本文讲述在 AI 编程时代,通过 SDD解决上下文腐烂、审查瘫痪、维护断层三大工程失序问题,并提供一套轻量、可落地的人机协作 SOP。
TL;DR (太长不看版)
痛点 1:上下文腐烂(Context Decay)。随着对话进行,Feature 开发容易跑偏。超长上下文导致大模型注意力分散,代码质量直线下降。或者new chat之后丢失原来的上下文,恢复起来费时费力。痛点 2:审查瘫痪(Review Paralysis)。这是 AI 时代的各种“鬼故事”之源。AI 能在几分钟内生成上万行代码。面对这种量级的 Diff,人类根本无法逐行 Review,导致“心里没底”不敢合并,或者盲目合并后埋下巨大隐患。痛点 3:维护断层(Maintenance Gap)。两个月后回来修 Bug,面对全是 AI 生成的陌生代码(且没有文档),不仅人看不懂,新的 AI 也因为缺乏背景知识而无法接手,导致“能跑但不敢动”。核心:SDD (Spec-Driven Development) 不是传统文档的复辟,而是Vibe Coding的“存档点” (Save Point)。价值:它用文档锚点锁定了上下文,让你在 "Rerolling over debugging"(重试优于调试)时,拥有稳定的“种子”。只有 Spec 稳了,代码才能真正成为“可抛弃的消耗品”根据任务复杂度,你可以灵活选择“重”度:
- 零侵入 (Zero Friction):无需安装 CLI,无需配置环境,新建一个
.md即可开始。 - 无痛回滚 (No Lock-in):随时可以停止使用。留下的文档是可读的“资产”,而不是难以维护的“技术债”。
- 操作:仅需一份简要的
Task_Spec作为上下文锚点,即可开始极速 Reroll。
- 适用:多人协作、复杂业务逻辑、需要长期维护的项目。
- 特点:完整的
Requirements->Interface->Implementation链路,确保 AI 在长周期内不漂移。
目标:30 分钟跑通一次“文档 → 实现 → 复核 → 留痕”,产出 docs/specs/feature-xxx/ 。
- 0–3min(Initialization):给 AI 一份“家规/约束/口径”,让它复述确认。
- 3–10min(Research):给大模型足够的上下文和清晰的需求,让他出spec文档(In/Out + AC + 约束),你 Sign-off。
- 10–15min(Plan):让大模型按照spec文档去规划步骤并且更新到文档中。
- 15–25min(Execute):按spec文档的描述分步写代码 + 最小单测。
- 25–30min(Review):New Chat/换模型审查 Spec文档 + Diff,然后人工review此次改动并且上线。
先把闭环跑通,再逐步把门禁、规则库、决策日志升级到团队级(Full 版)。
如果你希望先“照着跑一次完整闭环”(Spec → 实现 → 测试 → 交付留痕),可以先做一个开源项目的小练习:
- 案例:Halo 新增
SystemConfig 分组列表 API(只返回 group name)+ 单测 + AI_CHANGELOG
大模型与 AI 编程工具进入了快速迭代期:IDE、插件、模型能力每天都在刷新上限。表面上看是生产力爆发,但在真实的团队工程里,我们正在同时遭遇三类“隐性成本”,它们会抵消甚至吞噬工具红利。
团队把大量注意力投入在“用哪个模型/哪个 IDE 更强”的选择与配置上。短期看每个人都更快了,但由于缺少统一的输入标准与产出约束:
- 同一需求被不同人用不同工具实现,产物难以合并、难以维护
评测往往聚焦“写得快不快、能不能一把梭”,但工程需要回答的是:
- 需求变更时是否敢改、改得动(是否可追溯、可验证) 如果 AI 只是更快地产生“一次性代码”或“幻觉代码”,组织获得的不是效率,而是技术债累积速度。
不少人仍把 AI 当成“问答框”:
这种“补丁式/填空式”使用,缺少流程、缺少门禁、缺少协作协议,团队协作时很难形成稳定产能。
结论:我们缺的不是更强的模型,而是一套新的“AI 工程方法”
工具已经进入 AI 时代,但研发流程与协作方式仍停留在“人肉编码”的惯性里。要让 AI 真正成为可规模化的生产力,需要把个人技巧升级为团队 SOP。
我自己的真实 case:上个月用模型做了一个复杂功能(代码量大,经历多轮优化与 bugfix)并上线。后续出现几个小 bug、产品追加了几个新点;如果不用 SDD,就得翻提交+人工回忆来重建上下文,既慢也不精确;如果用 SDD,只要把“新需求文档 + 旧实施文档/决策留痕”交给模型,通常 10 分钟内就能启动下一轮迭代。
接下来要介绍的 SDD(Spec-Driven Development,规范驱动开发),核心目标很明确:让“文档/规范”成为任务的唯一事实来源,让 AI 围绕规范执行与互审,让人回到设计、决策与验收的位置。
2. 核心理念:什么是 SDD(Spec-Driven Development)?
💡极客时刻:重新定义 .md
曾有人提到过一个绝妙的笑话:以前编程语言都是从各种角度设计给人的,什么各种复杂的面向对象、类型系统、语法设计⋯很低效,虽然对于AI来说不在话下。下一个编程语言应该是直接给AI设计的,让AI可以高效创作。我建议命名为Machine Done(机器完成),后缀名都想好了,就叫.md。
这不仅仅是个段子,这正是 SDD 的本质。
在真正的 AI 原生语言出现之前,Markdown 就是我们将意图传递给硅基大脑的最佳中间语言(Intermediate Representation)。它既是人类的可读文档,更是机器的执行指令。写下 .md 的那一刻,就意味着:Human Designed, Machine Done.
