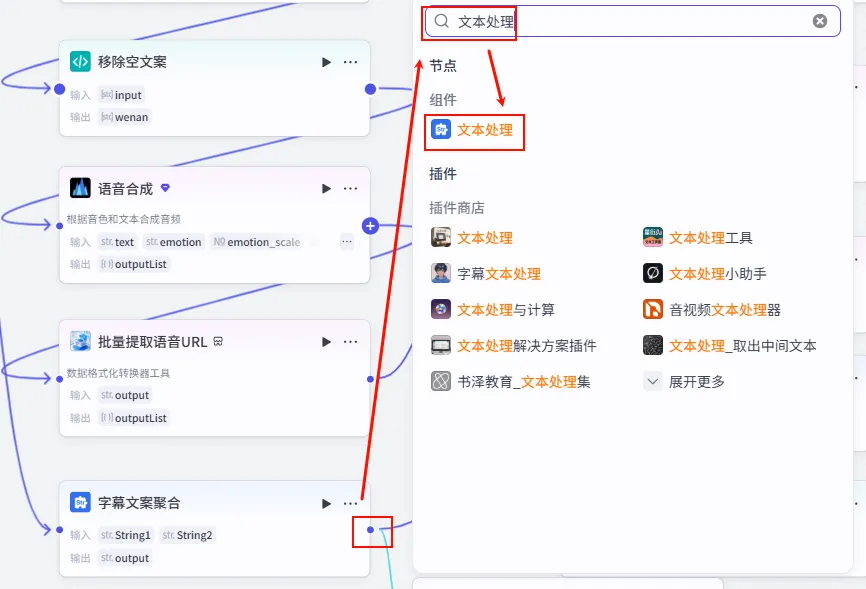
步骤 1.15:字幕格式处理 (文本处理)
为了让字幕与画面的每一帧/每一句对应,我们需要将聚合后的字幕文本再次拆分为列表。
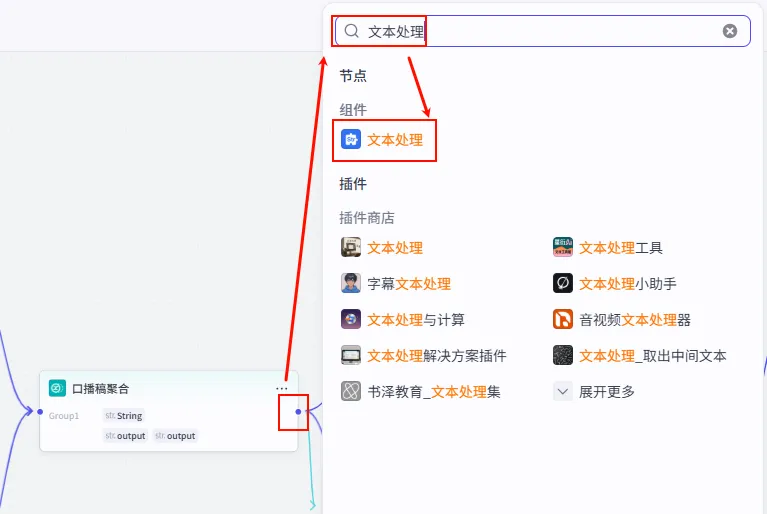
操作步骤:点击 字幕文案聚合节点后的 + 号,搜索 文本处理。
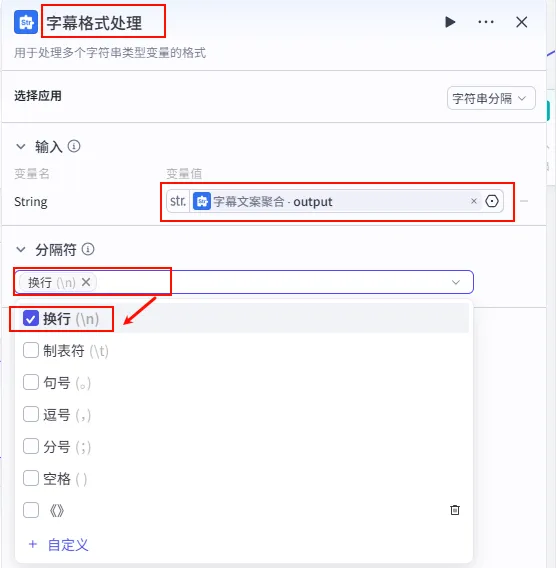
配置要点: 节点名称: 字幕格式处理。选择应用: 字符串分隔。输入变量: String引用字幕文案聚合.output。分隔符: 选择 换行 (\n)。输出: 获得字幕文本列表 ( Array<String>)。
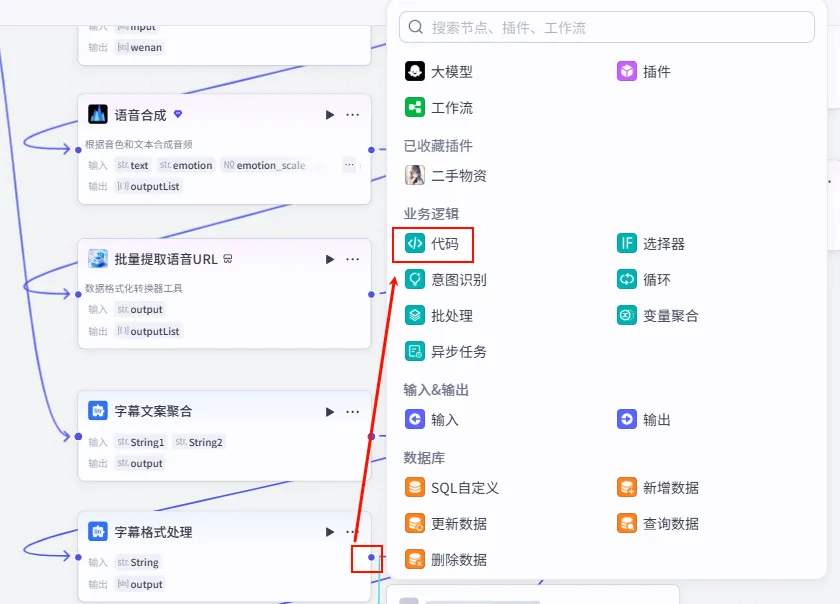
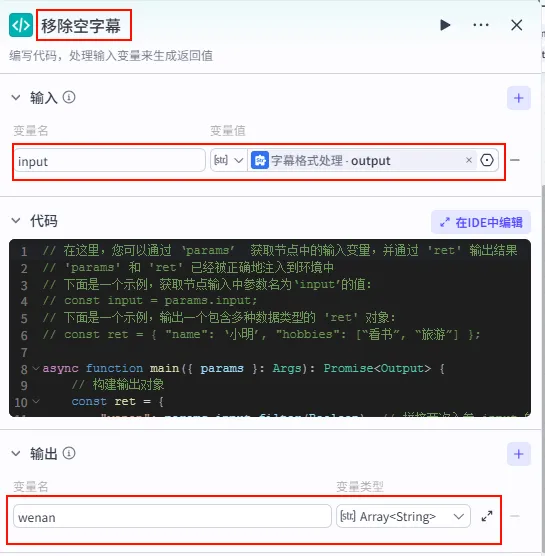
步骤 1.16:移除空字幕 (代码)
同样为了防止出现空行导致的错误,我们需要对分割后的字幕列表进行一次清洗。
操作步骤:点击 字幕格式处理节点后的 + 号,选择 代码。
配置要点: input: 引用字幕格式处理.output(Array<String>)。节点名称: 移除空字幕。输入变量: 代码: (代码获取方式见文末)。 输出变量: wenan(Array<String>类型)。
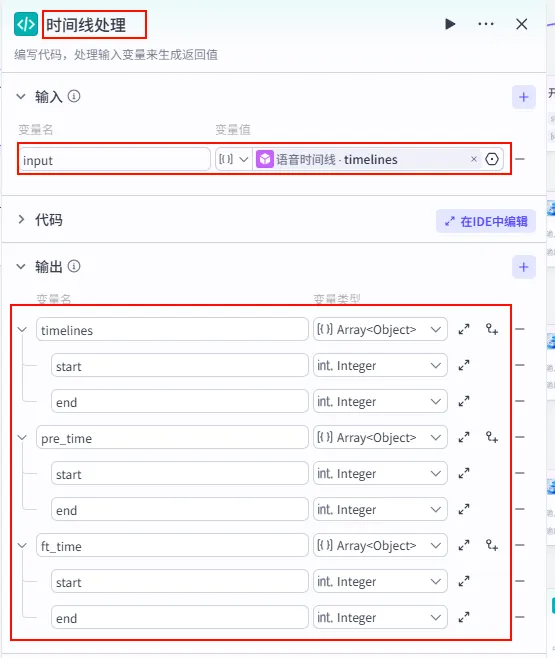
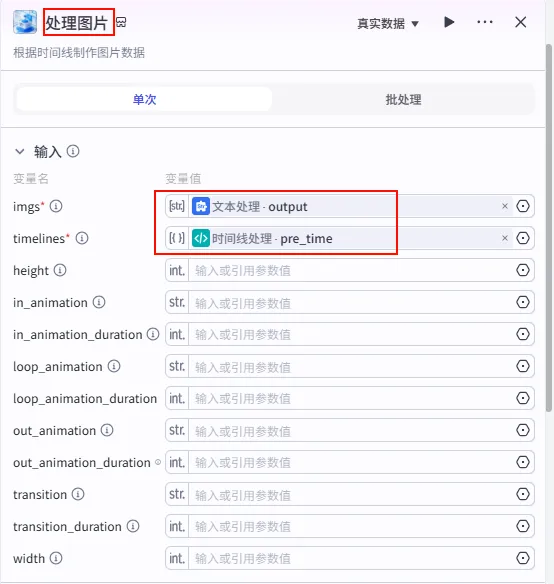
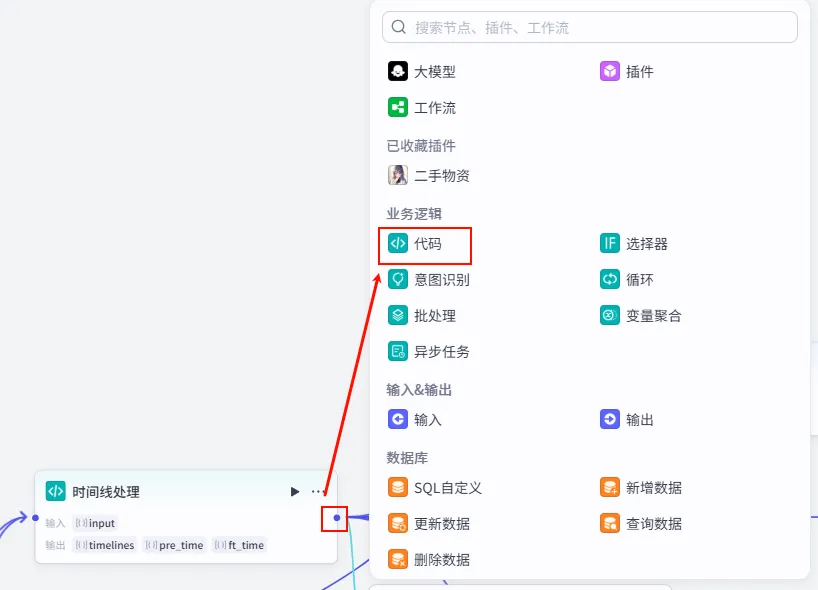
步骤 1.17:时间线处理 (代码)
这一步是 "音画同步" 的关键。我们将 语音时间线 (包含时长) 与 字幕文本 (包含内容) 合并,计算出每一句字幕/画面在视频中的精确 开始时间 和 结束时间。
操作步骤:点击 移除空字幕节点后的 + 号,选择 代码。同时将语音时间线的输出也能连接到此节点 (双输入)。
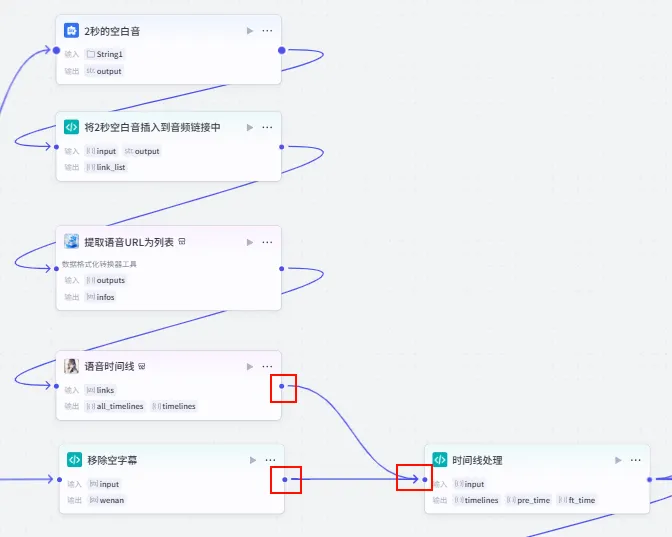
配置要点: timelines(Array<Object>)pre_time(Array<Object>)ft_time(Array<Object>)input: 引用语音时间线.timelines(包含时长的列表)。wenan: 引用移除空字幕.wenan(字幕文本列表)。(注意:需手动点击 + 号添加此变量)。节点名称: 时间线处理。输入变量: 代码: (代码获取方式见文末)。 输出变量: 设置为 Object列表,包含start,end等字段。
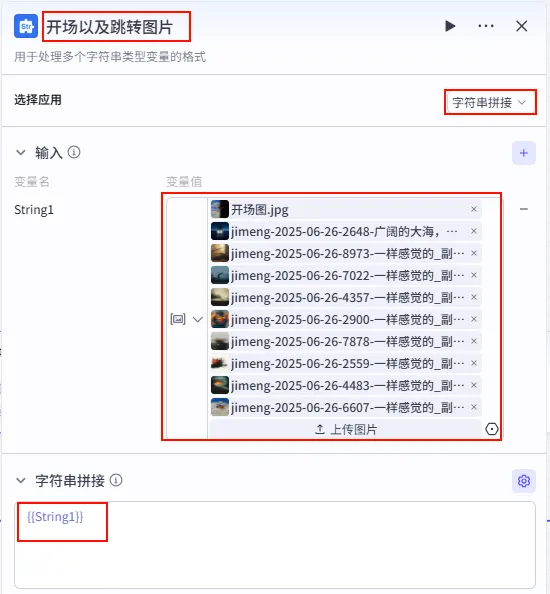
步骤 1.18:开场以及跳转图片 (文本处理)
这是时间线处理后的第一个分支,用于配置视频的 开场图片 (或转场图)。
操作步骤:点击 时间线处理节点后的 + 号 (拉出第一条分支),搜索 文本处理。
配置要点: String1: 上传 多张 开场/转场图片 (这些图片将按顺序循环使用或随机使用)。节点名称: 开场以及跳转图片。选择应用: 字符串拼接。输入变量: 模板: {{String1}}。
步骤 1.19:开场图格式处理 (文本处理)
为了适应后续的 "智能合成" 节点(它通常接受数组格式),我们需要将开场图片的字符串转换为列表。
操作步骤:点击 开场以及跳转图片节点后的 + 号,搜索 文本处理。
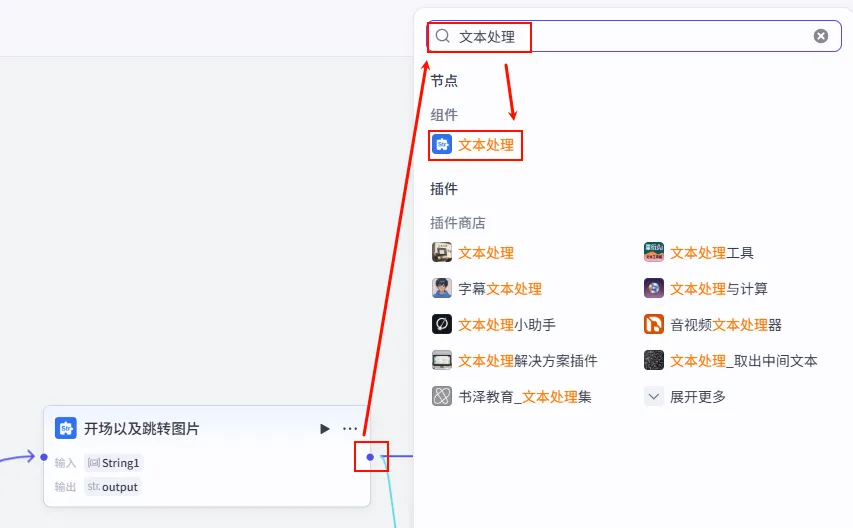
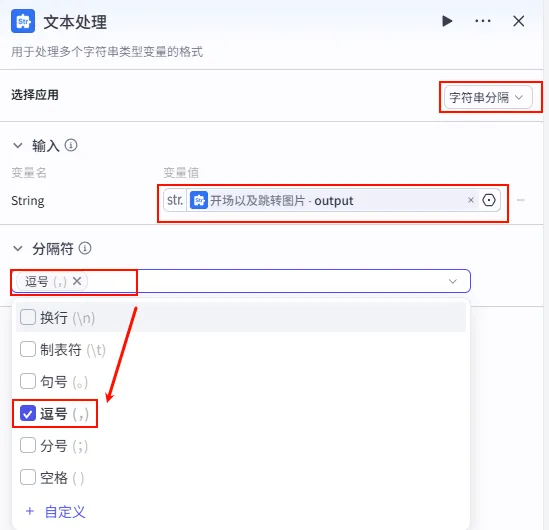
配置要点: 节点名称: 开场图格式处理(建议重命名以区分)。选择应用: 字符串分隔。输入变量: String引用开场以及跳转图片.output。分隔符: 选择 逗号 (,)。输出: 获得开场图列表 ( Array<String>)。
步骤 1.20:处理开场图片 (Plugin)
有了开场图列表和通过代码计算出的开场时长 (pre_time),我们需要调用插件生成最终的图片分镜参数。
操作步骤:点击 开场图格式处理节点后的 + 号,搜索 剪映小助手数据生成器 -> imgs_infos。注意:需要同时连接时间线处理的pre_time变量。
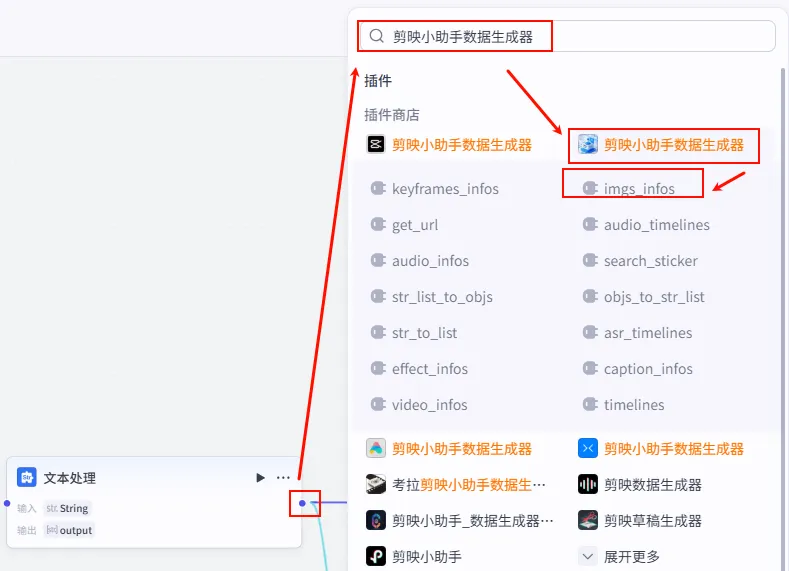
配置要点: imgs: 引用开场图格式处理.output(图片列表)。timelines: 引用时间线处理.pre_time(注意:引用的是预览/开场时间轴)。节点名称: 处理开场图片。输入变量: 输出: 获得开场图的最终参数 infos。
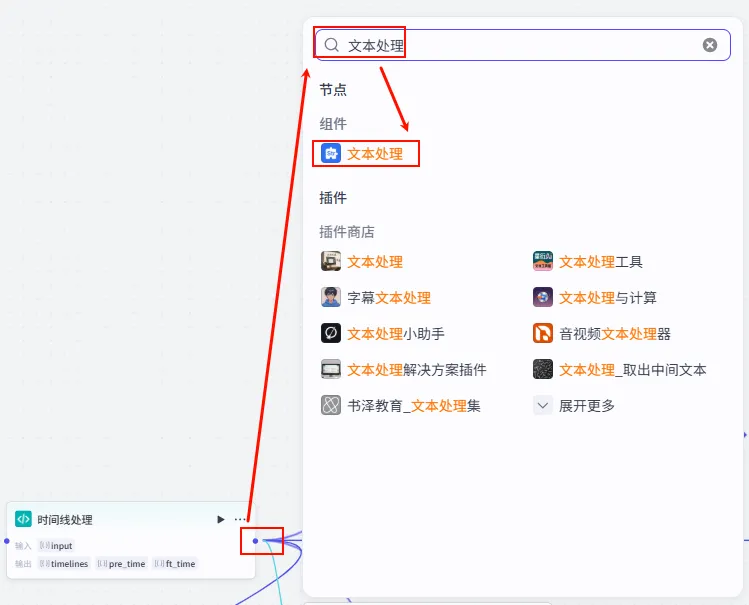
步骤 1.21:上发条音效素材 (文本处理)
这是时间线处理后的 第二条分支,用于添加特定的音效(如“上发条”的声音),增强视频的趣味性或提示转场。
操作步骤:点击 时间线处理节点后的 + 号 (拉出第二条分支),搜索 文本处理。
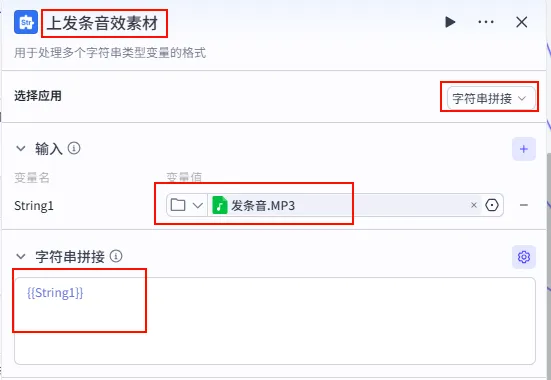
配置要点: String1: 上传 发条音.MP3 (或其他简短音效)。节点名称: 上发条音效素材。选择应用: 字符串拼接。输入变量: 模板: {{String1}}。
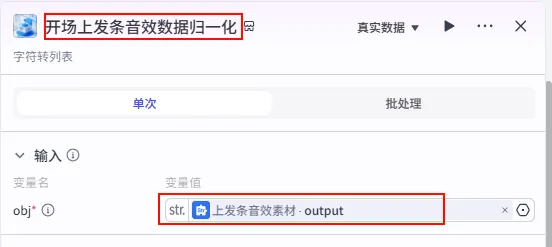
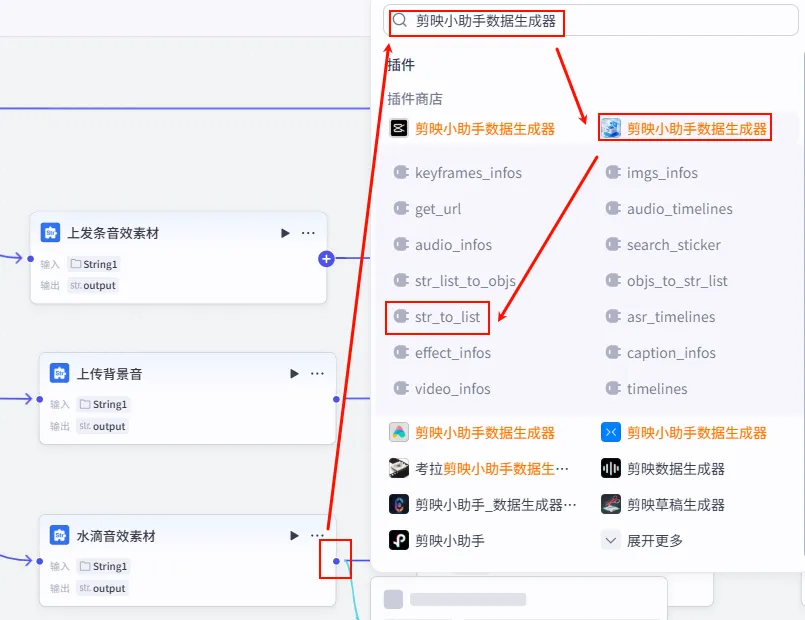
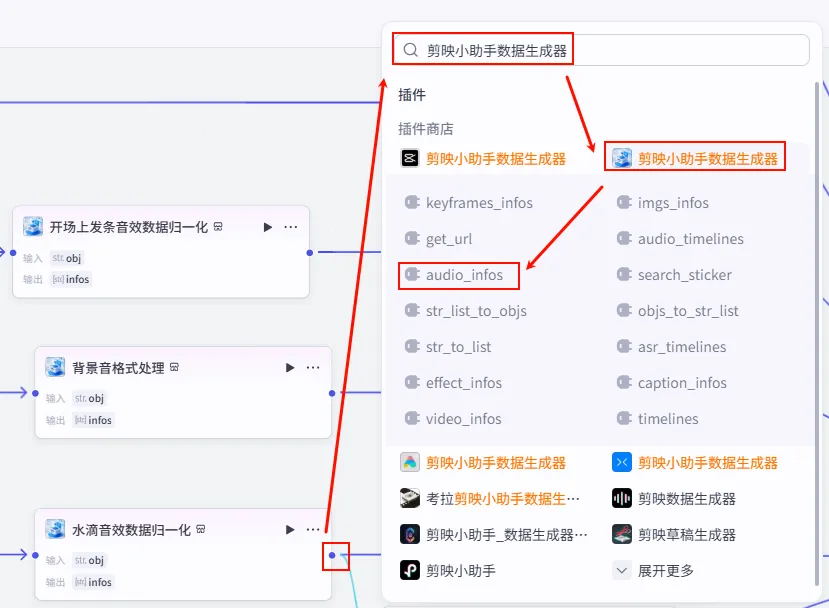
步骤 1.22:开场上发条音效数据归一化 (Plugin)
同样为了数据格式的统一,我们需要将音效字符串转换为列表。
操作步骤:点击 上发条音效素材节点后的 + 号,搜索 剪映小助手数据生成器 -> str_to_list。
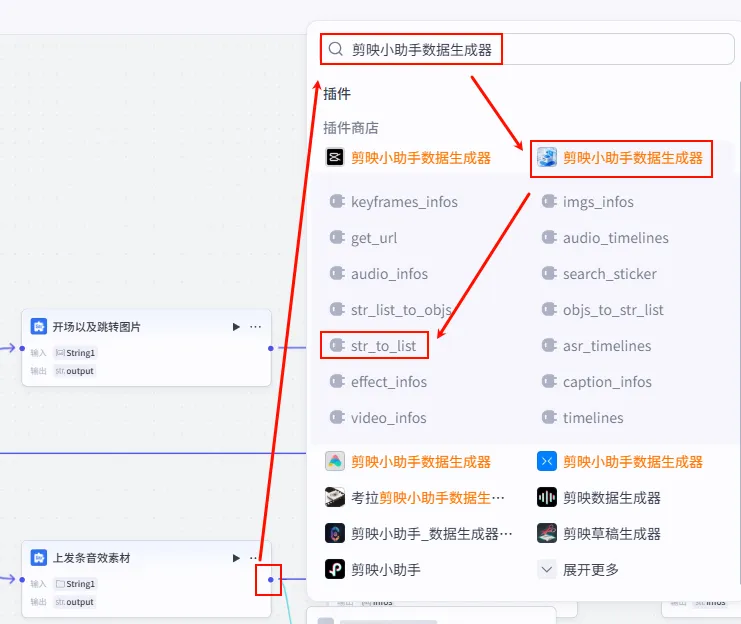
配置要点: obj: 引用上发条音效素材.output(音效字符串)。节点名称: 开场上发条音效数据归一化。输入变量: 输出: 获得音效列表 ( Array<String>)。
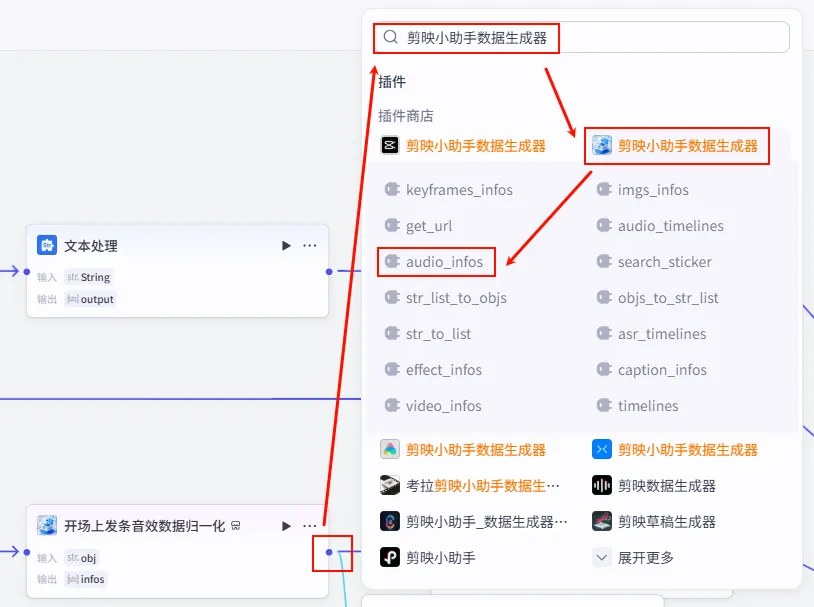
步骤 1.23:开场音效信息处理 (Plugin)
有了归一化后的音效列表,我们需要将其与特定的时间点 (ft_time) 结合,生成最终的音效轨道数据。
操作步骤:点击 开场上发条音效数据归一化节点后的 + 号,搜索 剪映小助手数据生成器 -> audio_infos。
配置要点: mp3_urls: 引用开场上发条音效数据归一化.infos(音效列表)。timelines: 引用时间线处理.ft_time(注意:引用的是ft_time时间轴)。volume: 设置为0.7(音量适中)。节点名称: 开场发条音效信息处理。输入变量: 输出: 获得音效音轨的参数 audio_infos。
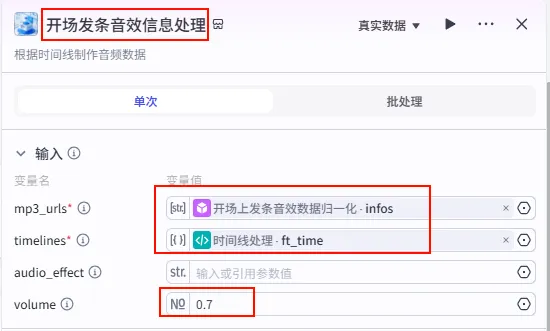
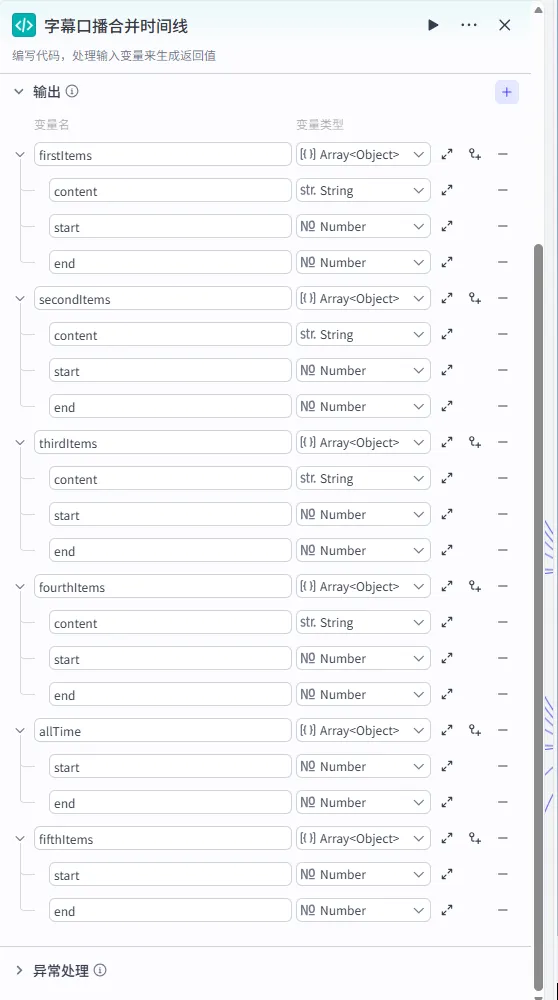
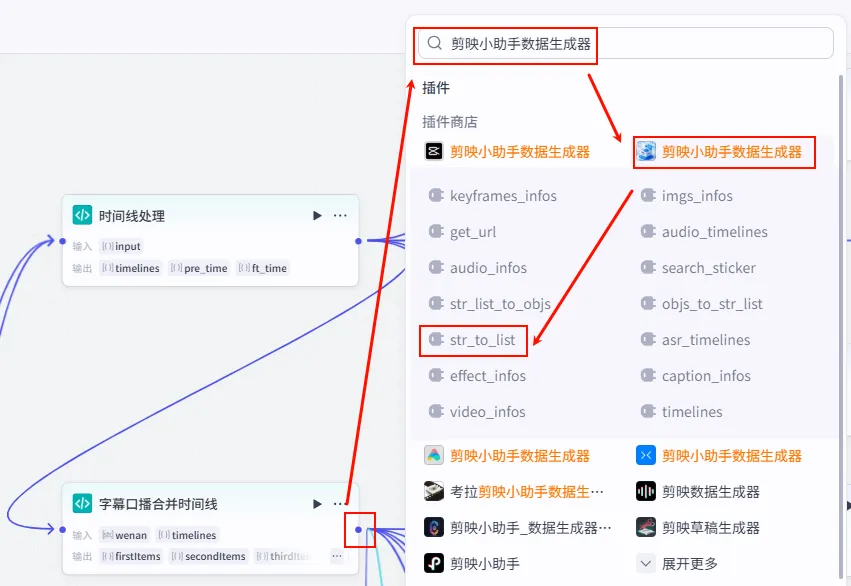
步骤 1.24:字幕口播合并时间线 (代码)
这是时间线处理后的 第三条分支,也是 字幕与时间线对齐 的核心枢纽。它将衍生出 6个下游分支 (BGM + 5组字幕)。
操作步骤:点击 时间线处理节点后的 + 号 (拉出第三条分支),选择 代码。同时连接移除空字幕的wenan变量。
配置要点: firstItems(前11句)secondItems(第12-22句)thirdItems(第23-33句)fourthItems(第34-44句)fifthItems(第45-55句)allTime(完整时间轴数据)(每个对象需包含 content,start,end字段)wenan: 引用移除空字幕.wenan(字幕文本)。timelines: 引用时间线处理.timelines(主时间轴)。节点名称: 字幕口播合并时间线。输入变量: 代码: (代码获取方式见文末)。 输出变量: 手动添加以下输出变量 ( Array<Object>),用于分段处理字幕:
步骤 1.25:上传背景音 (文本处理)
这是 字幕口播合并时间线 后的 第一个分支 (Branch 1 of 6),用于为视频添加背景音乐 (BGM)。
操作步骤:点击 字幕口播合并时间线节点后的 + 号 (拉出第一条下游分支),搜索 文本处理。(注:此处虽然不需要直接引用 1.25 的输出,但在逻辑上属于其并行流程的一部分,最终与 allTime 结合)
