代码就是一切:为什么Anthropic不再做“专用Agent”?
- 2026-07-06 07:56:01
大纲(先对齐结构)
• TL;DR:3分钟带走 5 个结论 • “代码就是一切”到底在说什么 • 能力强,但为什么还是干不好活 • Skills 是什么:一个目录,把流程、资料、脚本装在一起 • 渐进式披露:为什么它能规模化到“几百个技能” • 技能生态与趋势:从文档到工作流,和 MCP 怎么配合 • 一张图讲清完整架构:Loop / Runtime / MCP / Skills • 团队怎么落地:把重复工作变成技能库(含模板与清单) • 边界与风险:别把它当成万能药
TL;DR:3分钟带走 5 个结论
• Anthropic 的结论很直白:“代码”正在变成 Agent 做数字工作的统一接口。Bash + 文件系统 + 脚本,足够覆盖大量“真实工作”。 • 模型更聪明了,反而更容易暴露短板:通用能力不等于领域经验。真正缺的不是推理,而是可复用的 SOP、检查清单、模板、工具链。 • 从工程视角看,Skills 更接近一套“可版本化的文件资产”: SKILL.md(入口)+references/(资料)+ 可执行脚本(工具)。• 渐进式披露是关键:启动只暴露元信息(几十 tokens),命中才加载 SKILL.md(几百 tokens),需要细节再按需读references/(几千 tokens)。所以你可以给 Agent 配很多技能,但上下文成本仍可控。• 他们给出了一个更完整的 Agent 架构分层:Agent Loop(推理) / Runtime(执行) / MCP(连接外部) / Skills(专业知识与流程),并推进 Skills 标准化(agentskills.io)。
“代码就是一切”到底在说什么
Anthropic 在 2026-01-22 的这篇文章里,用一句话把他们的路线说透了:不要再把“代码”只当成一个用例,而要把它当成 Agent 的工作界面。
你可以把 Claude Code 想成一种“通用 Agent 的执行壳”:
• 需要查资料,写一段代码调 API。 • 需要整理数据,落到文件系统里,用脚本清洗、统计、画图。 • 需要产出报告,把结构、表格、格式要求写进脚本或模板。
过去我们喜欢“按领域造 Agent”:金融一个、市场一个、法务一个。Anthropic 说他们也这么想过,但后来发现,随着模型能力提升,这条路反而越走越重:不同 Agent 的工具、脚手架、状态管理、提示词体系都要重复造。
更轻的做法是:用一个通用 Agent + 代码执行环境承载能力,再用 Skills 承载经验。
能力强,但为什么还是干不好活
这里他们用了一个比喻,我觉得很贴切:
你愿意让谁帮你报税?
• 一个数学天才,从第一性原理推导税法 • 一个报过几千份税表的会计
多数人会选后者。原因很简单:会计的优势不在智商,而在经验。
今天的 Agent 很像数学天才:推理强、能举一反三,遇到真实工作却经常卡在三件事上:
• 缺背景:组织里的约定、历史决策、合规红线,模型默认不知道。 • 难沉淀:同类任务反复做,输出漂移,质量靠人盯。 • 不会自己长记性:这次踩过的坑,下次还会踩。
