期刊图片复现|Python实现不同区域驱动因子归因分析棒棒糖图
- 2026-07-04 21:39:41
期刊图片复现|Python实现不同区域驱动因子归因分析棒棒糖图

论文:Widening Urban–Rural Precipitation Differences in China:Regionally Varied Intensification Since 2000 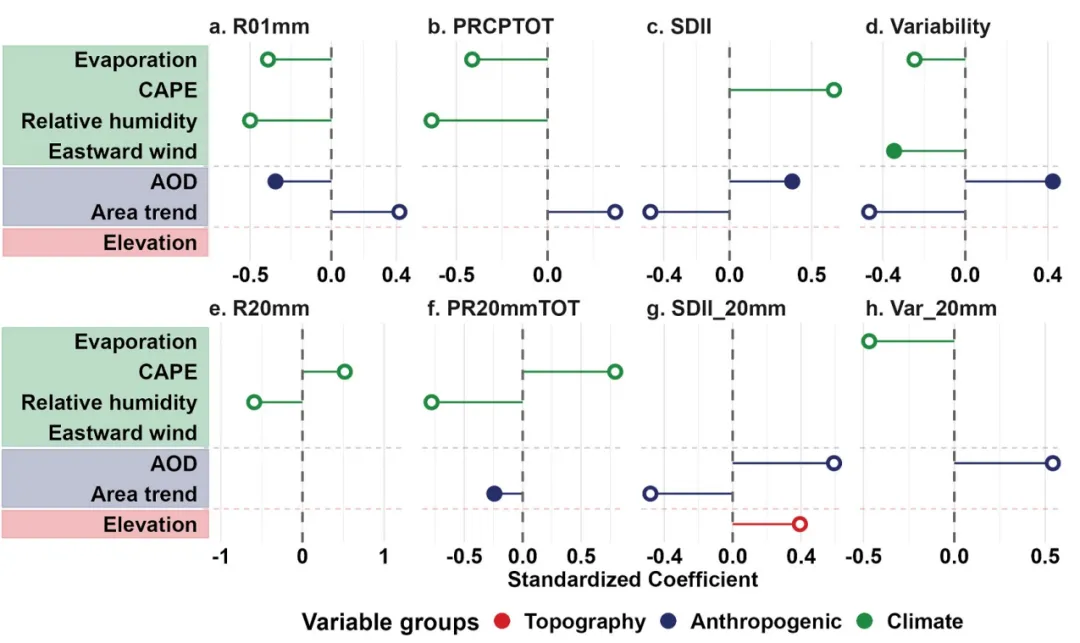
论文原图 此图通过标准化回归系数定量展示了1980至2022年间气候、人为及地形因素对中国城市化引起的各类降水指数变化的驱动作用。横坐标代表标准化回归系数。数值表示该驱动因子对城市化降水效应的影响强度和方向。右侧表示正向驱动。左侧表示负向驱动。纵坐标为潜在驱动因子。颜色用来区分驱动因子的类别:空心圆代表该因子与降水指标之间的关系在统计上是显著的。实心圆代表该因子在统计上未达到显著水平。原文使用的是逐步回归模型,我这用的是正常的回归模型,使用时还需要根据自己的需求来进行修改。 注意,此为个人理解,可能存在错误,具体内容还请阅读原文进行理解。 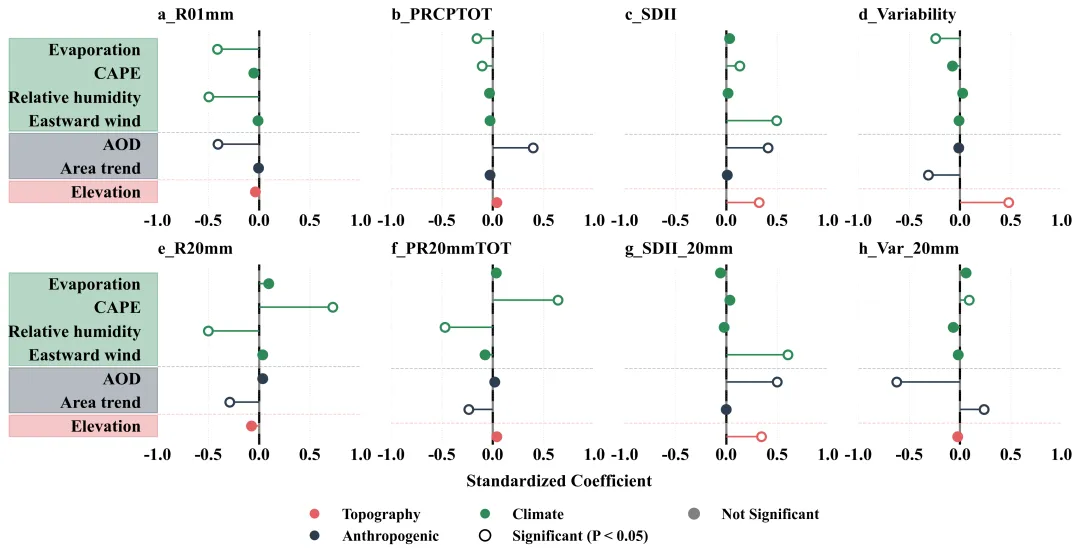
仿图 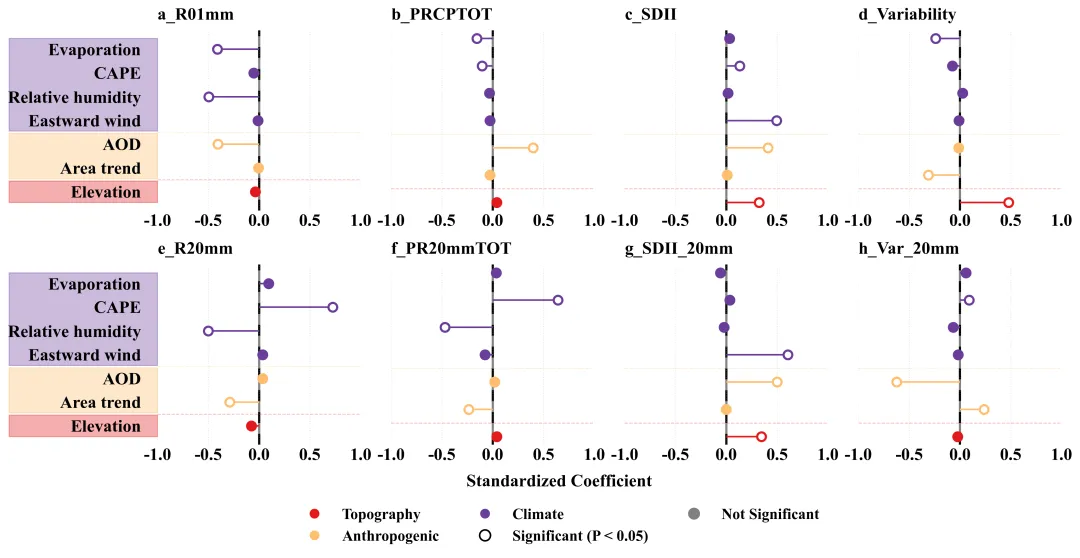
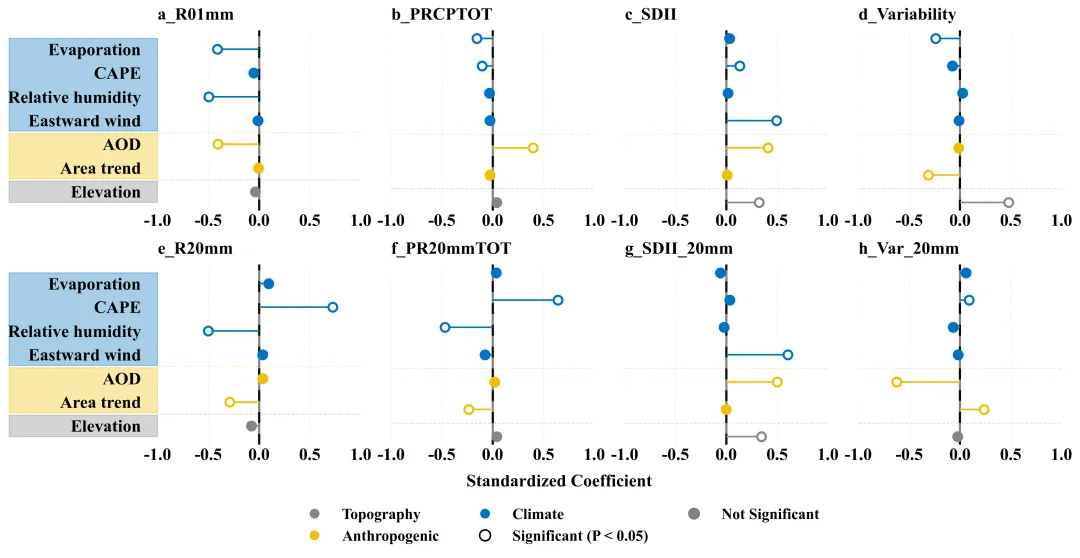
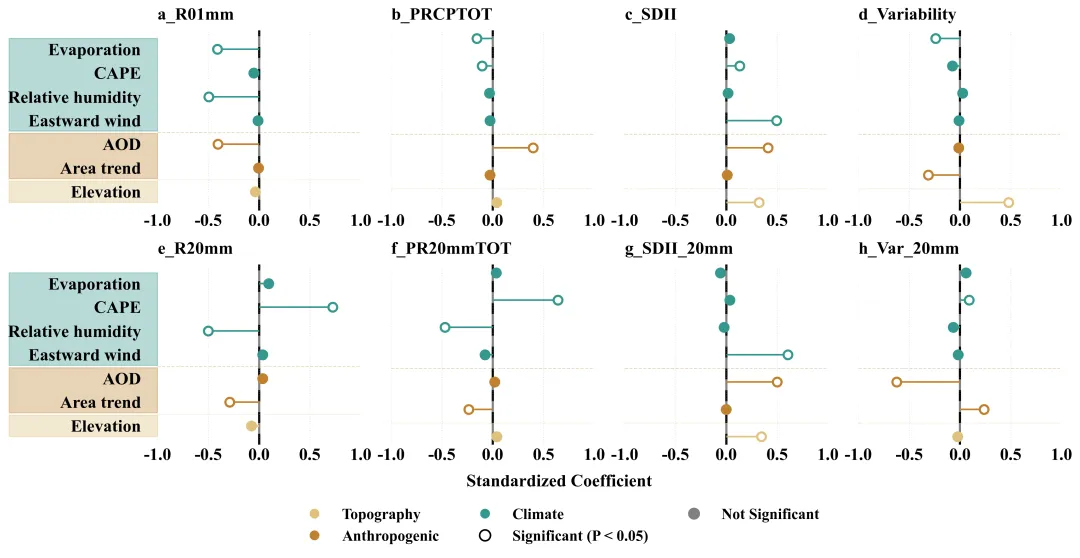
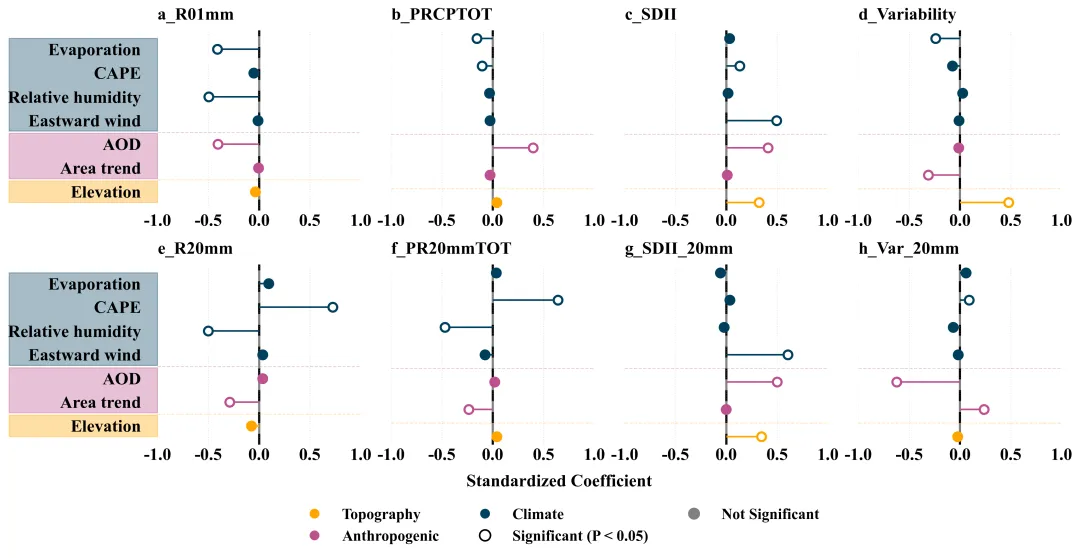
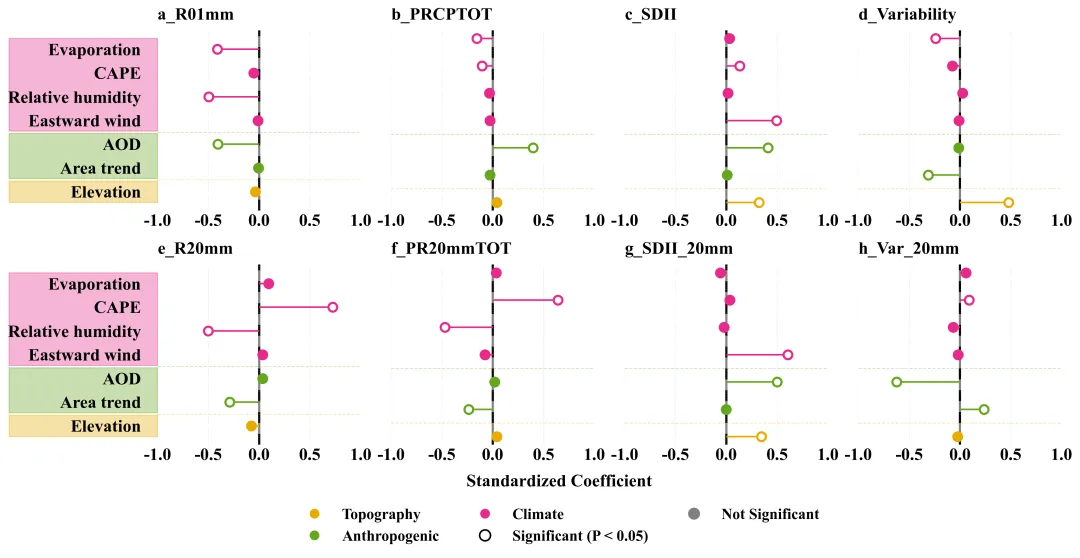
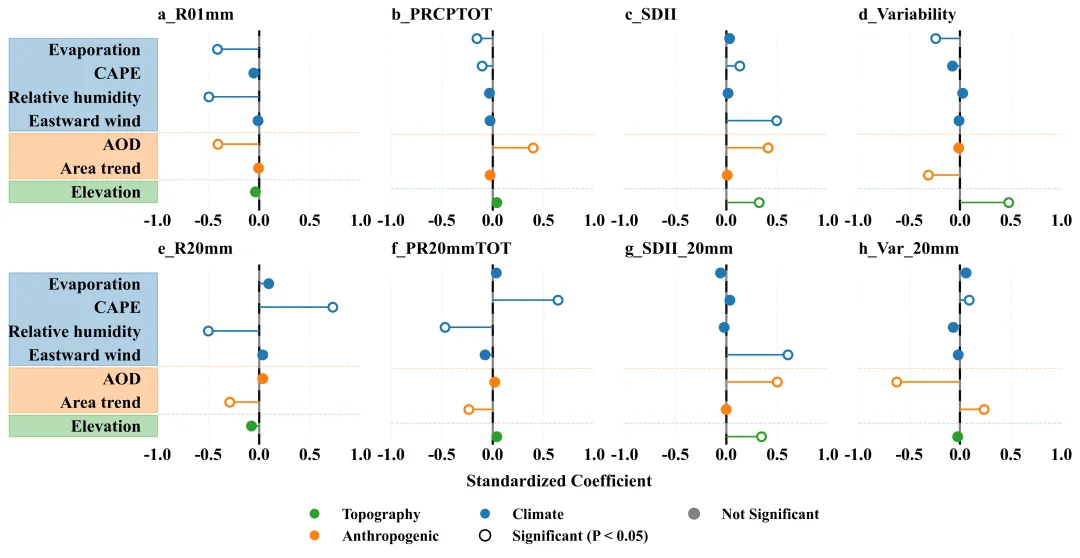
多种配色 



库的导入以及字体设置 

颜色库的设置以及配色方案的选择 

















期刊图片复现|Python绘制二维偏依赖PDP图 期刊复现|python绘制基于SHAP分析和GAM模型拟合的单特征依赖图 期刊图片复现|python绘制带有渐变颜色shap特征重要性组合图(条形图+蜂巢图) 期刊复现|用Python绘制SHAP特征重要性总览图、依赖图、双特征交互效应SHAP图,解锁XGBoost模型的终极奥秘 期刊图片复现|Python绘制shap重要性蜂巢图+单特征依赖图+交互效应强度气泡图+交互效应依赖图(回归+二分类+分类) 