SDD 的关键不在“写更多文档”,而在于把 Spec(Specification) 当作研发过程的“契约”。在 AI 时代,编程的重心从“人直接写代码”转向“人定义规范,AI 按规范实现”。
2.1 核心定义:文档是 AI 之间的“通信协议”
需要纠正一个常见误区:文档不只是写给人看的,它同样是写给 AI 看的。在 SDD 模式下,Spec 扮演一种“中间表示(IR)”:
- 另一 AI(或另一轮会话/模型)以 Spec 为准绳进行 Review
- 通过“以 Spec 为准”的闭环,减少口头沟通失真与上下文丢失
换句话说:Spec 是团队里人和 AI 的共同语言,也是跨角色协作的统一输入。
1) 解决上下文丢失:用 Spec 锚定任务(Context Anchoring)
大模型对话天然存在“记忆衰减、注意力丢失、上下文腐烂、重点漂移、换会话丢上下文”等问题。Spec 作为稳定锚点,使得:
- 任务可在任意时间恢复(把 Spec 交给 AI 即可重建上下文)
- 沟通更可追溯(争议回到 Spec,而不是回到聊天记录)
2) 不需要人类从零写文档:AI 起草,人类 Review / Sign-off
SDD 的典型操作流不是“人从头写一套文档”,而是:
- 人作为仲裁者 Review,补齐边界与验收标准,并最终签字确认
- 只有 Spec 通过,才进入编码与交付核心变化是:人把精力放在“正确性与决策”,而不是“打字与搬运”。
3) 角色边界清晰:不同角色对齐在不同层级的 Spec
SDD 不是让所有人都写同一种文档,而是让协作关系“各看各的关键点”:
- PM/业务:
Requirement Spec(目标、范围、验收) - 前后端/客户端:
Interface Spec(字段、错误码、示例、契约) - QA:
Test Spec(用例覆盖、边界、回归策略) - 架构/核心研发:
Implementation/Architecture Spec(实现路径、取舍、风险) 大家在各自关心的层面完成对齐,最终通过 Spec 链条咬合成闭环。
4) 真正解耦模型与工具:Spec 让产能可迁移
当 Spec 足够清晰、约束足够明确时:
- 模型/工具可以替换(写草稿、重构、补测试、做 Review 可用不同模型)
- 组织资产沉淀在 Spec 与规则里,而不是沉淀在某个工具的“私有用法”里
5) 信心锚点 (Confidence Anchor):消除“失控感”
AI 编程最大的副作用是“失控感”。当 AI 生成了你读不完的代码时,SDD 文档是你唯一能完全掌控的真理。它让 Review 从“在海量代码中找 Bug”变成了“检查代码是否兑现了文档承诺”。
结论:SDD 的核心不是“文档本身”,而是“以规范为中心的协作协议 + 可验证门禁”,从而把 AI 的能力变成组织可复制的工程能力。
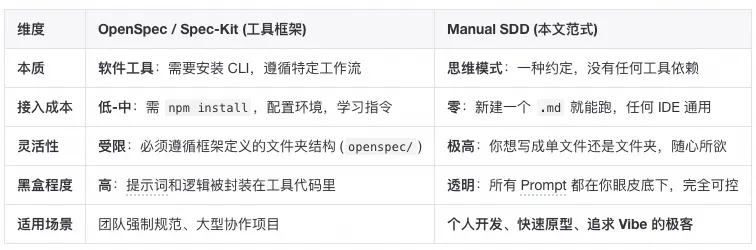
💡 核心辨析:为什么不直接用 OpenSpec 或 Spec-Kit?
市面上已经出现了如OpenSpec、GitHub Spec Kit等优秀的 SDD 自动化工具。它们很棒,但对于许多开发者来说,它们可能“太重了”或者“太死板”。
本文提出的Manual SDD 范式与这些工具框架的核心区别在于:
结论:OpenSpec 是把 SDD 变成了流程,而本文是把 SDD 变成了习惯。在 Vibe Coding 中,我们更倾向于“习惯”,因为习惯没有运行时开销。
3. 程序员实操 SOP:RIPER 工作流 (The RIPER Cycle)
"If fixing takes too long, regenerate." (如果修复太慢,就重生成) —— Manifesto for Vibe Coding但重生成的前提是:Spec 是准确的。否则重生成就是抽奖。
在这个单元,我们将深入“单兵作战”的细节。
很多程序员抱怨 AI 写的代码不能用,本质原因是 跳过了思考,直接进入了执行。为了解决这个问题,我们将传统的编码过程重构为 Initialization + RIPER + LAFR 全链路模型。
这不仅仅是写代码,这是一场精心编排的 人机协作 (Human-AI Symbiosis)。
初始化 (Initialization) —— 装载大脑
“在开始干活前,先告诉 AI 它是谁,以及家规和历史信息是什么。”不要上来就扔需求。大模型就像一个刚入职的天才实习生,你需要先给它做 Onboarding。
1. 装载协议:这是 SDD 的“操作系统”。如果你有没有个人偏好,或者以前没有用过大模型,请先发送以下指令,让 AI 进入“文档驱动模式”:
⚡️ 通用启动指令 (System Prompt)
# RoleYou are a Senior Engineer following the "Spec-Driven Development" protocol.# Workflow Rules1. **Context First**: Before coding, ALWAYS check if a relevant Spec file exists in `docs/`.2. **No Hallucinations**: If the user request contradicts the Spec, STOP and ask for clarification.3. **Update Loop**: If you change the code logic, suggest updates to the corresponding Spec file immediately.# File Structure Strategy- Use `01_requirements.md` for User Stories.- Use `02_interface.md` for Tech Stack & Data Structures.- Use `03_implementation.md` for detailed Logic/Prompts.