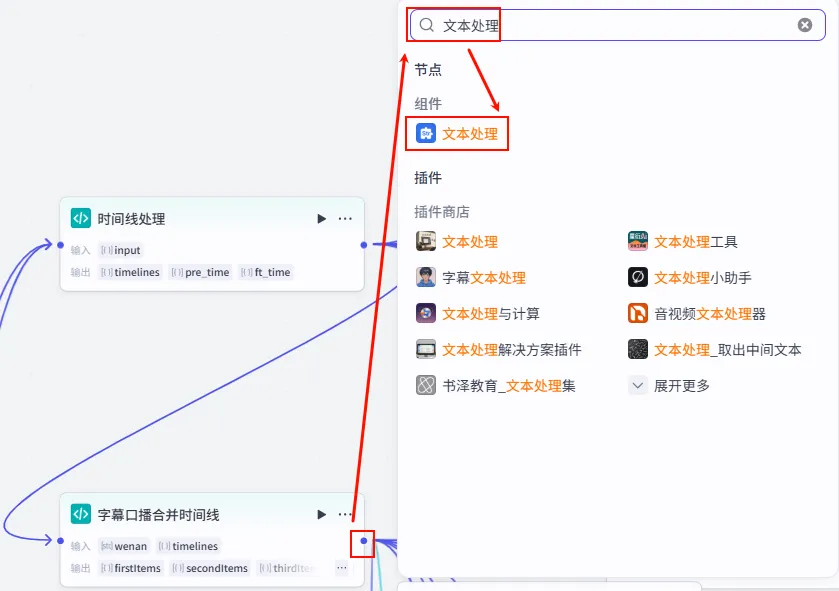
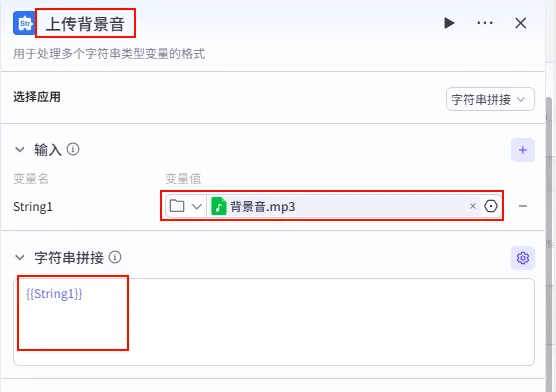
配置要点: String1: 上传 背景音.mp3 (纯音乐,轻柔舒缓)。节点名称: 上传背景音。选择应用: 字符串拼接。输入变量: 模板: {{String1}}。
步骤 1.26:背景音数据归一化 (Plugin)
为了适应后续插件的输入要求,需要将背景音字符串转换为列表格式。
操作步骤:点击
上传背景音节点后的 + 号,搜索 剪映小助手数据生成器 -> str_to_list。配置要点:
obj: 引用上传背景音.output(背景音字符串)。节点名称: 背景音格式处理。输入变量: 输出: 获得背景音列表 ( Array<String>)。
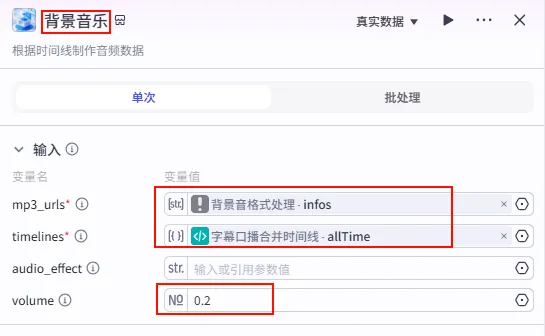
步骤 1.27:处理背景音乐信息 (Plugin)
这一步将背景音列表与视频时间轴结合,生成背景音乐轨道数据。
操作步骤:点击
背景音格式处理节点后的 + 号,搜索 剪映小助手数据生成器 -> audio_infos。需同时连接字幕口播合并时间线的allTime变量。配置要点:
mp3_urls: 引用背景音格式处理.infos(背景音列表)。timelines: 引用字幕口播合并时间线.allTime(完整时间轴)。volume: 设置为0.2(低音量背景)。节点名称: 背景音乐。输入变量: 输出: 获得 BGM 音轨参数 audio_infos。
步骤 1.28:水滴音效素材 (文本处理)
这是 字幕口播合并时间线 后的 第二个分支 (Branch 2 of 6),用于为视频增加水滴音效或其他点缀式声音。
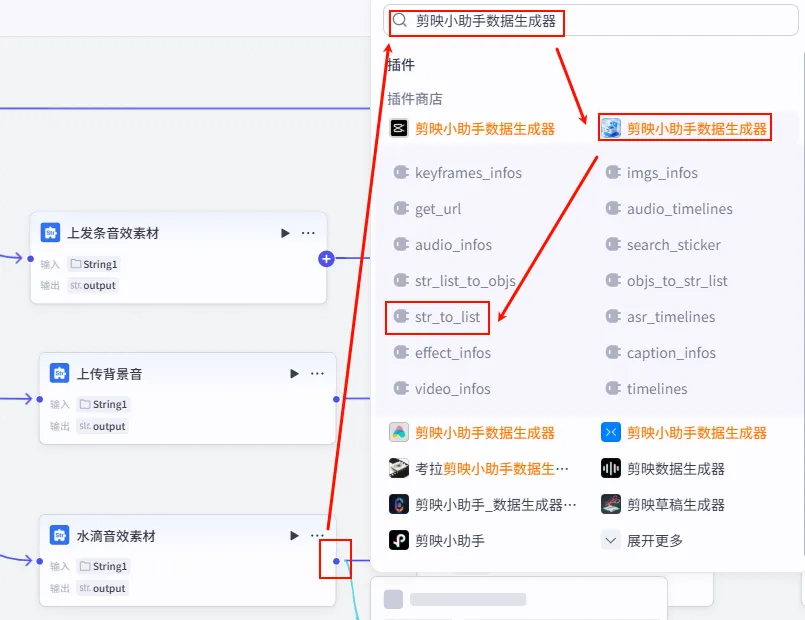
操作步骤:点击 字幕口播合并时间线节点后的 + 号 (拉出第二条下游分支),搜索 文本处理。
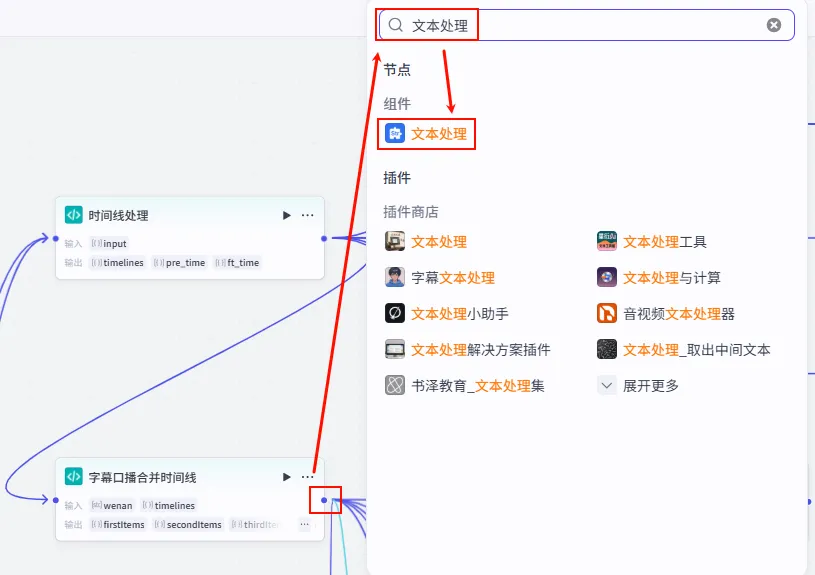
配置要点: String1: 上传 水滴音效.MP3。节点名称: 水滴音效素材。选择应用: 字符串拼接。输入变量: 模板: {{String1}}。
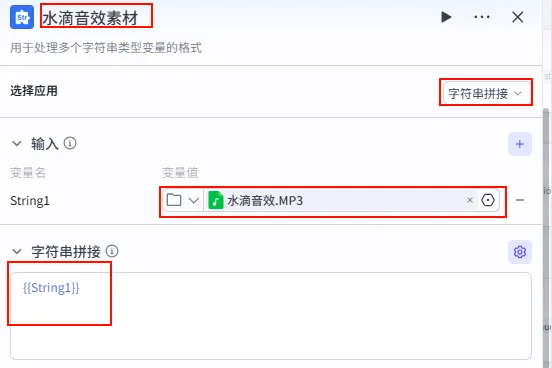
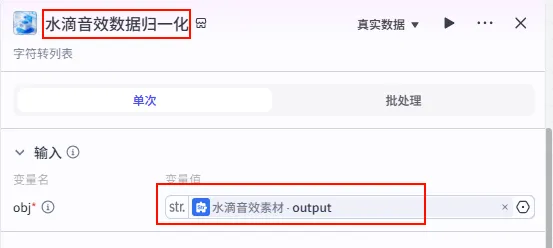
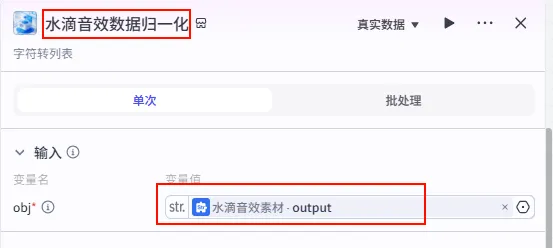
步骤 1.29:水滴音效数据归一化 (Plugin)
为了适应后续插件的输入要求,需要将水滴音效字符串转换为列表格式。
操作步骤:点击 水滴音效素材节点后的 + 号,搜索 剪映小助手数据生成器 -> str_to_list。
配置要点: obj: 引用水滴音效素材.output(水滴音效字符串)。节点名称: 水滴音效数据归一化。输入变量: 输出: 获得水滴音效列表 ( Array<String>)。
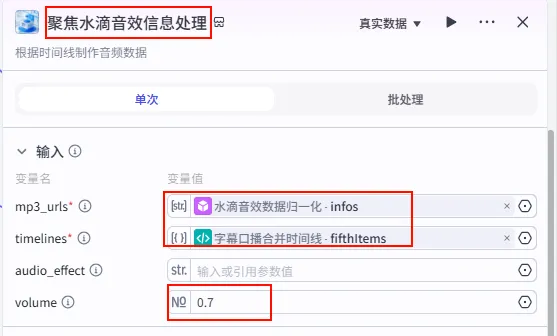
步骤 1.30:聚焦水滴音效信息处理 (Plugin)
这一步将水滴音效与特定的分段对齐(例如在视频结尾或某个核心观点处)。
操作步骤:点击 水滴音效数据归一化节点后的 + 号,搜索 剪映小助手数据生成器 -> audio_infos。需同时连接字幕口播合并时间线的fifthItems变量。
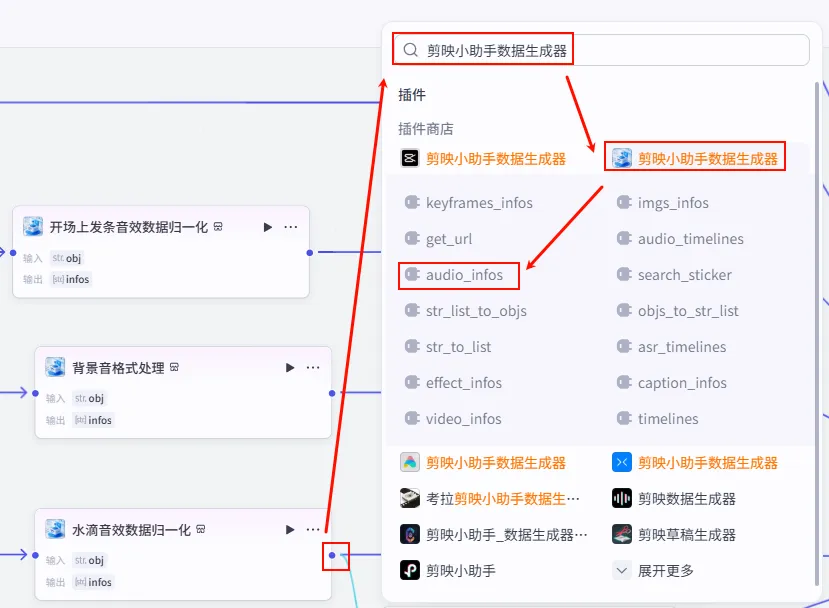
配置要点: mp3_urls: 引用水滴音效数据归一化.infos(水滴音效列表)。timelines: 引用字幕口播合并时间线.fifthItems(注意:这里引用的是第五组字幕时间轴)。volume: 设置为0.7。节点名称: 聚焦水滴音效信息处理。输入变量: 输出: 获得水滴音效的音轨参数 audio_infos。
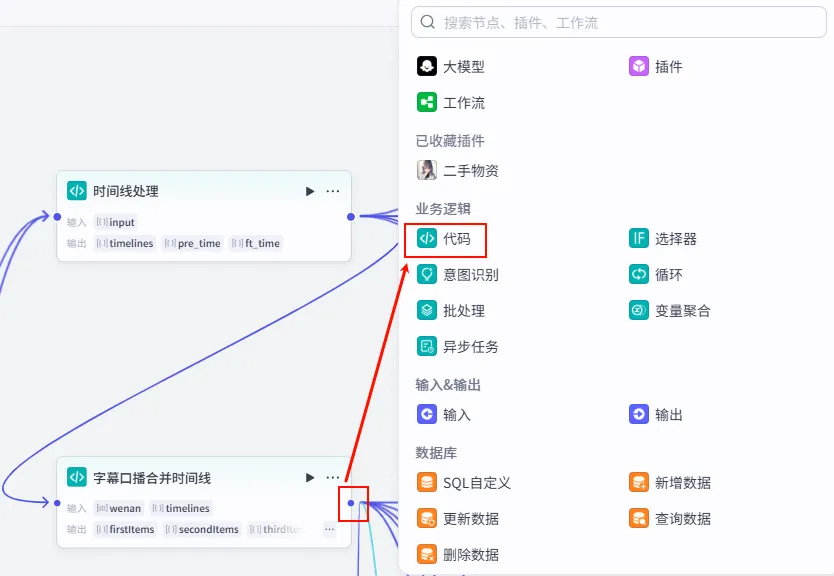
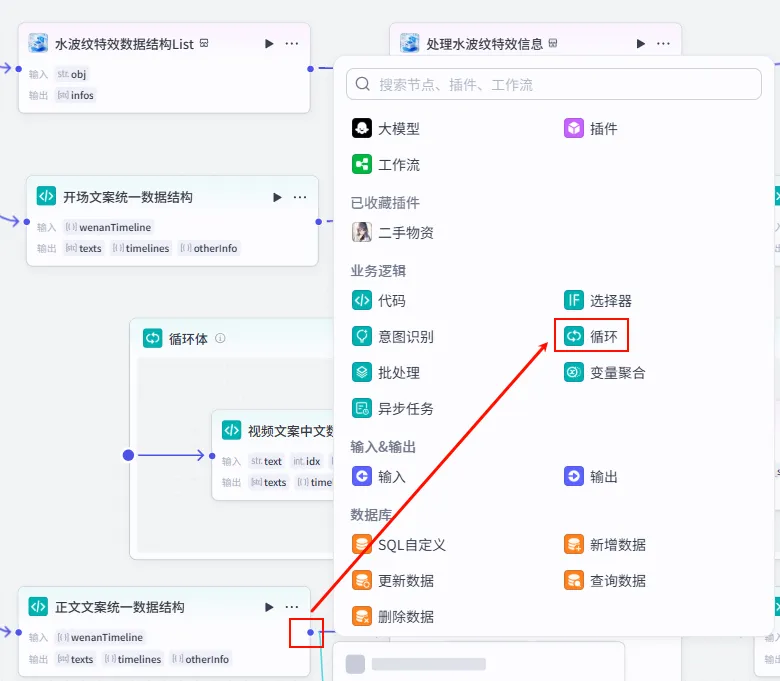
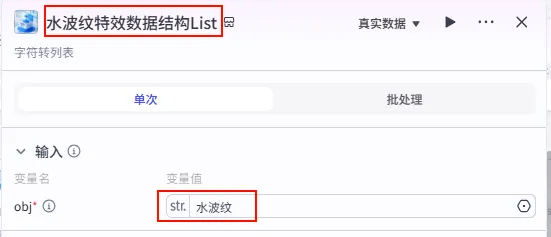
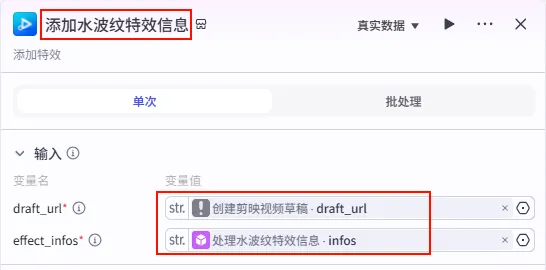
步骤 1.31:水波纹特效数据结构List (Plugin)
这是 字幕口播合并时间线 后的 第三个分支 (Branch 3 of 6),用于为视频准备特定的视觉特效(如水波纹)。
操作步骤:点击 字幕口播合并时间线节点后的 + 号 (拉出第三条下游分支),搜索 剪映小助手数据生成器 -> str_to_list。
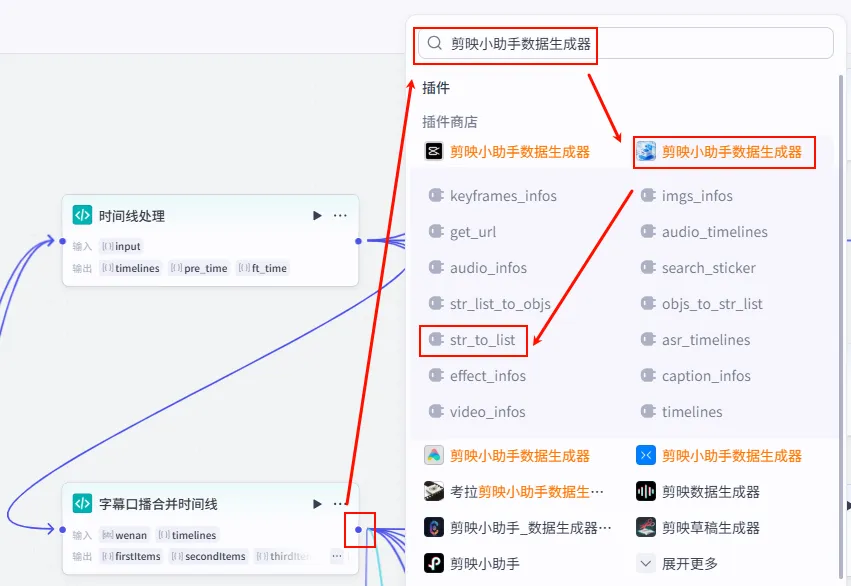
配置要点: obj: 手动输入字符串水波纹。节点名称: 水波纹特效数据结构List。输入变量: 输出: 获得特效列表。
步骤 1.32:处理水波纹特效信息 (Plugin)
这一步将预设的特效名称与视频时间轴匹配,生成剪映可识别的特效指令。
操作步骤:点击 水波纹特效数据结构List节点后的 + 号,搜索 剪映小助手数据生成器 -> effect_infos。需同时连接字幕口播合并时间线的fifthItems变量。
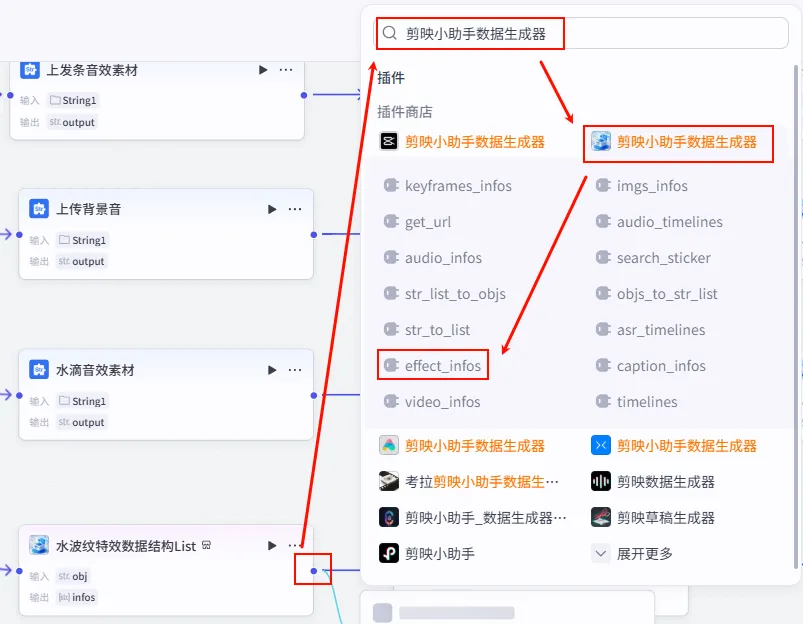
配置要点: effects: 引用水波纹特效数据结构List.infos(特效列表)。timelines: 引用字幕口播合并时间线.fifthItems(注意:这里引用的是第五组字幕时间轴)。节点名称: 处理水波纹特效信息。输入变量: 输出: 获得特效参数 effect_infos。
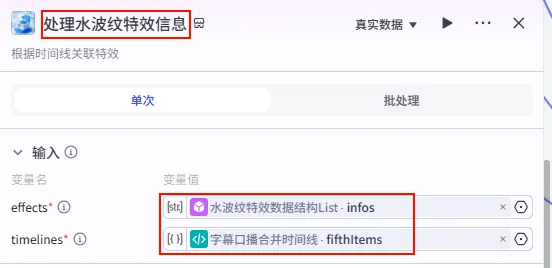
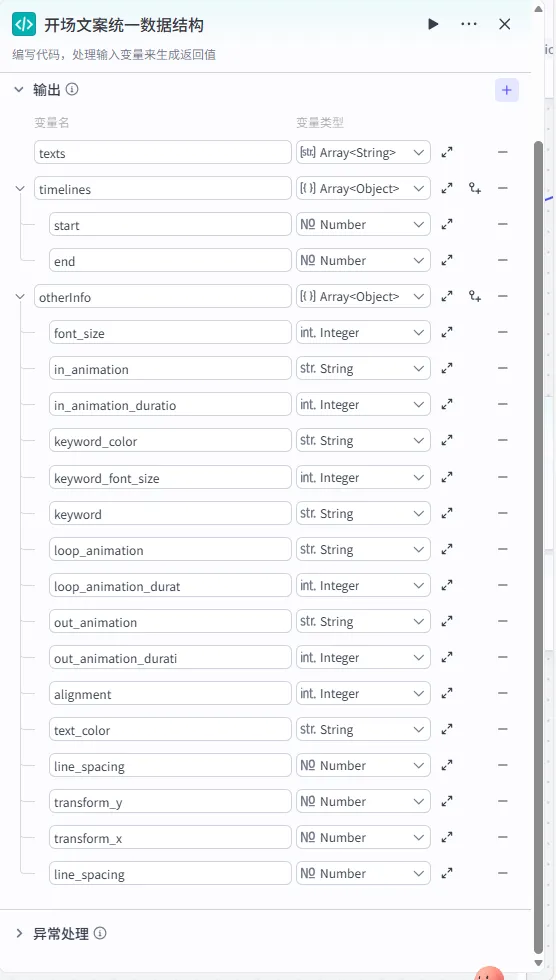
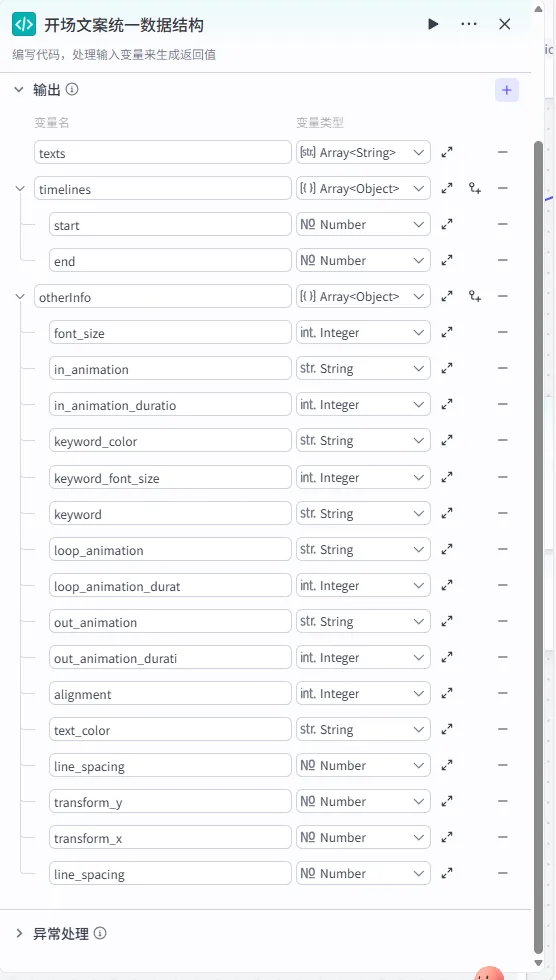
步骤 1.33:开场文案统一数据结构 (代码)
这是 字幕口播合并时间线 后的 第四个分支 (Branch 4 of 6),用于专门处理第一组字幕(通常包含书名、作者等信息),并将其包装成剪映插件所需的特定结构。
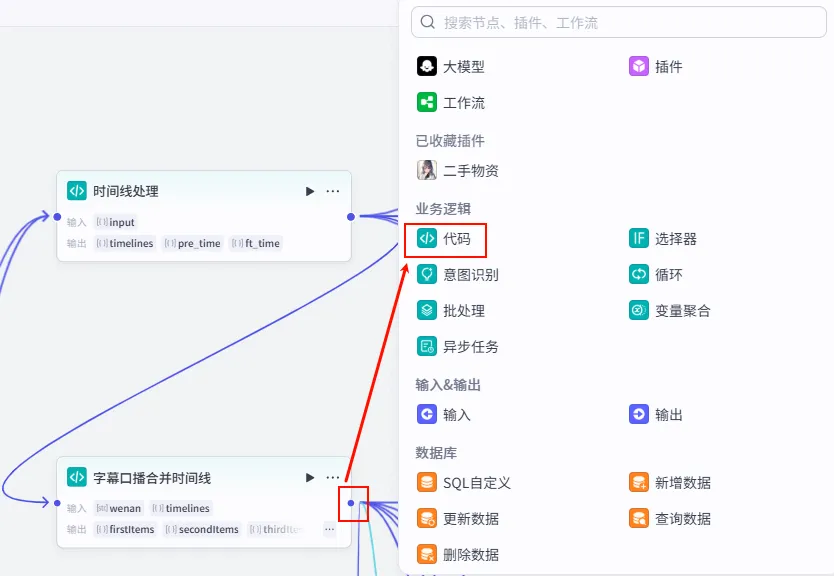
操作步骤:点击 字幕口播合并时间线节点后的 + 号 (拉出第四条下游分支),选择 代码。
配置要点: wenanTimeline: 引用字幕口播合并时间线.firstItems。节点名称: 开场文案统一数据结构。输入变量: 代码: (代码获取方式见文末)。
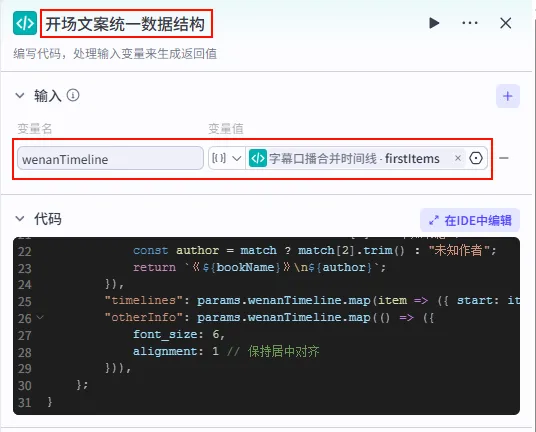
输出变量配置:为了让剪映插件能识别特定样式(如字体大小、对齐等),输出变量的结构需保持高度一致。
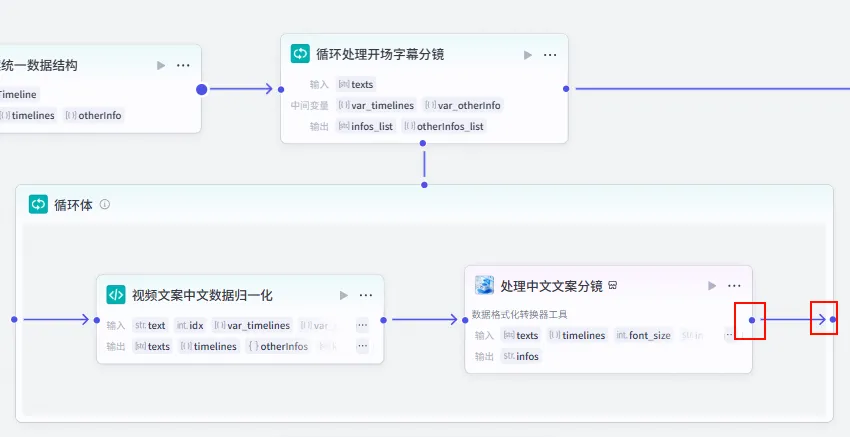
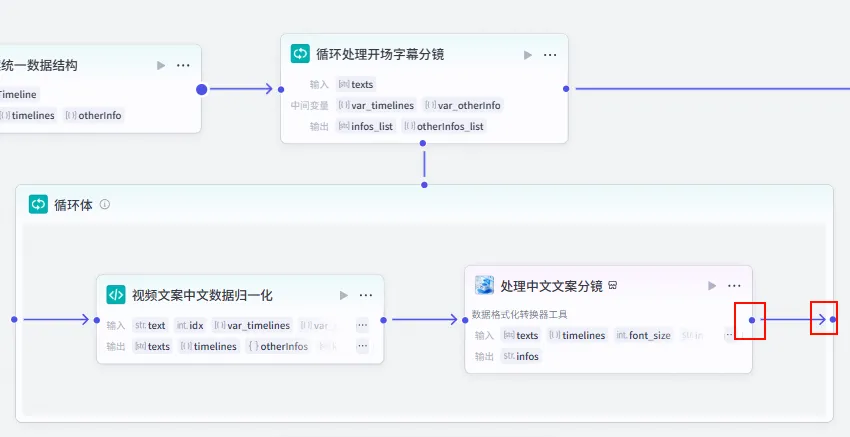
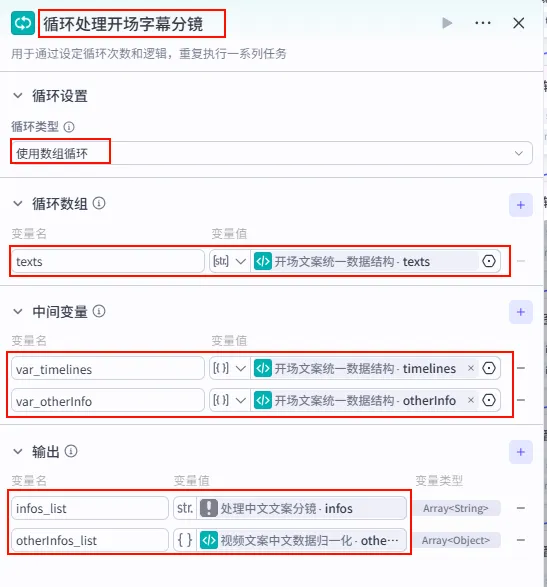
步骤 1.34:分段文案循环处理 (循环)
在开场文案数据结构化之后,我们需要通过循环节点来依次处理每一行字幕,将其转换为剪映可识别的指令格式。
操作步骤:点击 开场文案统一数据结构节点后的 + 号,选择 循环。将循环体内的节点输出连接回循环出口。
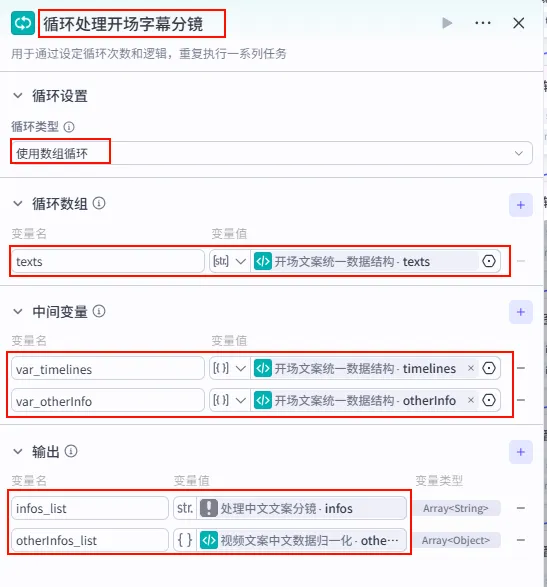
配置要点: infos_list: 引用处理中文文案分镜.infos。otherInfos_list: 引用视频文案中文数据归一化.otherInfos。var_timelines: 引用开场文案统一数据结构.timelines。var_otherInfo: 引用开场文案统一数据结构.otherInfo。节点名称: 循环处理开场字幕分镜。循环类型: 选择 使用数组循环。循环数组: texts引用开场文案统一数据结构.texts。中间变量 (用于在循环体内同步迭代): 输出配置 (收集循环体内所有节点的执行结果):
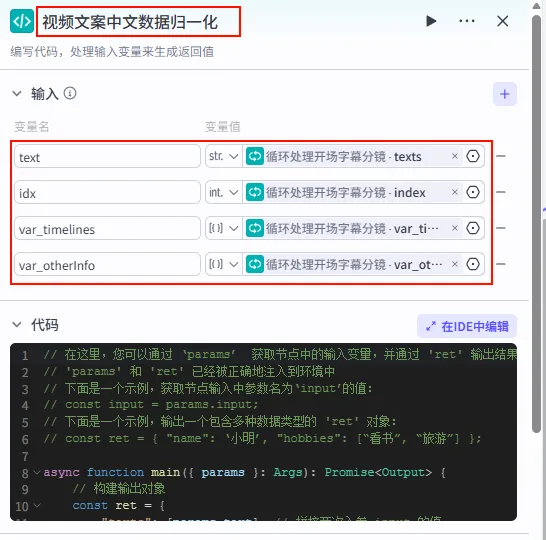
步骤 1.35:视频文案中文数据归一化 (代码 - 循环内)
该节点位于循环体内,用于处理循环迭代中的当前项数据(如单行文本、对应时间轴等),并将其标准化。
操作步骤:在 分段文案循环处理(循环) 节点内部,点击 + 号,选择 代码。
