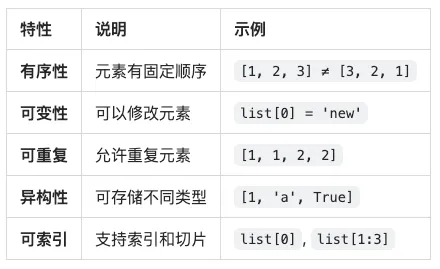
一、什么是列表?
列表是Python中最灵活的有序可变数据结构,可以存储任意类型的数据。# 基本示例fruits = ['apple', 'banana', 'orange']numbers = [1, 2, 3, 4, 5]mixed = [1, 'hello', 3.14, True, [1, 2, 3]]
🔑 列表的核心特性
二、列表的创建方式
方式1:直接创建
# 空列表empty_list = []empty_list2 = list()# 带初始值的列表fruits = ['apple', 'banana', 'orange']numbers = [1, 2, 3, 4, 5]
方式2:使用 list() 构造函数
# 从字符串创建chars = list('hello')print(chars) # 输出: ['h', 'e', 'l', 'l', 'o']# 从元组创建tuple_data = (1, 2, 3)list_data = list(tuple_data)print(list_data) # 输出: [1, 2, 3]# 从range创建numbers = list(range(1, 6))print(numbers) # 输出: [1, 2, 3, 4, 5]# 从字典创建(只取键)dict_data = {'a': 1, 'b': 2}keys = list(dict_data)print(keys) # 输出: ['a', 'b']
方式3:列表推导式(最强大)
# 基础推导式squares = [x**2 for x in range(1, 6)]print(squares) # 输出: [1, 4, 9, 16, 25]# 带条件的推导式evens = [x for x in range(10) if x % 2 == 0]print(evens) # 输出: [0, 2, 4, 6, 8]# 嵌套推导式matrix = [[i*j for j in range(1, 4)] for i in range(1, 4)]print(matrix) # 输出: [[1, 2, 3], [2, 4, 6], [3, 6, 9]]
方式4:使用 * 运算符
# 重复元素zeros = [0] * 5print(zeros) # 输出: [0, 0, 0, 0, 0]# ⚠️ 注意:嵌套列表的陷阱wrong = [[]] * 3 # 三个引用指向同一个列表wrong[0].append(1)print(wrong) # 输出: [[1], [1], [1]] # 所有子列表都被修改了!# ✅ 正确方式correct = [[] for _ in range(3)]correct[0].append(1)print(correct) # 输出: [[1], [], []]
三、列表的属性
1. 长度 - len()
fruits = ['apple', 'banana', 'orange']print(len(fruits)) # 输出: 3# 空列表empty = []print(len(empty)) # 输出: 0# 嵌套列表nested = [[1, 2], [3, 4, 5]]print(len(nested)) # 输出: 2 (只计算外层元素个数)
2. 索引访问
fruits = ['apple', 'banana', 'orange', 'grape', 'mango']# 正向索引(从0开始)print(fruits[0]) # appleprint(fruits[1]) # bananaprint(fruits[2]) # orange# 反向索引(从-1开始)print(fruits[-1]) # mango (最后一个)print(fruits[-2]) # grape (倒数第二个)print(fruits[-3]) # orange (倒数第三个)# 索引对照表# 索引: 0 1 2 3 4# 元素: 'apple' 'banana' 'orange' 'grape' 'mango'# 反向: -5 -4 -3 -2 -1
3. 切片操作
numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]# 基本切片 [start:stop:step]print(numbers[2:5]) # [2, 3, 4] (不包含索引5)print(numbers[:5]) # [0, 1, 2, 3, 4] (从开头到索引5)print(numbers[5:]) # [5, 6, 7, 8, 9] (从索引5到结尾)print(numbers[:]) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] (完整复制)# 带步长的切片print(numbers[::2]) # [0, 2, 4, 6, 8] (每隔一个取一个)print(numbers[1::2]) # [1, 3, 5, 7, 9] (从索引1开始,每隔一个)print(numbers[::3]) # [0, 3, 6, 9] (每隔两个取一个)# 反向切片print(numbers[::-1]) # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] (反转列表)print(numbers[-3:]) # [7, 8, 9] (最后三个元素)print(numbers[:-3]) # [0, 1, 2, 3, 4, 5, 6] (除了最后三个)# 高级切片print(numbers[2:8:2]) # [2, 4, 6] (从索引2到8,步长2)print(numbers[8:2:-1]) # [8, 7, 6, 5, 4, 3] (反向切片)
四、列表的核心方法(11个必会)
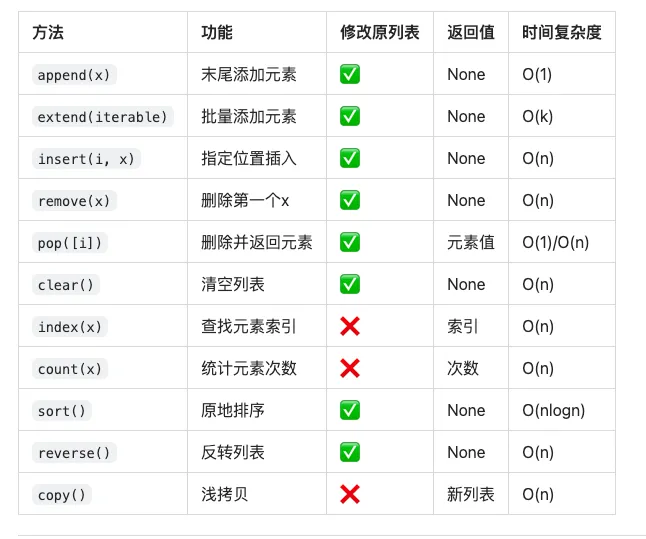
1️⃣ append() - 末尾添加元素
