基于Python的网络药理学实战教程:以黄芪治疗乳腺癌为例
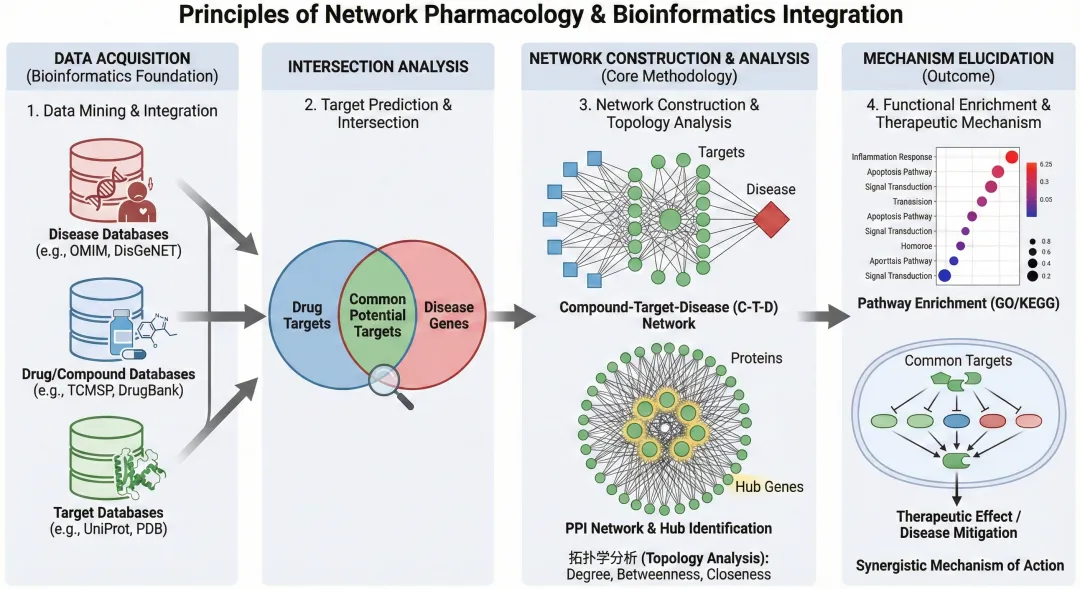
网络药理学作为中医药现代化研究的核心方法,已成为药物研发和机制研究的重要工具。2021年,国际期刊发布了网络药理学研究的标准化指南,标志着这一方法在学术界的广泛认可。然而,对于初学者而言,如何将理论转化为实践操作仍是一大挑战。本教程以黄芪治疗乳腺癌为案例,通过Python编程语言,完整呈现从成分筛选到靶点分析的全流程。您将掌握网络药理学的核心分析方法、Python在生物信息学中的实际应用,以及可复现的完整分析流程。无论您是医药研究人员、研究生,还是对中医药现代化感兴趣的学习者,这套零基础教程都能帮助您快速入门,开启系统生物学研究之路。传统中药研究长期面临着独特的挑战。一味中药往往包含数百种化学成分,每种成分又可能作用于多个靶点,这种复杂性使得用传统"单一化合物-单一靶点"的研究模式难以全面阐明中药的作用机制。以黄芪为例,现代植物化学研究已经从中分离鉴定出上百种化合物,包括黄酮类、皂苷类、多糖类等多种活性成分,这些成分通过不同途径共同发挥药理作用。正是在这样的背景下,网络药理学应运而生。这一方法借鉴系统生物学的思想,将药物、疾病、人体视为一个相互关联的整体网络,通过分析网络中的节点(基因、蛋白、代谢物)和连接(相互作用关系),揭示药物作用的整体规律。值得注意的是,这种"整体观"恰好与中医"辨证论治"的哲学思想不谋而合,为中医药理论的现代诠释提供了科学语言。近年来,网络药理学在学术界的影响力持续提升。从2007年概念提出至今,相关研究论文数量呈指数级增长。特别是在中医药领域,网络药理学已成为复方配伍研究、药效物质基础研究、作用机制研究的标准方法之一。网络药理学的核心在于"多成分-多靶点-多通路"的作用模式。传统西药研发遵循"一药一靶"原则,追求药物对单一靶点的高选择性。而中药的特点是多个活性成分协同作用,通过调控多个靶点,影响多条信号通路,最终产生整体治疗效果。这种作用方式更接近人体疾病发生发展的真实情况,因为大多数疾病本身就是多因素、多环节的复杂过程。从系统生物学视角来看,疾病是生物网络中某些节点或通路发生异常的结果,而药物的作用就是通过干预这些异常节点或通路,使网络重新达到平衡状态。网络药理学正是基于这一认识,通过构建"药物成分-作用靶点-疾病基因"的关联网络,识别出药物与疾病之间的共同作用节点,从而预测药物的治疗机制。与传统药理学相比,网络药理学具有明显的方法学优势。传统方法需要通过大量实验逐一验证每个成分的作用,耗时长、成本高。而网络药理学可以在实验前通过计算预测,筛选出最有可能的关键成分和靶点,为后续实验提供方向,大大提高研究效率。