点击上方蓝字关注我们
“在软件开发中,调试和修复代码问题一直是工程师们最耗时的工作之一。随着大语言模型的发展,能否让AI自动完成这些任务?”
本文介绍了NVIDIA团队在ICML 2025上发表的论文NEMOTRON-CORTEXA: Enhancing LLM Agents for Software Engineering Tasks via Improved Localization and Solution Diversity,提出了一个创新的AI代码助手系统。该系统在真实GitHub问题修复基准测试SWE-bench上取得了优异成绩,在SWE-bench Lite上达到42.00%的问题解决率,在SWE-bench Verified上达到52.60%,同时每个问题的平均成本仅为0.51美元,展现了实用价值。
论文链接可在ICML 2025会议论文集中查找,相关代码和模型NV-EmbedCode已在https://build.nvidia.com/nvidia/nv-embedcode-7b-v1发布。
真实软件工程任务的挑战
当前的大语言模型在解决编程面试题方面表现出色,但真实的软件工程任务远比这复杂得多。研究团队指出,实际代码仓库往往包含数十万行代码,而问题描述通常只有几百个词。例如,SWE-bench数据集中的实例平均每个问题描述195个单词,但对应的代码库却有43.8万行代码。
这带来了三个核心难题。首先是上下文窗口限制,即使是最先进的大语言模型也无法一次性处理整个代码库。其次是定位精度问题,模型需要从海量代码中准确找到需要修改的具体位置。第三是解决方案的多样性,不同的修复思路可能解决不同的问题子集。
现有的方法如OpenHands和SWE-Agent采用自由形式的操作序列,但动作空间大导致迭代成本高。Agentless虽然使用了结构化流程,但在准确定位问题和生成正确修复方案方面仍有提升空间。
专门的代码嵌入模型
NEMOTRON-CORTEXA的第一个关键创新是开发了专门用于代码检索的嵌入模型NV-EmbedCode。传统方法要么让大语言模型仅根据文件名判断相关性,要么使用通用嵌入模型效果不佳。
研究团队从现有的文本嵌入模型NV-EmbedQA-Mistral-7B-v2出发,使用LoRA技术进行参数高效微调。训练数据包含约53.4万对查询-文档样本,涵盖三类任务:从问题描述检索需要修改的文件、从大语言模型生成的问题摘要检索文件,以及各种通用代码检索任务。
为了增强模型对代码的理解,训练集还融合了公开数据集,包括文本到代码、代码到代码和混合检索任务。团队还通过提示DeepSeek-v2.5模型,根据编程问题生成代码,构建了合成数据集。