fruits = ['apple', 'banana']# 添加单个元素fruits.append('orange')print(fruits) # 输出: ['apple', 'banana', 'orange']# 添加列表(整体作为一个元素)fruits.append(['grape', 'mango'])print(fruits) # 输出: ['apple', 'banana', 'orange', ['grape', 'mango']]# ⚠️ 注意:append()修改原列表,返回Noneresult = fruits.append('kiwi')print(result) # 输出: None
2️⃣ extend() - 批量添加元素
fruits = ['apple', 'banana']# 扩展列表fruits.extend(['orange', 'grape'])print(fruits) # 输出: ['apple', 'banana', 'orange', 'grape']# 可以扩展任何可迭代对象fruits.extend('hi')print(fruits) # 输出: ['apple', 'banana', 'orange', 'grape', 'h', 'i']# 对比 append() 和 extend()list1 = [1, 2]list1.append([3, 4])print(list1) # [1, 2, [3, 4]]list2 = [1, 2]list2.extend([3, 4])print(list2) # [1, 2, 3, 4]# 等价于 += 运算符list3 = [1, 2]list3 += [3, 4]print(list3) # [1, 2, 3, 4]
时间复杂度:O(k),k为添加元素的个数
3️⃣ insert() - 指定位置插入
fruits = ['apple', 'banana', 'orange']# 在索引1的位置插入fruits.insert(1, 'grape')print(fruits) # 输出: ['apple', 'grape', 'banana', 'orange']# 在开头插入fruits.insert(0, 'mango')print(fruits) # 输出: ['mango', 'apple', 'grape', 'banana', 'orange']# 在末尾插入(索引超出范围)fruits.insert(100, 'kiwi')print(fruits) # 输出: ['mango', 'apple', 'grape', 'banana', 'orange', 'kiwi']# 负数索引fruits.insert(-1, 'pear') # 插入到倒数第一个元素之前print(fruits) # 输出: ['mango', 'apple', 'grape', 'banana', 'orange', 'pear', 'kiwi']
时间复杂度:O(n) - 需要移动后续元素
4️⃣ remove() - 删除指定值(第一个)
fruits = ['apple', 'banana', 'orange', 'banana', 'grape']# 删除第一个匹配的元素fruits.remove('banana')print(fruits) # 输出: ['apple', 'orange', 'banana', 'grape']# 再次删除fruits.remove('banana')print(fruits) # 输出: ['apple', 'orange', 'grape']# ❌ 删除不存在的元素会报错try: fruits.remove('kiwi')except ValueError as e: print(f"错误: {e}")# 输出: 错误: list.remove(x): x not in list# ✅ 安全删除if 'kiwi' in fruits: fruits.remove('kiwi')else: print("元素不存在")
时间复杂度:O(n) - 需要查找元素
5️⃣ pop() - 删除并返回指定位置元素
fruits = ['apple', 'banana', 'orange', 'grape']# 删除最后一个元素(默认)last = fruits.pop()print(last) # grapeprint(fruits) # ['apple', 'banana', 'orange']# 删除指定位置first = fruits.pop(0)print(first) # appleprint(fruits) # ['banana', 'orange']# 删除倒数第二个second_last = fruits.pop(-2)print(second_last) # bananaprint(fruits) # ['orange']# ❌ 空列表pop会报错empty = []try: empty.pop()except IndexError as e: print(f"错误: {e}")# 输出: 错误: pop from empty list
时间复杂度:
pop()删除末尾:O(1)pop(0)删除开头:O(n)
6️⃣ clear() - 清空列表
fruits = ['apple', 'banana', 'orange']# 清空列表fruits.clear()print(fruits) # 输出: []# 等价于fruits = ['apple', 'banana', 'orange']fruits = [] # 创建新列表# 或fruits[:] = [] # 清空原列表
7️⃣ index() - 查找元素索引
fruits = ['apple', 'banana', 'orange', 'banana', 'grape']# 查找元素第一次出现的索引idx = fruits.index('banana')print(idx) # 输出: 1# 指定查找范围 [start, end)idx = fruits.index('banana', 2) # 从索引2开始查找print(idx) # 输出: 3idx = fruits.index('banana', 2, 4) # 在索引2-4之间查找print(idx) # 输出: 3# ❌ 元素不存在会报错try: fruits.index('kiwi')except ValueError as e: print(f"错误: {e}")# 输出: 错误: 'kiwi' is not in list# ✅ 安全查找if 'kiwi' in fruits: idx = fruits.index('kiwi')else: idx = -1 print("元素不存在")
