摘要
本文通过多个 C 语言示例,详细解析 FIRM 中间表示(IR)的图结构特性。我们将从简单的算术运算开始,逐步深入到条件分支、循环控制和函数调用等复杂结构,每个示例都基于实际的 FIRM IR 图,直观展示 FIRM 如何将传统线性代码转换为基于图的中间表示。通过本文,读者将全面了解 FIRM IR 的设计哲学、图节点类型及其在实际编译中的应用。
目录
- 4. 循环控制(break/continue)的 IRG 表示
1. FIRM IR 设计哲学
FIRM(Flexible IR Manipulation)是由奥地利林茨大学开发的编译器基础架构,采用完全图基中间表示,将程序的控制流和数据流统一表示为有向图。与传统的线性 IR(如三地址码)相比,FIRM 的设计代表了现代编译器中间表示的发展方向。
FIRM 框架概述
FIRM 是一个用于编译器优化的开源框架,具有以下特点:
- • SSA 形式内置:所有值都是静态单赋值形式,Phi 节点处理控制流汇合
- • 图结构表示:程序表示为有向图,节点表示操作,边表示依赖关系
- • 多种优化:内建多种优化算法,如常量传播、死代码消除、循环优化等
核心特性
- • 数据依赖:通过黑色边(块内)和蓝色虚线边(块间)表示
- • 所有操作都是图中的节点,包括算术运算、控制转移、内存访问等
- • 基本块包含一组节点,这些节点共享相同的控制流入口
设计优势
FIRM 的图IR设计具有以下优势:
- 1. 优化友好:图结构天然支持多种优化算法,许多优化可以表示为简单的图变换
- 2. 分析准确:显式的依赖关系消除了传统IR中的隐式依赖,提高了分析的准确性
- 3. 并行化潜力:显式的数据依赖便于识别可并行执行的操作
- 4. 目标代码生成:图结构可以更直接地映射到现代处理器的指令调度
与线性 IR 的对比
2. 简单算术运算的 IRG 表示
C 语言示例
int add_example(int a, int b) { int c = a + b; int d = c * 2; return d;}
对应 IRG 图
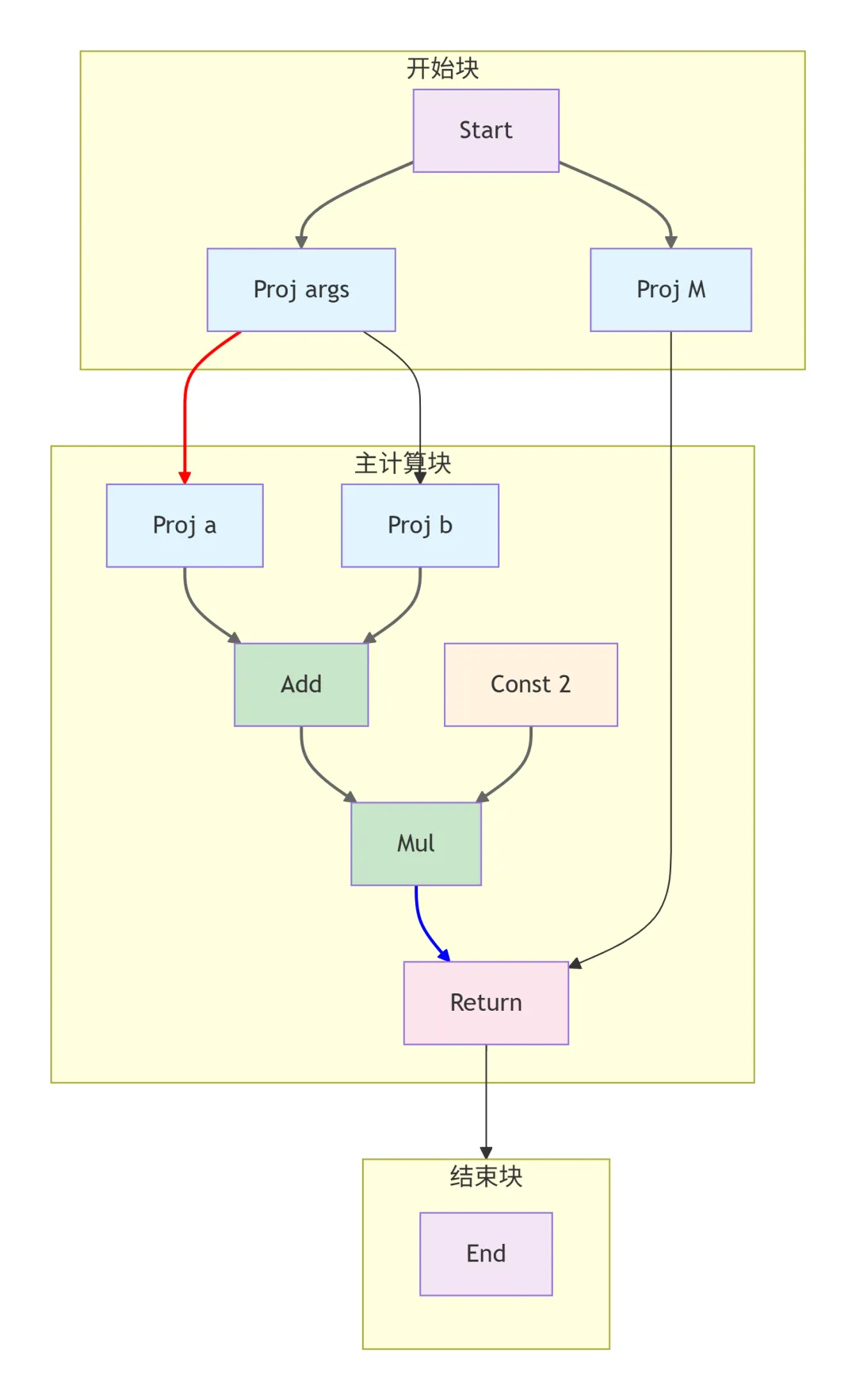
图结构解析
这个简单的 IRG 展示了 FIRM 的基本构建块:
