AI 编程别光凭感觉:手把手实操 SDD,把 Vibe Coding 拉回工程轨道.
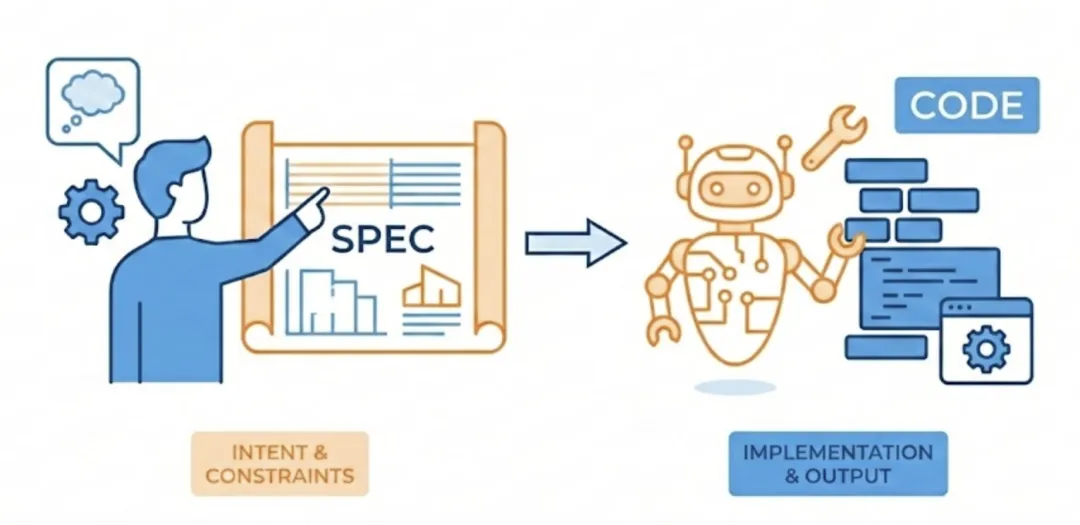
2025 年,Andrej Karpathy 把“Vibe Coding”(氛围编程) 带火了 — 给 AI 一个自然语言的目标,让 LLM 生成代码,自己只负责验收,不行再迭代。这种模式在做原型验证或创意探索时,问题不大。但一旦进入企业级系统与大型团队开发的深水区,情况就完全不同了。缺乏约束的 AI 很容易带来理解不一致、架构随意与风格碎片化,最终把成本转移到联调、返工和维护上。因此需要一种工程化方法,把 AI 编程的速度优势,转化为可控的工程产能。这就是为什么今天要聊聊SDD(Spec-Driven Development,规范驱动开发)。- 为什么需要 SDD:给 AI 一份“可执行的约束”
- 实战 SDD:Spec Kit + Github Copilot
为什么需要 SDD:给 AI 一份“可执行的约束”在 Claude、ChatGPT、Gemini等模型与 Coding Agent 的加持下,软件开发如虎添翼:开发者只要给出需求指令,AI 就能快速产出代码。但随着项目规模扩大,这种靠 AI 即兴发挥的副作用很明显:- 架构不一致:AI 自身“记忆”有限(且大型项目中会有多个AI)。时间一长,就会出现代码都“跑通”,但架构零散不一致。
- 维护性崩塌:缺乏统一的设计文档时,代码会变成唯一的事实来源。而现在代码由 AI 生成,人类未必完全理解 — 久而久之,代码就像一次性用品,不敢改、也改不动,任由 AI 生成大量“屎山代码”。
- 幻觉与安全隐患:在缺乏严格约束的情况下,AI 很容易引入“看似合理但其实错误”的逻辑甚至安全隐患,排查成本很高。
所以很显然:AI加速了代码产出,但是引入了新的复杂性。规范驱动开发(SDD)正是在此背景下诞生的工程化解法。它主张:把软件工程的重心从“代码实现”上移到“定义规范”(Spec)— 一份系统蓝图,也是软件工程的“乐谱”:明确系统要做什么、为什么这样做、约束与边界是什么、验收标准是什么等。SDD 让人机协作的分工变成:人类负责规范,AI 负责实现与产出。从历史渊源看,早在 AI 崛起之前,软件工程领域就有“规范先行”的探索:比如敏捷阵营里的 BDD(行为驱动开发) 实践,用验收语言把期望的软件行为前置。但以往这些方法要么偏学术、要么缺少足够强的工具支撑。当生成式 AI 工具强大并普及后,这条路突然变得现实:- AI能力有了质的提升,可以承担大量代码工作,这让人类开发者可以腾出精力当设计师与指挥家 — 专注把“谱子”写对。