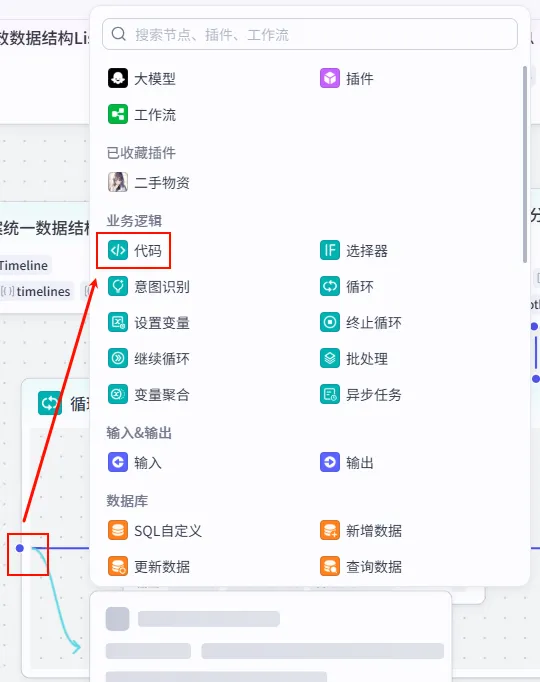
配置要点: text: 引用循环处理开场字幕分镜.texts(当前迭代文本)。idx: 引用循环处理开场字幕分镜.index(当前索引)。var_timelines: 引用循环处理开场字幕分镜.var_timelines。var_otherInfo: 引用循环处理开场字幕分镜.var_otherInfo。节点名称: 视频文案中文数据归一化。输入变量: 代码: (代码获取方式见文末)。
步骤 1.36:处理中文文案分镜 (Plugin - 循环内)
这是循环体内的核心插件节点,负责将归一化后的数据打包成剪映字幕分镜。
操作步骤:在循环体内,点击 视频文案中文数据归一化节点后的 + 号,搜索 剪映小助手数据生成器 -> caption_infos。
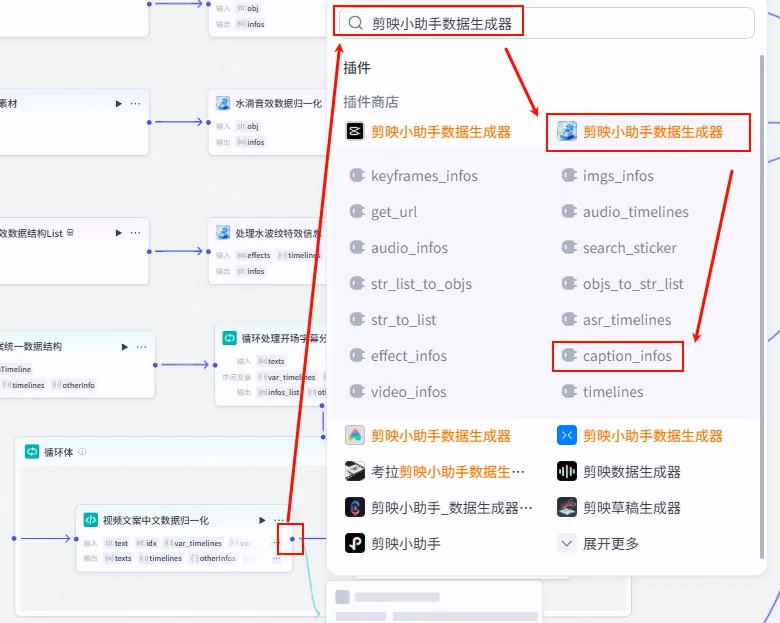
配置要点: 大部分参数(如 texts,timelines,font_size,keywords等)均通过引用视频文案中文数据归一化的输出获得。节点名称: 处理中文文案分镜。输入变量: 输出: 获得单分片字幕参数。
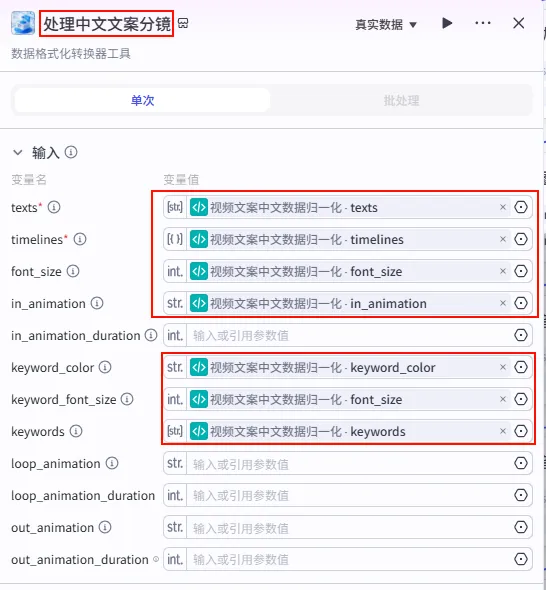
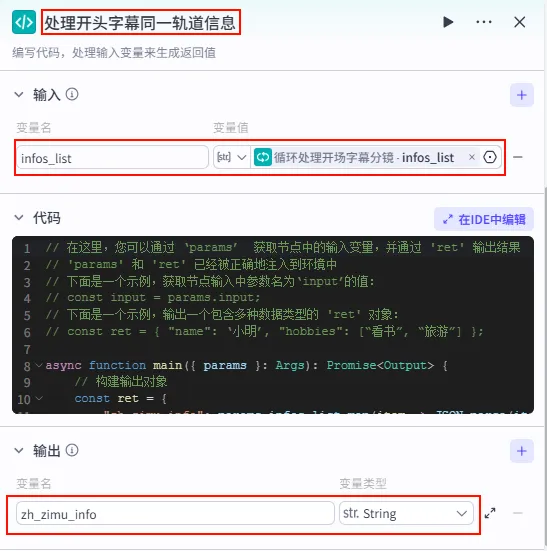
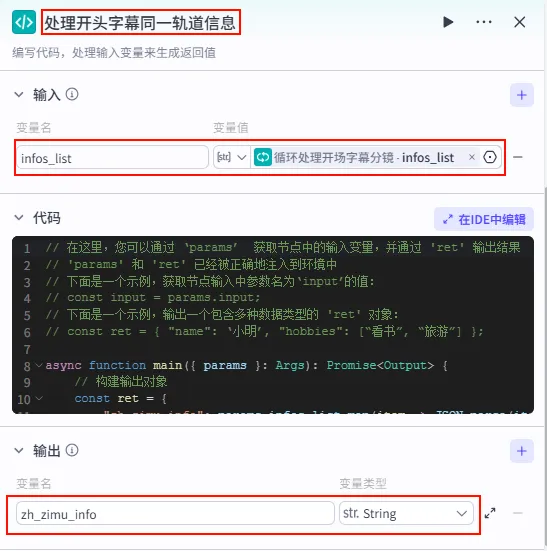
步骤 1.37:处理开头字幕同一轨道信息 (代码)
循环结束后,我们需要将所有迭代产生的分镜参数聚合在一起,并进行最终的格式转换,以便后续直接合成视频。
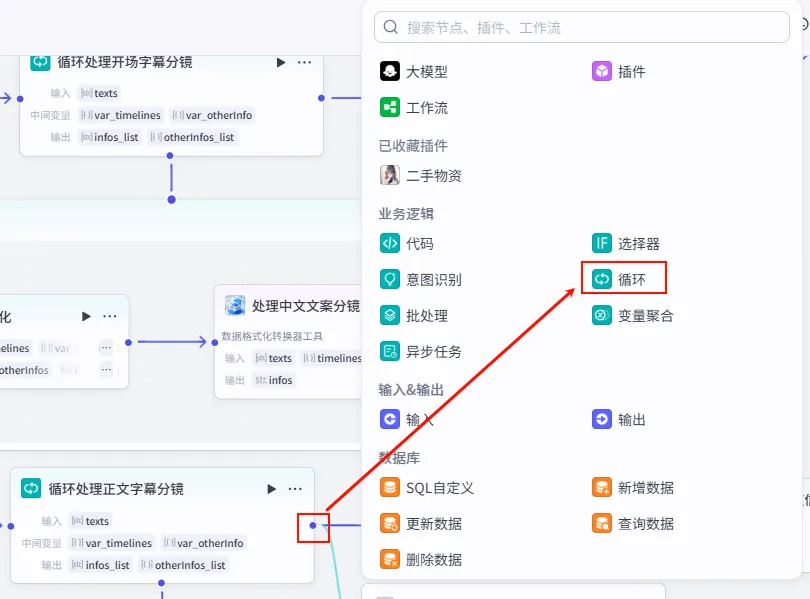
操作步骤:点击 循环处理开场字幕分镜整个大节点后的 + 号,选择 代码。
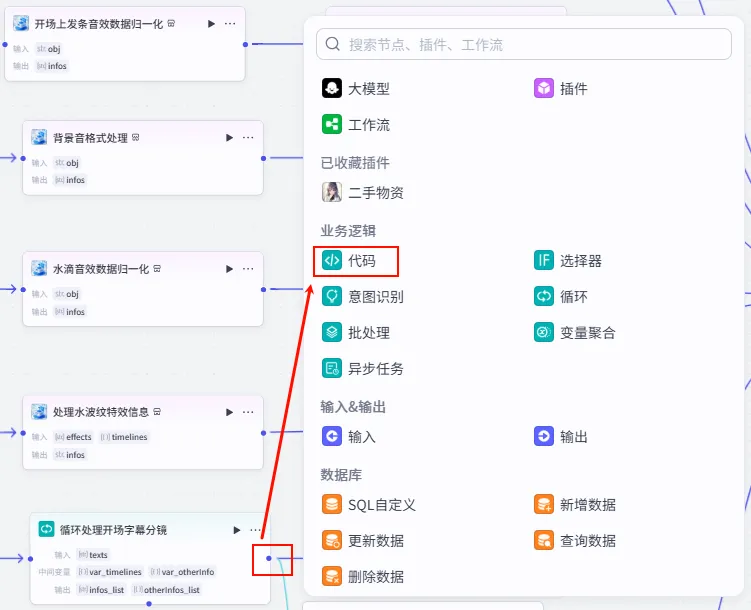
配置要点: infos_list: 引用循环处理开场字幕分镜.infos_list。节点名称: 处理开头字幕同一轨道信息。输入变量: 输出变量: zh_zimu_info(String 类型)。代码: (代码获取方式见文末)。
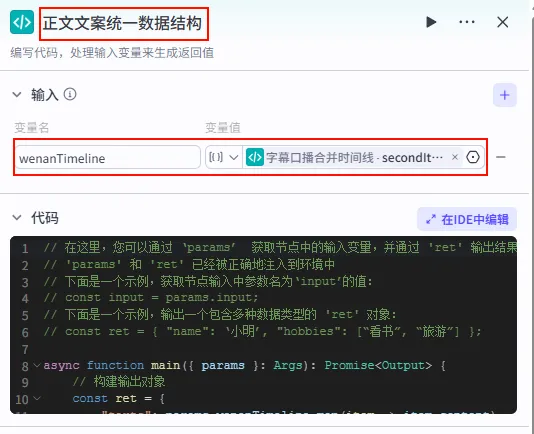
步骤 1.38:正文文案统一数据结构 (代码)
这是 字幕口播合并时间线 后的 第五个分支 (Branch 5 of 6),用于处理正文的第一段字幕分片,并将其格式化。
操作步骤:点击 字幕口播合并时间线节点后的 + 号 (拉出第五条下游分支),选择 代码。
配置要点: wenanTimeline: 引用字幕口播合并时间线.secondItems。节点名称: 正文文案统一数据结构。输入变量: 代码: (代码获取方式见文末)。
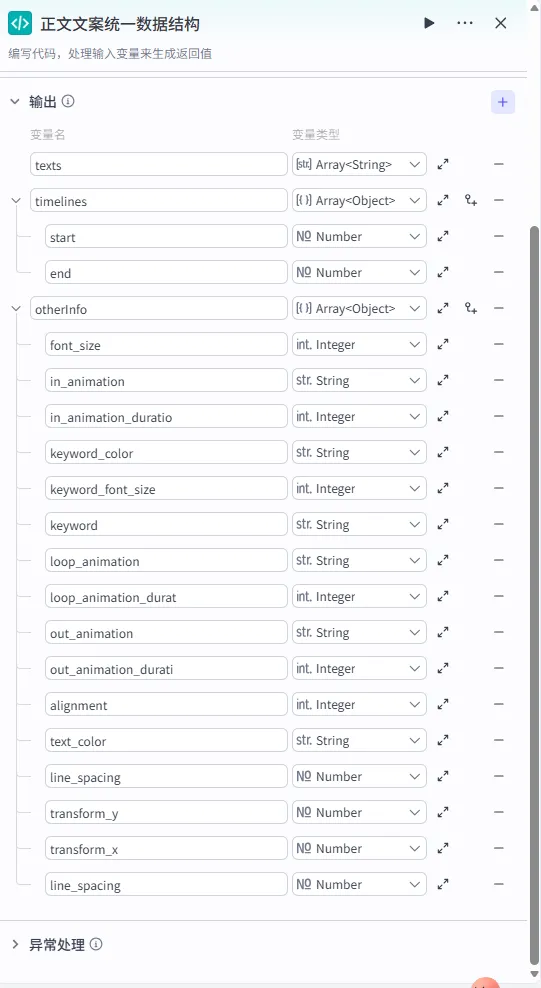
输出变量配置:此处的输出结构必须与 caption_infos插件所需的 Schema 严格对齐,包括丰富的样式和动画定义。
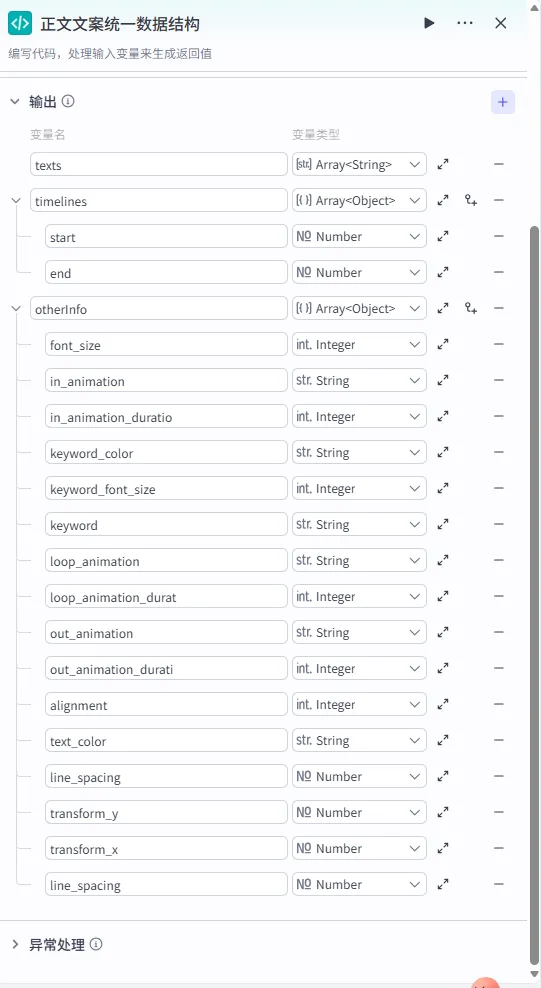
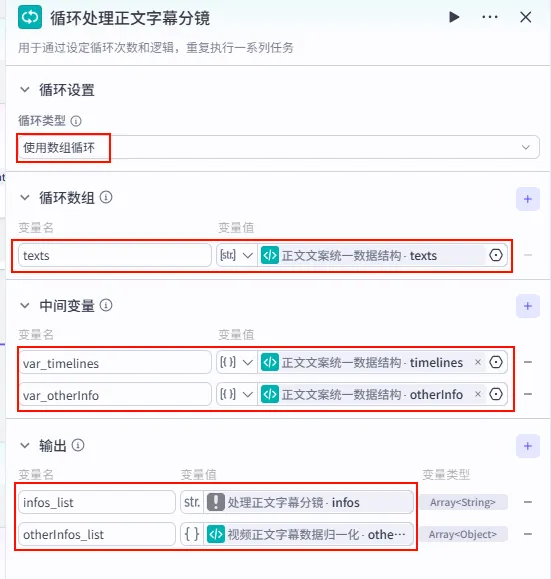
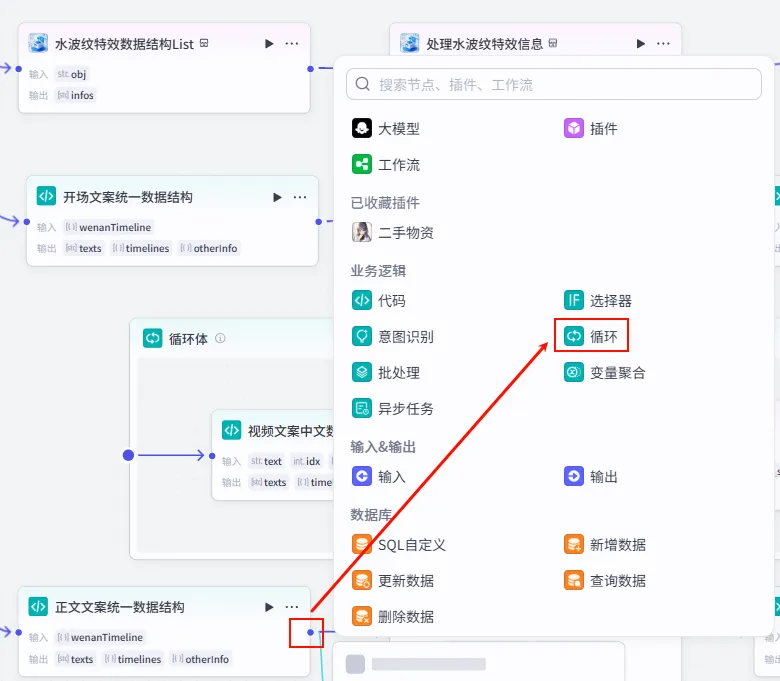
步骤 1.39:正文文案循环处理 (循环)
由于正文内容可能包含多行,我们需要通过循环节点来处理 texts 数组中的每一项。
操作步骤:点击 正文文案统一数据结构节点后的 + 号,选择 循环。确保循环体内的节点输出正确连接回循环出口。
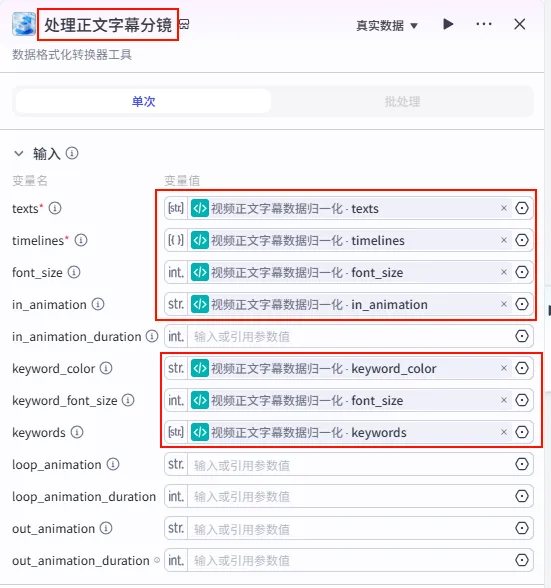
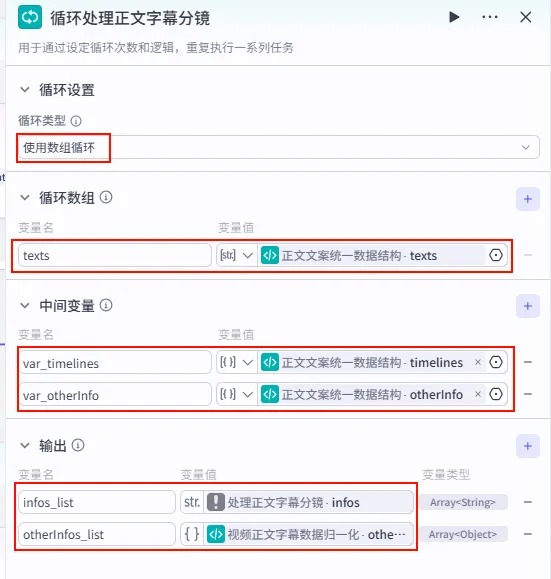
配置要点: infos_list: 引用处理正文字幕分镜.infos。otherInfos_list: 引用视频正文字幕数据归一化.otherInfos。var_timelines: 引用正文文案统一数据结构.timelines。var_otherInfo: 引用正文文案统一数据结构.otherInfo。节点名称: 循环处理正文字幕分镜。循环类型: 使用数组循环。循环数组: texts引用正文文案统一数据结构.texts。中间变量: 输出配置:
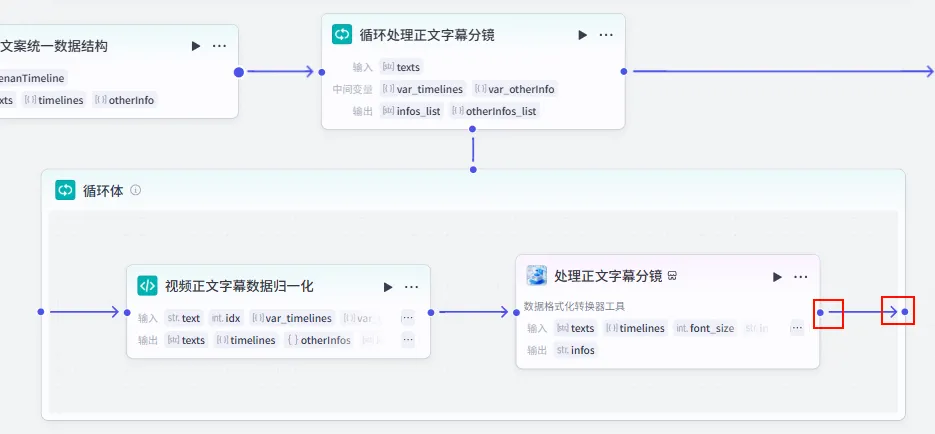
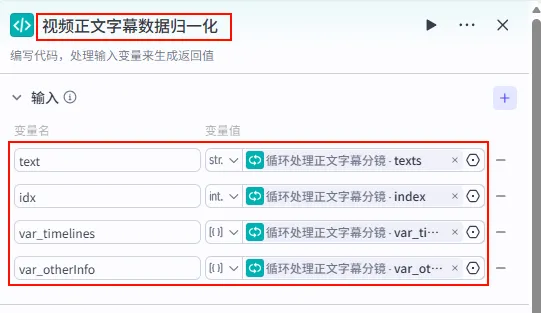
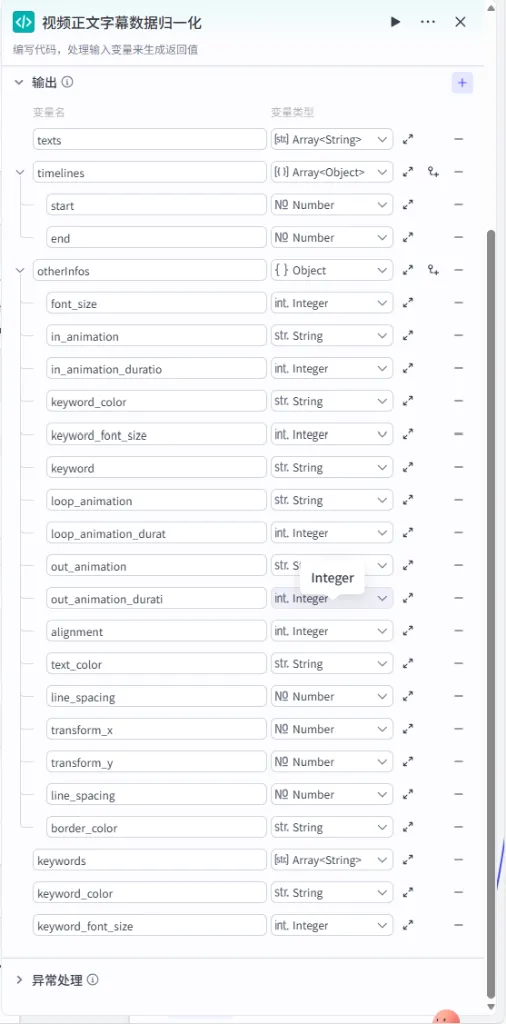
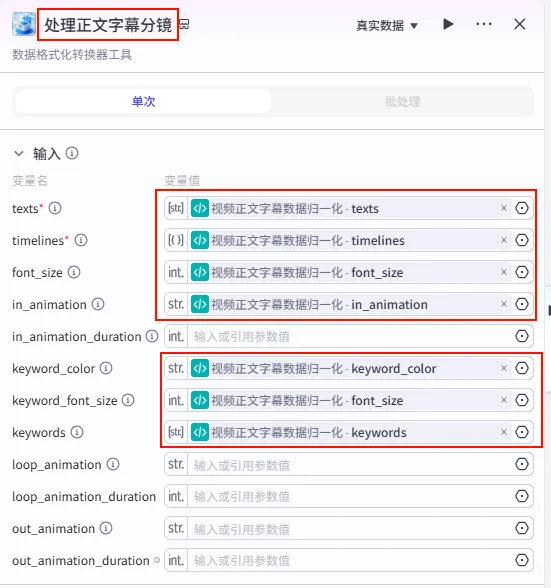
步骤 1.40:视频正文字幕数据归一化 (代码 - 循环内)
该节点位于正文循环体内,用于处理当前迭代的单行正文,并将其与全局样式信息结合。
操作步骤:在 正文文案循环处理内部,点击 + 号,选择 代码。
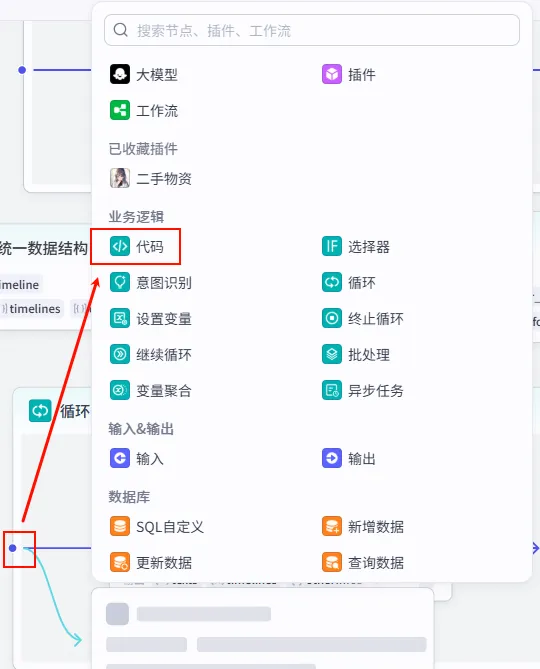
配置要点:
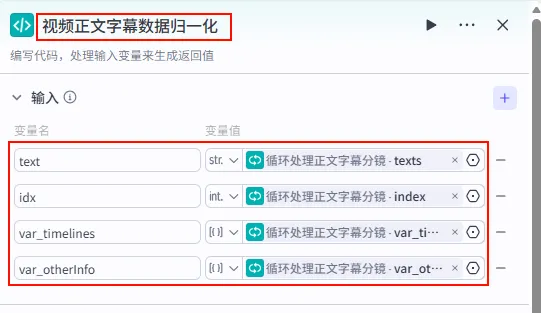
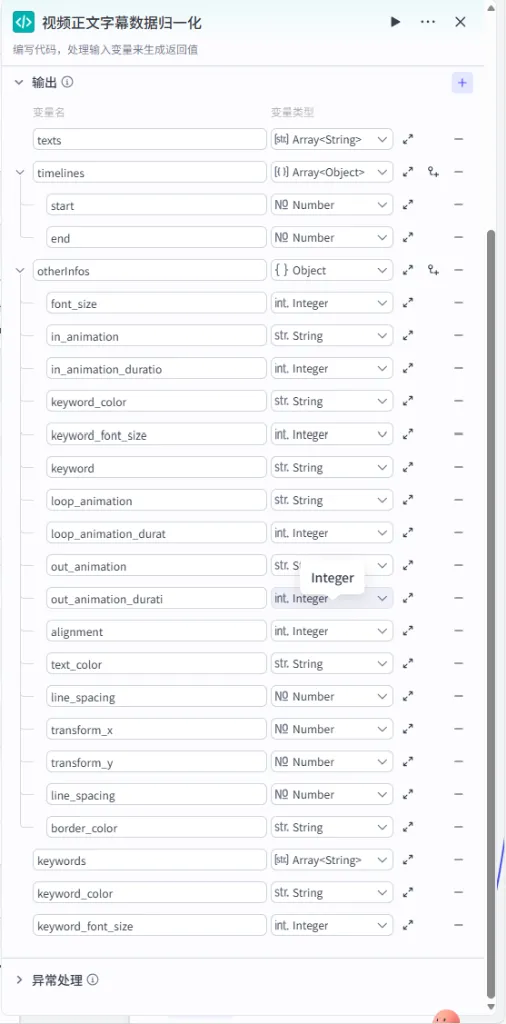
输出变量: 包含 texts,timelines,otherInfos(Object),keywords等详尽样式字段。代码: (代码获取方式见文末)。 text: 引用循环处理正文字幕分镜.texts。idx: 引用循环处理正文字幕分镜.index。var_timelines: 引用循环处理正文字幕分镜.var_timelines。var_otherInfo: 引用循环处理正文字幕分镜.var_otherInfo。节点名称: 视频正文字幕数据归一化。输入变量:
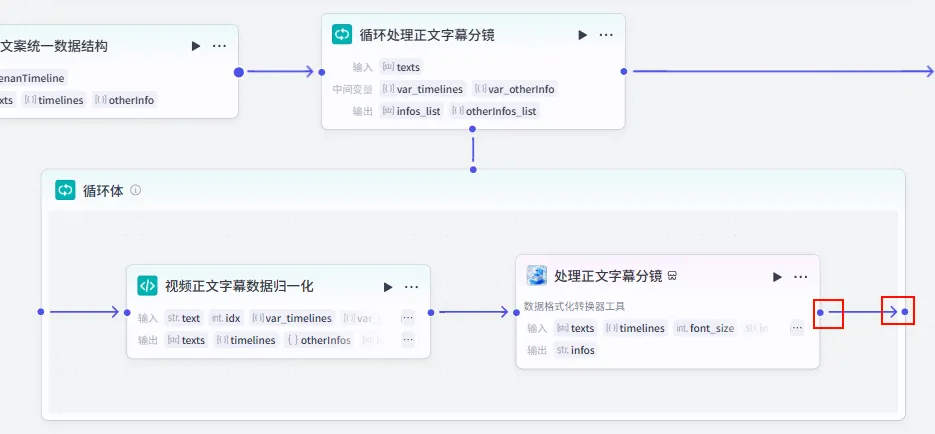
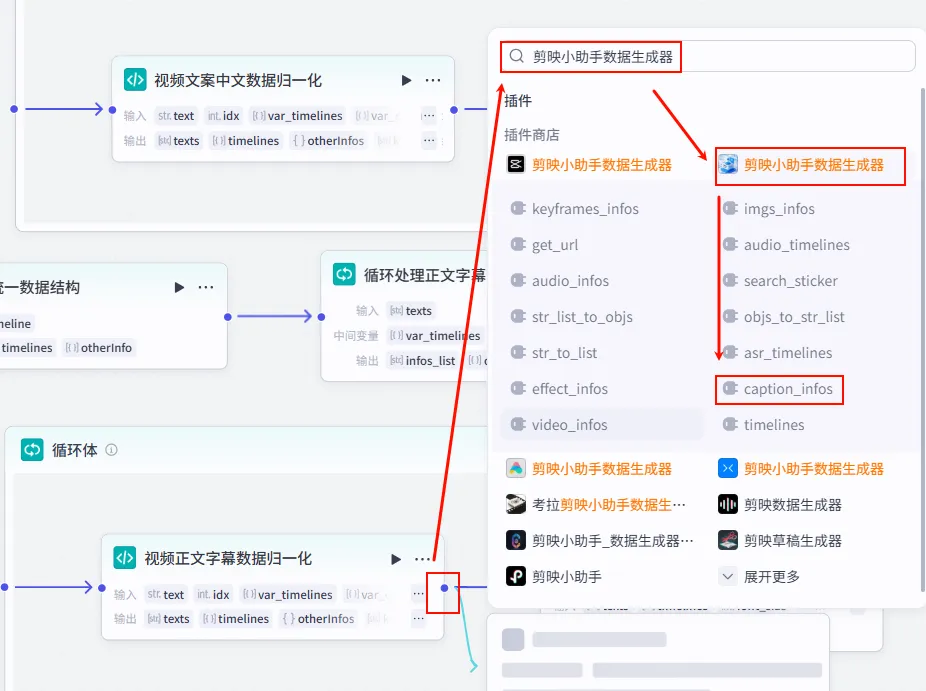
步骤 1.41:处理正文字幕分镜 (Plugin - 循环内)
这是正文循环体内的核心插件节点,负责将归一化后的每一行正文数据打包成剪映字幕分镜参数。
操作步骤:在正文循环体内,点击 视频正文字幕数据归一化节点后的 + 号,选择 插件 -> 剪映小助手数据生成器 -> caption_infos。
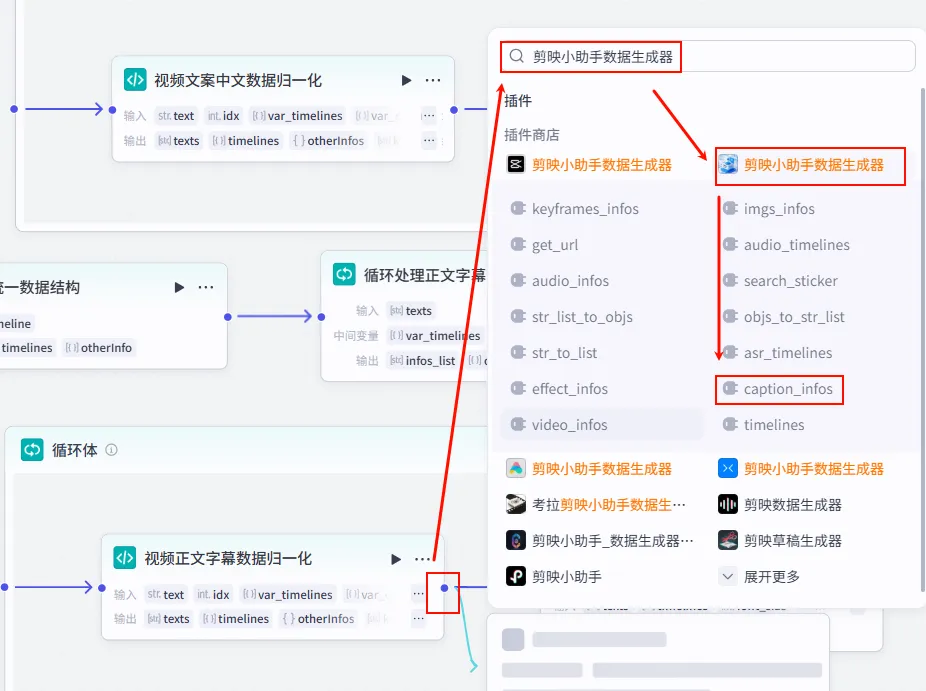
配置要点: 大部分参数通过引用 视频正文字幕数据归一化的输出获得。节点名称: 处理正文字幕分镜。输入变量: 输出: 获得单片正文字幕参数。
步骤 1.42:处理正文字幕同一轨道信息 (代码)
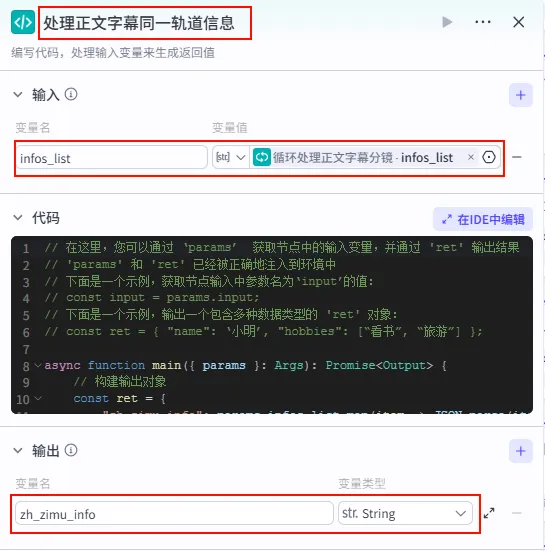
正文循环结束后,我们需要将迭代产生的多行正文字幕参数进行聚合。
操作步骤:点击 循环处理正文字幕分镜整个大节点后的 + 号,选择 代码。
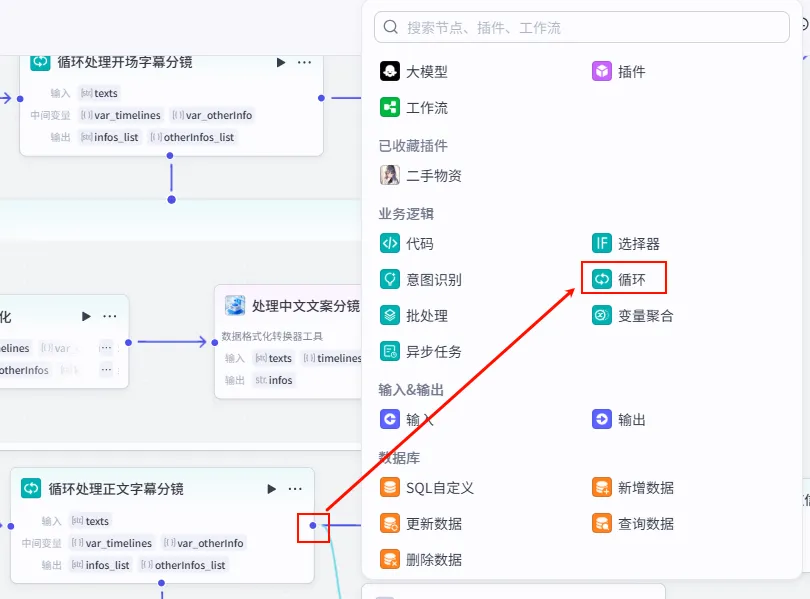
配置要点: infos_list: 引用循环处理正文字幕分镜.infos_list。节点名称: 处理正文字幕同一轨道信息。输入变量: 输出变量: zh_zimu_info(String 类型)。代码: (代码获取方式见文末)。
 为了适应后续插件的输入要求,需要将水滴音效字符串转换为列表格式。
为了适应后续插件的输入要求,需要将水滴音效字符串转换为列表格式。
操作步骤:点击 水滴音效素材节点后的 + 号,搜索 剪映小助手数据生成器 -> str_to_list。
配置要点: obj: 引用水滴音效素材.output(水滴音效字符串)。节点名称: 水滴音效数据归一化。输入变量: 输出: 获得水滴音效列表 ( Array<String>)。
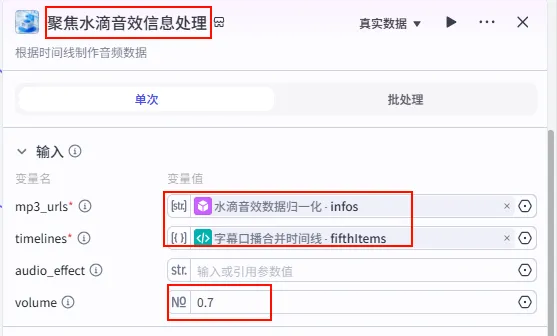
步骤 1.31:聚焦水滴音效信息处理 (Plugin)
这一步将水滴音效与特定的分段对齐(例如在视频结尾或某个核心观点处)。
操作步骤:点击 水滴音效数据归一化节点后的 + 号,搜索 剪映小助手数据生成器 -> audio_infos。需同时连接字幕口播合并时间线的fifthItems变量。
配置要点: mp3_urls: 引用水滴音效数据归一化.infos(水滴音效列表)。timelines: 引用字幕口播合并时间线.fifthItems(注意:这里引用的是第五组字幕时间轴)。volume: 设置为0.7。节点名称: 聚焦水滴音效信息处理。输入变量: 输出: 获得水滴音效的音轨参数 audio_infos。
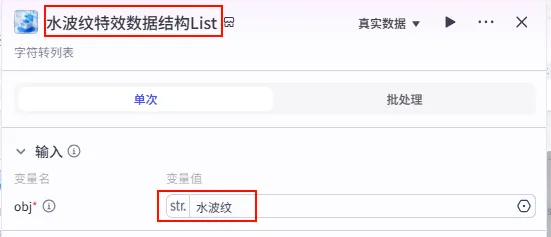
