大家好,我是大华!
Python 学习进入第 4 天,开始学习变量的作用域,以及代码的模块化组织方式。
比如:变量该放哪?怎么模块化?还有内置函数等。
今天的文章内容可能比前几天的要多一些,于是用 AI 生成了部分配图,缓解一下阅读的疲劳。
废话不多说,直接开始了。
一、变量作用域
1.1 什么是作用域?
作用域是变量在程序中可被访问的范围,决定了变量的"可见性"和"生命周期"。
1.2 四种作用域级别(LEGB规则)
LEGB 规则分布对应下面这4个:
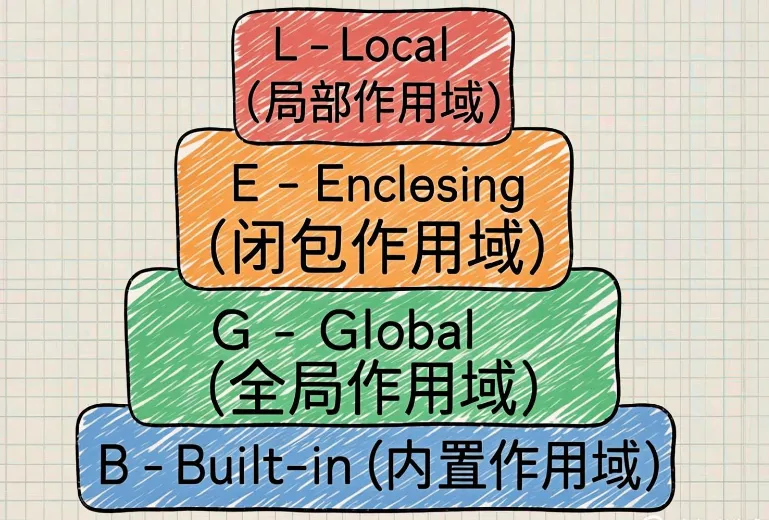
- • L - Local(局部作用域):函数内部定义的变量,只有在该函数内部可见
- • E - Enclosing(闭包作用域):嵌套函数的外层函数变量
- • G - Global(全局作用域):模块级别定义的变量
- • B - Built-in(内置作用域):Python内置的函数和变量
代码示例:
# 全局变量global_var = "我是全局变量"def outer_function(): # 闭包变量(外部函数变量) outer_var = "我是外部函数变量" def inner_function(): # 局部变量 local_var = "我是局部变量" # 内置作用域(如print, len等) print(local_var) # 局部变量 print(outer_var) # 闭包变量 print(global_var) # 全局变量 print(len("test")) # 内置函数 inner_function() # print(local_var) # 错误!无法访问内部函数的局部变量outer_function()print(global_var) # 正确,可以访问全局变量
输出结果:
我是局部变量我是外部函数变量我是全局变量4我是全局变量
特别说明:print(len("test")) 输出的4,是内置的函数 len() 读取 test 这个字符串的长度。
1.3 global 和 nonlocal 关键字
global 关键字
声明使用全局变量。
counter = 0def increment(): global counter # 使用全局变量 counter += 1 print(f"计数器: {counter}")increment() # 输出: 计数器: 1increment() # 输出: 计数器: 2
在需要使用全局变量的情况下,必须加上 global 关键字,不加会报错,如下:
counter = 0 # 全局变量def increment(): # 如果不用 global,Python会认为counter是新的局部变量 counter = counter + 1 # 这里会报错!increment()
这个代码会报错:UnboundLocalError: cannot access local variable 'counter' where it is not associated with a value

原因:Python 看到一个函数内部对变量赋值时,会认为这个变量是局部变量。
在 counter = counter + 1 中,右边的 counter 还没定义(局部变量),所以报错。
nonlocal 关键字
声明使用外部函数的变量
def outer(): message = "原始消息" def inner(): nonlocal message # 使用外部函数的变量 message = "修改后的消息" print(f"内部函数: {message}") inner() print(f"外部函数: {message}")outer()
输出结果:
内部函数: 修改后的消息外部函数: 修改后的消息
如果没有 nonlocal message 这个关键字,那么输出的结果如下:
内部函数: 修改后的消息外部函数: 原始消息
原因是:outer() 里的 message 没被修改,inner() 创建了自己的局部变量。
二、模块(Module)
2.1 什么是模块?