- 现代企业级软件整合了数十种服务/框架/依赖,维持这些组件与设计的一致耗时耗力,但现在 AI 可以轻松帮助实现对齐。
- 自动化闭环成为可能。现在的一些 SDD 工具链在AI协助下已经能够实现从规范到代码、再从代码到规范的“双向同步”。
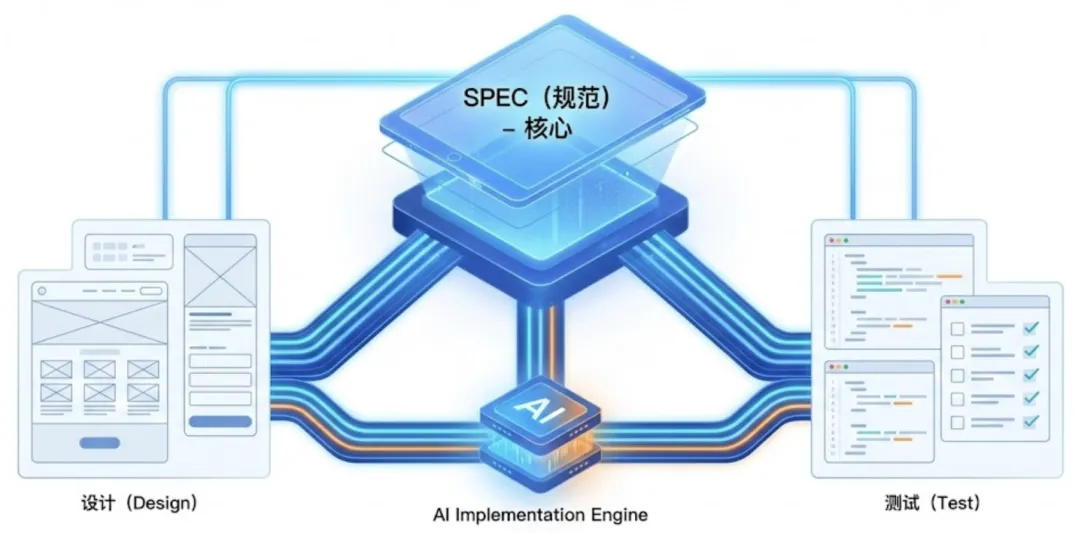
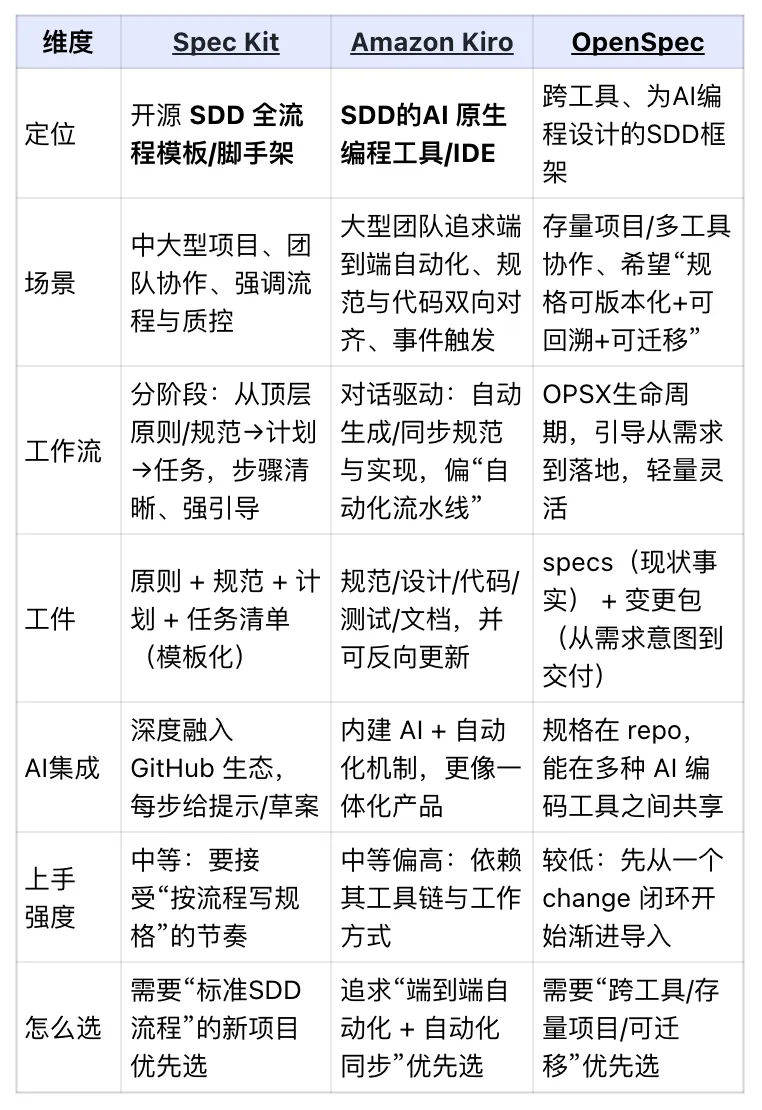
在传统开发里,文档经常滞后于代码:代码改了,文档来不及更新;久而久之,文档就变成“参考资料”。但在 SDD 范式中:规范才是第一“公民” — 它是团队协作的共同语言,也是唯一的事实来源。开发者用结构化、无歧义的自然语言或领域特定语言,把系统的意图、行为和约束讲清楚;随后由 AI Coding 作为“实现引擎”,严格依据规范生成代码、测试用例以及必要的辅助文档。以规范为中心组织开发:设计、代码、测试都围绕规范生成、验证与演进。注意,规范并不等于传统冗长的 Word 需求文档,后面我们会看到。此外,一个大型项目中可能会有很多规范(按功能/特性拆分)。随着 SDD 兴起,已经涌现出一批专门围绕该模式的 AI 工具生态。这里做简单了解与对比:- Github SpecKit:Github出品的一套标准化的命令行工具,适合中大型项目。得益于 Copilot 的深度集成,它能在每个规范环节提供智能模板与草案,帮助团队死磕流程标准化,做好质量控制。
- Amazon Kiro:主打从模糊需求到代码交付的端到端闭环。它最大的杀手锏是双向同步 — 代码变了,规范文档能反向更新保持对齐。配合自动化的 Hooks 检查机制,它将 SDD 理念完美融入了 DevOps 流水线。
- OpenSpec:不同于前两者侧重从 0 到 1 的构建,OpenSpec 更专注于存量系统的增量开发。它通过严格区分“系统当前状态”与“拟议变更”,确保每一次功能修改的边界都清晰可控,非常适合日常的迭代与维护。
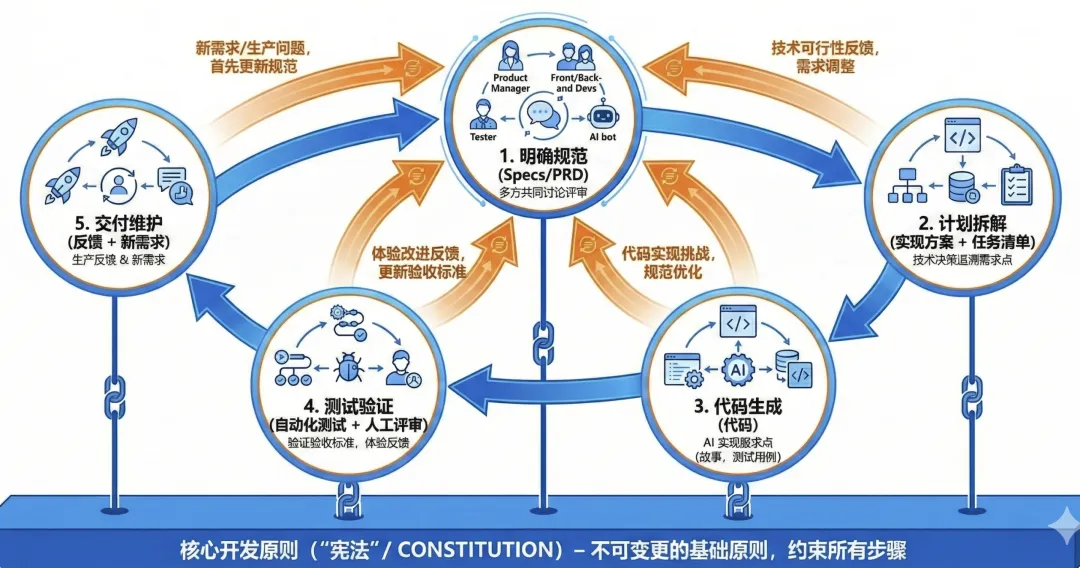
