一、项目概览
本文档是Shelley 的高层次介绍,阐述了其设计目的、核心特性与系统架构。它旨在帮助读者理解 Shelley 的整体结构及其内部组件如何协同工作。
如需获取安装与配置指南,请参阅Getting Started部分。如需深入了解架构细节,请参阅Architecture部分。关于特定子系统的详细信息,请参考本文档后续的对应章节。
二、Shelley 是什么
Shelley 是一个单用户、基于网页的编程助手,为软件开发任务提供AI驱动的辅助。它的核心功能包括执行shell命令、修改文件、与git仓库交互,并通过一个对话界面来处理代码。
在部署形式上,Shelley 被分发为一个单一、自包含的二进制文件,其中内嵌了HTTP服务器和基于网页的用户界面。所有对话历史和消息都存储在一个本地的 SQLite 数据库中。
在设计上,Shelley 旨在实现移动设备友好,支持多模态交互(文本和图像)、多个大语言模型(LLM)提供商以及多个并发的对话。它没有内置的授权或沙箱机制。
其名称“Shelley”来源于它所使用的主要工具(Shell,即命令行),同时也是对诗人珀西·比希·雪莱(Percy Bysshe Shelley)的诗歌《奥西曼提斯》(Ozymandias)的引用。
三、核心特性
本文档旨在对 Shelley 进行高层次介绍,阐述其目的、核心特性和系统架构。Shelley 的核心特性旨在提供一个强大且便捷的 AI 编程助手体验,具体如下:
| 特性 | 描述 |
|---|
| 单二进制文件 | 自包含的可执行文件,内嵌 UI 和模板 |
| 多模型支持 | 通过抽象层支持多个 LLM 提供商 |
| 多模态交互 | 处理文本和图像输入以实现更丰富的交互 |
| 多会话并发 | 维护多个独立的对话线程 |
| 基于 Web 的 UI | 可通过浏览器访问的 React 界面 |
| 移动设备友好 | 针对移动设备的响应式设计 |
| 持久化存储 | 使用 SQLite 数据库存储对话历史 |
| 实时更新 | 通过服务器发送事件 (SSE) 进行流式更新 |
| Shell 命令执行 | 执行 bash 命令并进行安全分析 |
| 文件操作 | 应用代码补丁和修改 |
| Git 集成 | 监控仓库变更并显示差异 |
| 浏览器自动化 | 控制和捕获浏览器会话 |
四、技术栈
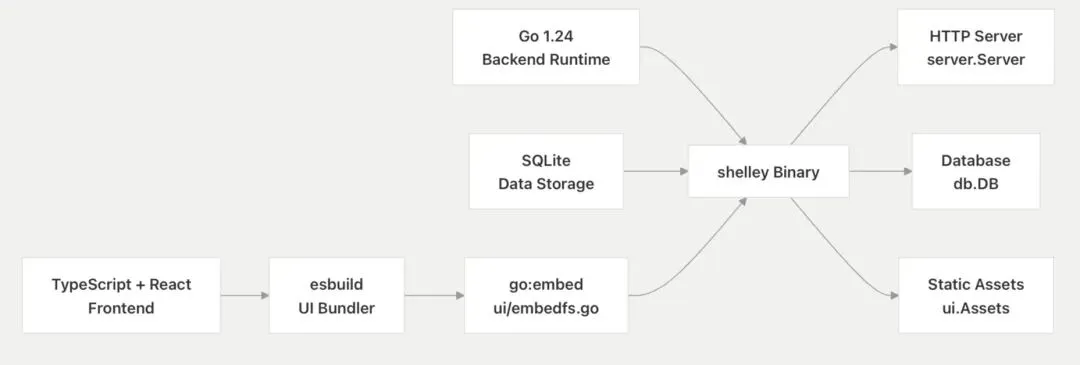
Shelley 的技术栈与其设计目标紧密契合,旨在构建一个高性能、跨平台且易于分发的桌面代理应用。
核心技术
根据文档,Shelley 主要构建于以下核心技术之上:
- Go 1.24:作为后端的主要开发语言。
- SQLite:用于数据存储。
- TypeScript + React:构成前端应用。
- esbuild:作为 UI 的打包构建工具。
最终的产出是一个名为shelley的单一二进制文件,它内部通过go:embed指令(具体实现于ui/embedfs.go文件中)嵌入了所有前端静态资源。
栈层级划分
其技术栈可按功能明确划分为后端、前端和构建系统三个主要层面。
后端
- Go:用于开发 HTTP 服务器(
server.Server)、代理主循环(agent loop)以及各类工具的执行逻辑。 - SQLite:通过
db.DB接口实现所有对话数据和消息的持久化存储。 - Server-Sent Events (SSE):用于实现从服务器到客户端的实时、流式更新。
前端