步骤 1.32:水波纹特效数据结构List (Plugin)
这是 字幕口播合并时间线 后的 第三个分支 (Branch 3 of 6),用于为视频准备特定的视觉特效(如水波纹)。
操作步骤:点击 字幕口播合并时间线节点后的 + 号 (拉出第三条下游分支),搜索 剪映小助手数据生成器 -> str_to_list。
配置要点: obj: 手动输入字符串水波纹。节点名称: 水波纹特效数据结构List。输入变量: 输出: 获得特效列表。
步骤 1.33:处理水波纹特效信息 (Plugin)
这一步将预设的特效名称与视频时间轴匹配,生成剪映可识别的特效指令。
操作步骤:点击 水波纹特效数据结构List节点后的 + 号,搜索 剪映小助手数据生成器 -> effect_infos。需同时连接字幕口播合并时间线的fifthItems变量。
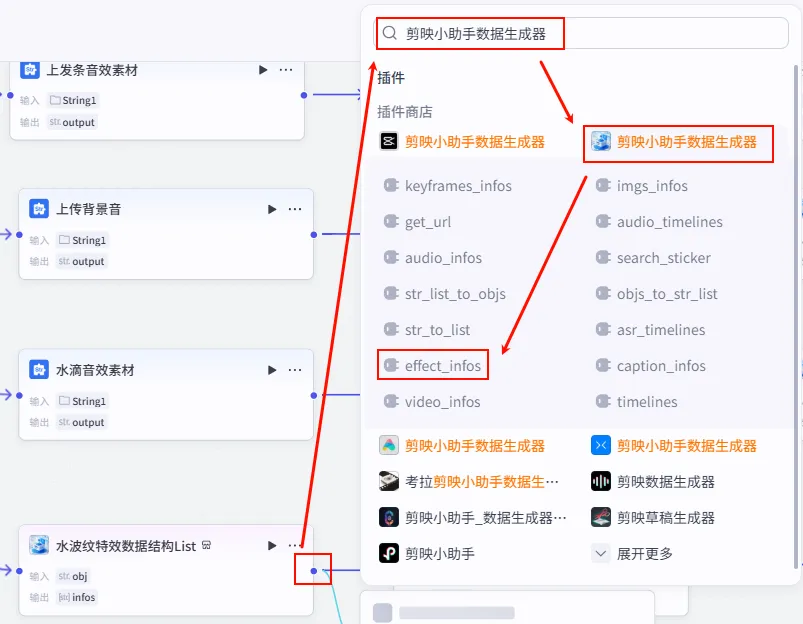
配置要点: effects: 引用水波纹特效数据结构List.infos(特效列表)。timelines: 引用字幕口播合并时间线.fifthItems(注意:这里引用的是第五组字幕时间轴)。节点名称: 处理水波纹特效信息。输入变量: 输出: 获得特效参数 effect_infos。
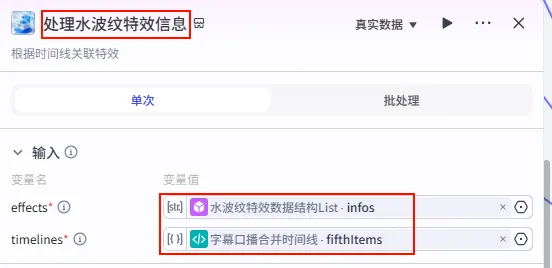
步骤 1.34:开场文案统一数据结构 (代码)
这是 字幕口播合并时间线 后的 第四个分支 (Branch 4 of 6),用于专门处理第一组字幕(通常包含书名、作者等信息),并将其包装成剪映插件所需的特定结构。
操作步骤:点击 字幕口播合并时间线节点后的 + 号 (拉出第四条下游分支),选择 代码。
配置要点: wenanTimeline: 引用字幕口播合并时间线.firstItems。节点名称: 开场文案统一数据结构。输入变量: 代码: (代码获取方式见文末)。
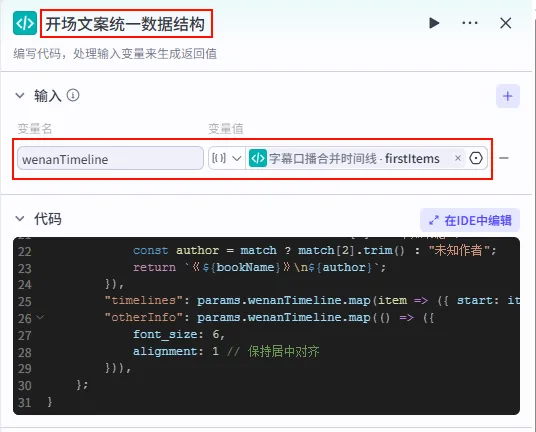
输出变量配置:为了让剪映插件能识别特定样式(如字体大小、对齐等),输出变量的结构需保持高度一致。
步骤 1.35:分段文案循环处理 (循环)
在开场文案数据结构化之后,我们需要通过循环节点来依次处理每一行字幕,将其转换为剪映可识别的指令格式。
操作步骤:点击 开场文案统一数据结构节点后的 + 号,选择 循环。将循环体内的节点输出连接回循环出口。
配置要点: infos_list: 引用处理中文文案分镜.infos。otherInfos_list: 引用视频文案中文数据归一化.otherInfos。var_timelines: 引用开场文案统一数据结构.timelines。var_otherInfo: 引用开场文案统一数据结构.otherInfo。节点名称: 循环处理开场字幕分镜。循环类型: 选择 使用数组循环。循环数组: texts引用开场文案统一数据结构.texts。中间变量 (用于在循环体内同步迭代): 输出配置 (收集循环体内所有节点的执行结果):
步骤 1.36:视频文案中文数据归一化 (代码 - 循环内)
该节点位于循环体内,用于处理循环迭代中的当前项数据(如单行文本、对应时间轴等),并将其标准化。
操作步骤:在 分段文案循环处理(循环) 节点内部,点击 + 号,选择 代码。
配置要点: text: 引用循环处理开场字幕分镜.texts(当前迭代文本)。idx: 引用循环处理开场字幕分镜.index(当前索引)。var_timelines: 引用循环处理开场字幕分镜.var_timelines。var_otherInfo: 引用循环处理开场字幕分镜.var_otherInfo。节点名称: 视频文案中文数据归一化。输入变量: 代码: (代码获取方式见文末)。
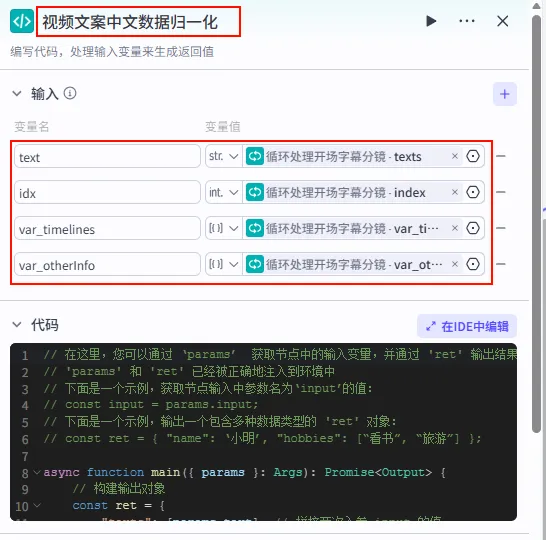
步骤 1.37:处理中文文案分镜 (Plugin - 循环内)
这是循环体内的核心插件节点,负责将归一化后的数据打包成剪映字幕分镜。
操作步骤:在循环体内,点击 视频文案中文数据归一化节点后的 + 号,搜索 剪映小助手数据生成器 -> caption_infos。
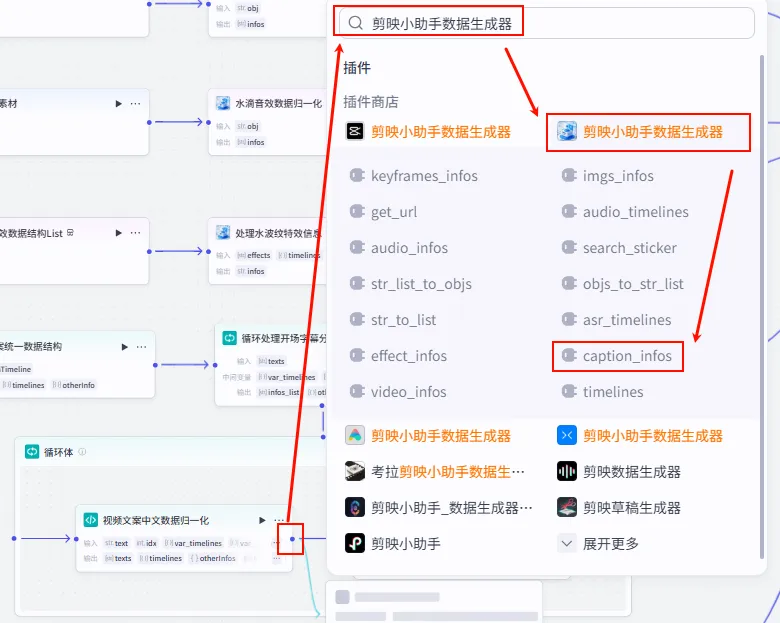
配置要点: 大部分参数(如 texts,timelines,font_size,keywords等)均通过引用视频文案中文数据归一化的输出获得。节点名称: 处理中文文案分镜。输入变量: 输出: 获得单分片字幕参数。
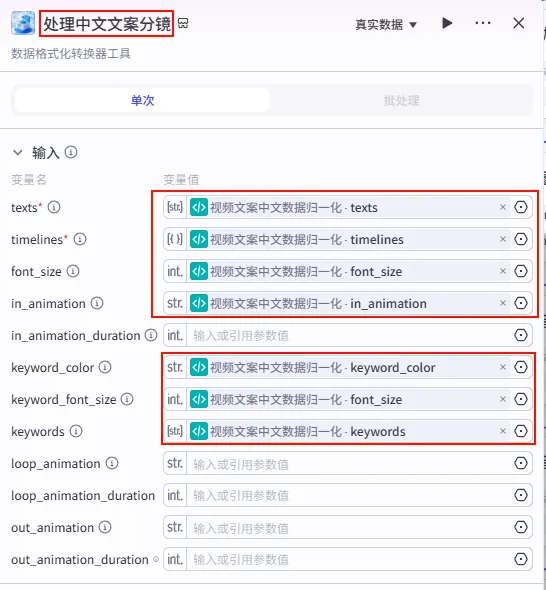
步骤 1.38:处理开头字幕同一轨道信息 (代码)
循环结束后,我们需要将所有迭代产生的分镜参数聚合在一起,并进行最终的格式转换,以便后续直接合成视频。
操作步骤:点击 循环处理开场字幕分镜整个大节点后的 + 号,选择 代码。
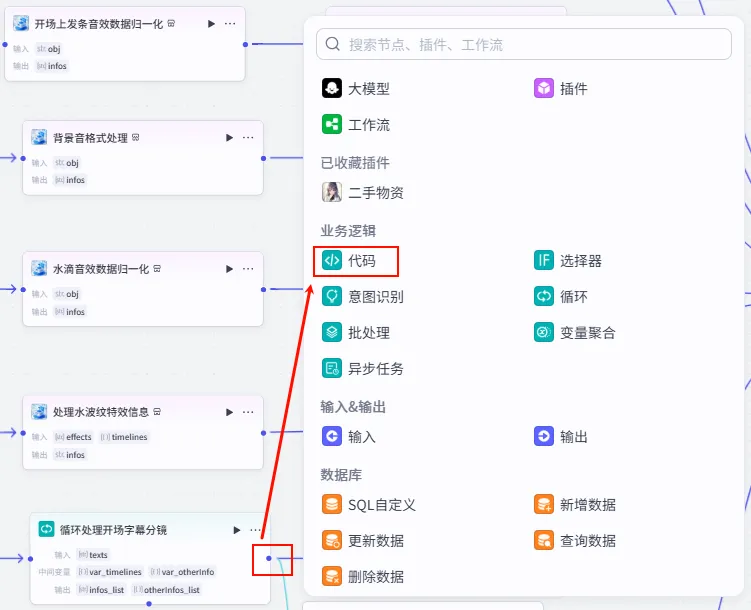
配置要点: infos_list: 引用循环处理开场字幕分镜.infos_list。节点名称: 处理开头字幕同一轨道信息。输入变量: 输出变量: zh_zimu_info(String 类型)。代码: (代码获取方式见文末)。
步骤 1.39:正文文案统一数据结构 (代码)
这是 字幕口播合并时间线 后的 第五个分支 (Branch 5 of 6),用于处理正文的第一段字幕分片,并将其格式化。
操作步骤:点击 字幕口播合并时间线节点后的 + 号 (拉出第五条下游分支),选择 代码。
配置要点: wenanTimeline: 引用字幕口播合并时间线.secondItems。节点名称: 正文文案统一数据结构。输入变量: 代码: (代码获取方式见文末)。
输出变量配置:此处的输出结构必须与 caption_infos插件所需的 Schema 严格对齐,包括丰富的样式和动画定义。
步骤 1.40:正文文案循环处理 (循环)
由于正文内容可能包含多行,我们需要通过循环节点来处理 texts 数组中的每一项。
操作步骤:点击 正文文案统一数据结构节点后的 + 号,选择 循环。确保循环体内的节点输出正确连接回循环出口。
配置要点: infos_list: 引用处理正文字幕分镜.infos。otherInfos_list: 引用视频正文字幕数据归一化.otherInfos。var_timelines: 引用正文文案统一数据结构.timelines。var_otherInfo: 引用正文文案统一数据结构.otherInfo。节点名称: 循环处理正文字幕分镜。循环类型: 使用数组循环。循环数组: texts引用正文文案统一数据结构.texts。中间变量: 输出配置:
步骤 1.41:视频正文字幕数据归一化 (代码 - 循环内)
该节点位于正文循环体内,用于处理当前迭代的单行正文,并将其与全局样式信息结合。
操作步骤:在 正文文案循环处理内部,点击 + 号,选择 代码。
配置要点:
输出变量: 包含 texts,timelines,otherInfos(Object),keywords等详尽样式字段。代码: (代码获取方式见文末)。 text: 引用循环处理正文字幕分镜.texts。idx: 引用循环处理正文字幕分镜.index。var_timelines: 引用循环处理正文字幕分镜.var_timelines。var_otherInfo: 引用循环处理正文字幕分镜.var_otherInfo。节点名称: 视频正文字幕数据归一化。输入变量:
步骤 1.42:处理正文字幕分镜 (Plugin - 循环内)
这是正文循环体内的核心插件节点,负责将归一化后的每一行正文数据打包成剪映字幕分镜参数。
操作步骤:在正文循环体内,点击 视频正文字幕数据归一化节点后的 + 号,选择 插件 -> 剪映小助手数据生成器 -> caption_infos。
配置要点: 大部分参数通过引用 视频正文字幕数据归一化的输出获得。节点名称: 处理正文字幕分镜。输入变量: 输出: 获得单片正文字幕参数。
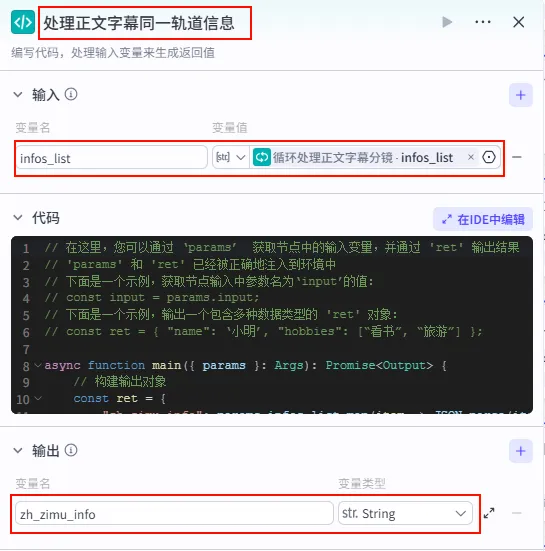
步骤 1.43:处理正文字幕同一轨道信息 (代码)
正文循环结束后,我们需要将迭代产生的多行正文字幕参数进行聚合。
操作步骤:点击 循环处理正文字幕分镜整个大节点后的 + 号,选择 代码。
配置要点: infos_list: 引用循环处理正文字幕分镜.infos_list。节点名称: 处理正文字幕同一轨道信息。输入变量: 输出变量: zh_zimu_info(String 类型)。代码: (代码获取方式见文末)。