除此之外,还有一些适应 SDD 的辅助生态工具,比如契约驱动的 API 开发工具、自动化质量测试工具等。既然 SDD 强调“一切从规范出发”,那么它的完整开发流程相较传统模式有哪些不同?目前并没有唯一权威的面向 AI 的“SDD标准流程”。不同的 SDD 工具厂家在方法论上有所差异,但核心闭环与“规范优先”的原则是一致的。我们参考 Github SpecKit 工具的方法,将开发周期组成一个动态闭环:规范 → 计划 → 实现 → 验证 → 反馈(迭代)此外,这个闭环建立在一个“不可更改的核心原则”之上 — 可以把它理解为项目的开发宪法(Constitution)。基石:核心原则(Constitution,开发“宪法”)这是一套全局适用的元规则。比如:要求遵循测试驱动开发(TDD)、采用组件化架构、代码质量标准、文档同步要求等。Constitution 是 SDD 的红线,任何后续规范或代码都不能违背它。这是闭环的起点。产品、开发、测试与 AI 助手协作,把模糊需求转化为结构化的规范文档(常见为 Markdown 文档)。需要强调的是:规范的主要读者不仅是人,也包括 AI。- 需求场景:清晰的用户故事、边缘场景;明确的功能要求(必须/可选)
- 验收标准:各种情境下的期望行为(可用 Given/When/Then 表达)
- 关键实体:如果功能特性涉及到数据,可以描述业务实体与属性等
- 约束与规则:非功能需求(并发、性能、安全等)、架构原则与限制条件
类似传统的需求分析/架构阶段,但表达方式更偏自然语言,同时带一定格式约束(例如基于模板),追求尽量精确、尽量无歧义。在此阶段,架构师与技术负责人,把需求规范拆解成实现方案与任务清单(在工具协助下),让后续执行可追踪、可对齐。通常包括:- 接口与流程:模块接口契约(如OpenAPI格式),必要的流程图
- 任务清单:拆成具体开发任务,并标注与规范条目/场景的对应关系
这一步产出的计划本身也可视为一种设计层面的“次级规范”:它让 AI 更容易按步骤生成成果,也让人类清楚每一步该检查什么、如何把控风险。这个阶段可能会发现规范中的歧义与漏洞,需要及时反馈调整。“根据任务清单(Tasks)执行 AI 编程,人类担任监工”AI 根据任务列表进行代码产出,并同步任务状态。在AI编程过程中可能涉及到依赖安装、组件实现、各个规范场景的任务实现、测试用例生成等。不同 SDD 工具的体验会有所差异:有的强调“一次生成一致的代码 + 测试 + 文档”,有的强调步骤化生成与逐步审查。早期的代码生成往往带探索性 — 它本身也在验证“规范是否可落地”,因此发现的偏差应及时反馈给规范。代码生成后,必须进行严格“体检”,确保符合规范与宪法:- 静态合规检查:检查是否违反“宪法”中的约束(质量/安全/风格等)