同时,网络分析还能发现单一实验难以观察到的成分间协同作用和靶点间的相互调控关系。一个完整的网络药理学研究通常包括以下几个关键步骤。首先是活性成分筛选,需要从中药的众多化学成分中,根据类药性质(如口服生物利用度、类药性指数等)筛选出可能发挥药效作用的成分。这一步骤至关重要,因为并非所有化学成分都能在体内达到有效浓度。其次是靶点预测与验证。对于筛选出的活性成分,通过数据库检索或分子对接等方法,预测它们可能作用的蛋白靶点。同时,从疾病相关数据库中获取疾病相关基因,两者取交集得到药物-疾病共同作用的关键靶点。然后是网络构建与分析。将成分、靶点、疾病基因等要素构建成可视化网络图,通过拓扑学分析识别网络中的关键节点,这些关键节点往往对应着药物发挥作用的核心靶点。最后是通路富集分析,将关键靶点映射到生物学通路数据库(如KEGG、GO等),阐明药物作用的具体生物学过程。整个流程体现了从宏观到微观、从预测到验证的研究思路,既保留了中医药整体观的特色,又符合现代医学对分子机制的认识要求。生物医学研究进入大数据时代,数据的规模和复杂度都达到了前所未有的水平。一个典型的网络药理学研究可能涉及数百个化合物、数千个基因、数万条相互作用关系。如果依靠人工处理,不仅效率极低,而且容易出错。这时候,编程工具的重要性就凸显出来。生物医学数据还有一个特点,就是来源多样、格式各异。研究者需要从TCMSP数据库获取中药成分信息,从GeneCards获取疾病基因,从STRING获取蛋白互作数据,从PubChem获取化合物结构,这些数据库的数据格式完全不同。手工整合这些数据既费时又容易遗漏信息,而编程可以实现自动化的数据抓取、转换和整合。更重要的是,网络药理学的核心在于数据分析和可视化。从原始数据到最终的韦恩图、网络图、通路图,中间需要进行大量的数据清洗、筛选、匹配、计算。这些重复性的工作用编程实现,不仅速度快,而且结果可重复、可验证,符合科学研究的严谨性要求。Python之所以成为生物信息学领域的首选语言,很大程度上得益于其丰富的科学计算库。在网络药理学研究中,几个核心工具库扮演着不可或缺的角色。Pandas是数据处理的基石。它提供了类似Excel表格的数据结构DataFrame,可以轻松实现数据的读取、筛选、合并、统计等操作。在本教程的案例中,从Excel文件读取成分数据、根据OB和DL值筛选活性成分、将药物靶点与疾病基因进行匹配,这些都是通过pandas完成的。pandas的强大之处在于,几行代码就能完成Excel中需要大量公式和手动操作才能实现的功能。mygene是专门用于基因信息查询的工具库。在网络药理学研究中,经常遇到基因名称不统一的问题,同一个基因可能有多种命名方式。