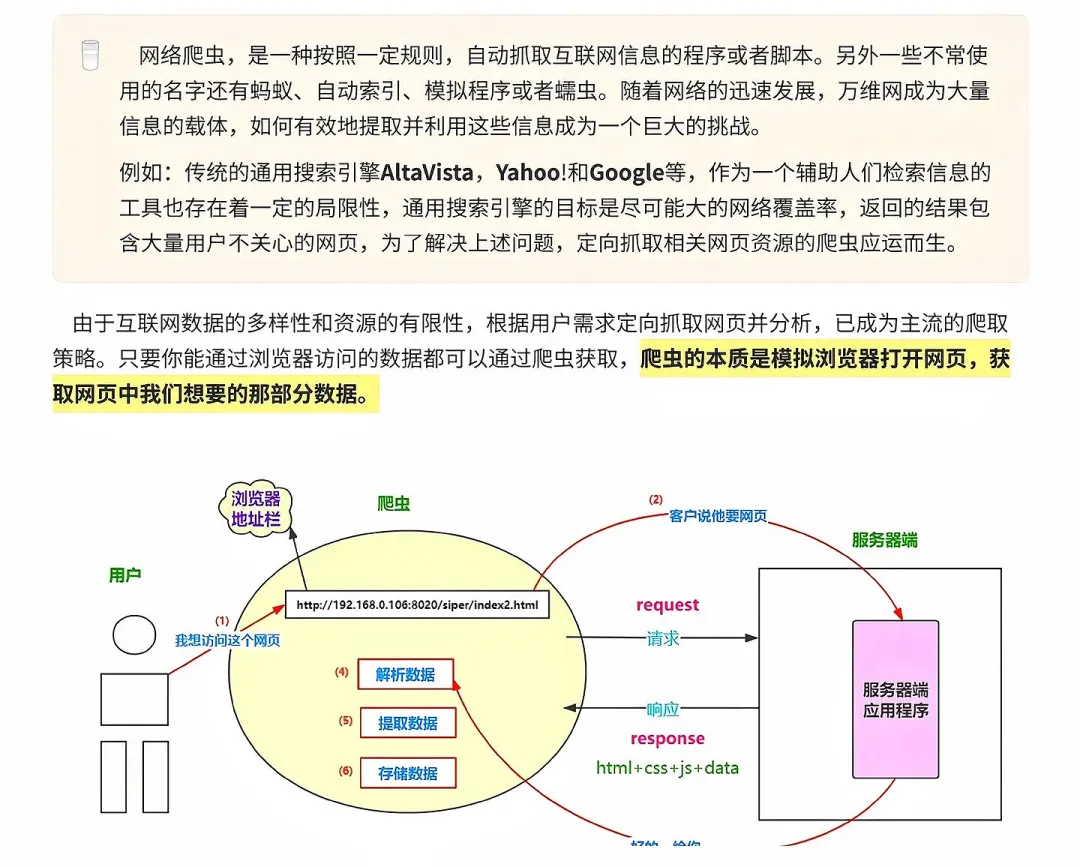









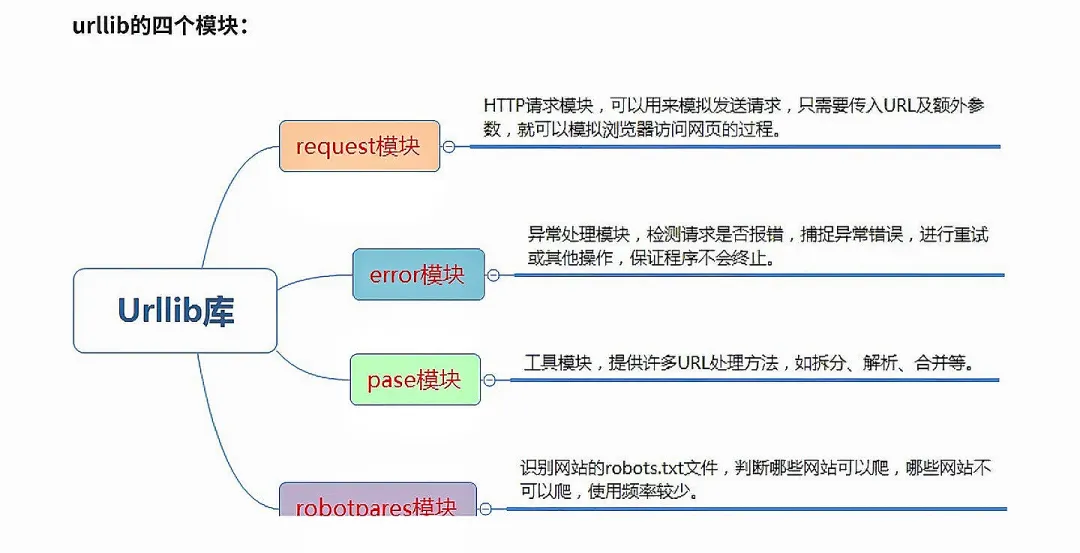

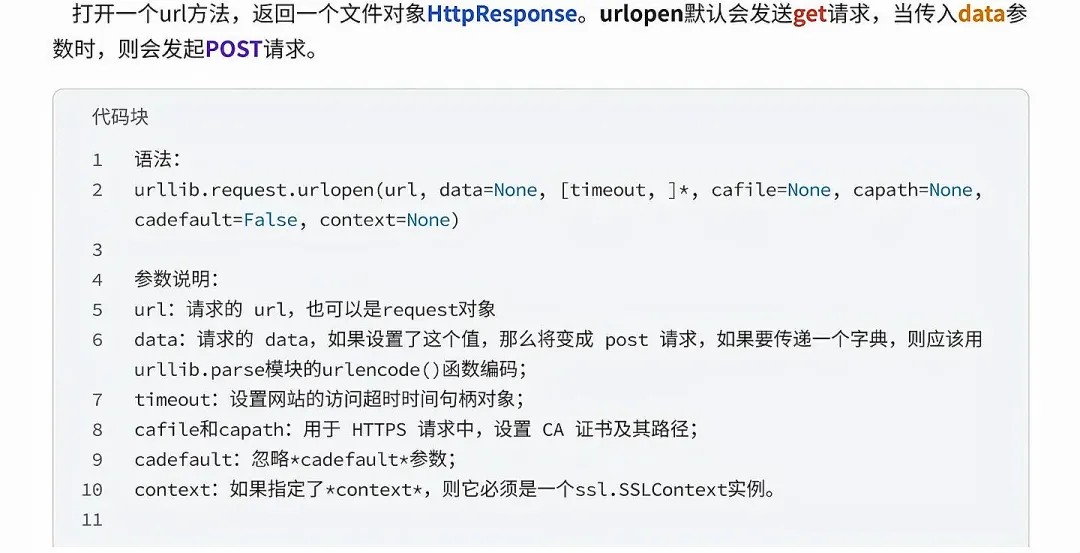



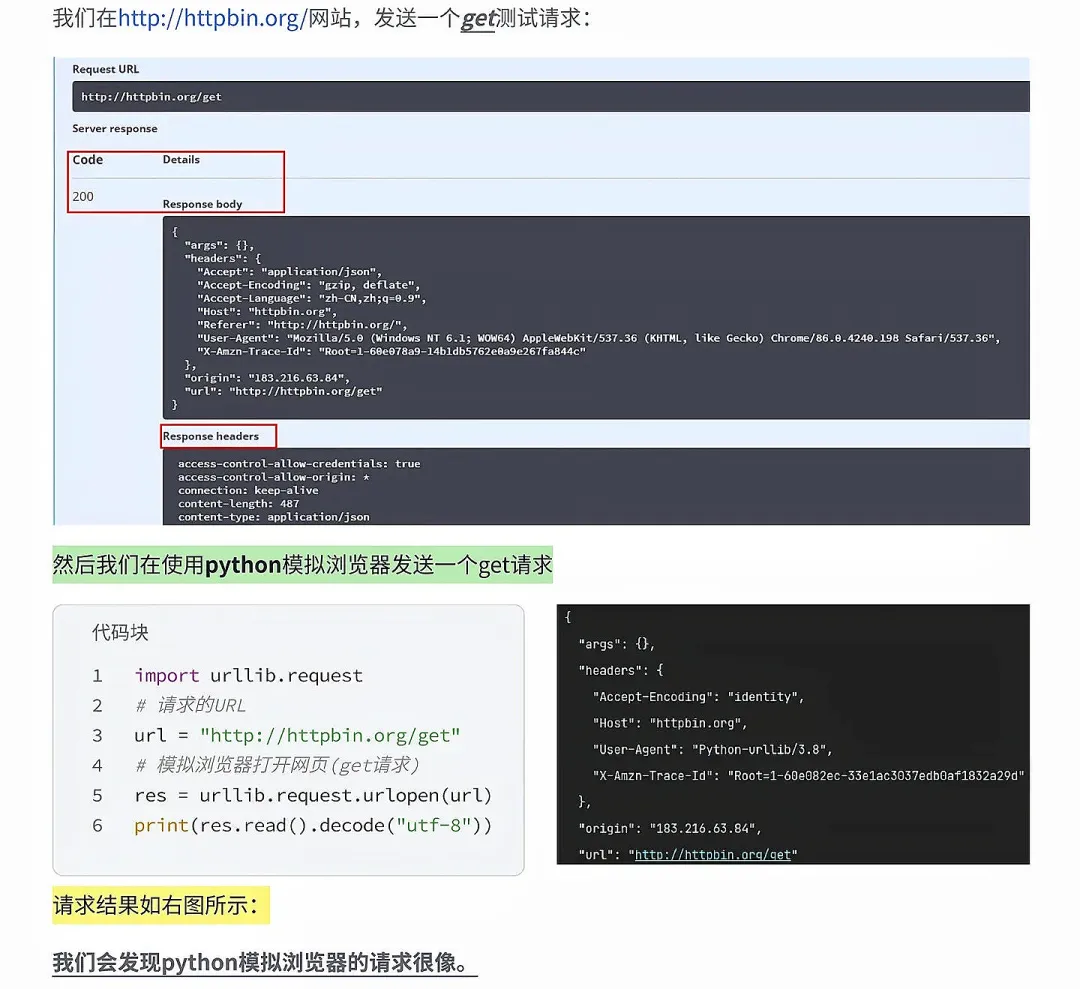




本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 迪拜电话卡攻略运营商+充值代码+避坑指南,落地直接用
- 建议学Python的都去B站死磕这几个老师!
- 效果甲方 | 树帆教育、核桃编程、集集星球、重庆九邻、原驰蜡象教育、碧莲盛医疗美容、微风、苏州易尔云、速通互联
- 上班摸鱼写了篇用Python自动化处理Excel
- Python 反复就这几页 寒假背呀直接起飞!
- 新手必学!Python数据预处理的4个重要步骤
- Python数据分析:英国电商销售数据实战
- 看漫画学Python,开心学编程
- 线上会议 ▏AI赋能,不会编程的期货投资者,也能用上量化交易!今晚8点,准时开播!
- Python配色党狂喜!这款颜色查询拾取工具直接封神