2. 加载偏好(可选):发送你的Prompt_Skill.md或.cursorrules的个性化部分。
- 告诉它你的“私有家规”(如:“禁止使用 Lombok”、“所有金额计算使用 BigDecimal”)。
- 注:如果没有特殊喜好,这一步可跳过,直接复用通用的启动指令即可。
3. 注入记忆:把项目里的 README.md和某些功能的过往的历史信息也提供给大模型。
- AI 是否确认收到了上下文?(让它简单复述一遍主要约束和对此项目的总结)
The Core Loop: RIPER Model
Step 1: Research (调研与意图锁定)
“不要急着给方案,先搞清楚到底要解决什么问题。”
很多时候,我们的需求描述是模糊的。这个阶段的核心是“反向复述”。
- 输入:你模糊的想法、Bug 的现象、或者一段杂乱的聊天记录。
- 让 AI 阅读并复述:指令它 —— “请阅读上述需求,用你自己的话复述一遍,并指出其中不清晰的地方。”
- 澄清边界:让 AI 告诉你,这个需求涉及哪些业务领域?需要参考哪些现有的代码逻辑?
- 产出:清晰的 Requirement Spec (需求意图)。
- AI 指出的“模糊点”是否都已解答?AI是不是已经完全明白了需求意图和项目结构?
Step 2: Innovate (设计与推演)
“这是体现架构师价值的环节。寻找最优解,而不是第一个想到的解。”这一步严禁写代码,而是要进行“审讯游戏 (The Interrogation Game)”。
- 生成草案:让 AI 根据需求整理一份《技术实施草案》 (HLD)。
- 你要问它:“除了这个方案,还有没有更好的?”“这样做的坏处是什么?”
- 逼它问你:指令它 —— “如果你对现有业务逻辑或代码细节有任何不确定的地方,请立刻向我提问,不要自己瞎猜(Hallucinate)。”
- 引入外部智慧:把你同事的建议,或者你在其他项目的经验喂给它作为补充。
💡 Pro Tip:去拟人化交互 (De-anthropomorphism)在向 AI 索要方案时,千万不要用“你” (You)。记住:不要问它“怎么看”,要问它“它模拟的那个专家角色”怎么看。例如:顶尖专家和学者将会如何修改这个bug;或者顶尖程序员和架构师将如何设计这个功能等。- 产出:Design Spec(设计/技术规格书),包含核心技术选型、Pros/Cons 分析。
- 你是否对这个设计方案进行了 review和Sign-off(批准)?
Step 3: Plan (规划与契约)
“从战略下沉到战术。不仅要告诉它造什么房子,还要告诉它每一块砖怎么砌。”文档即协议。我们要把模糊的 Design 变成精确的 Implementation Plan。
- Mock 数据:在写代码前,先定义好接口的 Request/Response 示例。
2. 认知对齐:再次进行 Review。问它:“为什么要在 Service 层做这个校验,而不是 Controller 层?”确保它不是在套模板,而是真的理解了逻辑。- 产出:Implementation Spec (详细实施/接口文档)。
- 实施计划是否拆解到了“原子级”任务,如果换一个大模型是否可以100%完美实施?
Step 4: Execute (执行与编码)
“你不是在看戏,你是在跟 AI 结对编程 (Pair Programming)。”
1. 分步指令:不要试图一次生成 500 行代码。按照 Plan 的步骤,一步一步来。- “好的,先完成 Step 1 的数据库 Schema 变更。”
- “现在进行 Step 2,实现 Service 层逻辑。”
2. 实时自检(Step-by-Step Check):每做完一步,让 AI 自己总结:“我完成了什么,这是否符合 Spec 的要求?”3. 人工干预:如果发现它跑偏了,立刻暂停。不要在原来的基础上打补丁,而是回滚这一步,修正 Prompt 后重试。- Lint Check:生成的代码必须通过 Linter 检查(无语法错误、无未使用的变量)。
- Compile Check:代码必须能编译通过。如果跑不通,严禁进入下一步。
Step 5: Review (验收与对齐)
“让一个 AI 去检查另一个 AI 的作业。”
“这是对抗‘代码通胀’的唯一防线。当 Diff 达到几千行时,不要试图人肉 Review,要相信 Spec 的验证能力。”
1. New Chat / New Model:实施完成后,开启一个新的对话窗口,甚至换一个模型(比如用 Claude Review GPT 的代码)。2. 法医式审查:把 Spec 文档 和 Git Diff 喂给新 AI。- 指令:“请基于这份 Spec 审查这次代码变更。寻找潜在 Bug、逻辑漏洞或不符合规范的地方。”
3. 迭代修正:把审查报告扔回给负责写的 AI,让它解释并修正。如此循环几次,直到“评审官”满意。4. 旁观者视角 (The Spectator Stance):不要问 AI:“你觉得刚才写的代码对吗?”(它通常会说“是对的”来讨好你)。要这样问:“如果请 Google 的 Principal Engineer 来做 Code Review,他会指出这段代码的哪些隐患?”通过引入第三方权威视角,可以有效打破模型的“顺从性幻觉”,强制它开启高强度的批判性思维。- 产出:单元测试、Review 报告、最终交付代码。
- Automated Tests:自动化测试必须全绿(覆盖门槛按项目等级设定,并在 CI/规则库中固化)。
- Interface Contract:新代码的接口响应必须与
02_interface.md定义的 JSON Schema 完全一致(使用工具自动比对)。 - 未过门禁 = 0 交付:任何一项失败,直接退回 Step 4,严禁合并代码。
“遇到 Bug 时,不要直接改代码。Bug 的本质是‘代码’与‘文档’的对齐失败。”当生产环境报错或测试不通过时,请严格执行 L.A.F.R. 流程:
1. Locate (定位):构建“案发现场”。投喂黄金三角:Spec 文档 + 相关代码 + 报错日志。2. Analyze (分析):让 AI 判决,是 “执行层错误”(代码写错了)还是 “设计层错误”(文档没写对)。- 如果是文档错 -> 必须先改文档,再重新生成代码。
- 在文档上打补丁:“⚠️ [FIX] 此处逻辑曾导致死锁,已修正为...”
