一句话讲清楚👉🏻 这篇论文提出了"Agent原生中期训练"新范式,通过两种agent-native轨迹数据(上下文原生+环境原生),用不到一半的训练数据超越了Kimi-Dev,在SWE-Bench Verified上达到58.5%准确率。
核心挑战:静态训练数据 vs 动态开发环境
大语言模型的能力边界正在经历一场深刻变革——从单轮代码生成(single-turn code generation)迈向代理式软件工程(agentic software engineering)。在这个新范式中,模型需要自主导航、编辑和测试复杂代码库,而不仅仅是写出一个函数就结束。
然而,现有方法面临一个根本性矛盾:训练数据是静态的,但真实开发是动态的。
传统post-training方法依赖精心筛选的轨迹数据,存在三个关键问题:
- 缺乏动态反馈:静态数据无法模拟"编写→运行→报错→修改"的真实迭代过程
- 早期能力缺失:只在后期训练中才接触agent行为,导致模型需要从零开始学习基础能力
更棘手的是,现有中期训练(mid-training)使用的数据并不能真实反映agent的实际工作方式。它们的分布与真实环境存在显著 mismatch——模型在训练时看到的样本,与它在实际运行时面对的场景截然不同。
daVinci-Dev的核心贡献:建立了一套系统化的Agent原生中期训练框架,通过数据合成原则和训练方法论的协同优化,用更少的数据实现更强的agent能力。
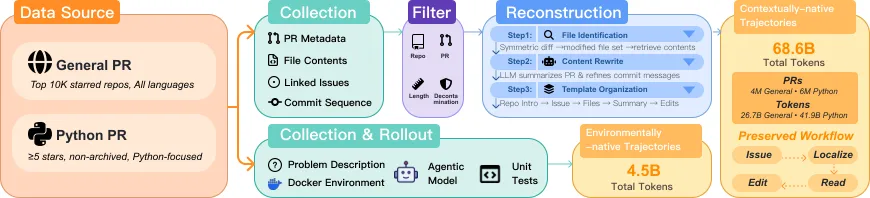
数据范式革新:从静态文件到动态轨迹
四种训练数据范式对比:(a)传统代码预训练使用孤立静态文件;(b)分解方法单独训练子任务造成训练-测试不匹配;(c)上下文原生PR将检索上下文与编辑轨迹捆绑;(d)环境原生轨迹捕获真实执行反馈循环
daVinci-Dev提出两种互补的agent-native轨迹数据,从根本上改变了数据分布:
1. 上下文原生轨迹(Contextually-native PR Trajectories)
从真实GitHub Pull Request中构建,保留完整的信息流——包括issue描述、commit信息、代码变更,以及最关键的:检索上下文与编辑操作的耦合关系。
数据规模:68.6B tokens
这种方法解决了传统代码数据的核心问题:真实开发中,开发者不是面对孤立文件,而是需要先理解上下文(这个文件在项目中的位置、与其他模块的关系、相关函数是什么),然后才能进行编辑。daVinci-Dev将这种"先检索后编辑"的模式原汁原味地保留下来。
2. 环境原生轨迹(Environmentally-native Executable Trajectories)
在真实可执行环境中收集的轨迹数据,observation来自真实的工具调用和测试执行结果。
数据规模:3.1B raw tokens → 4.5B effective tokens(包含测试通过和失败的rollouts)
关键创新点:模型不仅能看到成功案例,还能从失败中学习。"测试未通过"的轨迹同样有价值,因为它们模拟了真实开发中"尝试→失败→调整"的迭代过程。
两阶段训练流程
daVinci-Dev数据集生成pipeline,通过GitHub API构建结构化的PR表示
daVinci-Dev采用多阶段训练框架,逐步构建agent能力:
第一阶段:Agent原生中期训练(Agent-native Mid-training)
- 从Qwen2.5基础模型家族(32B/72B)开始
- 在上下文原生轨迹上进行中期训练(可选择混合环境原生轨迹)
- 产出checkpoint:daVinci-Dev-32B-MT / daVinci-Dev-72B-MT
第二阶段:环境原生SFT(Environment-native SFT)
- 产出最终模型:daVinci-Dev-32B / daVinci-Dev-72B
这种设计背后的理念很精妙:中期训练负责建立基础agent行为模式(理解上下文、执行编辑、遵循开发工作流),SFT阶段则负责将这种能力与真实执行环境对齐。
性能表现:全面超越现有方案
在软件工程领域的权威 benchmark SWE-Bench Verified 上的评估结果:
| | | | |
|---|
| Qwen2.5-32B基线(弱SFT) | | | | |
| Qwen2.5-32B基线(强SFT) | | | | |
| Ours(弱SFT) | | | | |
| Ours(强SFT) | | | | |
| daVinci-Dev-32B | | | | 56.1% |