- TypeScript 和 React:构成用户界面的核心,用于开发所有 UI 组件。
- Monaco Editor:用于代码的显示和编辑。
- Web Speech API:被集成以支持语音输入功能。
构建系统
- esbuild:负责对位于
ui/src/的 TypeScript 源代码进行编译和打包。 go:embed指令:在ui/embedfs.go文件中使用,将构建好的前端资产嵌入到最终的 Go 二进制文件中。- GoReleaser:用于创建跨平台(Linux 和 macOS)的二进制文件。
五、系统架构
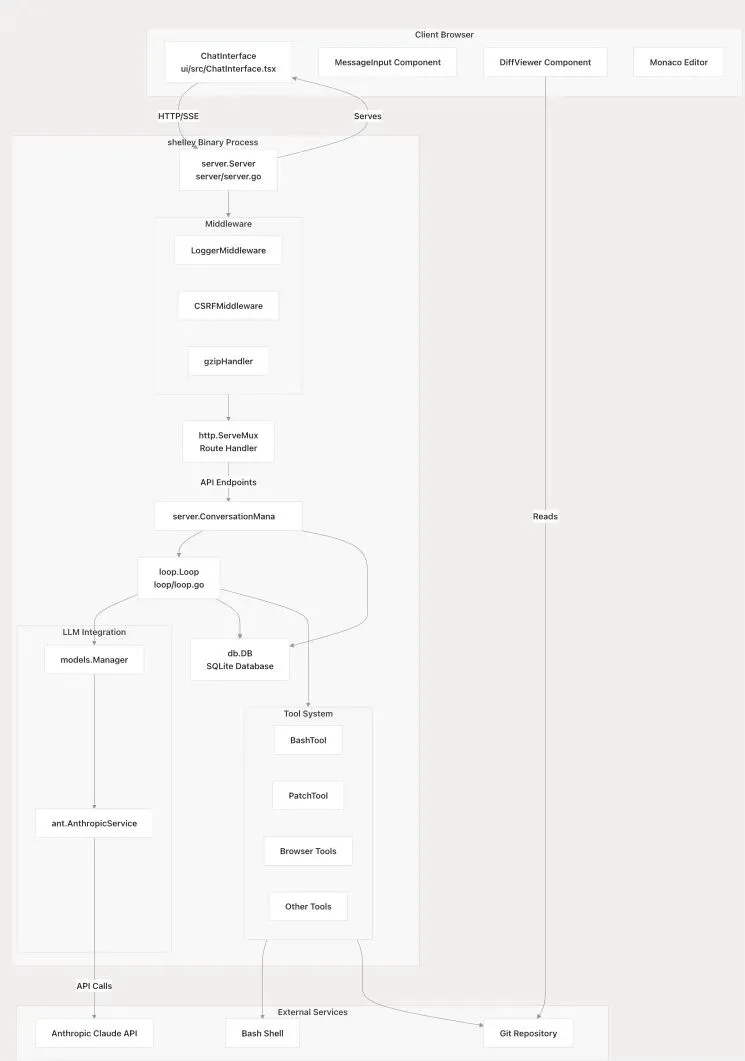
Shelley 是一个单进程、服务端内嵌的应用程序,其核心是一个包含所有组件的 Go 二进制文件。它的架构围绕处理用户请求、执行 AI 驱动的任务并保持对话状态而设计。下图概括了主要组件及其交互关系:
外部服务(External Services) <-HTTP/SSE->shelley 二进制进程(shelley Binary Process)
- 客户端浏览器(Client Browser) 通过HTTP/SSE与shelley 二进制进程通信。
- shelley 二进制进程调用LLM 集成(LLM Integration)。
- shelley 二进制进程通过Bash Shell和Git Repository与系统交互。
在shelley进程内部,组件按层次组织,共同处理请求流:
- API 端点(API Endpoints) 接收API 调用(API Calls)。
- HTTP 服务器(
server.Serverinserver/server.go)服务于(Serves)API 端点和前端 UI(Frontend UI (ui/src/ChatInterface.tsx))。 - 中间件(Middleware) 包括
LoggerMiddleware、CSRFMiddleware和gzipHandler。 - 服务器(
server.Server)持有(Holds)对话管理器(server.ConversationManager)。 - 对话管理器拥有(Owns)Agent 循环(
loop.Loopinloop/loop.go)。 - Agent 循环协调(Coordinates)工具系统(Tool System),工具系统包含
BashTool、PatchTool、Browser Tools和Other Tools。 - 服务器和循环都读取/写入(Reads/Writes)SQLite 数据库(
db.DBSQLite Database)。 - Agent 循环通过 LLM 管理器调用(Calls via LLM Manager (
models.Manager))LLM 服务(例如ant.AnthropicService连接至 Anthropic Claude API)。
前端 UI (ChatInterface在ui/src/ChatInterface.tsx) 由多个组件构成,包括MessageInput Component、DiffViewer Component和集成的Monaco Editor。
主要组件
HTTP 服务器 (server.Server)
该 HTTP 服务器是所有客户端交互的主要入口点。它在server/server.go中通过Server结构体实现,负责管理:
- 通过
RegisterRoutes进行 HTTP 请求路由 - 在
activeConversations映射中管理活跃的对话管理器 - 通过