4. 文档解剖学:端到端闭环实战(The Full Loop)
为了让“文档 = 协议”不再停留在概念层,这一章用一个贯穿示例(用户积分系统 - 签到功能)展示:一套最小但完整的 Spec 链条应该长什么样、写到什么粒度算合格、以及这些文档如何直接驱动 AI 产出与团队并行协作。
本章的核心原则:
- Spec 不是“说明书”,而是“可执行指令集”:能直接喂给 AI 生成代码/测试/评审。
- 每份 Spec 都要“可验收”:写清楚验收标准与边界,减少口头解释空间。
- 一份 Spec 对应一个 Owner 与一次 Sign-off:否则文档会快速漂移(Spec Drift)。
4.1 推荐目录结构(Documentation Engineering)
docs/├── specs/│ ├── feature-001-checkin/ # 一个 feature 一个目录│ │ ├── 00_context.md # 可选:一次性上下文(业务背景/现状/约束)│ │ ├── 01_requirement.md # 需求意图(PM/业务/Owner)│ │ ├── 02_interface.md # 接口契约(前后端/客户端共同协议)│ │ ├── 03_implementation.md # 实施细节(AI Coder 执行指令)│ │ └── 04_test_spec.md # 测试策略与用例(QA/Test Agent)├── decisions/│ ├── AI_CHANGELOG.md # 决策与变更日志(审计/追溯)│ └── ADR-xxxx.md # 可选:重大架构决策记录├── skills/│ └── SKILL.md # 团队规则库/“家规”(防复发)└── logs/ └── ai-review-reports/ # 可选:每次 Review 报告归档
约定建议(便于团队规模化):
- 命名稳定:
01/02/03/04 固定顺序,降低沟通成本。 - 一个 feature 一套文档:不要把多个需求混在一个 Spec 里,避免上下文污染。
- 文档也要版本意识:重大变更通过 PR 更新 Spec,让“讨论/决策/结果”都可追溯。
下面给出每类 Spec 的三件事:
- 门禁(Definition of Done)(写到什么程度才允许进入下一步/合并代码)
A. Requirement Spec(需求规格)——意图层(写给人,也写给 AI)
定位:把“想要什么”写成可验收的契约,避免实现阶段反复扯皮。主要读者:PM/业务 Owner、研发 TL、QA、AI(用于复述与生成后续文档)。
最小模板:01_requirement.md
- 范围(In Scope / Out of Scope):明确不做什么
- 验收标准(Acceptance Criteria, AC):必须可验证
- 约束(Constraints):性能/安全/兼容/依赖系统/灰度要求
- 风险与灰度(Risks & Rollout):上线策略、回滚预案(如适用)
示例片段(签到功能)
## Background为了提升 DAU 与留存,引入“每日签到得积分”,积分可用于兑换权益。## In/Out- In:每日签到、幂等、防重复、查询签到状态、积分发放- Out:积分商城兑换、积分过期策略(本期不做)## Acceptance Criteria- AC1:同一用户同一天只能签到一次,重复请求返回“已签到”且不重复发放积分- AC2:返回结果需包含:是否签到、签到时间、当次获得积分、当前总积分- AC3:接口 P95 < 200ms(依赖现有积分查询能力)- AC4:出现异常时必须可追溯(含必要审计字段)
门禁(写完才允许进入接口/实施)
- AC 至少覆盖:主流程 + 重复请求/幂等 + 至少 2 个失败场景
- In/Out 明确,避免“做到一半发现还要做 X”
- 关键约束写清楚(性能/安全/灰度/审计),否则后面补救成本更高
B. Interface Spec(接口契约)——协议层(跨角色并行的关键)
定位:这是前后端/客户端/测试并行启动的“唯一真相”。主要读者:前端/客户端(生成 types/mock)、后端(实现约束)、QA(生成用例/自动化)、AI(按契约写代码)。
最小模板:02_interface.md
- Request:字段表/Schema(含必填、类型、枚举、校验)
- Response:字段表/Schema(明确成功/失败结构)
- Examples:成功/失败示例(用于 mock 与契约测试)
## API: POST /api/v1/points/check-inAuth: Bearer TokenIdempotency: 同一 userId + 同一 date 必须幂等### Request- date (string, optional): YYYY-MM-DD,不传则默认当天(以服务端时区为准)### Response (Success)- checkedIn (boolean)- checkedInAt (string, ISO8601, nullable)- pointsEarned (int): 本次发放积分(已签到则为 0)- totalPoints (int)### Error Codes- INVALID_DATE:date 格式非法- UNAUTHORIZED:未登录/Token 无效- INTERNAL_ERROR:服务端异常(需返回 requestId)### ExamplesSuccess(first time):{ "checkedIn": true, "checkedInAt": "2026-01-02T09:00:00Z", "pointsEarned": 5, "totalPoints": 120 }Success (already checked-in):{ "checkedIn": true, "checkedInAt": "2026-01-02T09:00:00Z", "pointsEarned": 0, "totalPoints": 120 }
门禁(写完才允许前端/测试并行、后端进入实施)
- 必须有成功 + 已签到(幂等) + 至少 1 个失败示例
- Error Codes 写清“触发条件”,避免后续实现随意发挥