mygene可以调用美国国家生物技术信息中心的基因数据库,自动将各种基因名称转换为标准的基因符号(Symbol),确保数据的一致性。本教程中第三步的基因名称标准化就依赖这个工具。matplotlib和seaborn是科学可视化的双璧。matplotlib提供了底层的绘图功能,可以精确控制图形的每一个细节。seaborn在matplotlib基础上进行了封装,提供了更美观的默认样式和更便捷的统计图形绘制方法。在网络药理学研究中,韦恩图用于展示靶点交集,柱状图用于展示功能分类,网络图用于展示成分-靶点-通路的关系,这些都需要可视化工具来实现。除此之外,还有一些常用的工具库。matplotlib-venn专门用于绘制韦恩图,openpyxl用于读写Excel文件,这些工具各司其职,共同构成了Python网络药理学分析的工具箱。对于编程零基础的学习者,不必被技术细节吓倒。网络药理学分析中用到的Python知识主要集中在数据读取、条件筛选、数据合并这几个方面,语法相对简单。更重要的是,本教程提供的代码可以直接使用,您只需要修改文件名等少量参数,就能完成自己的分析。在使用过程中,逐渐理解代码的逻辑,自然而然就掌握了基本的编程技能。在正式开始之前,需要做一些准备工作。首先是安装Python环境,推荐使用Anaconda发行版,它已经预装了大部分科学计算库。安装完成后,在命令行中执行一条指令就能安装本教程需要的所有工具库,具体命令是:pip install pandas openpyxl mygene matplotlib-venn seaborn gseapy。
当然,除此之外,还有诸如 networkx等 , 可用于画网络图之类的操作,具体命令是:pip install pandas openpyxl mygene matplotlib matplotlib-venn seaborn gseapy networkx numpy scipy requests -i https://pypi.tuna.tsinghua.edu.cn/simple
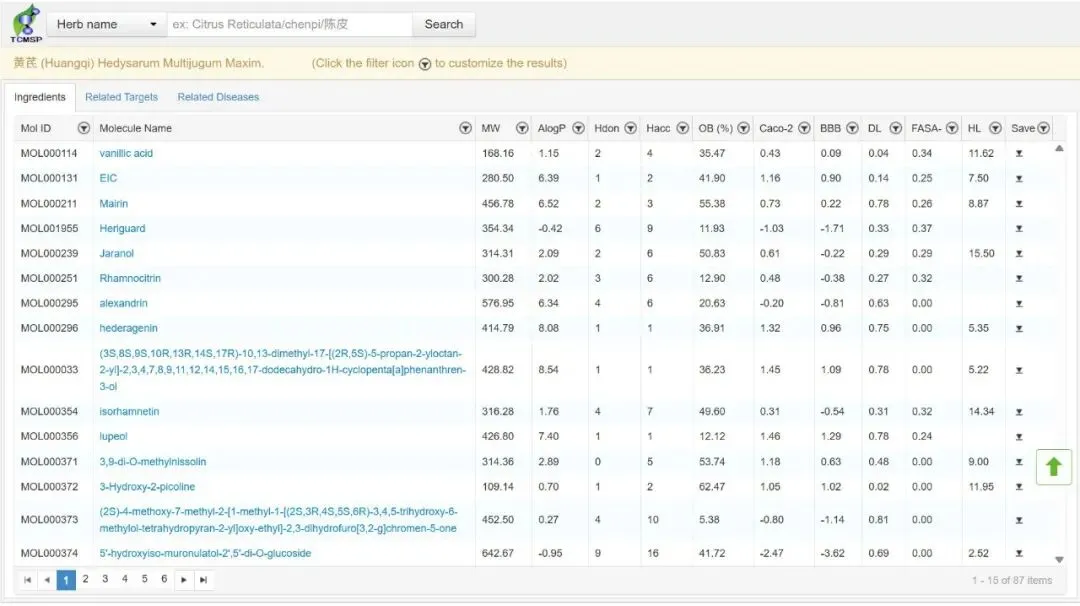
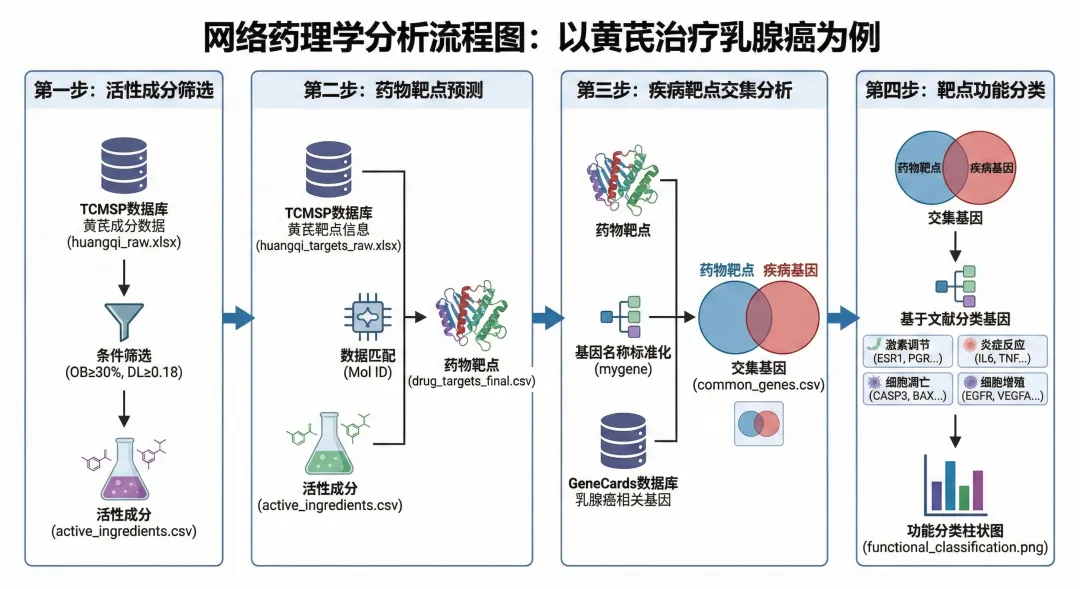
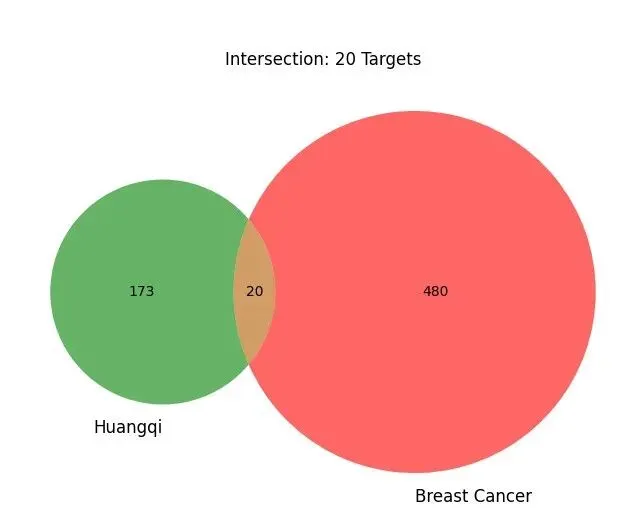
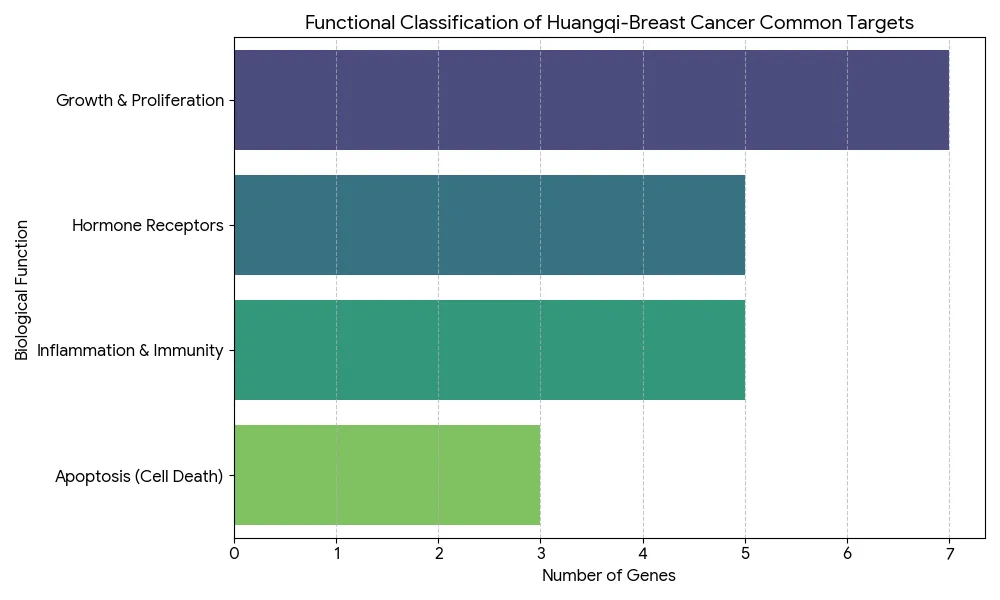