所以问题不在“智商”,而在“职业训练”。Skills 想补的就是这块。
Skills 是什么:一个目录,把流程、资料、脚本装在一起
Anthropic 给的定义非常工程化:Skills 是一组文件的组织方式,用来打包领域专业知识。
它可以简单到只有一个入口文件,也可以复杂到带一堆脚本和参考资料。典型结构像这样:
anthropic_brand/
├── SKILL.md
├── docs.md
├── slide-decks.md
└── apply_template.py这里有个容易被忽略的点:Skill 的载体是文件。
这意味着它天然具备工程属性:
• Git 可版本化,可 Code Review。 • 可放在共享盘或仓库,团队可复用。 • 不要求人人会写代码。产品、分析师、领域专家也可以贡献模板、清单、规范。
渐进式披露:为什么它能规模化到“几百个技能”
目录结构只是表象,真正让 Skills 变成“平台能力”的,是加载方式。
Anthropic 把它做成三层:
1. 元信息(metadata):只暴露 name/description,成本大概 ~50 tokens。它更像“路由表”,告诉模型“我会什么”。2. SKILL.md:当模型判断“需要这个 Skill”时才读取入口文件,成本大概 ~500 tokens。入口文件负责写清楚:流程、边界、验收方式。3. references/:需要更多细节时才按需读取,单个参考文件可能是 2000+ tokens,但不会常驻上下文。
你可以用一张图理解它的运行方式:
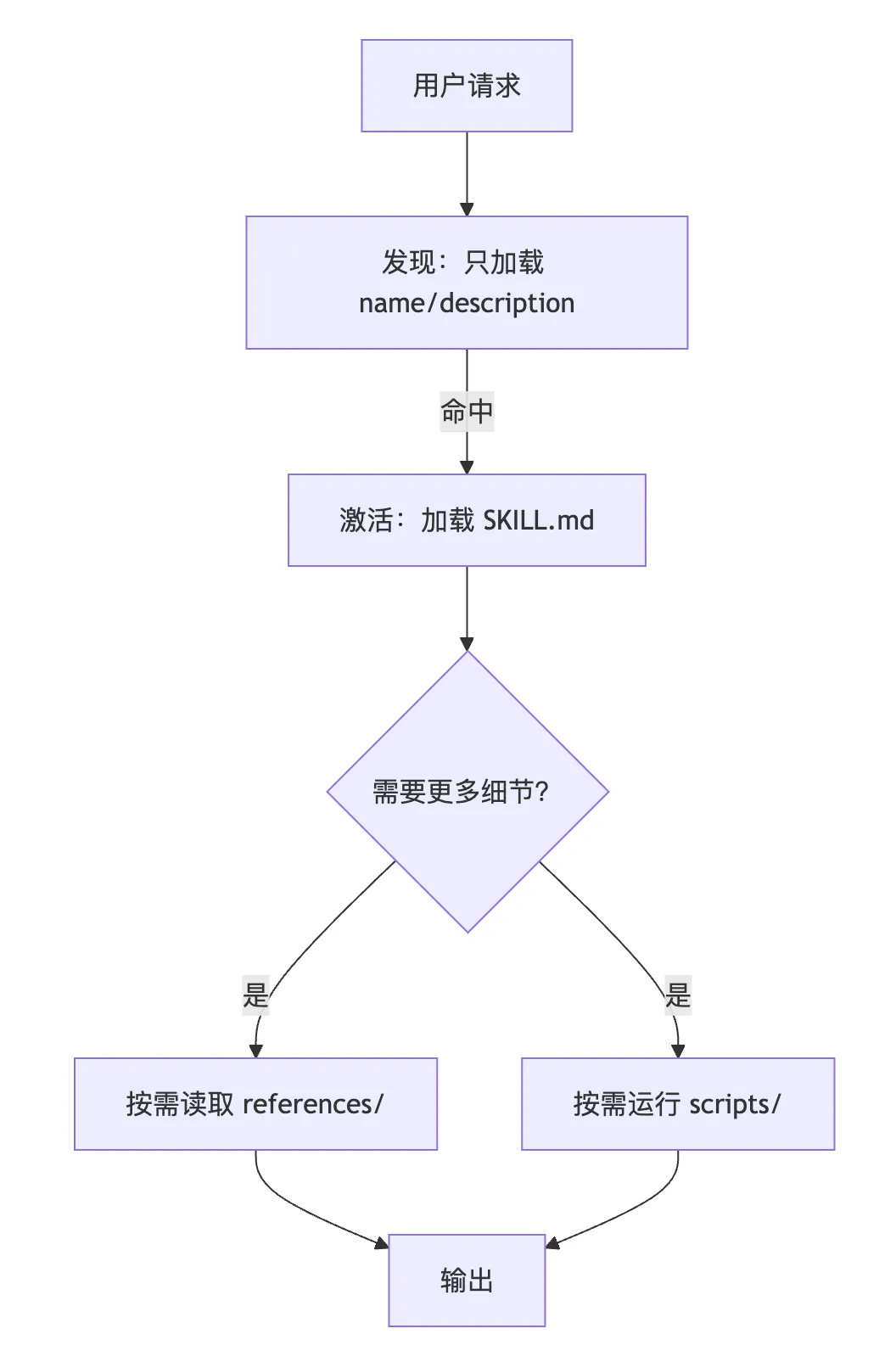
工程含义很直接:技能规模可以很大,但常驻上下文仍然很轻。
description 不是简介,更像路由规则
很多团队第一次写 Skill,最容易写废的地方是 description。
它更像一条路由规则,告诉模型两件事:
• 什么时候该用它 • 用了之后会产出什么
写法上有两个小技巧:
• 用“真实触发词”写进去:团队成员会怎么说,就把关键词放进 description。• 把产出说具体:报告、表格、代码改动、检查清单,别写成抽象能力。
脚本即工具:把确定性工作交给代码
文章里举了一个很现实的例子:他们反复看到 Claude 写同一段脚本,用来把演示文稿套上 Anthropic 的模板。
与其每次都“让模型再写一遍”,不如把脚本保存下来,让 Agent 自己调用。
这一点我非常认同,因为它踩中了传统“工具化”的三个痛点:
• 工具说明写得烂,模型理解成本高。 • 工具不易改,遇到边缘情况只能硬 prompt。 • 工具描述一长,上下文膨胀。
脚本的好处是:可执行、可修改、可复用。模型从“重复劳动者”退回到“编排者”。
技能生态与趋势:从文档到工作流
Anthropic 观察到 Skills 很快出现了三类生态:
• 基础技能:文档、表格、演示等通用能力,把最佳实践固化下来。 • 伙伴技能:第三方公司把服务封装成 Skills,让 Agent 能直接调用(更像一种“能力接入协议”)。 • 企业技能:把组织内部流程、合规要求、制度知识封装成 Skills,变成企业可复用资产。
他们还给了一个很有用的“复杂度刻度”:
