「井蛙说天」
以井为起点,谈天的边界。
认知有限,但从不停止向上张望。
一觉睡醒,DeepSeek又又又发论文了,并且又开源了,距离上次发论文没几天。这一次是OCR方向的论文,我不得不感叹DeepSeek团队真快,有钱真好,量化交易真挣钱。
说个好玩的,今天早上想着在DeepSeek上查一下这篇论文的相关情况,直接出现下图所示情况,足见发论文迅速之程度甚至来DeepSeek训练团队都没来得及。
火速通读完论文,感觉好像这又要掀起什么风暴?
你是否有过这样的经历:好不容易找到一篇重要论文,想把里面的内容复制出来,结果OCR 识别完左边一栏,右边一栏全混到一起,表格数据乱成一锅粥,公式直接变成了火星文。这就是传统 OCR 技术的困境:它只能“扫描”文档,却无法“理解”文档的语义和结构。
这是因为:
传统的OCR 模型就像一个只会按固定路线走路的机器人,它从左上到右下,地毯式扫一遍图片,不管文档的语义和结构。这种方式在面对复杂版面(如双栏文档、错落的表格)时,往往会切断语义的逻辑连贯性。
举个形象的例子:在我们下图时,我们人类会按照逻辑结构、并且会跳读+回看,自动建立“图 ↔ 字 ↔ 因果”的关系。
传统OCR是从左到右、从上到下扫把所有能识别的字抠出来输出一大坨无结构文,得到的是“字的尸体”,而不是“知识的活体”。
而DeepSeekOCR2模型则是:
第一步:整体空间理解(不是先读字)
DeepSeek-OCR 2 会先判断:这是一个横向时间轴,中间是主线,上下是分支,图片属于“说明型元素”,不是正文。
相当于人类第一眼就知道:“这是历史时间线,不是散文”
第二步:语义块切分(而不是字符切分)
它会把画面切成:时间节点块:公元前3000 年,文明说明块:古埃及文字、楔形文字:图片注释块,引用性说明(旁边的小字)。按“意义”切,而不是按“位置”切。
第三步:建立视觉因果关系
比如它会知道:楔形文字≠ 随机图片,它是“文字起源”的一个例证,时间点 ≠ 普通数字,而是历史顺序。
这一步非常关键:AI 知道“谁解释谁”,而不是“谁挨着谁”
第四步:输出的是“结构化知识”,不是纯文本
DeepSeek-OCR 2 的输出不是:“公元前3000年……文字……埃及……”
而更接近:
主题:人类文字起源时间轴
时间节点:
- 公元前3000年:古埃及象形文字
- 公元前3200年:楔形文字
配图说明:
- 图A:埃及象形文字实例
- 图B:楔形文字泥板
这是“理解”,不是“抄写”,更接近于人脑理解后的内容。
DeepSeek-OCR 2 的核心创新点
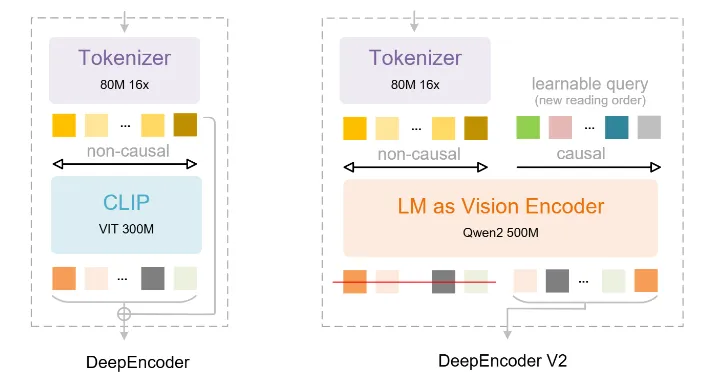
DeepSeek-OCR-2 的核心是 DeepEncoder V2 架构。这个架构采用了一种类语言模型结构,替代了原先基于 CLIP 的视觉编码模块,并在编码器内部引入可学习的“因果流查询 token”。
架构组成
DeepEncoder V2 主要由两部分组成: 1. 视觉分词器:沿用了 SAM-base(80M 参数)加卷积层的设计,将图像转换为视觉 Token。 2. 作为视觉编码器的 LLM:使用了一个 Qwen2-0.5B 模型,不仅处理视觉 Token,还引入了一组可学习的“查询 Token”。
关键创新:双流注意力机制
关键的创新点在于注意力掩码的设计:- 视觉 Token 之间采用双向注意力,保持全局感知能力,类似于 ViT。 - 而查询 Token 则采用因果注意力,每一个查询 Token 只能看到它之前的 Token。
通过这种设计,DeepEncoder V2 实现了两级级联的因果推理:编码器通过可学习的查询对视觉 Token 进行语义重排,随后的 LLM 解码器则在这个有序序列上进行自回归推理。这意味着,DeepSeek-OCR-2 在编码阶段就已经把图像里的信息“理顺”了,而不是一股脑地扔给解码器。
性能验证:数据说话