Branch 6:文案分段 (LLM Process)
基于 字幕口播合并时间线 节点的 fourthItems 输出,对剩余的口播文案进行语义化分段合并(最多 5 段),以便后续生成对应的视觉分镜。
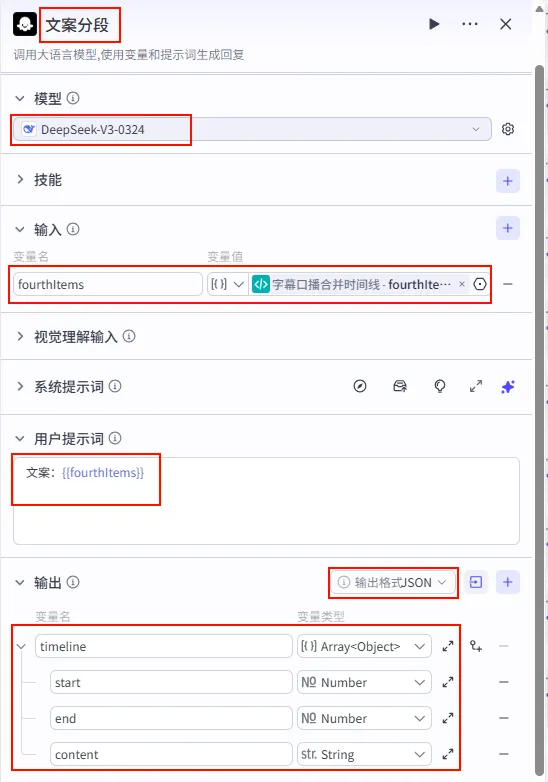
步骤 1.43:文案分段 (LLM)
将离散的字幕句子按语义和情绪逻辑进行合并。
操作步骤:点击
字幕口播合并时间线节点后的 + 号,选择 大模型。配置要点:
输出方式: JSON。Schema: start(Number)end(Number)content(String)timeline(Array<Object>)fourthItems:引用字幕口播合并时间线的fourthItems。节点名称: 文案分段。模型: DeepSeek-V3-0324。输入参数: 系统提示词:(代码获取方式见文末)。 用户提示词: 文案:{{fourthItems}}输出配置:
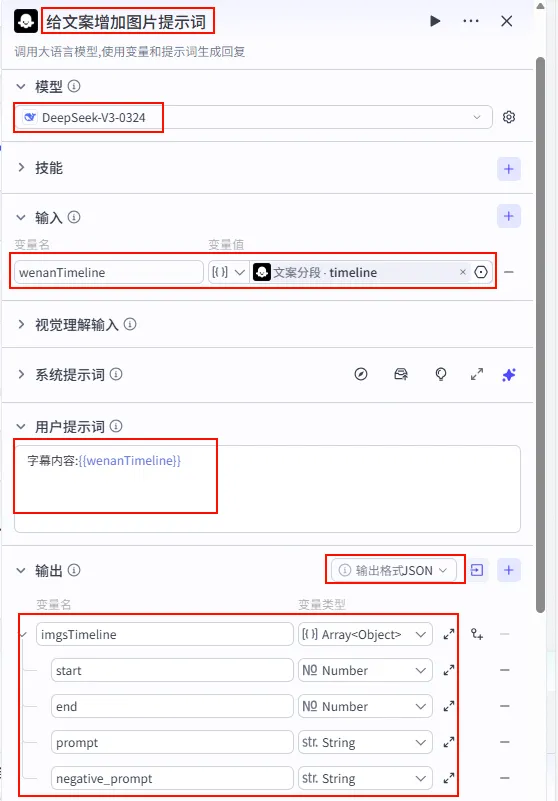
步骤 1.44:给文案增加图片提示词 (LLM)
将分段后的文案转换为 AI 绘画所需的英文提示词。
操作步骤:点击
文案分段节点后的 + 号,选择 大模型。配置要点:
输出方式: JSON。Schema: start(Number)end(Number)prompt(String)negative_prompt(String)imgsTimeline(Array<Object>)wenanTimeline:引用文案分段的timeline。节点名称: 给文案增加图片提示词。模型: DeepSeek-V3-0324。输入参数: 系统提示词:(代码获取方式见文末)。 用户提示词: 字幕信息:{{wenanTimeline}}输出配置:
步骤 1.45:循环生成图片以及分镜信息 (Loop)
遍历每个图片提示词,批量生成图片并构建分镜信息。
操作步骤:点击 给文案增加图片提示词节点后的 + 号,选择 循环。
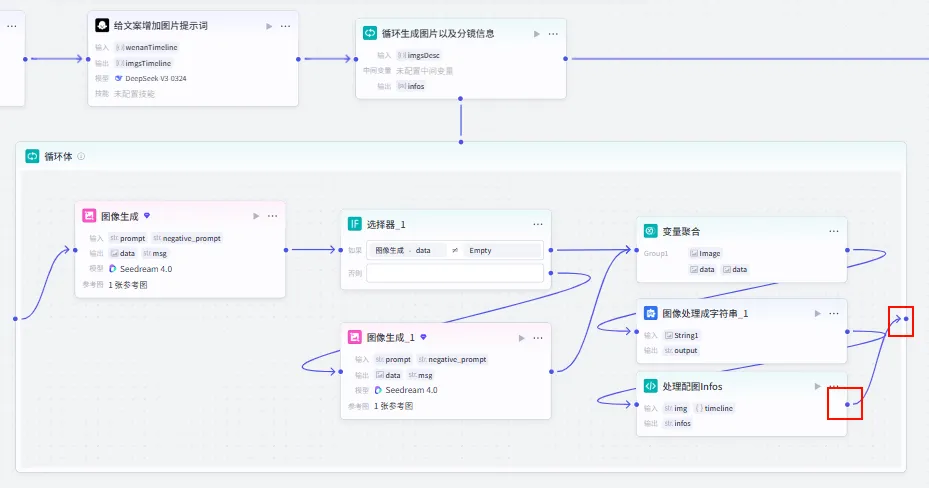
配置要点: infos:引用处理配图Infos.infos(收集循环体内生成的分镜信息列表)。图片生成节点。 数据处理节点。 节点名称: 循环生成图片以及分镜信息。循环类型:数组循环。 循环数组:引用 给文案增加图片提示词的imgsTimeline。循环体内节点: 输出收集:
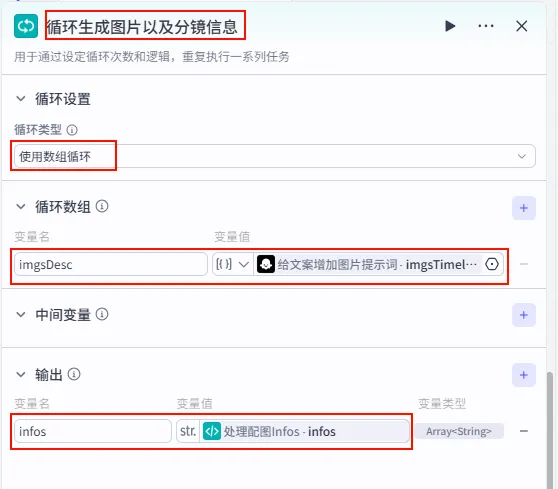
步骤 1.45.1:图像生成 (循环体内)
在循环体内,使用 AI 绘画模型根据提示词生成图片。
操作步骤:在
循环生成图片以及分镜信息循环体内部,点击 + 号,搜索并选择 图像生成。配置要点:
宽高比:9:16 (竖屏)。 生成数量:1。 prompt:引用循环变量imgsDesc.prompt。negative_prompt:引用循环变量imgsDesc.negative_prompt。节点类型:图像生成。 模型:ByteWeb (或其他图像生成模型)。 输入参数: 生成参数: 输出:生成的图片 URL。
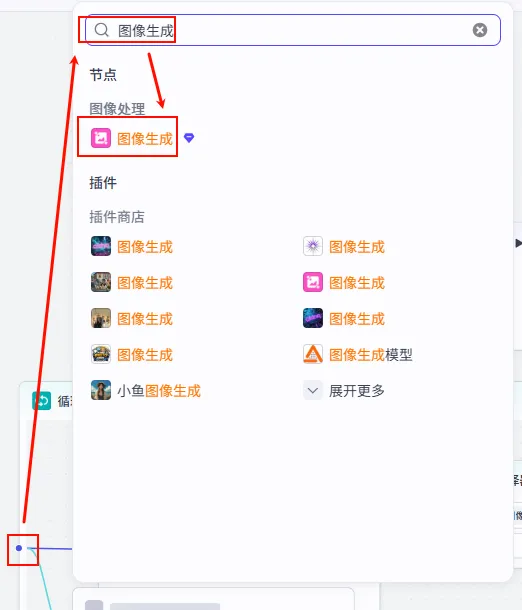
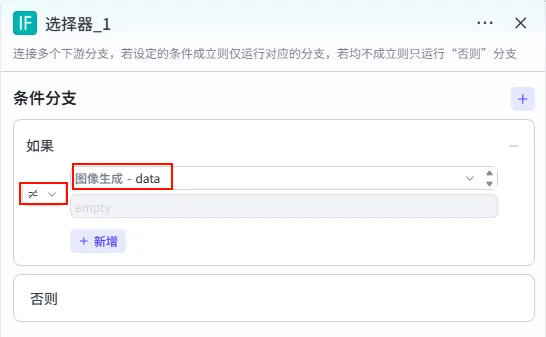
步骤 1.45.2:选择器 (循环体内)
判断图像生成是否成功,如果失败则进入重试分支。
操作步骤:在循环体内,点击 图像生成节点后的 + 号,选择 选择器。
配置要点: 如果: 图像生成.data不为空 (≠ empty)。则: 继续后续处理。 否则: 进入重试分支。 节点类型:选择器 (IF)。 条件判断:
步骤 1.45.2.1:图像生成_1 (重试 - 否则分支)
在选择器的"否则"分支中,如果第一次生成失败,则进行重试。
操作步骤:在选择器的 否则 分支中,点击 + 号,搜索并选择 图像生成。
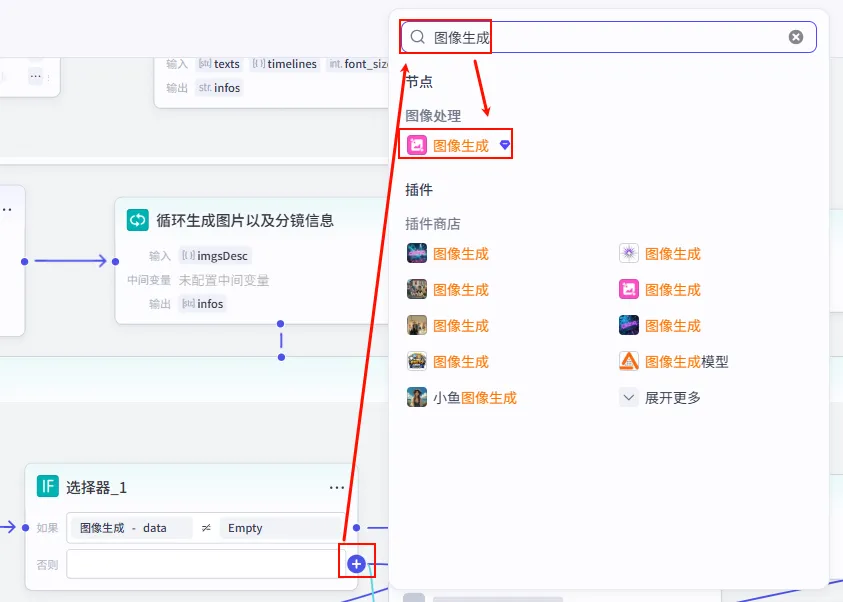
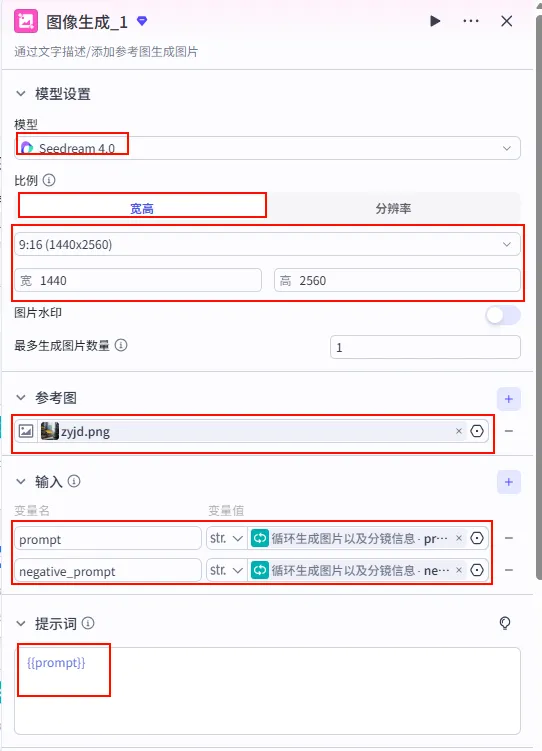
配置要点: 比例:宽高 (9:16, 1440x2560)。 生成数量:1。 参考图:可选。 prompt:引用循环变量imgsDesc.prompt。negative_prompt:引用循环变量imgsDesc.negative_prompt。节点类型:图像生成。 模型:Seedream 4.0。 输入参数: 生成参数: 输出:生成的图片 URL。
步骤 1.45.3:变量聚合 (循环体内)
合并选择器两个分支的图像生成结果。
操作步骤:在循环体内,点击选择器的"如果"分支和"否则"分支后的 + 号,选择 变量聚合,将两个分支连接到同一个变量聚合节点。
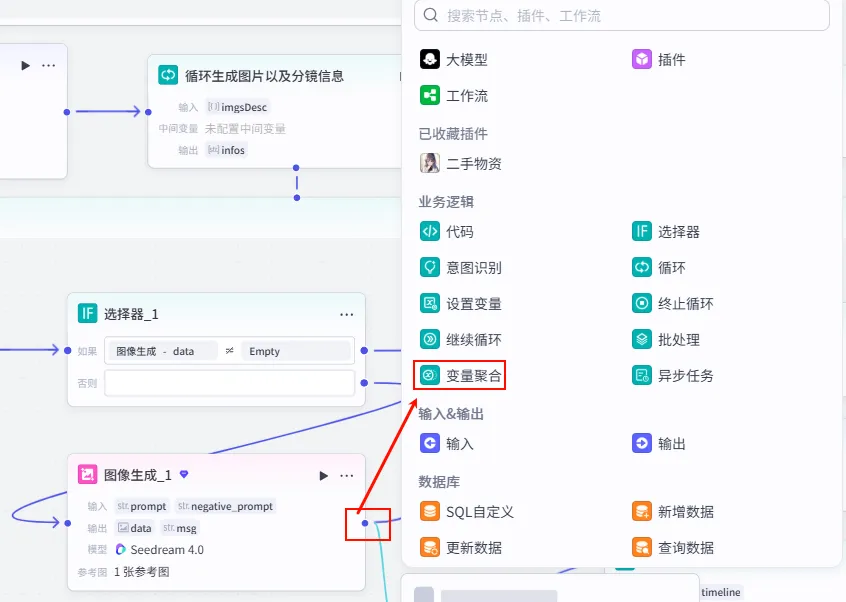
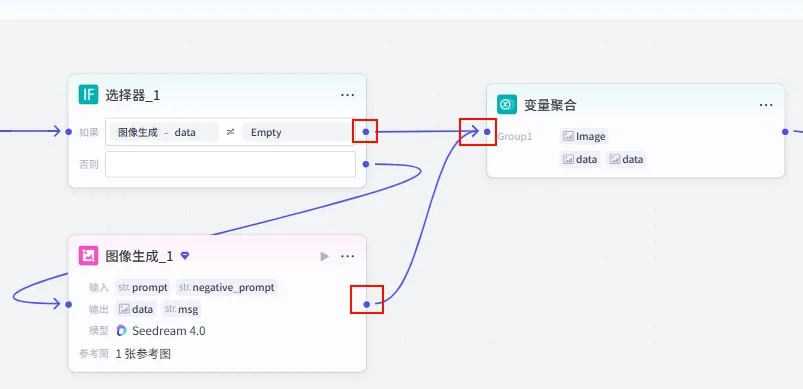
配置要点: Group1 - image: 图像生成.data图像生成_1.data节点名称: 变量聚合。聚合策略:返回各个分组中第一个非空的值。 分组配置:
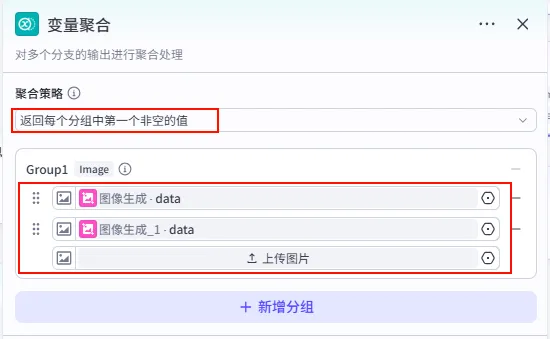
步骤 1.45.3.1:图像处理成字符串 (文本处理 - 循环体内)
将变量聚合输出的全部图片结果转换为字符串格式,方便后续处理。
操作步骤:在 变量聚合节点后添加 文本处理 节点。
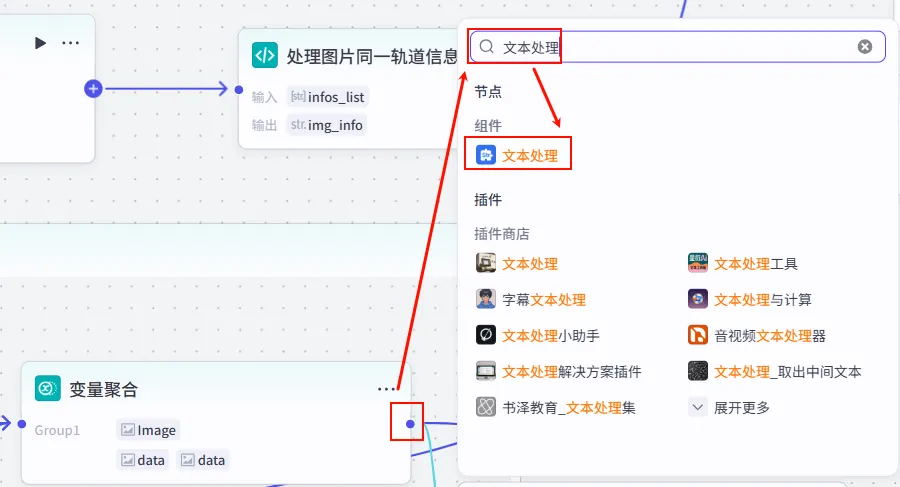
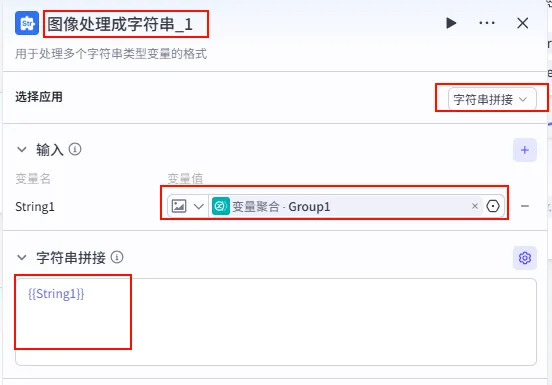
配置要点: String1:引用变量聚合.Group1。节点名称: 图像处理成字符串_1。选择应用:字符串拼接。 输入变量: 字符串拼接: {{String1}}。
步骤 1.45.4:处理配图Infos (代码 - 循环体内)
将变量聚合输出的图片 URL 和当前循环的时间线信息组装成 JSON 分镜片段。
操作步骤:在 图像处理成字符串节点后添加 代码 节点。
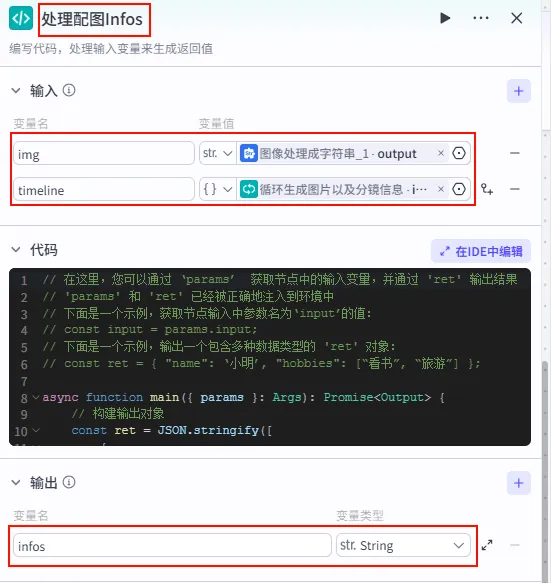
配置要点: img: 引用图像处理成字符串_1.output。timeline: 引用循环变量imgsDesc。节点名称: 处理配图Infos。输入变量: 输出: infos(String, JSON 格式的分镜片段)。代码:(代码获取方式见文末)。
步骤 1.46:处理图片同一轨道信息 (代码)
循环结束后,将所有迭代产生的图片分镜参数聚合在一起,并进行最终的格式转换。
操作步骤:点击 循环生成图片以及分镜信息整个大节点后的 + 号,选择 代码。
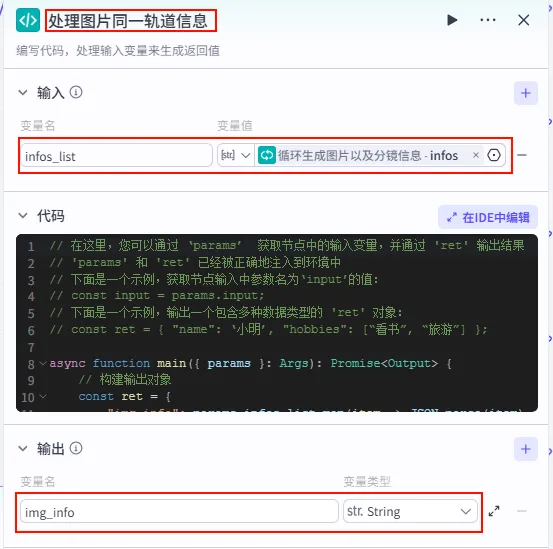
配置要点: infos_list:引用循环生成图片以及分镜信息.infos。节点名称: 处理图片同一轨道信息。输入变量: 输出: img_info(String, 聚合后的图片轨道信息)。代码:(代码获取方式见文末)。
步骤 1.47:创建剪映视频草稿 (Create Draft)
这是整个工作流的最终汇聚点,所有的音频、视频、字幕、特效以及图片轨道信息都在这里汇总,生成最终的剪映草稿。
操作步骤:点击 处理图片同一轨道信息节点后的 + 号,搜索 视频合成_剪映小助手 -> create_draft。
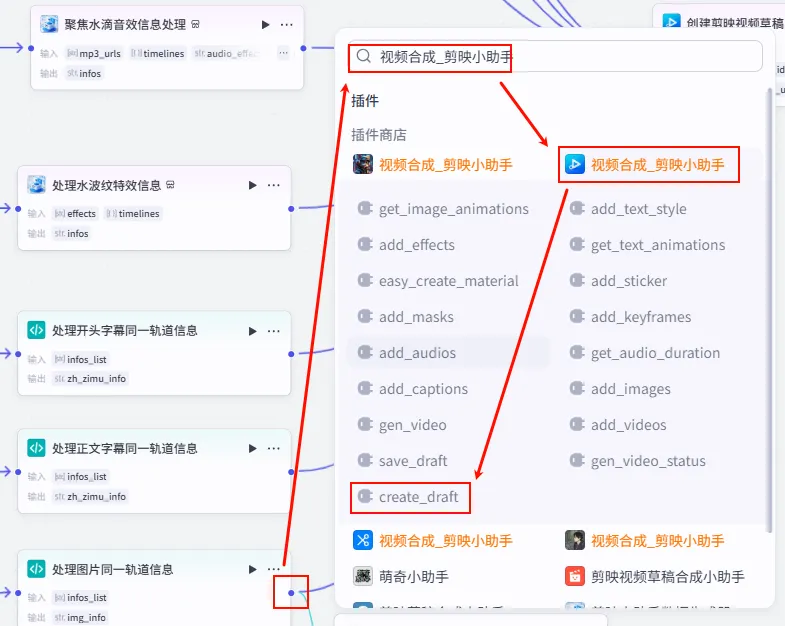
连接配置:作为最后一步,将之前所有并行处理的分支结果连接到 create_draft节点。
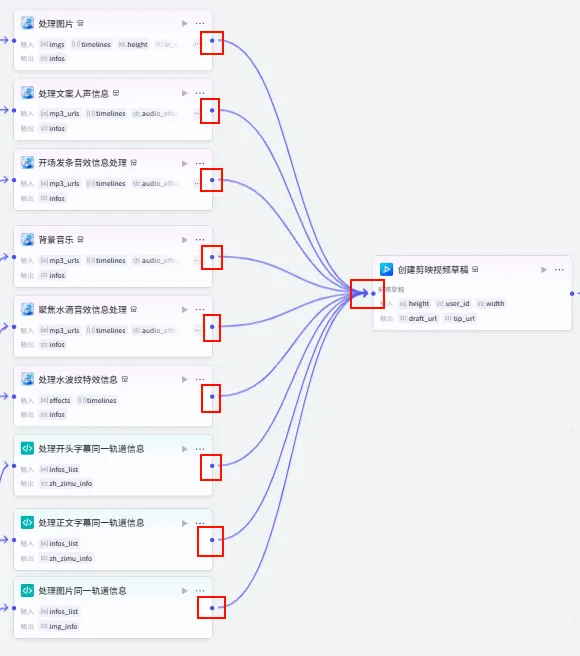
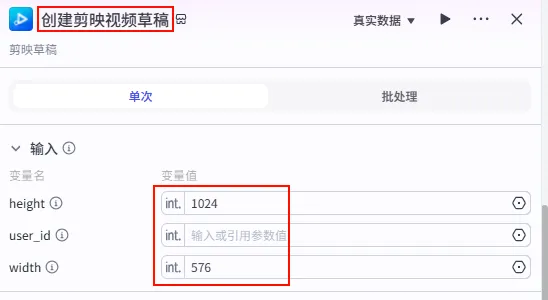
配置要点: height: 1024 (或 1920)。width: 576 (或 1080)。user_id: (选填) 调试时可填入自己的 ID,生产环境可不填或动态获取。节点名称: 创建剪映视频草稿。参数配置: 输入变量连接 (汇聚 9 路信号): 输出: draft_url。处理图片(infos) ->infos处理文案人声信息(infos) ->infos开场发条音效信息处理(infos) ->infos背景音乐(infos) ->infos聚焦水滴音效信息处理(infos) ->infos处理水波纹特效信息(infos) ->infos处理开头字幕同一轨道信息(zh_zimu_info) ->zh_zimu_info处理正文字幕同一轨道信息(zh_zimu_info) ->zh_zimu_info处理图片同一轨道信息(img_info) ->img_info
