from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, avg, stddev, desc, split, explode, regexp_replace, trim, when, isnan
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.clustering import KMeans
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.evaluation import ClusteringEvaluator
import jieba
import re
from collections import Counter
# 初始化SparkSession
spark = SparkSession.builder \
.appName("DianpingFoodAnalysis") \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.adaptive.coalescePartitions.enabled", "true") \
.master("local[*]") \
.getOrCreate()
# 核心功能1:区域餐厅密度与消费水平分析
def analyze_regional_features(df):
regional_stats = df.groupBy("region") \
.agg(
count("*").alias("restaurant_count"),
avg("per_capita_consumption").alias("avg_consumption"),
stddev("per_capita_consumption").alias("consumption_std"),
avg("overall_rating").alias("avg_rating"),
avg("taste_rating").alias("avg_taste"),
avg("environment_rating").alias("avg_env"),
avg("service_rating").alias("avg_service")
) \
.withColumn("density_level",
when(col("restaurant_count") > 500, "高密度")
.when(col("restaurant_count") > 200, "中密度")
.otherwise("低密度")) \
.withColumn("consumption_level",
when(col("avg_consumption") > 150, "高端消费")
.when(col("avg_consumption") > 80, "中端消费")
.otherwise("大众消费")) \
.orderBy(desc("restaurant_count"))
density_analysis = regional_stats.select("region", "restaurant_count", "density_level",
"avg_consumption", "consumption_level", "avg_rating").collect()
result_list = []
for row in density_analysis:
result_list.append({
"region": row.region,
"count": row.restaurant_count,
"density": row.density_level,
"avg_cost": round(float(row.avg_consumption), 2),
"cost_level": row.consumption_level,
"avg_score": round(float(row.avg_rating), 2)
})
return result_list
# 核心功能2:高性价比餐厅识别与聚类分析
def analyze_cost_performance(df):
processed_df = df.filter(col("per_capita_consumption").isNotNull()) \
.filter(col("overall_rating").isNotNull()) \