llmManager字段访问 LLM 提供商 - 通过服务器发送事件 (Server-Sent Events) 实现实时更新
服务器监听一个可配置的端口(默认 9000),并提供 API 端点和嵌入的 UI 资源服务。
数据库 (db.DB)
SQLite 数据库使用在db包中定义的模式持久化所有对话数据。关键表包括:
conversations: 对话元数据(ID、slug、创建/更新时间戳、归档状态)messages: 包含类型、序列 ID、LLM 数据、用户数据、使用数据和显示数据的独立消息
消息根据db.MessageType分类:user、agent、tool、error或gitinfo。
对话管理器 (server.ConversationManager)
每个活跃的对话都有一个ConversationManager,它负责:
- 编排 Agent 循环的生命周期
- 为 SSE 流式传输管理消息订阅者
- 跟踪对话活动以便清理
- 在 HTTP 处理程序和 Agent 循环之间进行协调
管理器按需创建,并缓存在Server.activeConversations映射中,在闲置 30 分钟后进行清理。
Agent 循环 (loop.Loop)
Agent 循环实现了核心的对话逻辑,通过多轮 LLM 交互和工具执行来处理用户消息。它维护对话状态,并与 LLM 执行请求-响应循环。
LLM 管理器 (models.Manager)
LLM 管理器通过抽象层支持多个 LLM 提供商。它实现了在server/server.go中定义的LLMProvider接口,并根据模型 ID 将请求路由到相应的服务。
工具系统
工具扩展了 Agent 超越文本生成的能力。每个工具都实现一个执行接口,并为 LLM 提供调用它的模式。工具被注册在一个claudetool.ToolSet中,并在对话轮次中提供给 LLM 使用。
六、数据模型
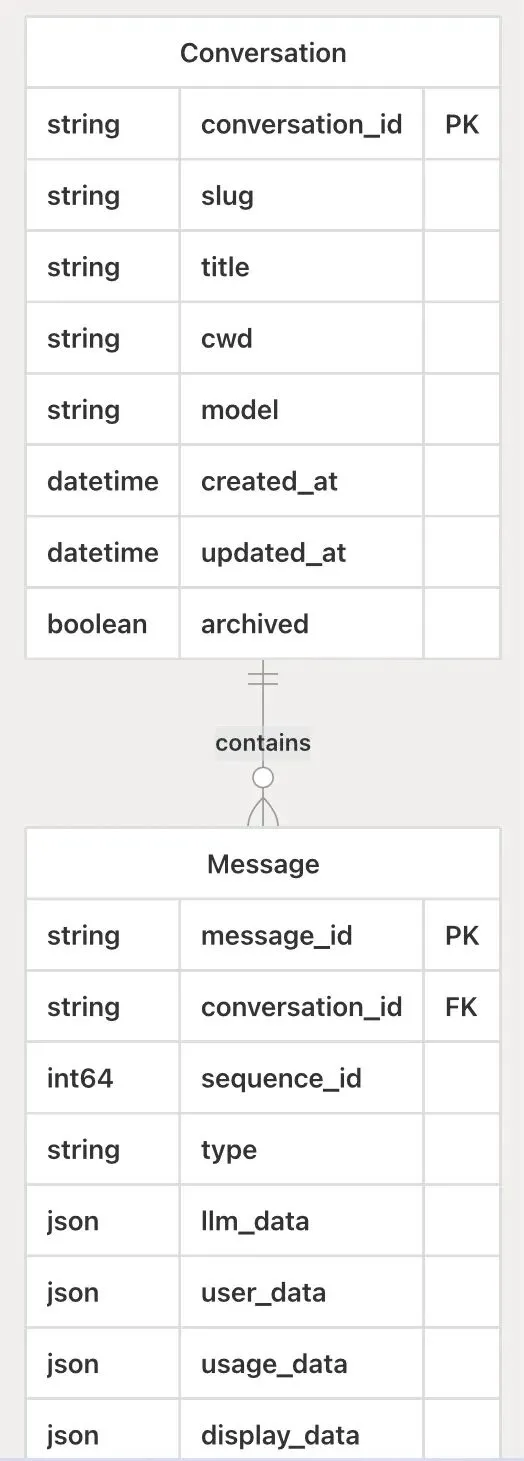
Shelley 的核心数据模型围绕对话与消息这两个核心实体构建,所有交互历史和状态都通过它们进行定义和持久化。
对话结构
对话代表与 AI 代理进行的一个完整交互线程。在数据库中,它对应conversations表,其核心字段包括:
conversation_id: 唯一标识符(主键)。slug: 一个人类可读的短标识,用于生成可直接访问的 URL。title: 对话的标题。cwd: 当前工作目录,用于工具执行(如 Bash、Git)的上下文。model: 该对话选择的 LLM 模型。created_at/updated_at: 时间戳,记录创建和最后活动时间。archived: 布尔值,标记对话是否已归档。
每个对话在逻辑上通过conversation_id隔离,并对应一个缓存在服务器内存中的server.ConversationManager实例来管理其活动生命周期。
消息结构
消息是对话中的一个独立轮次或事件。它对应messages表,是系统中最活跃的数据单元。其关键字段设计如下:
message_id: 唯一标识符(主键)。conversation_id: 外键,关联到所属的对话。sequence_id: 一个int64类型的序列号,用于在对话内对消息进行排序。type: 消息类型,由db.MessageType枚举定义,用于区分消息的来源和用途:user: 用户输入的文本或图像。agent: LLM 生成的响应,可能包含文本或工具调用指令。tool: 工具(如 Bash、Patch、Browser)执行后产生的结果。error: 系统或工具执行过程中产生的错误信息。gitinfo: Git 仓库状态变更的通知。