其次是了解数据来源。TCMSP是中药系统药理学数据库,提供了中药成分、靶点、疾病等信息,用户可以免费注册使用。GeneCards是人类基因数据库,收录了各种疾病相关基因及其功能注释。熟悉这些数据库的使用方法,能够帮助您更好地理解数据的含义。最后是文件管理。建议在电脑上新建一个专门的文件夹,将所有Excel数据文件和Python脚本放在同一个目录下。这样可以避免文件路径错误导致的程序运行失败。良好的文件组织习惯是科研工作的基本素养。黄芪是传统的补气中药,在《神农本草经》中被列为上品。现代药理学研究发现,黄芪具有免疫调节、抗氧化、抗肿瘤等多种生物活性。特别是在肿瘤治疗方面,黄芪多糖被证实能够增强机体免疫功能,黄芪甲苷可以诱导肿瘤细胞凋亡、抑制肿瘤血管生成。临床上,黄芪常与其他中药配伍用于癌症患者的辅助治疗,既能减轻化疗副作用,又能提高生活质量。乳腺癌是全球女性最常见的恶性肿瘤之一。尽管手术、放化疗等治疗手段不断进步,但复发转移仍是临床面临的难题。近年来研究发现,中医药在改善患者预后方面具有独特优势。本案例通过网络药理学方法,系统阐明黄芪治疗乳腺癌的潜在分子机制,为临床应用提供科学依据。网络药理学分析的第一步是从中药的众多成分中筛选出真正具有药效的活性成分。这一步骤的科学依据是ADME原则,即药物的吸收(Absorption)、分布(Distribution)、代谢(Metabolism)、排泄(Excretion)特性。一个化合物即使在体外实验中显示出很强的生物活性,如果不能被人体吸收或迅速代谢排出,也无法发挥治疗作用。在实际操作中,我们采用两个关键指标进行筛选。第一个是口服生物利用度,用OB值表示,反映药物经口服给药后进入血液循环的比例。一般认为OB值大于等于30%的化合物具有较好的口服吸收性。第二个是类药性指数,用DL值表示,综合评价化合物在分子量、脂溶性、氢键等方面是否符合药物特征。通常DL值大于等于0.18被认为具有类药性质。具体的操作流程是这样的:首先从TCMSP数据库下载黄芪的全部化学成分信息,保存为Excel文件,命名为huangqi_raw.xlsx。这个文件包含了成分的中英文名称、分子式、OB值、DL值等详细信息。然后使用Python脚本对数据进行筛选。第一步是读取Excel文件,这里使用pandas库的read_excel函数。需要注意的是,有些Excel文件可能需要指定openpyxl引擎才能正确读取。第二步是清理列名,因为从数据库下载的数据表头可能包含空格或换行符,需要用字符串处理方法去除这些干扰字符。第三步是智能查找OB和DL列。不同来源的数据,列名可能略有差异,比如有的叫"OB (%)",有的叫"OB"。代码通过遍历所有列名,找到包含"OB"和"DL"关键词的列,实现了一定的智能性,避免了因列名不完全一致导致的错误。第四步是数据类型转换和空值处理。OB和DL的原始数据可能是字符串格式,需要转换为数值才能进行比较运算。