- 1. Start 节点:函数入口点,产生一个包含参数元组和控制流的元组
- •
Proj a 和 Proj b:从参数元组中投影出具体参数
- 4. 常量节点:
Const 2 表示字面量常量 2 - 5. Return 节点:函数返回点,连接到 End 节点
数据流和控制流
在 FIRM 中,数据流和控制流是分离的:
- 1. 数据流:
a → Add → Mul → Returnb ↗ ↗ Const 2
数据流清晰地表示了值的计算顺序和依赖关系。
- 2. 内存流:
Proj M → Return
内存状态在函数开始时被投影,在函数返回时被使用,确保内存操作的顺序性。
- 3. 控制流:
Start → 主计算块 → Return → End
控制流表示执行的顺序,从 Start 开始,经过主计算块,到 Return 结束。
关键观察
- 1. 所有值都是 SSA 形式:每个值只被赋值一次,通过数据依赖边传递
- 3. 块内并行潜力:如果两个操作没有数据依赖,它们可以在同一基本块内并行执行
- 4. 内存状态显式化:内存操作通过特殊边序列化,支持精确的内存分析
3. 条件分支(if-else)的 IRG 表示
C 语言示例
int max(int a, int b) { int result; if (a > b) { result = a; } else { result = b; } return result;}
对应 IRG 图
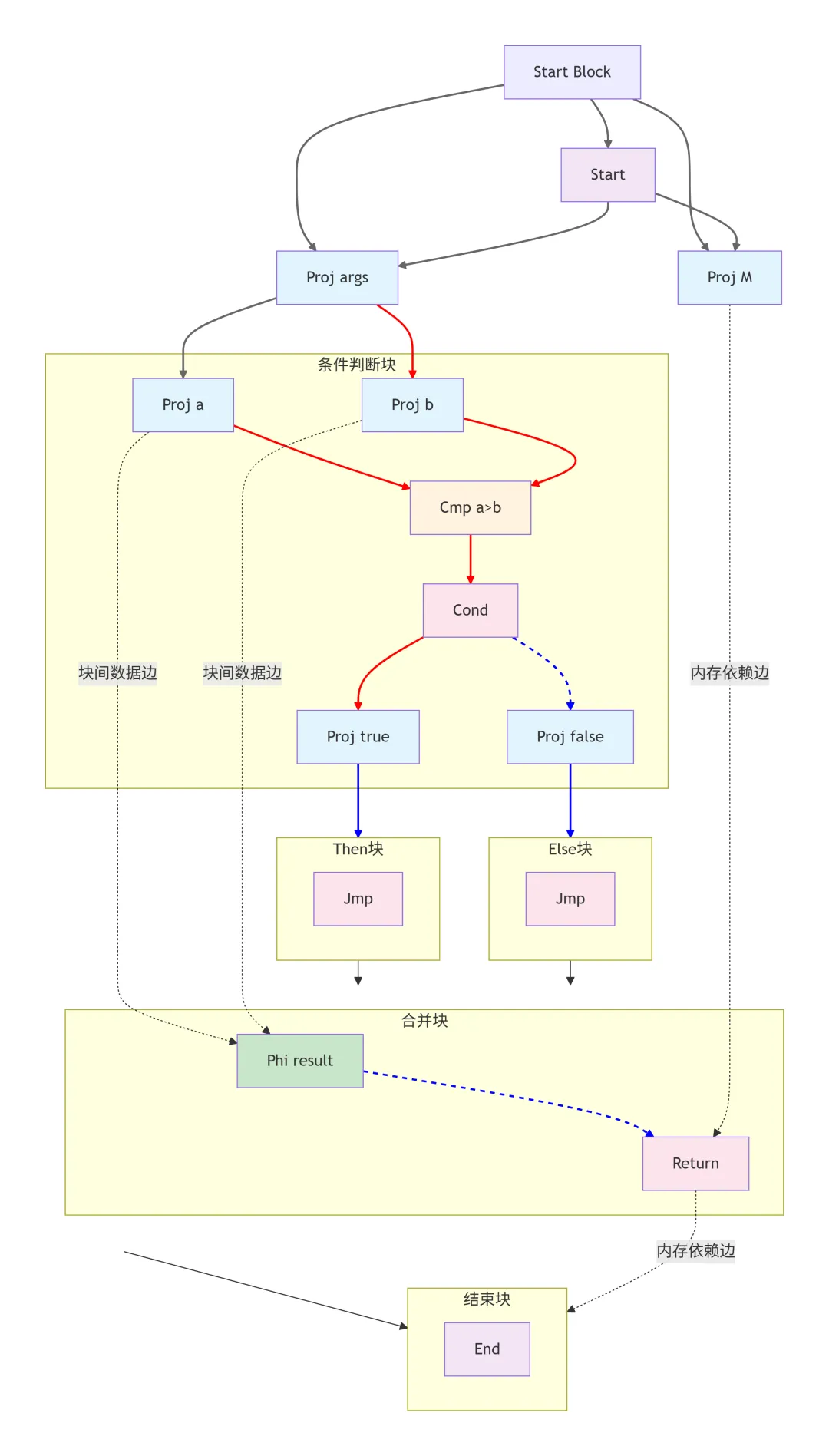
控制流模式
这个 IRG 展示了条件分支的标准模式:
- 1. 条件判断块:包含
Cmp 比较节点和 Cond 条件节点,产生两个控制流投影(true/false) - 2. 分支块分离:then 和 else 分支位于不同基本块,通过
Jmp 节点连接到汇合块 - 3. Phi 节点合并:在控制流汇合点的
Phi 节点根据前驱块选择正确的值 - 4. 显式跨块数据依赖:
Phi 节点直接从源基本块的 Proj 节点获取值(蓝色虚线)
关键特性
- 1. 控制流边:从控制流节点(
Proj true/false)指向基本块(红色实线) - 2. 跨块数据边:从源节点的数据输出到目标节点的数据输入(蓝色虚线)