验证过程中发现的问题(比如涉及到用户交互、或者边缘场景),需要反馈到规范中,作为新的约束条件,驱动下一轮迭代。交付维护(Delivery & Maintenance)上线之后,面对 Bug 或新需求,SDD 的思路不是“先打补丁再说”,而是应该把变化纳入规范闭环:- 生产反馈:监控指标、故障、用户反馈作为下一轮规范输入
- 新需求:先更新规范,再走计划/实现/验证的完整闭环
这样,传统 SDLC 从“阶段性交付”变成“持续演进”:生产环境的任何反馈,本质上都是对规范的补充。系统更容易保持架构一致与可维护。通过上述闭环,一个功能就能相对完整地交付。更关键的是,整个过程的产物(规范、计划、代码、测试用例等)都彼此对齐 — 这对后续维护、交接与新需求开发都极其友好。相比传统“边干边补文档”的混沌过程,SDD 的确提供了更强的可控性与可追溯性。实战 SDD:Spec-Kit + Github Copilot为了更直观地感受 SDD 如何落地,我们用 Gitub Spec Kit 搭配 Copilot,做一个最小可行的练习:开发一个简单的个人 Blog 网站并做一次迭代。也可以换成其他 Coding Agent:Spec Kit 几乎支持所有的 AI 编程工具
如果你希望“长期使用”,可以把 CLI 持久安装到环境里uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
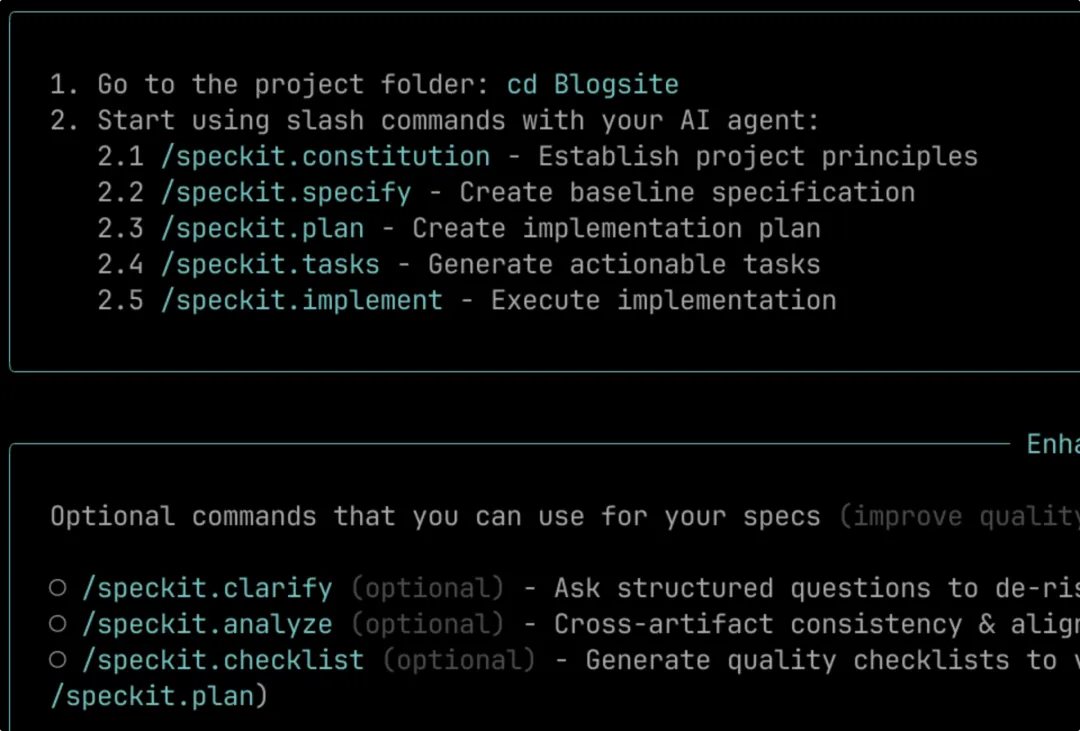
选择需要搭配的Code Agent,这里我们选择copilot。列出在 Copilot 里可用的 slash 命令(这些命令对应 SDD 的关键环节。其本质上是一种自定义智能体,提示模板放在.github目录下)。【3】打开VS Code,确认 Copilot 面板能看到命令。打开 Visual Studio Code,并打开 Copilot 面板。在输入框里键入 /speckit,应该会出现一系列 Speckit 命令列表。 