同时,有些成分可能缺少OB或DL数据,这些记录应该删除,否则会影响后续分析。最后一步是条件筛选,使用pandas的布尔索引功能,选出同时满足OB大于等于30且DL大于等于0.18的记录,保存到新的CSV文件中。运行这个脚本后,程序会在屏幕上显示筛选结果,比如"筛选完成!获得活性成分:20个"。打开生成的active_ingredients.csv文件,可以看到筛选后的成分列表。这些成分就是我们认为可能具有抗乳腺癌活性的黄芪有效成分,为下一步的靶点分析奠定了基础。确定了活性成分之后,接下来要解决的问题是:这些成分作用于人体的哪些蛋白靶点?这就是靶点预测的任务。在传统药理学研究中,确定一个化合物的作用靶点需要大量的体外实验和体内验证。而网络药理学可以利用现有的数据库资源,快速预测可能的作用靶点。TCMSP数据库不仅包含中药成分的理化性质,还整合了成分-靶点的作用关系。这些关系大多来源于已发表的文献和高通量筛选实验。每个成分都有一个唯一的Mol ID作为标识符,通过这个ID可以关联到对应的靶点信息。首先准备两个输入文件,一个是上一步生成的activeingredients.csv,包含筛选后的活性成分及其Mol ID;另一个是从TCMSP下载的黄芪靶点信息表huangqitargets_raw.xlsx,包含了所有成分对应的靶点蛋白名称。代码的关键在于数据匹配。两个表都包含Mol ID这一列,但列名可能不完全一致。代码首先定义了一个智能查找函数,自动识别包含"MOL"和"ID"关键词的列,然后将两个表中的对应列统一重命名为"Mol ID"。这样做的好处是增强代码的通用性,即使数据来源稍有变化,代码仍能正常运行。接下来使用pandas的merge函数进行表连接。这个操作类似于Excel中的VLOOKUP或数据库中的JOIN操作,根据Mol ID将两个表关联起来。连接方式选择inner,意思是只保留两个表中都存在的Mol ID,这样就筛选出了活性成分对应的靶点。最后从合并后的表中提取靶点名称列。TCMSP中靶点名称列通常叫做"Target Name",包含了靶点蛋白的全称。代码通过智能查找包含"TARGET"和"NAME"关键词的列,提取出所有不重复的靶点名称,保存到drugtargetsfinal.csv文件中。运行结果会显示"匹配完成!获得药物靶点:50个"(具体数字取决于实际数据)。这50个靶点就是黄芪活性成分可能作用的蛋白质,它们涵盖了激素受体、酶、离子通道、转录因子等多种类型。这一步的输出为后续的疾病基因交集分析提供了药物侧的数据。有了药物靶点,还需要疾病靶点,才能找到两者的交集。疾病靶点是指与特定疾病发生发展密切相关的基因或蛋白质。