- 字段定义要可直接生成类型(TypeScript/Java DTO),否则契约无法落地
C. Implementation Spec(实施细节)——执行层(给 AI Coder 的“施工图”)
定位:把“怎么改”写成可执行计划,控制 AI 的改动范围与顺序。主要读者:实现负责人、AI Coder、Reviewer。
最小模板:03_implementation.md
- 目标复述:用 3~5 行复述本次要实现什么(对齐)
- 分步执行计划:Step 1/2/3…(每步可独立验收)
示例片段(实现计划)
## File Changes- backend/src/main/java/.../CheckInController.java- backend/src/main/java/.../PointsService.java- backend/src/main/java/.../PointsRepository.java- backend/src/test/java/.../PointsServiceTest.java## Core Logic(pseudo)1) parse date(default today) -> validate format2) start tx3) try insert checkin_record(user_id, date) with unique(user_id, date) - if conflict -> return already checked-in(pointsEarned=0)4) if inserted -> add points(+5)and write ledger/audit5) commit6) query totalPoints -> return response## Execution Plan- Step1: 增加/确认 checkin_record 唯一约束与实体映射- Step2: 实现 PointsService.checkIn(date) 幂等逻辑 + 错误码映射- Step3: Controller 层对齐接口契约(02_interface.md)- Step4: 补单测(首次签到/重复签到/非法日期)
门禁(写完才允许进入编码)
D. Test Spec(测试策略)——验证层(把验收落到可执行用例)
定位:把 AC 与接口契约转成测试策略与用例清单,避免“上线后才发现漏测”。主要读者:QA、研发(补单测/集成测试)、AI Test Agent(生成用例/脚本)。
最小模板:04_test_spec.md
- 测试范围:覆盖哪些层(Service/Controller/契约/集成)
- 用例列表:编号 + 场景 + 期望结果(对齐 AC/Error Codes)
- 数据准备:前置数据、时间/时区假设、Mock 依赖
## Strategy- Service 层:单测覆盖幂等与错误码- Controller 层:契约测试校验 JSON 字段与类型(对齐 02_interface.md)## Test Cases- TC1 首次签到:返回 checkedIn=true, pointsEarned=5,totalPoints 增加- TC2 重复签到:pointsEarned=0,总积分不变,checkedInAt 不变化- TC3 非法 date:返回 INVALID_DATE- TC4 并发重复请求:最多一次发放积分(验证唯一约束/幂等)
门禁(写完才允许合并/上线)
- 用例必须覆盖:AC 中的关键路径 + Error Codes + 并发/幂等
E. 交付与归档模板(让“可追溯”成为默认)
1) Implementation Summary(交付小结,建议进入 PR 描述)
- Feature:实现每日签到得积分(含幂等)- Changes:新增 checkin_record 唯一约束;新增/修改 PointsService.checkIn;补充单测- Risks:时区口径(服务端时间为准);并发下依赖唯一约束兜底- Rollback:开关关闭签到入口;保留数据表但停止写入- Related Specs:docs/specs/feature-001-checkin/*
2) AI_CHANGELOG.md(决策日志:记录“为什么这么改”)
2026-01-02 feature-001-checkin- Decision:幂等通过数据库唯一约束实现,而不是 Redis 计数- Reason:降低一致性风险与依赖复杂度;数据库作为最终一致性来源- Risk:高并发写入压力;需关注索引与事务耗时
在你把 Spec 丢给 AI 之前,先自检 2 分钟:
- Requirement:AC 是否“可测试”、是否包含边界与失败?
- Interface:是否有幂等/错误码/示例?前端能否直接做 mock?
- Implementation:是否写清文件路径、步骤、事务/并发处理与回滚?
- Test:是否覆盖幂等与错误码?是否写清数据准备与回归点?做到以上四点,章节 3 的 RIPER 执行才会真正稳定;否则再强的模型也会在“缺口处自由发挥”。
5. 团队协作 SOP:构建“文档即接口”的通信协议
如果说上一章解决的是“如何让 AI 帮你写好代码”,那么这一章要解决的是“如何让 AI 帮团队消除沟通噪音”。
现状是分裂的:我们每个人手里都有了核武器(大模型),但团队协作还在用冷兵器(开会、口述、聊天记录)。我们必须构建一套新的协作 SOP,核心理念只有一条:人与人的沟通只负责确认意图,AI 与 AI 的沟通负责传递细节。
5.1 理想国:全链路的“去噪音化” (The Ideal Flow)
虽然完全实现尚需时日,但我们应以此为北极星:
- 前线人员不再扔一堆杂乱的聊天记录给产品,而是先让 AI 总结:“把这段客户沟通整理成结构化的需求草案,去除废话,保留核心痛点。”
- 产品经理将草案喂给 AI,生成标准化的 PRD(需求规格书)。
- 价值:虽然开发人员知道需求是什么,但大模型不知道。PM 用 AI 生成的文档,本质上是在为开发的 AI 准备“精准的 Prompt”。
- Team Leader 维护一份
Team_Context.md(组员负责的方向、当前负荷、技术栈偏好)。 - 让 AI 辅助决策:“基于这个需求文档和团队现状,建议分配给谁?有什么技术风险?”