• 简单:100 行级别,模板与格式化(例如状态报告写作器) • 中等:800 行级别,数据检索 + 复杂计算(例如财务模型) • 复杂:2500+ 行级别,多工具协作与工作流编排(例如 RNA 测序管道)
我更关注的是这个趋势:Skill 会从“文档型知识”演进为“可执行工作流”。
这也是 MCP 发挥作用的地方。
Skills 和 MCP 怎么配合
如果把 Skills 看成“怎么做”,MCP 更像“去哪里拿数据、用什么外部工具”。
Anthropic 的例子是竞争分析:一个 Skill 可以编排 Web 搜索、内部数据库(通过 MCP)、Slack 历史、Notion 页面,最后汇总成一份结构化报告。
这里的分工很干净:
• Skills 负责流程、模板、检查点、验收方式。 • MCP 负责连接外部世界,把数据和工具带进来。
为什么他们要把 Agent Skills 做成开放标准
文章里提到他们在推进 Skills 标准化(agentskills.io),动机我理解主要是两点:
• 可移植:同一个 Skill,不应该被锁死在某个平台或某个工具栈里。 • 可共享:社区里沉淀出来的好技能,能在不同团队之间迁移复用,让后来的 Agent 天生就更“职业”。
这件事如果真跑通,影响会比“又多了一套配置格式”大:它会把经验从“人脑”搬到“文件资产”,再从“单团队资产”搬到“生态资产”。
一张图讲清完整架构:Loop / Runtime / MCP / Skills
文章给出了一个四层架构,我建议每个做 Agent 工程的人都记住它:
1. Agent Loop:决定下一步做什么(推理与规划) 2. Agent Runtime:执行环境(代码、文件系统、沙箱) 3. MCP Servers:连接外部工具与数据源 4. Skills Library:领域专业知识与程序化流程 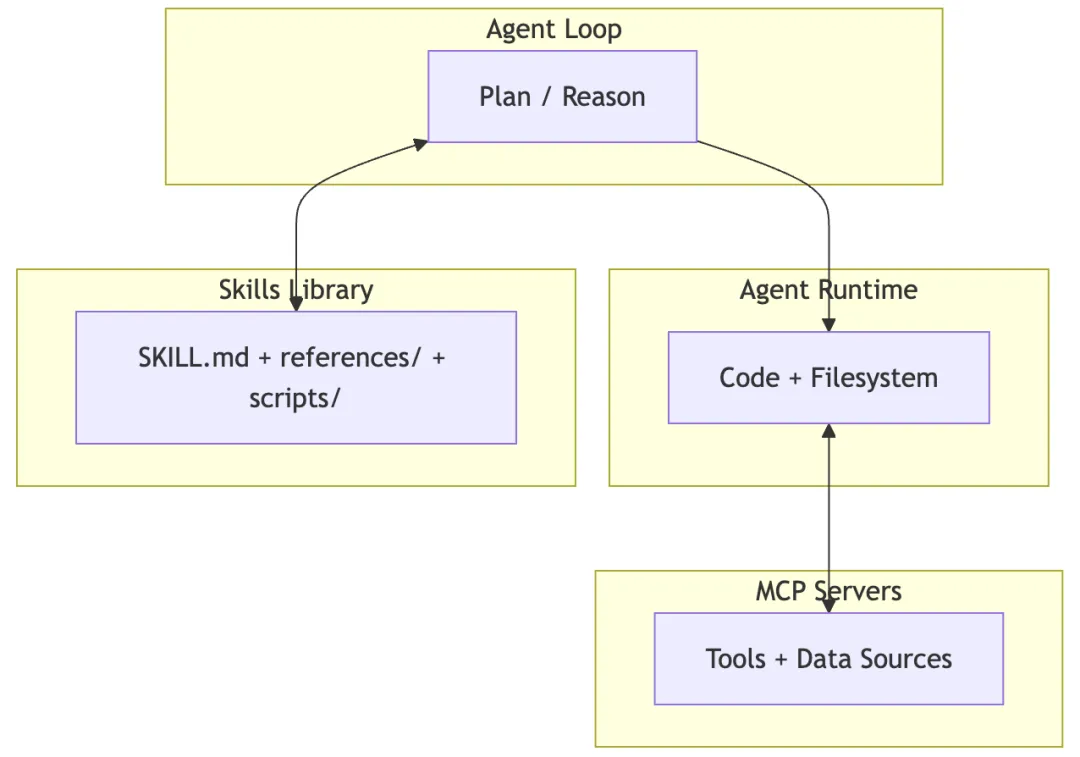
这种分层的价值在于:每层都能独立演进。推理模型变强不影响 Skill 资产,MCP 更换供应商不影响流程结构。
团队怎么落地:把重复工作变成技能库
如果你想在团队里用起来,我建议按“最小可用”做,不要一上来就想着搞一个“全能技能平台”。
1) 选题:从高频、可验收的任务下手
优先挑这类:
• PR review(风险识别 + 测试补齐 + 输出模板) • 故障分级与排障(证据收集 + 定位步骤 + 复盘模板) • 周报/月报/项目状态报告(结构化输出 + 指标口径) • 投标材料/宣讲 PPT(模板 + 自动化套版脚本)
信号也很简单:同一件事你们每周都在重复做,且每次都要“重新说明一遍怎么做”。
2) 写 SKILL.md:只写入口,不写百科
入口文件建议只放三件事:
• 流程:按顺序做什么 • 边界:缺什么先问,什么情况不要做 • 验收:怎样算完成(尽量可验证)
一个很小的骨架示例:
---
name: incident-triage
description: 线上故障分级与排障流程。用于收集证据、定位根因、制定修复或回滚方案并输出复盘草稿。触发词:告警、线上故障、排障、root cause、回滚、复盘。
---
## 输入
- 业务影响描述、告警截图或日志链接、最近变更(commit、发布单)
