期刊图片复现|Python绘制概率密度分布对比图
- 2026-07-06 03:08:16
期刊图片复现|Python绘制概率密度分布对比图

论文:Widening Urban–Rural Precipitation Differences in China:Regionally Varied Intensification Since 2000 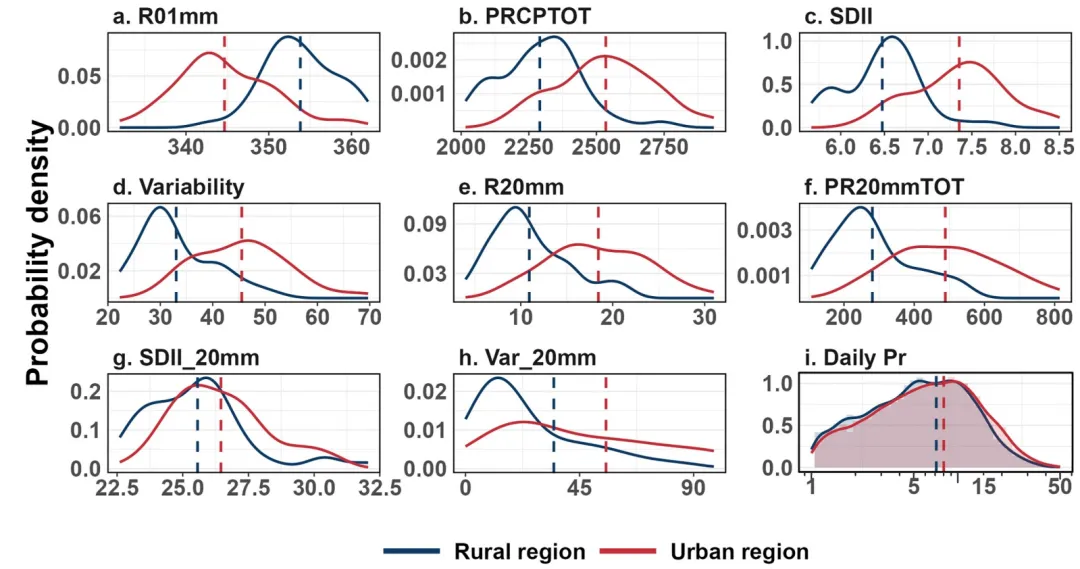
论文原图 此图表揭示了 1980 年至 2022 年间中国城市与乡村地区在降水模式上的显著差异:城市化导致降水特征呈现出系统性的“右偏”分布,即城市地区的整体降水量、降水强度和年际变率均高于乡村 。具体而言,乡村地区的R01mm更高,其密度曲线均值位于城市左侧,说明城市化倾向于减少总降水天数 ;但在SDII、R20mm以及PR20mmTOT等方面,城市曲线表现出明显的右移且形态更为平缓,反映出城市地区降水极端化趋势更强,面临更高的洪涝风险 。 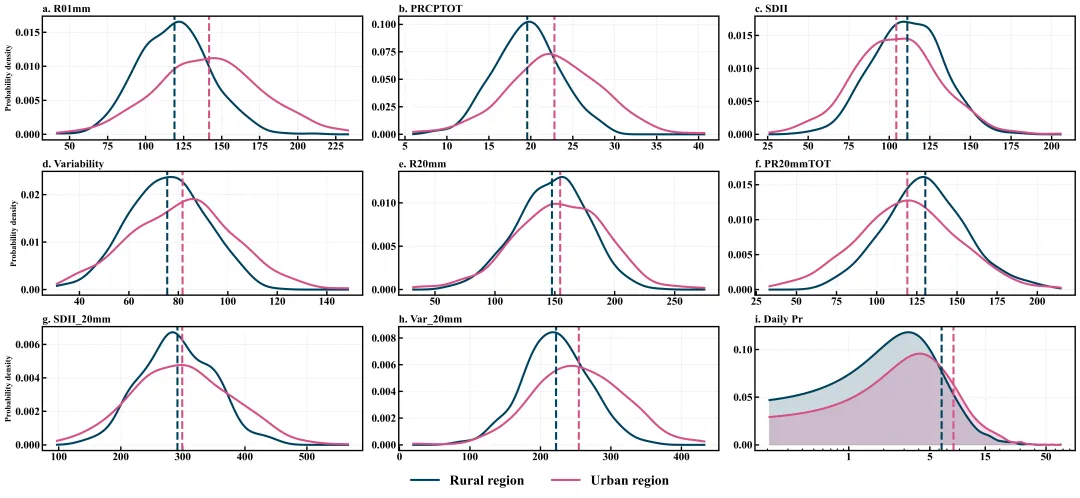
仿图 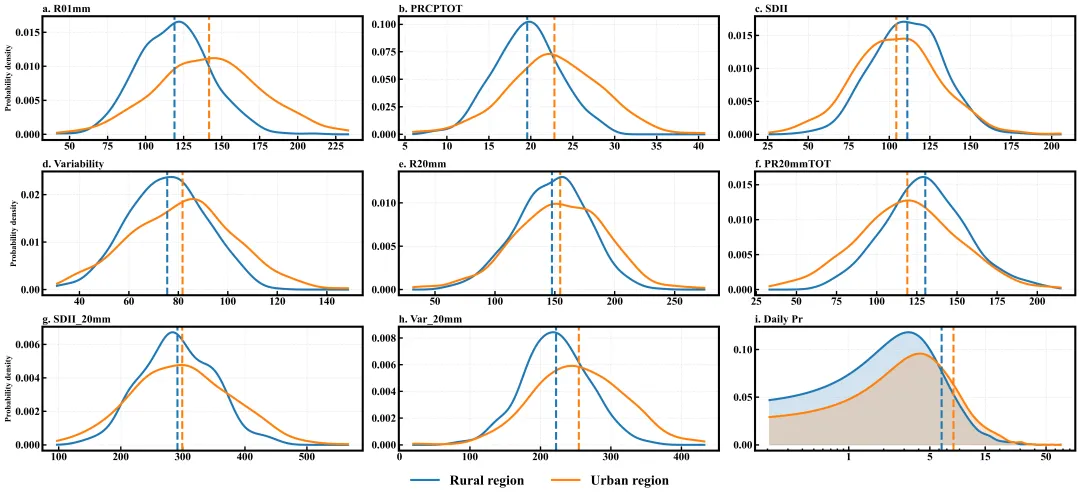
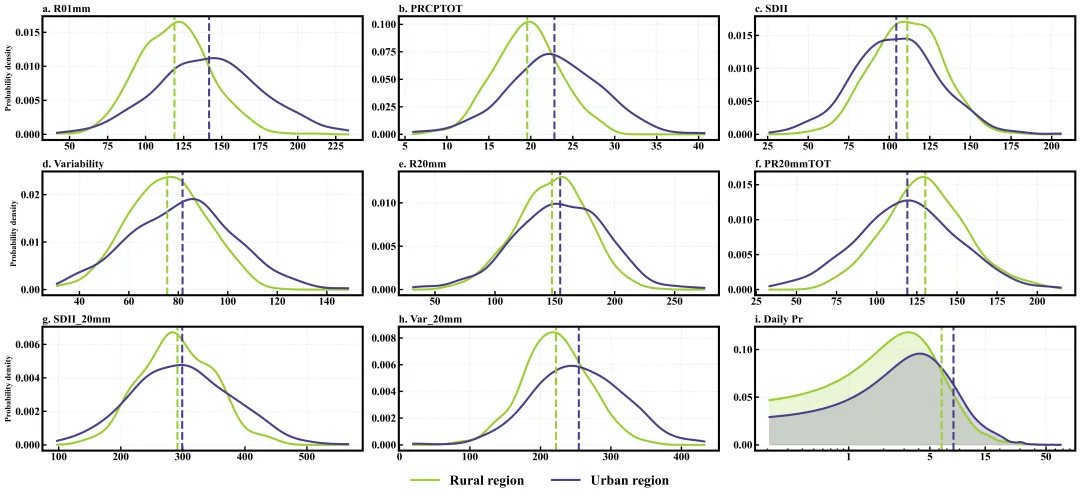