如果没有出现,最常见原因是:VS Code 打开的目录不是刚初始化的项目根目录(导致 .github 里的提示模板没被加载)。【4】制定项目“宪法”(Constitution)选择一个常用的模型(我选择了GPT-5.2),然后输入如下命令:随后你会得到一个“项目宪法”文件(默认路径通常在):- .specify/memory/constitution.md
这个文件就是前面提到的“红线”,你完全可以按团队习惯删减和改写,以下是部分speckit生成的模板内容:借助/speckit.specify命令来把模糊的需求转化成结构化的模板规范:你会看到 Spec Kit 自动创建了一个分支目录(在 specs/ 下),并生成 spec.md。部分内容如下:现实项目里,这一步的输入不可能只有一句“做个 Blog”。更常见做法是:先让 AI 起草 spec.md,然后产品/研发/测试一起补齐、删改、对齐口径,形成可执行的共识版本。如果说 Spec 阶段输出的是 What & Why,Plan 阶段就开始回答 How。运行 /speckit.plan(并在提示里补充一些必要约束):Plan过程是一个比较复杂的过程,我们尽量简化的描述其处理步骤:- 读取:spec.md + constitution.md
- 生成:plan.md草案(带不确定项)+ 宪法检查清单
- 研究:把不确定项落实为明确决策(常见产物如 research.md)
- 落地:补齐关键设计(数据模型data-model.md、契约contracts/等)
运行/speckit.tasks,核心目标是把 Spec 里的需求按用户故事拆成可执行任务清单(tasks.md):最终你将看到如下的Task清单,会按依赖顺序排列,并标出能否并行;且自带checklist,方便跟踪进度:这份 tasks.md 就是 AI 下一步“干活”的施工单,人类则负责“监工”。运行/speckit.implement,让 AI 按 tasks.md 的顺序推进代码生成:生成代码后,需要开发者 + QA 做验收。由于“宪法”通常会要求 TDD 或至少自动化测试,AI 往往会同时生成单测与端到端测试。可以先让 AI 跑测试并修到通过,再做人工体验测试,把体验问题回写规范。在修复问题后,启动应用,就可以看到一个遵循规范的应用已经成型:Spec Kit工具提供了可选的/speckit.analyze命令,用来自动检查 Spec / Plan / Tasks 之间的不一致、重复、含糊、覆盖缺口,以及与宪法冲突的问题,并按严重程度输出分析建议。你可以据此进行修复:- 用 Spec / Plan / Tasks指导代码,而不是反过来