公众号中的所有所有的免费代码都已经下架了,都并入到付费部分里了,付费合集代码和数据的购买通道已经开通,全部合集100元,后续将会持续更新,决定购买请后台私信我,注意只会分享练习数据和代码文件,不会提供答疑服务,代码文件中已经包含了每行代码的完整注释,购买前请确保真的需要!!!
代码绘制成果展示
代码解释
第一部分
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport statsmodels.api as smfrom matplotlib.lines import Line2Dimport matplotlibplt.rcParams['font.family'] = 'serif'plt.rcParams['font.serif'] = ['Times New Roman']plt.rcParams['axes.unicode_minus'] = Falseplt.rcParams['mathtext.fontset'] = 'stix'
第二部分
COLOR_SCHEMES = {1: {'Climate': '#2E8B57', 'Anthro': '#2c3e50', 'Topo': '#E35F62'},}SCHEME_ID = 2 #使用的颜色方案current_colors = COLOR_SCHEMES.get(SCHEME_ID, COLOR_SCHEMES[1]) #提取颜色#不同类型指标的颜色COLOR_CLIMATE = current_colors['Climate']COLOR_ANTHRO = current_colors['Anthro']COLOR_TOPO = current_colors['Topo']
第三部分
回归分析函数:负责读取数据并计算标准化回归系数