8️⃣ count() - 统计元素出现次数
numbers = [1, 2, 3, 2, 4, 2, 5, 2]# 统计元素出现次数count = numbers.count(2)print(count) # 输出: 4count = numbers.count(10)print(count) # 输出: 0 (不存在返回0,不会报错)# 统计列表中的列表nested = [[1, 2], [3, 4], [1, 2], [5, 6]]count = nested.count([1, 2])print(count) # 输出: 2
9️⃣ sort() - 原地排序
numbers = [3, 1, 4, 1, 5, 9, 2, 6]# 升序排序(默认)numbers.sort()print(numbers) # 输出: [1, 1, 2, 3, 4, 5, 6, 9]# 降序排序numbers.sort(reverse=True)print(numbers) # 输出: [9, 6, 5, 4, 3, 2, 1, 1]# 字符串排序fruits = ['banana', 'apple', 'orange', 'grape']fruits.sort()print(fruits) # 输出: ['apple', 'banana', 'grape', 'orange']# 按长度排序(使用key参数)fruits.sort(key=len)print(fruits) # 输出: ['apple', 'grape', 'banana', 'orange']# 按自定义规则排序students = [ {'name': 'Alice', 'age': 25}, {'name': 'Bob', 'age': 20}, {'name': 'Charlie', 'age': 23}]students.sort(key=lambda x: x['age'])print(students)# 输出: [{'name': 'Bob', 'age': 20}, {'name': 'Charlie', 'age': 23}, {'name': 'Alice', 'age': 25}]# ⚠️ 注意:sort()修改原列表,返回Noneresult = numbers.sort()print(result) # 输出: None
对比 sort() 和 sorted()
numbers = [3, 1, 4, 1, 5]# sort() - 原地排序,修改原列表numbers.sort()print(numbers) # [1, 1, 3, 4, 5]# sorted() - 返回新列表,不修改原列表numbers = [3, 1, 4, 1, 5]sorted_numbers = sorted(numbers)print(numbers) # [3, 1, 4, 1, 5] (未改变)print(sorted_numbers) # [1, 1, 3, 4, 5]
🔟 reverse() - 反转列表
numbers = [1, 2, 3, 4, 5]# 反转列表numbers.reverse()print(numbers) # 输出: [5, 4, 3, 2, 1]# ⚠️ 注意:reverse()修改原列表,返回Noneresult = numbers.reverse()print(result) # 输出: None# 对比 reverse() 和 [::-1]numbers = [1, 2, 3, 4, 5]# reverse() - 原地反转numbers.reverse()print(numbers) # [5, 4, 3, 2, 1]# [::-1] - 返回新列表numbers = [1, 2, 3, 4, 5]reversed_numbers = numbers[::-1]print(numbers) # [1, 2, 3, 4, 5] (未改变)print(reversed_numbers) # [5, 4, 3, 2, 1]
1️⃣1️⃣ copy() - 浅拷贝列表
# 方式1:使用copy()方法original = [1, 2, 3]copied = original.copy()copied[0] = 999print(original) # [1, 2, 3] (未改变)print(copied) # [999, 2, 3]# 方式2:使用切片copied2 = original[:]# 方式3:使用list()构造函数copied3 = list(original)# ⚠️ 浅拷贝的陷阱(嵌套列表)original = [[1, 2], [3, 4]]copied = original.copy()copied[0][0] = 999print(original) # [[999, 2], [3, 4]] (被修改了!)print(copied) # [[999, 2], [3, 4]]# ✅ 深拷贝(完全独立)import copyoriginal = [[1, 2], [3, 4]]deep_copied = copy.deepcopy(original)deep_copied[0][0] = 999print(original) # [[1, 2], [3, 4]] (未改变)print(deep_copied) # [[999, 2], [3, 4]]
五、列表的高级操作
1. 列表运算符