为了验证DeepSeek-OCR-2 的性能,研究团队在 OmniDocBench v1.5 基准上进行了全面评估。该基准涵盖多种类型的中英文文档,包括学术论文、杂志、报告等,重点考察文本识别、公式解析、表格结构还原以及阅读顺序等指标。
综合得分:91.09%,较前代提升 3.73%
测试结果显示,在视觉Token 上限更低的情况下,DeepSeek-OCR-2 的整体得分达到了 91.09%,相较 DeepSeek-OCR 提升了 3.73%。这个提升幅度在 OCR 领域已经是很可观的进步了,毕竟技术发展到现在,每一点提升都不容易。
阅读顺序:编辑距离从0.085 降至 0.057
更能说明新架构价值的是“阅读顺序”指标:编辑距离从 0.085 降到 0.057,意味着模型对文档结构的判断更准确。它确实在学着按语义而非空间来组织信息。
视觉Token 效率:256–1120 个,远低于同类模型
DeepSeek-OCR-2 仅用 256 到 1120 个视觉 Token 就能覆盖复杂文档,而多数同类模型需要超过 6000 个。视觉 Token 数量的减少,不仅降低了计算成本,还提高了处理速度。
生产环境表现:重复率显著下降
在实际生产环境中,DeepSeek-OCR-2 的表现也非常出色。在线用户日志图像的重复率从 6.25% 降至 4.17%,批处理 PDF 数据的重复率从 3.69% 降至 2.88%。这些改进使得模型在保持高压缩率的同时,提升了实际应用场景中的可靠性。
看完这些实验数据,以及DeepSeek近期这么频繁的发论文,我不由思考DeepSeek还藏了多少东西。根据公开信息,DeepSeek V4预计在2月中旬发布,去年也差不多是春节发布的,不知届时又会掀起什么浪潮。去年的直接开源可以说的上是掀桌子了,今年又会怎样呢?这是要再造一次“AI 的 iPhone 时刻”吗?
行业影响:是否能成为OCR 领域的技术转折点?
DeepSeek-OCR-2 的发布无疑给 OCR 领域带来了巨大的冲击。它不仅在技术上实现了突破,还在应用场景上拓展了 OCR 技术的边界。那么,它是否能成为 OCR 领域的技术转折点呢?
技术范式的转变
DeepSeek-OCR-2 的出现,标志着 OCR 技术从“扫描”时代进入了“理解”时代。传统的 OCR 模型主要关注字符识别的准确率,而 DeepSeek-OCR-2 则更关注文档的语义和结构理解。这种技术范式的转变,将推动 OCR 技术向更高的层次发展。
行业格局的重塑
DeepSeek-OCR-2 的发布也将重塑 OCR 领域的行业格局。传统的 OCR 厂商可能需要重新审视自己的技术路线,加快技术创新的步伐。而新兴的 AI 公司则可能凭借 DeepSeek-OCR-2 等技术优势,在 OCR 领域占据一席之地。
全模态统一的新可能
DeepSeek V3和R1很强,甚至在纯文本推理能力上超越了o1,但都只是纯文本模型,在多模态推理上依旧无法碰瓷o1。
DeepSeek-OCR-2 的设计为未来构建统一的全模态编码器提供了可行的路径。它将二维的视觉图像通过因果推理转化为一维的有序 Token 序列,和语言的结构保持一致。这就为其他模态的处理提供了一个可借鉴的思路,比如处理视频数据,可以把视频的帧转化为视觉 Token,再通过因果流查询按语义顺序排列。一旦这个思路走通,全模态统一的编码器就有了雏形,未来的 AI 模型就不用再为不同的模态设计不同的处理逻辑,能大幅降低模型的复杂度,提升多模态理解的效率和效果。
参考资料:
- 论文:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
- 模型:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
「井蛙说天」
记录我作为一只井里的蛙,对技术、趋势和未来的每一次抬头。
如果你愿意陪我一起,在有限视角中,不断校准方向——欢迎关注。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