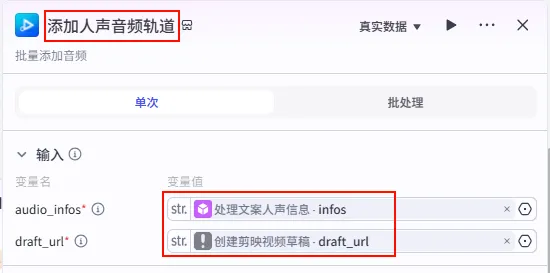
步骤 1.48:添加人声音频轨道 (Add Audios)
虽然 create_draft 可以汇聚大部分信息,但为了更精细的控制(或处理特定逻辑),我们有时会单独添加某些轨道。这里演示如何单独添加人声轨道。
操作步骤:点击 创建剪映视频草稿节点后的 + 号,搜索 视频合成_剪映小助手 -> add_audios。
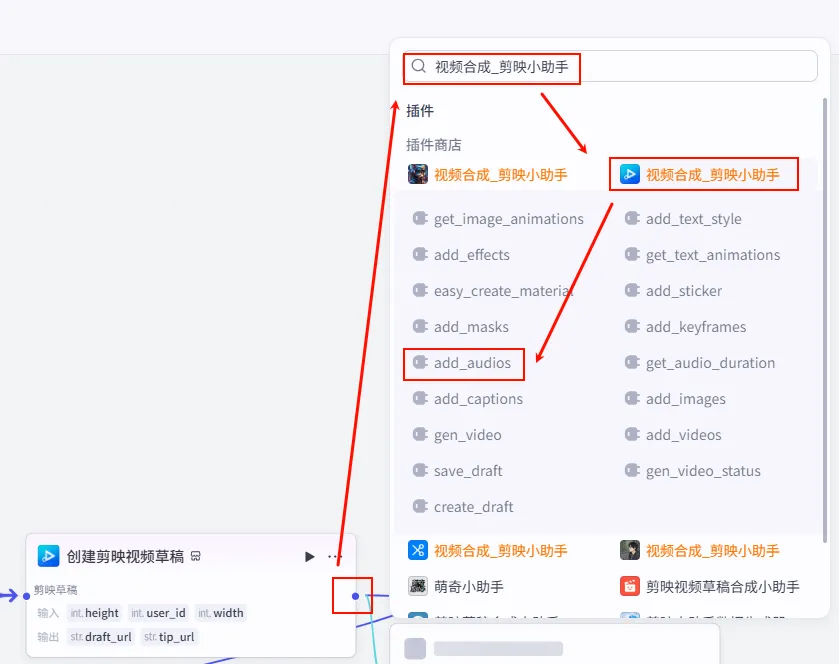
配置要点: audio_infos: 引用处理文案人声信息.infos。draft_url: 引用创建剪映视频草稿.draft_url。节点名称: 添加人声音频轨道。输入变量:
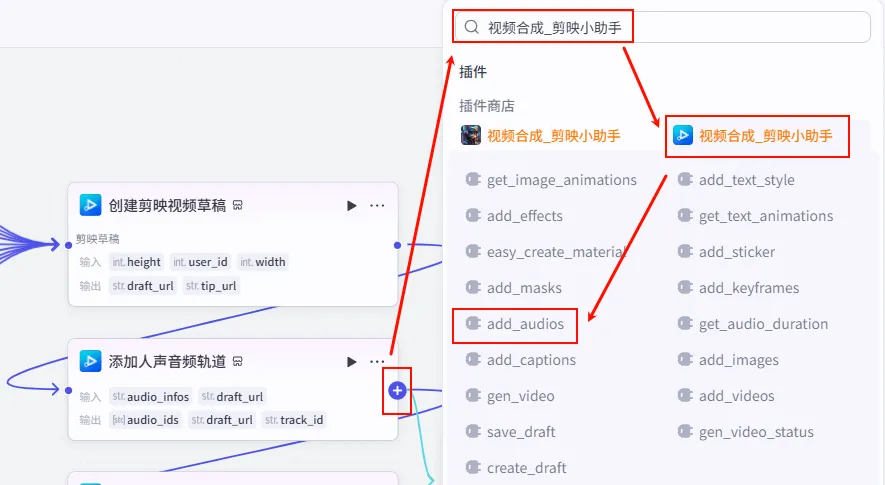
步骤 1.49:添加背景音乐轨道 (Add BGM)
接着,我们继续添加背景音乐轨道。注意,这里演示了链式添加的逻辑。
操作步骤:点击 添加人声音频轨道节点后的 + 号,再次选择 add_audios。
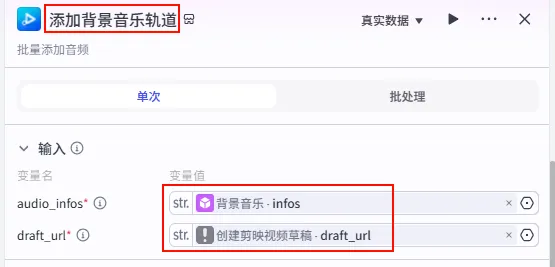
配置要点: audio_infos: 引用背景音乐.infos。draft_url: 依然引用创建剪映视频草稿.draft_url(始终指向最初的草稿容器)。节点名称: 添加背景音乐轨道。输入变量:
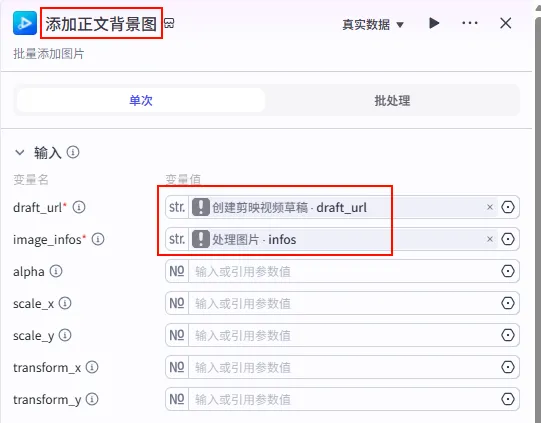
步骤 1.50:添加正文背景图 (Add Images)
音频轨道配置完成后,我们开始处理视频画面。首先是添加正文的背景图。
操作步骤:点击 添加背景音乐轨道节点后的 + 号,选择 add_images。
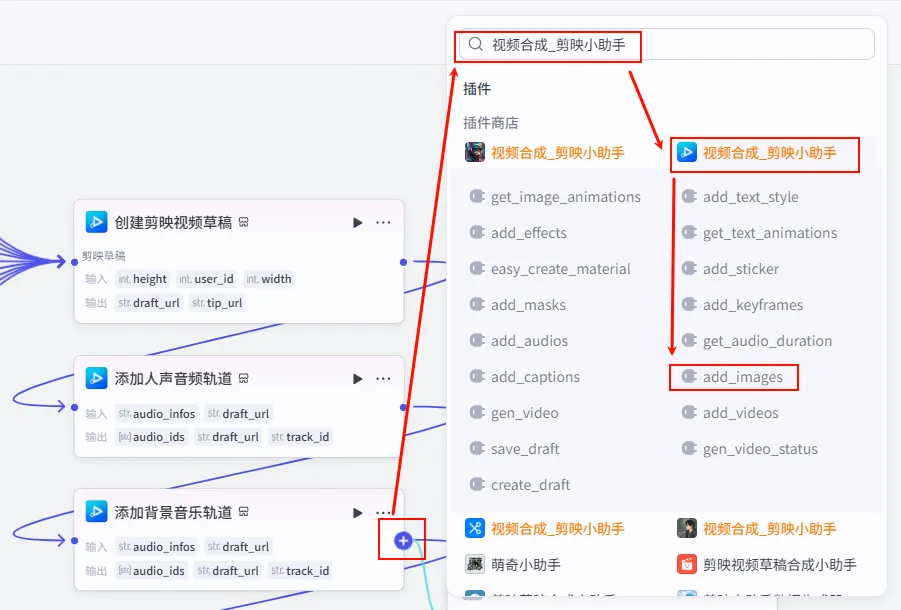
配置要点: draft_url: 引用创建剪映视频草稿.draft_url。image_infos: 引用处理图片.infos(这是第一条支线处理好的图片分镜信息)。节点名称: 添加正文背景图。输入变量:
步骤 1.51:添加开场发条音效轨道 (Add SFX)
背景图添加完毕后,我们再补充一些细节音效,比如开场的发条声,增加视频的趣味性。
操作步骤:点击 添加正文背景图节点后的 + 号,选择 add_audios。
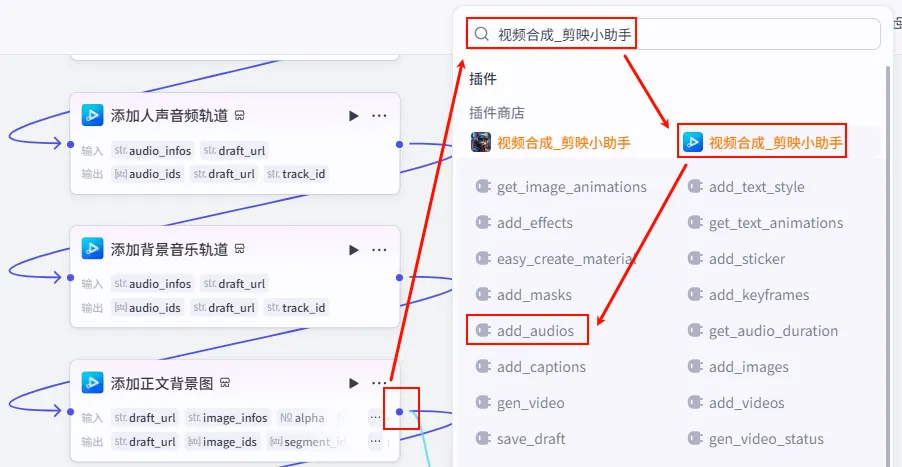
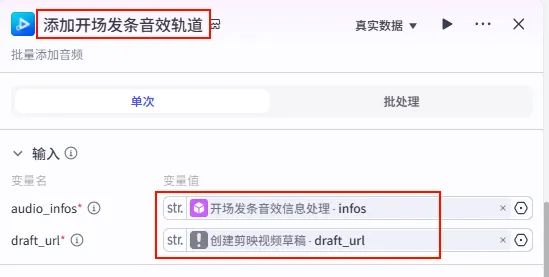
配置要点: audio_infos: 引用开场发条音效信息处理.infos。draft_url: 引用创建剪映视频草稿.draft_url。节点名称: 添加开场发条音效轨道。输入变量:
步骤 1.52:添加聚焦水滴音效轨道 (Add SFX)
为了配合书单内容的视觉焦点切换,我们添加一个“水滴”音效,提升精致感。
操作步骤:点击 添加开场发条音效轨道节点后的 + 号,选择 add_audios。
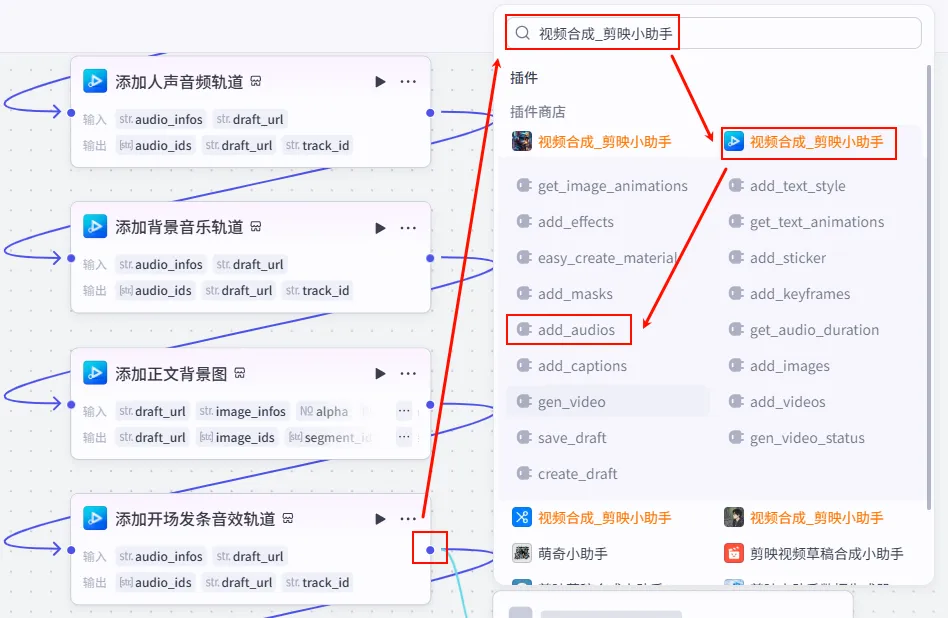
配置要点: audio_infos: 引用聚焦水滴音效信息处理.infos。draft_url: 引用创建剪映视频草稿.draft_url。节点名称: 添加聚焦水滴音效轨道。输入变量:
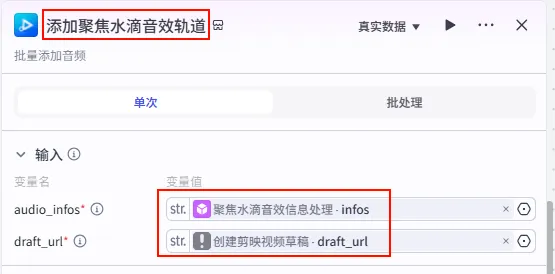
步骤 1.53:添加开场图以及齿轮转动图 (Add Opening & Gear Images)
这一步是将我们前面精心处理的“开场图”和“齿轮转动动画”添加到视频轨道中。注意,这里的图片信息是经过代码节点聚合处理过的。
操作步骤:点击 添加聚焦水滴音效轨道节点后的 + 号,选择 add_images。
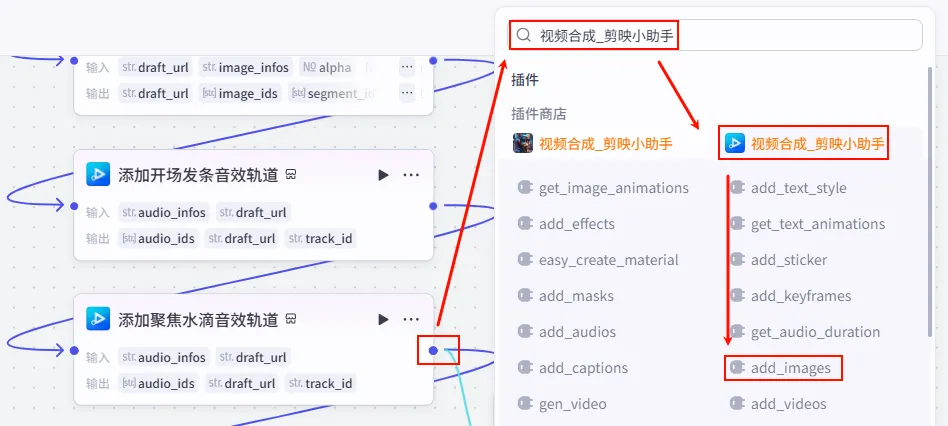
配置要点: draft_url: 引用创建剪映视频草稿.draft_url。image_infos: 引用处理图片同一轨道信息.img_info(注意来源:这是 Step 1.46 聚合后的信息)。节点名称: 添加开场图以及齿轮转动图。输入变量:
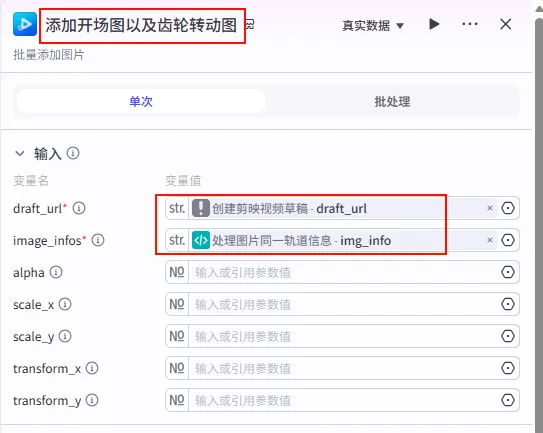
步骤 1.54:添加水波纹特效信息 (Add Effects)
为视频添加一层水波纹特效,增加梦幻感。
操作步骤:点击 添加开场图以及齿轮转动图节点后的 + 号,选择 add_effects。
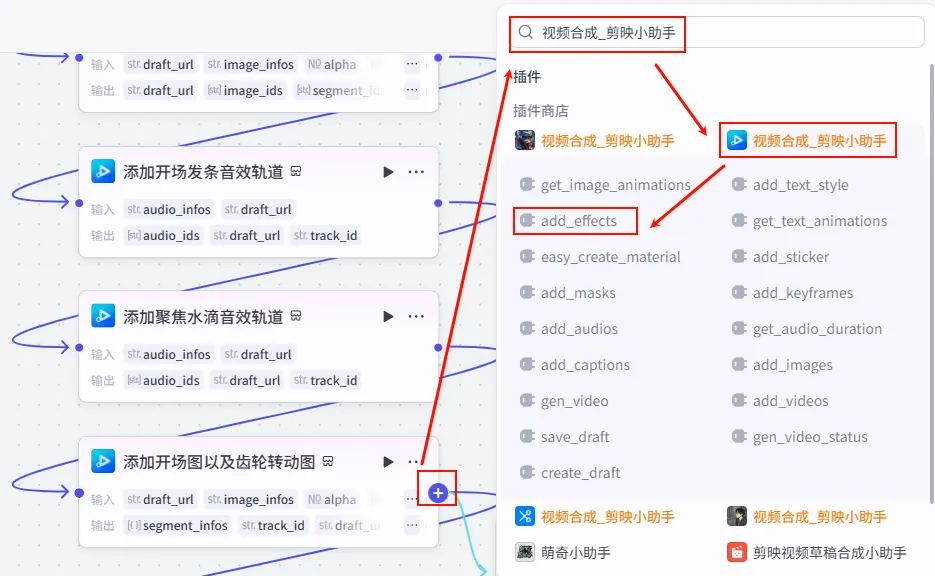
配置要点: draft_url: 引用创建剪映视频草稿.draft_url。effect_infos: 引用处理水波纹特效信息.infos。节点名称: 添加水波纹特效信息。输入变量:
步骤 1.55:添加开头字幕 (Add Opening Captions)
接下来添加视频开头的字幕,注意字体和颜色的搭配,使其清晰可见且符合整体风格。
操作步骤:点击 添加水波纹特效信息节点后的 + 号,选择 add_captions。
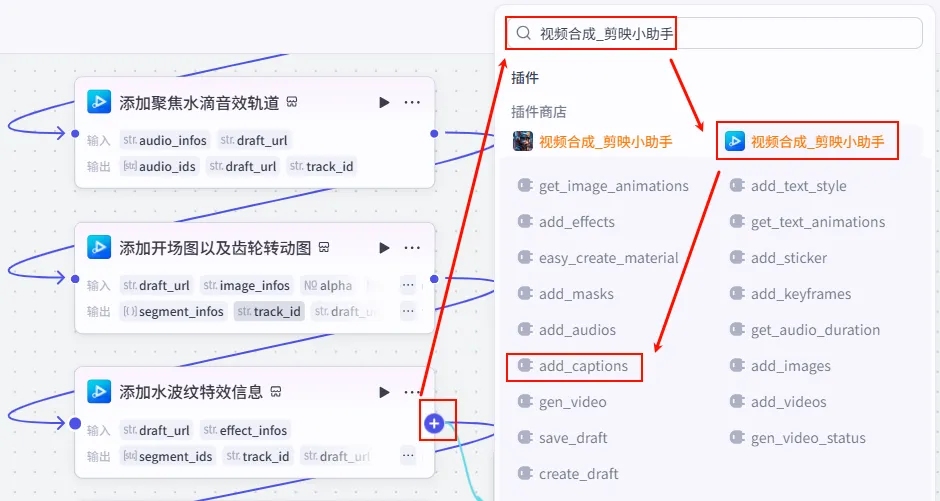
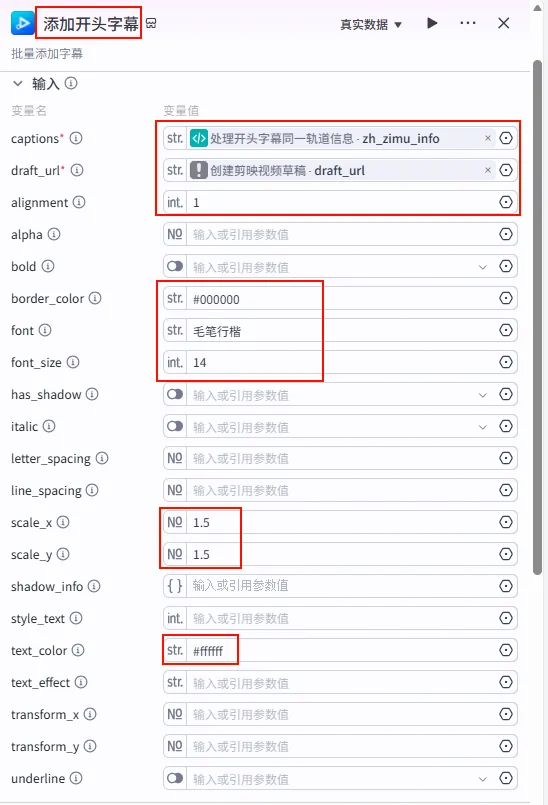
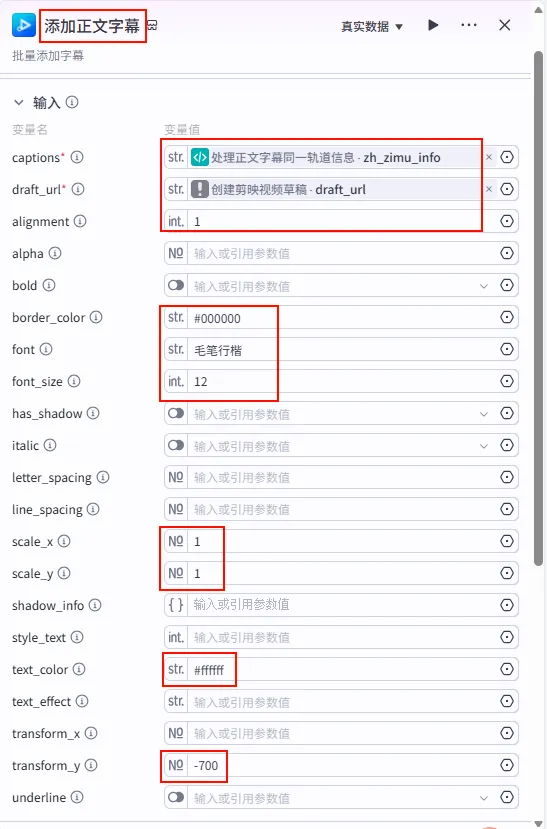
配置要点: alignment:1(对齐方式)。border_color:#000000(描边颜色)。font:毛笔行楷(使用具有中国风的字体)。font_size:14(字体大小)。scale_x:1.5(横向缩放)。scale_y:1.5(纵向缩放)。text_color:#ffffff(文本颜色)。captions: 引用处理开头字幕同一轨道信息.zh_zimu_info。draft_url: 引用创建剪映视频草稿.draft_url。节点名称: 添加开头字幕。输入变量: 参数配置:
步骤 1.56:添加正文字幕 (Add Body Captions)
最后添加书单的正文内容字幕。这里为了避免遮挡画面主体,通常会调整位置(如通过 transform_y 参数)。
操作步骤:点击 添加开头字幕节点后的 + 号,选择 add_captions。
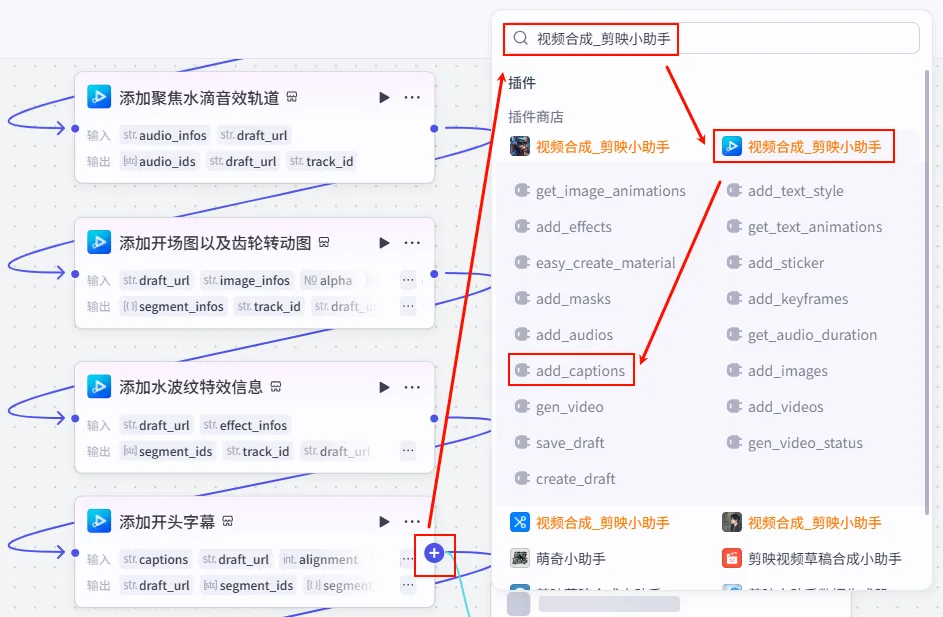
配置要点: font:毛笔行楷。font_size:12(比标题略小)。scale_x/scale_y:1(不缩放)。transform_y:-700(关键参数:向上移动字幕位置,让出画面中心)。其他样式保持一致(白色文字,黑色描边)。 captions: 引用处理正文字幕同一轨道信息.zh_zimu_info。draft_url: 引用创建剪映视频草稿.draft_url。节点名称: 添加正文字幕。输入变量: 参数配置:
步骤 1.57:结束节点 (End Node)
最后,我们将生成的剪映草稿链接和口播文案通过结束节点输出,方便用户直接复制使用。
操作步骤:将 添加正文字幕节点的输出连接到结束节点。
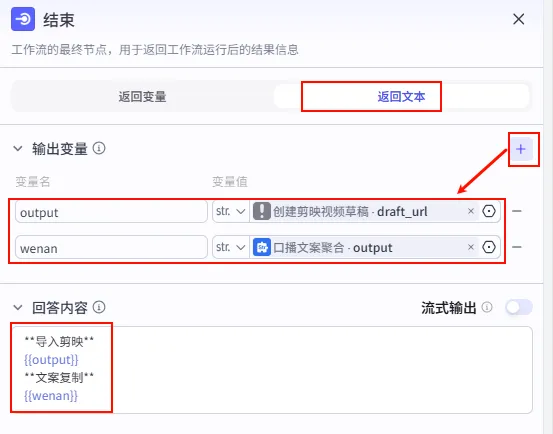
配置要点: output: 引用创建剪映视频草稿.draft_url(注意:虽然最后一步是加字幕,但草稿链接的核心来源始终是最初的 create_draft 节点,或者任意传递了 draft_url 的节点均可,这里为了逻辑清晰引用了源头,实际操作中引用上一步的输出亦可,只要是同一个草稿对象)。wenan: 引用口播文案聚合.output(这是为了方便发视频时复制文案)。输出方式:选择 返回文本。输出变量: 回答内容 (Markdown 格式): **导入剪映**{{output}}**文案复制**{{wenan}}
V31 的灵魂在于 Prompt 对“画面感”的极致把控。它证明了在 AI 时代,审美力就是第一生产力。不用复杂的代码,仅靠精准的图文描述,就能产出电影级的短视频。
02. 👶 V33:育儿故事动画——角色扮演与动态生成的完美融合
核心价值:V33 是 Day 37 的重头戏,它突破了静态图片的限制,引入了 Image-to-Video (图生视频) 技术。通过角色扮演 (Roleplay) 让文案具有真情实感(宝宝 vs 父母双视角),再通过 Python 代码 实现视频片段与音频的精确对齐,打造出真正意义上的“AI 动画片”。
工作流程:角色设定(宝宝/父母) → 冲突故事生成 → 动态分镜脚本 → 批量图生视频 → Python 音画对齐 → 剪映草稿