# + 连接列表list1 = [1, 2, 3]list2 = [4, 5, 6]result = list1 + list2print(result) # 输出: [1, 2, 3, 4, 5, 6]# * 重复列表list3 = [1, 2] * 3print(list3) # 输出: [1, 2, 1, 2, 1, 2]# in 成员检测print(2 in [1, 2, 3]) # Trueprint(5 in [1, 2, 3]) # False# not inprint(5 not in [1, 2, 3]) # True# 比较运算符(按字典序)print([1, 2, 3] < [1, 2, 4]) # Trueprint([1, 2, 3] == [1, 2, 3]) # True
2. 列表解包
# 基本解包a, b, c = [1, 2, 3]print(a, b, c) # 输出: 1 2 3# 使用 * 收集剩余元素first, *rest = [1, 2, 3, 4, 5]print(first) # 1print(rest) # [2, 3, 4, 5]*start, last = [1, 2, 3, 4, 5]print(start) # [1, 2, 3, 4]print(last) # 5first, *middle, last = [1, 2, 3, 4, 5]print(first) # 1print(middle) # [2, 3, 4]print(last) # 5# 交换变量a, b = 1, 2a, b = b, aprint(a, b) # 2 1
3. 列表的内置函数
numbers = [3, 1, 4, 1, 5, 9, 2, 6]# len() - 长度print(len(numbers)) # 8# max() - 最大值print(max(numbers)) # 9# min() - 最小值print(min(numbers)) # 1# sum() - 求和print(sum(numbers)) # 31# all() - 所有元素为Trueprint(all([True, True, True])) # Trueprint(all([True, False, True])) # Falseprint(all([1, 2, 3])) # Trueprint(all([1, 0, 3])) # False# any() - 任一元素为Trueprint(any([False, False, True])) # Trueprint(any([False, False, False])) # Falseprint(any([0, 0, 1])) # True# enumerate() - 枚举(索引和值)fruits = ['apple', 'banana', 'orange']for idx, fruit in enumerate(fruits): print(f"{idx}: {fruit}")# 输出:# 0: apple# 1: banana# 2: orange# 指定起始索引for idx, fruit in enumerate(fruits, start=1): print(f"{idx}: {fruit}")# 输出:# 1: apple# 2: banana# 3: orange# zip() - 并行迭代names = ['Alice', 'Bob', 'Charlie']ages = [25, 30, 35]for name, age in zip(names, ages): print(f"{name}: {age}")# 输出:# Alice: 25# Bob: 30# Charlie: 35# map() - 映射numbers = [1, 2, 3, 4, 5]squared = list(map(lambda x: x**2, numbers))print(squared) # 输出: [1, 4, 9, 16, 25]# filter() - 过滤evens = list(filter(lambda x: x % 2 == 0, numbers))print(evens) # 输出: [2, 4]
六、列表推导式(List Comprehension)
基础语法
# 基本形式[expression for item in iterable]# 带条件[expression for item in iterable if condition]# 多重循环[expression for item1 in iterable1 for item2 in iterable2]
实战示例
# 1. 生成平方数squares = [x**2 for x in range(1, 6)]print(squares) # 输出: [1, 4, 9, 16, 25]# 2. 过滤偶数numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]evens = [x for x in numbers if x % 2 == 0]print(evens) # 输出: [2, 4, 6, 8, 10]# 3. 字符串处理words = ['hello', 'world', 'python']upper_words = [word.upper() for word in words]print(upper_words) # 输出: ['HELLO', 'WORLD', 'PYTHON']# 4. 条件表达式numbers = [1, 2, 3, 4, 5]result = ['even' if x % 2 == 0 else 'odd' for x in numbers]print(result) # 输出: ['odd', 'even', 'odd', 'even', 'odd']# 5. 嵌套列表展平nested = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]flat = [num for sublist in nested for num in sublist]print(flat) # 输出: [1, 2, 3, 4, 5, 6, 7, 8, 9]# 6. 生成坐标点points = [(x, y) for x in range(3) for y in range(3)]print(points) # 输出: [(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]# 7. 字典转列表data = {'a': 1, 'b': 2, 'c': 3}pairs = [(k, v) for k, v in data.items()]print(pairs) # 输出: [('a', 1), ('b', 2), ('c', 3)]# 8. 多条件过滤numbers = range(1, 21)result = [x for x in numbers if x % 2 == 0 if x % 3 == 0]print(result) # 输出: [6, 12, 18]# 9. 嵌套推导式(生成矩阵)matrix = [[i*j for j in range(1, 4)] for i in range(1, 4)]print(matrix) # 输出: [[1, 2, 3], [2, 4, 6], [3, 6, 9]]
七、实战案例