llm_data: 一个 JSON 字段,存储 LLM 提供商所需的结构化消息格式(llm.Message),用于维护对话上下文和进行下一次 LLM 调用。user_data: 一个 JSON 字段,存储与用户输入相关的原始数据。display_data: 一个 JSON 字段,包含工具特定的渲染数据,供前端 UI(如DiffViewer组件)展示丰富内容,例如代码差异的详细信息。usage_data: 一个 JSON 字段,用于跟踪令牌消耗和成本。created_at: 消息创建的时间戳。
这种结构化的消息模型确保了从用户输入、LLM 推理、工具执行到最终界面渲染的整个数据流都得以完整记录和关联,为对话的持续性、可追溯性以及实时流式更新提供了坚实的数据基础。
七、请求-响应流程
在完成对 Shelley 系统架构与核心数据模型的基本介绍后,一个核心问题浮现:当用户输入一条消息后,系统内部究竟发生了哪些关键事件,才能将用户的自然语言指令转化为工具行动,并最终将结果实时呈现在前端?这是一个 LLM 驱动的智能体(Agent)核心的迭代循环过程。下图概括了从用户消息提交到结果流式返回的完整数据流与关键角色:
具体来说,该流程依据 <搜集资料> 可分解为以下十个关键步骤:
1. HTTP 请求接收
前端通过POST /api/conversation/{id}/chat端点发送用户消息。HTTP 处理器(位于server.Server中)接收到请求,其中包含了对话的唯一标识符conversation_id和用户输入的内容。
2. 对话会话管理器定位
服务器调用getOrCreateConversationManager方法,根据conversation_id从Server.activeConversations映射中检索对应的server.ConversationManager实例。如果该对话的会话管理器不存在(例如对话首次被激活),则会创建一个新的管理器并缓存。
3. 启动代理主循环
检索到的ConversationManager调用其AcceptUserMessage方法。此方法的核心职责是启动或唤醒与该对话绑定的loop.Loop(代理主循环),并将用户消息传递给它,从而驱动一次完整的“思考-行动”迭代。
4. 持久化用户消息
loop.Loop首先将接收到的用户消息(类型为user)通过db.DB.CreateMessage方法持久化到 SQLite 数据库的messages表中。这条记录包含了完整的user_data等信息。
5. 构造并发送 LLM 请求
接着,循环通过LLMManager.GetService().Do()方法调用 LLM 服务。它会将当前的完整对话历史(从数据库中加载)以及所有已注册的可用工具(claudetool.ToolSet)的模式(schema)一同发送给选定的 LLM 提供商。
6. 接收并解析 LLM 响应
外部 LLM(如 Anthropic Claude API)处理请求后,返回包含纯文本和/或结构化工具调用(tool calls)的响应。models.Manager抽象层将此响应返回给loop.Loop。
7. 执行工具调用(迭代循环)
如果 LLM 的响应中包含工具调用,loop.Loop会依次执行这些工具。每个工具(如BashTool,PatchTool)根据调用参数运行,并将执行结果(成功或错误)收集起来。