- 3. 内存依赖边:从
Proj M 到 Return 的内存状态传递(蓝色实线) - 4. Phi 节点:在控制流汇合点合并来自不同路径的值,这是 SSA 形式的核心
与传统三地址码对比
传统三地址码:
t1 = a > bif t1 goto L1result = bgoto L2L1:result = aL2:return result
FIRM 优势:
4. 循环控制(break/continue)的 IRG 表示
C 语言示例
int loop_example(int n) { int sum = 0; int i = 0; while (i < n) { if (i == 5) { break; // 提前退出循环 } if (i % 2 == 0) { i++; // continue 的等价操作 continue; } sum += i; i++; } return sum;}
对应 IRG 图
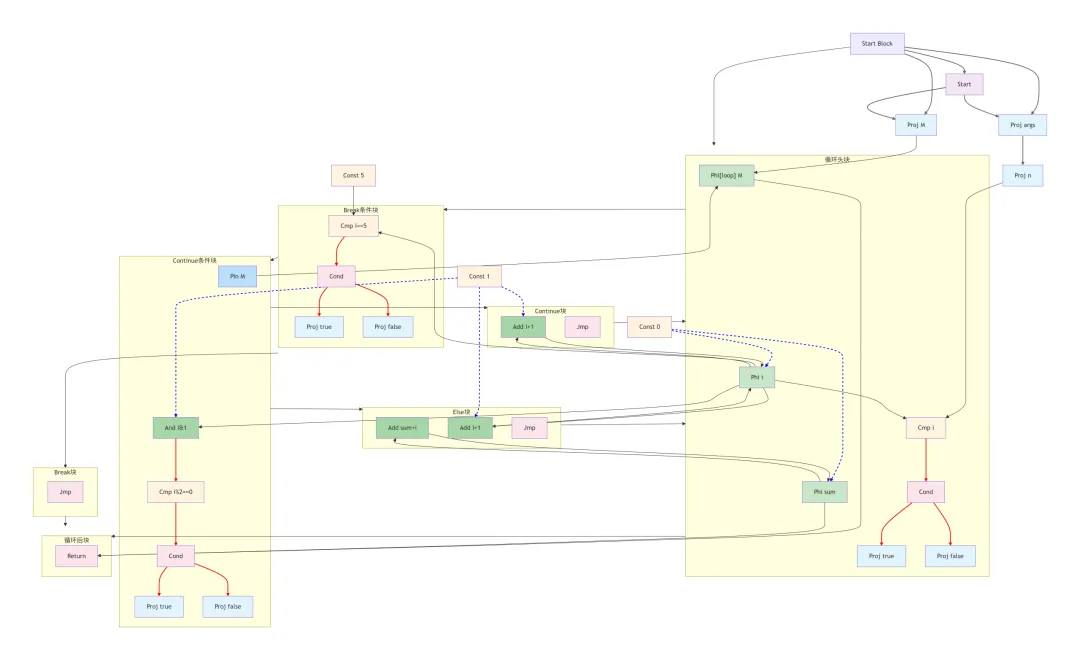
循环结构解析
这个复杂的 IRG 展示了循环控制流的完整表示:
- •
Phi[loop] M:内存状态Phi节点,跟踪循环中的内存状态 - •
Phi i:循环变量i的Phi节点,合并每次迭代的值
- • 内层2:continue条件
i % 2 == 0
- • continue路径:跳过sum累加,直接进行i++
- • 加法操作的结果通过跨块数据边反馈到对应的Phi节点
- 5. 循环出口:正常退出(条件为假)和提前退出(break)都汇聚到循环后块
内存状态管理
- •
Phi[loop] M:特殊的循环内存Phi节点,确保内存操作在循环中的正确顺序 - •
Pin M:内存状态钉住节点,将内存状态从循环体传递回循环头
循环优化潜力
FIRM 的循环表示为优化提供了丰富的信息:
- 1. 循环不变代码外提:可以识别循环中不变的计算并移到循环外
- 2. 归纳变量优化:循环变量i的Phi节点和更新操作便于进行归纳变量优化
- 3. 循环展开:循环结构明确,便于进行循环展开优化
- 4. 软件流水线:显式的数据依赖便于安排指令执行顺序
5. 函数调用的 IRG 表示
C 语言示例