模块是一个包含 Python 代码的.py文件,可以包含函数、类、变量等。

2.2 创建和使用模块
创建 calculator.py 文件,这是一个模块文件,然后在另一个文件导入它。
def add(a, b): # 返回两个数的和 return a + bdef subtract(a, b): # 返回两个数的差 return a - bdef multiply(a, b): # 返回两个数的乘积 return a * bdef divide(a, b): # 返回两个数的商 if b == 0: return "错误:除数不能为零" return a / b# 模块级别的变量PI = 3.14159VERSION = "1.0.0"
创建 main.py,在该文件导入使用 calculator.py。
这里的导入也分几种导入方式,如下:
方式1:导入整个模块
import calculator# 调用calculator模块的add函数result = calculator.add(10, 5)print(f"10 + 5 = {result}")print(f"PI值: {calculator.PI}")
方式2:导入特定功能
from calculator import add, subtract, PIresult = add(20, 10)print(f"20 + 10 = {result}")print(f"PI值: {PI}")
方式3:使用别名
import calculator as calcfrom calculator import multiply as mulresult = calc.divide(20, 4)print(f"20 ÷ 4 = {result}")result = mul(5, 6)print(f"5 × 6 = {result}")
2.3 Python 标准库常用模块
1.日期时间
使用 datetime 模块处理日期时间
import datetime# 获取当前日期和时间now = datetime.datetime.now()print(f"当前时间: {now}")print(f"日期: {now.date()}")print(f"时间: {now.time()}")# 格式化日期formatted = now.strftime("%Y年%m月%d日 %H:%M:%S")print(f"格式化后: {formatted}")
输出结果:
当前时间: 2026-01-30 17:07:30.442070日期: 2026-01-30时间: 17:07:30.442070格式化后: 2026年01月30日 17:07:30
2.math
使用 math 模块进行数学运算
import mathprint(f"π的值: {math.pi}")print(f"e的值: {math.e}")print(f"平方根: {math.sqrt(16)}")print(f"绝对值: {math.fabs(-10)}")
输出结果:
π的值: 3.141592653589793e的值: 2.718281828459045平方根: 4.0绝对值: 10.0
3.random
使用random模块生成随机数
import randomprint(f"随机整数: {random.randint(1, 100)}")print(f"随机浮点数: {random.random()}")print(f"随机选择: {random.choice(['苹果', '香蕉', '橙子'])}")
输出结果:
随机整数: 2随机浮点数: 0.6870458703638805随机选择: 苹果
4.os
使用os模块进行操作系统交互
import osprint(f"当前工作目录: {os.getcwd()}")print(f"当前目录文件列表: {os.listdir('.')}")print(f"环境变量PATH: {os.environ.get('PATH')}")
输出结果:
当前工作目录: D:\liudahua\pythonCode\python当前目录文件列表: ['calculator.py', 'main.py', '__pycache__']环境变量PATH: c:\Users\xx\AppData\Roaming\Code\User\globalStorage\xxx
除了 datetime、math、random、os 这些常用模块,Python 标准库包含了 200+ 个内置模块,涵盖了几乎所有基础功能。
三、包(Package)
3.1 什么是包?
包是包含多个模块的目录,每一个包需要包含一个特殊的 __init__.py 文件。
3.2 创建包的结构
my_package/├── __init__.py├── module1.py├── module2.py└── subpackage/ ├── __init__.py └── module3.py
3.3 __init__.py 有什么作用呢?
情况 1:有 __init__.py
my_package/├── __init__.py└── module.py
引入包的几种方式:
import my_packageimport my_package.modulefrom my_package import module
全都正常, Python 会很清楚:my_package 是一个包。
情况 2:没有 __init__.py
my_folder/└── module.py
这样写会报错
import my_folder
必须要明确的导入那个文件。
import my_folder.module
而且有时能跑,有时不能(命名空间包的行为),不推荐这种写法。
在 Python 3.2 及以前的版本是必须要有的,没有 __init__.py 的目录不是包。Python 3.3+以后就是可选的了,因为引入了"命名空间包"(Namespace Package)。
3.4 包的使用示例
创建一个文件夹my_package,文件夹下面新增module1.py、module2.py 和 __init__.py文件。
module1.py
# my_package/module1.pydef function1(): return "这是模块1的函数"def internal_function(): return "这是内部函数,不建议直接使用"
module2.py
# my_package/module2.pydef function2(): return "这是模块2的函数"
__init__.py
# my_package/__init__.pyprint("包初始化开始...")# 导入子模块的函数到包的命名空间from .module1 import function1from .module2 import function2__version__ = "1.0.0"__author__ = "Python学习者"print("包初始化完成!")