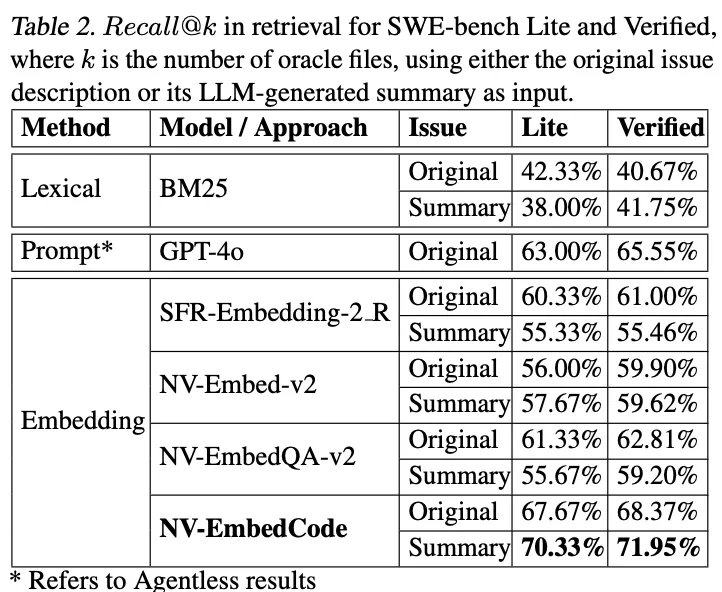
实验结果显示,NV-EmbedCode在SWE-bench Lite上达到70.33%的召回率,在Verified集上达到71.95%,明显超越了现有的嵌入模型和基于提示的方法。Table 2展示了不同检索方法的对比结果,证明了专门训练的代码嵌入模型的有效性。
仅仅找到相关文件还不够,因为完整文件内容仍可能超出上下文限制。NEMOTRON-CORTEXA设计了一个定位代理,能够进一步将问题定位到具体的类、函数或方法级别。
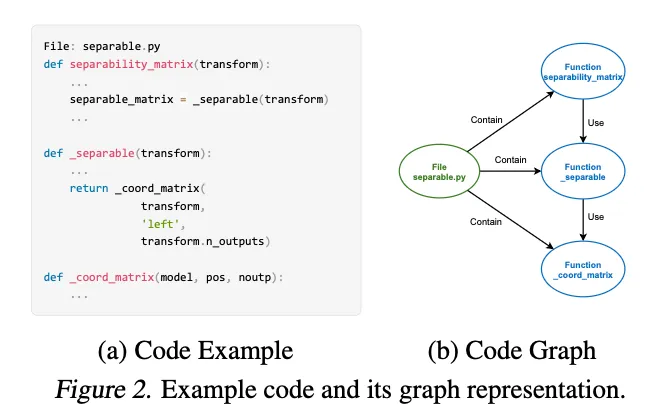
系统首先使用抽象语法树构建代码库的图结构表示。节点代表文件和代码实体,边分为两类:contain边表示层级关系(如文件包含函数),use边表示功能依赖(如函数调用)。Figure 2展示了代码示例及其图表示。
定位代理配备了三个工具来导航这个代码图:get_definition获取指定实体的代码定义,get_incoming_dependency查找调用该实体的代码,get_outgoing_dependency查找该实体调用的代码。这些工具基于语言服务器协议实现,类似于集成开发环境中的跳转到定义和调用层级功能。
代理从嵌入模型检索的前6个文件开始,先用大语言模型识别可疑实体,然后通过最多5轮工具调用探索相关代码。每轮可以发起多次工具调用,代理会过滤上下文只保留相关信息,避免上下文过载。
研究团队发现,生成修复方案的上下文和提示格式对结果有显著影响。即使其他条件相同,仅改变补丁格式就会产生不同的解决方案,且能解决不同的问题实例。
团队对比了两种编辑格式:search/replace格式包含要替换的原始代码和替换内容,edit_file格式指定文件路径、起止行号和修改内容。同时考虑两种上下文:定位代理识别的实体和检索到的顶级文件。
Figure 3的维恩图展示了不同组合的效果。四种组合在SWE-bench Lite上分别解决了19.3%到32%的问题,但它们覆盖的问题实例有很大差异。通过组合所有策略,总体通过率达到40.3%。
基于这一发现,NEMOTRON-CORTEXA采用了创新的多样化生成策略。系统考虑4种上下文(File、LA、DP和LA+DP组合)、2种编辑格式和2种温度设置(贪婪采样0.0和温度采样0.8)。最终生成9个候选补丁:4个用贪婪采样不同上下文和格式组合,1个用特定组合,4个用温度采样。
这种方法比Agentless的40个补丁方案更高效。实验表明,通过增加生成策略的多样性而非简单增加采样次数,可以用更少的推理调用达到更好的效果,将补丁生成的推理调用次数减少了4.4倍。