| Qwen2.5-72B基线(弱SFT) | | | | |
| Qwen2.5-72B基线(强SFT) | | | | |
| Kimi-Dev | | D_AgentlessRL + D_SWE-smith | | |
| Kimi-Dev | | D_AgentlessRL + D_env^pass | | |
| Ours(弱SFT) | | | | |
| Ours(强SFT) | | | | |
| daVinci-Dev-72B | | | | 58.5% |
关键发现:
- daVinci-Dev-72B达到58.5%,超越Kimi-Dev的48.6%(在相同基线和agent scaffold下)
- daVinci-Dev-32B达到56.1%,成为使用agent scaffold的开源训练方案中的SOTA,且起点是非编码器的Qwen2.5-32B-Base(Kimi-Dev使用的是Qwen2.5-Coder-32B系列)
- 训练效率:使用不到一半的token(73.1B vs 150B+)超越了Kimi-Dev
这说明:数据质量远比数据数量重要。Agent-native的数据分布让模型能更高效地学习真正的agent能力。
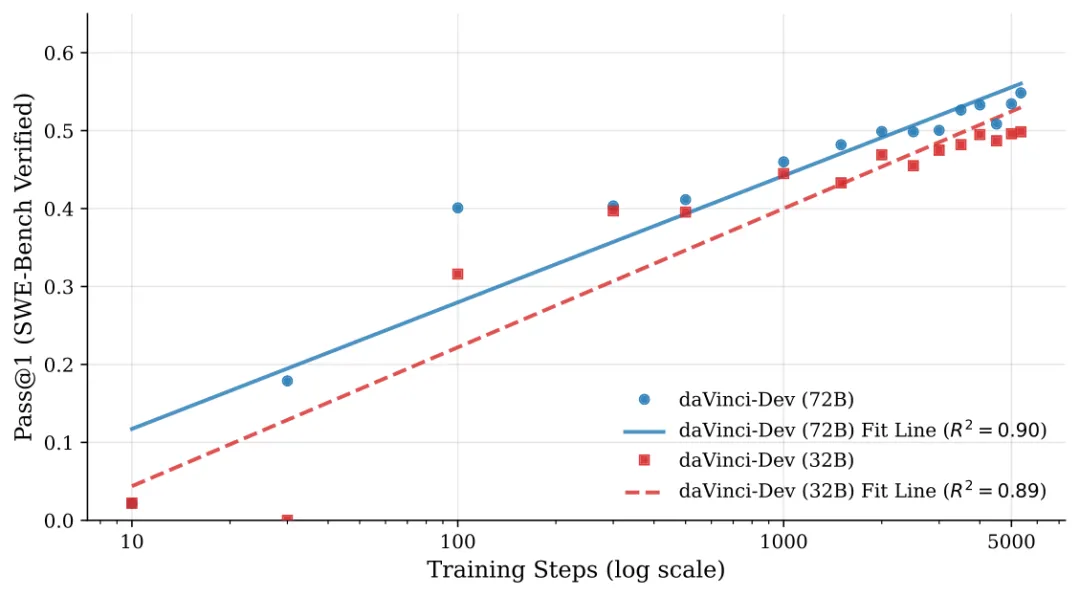
Scaling Law:能力随训练稳定增长
Agent原生中期训练的Scaling Law:在D_ctx^py + D_env混合数据上,SWE-Bench Verified的Pass@1性能随训练步数变化。强对数线性拟合(R² = 0.89~0.90)表明agent能力随训练步数可预测地增长
daVinci-Dev还揭示了一个重要发现:Agent能力遵循可预测的Scaling Law。
在32B和72B两个规模上,模型性能都呈现出强对数线性增长(R² = 0.89~0.90),这意味着:
- Agent能力没有快速饱和:继续增加训练数据,能力还会稳定提升
- Scaling可预测:可以根据目标性能规划训练资源
对于72B模型,将环境原生轨迹加入中期训练混合,Final SFT分数从56.5%提升到57.8%——这表明中期训练让模型更深入地内化了执行环境的动态特性。
核心启示
1. 重新定义中期训练的价值
传统观点认为中期训练"太贵不值得",daVinci-Dev证明:如果数据分布正确,中期训练是建立agent基础能力的最Scalable路径,比单纯依赖昂贵的强化学习更高效。
2. 数据分布比数据量更重要
68.6B + 3.1B = 71.7B tokens(实际有效约73.1B)远少于Kimi-Dev的150B+,但效果更好。关键在于:训练数据要反映真实任务分布。
3. 成功与失败轨迹都有价值
包含失败案例的轨迹让模型学会"如何从错误中恢复",这正是真实开发中最重要的能力之一。
4. 基础模型选择有讲究
daVinci-Dev使用非编码器的Qwen2.5-32B-Base作为起点,依然超越使用编码器版本的方案——说明中期训练可以弥补基础模型的领域不足。
开源资源
- 代码:GAIR-NLP/daVinci-Dev[2]
- 模型:GAIR/daVinci-Dev-72B[3]、GAIR/daVinci-Dev-32B[4]
总结
daVinci-Dev代表了AI代码生成向AI软件工程演进的一个重要里程碑。它证明了:要让AI成为真正的软件工程agent,中期训练的数据分布设计是关键。
通过上下文原生轨迹和环境原生轨迹的创新组合,daVinci-Dev用更少的训练数据实现了更强的agent能力。更重要的是,它揭示的Scaling Law表明,我们还远未触及agent能力的天花板。
未来展望:随着更多高质量agent-native数据的积累和更大规模训练的进行,AI自主完成复杂软件工程任务的那一天,或许会比预期更早到来。
⭐️关注我,实时跟进AI最新进展⭐️引用链接
[1]arXiv:2601.18418: https://arxiv.org/abs/2601.18418
[2]GAIR-NLP/daVinci-Dev: https://github.com/GAIR-NLP/daVinci-Dev
[3]GAIR/daVinci-Dev-72B: https://huggingface.co/GAIR/daVinci-Dev-72B
[4]GAIR/daVinci-Dev-32B: https://huggingface.co/GAIR/daVinci-Dev-32B
[5]GAIR/daVinci-Dev: https://huggingface.co/datasets/GAIR/daVinci-Dev