## 流程
1) 收集证据:日志、指标、变更点
2) 缩小范围:时间窗口、组件边界、可疑变更
3) 给出处置:修复或回滚,明确验证步骤
4) 输出复盘草稿:时间线、根因、改进项
## 验收
- 给出可执行的验证命令或检查点
- 复盘草稿包含时间线与可追踪证据3) 把确定性部分脚本化
只要能脚本化,就别让模型“即兴发挥”:
• 结构校验(Markdown 结构、JSON schema、表格字段) • 批量抓日志和关键指标 • 生成固定格式的表格、PPT、报告骨架
模型更擅长的部分,是“编排”和“判断”:接到一个模糊请求,拆解成步骤,决定调用哪个脚本、读哪份资料。
4) 把“创建 Skill”做成标准动作
Anthropic 提到一个细节:Skill 的贡献者正在从工程师扩展到产品、分析师、领域专家。他们甚至做了一个 skill-creator 工具,帮助人在 30 分钟内做出第一个可用 Skill。
你不一定要用他们的工具,但可以学这个思路:把“写 Skill”本身也做成一套模板。
比如约定每个 Skill 都带这些小段落:
• 输入长什么样(链接、文件、字段) • 输出长什么样(结构、格式、文件落点) • 异常怎么处理(缺权限、缺数据、环境不满足)
5) 设一个“技能治理”底线
技能库一旦开始增长,就会出现两类债务:
• 过期:流程变了,Skill 没更新 • 混乱:同一类技能重复建设,路由互相打架
最小治理方式也很简单:
• 每个 Skill 标注 owner • description写清触发场景,避免重叠• 每季度做一次“技能盘点”,删掉不用的,合并重复的
可直接照做的落地清单(12 条)
• 把“高频重复任务”拉一张清单,先选 1 个做试点 • 明确输入、输出、验收标准,不要一上来写长文档 • description写成路由规则:触发场景 + 产出物• 入口 SKILL.md只写流程、边界、验收,细节拆进references/• 把模板、清单、口径表放进 references/,不要常驻上下文• 把确定性操作脚本化:校验、抽取、格式化、生成骨架 • 给脚本设计失败模式:缺权限、缺依赖、输入不合法要能报清楚 • 给每个 Skill 设 owner,允许小步迭代 • 建一个“技能目录页”,让团队知道“有哪些能力可以直接调用” • 每月做一次技能盘点:合并重复、删掉不用、补齐验收 • 安全与合规前置:能读什么、能写什么、能跑什么脚本写清楚 • 当 Skill 超过 20 个,开始考虑命名规范与分类体系
边界与风险:别把它当成万能药
Skills 更像“把经验做成资产”,它不会替你解决所有问题:
• 它解决不了“没有数据、没有权限、没有工具”的现实约束,最多帮你把缺口说清楚。 • 它也解决不了“需求不明确”。入口文件写得再好,输入不足仍然只能先追问。 • 安全与合规要前置:能读什么、能写什么、能跑什么脚本,要在 Skill 的边界里写清楚。
结语:别再把工程经验塞进一次次对话里
我读完这篇文章最大的感受是:Anthropic 正在把 Agent 从“会聊天的模型”推向“可交付的工程系统”。
通用 Agent 负责能力上限,Skills 负责稳定性与可复制性。