def perform_regression_from_excel(file_path):excel_file = pd.ExcelFile(file_path) # 加载 Excel 文件对象indices = excel_file.sheet_names # 获取所有工作表的名称# 定义驱动因子在图表中的排列顺序drivers_ordered = ['Evaporation', 'CAPE', 'Relative humidity', 'Eastward wind', 'AOD', 'Area trend', 'Elevation'][::-1]analysis_results = {} # 初始化用于存储回归分析结果的字典scaler = StandardScaler() # 初始化标准化器# 循环处理每一个不同区域for idx in indices:df_raw = pd.read_excel(file_path, sheet_name=idx) # 读取数据# 对所有数据进行标准化(Z-score),使不同量纲的系数具有可比性df_scaled = pd.DataFrame(scaler.fit_transform(df_raw), columns=df_raw.columns)y = df_scaled['TARGET_VALUE'] #目标X = df_scaled.drop(columns=['TARGET_VALUE']) #自变量# 整理结果for driver in drivers_ordered:c = coefs[driver] if driver in coefs else 0 # 如果变量存在则取系数,否则记为0p = pvalues[driver] if driver in pvalues else 1 # 如果变量存在则取P值,否则记为1plot_data.append({'driver': driver, #名称'coef': c, # 回归系数'p_value': p, #显著性检验 P 值'significant': p < 0.05 # 判断并记录该因子是否显著(P < 0.05)})analysis_results[idx] = pd.DataFrame(plot_data) # 将结果转为 DataFrame 并存入总字典return analysis_results, drivers_ordered # 返回所有回归分析结果和排序后的标签
第四部分
棒棒糖绘制函数:初始化与分类设置