对于乳腺癌,已有大量研究识别出了关键的驱动基因、抑癌基因、代谢相关基因等。GeneCards是目前最全面的人类基因数据库之一,整合了基因组学、转录组学、蛋白质组学等多个层面的信息。在GeneCards网站上搜索"Breast Cancer",可以得到数百个相关基因,按照相关性评分排序。研究者通常选择评分较高的前几百个基因作为疾病靶点集合。这一步面临一个技术挑战:基因命名的标准化。从TCMSP获得的药物靶点通常是蛋白质的全称,比如"Estrogen receptor alpha",而GeneCards中的疾病基因通常用基因符号表示,比如"ESR1"。如果不进行名称转换,就无法准确匹配两者的交集。这里使用的工具是mygene库。它提供了一个在线查询接口,可以将各种形式的基因或蛋白质名称转换为标准的基因符号。代码首先读取drugtargetsfinal.csv中的靶点名称列表,调用mygene的querymany函数进行批量查询。查询参数中,scopes指定输入的名称类型为"name"(蛋白质名称),fields指定输出的信息为"symbol"(基因符号),species限定为"human"(人类)。查询结果是一个列表,每个元素对应一个输入的靶点。如果查询成功,结果中会包含"symbol"字段,代码提取这些符号并统一转换为大写,形成药物靶点的基因符号集合。对于疾病靶点,从GeneCards下载的Excel文件中直接提取基因符号列,同样转换为大写。统一大小写是为了避免因大小写不一致导致的匹配失败。有了两个标准化的基因集合,求交集就很简单了。Python的set数据结构天生支持交集运算,一行代码就能完成。得到交集基因后,程序会输出统计信息:"药物靶点50个,疾病基因300个,交集基因32个"。这32个基因就是黄芪治疗乳腺癌的关键靶点,既受药物调控,又与疾病相关。为了直观展示这种关系,代码使用matplotlib-venn库绘制韦恩图。图中两个圆圈分别代表药物靶点和疾病基因,重叠部分标注交集的数量。这张图清晰地表达了网络药理学的核心思想:药物作用的靶点与疾病相关基因的重叠程度越高,提示药物对该疾病的治疗潜力越大。交集基因被保存到common_genes.csv文件中,这个文件将作为下一步功能分类的输入。这些基因不是孤立的,它们在细胞中参与各种生物学过程,相互协作共同影响疾病的进程。理解它们的功能分布,就能从分子层面阐明黄芪的作用机制。获得交集基因后,最后一步是对这些基因进行功能分类,揭示它们参与的生物学过程。这一步需要结合生物学知识和文献调研,将基因归类到不同的功能模块。在乳腺癌研究领域,有几个公认的关键功能模块。第一个是激素受体调节。乳腺癌的发生发展与雌激素、孕激素等性激素密切相关,雌激素受体ESR1是乳腺癌分型和治疗的重要标志物。