换句话说:当你发现需求不合理或技术路线需要调整,优先回到上游文档更新,再让 AI 重新对齐实现;不要只在代码层“硬改”,最后让文档彻底过期。- 小 bug / 拼写 / 样式等不影响验收口径的细节:可以少量直接改代码
- 影响用户感知、接口、验收标准或技术路线:必须回到 spec/plan 更新
- 新功能/新特性:新建 Feature 分支,跑一轮新的闭环
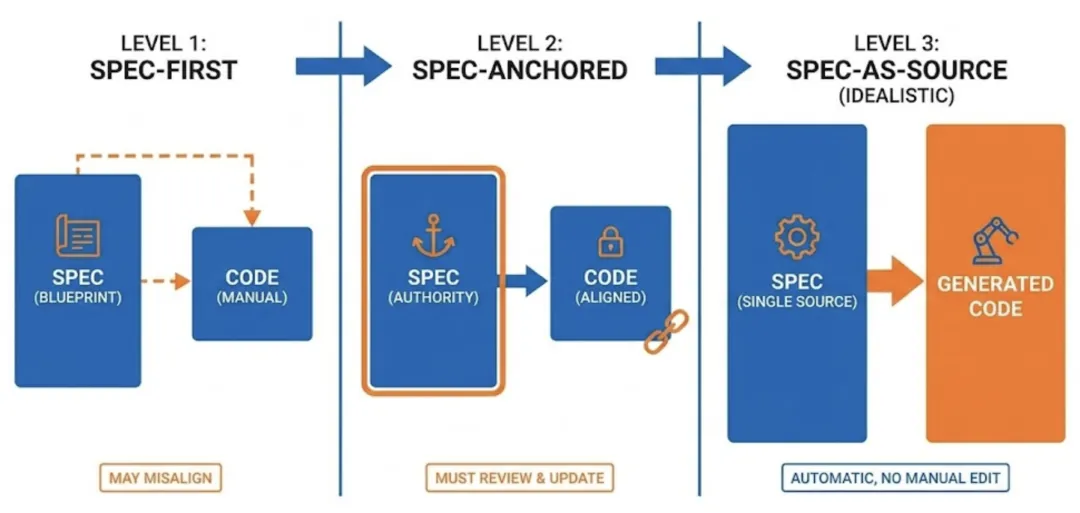
默认情况下 AI 会创建新的 Feature 分支(新的分支文档目录),用来开始新的一次 SDD 迭代:接下来依次完成 plan->tasks->implement,就完成了这个分支的开发。至此就完成了一次典型的 AI 协助下的 SDD 范式的开发与迭代。当然,SDD 领域还在快速演化,不同工具会把步骤合并/拆分,产物命名也可能不同。核心抓两点就行:规范优先 + 可验证闭环。很显然,引入 SDD 不只是“换一套工具”,它会直接牵动开发与协作流程、人员技能,甚至团队的开发文化。这个话题很大,这里给出一些关键分析。SDD 的落地可以分为三个“强度等级”,代表从轻到重的演进路线:- Spec-first(规范优先):强调先写规范再写代码,但可能出现不对齐。
- Spec-anchored(规范锚定):强调规范是权威,必须先改规范并评审。
- Spec-as-source(规范即源码):人只改规范,代码强制由工具生成。
第三层属于一种“理想主义”的模式,但对规范质量、工具能力、团队纪律要求都非常高。通常建议可以从第一层起步更现实 — 养成“规范优先“的习惯。当规范取代代码,成为交付与协作的核心,会带来几类本质变化:- 需求前置:需求不再是丢给开发的 Word 文档,而是由产品、开发、测试共同打磨的可执行功能规范。规范没对齐、没验收口径,就不要启动编码。
- 测试左移:QA 更像“规范守护者”。测试用例在编码前就写进规范里;当发现缺陷,第一反应不再只是“改代码”,而是先确认:这是实现偏离规范,还是规范本身就欠考虑?