def plot_figure_9(analysis_results, driver_labels):# 创建 2 行 4 列的画布fig, axes = plt.subplots(2, 4, figsize=(16, 8))axes = axes.flatten() # 将多维子图数组展平为一维方便循环处理# 定义各驱动因子所属的分类及对应的颜色group_colors = {'Evaporation': COLOR_CLIMATE,'CAPE': COLOR_CLIMATE,'Relative humidity': COLOR_CLIMATE,'Eastward wind': COLOR_CLIMATE,'AOD': COLOR_ANTHRO,'Area trend': COLOR_ANTHRO,'Elevation': COLOR_TOPO}indices = list(analysis_results.keys()) # 获取所有需要绘图的工作表键名
第五部分
棒棒糖绘制函数:循环绘图,参考线绘制以及特征名称背景色填充
for i, ax in enumerate(axes): # 遍历每一个子图坐标轴if i >= len(indices): # 如果子图位置超出了数据量ax.axis('off') # 隐藏多余的子图坐标轴continuekey = indices[i] # 获取当前子图对应的指标名称df = analysis_results[key] # 获取对应的回归分析结果数据ax.axhspan(0.55, #y轴起始2.45, #y轴终止xmin=-0.73, # x 轴方向的起始比例xmax=0, # x 轴方向的结束比例color=COLOR_ANTHRO, # 颜色填充alpha=0.35, # 透明度transform=ax.get_yaxis_transform(), #坐标系zorder=0,clip_on=False) # 允许在绘图框外显示色块ax.axhspan(-0.45, #y轴起始0.45, #y轴终止xmin=-0.73, # x 轴方向的起始比例xmax=0, # x 轴方向的结束比例color=COLOR_TOPO, # 颜色填充alpha=0.35, # 透明度transform=ax.get_yaxis_transform(), #坐标系zorder=0,clip_on=False) # 允许在绘图框外显示色块
第六部分