8. 工具结果回传与持续对话
loop.Loop将工具执行的结果作为新的上下文,再次发送回 LLM(重复步骤 5-7),以获取基于工具结果的后续分析或进一步的动作指令。这个“LLM 思考 -> 工具执行 -> 结果反馈”的循环可能会持续多轮,直到 LLM 决定返回最终的文本答复给用户。
9. 全链路消息持久化
在整个流程的每一步,只要产生新的消息实体,无论是agent(LLM 回复)、tool(工具结果)、error还是gitinfo,loop.Loop都会通过db.DB.CreateMessage将其作为一条独立的记录写入数据库。每条消息都包含完整的llm_data、display_data和usage_data,确保对话的全链路可追溯。
10. 实时流式推送至前端
在每次成功调用db.DB.CreateMessage写入数据库之后,ConversationManager会立即调用notifySubscribersNewMessage方法。该方法将这条新消息广播给所有通过/api/conversation/{id}/stream端点连接的 Server-Sent Events (SSE) 订阅者。前端浏览器通过这个 SSE 连接,实时地、增量地接收到对话的所有更新(用户消息、LLM 思考过程、工具调用与结果、错误信息等),并渲染到 UI 中。
这完整的“请求-响应”流程,构成了 Shelley 作为 AI 编程助手与用户进行多轮、工具增强式对话的核心引擎。它确保了用户意图被可靠地转化为行动,所有中间状态被完整记录,且结果的交付是实时、流式的。
八、API 接口
Shelley 的 HTTP 服务器 (server.Server) 通过其RegisterRoutes方法,对外暴露了一套完整的 RESTful API。所有客户端交互都通过这些预定义的端点进行,它们与之前章节介绍的ConversationManager和 Server-Sent Events (SSE) 机制紧密配合,共同驱动整个应用。
主要端点列表
下表列出了 Shelley 后端提供的主要 HTTP API 端点、其方法及核心用途:
| 端点 | 方法 | 用途 |
|---|
/api/conversations | GET | 列出非归档的对话 |
/api/conversations/archived | GET | 列出已归档的对话 |
/api/conversations/new | POST | 创建新对话 |
/api/conversation/{id}/chat | POST | 向指定对话发送消息(触发核心处理流程) |
/api/conversation/{id}/stream | GET | 订阅指定对话的SSE 实时更新流 |
/api/conversation/{id} | GET / PATCH / DELETE | 对话的获取、更新(如归档)、删除操作 |
/api/git/diffs | GET | 列出 Git 仓库的差异 |
/api/git/file-diff/{path} | GET | 获取特定文件的详细差异 |
/api/upload | POST | 上传文件(例如,用户发送的图片) |
/api/read | GET | 读取已上传的文件 |
/api/validate-cwd | GET | 验证工作目录的有效性 |
/api/list-directory | GET | 列出目录内容 |
中间件与根路径