案例1:数据清洗
# 原始数据(包含空值、重复值)raw_data = [1, 2, None, 3, 2, '', 4, 5, None, 3]# 清洗:去除None和空字符串,去重cleaned = list(set([x for x in raw_data if x not in (None, '')]))print(cleaned) # 输出: [1, 2, 3, 4, 5]# 保持顺序的去重def remove_duplicates(lst): seen = set() result = [] for item in lst: if item not in seen and item not in (None, ''): seen.add(item) result.append(item) return resultcleaned_ordered = remove_duplicates(raw_data)print(cleaned_ordered) # 输出: [1, 2, 3, 4, 5]
案例2:分组统计
# 学生成绩数据scores = [85, 92, 78, 90, 88, 76, 95, 89, 84, 91]# 按等级分组def grade_level(score): if score >= 90: return 'A' elif score >= 80: return 'B' elif score >= 70: return 'C' else: return 'D'grades = {}for score in scores: level = grade_level(score) grades.setdefault(level, []).append(score)print(grades)# 输出: {'B': [85, 88, 89, 84], 'A': [92, 90, 95, 91], 'C': [78, 76]}# 统计各等级人数grade_counts = {k: len(v) for k, v in grades.items()}print(grade_counts)# 输出: {'B': 4, 'A': 4, 'C': 2}
案例3:数据转换
# CSV数据转字典列表csv_data = [ ['Name', 'Age', 'City'], ['Alice', '25', 'Beijing'], ['Bob', '30', 'Shanghai'], ['Charlie', '35', 'Guangzhou']]# 转换为字典列表headers = csv_data[0]data = [dict(zip(headers, row)) for row in csv_data[1:]]print(data)# 输出: [# {'Name': 'Alice', 'Age': '25', 'City': 'Beijing'},# {'Name': 'Bob', 'Age': '30', 'City': 'Shanghai'},# {'Name': 'Charlie', 'Age': '35', 'City': 'Guangzhou'}# ]
案例4:滑动窗口
# 计算移动平均def moving_average(data, window_size): result = [] for i in range(len(data) - window_size + 1): window = data[i:i + window_size] avg = sum(window) / window_size result.append(avg) return resultprices = [10, 12, 13, 11, 14, 15, 13, 16]ma3 = moving_average(prices, 3)print(ma3)# 输出: [11.666..., 12.0, 12.666..., 13.333..., 14.0, 14.666...]# 使用列表推导式ma3_compact = [sum(prices[i:i+3])/3 for i in range(len(prices)-2)]print(ma3_compact)
案例5:矩阵操作
# 矩阵转置matrix = [ [1, 2, 3], [4, 5, 6], [7, 8, 9]]# 方法1:使用ziptransposed = [list(row) for row in zip(*matrix)]print(transposed)# 输出: [[1, 4, 7], [2, 5, 8], [3, 6, 9]]# 方法2:使用推导式transposed2 = [[matrix[j][i] for j in range(len(matrix))] for i in range(len(matrix[0]))]print(transposed2)# 输出: [[1, 4, 7], [2, 5, 8], [3, 6, 9]]# 矩阵相加matrix1 = [[1, 2], [3, 4]]matrix2 = [[5, 6], [7, 8]]result = [[matrix1[i][j] + matrix2[i][j] for j in range(len(matrix1[0]))] for i in range(len(matrix1))]print(result)# 输出: [[6, 8], [10, 12]]
八、性能优化技巧