如果你今天在做 Agent 产品或团队落地,我建议你至少试一次:选一个高频任务,把它从提示词里挪出来,做成一个小 Skill。等你做出 5 个,你会明显感觉到系统开始“长记性”。
参考
• Anthropic Blog(2026-01-22):Building Agents with Skills: Equipping agents for specialized work https://claude.com/blog/building-agents-with-skills-equipping-agents-for-specialized-work• 新范式:代码就是一切 https://claudecn.com/blog/claude-skills-new-paradigm-code-is-all-you-need/如喜欢本文,请点击右上角,把文章分享到朋友圈如有想了解学习的技术点,请留言给若飞安排分享
因公众号更改推送规则,请点“在看”并加“星标”第一时间获取精彩技术分享
·END·
相关阅读:
Claude Code 最佳实践:把上下文变成生产力(团队可落地版) 把 AI 当成新同事:Agent Coding 的上下文与验证体系 一周写百万行的背后:Cursor长时间运行 Agent 的工程方法论 2026年生活重启指南 我真不敢相信,AI 先加速的是工程师。 扒一扒 Claude Cowork 系统提示词:Anthropic 如何打造数字同事 Cowork 安全架构深度解析:从 Claude Code 到 Cowork,Anthropic 如何把“可控”做成产品 Anthropic官方万字长文:AI Agent评估的系统化方法论 银弹还是枷锁?Claude Agent SDK 的架构真相 Claude Code创始人亲授13条使用技巧 Claude Code 内部工具开源 code-simplifier:终结 AI 屎山代码的终极方案
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
架构师 我们都是架构师!

关注架构师(JiaGouX),添加“星标”
获取每天技术干货,一起成为牛逼架构师
技术群请加若飞:1321113940 进架构师群
投稿、合作、版权等邮箱:admin@137x.com
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 欢迎免费试听!NOAI奥赛官方指定Python寒假课开班啦!直击LMCC认证高效夺奖,报名立省3000元!
- 不懂 Python 也能搞量化?4 个网站,轻松搞定 A 股回测
- 50个Python常用库,数分必备!
- 熬夜整理了自学Python超绝路线图
- 基于Python深度学习的车辆车牌识别系统(PyTorch2卷积神经网络CNN+OpenCV4实现)- 集成到web系统-车牌识别实现
- 521 页!800 个实例!清华 Python"砖头书":是入门捷径还是知识过载?《王者归来》
- Python窗体开发新玩法 AI生成草稿再转设计器精调美化
- 2026年AI工程新范式:从写代码到搭架构,一个价值千万的思维转变
- AI+编程:物体观察--三视图动画分享
- 《Python让繁琐工作自动化》(1)