NEMOTRON-CORTEXA还采用了模型集成策略。定位代理使用四个不同的大语言模型实例化:DeepSeek-v3、GPT-4o、Llama-3.3 70B和Qwen2.5-72B-Instruct。
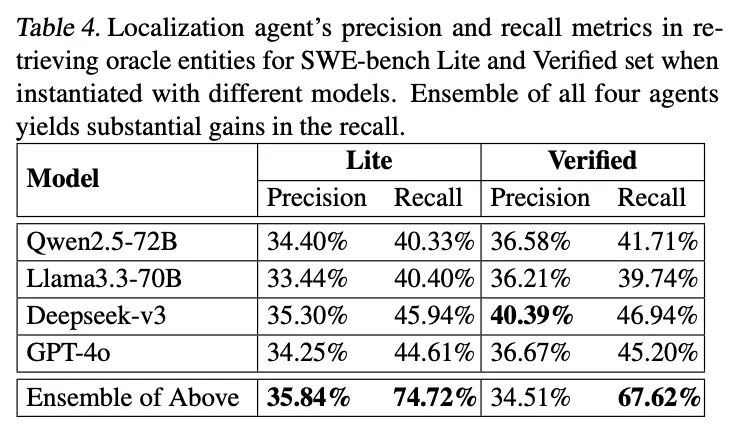
Table 4显示了集成效果。单个模型在SWE-bench Lite上的召回率在40.33%到45.94%之间,但四个模型的集成将召回率提升到74.72%,在Verified集上从最好的46.94%提升到67.62%。这表明不同模型在解决不同问题子集上各有优势,集成能够充分利用它们的互补能力。
补丁选择过程包括多个过滤步骤。首先移除无法生成有效编辑指令或导致语法错误的方案。然后对代码进行标准化处理,删除注释和文档字符串,统一变量和函数名,记录重复方案的频率。接着使用回归测试和生成的复现测试过滤失败的方案。最后通过多数投票选择最终补丁。
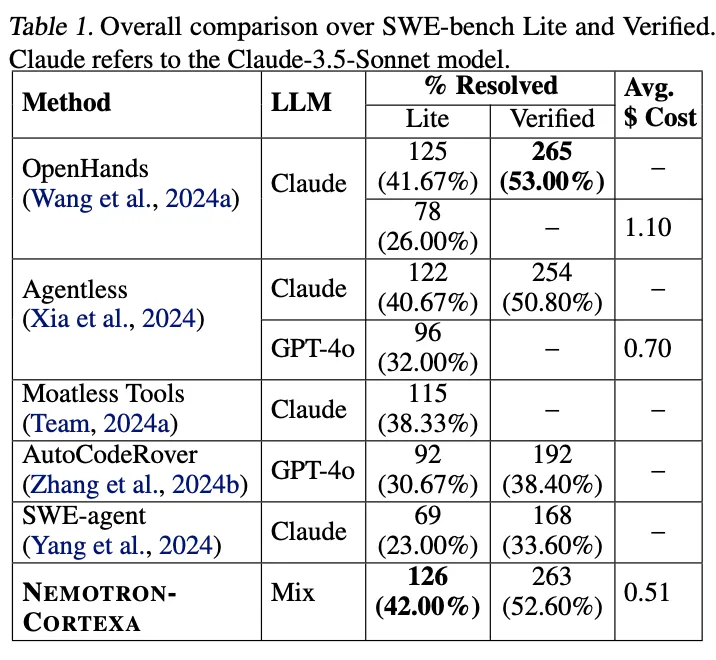
整个系统在SWE-bench Lite上解决了126个问题(42.00%),在Verified上解决了263个问题(52.60%),平均每个问题成本仅0.51美元。相比之下,OpenHands在Lite上的解决率为26%但成本1.10美元,Agentless为32%成本0.70美元。Table 1展示了与其他方法的全面对比。
这项研究提供了几个重要启示。首先,针对特定任务微调嵌入模型能够显著提升检索准确性,专门的代码嵌入模型比通用模型更适合软件工程任务。其次,多步推理结合专门工具能够实现更精确的问题定位,抽象语法树和语言服务器协议为代码导航提供了有效支持。
第三,解决方案的多样性比单纯增加采样次数更重要。通过改变上下文和提示格式生成的多样化方案,能够以更低成本覆盖更多问题实例。第四,模型集成是推理时扩展的有效途径,不同模型的互补优势能够大幅提升整体性能。
研究团队指出,当前的多数投票选择机制仍有改进空间,因为正确方案可能只生成一次。通过使用基于大语言模型的投票、生成更准确的复现测试,以及在补丁生成阶段使用推理模型,系统在Verified集上的解决率可以达到68.4%,但成本会上升到每个问题3.28美元。
这项工作展示了通过改进定位和增加解决方案多样性来增强大语言模型软件代理的有效路径,为自动化软件工程任务提供了实用的技术方案。
素材来自于网上公开开源内容,内容经LLM辅助,如有侵权,随时可删。 更多信息请关注本公众号(小红书同名)。 喜欢就关注哦



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