棒棒糖绘制函数:绘制棒棒糖主体
# 遍历当前子图数据中的每一行驱动因子for idx, row in df.iterrows():driver = row['driver'] # 获取驱动因子名称val = row['coef'] # 获取系数大小is_sig = row['significant'] # 获取显著性状态color = group_colors[driver] # 获取该因子对应的颜色y_pos = driver_labels.index(driver) # 确定在 Y 轴上的显示位置# 如果显著则填充白色,不显著则填充实心颜色face_c = 'white' if is_sig else color# 绘制回归系数的数值点ax.plot(val, # 在xy_pos, #ymarker='o', # 点的形状markersize=8, # 大小markerfacecolor=face_c, # 内部填充颜色markeredgecolor=color, #外边框颜色markeredgewidth=2, # 边框的粗细zorder=3)
第七部分
棒棒糖绘制函数:x、y轴刻度线、标注,图框,横向虚线等细节设置
# 设置 Y 轴刻度位置ax.set_yticks(range(len(driver_labels)))# 如果是第一列子图if i % 4 == 0:#y轴名称标签ax.set_yticklabels(driver_labels,fontweight='bold',fontsize=15)#Y轴标签与轴线的间距ax.tick_params(axis='y',pad=15)# 隐藏所有的坐标轴刻度线ax.tick_params(axis='both',which='both',length=0,labelsize=16)[label.set_fontweight('bold') for label in ax.get_xticklabels()] # 遍历并设置 x 轴数值标注为加粗[label.set_fontweight('bold') for label in ax.get_yticklabels()] # 遍历并设置 y 轴数值标注为加粗#子图的标题ax.set_title(key, #内容loc='left', #位置fontweight='bold', #加粗fontsize=16, #大小pad=10) #间距#X轴固定范围ax.set_xlim(-1, 