外部再创建一个 main.py 来使用这个包。
# 使用包import my_packageprint(my_package.function1())print(my_package.function2())print(f"包版本: {my_package.__version__}")
执行这个main.py
python `main.py
输出结果:
包初始化开始...包初始化完成!这是模块1的函数这是模块2的函数包版本: 1.0.0
可以看到,__init__.py 代码的优先级是最高的,非常适合做初始化工作。比如数据库连接、环境变量、组件注册等等。
四、常用内置模块
4.1 collections模块
下面的几个示例,先导入这行哈。
from collections import Counter, defaultdict, deque, namedtuple
Counter:计数器
text = "apple banana apple orange banana apple"word_count = Counter(text.split())print(f"单词统计: {word_count}")print(f"apple出现次数: {word_count['apple']}")
defaultdict:带默认值的字典
fruit_prices = defaultdict(lambda: 0.0)fruit_prices['apple'] = 5.0fruit_prices['banana'] = 3.0print(f"苹果价格: {fruit_prices['apple']}")print(f"橙子价格: {fruit_prices['orange']}") # 返回默认值0.0,不会报错
deque:双端队列
queue = deque(['A', 'B', 'C'])queue.append('D') # 右侧添加queue.appendleft('Z') # 左侧添加print(f"队列: {queue}")print(f"弹出左侧: {queue.popleft()}")print(f"弹出右侧: {queue.pop()}")
namedtuple:命名元组
Point = namedtuple('Point', ['x', 'y'])p = Point(10, 20)print(f"点坐标: ({p.x}, {p.y})")
4.2 json模块
import json# Python对象转换为JSON字符串data = { "name": "张三", "age": 25, "is_student": False, "courses": ["Python", "数据结构", "算法"], "address": { "city": "北京", "district": "海淀区" }}json_str = json.dumps(data, ensure_ascii=False, indent=2)print("JSON字符串:")print(json_str)# 保存到文件with open("data.json", "w", encoding="utf-8") as f: json.dump(data, f, ensure_ascii=False, indent=2)# 从JSON字符串解析json_data = '{"name": "李四", "age": 30}'parsed_data = json.loads(json_data)print(f"解析后的数据: {parsed_data}")print(f"姓名: {parsed_data['name']}")# 从文件读取with open("data.json", "r", encoding="utf-8") as f: loaded_data = json.load(f)print(f"从文件加载: {loaded_data['name']}")
输出结果:
JSON字符串:{ "name": "张三", "age": 25, "is_student": false, "courses": [ "Python", "数据结构", "算法" ], "address": { "city": "北京", "district": "海淀区" }}解析后的数据: {'name': '李四', 'age': 30}姓名: 李四从文件加载: 张三
五、包管理
5.1 pip包管理工具
# 安装包pip install requestspip install pandas==1.5.0 # 指定版本pip install -r requirements.txt # 从文件安装# 查看已安装的包pip listpip show requests # 查看特定包信息# 升级包pip install --upgrade requests# 卸载包pip uninstall requests# 生成requirements.txtpip freeze > requirements.txt
5.2 requirements.txt示例
# 项目依赖文件requests==2.28.1pandas>=1.5.0numpy==1.23.5beautifulsoup4>=4.11.0flask>=2.2.0# 开发环境依赖pytest>=7.0.0black>=22.0.0flake8>=5.0.0
六、完整的项目结构示例
my_project/├── README.md # 项目说明├── requirements.txt # 依赖包列表├── .gitignore # Git忽略文件├── src/ # 源代码目录│ ├── __init__.py│ ├── main.py # 主程序│ ├── utils/ # 工具模块│ │ ├── __init__.py│ │ ├── file_utils.py│ │ └── math_utils.py│ ├── models/ # 数据模型│ │ ├── __init__.py│ │ └── user.py│ └── config.py # 配置文件├── tests/ # 测试代码│ ├── __init__.py│ ├── test_utils.py│ └── test_models.py├── docs/ # 文档│ └── tutorial.md└── data/ # 数据文件 └── sample.json
今天的学习内容先到这里。如果有不对或者需要补充的地方,欢迎指正。
如果你觉得文章写的还不错,不妨点赞、推荐,转发给你的朋友看一下。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