int helper(int x) { return x * 2;}int caller(int a, int b) { int temp = helper(a); return temp + b;}
对应 IRG 图
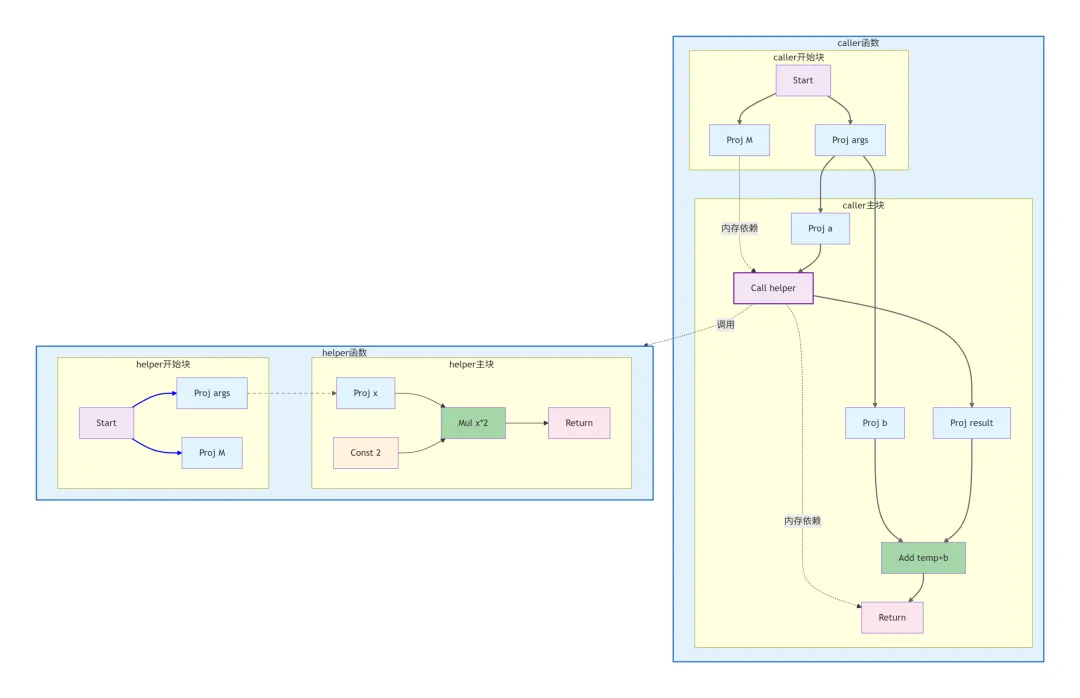
函数调用模式
函数调用在 FIRM 中表示为特殊结构:
- 1. Call 节点:表示函数调用,连接到被调用函数的 IRG
- 2. 参数传递:调用者参数通过 Call 节点的输入边传递
- 3. 控制流转移:Call 节点会等待被调用函数执行完毕
- 4. 返回值处理:Call 节点的结果投影包含返回值
- 5. 独立 IRG:每个函数有自己独立的 IRG,通过 Call 节点连接
- 6. 内存依赖传递:内存状态通过 Call 节点在调用者和被调用者之间传递
内存状态流
Proj M (caller) → Call helper → Return (caller)
内存状态在函数调用前后保持一致,确保内存操作的顺序性。
函数调用优化
FIRM 的函数调用表示支持多种优化:
- 1. 内联优化:Call 节点可以被被调用函数的 IRG 替换
6. 综合示例与模式总结
FIRM IR 节点类型总结
| 节点类型 | 功能 | 示例 |
|---|
| Start | | Start |
| Proj | | Proj args |
| Const | | Const 0 |
| 计算节点 | | Add |
| Cond | | Cond |
| Phi | | Phi result |
| Phi[loop] | | Phi[loop] M |
| Pin | | Pin M |
| Call | | Call helper |
| Return | | Return |
| Jmp | | Jmp |
| End | | End |
边类型总结
| 边类型 | 表示 | 颜色/样式 | 功能 |
|---|
| 控制流边 | | | |
| 块内数据边 | | | |
| 块间数据边 | | | |
| 内存依赖边 | | | |
| 跨函数调用边 | | | |
如果您希望更加极端地限制每行长度(强制每行最多6-8个字符):
| 边类型 | 表示 | 颜色/样式 | 功能 |