如果交集基因中包含ESR1、PGR(孕激素受体)、AR(雄激素受体)等基因,提示黄芪可能通过调节激素信号通路发挥作用。第二个是炎症反应控制。慢性炎症是肿瘤微环境的重要组成部分,炎症因子如IL6、TNF能够促进肿瘤细胞增殖、侵袭和转移。如果黄芪能够抑制这些促炎因子的表达,就可能发挥抗肿瘤效果。第三个是细胞凋亡调控。正常细胞有程序性死亡机制,当DNA损伤无法修复时会启动凋亡程序。而癌细胞通过各种途径逃避凋亡,获得"永生化"能力。CASP3、CASP8等半胱天冬酶是凋亡执行的关键蛋白,BAX和BCL2分别是促凋亡和抑凋亡蛋白的代表。如果黄芪能够激活凋亡通路,就能诱导癌细胞死亡。第四个是细胞增殖相关。EGFR、VEGFA等基因参与细胞生长和血管生成,是抗癌药物的常见靶点。TOP2A是DNA拓扑异构酶,许多化疗药物的靶点。这些基因的调控对控制肿瘤生长至关重要。代码实现上,首先定义一个字典,键是功能类别的名称,值是属于该类别的基因列表。这一步需要研究者根据实际分析出的交集基因手动分类。然后将字典转换为适合绘图的DataFrame格式,每一行代表一个基因及其所属的功能类别。接下来使用seaborn库绘制横向柱状图。图的纵轴是功能类别,横轴是该类别包含的基因数量。为了让图表更美观,可以设置配色方案、添加数据标签等。生成的图片保存为functional_classification.png,直观展示了黄芪抗乳腺癌作用涉及的主要生物学过程。从功能分类结果可以看出,黄芪的抗乳腺癌作用是多靶点、多途径的。它既能调节激素受体,又能抑制炎症,还能诱导凋亡、抑制增殖。这种多管齐下的作用模式正是中药的特色,也解释了为什么黄芪在临床上常作为辅助治疗使用,能够从多个角度改善患者状态。掌握了这套分析流程,您就可以将其应用到其他研究中。比如将黄芪换成当归、人参、甘草等其他常用中药,分析它们对乳腺癌或其他疾病的作用机制。只需要更换TCMSP数据库中的药材名称和GeneCards中的疾病名称,重新运行代码即可。对于复方研究,可以将多味中药的活性成分合并,分析配伍后的整体作用靶点。这种方法能够揭示复方中各药材的协同增效或减毒作用。比如四君子汤由人参、白术、茯苓、甘草组成,可以分别分析四味药的靶点,再分析它们的交集和并集,探讨配伍规律。还可以将网络药理学与实验研究结合。通过网络药理学预测关键靶点后,设计细胞实验或动物实验进行验证。这种"计算预测-实验验证"的模式既能提高研究效率,又能增强结论的可信度,是目前中医药研究的主流范式。本教程介绍的是网络药理学的入门流程,实际研究中还有更深入的分析方法。GO功能富集分析和KEGG通路富集分析是其中的重点。