AI生成代码检测的持续演进
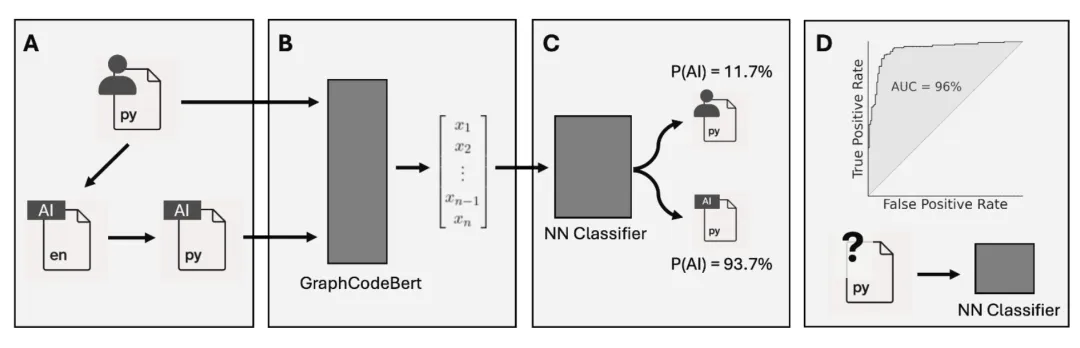
该研究构建的分类器依赖GraphCodeBert提取代码特征。随着生成式AI模型的快速迭代,检测方法需要持续更新。对抗性训练框架可以模拟"检测器-生成器"的军备竞赛,通过生成对抗网络(GAN)让检测器学习识别最难区分的AI代码。元学习方法可以使检测器快速适应新模型:在多个已知模型上预训练后,仅需少量新模型样本即可微调。此外,代码风格的时间漂移是一个挑战——人类编程风格本身也在受AI影响而演变。持续学习(Continual Learning)技术可以在不忘记旧知识的前提下适应新的分布,避免灾难性遗忘。多模态特征融合——结合代码文本、抽象语法树、数据流图、甚至开发者的提交历史——可以提供更鲁棒的检测信号。
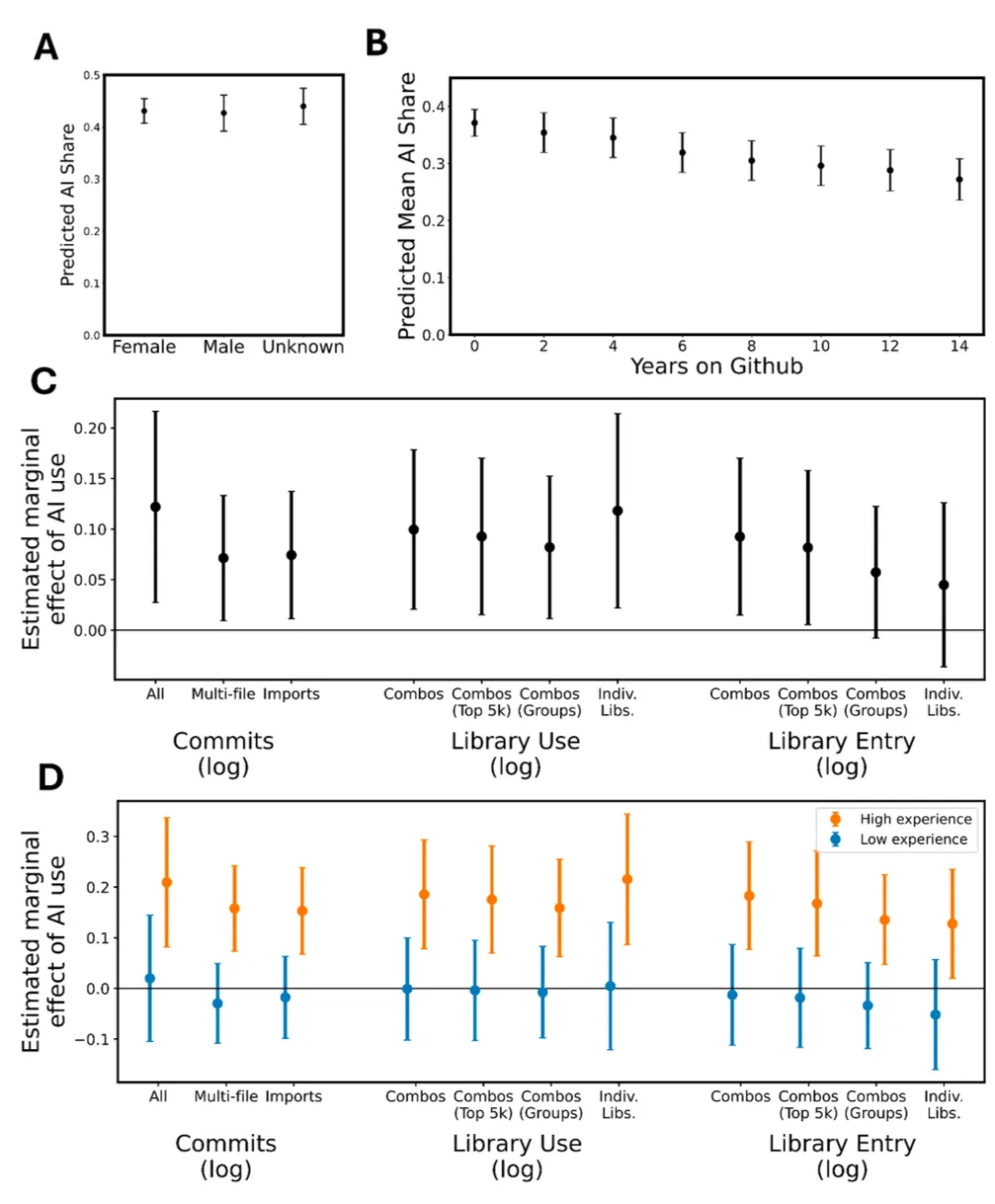
开发者生产力的因果推断与个性化干预