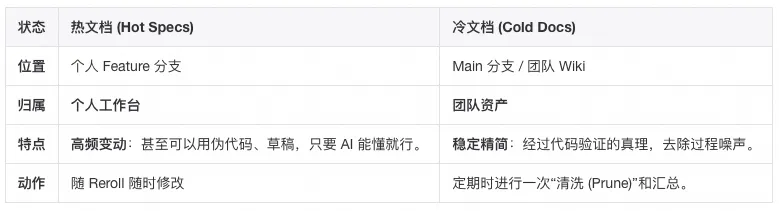
在实战中,我们发现强行要求“文档与代码实时完美同步”会严重拖慢开发节奏。因此,我们总结出了“双态管理”策略,将文档区分为“热数据”与“冷数据”:
💡 经验之谈:
- 开发时:不要有心理负担,把 Spec 当作你的草稿纸。
- 合并时:就像你会 Squash 那些琐碎的 Git Commit 一样,你也应该Squash 你的文档,只把最终生效的逻辑同步给团队。
- 最终这些文档会合并上传并沉淀在你团队的知识库,成为团队宝贵的资产。
5.3 落地现实:技术铁三角的协作闭环
(The Pragmatic Protocol)
鉴于业务侧的不确定性,我们可以优先在后端、前端/客户端、测试之间建立强制性的 Spec 协作流。
责任分工(建议,避免“文档写了没人维护”)
01_requirement.md:Owner=需求/产品或需求提出人;Sign-off=业务 Owner + TL。02_interface.md:Owner=接口提供方(通常后端);Sign-off=接口消费者(前端/客户端)+ QA。03_implementation.md:Owner=实现负责人;Sign-off=TL/核心评审人。04_test_spec.md:Owner=QA(或测试 Owner);Sign-off=实现负责人 + QA。
阶段一:后端作为“定义者” (Backend as Definer)
后端开发不再是默默写代码,而是先产出“契约”。
- 动作:后端在写业务逻辑代码前,先让 AI 按照章节2的流程生成技术文档、实施文档和
02_interface.md(接口文档) 。 - 人类介入:Leader和同事只需要 Review 这些文档。文档通过,等于架构设计通过。
阶段二:并行开发 (Parallel Execution)
这是效率提升最显著的环节。传统的“前端等后端接口”模式被彻底打破。
- 输入:拿到后端发来的
02_interface.md。
1. “阅读这份接口文档,为我生成 TypeScript 类型定义 (Interface/Types)。”2. “基于文档生成一个 Mock Server 的代码,并制造 5 组边缘情况的假数据。”- 结果:在后端一行代码没写的时候,前端已经基于 AI 生成的“完美模拟器”完成了 UI 开发和逻辑联调。
- 输入:拿到
01_requirement.md (需求) + 02_interface.md (接口)。
1. “作为 QA 专家,阅读这些文档,生成覆盖所有分支的测试用例列表。”2. “为这些接口生成自动化测试脚本(如 Pytest/Postman)。”- 结果:测试可以根据文档来精准确认修改范围和波及的功能,并且可以更快速的更新自动化和回归测试。
阶段三:交付与归档 (Handover & Archive)
- 提交代码时,必须附带由 AI 更新过的 Implementation Summary (实施总结)。
- 内容包括:改了什么?为什么这么改?哪里有潜在风险?配置项怎么配?
- 项目结束后,将所有文档(需求、接口、实施、测试)丢给大模型。
- “把这些文档归档,更新到项目的
README.md和Architecture.md中,保持项目知识库的鲜活。”
1. 大模型的“通天塔”作用:
- 前端看不懂后端的 Java 代码,测试看不懂前端的 React 代码。
- 但所有人的 AI 都能看懂 Markdown 文档。文档成为了跨语言、跨角色的通用字节码。
2. 消除“幻觉传递”:
- 口述最容易失真。A 说“大概两小时”,B 听成“两小时后上线”。
- 文档是静态的、可追溯的。AI 基于文档生成的代码,只会忠实于文档,不会忠实于你的“口误”。
3. 极低的接入成本:
- 大家依然用自己喜欢的 IDE 和 AI 工具,只是输入源变了。
4. 归档和溯源:
- 现在每个人都需要强制写文档和留存文档了,可以极大地增强文档的覆盖率。
- 如果出现一些误会和问题,可以快速准确的定位,不需要再翻聊天记录扯皮了。
5.5 人类的位置:由于 AI 做了执行,人类必须做决策
千万不要觉得“全都交给 AI 了,人没事干了”。恰恰相反,在这个流程中,人的“决断力”变得前所未有的重要。
PM要决断:AI 生成的需求文档,逻辑是否自洽?是不是用户真正想要的?
后端要决断:AI 建议的数据库设计,三年后是否会成为系统性风险?
前端要决断:AI 写的 Mock 数据是不是太理想化了?真实网络环境会怎样?