🔧 阵法布局
步骤 2.0:入参配置 (开始节点)
配置工作流的启动参数,这里我们需要接收用户输入的角色身份以及剪映的 API 令牌。
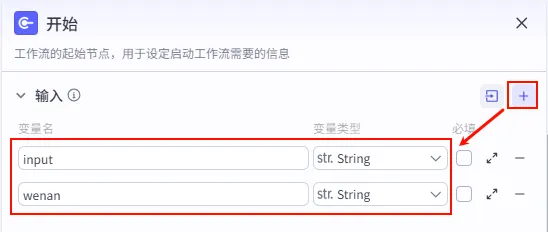
input (String): 用户输入的角色设定 (如 "我是宝宝" / "我是妈妈"),必填。 api_token (String): 剪映云渲染 API Token,必填 (api_token申请地址:https://www.51aigc.cc/#/home?user_id=572017)。
步骤 2.1:双视角角色扮演 (大模型)
这一步解决了育儿内容“同质化”的问题,通过大模型模拟“宝宝”或“家长”的口吻生成文案。
操作步骤:点击 开始节点后的 + 号,选择 大模型。
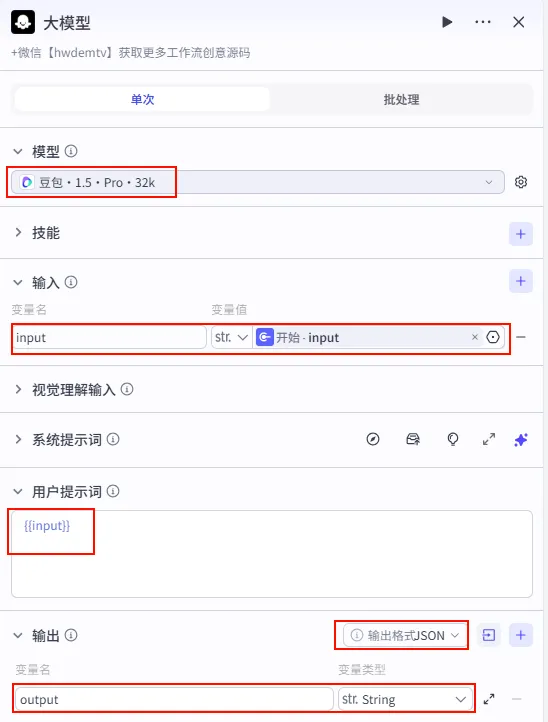
配置要点: 输出格式: JSON(关键!方便后续节点提取)。输出变量: output(Type:String)。input: 引用开始节点的input。节点名称: 修改为 大模型_文案生成。模型: 豆包·1.5·Pro·32k(我们需要长文本和较强的角色扮演能力)。输入变量: 用户提示词: {{input}}。系统提示词: (获取方式见文末)。 输出设置:
步骤 2.2:动态分镜设计 (大模型)
视频不同于图片,它需要动作。我们需要将文案翻译成 AI 绘画能理解的“画面描述”,这里使用 DeepSeek 模型来增强逻辑推理能力。
操作步骤:点击 大模型_文案生成节点后的 + 号,再次添加 大模型。
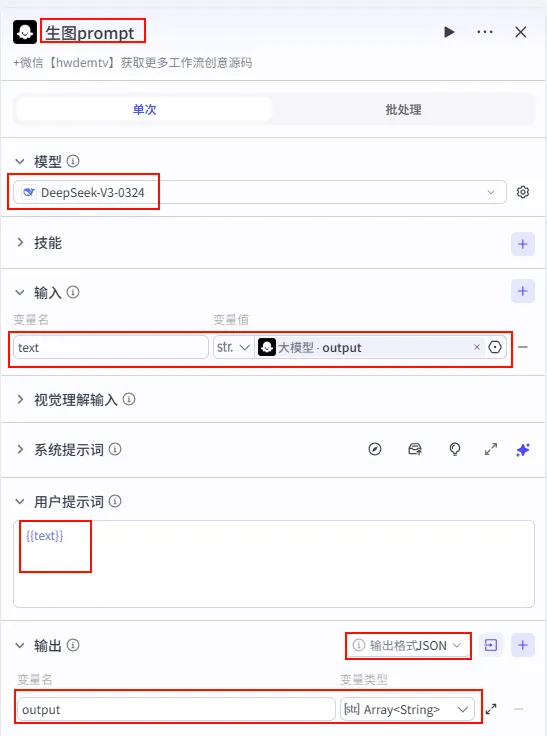
配置要点: 输出格式: JSON(输出为字符串数组)。输出变量: output(Type:Array<String>)。text: 引用大模型_文案生成的output。节点名称: 修改为 生图prompt(意为生成绘画提示词)。模型: DeepSeek-V3(利用其强大的指令遵循能力,确保输出格式准确)。输入变量: 用户提示词: {{text}}。系统提示词: (获取方式见文末)。 输出设置:
步骤 2.3:文案分句处理 (文本处理)
为了让后续的语音合成与字幕对齐更精准,我们需要将大模型生成的一整段文案拆分为独立的句子。
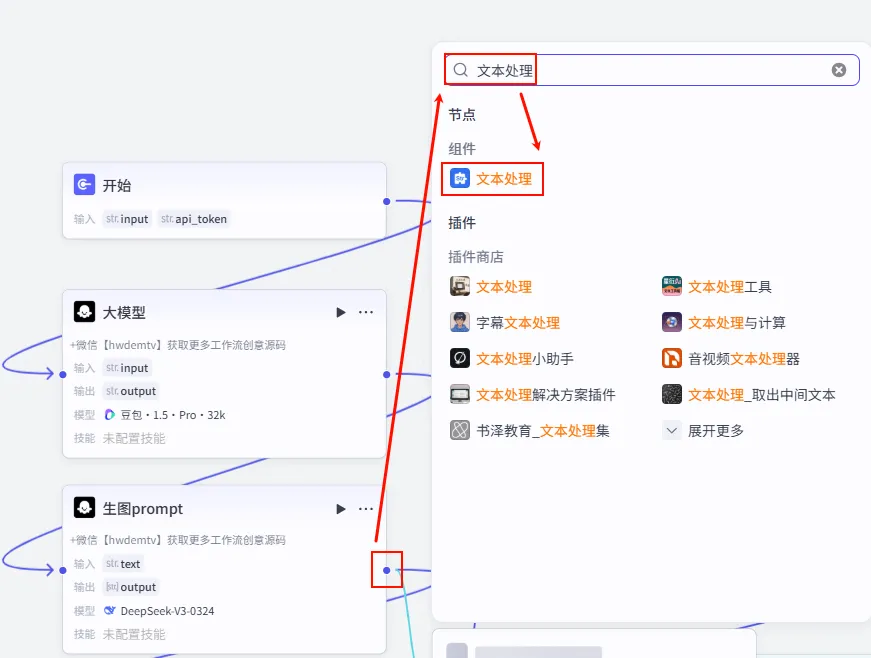
操作步骤:点击 生图prompt节点后的 + 号(实际上是并行分支),搜索 文本处理,选择文本处理。
配置要点: String: 引用大模型_文案生成的output(注意:是 Step 2.1 的输出,不是 Step 2.2)。节点名称: 文本处理。选择应用: 字符串分隔。输入变量: 分隔符: 选择 换行 (\n),句号 (.),?,!等自然分句符号。输出变量: 这里会自动生成一个字符串数组,用于后续遍历。
步骤 2.4:数据清洗 (Code)
有时文本分割会产生空行,我们需要用一段简单的 Python 代码去除空元素,并重新组合成标准字符串。
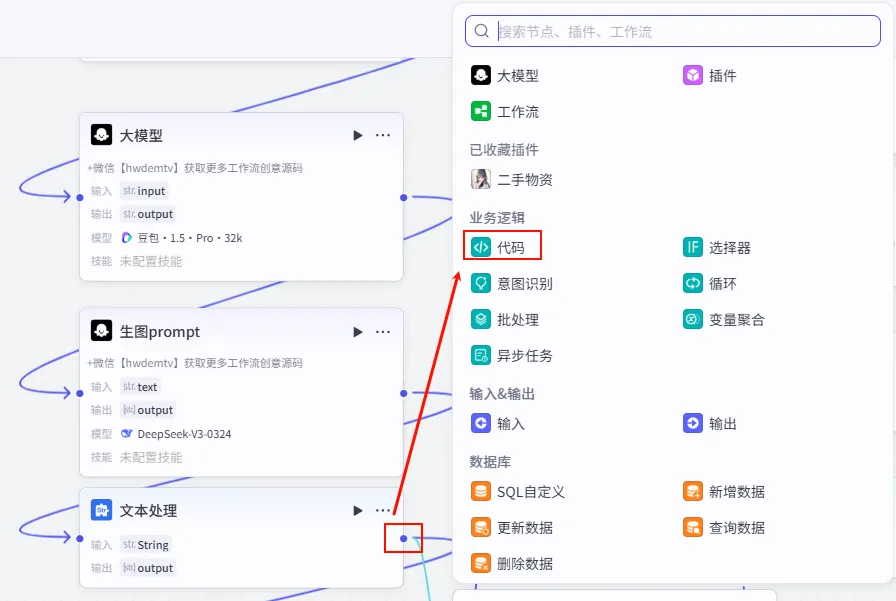
操作步骤:点击 文本处理节点后的 + 号,选择 代码。
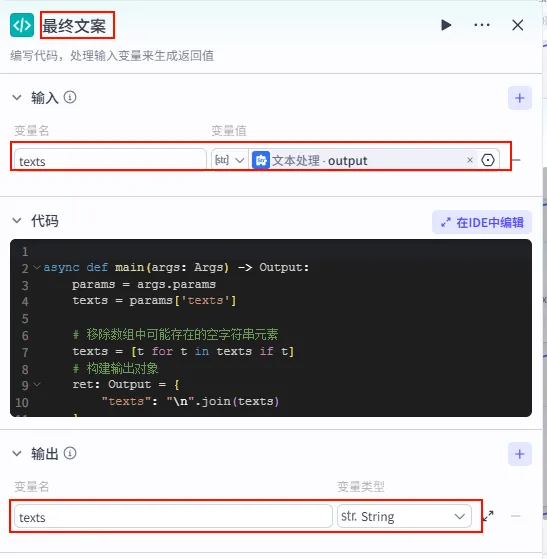
配置要点: 节点名称: 最终文案。输入变量: texts(引用文本处理.output)。代码逻辑: 遍历数组,去除空字符串,用换行符拼接。 代码: (获取方式见文末)。 输出变量: texts(String)。
步骤 2.5:批量生图 (Batch Process)
这是 V33 成本最高但也最酷的部分。我们首先通过批处理节点,循环遍历每一个分镜提示词,生成静态图片。
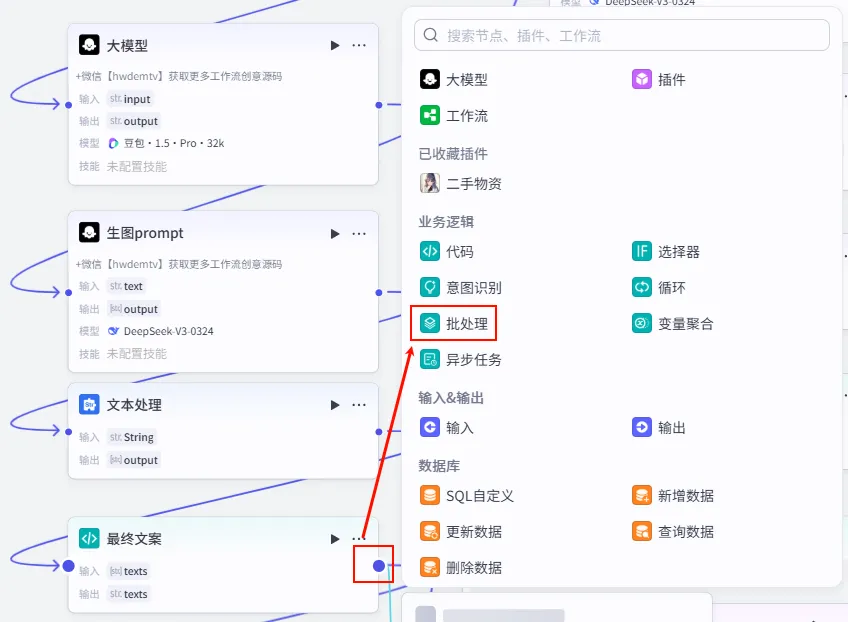
1. 添加批处理节点:点击 最终文案节点后的 + 号,选择 批处理。
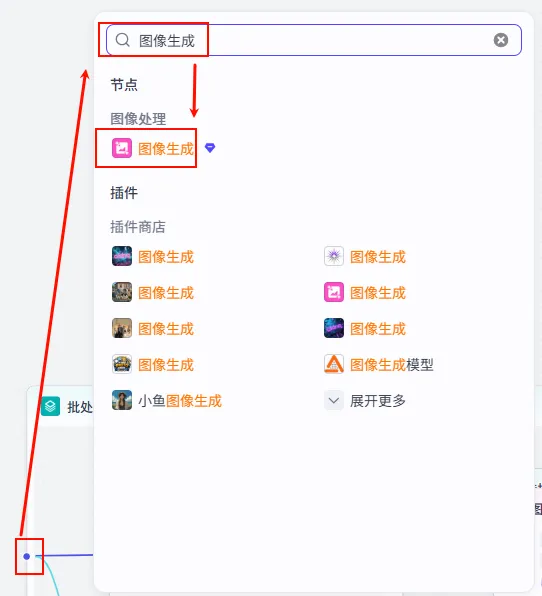
2. 添加生图节点:在批处理的 循环体内部 (即蓝色方框内),点击小圆点添加 图像生成 节点。
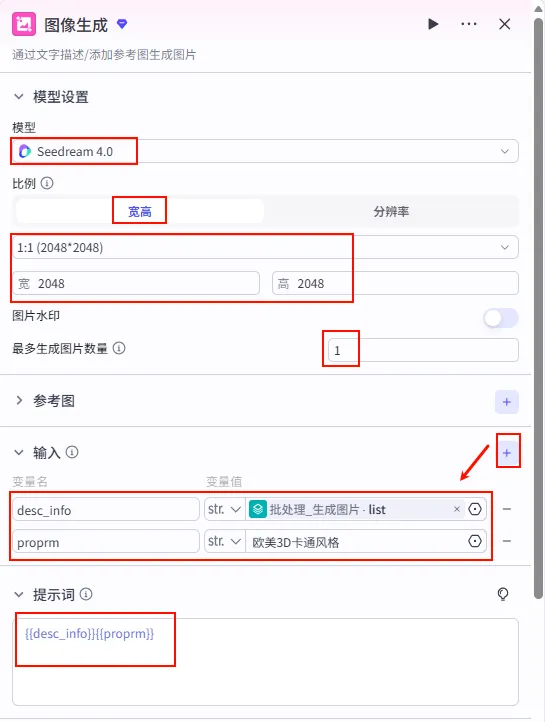
配置要点: 模型: Seedream 4.0(或其他高质量绘图模型)。比例: 1:1(2048x2048) 或根据平台需求调整为 9:16。输入变量: 提示词: {{desc_info}}{{proprm}}。生成数量: 1 张。 desc_info: 引用批处理_生成图片的list(即当前循环项 item)。proprm: 固定值欧美3D卡通风格(或其他风格后缀)。输入列表: 引用 生图prompt.output(Step 2.2 的输出,即 Prompt 数组)。处理方式: 并行处理 (Parallel) 以提高速度。 批处理设置: 图像生成节点设置 (循环体内):
步骤 2.6:异常处理 (Selector)
AI 生图偶有失败,为了防止生图失败导致整个流程中断,我们需要增加一个判断逻辑。
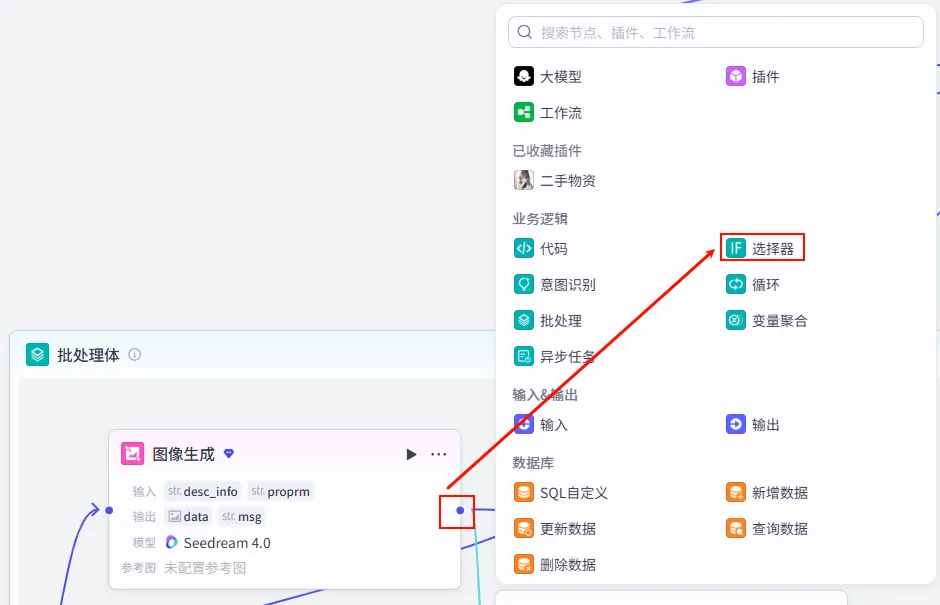
操作步骤:点击 图像生成节点后的 + 号,选择 选择器 (IF)。
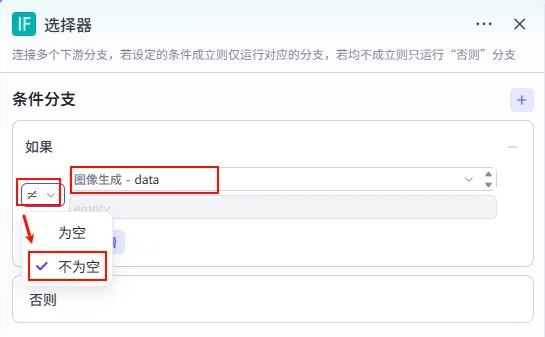
配置要点: 条件 (如果): 图像生成.data不为空。逻辑: 只有当生成图片成功时,才进行后续的视频生成;否则进入 否则 (Else) 分支。
否则分支 (Retry):如果第一次生图失败,我们在 Else 分支中再添加一个 图像生成 节点进行重试。
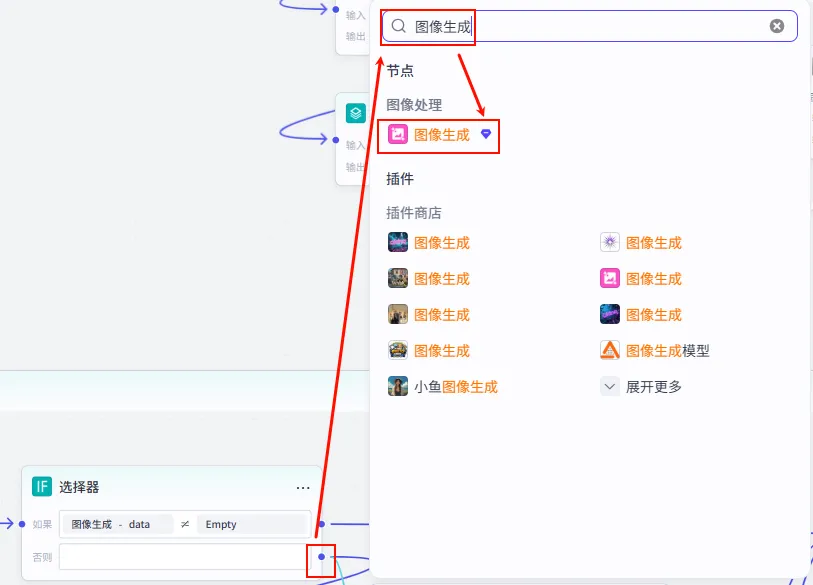
配置: 与 Step 2.5 保持一致 (Seedream 4.0, 1:1, 提示词 {{desc_info}}{{proprm}})。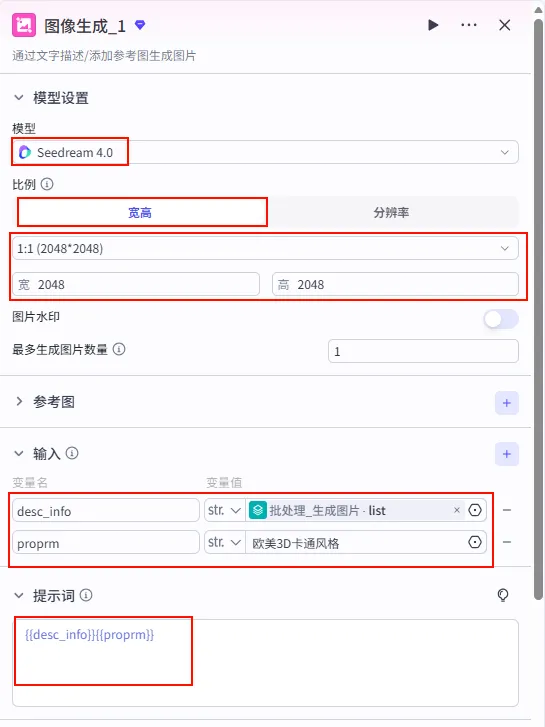
此外,为了确保重试后的图片有效,我们在重试节点后再次添加一个 选择器 (IF)。
配置: 条件: 图像生成_1.data不为空。目的: 只有重试成功才继续,确保绝对安全。
否则分支 (Final Retry):若第二次重试仍失败,我们在 Selector_1 的 Else 分支再加一层保险(共 3 次生图机会)。
配置: 依然保持一致 (Seedream 4.0, 1:1, 提示词 {{desc_info}}{{proprm}})。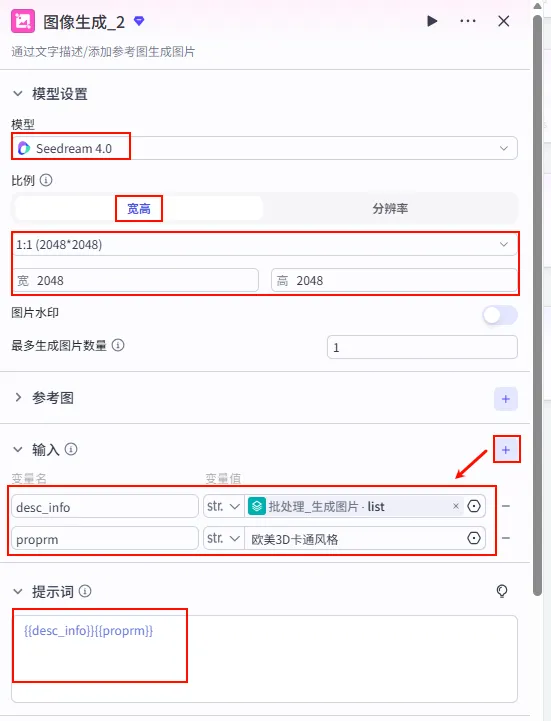
步骤 2.7:结果聚合 (Variable Aggregation)
由于我们有三条可能的生图路径(首发成功、一次重试成功、二次重试成功),我们需要将它们的结果汇聚到一个变量中,传给后续节点。
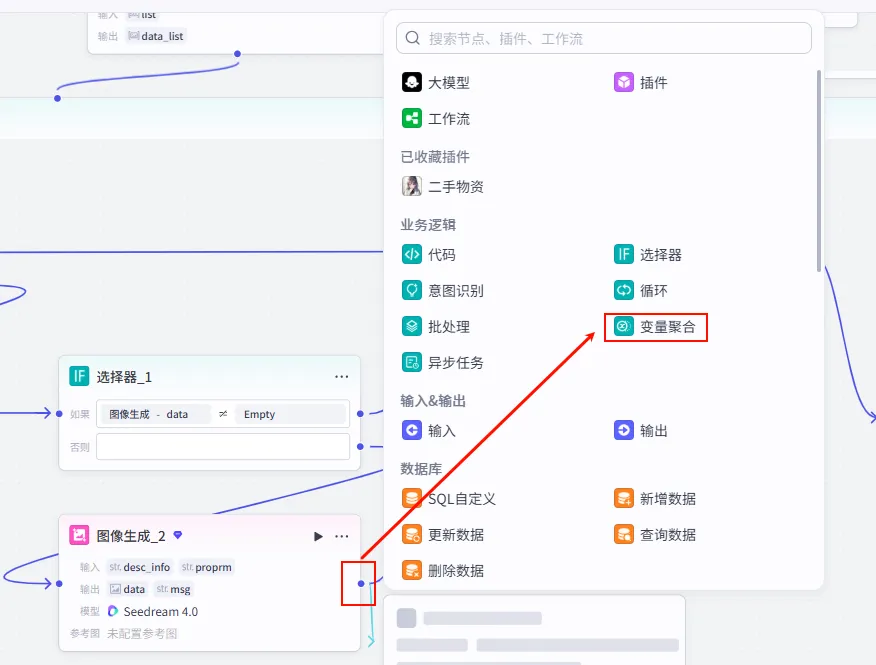
操作步骤:点击 图像生成_2节点后的 + 号,选择 变量聚合。
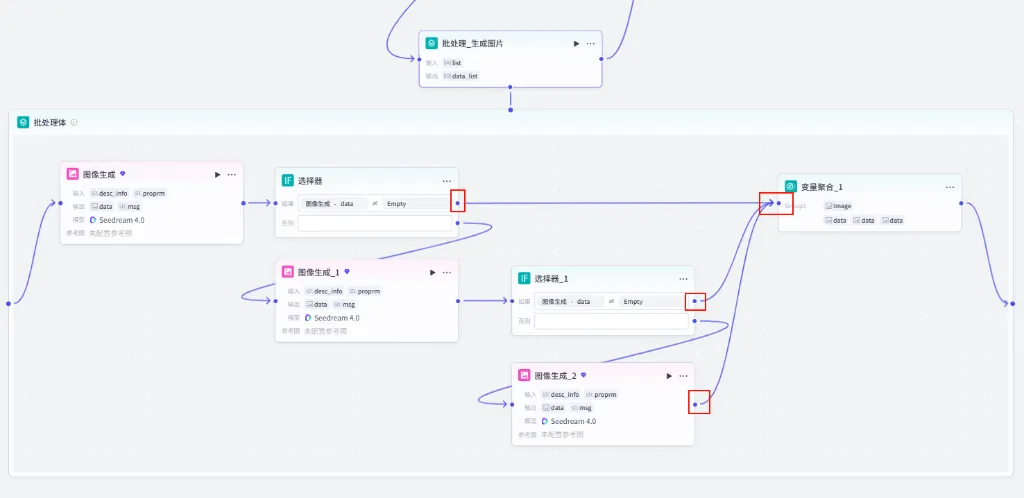
连接逻辑: 将 选择器的 如果 (Yes) 分支连接到聚合节点。将 选择器_1的 如果 (Yes) 分支连接到聚合节点。将 图像生成_2(即 Final Retry) 的输出连接到聚合节点。配置要点: 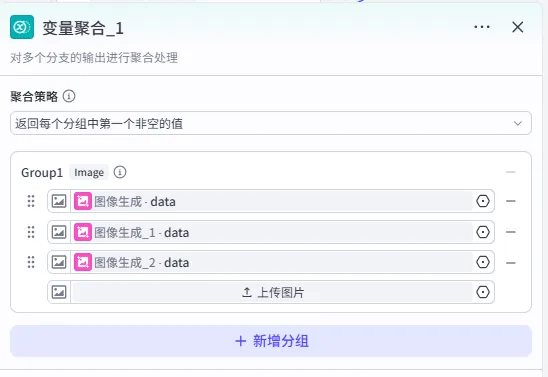
添加 图像生成.data(首发)。添加 图像生成_1.data(一重试)。添加 图像生成_2.data(二重试)。聚合策略: 选择 返回每个分组中第一个非空的值。变量组 (Group1): 命名为 Image。作用: 系统会按顺序检查,只要有一个成功生成了图片,就将其作为最终输出,确保流程稳健。
闭环与输出 (Batch Output):最后,我们需要配置批处理节点的最终输出。
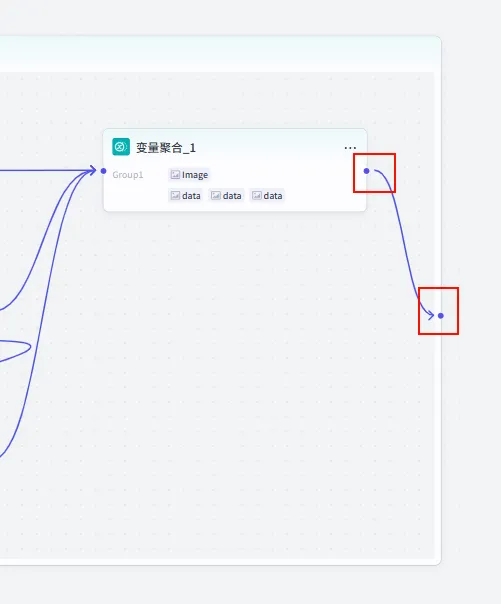
连接: 将 变量聚合节点的输出点,连接到批处理体右侧边缘的 结束点。批处理配置: 点击批处理节点本身。 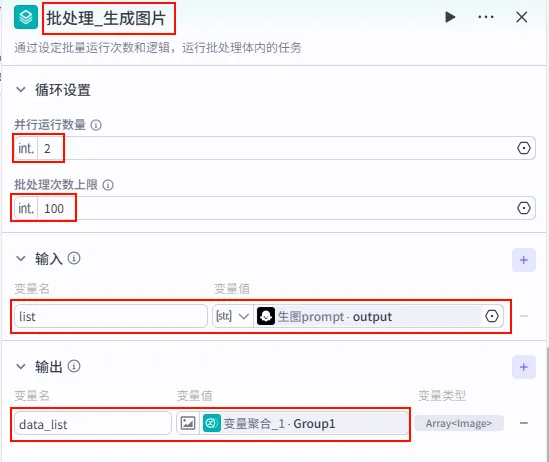
并行运行数量: 建议设为 2(避免并发过高导致生图接口限流)。输出变量: 将内部的 变量聚合_1.Group1映射为外部输出data_list(Array<Image>)。
步骤 2.8:批量生成视频 (Batch)
图生视频是让画面动起来的关键。
节点: 批处理_生成视频逻辑: 将上一步生成的静态图 ( 变量聚合.Image) 作为输入,调用Image-to-Video模型生成动态视频片段。