该研究使用双向固定效应模型估计AI的生产力效应,但面临测量误差导致的向下偏差。工具变量方法可以利用AI工具的外生可得性变化(如Copilot的分阶段推出)作为工具,获得更一致的因果估计。异质性处理效应(HTE)模型——如因果森林、BART、或基于深度学习的CATE估计器——可以识别哪些开发者特征预测了更大的AI收益,为个性化培训和工具推荐提供依据。强化学习可以优化AI编程助手的介入时机和方式:学习何时主动建议代码、何时等待提问、对哪类任务提供何种粒度的帮助,以最大化开发者的长期学习和生产力。
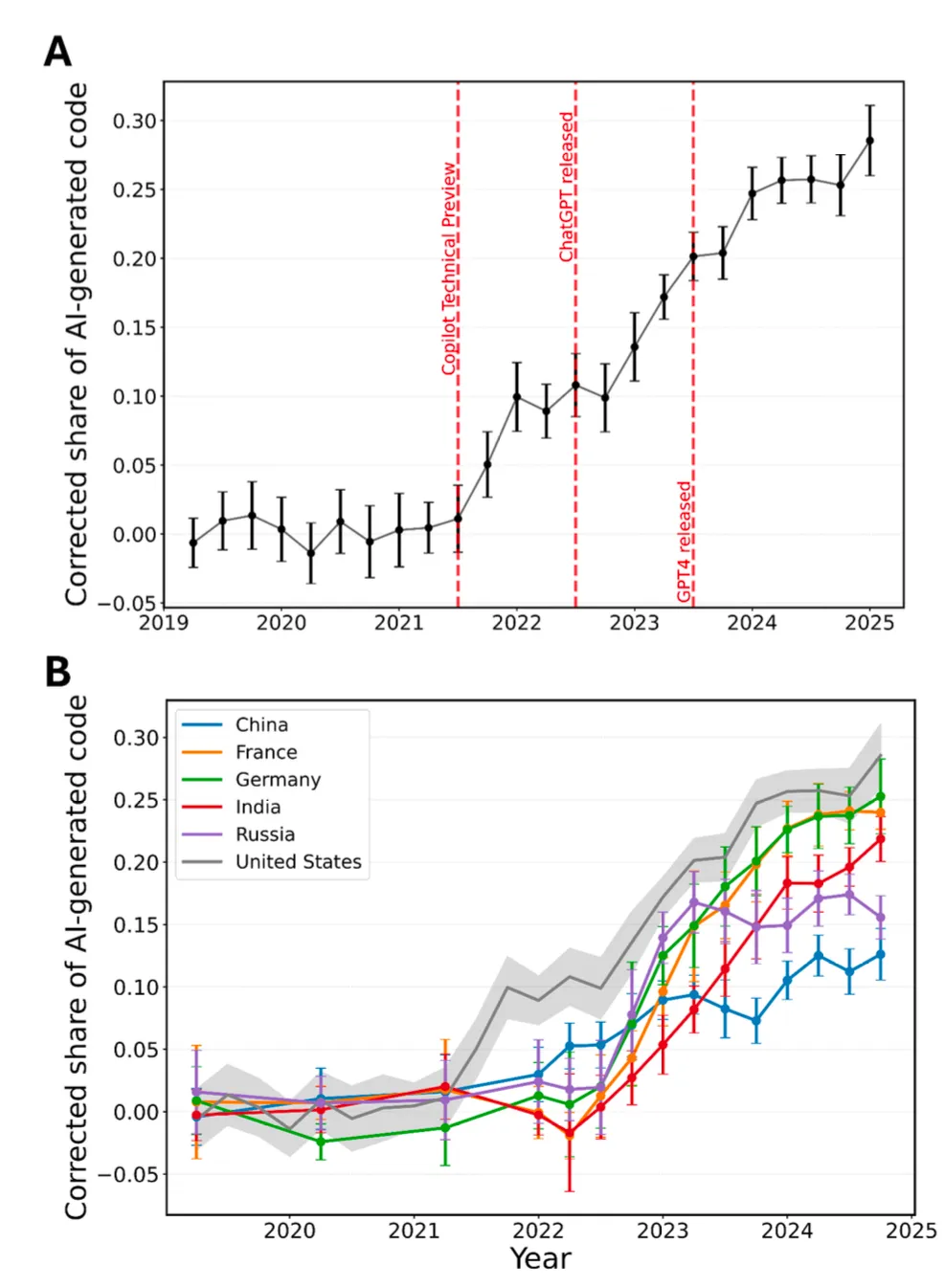
跨国AI采用差异的预测与政策模拟
该研究发现了显著的跨国AI采用差异,但未深入探讨其决定因素。结构方程模型或因果图模型可以分解供给侧因素(API可得性、定价、语言支持)和需求侧因素(数字基础设施、技能储备、制度环境)的相对贡献。技术扩散模型——如Bass模型或传染病模型——可以刻画AI采用的S型曲线,预测不同国家的"拐点"时间。基于Agent的模型(ABM)可以模拟政策干预的效果:如果某国放开AI服务访问限制、或推出AI技能培训补贴,采用率和生产力会如何演变?图神经网络可以建模开发者社交网络中的同伴效应,识别"超级传播者"——那些采用AI后影响周围开发者采用决策的关键节点。
代码质量与长期影响的多维评估
该研究聚焦于代码产出数量(提交次数),但代码质量同样关键。自然语言处理技术可以分析提交信息、代码评审评论、Issue讨论,评估代码的可维护性、可读性和bug倾向。静态分析工具结合机器学习可以预测代码的缺陷密度、技术债务和安全漏洞风险。时间序列分析可以追踪AI采用后项目的长期健康指标:Issue解决速度、PR合并率、贡献者留存率、代码流失率等。知识图谱可以建模开发者的技能演化轨迹,评估AI是否真正帮助新手"升级"还是让他们"跳过"了关键学习阶段,这对理解AI时代的人才培养至关重要。


























 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