|---|
| 控制流边 | | | |
| 块内数据边 | | | |
| 块间数据边 | | | |
| 内存依赖边 | | | |
| 跨函数调用边 | | | |
FIRM IR 的设计优势
- 1. 显式依赖关系:所有依赖(控制、数据、内存)都显式表示为边,优化器可以直接利用图结构
- 2. 自然循环表示:循环在图中形成环,循环头有专门的Phi节点,便于循环优化
- 3. 统一的SSA表示:所有值都是SSA形式,Phi节点机制天然支持SSA
- 4. 跨块数据流:允许数据依赖跨越基本块边界,更精确地表示数据流
- 5. 内存模型显式化:内存操作通过特殊依赖边序列化,支持复杂的内存优化
- 6. 函数边界清晰:每个函数有独立IRG,通过Call节点连接,支持过程间优化
实际编译器中的应用
FIRM 的图IR在编译器中提供了以下优势:
- 1. 优化算法简化:许多优化(如常量传播、死代码消除)可以表示为图变换
- 2. 分析效率高:数据流分析可以直接遍历图边,无需额外数据结构
- 3. 并行化支持:显式的依赖关系便于识别可并行执行的部分
- 4. 硬件映射直接:图结构可以更直接地映射到现代硬件的并行执行单元
与传统编译器的对比
| 特性 | 传统编译器 | FIRM 编译器 |
|---|
| 中间表示 | | |
| 优化方式 | | |
| 循环分析 | | |
| 数据流分析 | | |
| 并行化 | | |
结论
通过以上示例和分析,我们可以看到 FIRM 的图中间表示不仅能够准确表达程序语义,还通过显式的依赖边提供了丰富的结构信息。这种表示方法在保留传统控制流图直观性的同时,通过统一的数据依赖边和特殊的内存模型实现了更强大的分析和优化能力。
FIRM 的设计体现了现代编译器中间表示的发展趋势:
对于编译器开发者而言,理解 FIRM 的图IR设计有助于掌握现代编译器技术的关键概念;对于计算机科学学生而言,FIRM 提供了学习和研究编译器优化的绝佳平台。
随着计算机体系结构的发展和多核处理器的普及,图基中间表示的重要性将日益凸显。FIRM 作为这一领域的先驱,为未来的编译器设计提供了宝贵的经验和思路。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