1. 选择合适的方法
# ❌ 低效:频繁使用insert(0)def slow_prepend(n): result = [] for i in range(n): result.insert(0, i) # O(n) 每次都要移动所有元素 return result# ✅ 高效:使用append后reversedef fast_prepend(n): result = [] for i in range(n): result.append(i) # O(1) result.reverse() # O(n) 只执行一次 return result
2. 列表推导式 vs 循环
# ❌ 使用循环result = []for i in range(1000): result.append(i**2)# ✅ 使用列表推导式(更快)result = [i**2 for i in range(1000)]# ✅ 使用生成器(节省内存)result = (i**2 for i in range(1000)) # 惰性求值
3. 避免不必要的复制
# ❌ 创建不必要的副本def process_list_bad(lst): new_list = lst[:] # 复制整个列表 new_list.append(1) return new_list# ✅ 直接修改(如果允许)def process_list_good(lst): lst.append(1) return lst
4. 使用集合去重(更快)
# ❌ 使用列表去重(慢)def remove_duplicates_slow(lst): result = [] for item in lst: if item not in result: # O(n) 查找 result.append(item) return result# ✅ 使用集合去重(快)def remove_duplicates_fast(lst): return list(set(lst)) # O(1) 查找# ✅ 保持顺序的快速去重def remove_duplicates_ordered(lst): seen = set() result = [] for item in lst: if item not in seen: # O(1) 查找 seen.add(item) result.append(item) return result
九、常见陷阱与避坑指南
陷阱1:可变默认参数
# ❌ 错误:使用可变对象作为默认参数def add_item_bad(item, lst=[]): lst.append(item) return lstprint(add_item_bad(1)) # [1]print(add_item_bad(2)) # [1, 2] ⚠️ 不是 [2]!print(add_item_bad(3)) # [1, 2, 3] ⚠️ 不是 [3]!# ✅ 正确:使用None作为默认参数def add_item_good(item, lst=None): if lst is None: lst = [] lst.append(item) return lstprint(add_item_good(1)) # [1]print(add_item_good(2)) # [2] ✅print(add_item_good(3)) # [3] ✅
陷阱2:循环中修改列表
# ❌ 错误:边遍历边删除numbers = [1, 2, 3, 4, 5]for num in numbers: if num % 2 == 0: numbers.remove(num)print(numbers) # [1, 3, 5] ⚠️ 可能漏删# ✅ 正确方法1:倒序遍历numbers = [1, 2, 3, 4, 5]for i in range(len(numbers)-1, -1, -1): if numbers[i] % 2 == 0: numbers.pop(i)print(numbers) # [1, 3, 5]# ✅ 正确方法2:创建新列表numbers = [1, 2, 3, 4, 5]numbers = [num for num in numbers if num % 2 != 0]print(numbers) # [1, 3, 5]
陷阱3:浅拷贝问题
# ❌ 错误:浅拷贝嵌套列表original = [[1, 2], [3, 4]]copied = original.copy()copied[0][0] = 999print(original) # [[999, 2], [3, 4]] ⚠️ 原列表被修改了!# ✅ 正确:深拷贝import copyoriginal = [[1, 2], [3, 4]]copied = copy.deepcopy(original)copied[0][0] = 999print(original) # [[1, 2], [3, 4]] ✅print(copied) # [[999, 2], [3, 4]]
陷阱4:列表乘法的陷阱
# ❌ 错误:嵌套列表使用乘法matrix = [[0] * 3] * 3matrix[0][0] = 1print(matrix) # [[1, 0, 0], [1, 0, 0], [1, 0, 0]] ⚠️ 所有行都被修改了!# ✅ 正确:使用列表推导式matrix = [[0] * 3 for _ in range(3)]matrix[0][0] = 1print(matrix) # [[1, 0, 0], [0, 0, 0], [0, 0, 0]] ✅
陷阱5:列表比较
# 列表比较是按字典序print([1, 2, 3] < [1, 2, 4]) # Trueprint([1, 2, 3] < [1, 3]) # Trueprint([2] > [1, 9, 9, 9]) # True ⚠️# 比较列表内容是否相同list1 = [1, 2, 3]list2 = [1, 2, 3]print(list1 == list2) # True (值相同)print(list1 is list2) # False (不是同一个对象)