.withColumn("review_count_num", col("review_count").cast("int")) \
.filter(col("review_count_num") > 50) \
.withColumn("cost_performance_ratio",
col("overall_rating") / (col("per_capita_consumption") / 50 + 1)) \
.withColumn("popularity_score",
col("overall_rating") * 0.4 + col("taste_rating") * 0.3 +
(col("review_count_num") / 1000) * 0.3)
assembler = VectorAssembler(
inputCols=["per_capita_consumption", "overall_rating", "review_count_num", "cost_performance_ratio"],
outputCol="features"
)
feature_df = assembler.transform(processed_df)
scaler = StandardScaler(inputCol="features", outputCol="scaled_features", withStd=True, withMean=True)
scaled_df = scaler.fit(feature_df).transform(feature_df)
kmeans = KMeans(k=4, seed=42, featuresCol="scaled_features", predictionCol="cluster")
model = kmeans.fit(scaled_df)
clustered_df = model.transform(scaled_df)
high_value_cluster = clustered_df.groupBy("cluster") \
.agg(avg("cost_performance_ratio").alias("avg_cp")) \
.orderBy(desc("avg_cp")).first()["cluster"]
high_value_restaurants = clustered_df.filter(col("cluster") == high_value_cluster) \
.select("shop_name", "region", "main_cuisine", "per_capita_consumption",
"overall_rating", "cost_performance_ratio") \
.orderBy(desc("cost_performance_ratio")) \
.limit(20).collect()
result = []
for r in high_value_restaurants:
result.append({
"name": r.shop_name,
"region": r.region,
"cuisine": r.main_cuisine,
"cost": float(r.per_capita_consumption),
"rating": float(r.overall_rating),
"cp_ratio": round(float(r.cost_performance_ratio), 3)
})
evaluator = ClusteringEvaluator(predictionCol="cluster", featuresCol="scaled_features")
silhouette_score = evaluator.evaluate(clustered_df)
return {"restaurants": result, "silhouette": silhouette_score, "cluster_centers": model.clusterCenters()}
# 核心功能3:推荐菜品的文本挖掘与热门趋势分析
def analyze_popular_dishes(df):
all_dishes_rdd = df.filter(col("recommended_dishes").isNotNull()) \
.select("recommended_dishes", "overall_rating", "review_count") \