- 进度重新定义:不再问“写了几行代码”,而更多问“规范覆盖了多少关键场景”“任务清单还剩多少”“验收点通过率如何”。
- 集成与发布升级:借助 SDD 工具(例如 /speckit.analyze ),可以把“规范与实现是否对齐”的检查纳入 CI,把“文档过期”这件事从流程上卡住。
AI Coding/SDD 不会淘汰人,但它会淘汰“只靠体力堆代码”的工作方式。每个角色的价值都要更靠近“意图、规则与验收”。产品经理
不再只写 PRD 的“业务表述”,而要与技术团队更紧密协作,共同产出可执行的 Spec。核心能力从“讲清楚需求”升级为“结构化定义需求”:边界、优先级、验收口径、异常情况,让 AI 也能准确理解需求。
软件架构师
更需要主导 SDD 的全局设计:如何组织文档体系、如何制定项目宪法(质量/安全红线、开发原则等)、如何定义架构规范,让 AI 在框架内“带着镣铐跳舞”。同时还要推动落地:哪些模块先试点、如何评审、如何把控风险。
开发工程师
职能更像 AI 的“驾驶员/导师”。Coding 仍然要懂,但重心从“自己写”转向“指导 AI 写对”:维护高质量规范,审查 AI 的设计与代码,给出修改指令,确保规范库长期干净、一致、可演进。
测试/QA 工程师
地位会前移并提升:从需求阶段就加入,确保规范可测试、覆盖完整(尤其是边界场景);在测试阶段则要把更多精力放在“测试问题与规范条目”的对应确认上,推动规范修订,而不是把问题停留在“改完这版就算了”。
归根结底,各角色都需要一项共同能力:规范工程能力。包括:- 结构化表达:熟悉 Markdown、Given/When/Then 等表达方式,用清晰、无歧义的方式描述需求与验收。
- 提示与协作:知道如何给 AI 下达明确指令,让它更稳定地产出高质量 Spec / Plan / Tasks / Code。
- 规范审查:像过去 code review 一样 review 规范:业务逻辑是否闭环?边界条件是否覆盖?约束是否完整?等等。
- 持续复盘沉淀:把常见问题、模板、最佳实践沉淀下来,形成团队的“规范资产”。
- 不适应写规范:很多工程师更愿意写代码,不愿写文档。
- 规范质量不稳定:规范本身含糊,AI 会把含糊放大,最终输出更不可控。
- 流程不闭环:赶进度时直接改代码,最后又回到“文档过期”的老路。
因此,在企业内更稳妥的推行 SDD 的方式通常是:- 先做到 Spec-first(先规范再代码),再逐步升级为 Spec-anchored(所有变更以规范为锚)。
- 把规范更新纳入 PR/评审流程(像测试一样“必过”),让流程逼着团队长期保持一致性。
SDD 的方法与工具还处于发展中,但代表了 AI Coding 时代软件工程的一个重要方向。对开发者来说,别因为 AI 能写代码,就放弃了思考。恰恰相反:因为 AI 能写代码,你更需要像产品经理、像设计师一样思考问题,制定严谨的规范,让AI的工作质量更高更可控。所以,下一步的你可以挑一个你维护的“屎山”项目,试着为其中一个功能展开SDD 的重构过程,看看它产出的代码,会不会让你大吃一惊。























 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