SOP 的目的不是把人变成机器,而是把人从“复读机”和“搬运工”的低级劳动中解放出来,去把控那些只有人类能理解的复杂性(Context & Humanity)。
6. 基础设施与资产沉淀:Prompt 才是核心资产
在 SDD 模式下,代码变得廉价且易变(Disposable)。那么,团队究竟在积累什么? 答案是:积累“如何让 AI 写出好代码”的知识。以前,资深工程师的经验存在脑子里;现在,必须把这些经验固化为 Agent Skills。
6.1 建立团队的“第二大脑” (The Skill Store)
"Taste is the ultimate filter." (品味是终极过滤器)
不要让每个人都去重复踩坑。
- 动作:在项目根目录维护一个
.cursorrules 文件或 docs/skills/SKILL.md。
- 技术偏好:“本项目使用 Java 17,优先使用 Record 类,禁止使用 Lombok。”
- 业务铁律:“所有涉及金额的字段,数据库必须用
_Decimal(19,4)_,Java 必须用_BigDecimal_,禁止用_Double_。” - 测试规范:“单元测试必须使用 JUnit 5,且必须覆盖空指针异常。”
- 机制:每次有新同学(或新 AI Session)加入开发时,第一件事就是读取这份文件。这相当于给 AI 装载了团队的“集体记忆”。
6.2 错误即规则 (Error to Rule)
这是 SDD 模式下最有复利的进化逻辑。
- 传统模式:出现 Bug -> 修代码 -> 提交 -> 下次还敢。
- SDD 模式:出现 Bug -> 修 Skill -> 让 AI 重新生成代码。
- 请在
SKILL.md 里加一条:“规则 #42:所有列表查询接口必须默认包含分页参数。” - 累计的错误记录,bug总结,修复方法也会成为团队的宝贵财富。
当代码不是人写的,“由于什么原因改了什么”变得比代码本身更重要。
- 强制维护
docs/decisions/AI_CHANGELOG.md(这点可以使用一些skill来简单高效的完成)。 - 格式:“2026-01-01: 基于
_Spec-Auth-v2.md_重构了登录模块。风险点:废弃了旧版 Token 校验逻辑。”
6.4 Spec 资产保鲜:生命周期管理协议
(Lifecycle Management)
文档最怕的是“写完即死”。为了防止 Spec Drift(规格漂移,即代码改了文档没改),必须建立严格的生命周期管理:
- 每份 Spec 必须有明确的 Human Owner(通常是提交 PR 的人)。AI 只是 Writer,人是 Owner。
- 需求变更:改代码前,必须先改
Requirement Spec。 - 代码重构:改逻辑前,必须先更新
Implementation Spec。 - 线上 Bug:执行 LAFR 流程修复后,必须回填
Test Spec(补录 Case)。
没有约束的 AI 也是一种灾难。作为架构师,你必须划定红线。
7.1 数据安全分级 (Data Privacy)
参考 C1/C2/C3 标准,建立严格的模型使用纪律:
C3 (高敏感/核心代码):如支付核心、用户隐私数据(在这个场景下,此方案变得尤其好用)。
红线:严禁把敏感信息喂给外部大模型。
SOP:使用私有化部署模型(如内部的 Qwen)生成脱敏后的 Spec 文档,让外部大模型阅读修改脱敏后的文档,最后让内部大模型还原文档和实施代码。
C1/C2 (通用逻辑/工具):如前端 UI、工具类、单元测试。
策略:大胆使用最先进的外部模型(GPT-5.2/Claude 4.5),追求最高效率。
7.2 幻觉识别 (Anti-Hallucination)
大模型最擅长“一本正经地胡说八道”。
- 如果 AI 调用了一个你没见过的库函数,90% 是幻觉。
- 对策:在 RIPER 流程 的 Step 5 (Review)阶段,强制 AI 提供代码的出处或官方文档链接。
- SDD 的原则是:你必须有能力为 AI 的产出兜底。看不懂的代码就是埋在项目里的地雷。
7.3 责任归属 (Accountability)
- 基本法:谁 Sign-off 文档,谁 Sign-off 代码,谁就对 Bug 负责。
- 不要试图甩锅给“是 AI 写的”。AI 是你的笔,字写错了是人的问题。
Q1:新项目冷启动,怎么让大模型“快速上手”?
你本来就会让模型先做一次 research(读 README/架构/依赖/目录结构/关键约束),区别在于:不要让 research 只停留在对话里。
一个很实用的习惯:每次让模型做完 research,顺手补一句——
- “把你刚才的结论总结成规整文档,输出到
docs/(并给出建议的目录结构/后续要写的 01/02/03/04)。”
这样新项目的“上下文载体”就建立了:后续你 new chat、换模型、换人,都能从docs/直接恢复状态,而不是靠人肉复述。
Q2:老项目冷启动(存量),没有文档怎么办?
存量项目迟早都要做文档;区别只是被动补救还是增量沉淀。
建议不要试图“一次性补齐全量文档”,而是从你下一次要做的变更开始增量补:
1. 选一个真实的 feature/bugfix,当场写一套最小 Spec(01/02/03/04)。
2. 让模型基于代码现状生成03_implementation.md骨架(改哪里、边界在哪、风险在哪)。
3. 每次合并 PR 时强制更新:docs/decisions/AI_CHANGELOG.md(为什么这么改),并回填测试用例(防复发)。
这样文档会自然“长出来”,而不是变成一个永远排不上期的“大重构”任务。
Q3:老项目已经有文档,怎么用才不浪费?