步骤 2.9:字幕音频对齐 (Align)
为了让字幕时间轴精确匹配语音,我们需要使用 alignTextToAudio 工具。
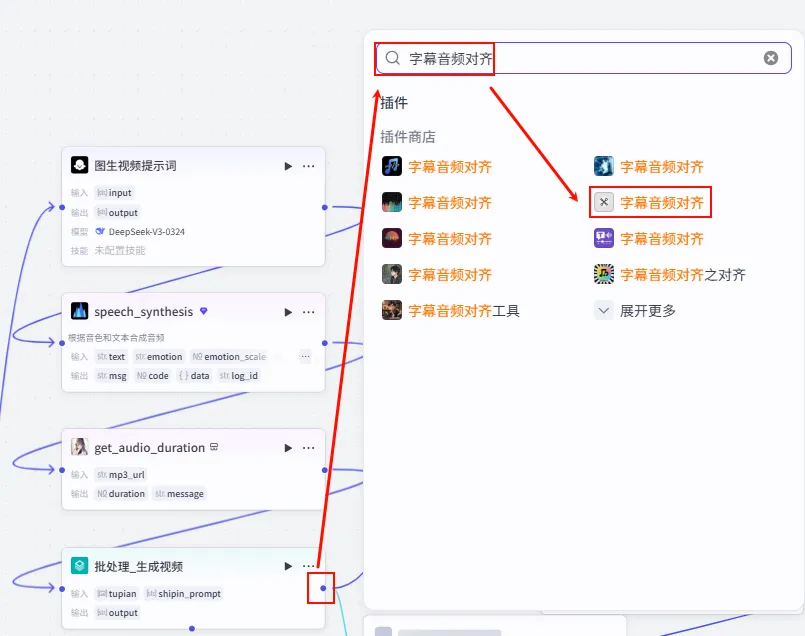
操作步骤:点击 批处理_生成视频节点后的 + 号,搜索并选择 字幕音频对齐。
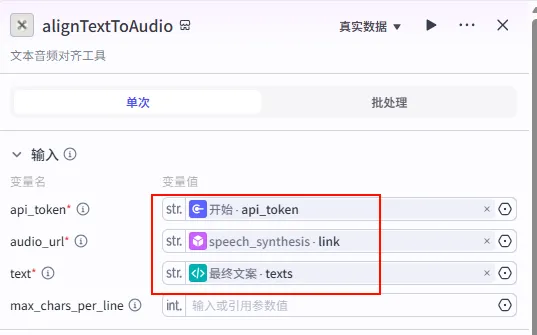
配置要点: api_token: 引用 开始.api_token(剪映 Token)。audio_url: 引用 speech_synthesis.link(注意:这意味着在此之前需要有一个 语音合成 节点,将Final Copy转换为音频)。text: 引用 最终文案.texts。作用: 生成包含每个单词/字符精确时间戳的 JSON 数据,供后续 Python 节点计算轨道。
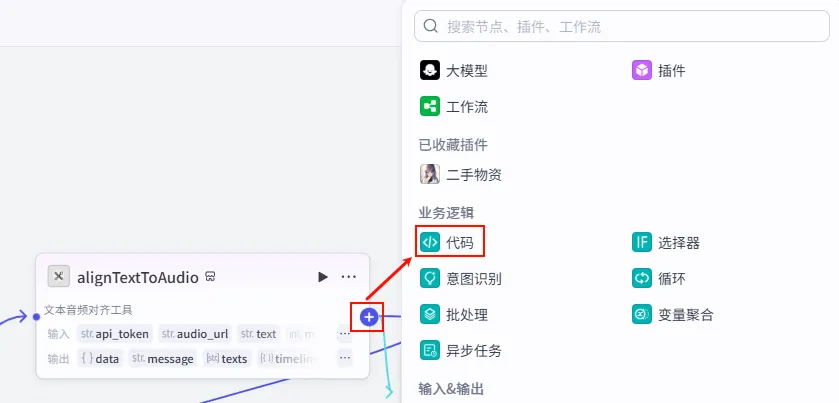
步骤 2.10:视频列表循环 (Code)
为了防止视频画面跟不上音频时长(例如音频20秒,生成的视频只有15秒),我们需要用代码将视频列表进行循环填充。
操作步骤:点击 alignTextToAudio节点后的 + 号,选择 代码。
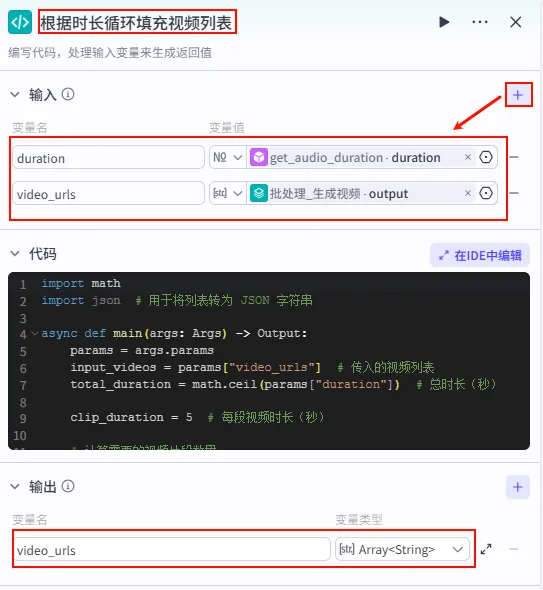
配置要点: duration: 引用get_audio_duration.duration(需添加获音频时长工具)。video_urls: 引用批处理_生成视频.output(变量聚合后的视频列表)。输入变量: 代码逻辑: 计算音频总时长与单段视频时长的比例,循环复制视频列表。 输出变量: video_urls(Array<String>) (调整后的视频列表)。
步骤 2.11:数据重组与轨道生成 (Code)
有了对齐的字幕数据和足够的视频片段,最后一步是组装剪映草稿的轨道数据。
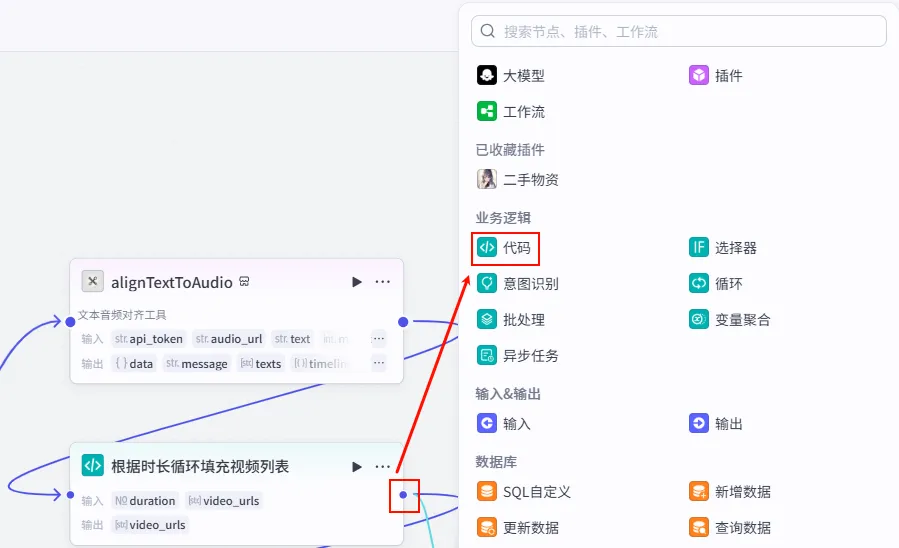
操作步骤:点击 根据时长循环填充视频列表节点后的 + 号,再次选择 代码。
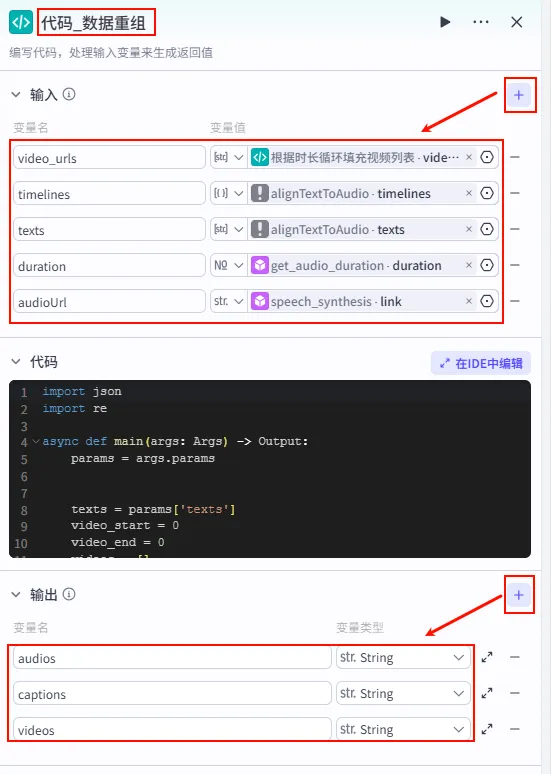
配置要点: video_urls: 引用根据时长循环填充视频列表.video_urls(Step 2.10 的输出)。timelines: 引用alignTextToAudio.timelines(Step 2.9 的输出)。texts: 引用alignTextToAudio.texts(Step 2.9 的输出)。duration: 引用get_audio_duration.duration。audioUrl: 引用speech_synthesis.link。节点名称: 代码_数据重组。输入变量: 代码逻辑: 将上述素材组合成 CapCut 草稿协议所需的 audios,captions,videos轨道数据。代码: (获取方式见文末)。 输出变量: audios,captions,videos(全部为 String 类型)。
步骤 2.12:创建空草稿 (Create Draft)
首先,我们创建一个空的剪映草稿容器,为后续填入素材做准备。
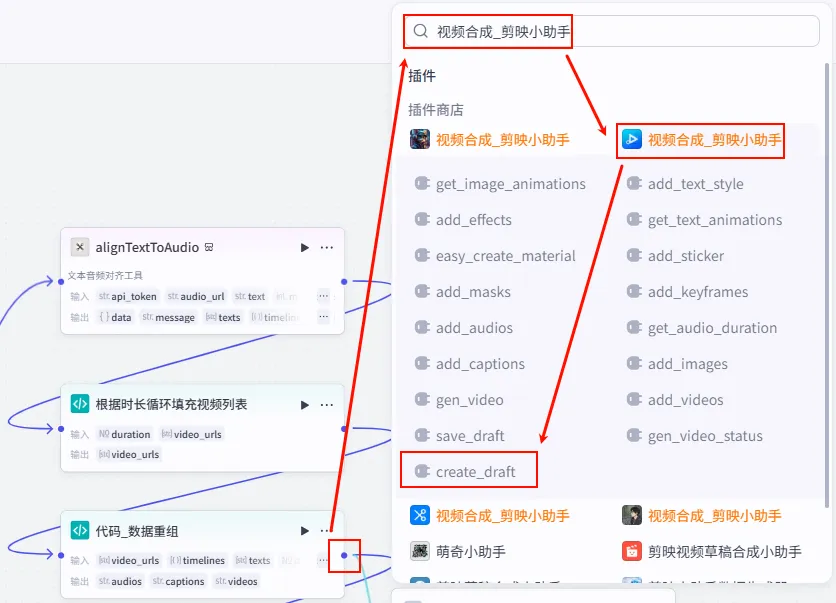
操作步骤:点击 代码_数据重组节点后的 + 号,搜索并添加create_draft工具。
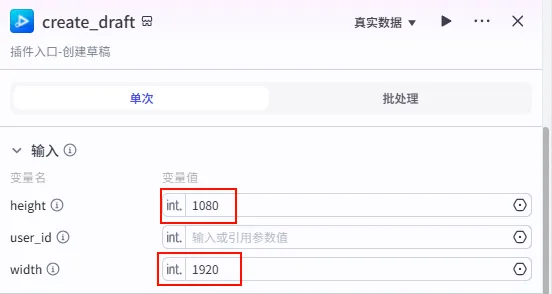
配置要点: height: 1080(竖屏高度)。width: 1920。输出: 获得一个初始的 draft_id或draft_url。
步骤 2.13:添加音频轨道 (Add Audios)
有了空草稿后,我们采用“分层组装”的方式,先把音频数据填进去。
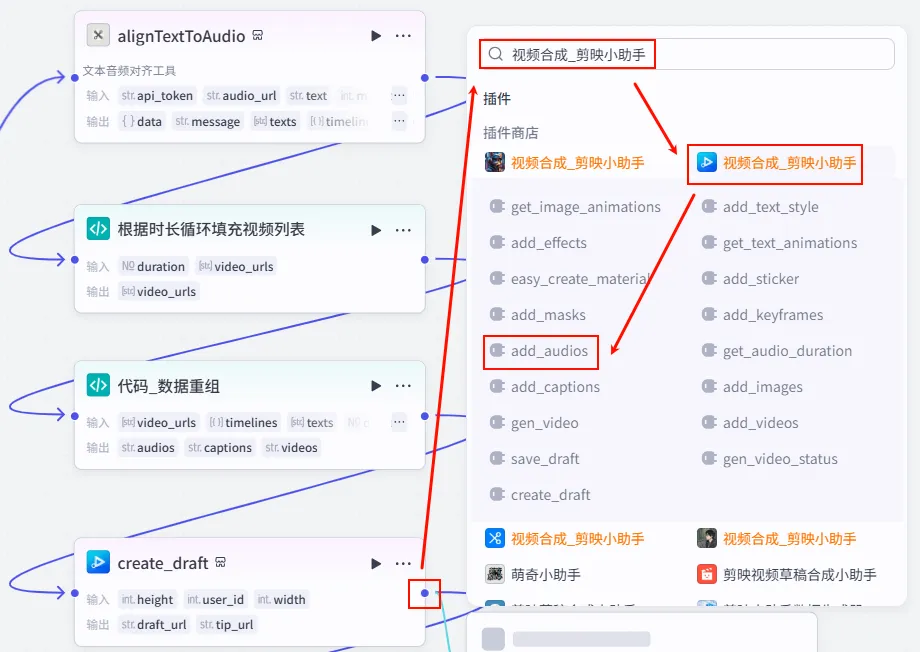
操作步骤:点击 create_draft节点后的 + 号,搜索并添加add_audios工具。
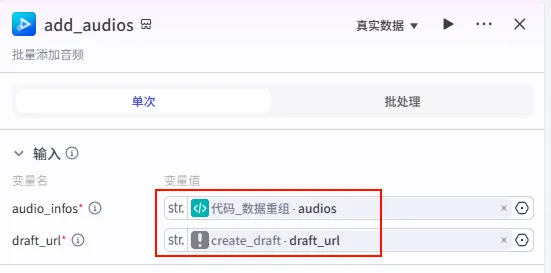
配置要点: audio_infos: 引用 代码_数据重组.audios(这是我们在 Python 节点中组装好的音频轨道数据)。draft_url: 引用 create_draft.draft_url(确保添加到刚才创建的那个草稿中)。
步骤 2.14:添加视频轨道 (Add Videos)
音频就位后,我们将 AI 生成的视频片段铺设到画面上。
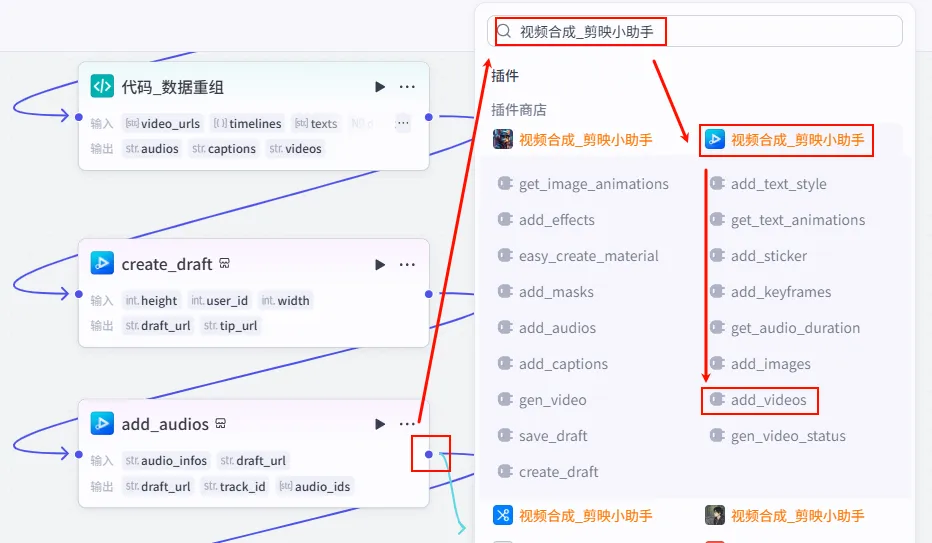
操作步骤:点击 add_audios节点后的 + 号,搜索并添加add_videos工具。
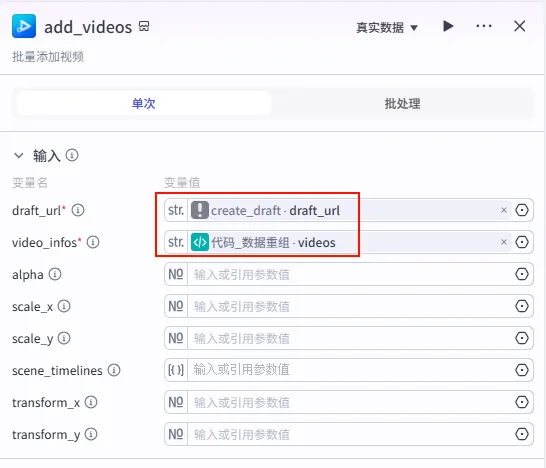
配置要点: video_infos: 引用 代码_数据重组.videos。draft_url: 引用 add_audios.draft_url(注意:这里要引用上一步返回的草稿 URL,形成链式调用)。
步骤 2.15:添加字幕轨道 (Add Captions)
最后,也是最显眼的部分——字幕。我们使用 add_captions 工具将生成的字幕数据“烧录”进去。
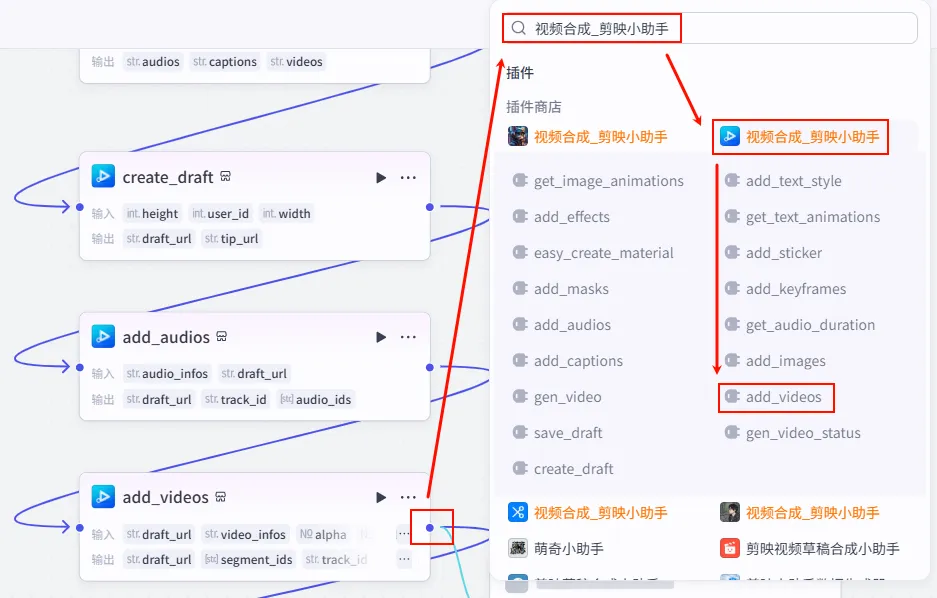
操作步骤:点击 add_videos节点后的 + 号,搜索并添加add_captions工具。
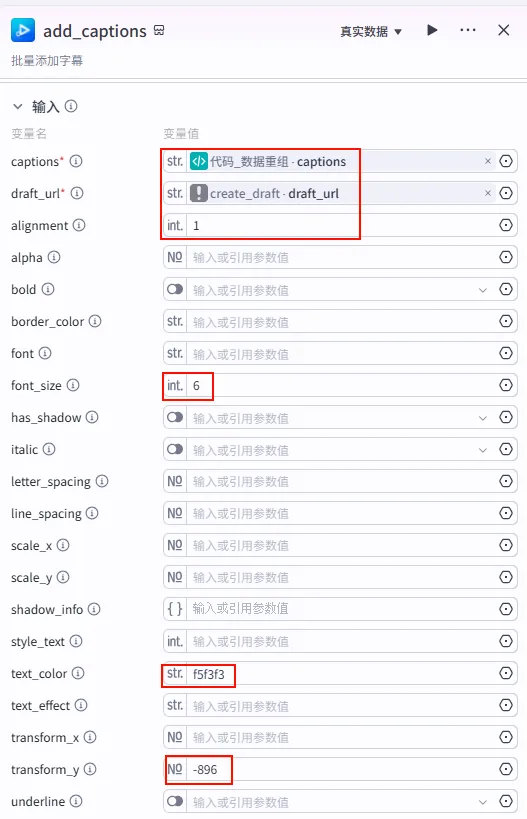
配置要点: captions: 引用 代码_数据重组.captions。draft_url: 引用 create_draft.draft_url(始终指向最初创建的那个草稿)。font_size: 6(根据经验,这个数值对应剪映里的适中字号)。text_color: f5f3f3(米白色,比纯白更柔和)。transform_y: -896(将字幕位置调整到底部区域)。
关于 Draft URL 的传递
在使用 add_audios, add_videos, add_captions 等插件链式操作时,draft_url 始终引用最初创建的那个 create_draft.draft_url 即可。因为这些插件是“远程操作”同一个云端草稿,而不是像接力棒一样传递修改后的草稿对象。
步骤 2.16:保存草稿 (Save Draft)
所有轨道添加完毕后,必须显式调用保存接口,才能生成最终可用的 draft_content。
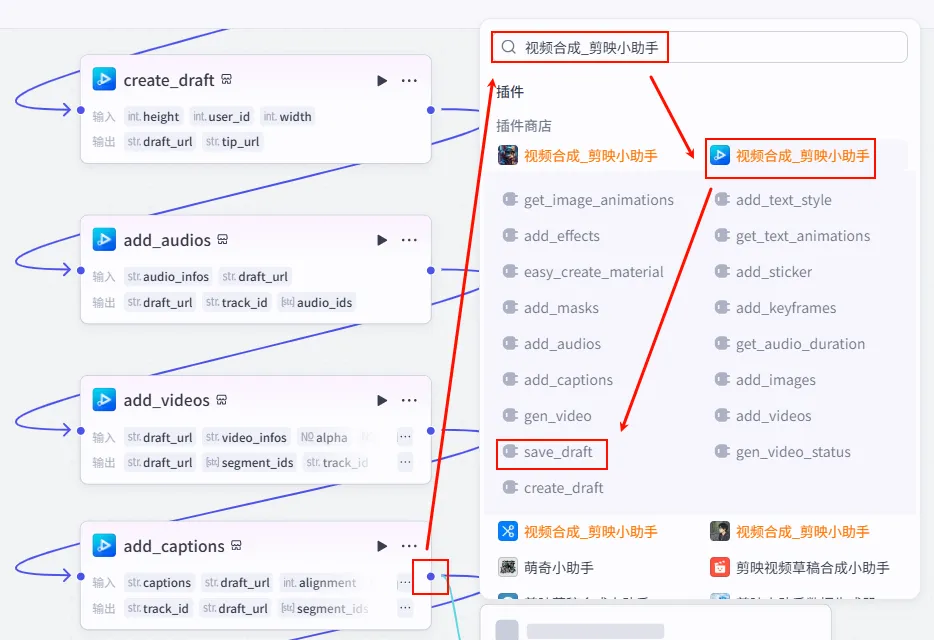
操作步骤:点击 add_captions节点后的 + 号,搜索并添加save_draft工具。
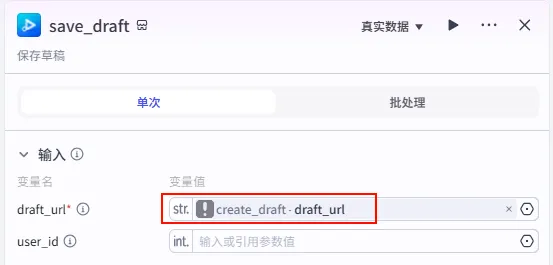
配置要点: draft_url: 引用 create_draft.draft_url(或者add_captions.draft_url,指向同一个对象即可)。输出: 最终的 draft_content,这就是我们需要的剪映草稿数据。
步骤 2.17:输出配置 (End)
最后,我们将生成的草稿链接作为整个工作流的最终输出。
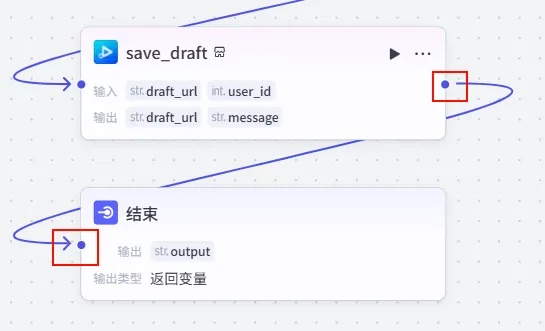
操作步骤:将 save_draft的输出连接到结束节点。
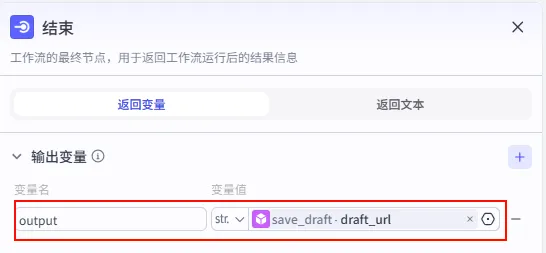
配置要点: 输出变量: 设置为 output。变量值: 引用 save_draft.draft_url。作用: 当用户运行工作流结束后,直接返回这个链接。用户点击链接即可唤起剪映打开草稿。
03. 🎁 资源与源码获取
这套工作流(V31 & V33)代表了目前 Coze 视频流的顶尖水平,涵盖了从高审美图文到复杂逻辑动画的全过程。
🅰️ 动手党(免费)Coze 插件广场搜索相关插件,结合本文逻辑图尝试搭建。关注公众号,后台发送 “Day37” 获取核心提示词与 Python 代码。
🅱️ 懒人党(¥9.9 / 拿来主义)扫码添加作者微信 (hwdemtv),获取 V31 & V33 完整 DSL 源码文件,导入 Coze 即可使用。

💎 进阶党(¥99 / 永久社群)加入我的专属学习群,获取 60 天挑战的全部 119 个工作流源码,与一群“弄脏双手”的硬核 AI 玩家共同进化。
🏢 企业定制(按需报价)支持 Coze / n8n / Dify 工作流定制开发,私聊咨询。
下期预告:Day 38 我们将继续挑战 V37 一键生成背单词视频,敬请期待!