.rdd.map(lambda row: (row.recommended_dishes, row.overall_rating, row.review_count))
def extract_dishes(text_rating_count):
text, rating, review_cnt = text_rating_count
if not text or text.strip() == "":
return []
text = str(text).replace("推荐菜:", "").replace("等", "")
dish_list = [d.strip() for d in text.split("、") if len(d.strip()) > 1 and len(d.strip()) < 15]
results = []
for dish in dish_list:
words = list(jieba.cut(dish))
filtered_words = [w for w in words if len(w) > 1 and not w.isdigit()]
clean_dish = "".join(filtered_words)
if len(clean_dish) >= 2:
weight = float(rating) * 0.6 + (float(review_cnt) / 1000) * 0.4 if review_cnt else float(rating) * 0.6
results.append((clean_dish, (1, weight, float(rating))))
return results
dish_pairs = all_dishes_rdd.flatMap(extract_dishes)
dish_aggregated = dish_pairs.reduceByKey(lambda a, b: (a[0]+b[0], a[1]+b[1], a[2]+b[2]))
dish_stats = dish_aggregated.map(lambda x: (x[0], x[1][0], x[1][1]/x[1][0], x[1][2]/x[1][0])) \
.filter(lambda x: x[1] >= 5) \
.sortBy(lambda x: x[2], ascending=False)
top_dishes = dish_stats.take(30)
dish_combinations = all_dishes_rdd.flatMap(lambda x: [(tuple(sorted([a.strip(), b.strip()])), 1)
for a in x[0].split("、") for b in x[0].split("、")
if a.strip() != b.strip() and len(a.strip()) > 1 and len(b.strip()) > 1][:5]) \
.reduceByKey(lambda a, b: a+b) \
.filter(lambda x: x[1] >= 3) \
.sortBy(lambda x: x[1], ascending=False) \
.take(15)
final_dish_list = []
for dish, count, weighted_score, avg_rating in top_dishes:
final_dish_list.append({
"dish_name": dish,
"mention_count": count,
"weighted_score": round(weighted_score, 2),
"avg_rating": round(avg_rating, 2)
})
combo_list = [{"pair": list(combo), "co_occurrence": count} for combo, count in dish_combinations]
return {"hot_dishes": final_dish_list, "common_combinations": combo_list}



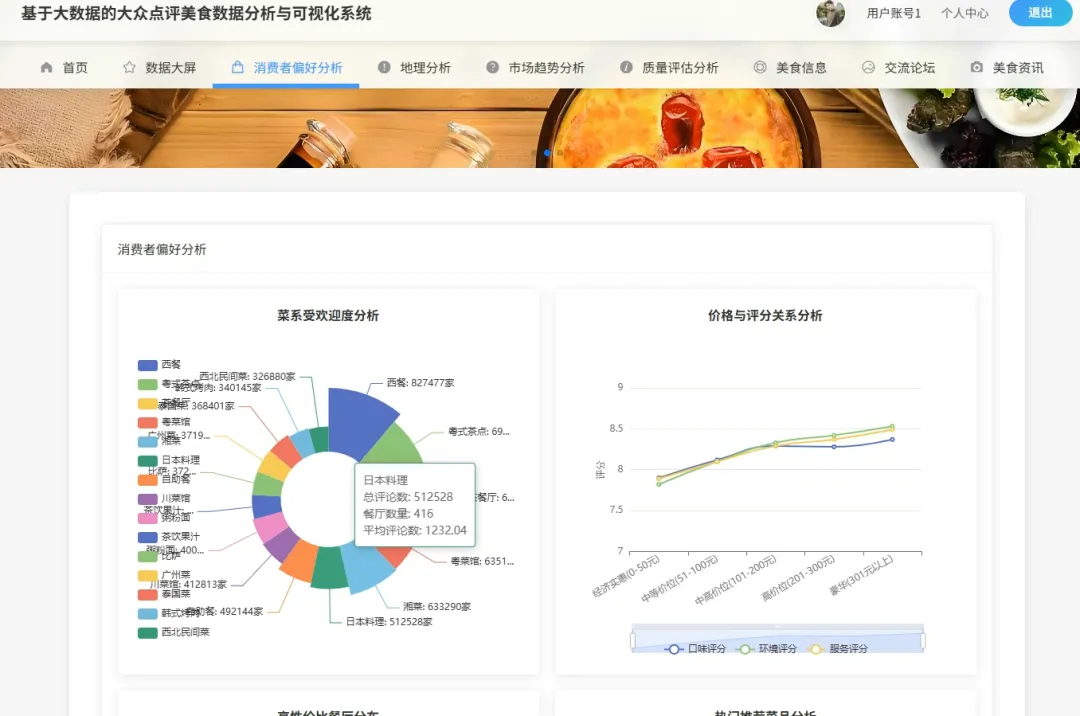
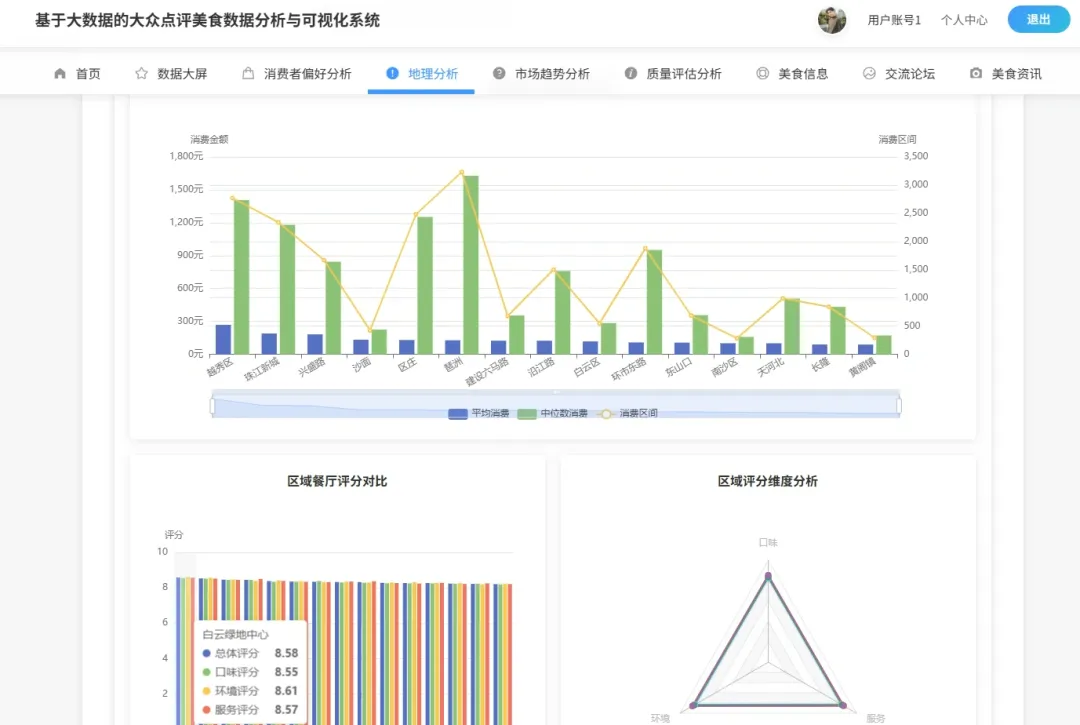






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