1)ax.xaxis.set_major_locator(ticker.MultipleLocator(0.5)) # 设置主刻度间隔# X轴的垂直网格参考线ax.grid(axis='x', #x 轴linestyle=':', #网格线的样式alpha=0.3) # 透明度
第八部分
棒棒糖绘制函数:图例设置以及绘图结果的保存
#x轴标题fig.text(0.5, #x0.16, #y'Standardized Coefficient', #文本ha='center', #水平对齐va='center', #垂直对齐fontweight='bold', #粗细fontsize=16) #字体大小#创建图例legend_elements = [Line2D([0], #x[0], #ymarker='o', #标记形状color='w', #颜色label='Topography', #文本markerfacecolor=COLOR_TOPO, #点的填充颜色markersize=10), #圆点的大小Line2D([0], [0], marker='o', color='w', label='Anthropogenic', markerfacecolor=COLOR_ANTHRO, markersize=10),Line2D([0], [0], marker='o', color='w', label='Climate', markerfacecolor=COLOR_CLIMATE, markersize=10),plt.subplots_adjust(wspace=0.15, #子图之间的横向间距hspace=0.3, #纵向间距bottom=0.22, #底部left=0.18) #左侧边缘
第九部分
执行部分
# =========================================================================================# ======================================2.颜色库=======================================# =========================================================================================if __name__ == "__main__":input_excel = r'data.xlsx' #输入数据# 执行回归计算并获取结果results, labels = perform_regression_from_excel(input_excel)# 调用绘图函数plot_figure_9(results, labels)
如何应用到你自己的数据
1.设置颜色方案:
SCHEME_ID = 2 #使用的颜色方案2.提取驱动因子:
drivers_ordered = ['Evaporation', 'CAPE', 'Relative humidity', 'Eastward wind', 'AOD', 'Area trend', 'Elevation'][::-1] 3.提取目标:
y = df_scaled['TARGET_VALUE'] #目标4.划分变量的类别:
group_colors = { 'Evaporation': COLOR_CLIMATE, 'CAPE': COLOR_CLIMATE, 'Relative humidity': COLOR_CLIMATE, 'Eastward wind': COLOR_CLIMATE, 'AOD': COLOR_ANTHRO, 'Area trend': COLOR_ANTHRO, 'Elevation': COLOR_TOPO}5.设置绘图结果的保存路径:
plt.savefig(fr'theme_{SCHEME_ID}.png', dpi=300,bbox_inches='tight')plt.savefig(fr'theme_{SCHEME_ID}.pdf',bbox_inches='tight')
6.设置原始数据的路径:
input_excel = r'data.xlsx' #输入数据7.设置分析数据的路径:
output_excel_path = r'regression_summary.xlsx'推荐
获取方式
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