Q4:这会不会变成“写文档负担”?
关键不在“写更多”,而在“写对地方”:
文档只写到能驱动实现与验收的程度(Spec 是指令集,不是长作文)。
让 AI 起草,你只做 Review/Sign-off;把文档写作成本压到“可接受的固定开销”。
用门禁保证文档不死:需求变更先改 01,重构先改 03,线上问题必须回填 04 + SKILL。
Q5:后续维护是不是都“基于文档”,不直接改代码?
理想状态是:人尽量不直接改代码,而是先改/补 Spec,再让 AI 按 Spec 改代码(然后由人做 Review/Sign-off)。
原因很简单:当你把编码执行交给模型之后,最大风险来自new chat的上下文缺失——同一个需求、同一段代码,换会话/换模型就可能出现理解偏差。Spec 作为“唯一事实来源”,能让后续的 feature/bugfix 复用同一套上下文与约束,避免每次都靠聊天重建。
现实落地时可以这么做(低摩擦):
Q6:现在是不是所有代码变更都走这套方法论?大概有多少真实代码实践?
不必教条化到“100% 的改动都写全套 Spec”。更现实的做法是:
至于“真实实践量”,更有意义的指标不是行数本身,而是:是否覆盖了“新功能上线 + 多轮优化 + 多次 bugfix + 需求增量”的完整生命周期;只要能在多次new chat下依然稳定复用上下文,说明方法论已经在真实场景里跑通。
Q7:别人还在写 Spec,我已经上线了,会不会被流程拖慢?
如果 Spec 变成“写完一套长作文才允许动手”,当然会拖慢;SDD 追求的是把最小必要的对齐与验收前置,让执行可以更快、更稳。
建议的节奏是:
先写最小 01/02(范围 + 契约),让并行与执行立刻启动。
03/04可以在实现过程中增量补齐,但必须在合并/上线前达到门禁。
对于小改动,允许 Lite 甚至“先修再补留痕”,但要保证不会形成长期 Spec Drift。
Q8:有没有办法把“文档成本”再降一些?是不是要等 DeepWiki 之类的能力成熟?
文档能力当然会被工具持续增强(例如自动索引、统一检索、知识库/DeepWiki、MCP 接入等),但这不是 SDD 成败的前提。SDD 的重点是“上下文有载体 + 可验收 + 可追溯”,形态很灵活:
换句话说:工具越强,成本越低;但即使没有 DeepWiki,你也可以从“顺手落docs/”开始,把上下文沉淀起来,先跑通闭环。
Q9:有人觉得写 Spec 太重,不够 Vibe Coding?
这是一个误区。没有 Spec 的 Vibe Coding 不是“快”,而是“赌”。Vibe Coding 提倡 "If fixing takes too long, regenerate"。但如果没有 Spec 文档作为基准,你每次 Regenerate 都是在碰运气(幻觉漂移)。SDD 实际上是 Vibe Coding 的“安全带”——它极轻(Lite 版),但能让你在高速飙车(Reroll)时,始终不偏离轨道。
Q10:既然有 OpenSpec 这种工具,我为什么要手写文档?
因为工具会过时,但“文本”永存。
- 反脆弱:使用专门的工具框架(OpenSpec/Spec-Kit)意味着你绑定了它的生态。如果有一天它不维护了,或者不支持最新的模型了,你的工作流就断了。
- 原生感:Manual SDD 是LLM Native的。它利用的是大模型最原始的阅读能力(Markdown),这意味着无论你是用 Cursor、Windsurf、还是未来的 GPT-6,这套方法论永远通用,不需要等工具适配。
Q11:文档维护会不会很麻烦?特别是开发期变动频繁时。
不会。采用“松耦合”策略,区分“个人工作台”与“团队知识库”。
正如你提到的,现代开发通常是“一人负责一个模块”:
- 开发期(热数据):Spec 文档就在你的本地或 Feature 分支里。它是你的私人草稿本,随改随用,不需要实时同步给所有人,也不会影响主干。
- 归档期(冷数据):等到月度或季度复盘时,再将这些经过代码验证的 Spec精简后,上传到部门知识库(Wiki)。这样,既享受了 SDD 的开发便利,又自然而然地完成了团队的知识沉淀,还可以给知识库持续“造血”。
我们正站在软件工程历史的转折点上。
这篇教程里的 SOP(RIPER-5、文档驱动、Skill 沉淀),可能会让你觉得繁琐。你可能会想:“我自己写两行代码不就完了吗?”
但在 90% 的场景下,“快”是最大的陷阱。 你省下的那写文档的 10 分钟,未来会变成 10 个小时的 Debug 时间和无尽的维护噩梦。
SDD (文档驱动开发) 的本质,是逼迫你从“低头拉车”(Coding)变为“抬头看路”(Designing)。 它并没有剥夺你作为程序员的乐趣,相反,它剥夺的是那些枯燥的、重复的、易错的体力劳动,而把最宝贵的创造力、架构思维、业务洞察留给了你。
代码会过时,工具会迭代,模型会换代。但你对业务的理解、对架构的审美、以及驾驭 AI 的能力,将是你在这个时代最坚固的护城河。
不要等待未来,未来已来。 请打开你的 IDE,建立那个叫 docs/ 的文件夹,开始你的第一次 SDD 之旅吧。
注:以上图片均由Gemini3制作,内容由Gemini3、Qwen生成。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