所有 API 端点都统一经过一组中间件处理,以确保请求的日志记录、安全和性能:
- LoggerMiddleware:记录 HTTP 请求和响应信息。
- CSRFMiddleware:提供跨站请求伪造保护。
- gzipHandler:对响应数据进行 GZIP 压缩,提升传输效率。
此外,根路径/被用于服务嵌入到 Go 二进制文件中的 React 前端用户界面,其静态资产来自ui.Assets()。
九、构建与分发
Shelley 的构建与分发遵循一个清晰的管道,旨在生成单一、自包含的跨平台二进制文件。
构建流程
构建管道是一个多阶段过程:
- UI 构建:位于
ui/src/的 TypeScript 源代码由esbuild编译和打包,生成资产到ui/dist/目录。 - 嵌入:
ui/dist/目录通过go:embed指令(定义在ui/embedfs.go中)被嵌入到 Go 二进制文件中。 - Go 构建:Go 源代码被编译成一个名为
shelley的单一二进制文件。 - 交叉编译:GoReleaser为 Linux 和 macOS 的 AMD64 和 ARM64 架构创建二进制文件。
版本方案
Shelley 采用一种确定性版本方案:v0.N.9OCTAL,其中:
- N是 git 历史中的总提交数。
- 9OCTAL是提交 SHA 的前 6 个字符编码为八进制,并以
9为前缀。
此方案确保每个提交都有一个唯一的、可复现的版本号。每次推送到主分支都会自动创建新版本。
分发渠道
预构建的 Shelley 二进制文件通过以下渠道分发:
- GitHub Releases:提供适用于 Linux 和 macOS(AMD64 和 ARM64)的预构建二进制文件。
- Homebrew:通过
boldsoftware/tap/shelley进行 Cask 安装。 - 源码:使用
make从源代码构建。
十、开发历史与许可
Shelley的项目历史与命名本身反映了其以 AI 辅助、迭代演进为核心的开发理念。其代码的开源与贡献规范则由明确的协议管理。
发展历程:基于前代项目的 AI 协创
Shelley 部分建立在名为Sketch的上一代 AI 编码助手项目的基础上。其绝大部分代码的编写大量借助了包括 Shelley 自身、Sketch、Claude Code 和 Codex 在内的多种 AI 编程助手。这实践了一种自举式的开发方式,即使用 AI 助手来构建和迭代自身的代码库,使其自身成为其核心能力的产物。
项目命名:实用主义与诗意的结合
项目名称“Shelley”的由来具有双重含义:
- 工具之源:源于其核心使用的工具——Shell(命令行终端),体现了其作为执行命令、与系统交互的智能助手本质。
- 文化指涉:引用自英国浪漫主义诗人珀西·比希·雪莱(Percy Bysshe Shelley)的著名诗歌《奥兹曼迪亚斯》(“Ozymandias”)。这一引用为项目名称增添了文学色彩和象征意义。
开源许可与贡献规范
Shelley 项目采用Apache License 2.0开源协议进行分发。该协议是商业友好的 permissive 许可证,允许用户自由使用、修改和分发软件,同时要求保留版权和许可声明。该协议的具体条款可见于项目源码仓库中包含的LICENSE文件。
为了保证项目持续贡献的法律明确性和一致性,所有贡献者(Contributors)都需要签署一份贡献者许可协议(Contributor License Agreement,简称 CLA)。这一流程有助于明确知识产权归属,保障项目及其使用者的权益。