这两种方法可以将交集基因映射到基因本体数据库和通路数据库,统计哪些生物学过程或信号通路被显著富集,从而更系统地阐明作用机制。Python的gseapy库提供了便捷的富集分析接口。蛋白互作网络分析是另一个重要方向。交集基因对应的蛋白质在细胞中不是孤立存在的,它们通过物理相互作用或功能相关性形成复杂的网络。可以利用STRING数据库构建蛋白互作网络,通过拓扑学分析找出网络中的关键节点,这些节点往往是药物作用的核心靶点。网络图的绘制可以使用Python的networkx库或专业软件Cytoscape。对于追求更高精度的研究者,还可以进行分子对接验证。分子对接是计算化学的方法,模拟药物分子与靶点蛋白的结合过程,预测结合模式和亲和力。通过对接可以验证网络药理学预测的成分-靶点对是否真实存在结合作用。常用的分子对接软件包括AutoDock、AutoDock Vina等,它们也有Python接口可以调用。在实际操作中,初学者可能会遇到一些问题。关于数据库使用,TCMSP和GeneCards都是免费开放的,但需要注册账号。下载数据时要注意选择正确的物种(人类)和数据类型。有些数据库可能因为访问量大而响应缓慢,耐心等待或换个时间段访问即可。代码运行出错时,首先检查文件名和路径是否正确,这是最常见的错误来源。确保所有Excel文件和Python脚本在同一个文件夹下,文件名与代码中指定的名称完全一致。其次检查数据格式,比如OB和DL的数值不能包含百分号或其他非数字字符,否则无法进行数值比较。如果代码提示找不到某个列,打开Excel文件检查列名是否与预期一致。关于结果解读,网络药理学是预测性分析,预测结果需要结合文献和实验验证。如果交集基因数量很少甚至为零,可能是筛选条件过于严格,可以适当放宽OB和DL的阈值。如果交集基因过多,可以进一步根据相关性评分或文献支持度筛选核心靶点。将网络药理学研究撰写成科研论文时,需要遵循标准的结构:引言部分阐述研究背景和意义,材料与方法部分详细描述数据来源和分析流程,结果部分展示筛选结果、韦恩图、网络图、富集分析图等,讨论部分结合文献解释发现的生物学意义。图表要清晰美观,结论要有数据支撑,避免过度推测。网络药理学为中医药研究提供了系统化、标准化的研究范式,而Python编程工具的普及使得这一前沿方法不再是少数人的专利。从本案例可以看出,通过规范的分析流程,我们能够从分子层面阐明传统中药的作用机制,为临床应用提供科学依据。随着多组学技术的发展和大数据分析方法的完善,网络药理学将在精准医疗、新药研发等领域发挥更大作用。掌握这项技能,不仅能够提升科研能力,更能让您站在中医药现代化研究的最前沿。您认为网络药理学在中医药研究中还可以解决哪些问题?欢迎在评论区分享您的见解和研究方向。