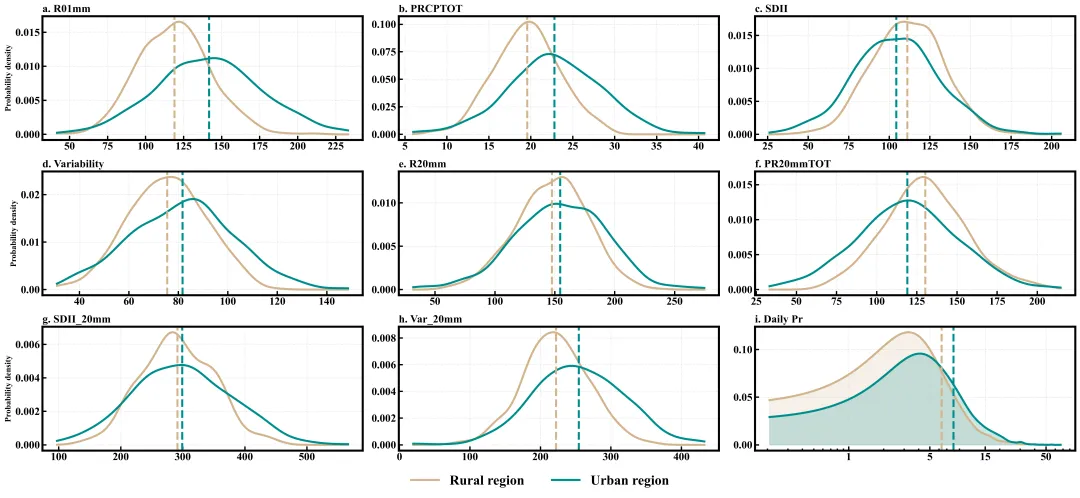
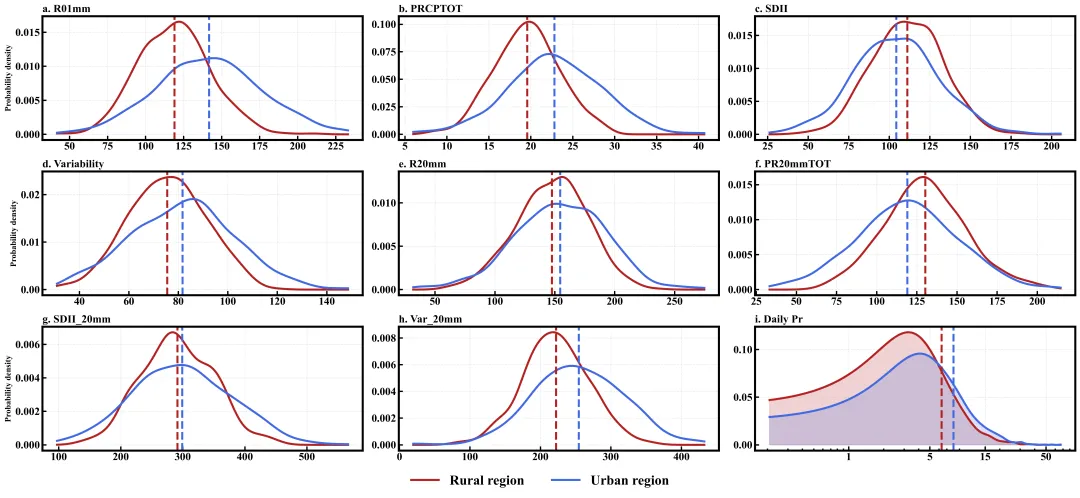
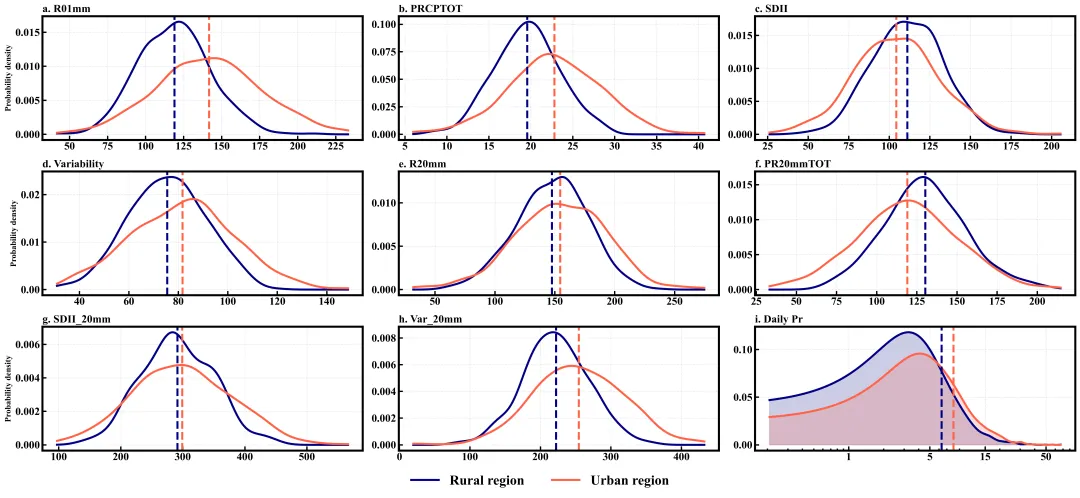
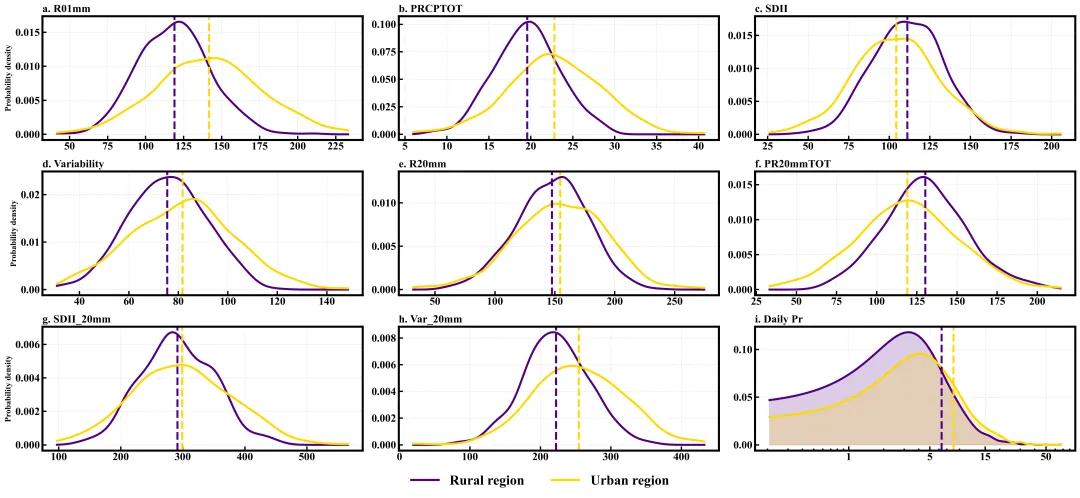
多种配色 



库的导入以及字体设置 

颜色库设置以及配色方案的选择 

子图绘制函数:核密度估计与坐标轴设置 

子图绘制函数:绘制曲线与填充 

子图绘制函数:绘制均值线与细节美化 

主绘制函数:创建组合图与循环遍历绘制子图 

主绘制函数:独立绘制子图及保存 

主绘制函数:组合图保存以及图例设置 

数据读取以及执行部分 



期刊图片复现|Python绘制二维偏依赖PDP图 期刊复现|python绘制基于SHAP分析和GAM模型拟合的单特征依赖图 期刊图片复现|python绘制带有渐变颜色shap特征重要性组合图(条形图+蜂巢图) 期刊复现|用Python绘制SHAP特征重要性总览图、依赖图、双特征交互效应SHAP图,解锁XGBoost模型的终极奥秘 期刊图片复现|Python绘制shap重要性蜂巢图+单特征依赖图+交互效应强度气泡图+交互效应依赖图(回归+二分类+分类) 

公众号中的所有所有的免费代码都已经下架了,都并入到付费部分里了,付费合集代码和数据的购买通道已经开通,全部合集100元,后续将会持续更新,决定购买请后台私信我,注意只会分享练习数据和代码文件,不会提供答疑服务,代码文件中已经包含了每行代码的完整注释,购买前请确保真的需要!!!
代码绘制成果展示
代码解释
第一部分
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom scipy.stats import gaussian_kdeimport osfrom matplotlib.lines import Line2Dimport matplotlib
第二部分
COLOR_SCHEMES = {1: {'rural': '#003f5c', 'urban': '#d45087'},}# 设置配色方案SCHEME_ID = 40#获取颜色方案colors = COLOR_SCHEMES.get(SCHEME_ID, COLOR_SCHEMES[1])
第三部分
def plot_single_ax(ax, key, r_vals, u_vals, colors, title, is_log=False):# 数据的核密度估计density_r = gaussian_kde(r_vals)density_u = gaussian_kde(u_vals)# 生成X轴的数据点,范围覆盖两组数据的最小值到最大值xs = np.linspace(min(min(r_vals), min(u_vals)), max(max(r_vals), max(u_vals)), 200)# 需要对数坐标if is_log:xs = np.logspace(np.log10(max(0.1, min(r_vals))), np.log10(max(r_vals)), 200)
第四部分
# 绘制乡村/城市数据的密度曲线ax.plot(xs, density_r(xs), color=colors['rural'], linewidth=3)ax.plot(xs, density_u(xs), color=colors['urban'], linewidth=3)# 填充曲线下的区域 (带透明度)ax.fill_between(xs, density_r(xs), color=colors['rural'], alpha=0.2)ax.fill_between(xs, density_u(xs), color=colors['urban'], alpha=0.2)
第五部分
# 绘制均值虚线ax.axvline(np.mean(r_vals), color=colors['rural'], linestyle='--', linewidth=3)ax.axvline(np.mean(u_vals), color=colors['urban'], linestyle='--', linewidth=3)# 设置子图标题、边框线宽和刻度样式ax.set_title(title, loc='left', fontweight='bold', fontsize=16)# 刻度标签设为粗体并开启网格for label in ax.get_xticklabels() + ax.get_yticklabels():label.set_fontweight('bold')ax.grid(True, linestyle=':', alpha=0.6)
第六部分
def draw_figures(data):# 创建 3x3 的组合画布fig_main, axes_main = plt.subplots(3, 3, figsize=(22, 10))axes_main = axes_main.flatten()for i, (key, ax_main) in enumerate(zip(data.keys(), axes_main)):r_vals = data[key]['rural']u_vals = data[key]['urban']is_log = (key == 'Daily Pr')current_title = f"{chr(97 + i)}. {key}" # 生成 a. b. c. 编号标题
第七部分
# 同时为每一个变量创建一个单独的画布并保存fig_single, ax_single = plt.subplots(figsize=(8, 5))plot_single_ax(ax_single, key, r_vals, u_vals, colors, current_title, is_log=is_log)ax_single.set_ylabel('Probability density', fontsize=12, fontweight='bold')# 保存并关闭,释放内存fig_single.savefig(fr'{key}_Scheme{SCHEME_ID}.png', dpi=300, bbox_inches='tight')plt.close(fig_single)
第八部分
# 同时为每一个变量创建一个单独的画布并保存fig_single, ax_single = plt.subplots(figsize=(8, 5))plot_single_ax(ax_single, key, r_vals, u_vals, colors, current_title, is_log=is_log)ax_single.set_ylabel('Probability density', fontsize=12, fontweight='bold')# 保存并关闭,释放内存fig_single.savefig(fr'{key}_Scheme{SCHEME_ID}.png', dpi=300, bbox_inches='tight')plt.close(fig_single)
第九部分
if __name__ == "__main__":# 读取数据df = pd.read_excel(r'Data.xlsx')data = {}processed_vars = set()# 遍历列名,寻找成对的 Rural 和 Urban 数据for col in df.columns:if col.endswith('_Rural'):base_name = col[:-6] # 获取变量名前缀if base_name not in processed_vars and f"{base_name}_Urban" in df.columns:r_data = df[f"{base_name}_Rural"].dropna().valuesu_data = df[f"{base_name}_Urban"].dropna().valuesdata[base_name] = {'rural': r_data, 'urban': u_data}processed_vars.add(base_name)# 调用绘图函数draw_figures(data)
如何应用到你自己的数据
1.设置颜色方案:
SCHEME_ID = 402.设置要提取的数据:
r_vals = data[key]['rural']u_vals = data[key]['urban']
3.设置子图保存地址:
fig_single.savefig(fr'{key}_Scheme{SCHEME_ID}.png', dpi=300, bbox_inches='tight')# 关闭4.设置组合图保存地址:
fig_main.savefig(fr'Scheme{SCHEME_ID}.png', dpi=300, bbox_inches='tight')fig_main.savefig(fr'Scheme{SCHEME_ID}.pdf', bbox_inches='tight')
5.设置原始数据的路径:
df = pd.read_excel(r'Data.xlsx')推荐
获取方式
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

